iobjectspy package¶
Subpackages¶
Submodules¶
iobjectspy.analyst module¶
ananlyst 模块提供了常用的空间数据处理和分析的功能,用户使用analyst 模块可以进行缓冲区分析( create_buffer() )、叠加分析( overlay() )、
创建泰森多边形( create_thiessen_polygons() )、拓扑构面( topology_build_regions() )、密度聚类( kernel_density() )、
插值分析( interpolate() ),栅格代数运算( expression_math_analyst() )等功能。
在 analyst 模块的所有接口中,对输入数据参数要求为数据集( Dataset , DatasetVector , DatasetImage , DatasetGrid )的参数,
都接受直接输入一个数据集对象(Dataset)或数据源别名与数据集名称的组合(例如,'alias/dataset_name', 'alias\dataset_name'),也支持数据源连接信息与数据集名称的组合(例如,'E:/data.udb/dataset_name')。
支持设置数据集
>>> ds = Datasource.open('E:/data.udb') >>> create_buffer(ds['point'], 10, 10, unit='Meter', out_data='E:/buffer_out.udb')支持设置数据集别名和数据集名称组合
>>> create_buffer(ds.alias + '/point' + , 10, 10, unit='Meter', out_data='E:/buffer_out.udb') >>> create_buffer(ds.alias + '\\point', 10, 10, unit='Meter', out_data='E:/buffer_out.udb') >>> create_buffer(ds.alias + '|point', 10, 10, unit='Meter', out_data='E:/buffer_out.udb')支持设置 udb 文件路径和数据集名称组合
>>> create_buffer('E:/data.udb/point', 10, 10, unit='Meter', out_data='E:/buffer_out.udb')支持设置数据源连接信息和数据集名称组合,数据源连接信息包括 dcf 文件、xml 字符串等,具体参考
DatasourceConnectionInfo.make()>>> create_buffer('E:/data_ds.dcf/point', 10, 10, unit='Meter', out_data='E:/buffer_out.udb')
注解
当输入的是数据源信息时,程序会自动打开数据源,但是接口运行结束时不会自动关闭数据源,也就是打开后的数据源会存在当前工作空间中
在 analyst 模块中所有接口中,对输出数据参数要求为数据源( Datasource )的,均接受 Datasource 对象,也可以为 DatasourceConnectionInfo 对象,
同时,也支持当前工作空间下数据源的别名,也支持 UDB 文件路径,DCF 文件路径等。
支持设置 udb 文件路径
>>> create_buffer('E:/data.udb/point', 10, 10, unit='Meter', out_data='E:/buffer_out.udb')支持设置数据源对象
>>> ds = Datasource.open('E:/buffer_out.udb') >>> create_buffer('E:/data.udb/point', 10, 10, unit='Meter', out_data=ds) >>> ds.close()支持设置数据源别名
>>> ds_conn = DatasourceConnectionInfo('E:/buffer_out.udb', alias='my_datasource') >>> create_buffer('E:/data.udb/point', 10, 10, unit='Meter', out_data='my_datasource')
注解
如果输出数据的参数输入的是数据源连接信息或 UDB 文件路径等,程序会自动打开数据源,如果是 UDB 数据源而本地不存在,还会自动新建一个UDB数据源,但需要确保UDB数据源所在的文件目录存在而且可写。 在功能完成后,如果数据源是由程序自动打开或创建的,会被自动关闭掉(这里与输入数据为 Dataset 不同,输入数据中被自动打开的数据源不会自动关闭)。所以,对于有些接口 输出结果为数据集的,就会返回结果数据集的名称,如果传入的是数据源对象,返回的便是结果数据集。
-
iobjectspy.analyst.create_buffer(input_data, distance_left, distance_right=None, unit=None, end_type=None, segment=24, is_save_attributes=True, is_union_result=False, out_data=None, out_dataset_name='BufferResult', progress=None)¶ 创建矢量数据集或记录集的缓冲。
缓冲区分析是围绕空间对象,使用一个或多个与这些对象的距离值(称为缓冲半径)作为半径,生成一个或多个区域的过程。缓冲区也可以理解为空间对象的一种影响或服务范围。
缓冲区分析的基本作用对象是点、线、面。SuperMap 支持对二维点、线、面数据集(或记录集)和网络数据集进行缓冲区分析。其中,对网络数据集进行缓冲区分析时,是对其中的弧段作缓冲区。缓冲区的类型可以分析单重缓冲区(或称简单缓冲区)和多重缓冲区。下面以简单缓冲区为例分别介绍点、线、面的缓冲区。
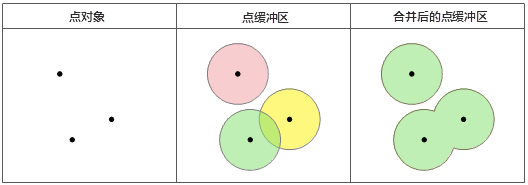
点缓冲区 点的缓冲区是以点对象为圆心,以给定的缓冲距离为半径生成的圆形区域。当缓冲距离足够大时,两个或多个点对象的缓冲区可能有重叠。选择合并缓冲区时,重叠部分将被合并,最终得到的缓冲区是一个复杂面对象。
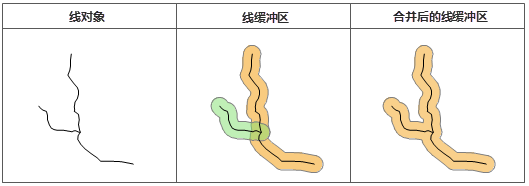
线缓冲区 线的缓冲区是沿线对象的法线方向,分别向线对象的两侧平移一定的距离而得到两条线,并与在线端点处形成的光滑曲线(也可以形成平头)接合形成的封闭区域。同样,当缓冲距离足够大时,两个或多个线对象的缓冲区可能有重叠。合并缓冲区的效果与点的合并缓冲区相同。
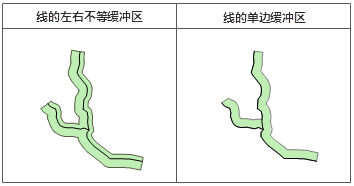
线对象两侧的缓冲宽度可以不一致,从而生成左右不等缓冲区;也可以只在线对象的一侧创建单边缓冲区。此时只能生成平头缓冲区。
面缓冲区
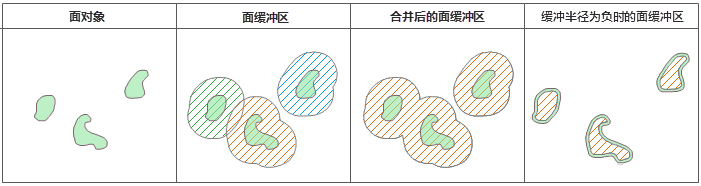
面的缓冲区生成方式与线的缓冲区类似,区别是面的缓冲区仅在面边界的一侧延展或收缩。当缓冲半径为正值时,缓冲区向面对象边界的外侧扩展;为负值时,向边界内收缩。同样,当缓冲距离足够大时,两个或多个线对象的缓冲区可能有重叠。也可以选择合并缓冲区,其效果与点的合并缓冲区相同。
多重缓冲区是指在几何对象的周围,根据给定的若干缓冲区半径,建立相应数据量的缓冲区。对于线对象,还可以建立单边多重缓冲区,但注意不支持对网络数据集创建。
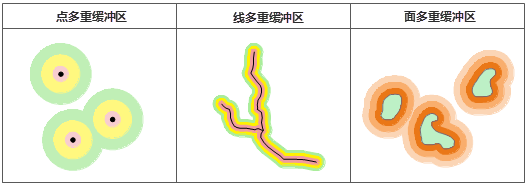
缓冲区分析在 GIS 空间分析中经常用到,且往往结合叠加分析来共同解决实际问题。缓冲区分析在农业、城市规划、生态保护、防洪抗灾、军事、地质、环境等诸多领域都有应用。
例如扩建道路时,可根据道路扩宽宽度对道路创建缓冲区,然后将缓冲区图层与建筑图层叠加,通过叠加分析查找落入缓冲区而需要被拆除的建筑;又如,为了保护环境和耕地,可对湿地、森林、草地和耕地进行缓冲区分析,在缓冲区内不允许进行工业建设。
说明:
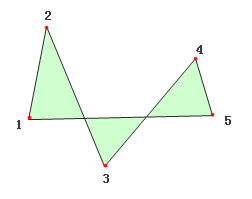
- 对于面对象,在做缓冲区分析前最好先经过拓扑检查,排除面内相交的情况,所谓面内相交,指的是面对象自身相交,如图所示,图中数字代表面对象的节点顺序。
对“负半径”的说明
- 如果缓冲区半径为数值型,则仅面数据支持负半径;
- 如果缓冲区半径为字段或字段表达式,如果字段或字段表达式的值为负值,对于点、线数据取其绝对值;对于面数据,若合并缓冲区,则取其绝对值,若不合并,则按照负半径处理。
参数: - input_data (Recordset or DatasetVector or str) -- 指定的创建缓冲区的源矢量记录集是数据集。支持点、线、面数据集和记录集。
- distance_left (float or str) -- (左)缓冲区的距离。如果为字符串,则表示(左)缓冲距离所在的字段,即每个几何对象创建缓冲区时使用字段中存储的值作为缓冲半径。对于线对象,表示左缓冲区半径,对于点和面对象,表示缓冲区半径。
- distance_right (float or str) -- 右缓冲区的距离,如果为字符串,则表示右缓冲距离所在的字段,即每个线几何对象创建缓冲区时使用字段中存储的值作为右缓冲半径。该参数只对线对象有效。
- unit (Unit or str) -- 缓冲区距离半径单位,只支持距离单位,不支持角度和弧度单位。
- end_type (BufferEndType or str) -- 缓冲区端点类型。用以区分线对象缓冲区分析时的端点是圆头缓冲还是平头缓冲。对于点或面对象,只支持圆头缓冲
- segment (int) -- 半圆弧线段个数,即用多少个线段来模拟一个半圆,必须大于等于4。
- is_save_attributes (bool) -- 是否保留进行缓冲区分析的对象的字段属性。当合并结果面数据集时,该参数无效。即当 isUnion 参数为 false 时有效。
- is_union_result (bool) -- 是否合并缓冲区,即是否将源数据各对象生成的所有缓冲区域进行合并运算后返回。对于面对象而言,要求源数据集中的面对象不相交。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.overlay(source_input, overlay_input, overlay_mode, source_retained=None, overlay_retained=None, tolerance=1e-10, out_data=None, out_dataset_name='OverlayOutput', progress=None, output_type=OverlayAnalystOutputType.INPUT, is_support_overlap_in_layer=False)¶ 叠加分析用于对输入的两个数据集或记录集之间进行各种叠加分析运算,如裁剪(clip)、擦除(erase)、合并(union)、相交(intersect)、同一(identity)、 对称差(xOR)和更新(update)。叠加分析是 GIS 中的一项非常重要的空间分析功能。是指在统一空间参考系统下,通过对两个数据集进行的一系列集合运算, 产生新数据集的过程。叠加分析广泛应用r于资源管理、城市建设评估、国土管理、农林牧业、统计等领域。因此,通过此叠加分析类可实现对空间数据的加工和分析, 提取用户需要的新的空间几何信息,并且对数据的属性信息进行处理。
- 进行叠加分析的两个数据集中,被称作输入数据集(在 SuperMap GIS 中称作第一数据集)的那个数据集,其类型可以是点、线、面等;另一个被称作叠加数据集(在 SuperMap GIS 中称作第二数据集)的数据集,其类型一般是面类型。
- 应注意面数据集或记录集中本身应避免包含重叠区域,否则叠加分析结果可能出错。
- 叠加分析的数据必须为具有相同地理参考的数据,包括输入数据和结果数据。
- 在叠加分析的数据量较大的情况下,需对结果数据集创建空间索引,以提高数据的显示速度
- 所有叠加分析的结果都不考虑数据集的系统字段
- 需要注意:
- 当 source_input 为数据集时,overlay_input 可以为数据集、记录集和面几何对象列表
- 当 source_input 为记录集时,overlay_input 可以为数据集、记录集和面几何对象列表
- 当 source_input 为几何对象列表时,overlay_input 可以为数据集、记录集和面几何对象列表
- 当 source_input 为几何对象列表时,必须设置有效的结果数据源信息
参数: - source_input (DatasetVector or Recordset or list[Geometry]) -- 叠加分析的源数据,可以是数据集、记录集和几何对象列表。当叠加分析模式为 update、xor 和 union 时,源数据只支持面数据。 当叠加分析模式为 clip、intersect、erase 和 identity 时,源数据支持点线面。
- overlay_input (DatasetVector or Recordset or list[Geometry]) -- 参与计算的叠加数据,必须为面类型数据,可以是数据集、记录集和几何对象列表
- overlay_mode (OverlayMode or str) -- 叠加分析模式
- source_retained (list[str] or str) -- 源数据集或记录集中需要保留的字段。当 source_retained 为 str 时,支持设置 ',' 分隔多个字段,例如 "field1,field2,field3"
- overlay_retained (list[str] or str) -- 参与计算的叠加数据需要保留的字段。当 overlay_retained 为 str 时,支持设置 ',' 分隔多个字段,例如 "field1,field2,field3"。 对于裁剪 (CLIP) 和擦除 (ERASE) 无效
- tolerance (float) -- 叠加分析的容限值
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据保存的数据源。如果为空,则结果数据集保存到叠加分析源数据集所在的数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - output_type (str or OverlayAnalystOutputType) -- 结果数据集类型,对于面面求交,可以选择返回点数据集。
- is_support_overlap_in_layer (bool) -- 是否支持数据集内存在面重叠的对象。默认为 False,即不支持,如果面数据集内存在交叠情形,则叠加 分析结果可能会存在错误。如果设置为 True,将使用新的算法进行计算。
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.multilayer_overlay(inputs, overlay_mode, output_attribute_type='ONLYATTRIBUTES', tolerance=1e-10, out_data=None, out_dataset_name='OverlayOutput', progress=None)¶ 多图层叠加分析,支持多数据集或多记录集的叠加分析。只支持面数据集或面对象叠加分析。
>>> ds = open_datasource('E:/data.udb') >>> input_dts = [ds['dltb_2017'], ds['dltb_2018'], ds['dltb_2019']] >>> result_dt = multilayer_overlay(input_ds, 'intersect', 'OnlyID', 1.0e-7) >>> assert result_dt is not None True
参数: - inputs (list[DatasetVector] or list[Recordset] or list[list[Geometry]]) -- 参加叠加分析的数据集或记录集
- overlay_mode (OverlayMode or str) -- 叠加分析模式,仅支持相交(
OverlayMode.INTERSECT)和合并(OverlayMode.UNION) - output_attribute_type (OverlayOutputAttributeType or str) -- 多图层叠加分析字段属性返回类型
- tolerance (float) -- 节点容限
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据保存的数据源。如果为空,则结果数据集保存到叠加分析源数据集所在的数据源。当 inputs 输入中全是几何对象数组时,必须 设置结果数据保存的数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.create_random_points(dataset_or_geo, random_number, min_distance=None, clip_bounds=None, out_data=None, out_dataset_name=None, progress=None)¶ 在几何对象内随机生成点。生成随机点可以指定结果随机点数目和随机点距离,当同时指定随机点数目和最小距离时,优先满足最小距离,即生成的随机点之间的距 离一定大于最小距离,当数目可能少于随机点数目。
>>> ds = open_datasource('E:/data.udb') >>> dt = ds['dltb'] >>> polygon = dt.get_geometries('SmID == 1')[0] >>> points = create_random_points(polygon, 10) >>> print(len(points)) 10 >>> points = create_random_points(polygon, 10, 1500) >>> print(len(points)) 9 >>> assert compute_distance(points(0),points(1)) > 1500 True >>> >>> random_dataset = create_random_points(dt, 10, 1500, None, ds, 'random_points', None) >>> print(random_dataset.type) 'Point'
参数: - dataset_or_geo (GeoRegion or GeoLine or Rectangle or DatasetVector or str) -- 用于创建随机点的几何对象或数据集。当指定为单个几何对象时,支持线和面类型几何对象。当指定为数据集时,支持点、线和面类 型的数据集。
- random_number (str or float) -- 随机点数目或随机点数目所在的字段名称。只有在数据集中生成随机点才能指定为字段名称。
- min_distance (str or float) -- 随机点最小距离或最小距离所在的字段名称。当随机点距离值为 None 或 0 时,则生成的随机点不考虑两点之间距离限制。当大于 0时,任意两个随机点之间的距离必须大于指定的距离,此时,生成的随机点数目可能不一定等于指定的随机点数目。只有在数据集中 生成随机点才能指定为字段名称。
- clip_bounds (Rectangle) -- 生成随机点的范围,可以为 None。当为 None 时,则在整个数据集或几何对象内生成随机点。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 随机点列表或随机点所在的数据集。当在几何对象中生成随机点时,将返回 list[Point2D]。当在数据集中生成随机点时,将返回数据集。
返回类型: list[Point2D] or DatasetVector or str
-
iobjectspy.analyst.regularize_building_footprint(dataset_or_geo, offset_distance, offset_distance_unit=None, regularize_method=RegularizeMethod.ANYANGLE, min_area=0.0, min_hole_area=0.0, prj=None, is_attribute_retained=False, out_data=None, out_dataset_name=None, progress=None)¶ 对面类型的建筑物对象进行规则化处理,生成覆盖原始面对象的规则化对象。
>>> ds = open_datasource('E:/data.udb') >>> dt = ds['building'] >>> polygon = dt.get_geometries('SmID == 1')[0]
对几何对象进行规则化处理,偏移距离为 0.1,单位为数据集坐标系单位:
>>> regularize_result = regularize_building_footprint(polygon, 0.1, None, RegularizeMethod.ANYANGLE, >>> prj=dt.prj_coordsys) >>> assert regularize_result.type == GeometryType.GEOREGION
True
对数据集进行规则化处理:
>>> regularize_dt = regularize_building_footprint(dt, 0.1, 'meter', RegularizeMethod.RIGHTANGLES, min_area=10.0, >>> min_hole_area=2.0, is_attribute_retained=False) >>> assert regularize_dt.type = DatasetType.REGION
True
参数: - dataset_or_geo (GeoRegion or Rectangle or DatasetVector or str) -- 待处理的建筑物面对象或面数据集
- offset_distance (float) -- 规则化对象可从其原始对象的边界偏移的最大距离。通过 .py:attr:.offset_distance_unit 可以设置基于 数据坐标系的线性单位值,也可以设置距离单位值。
- offset_distance_unit (Unit or str) -- 规则化偏移距离的单位,默认为 None,即使用数据的单位。
- regularize_method (RegularizeMethod or str) -- 规则化方法
- min_area (float) -- 规则化对象的最小面积,小于该面积的对象将被删除。当值大于0时才有效。当空间坐标系或数据集的坐标系为投影或经纬度时,面 积单位为平方米,当坐标系为 None 或为平面坐标系时,面积单位与数据单位相对应。
- min_hole_area (float) -- 规则化对象中洞的最小面积,小于该面积的洞将被删除。当值大于0时才有效。当空间坐标系或数据集的坐标系为投影或经纬 度时,面积单位为平方米,当坐标系为 None 或为平面坐标系时,面积单位与数据单位相对应
- prj (PrjCoordSys or str) -- 建筑物面对象的坐标系,仅当输入为几何对象时才有效。
- is_attribute_retained (bool) -- 是否保存原对象的属性字段值。当输入为数据集时才有效。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果规则化面对象或面数据集。输入为面对象的,生成的结果也为面对象。输入为面数据集时,生成的结果也为面数据集,生成的面数据集中将会生成一 个 status 字段,status 字段值为 0 时表示规则化失败,保存的对象为原始对象。status 字段值为 1 时表示规则化成功,保存的对象为规则化 对象。
返回类型:
-
iobjectspy.analyst.tabulate_area(class_dataset, zone_dataset, class_field=None, zone_field=None, resolution=None, out_data=None, out_dataset_name=None, progress=None)¶ 区域制表,统计区域面内的各类别面积,并输出属性表。便于用户查看各区域内每种类别的面积汇总情况。 结果属性表中:
- 区域数据集的每个唯一值有一条记录 - 待进行面积统计的类别数据集的每个唯一值具有一个字段 - 每个记录将存储每个区域内每个类别的面积 .. image:: ../image/TabulateArea.png
参数: - class_dataset (DatasetGrid or DatasetVector or str) -- 待进行面积统计的类别数据集,支持栅格和点、线、面数据集。建议优先使用栅格数据集,若使用点或线数据集,则将输出与要素相 交的区域
- zone_dataset (DatasetGrid or DatasetVector or str) -- 区域数据集,支持栅格和点、线、面数据集。区域定义为输入中具有相同值的所有区,各区无需相连。 建议优先使用栅格数据集,若使用矢量数据集,则会在内部对其使用“矢量转栅格”进行转换。
- class_field (str) -- 面积统计的类别字段,当
class_dataset为 DatasetVector 时,必须指定有效的类别字段。 - zone_field (str) -- 区域指字段。当
zone_dataset为 DatasetVector 时,必须指定有效的区域值字段。 - resolution (float) -- 分辨率。区域制表结果汇总了各区域各类别的面积情况,该面积是用各类别栅格数和分辨率计算得到,因此,分辨率直接影响面积 统计结果。用户根据需求及期望设置分辨率,如果设置的分辨率与区域数据或类型数据的分辨率不同,内部会重采样为设置的分辨 率,使得耗时增加。若没有分辨率要求,建议可以不设置该值,即使用默认分辨率。 未设置该值时,默认分辨率由区域数据集确定: - 如果区域数据集为栅格,默认分辨率与区域栅格分辨率相同 - 如果区域数据集为矢量,默认分辨率为该矢量数据集空间范围的长或宽较小值除以250.
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果属性表数据集
返回类型:
-
iobjectspy.analyst.auto_compute_project_points(point_input, line_input, max_distance, out_data=None, out_dataset_name=None, progress=None)¶ 自动计算点到线的垂足。
>>> ds = open_datasource('E:/data.udb') >>> auto_compute_project_points(ds['point'], ds['line'], 10.0)
参数: - point_input (DatasetVector or Recordset) -- 输入的点数据集或记录集
- line_input (DatasetVector or Recordset) -- 输入的线数据集或记录集
- max_distance (float) -- 最大查询距离,距离单位与数据集坐标系单位相同。当值小于0时,表示搜索距离不受限制。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回点到线的垂足。
返回类型: DatasetVector or str
-
iobjectspy.analyst.compute_natural_breaks(input_dataset_or_values, number_zones, value_field=None)¶ 计算自然间断点。自然间断点法(Jenks Natural Breaks)是一种根据数值统计分布规律分级和分类的统计方法,它能使类与类之间的不同最大化,即可以使组内方差尽量小,组间方差尽量大, 要素被划分为多级或多类,对于这些级或类,会在数据值的差异相对较大的位置处设置其边界。
参数: - input_dataset_or_values (DatasetGrid or DatasetVector or list[float]) -- 待分析的数据集或浮点数列表。支持栅格数据集和矢量数据集。
- number_zones (int) -- 分组数量
- value_field (str) -- 用于进行自然间断点分段的字段名称。当输入的数据集为矢量数据集时,必须设置有效的字段名称。
返回: 自然间断点数组,每个间断点的值为该分组的最大值
返回类型: list[float]
-
iobjectspy.analyst.erase_and_replace_raster(input_data, replace_region, replace_value, out_data=None, out_dataset_name=None, progress=None)¶ 对栅格或影像数据集进行擦除与填充,即可以修改指定区域的栅格值。
>>> region = Rectangle(875.5, 861.2, 1172.6, 520.9) >>> result = erase_and_replace_raster(data_dir + 'example_data.udbx/seaport', region, (43,43,43))
对栅格数据进行处理:
>>> region = Rectangle(107.352104894652, 30.1447395778174, 107.979276445055, 29.6558796240814) >>> result = erase_and_replace_raster(data_dir + 'example_data.udbx/DEM', region, 100)
参数: - input_data (DatasetImage or DatasetGrid or str) -- 要进行擦除的栅格或影像数据集
- replace_region (Rectangle or GeoRegion) -- 擦除区域
- replace_value (float or int or tuple[int,int,int]) -- 擦除区域的替换值,使用 replace_value 替换指定擦除区域内的栅格值。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or DatasetImage or str
-
iobjectspy.analyst.dissolve(input_data, dissolve_type, dissolve_fields, field_stats=None, attr_filter=None, is_null_value_able=True, is_preprocess=True, tolerance=1e-10, out_data=None, out_dataset_name='DissolveResult', progress=None)¶ 融合是指将融合字段值相同的对象合并为一个简单对象或复杂对象。适用于线对象和面对象。子对象是构成简单对象和复杂对象的基本对象。简单对象由一个子对象组成, 即简单对象本身;复杂对象由两个或两个以上相同类型的子对象组成。
参数: - input_data (DatasetVector or str) -- 待融合的矢量数据集。必须为线数据集或面数据集。
- dissolve_type (DissolveType or str) -- 融合类型
- dissolve_fields (list[str] or str) -- 融合字段,融合字段的字段值相同的记录才会融合。当 dissolve_fields 为 str 时,支持设置 ',' 分隔多个字段,例如 "field1,field2,field3"
- field_stats (list[tuple[str,StatisticsType]] or list[tuple[str,str]] or str) -- 统计字段名称和对应的统计类型。stats_fields 为 list,list中每个元素为一个tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型。 当 stats_fields 为 str 时,支持设置 ',' 分隔多个字段,例如 "field1:SUM, field2:MAX, field3:MIN"
- attr_filter (str) -- 数据集融合时对象的过滤表达式
- tolerance (float) -- 融合容限
- is_null_value_able (bool) -- 是否处理融合字段值为空的对象
- is_preprocess (bool) -- 是否进行拓扑预处理
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据保存的数据源。如果为空,则结果数据集保存到输入数据集所在的数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
>>> result = dissolve('E:/data.udb/zones', 'SINGLE', 'SmUserID', 'Area:SUM', tolerance=0.000001, out_data='E:/dissolve_out.udb')
-
iobjectspy.analyst.aggregate_points(input_data, min_pile_point, distance, unit=None, class_field=None, out_data=None, out_dataset_name='AggregateResult', progress=None)¶ 对点数据集进行聚类,使用密度聚类算法,返回聚类后的类别或同一簇构成的多边形。 对点集合进行空间位置的聚类,使用密度聚类方法 DBSCAN,它能将具有足够高密度的区域划分为簇,并可以在带有噪声的空间数据中发现任意形状的聚类。它定义 簇为密度相连的点的最大集合。DBSCAN 使用阈值 e 和 MinPts 来控制簇的生成。其中,给定对象半径 e 内的区域称为该对象的 e一邻域。如果一个对象的 e一邻域至少包含最小数目 MinPtS 个对象,则称该对象为核心对象。给定一个对象集合 D,如果 P 是在 Q 的 e一邻域内,而 Q 是一个核心对象,我们说对象 P 从对象 Q 出发是直接密度可达的。DBSCAN 通过检查数据里中每个点的 e-领域来寻找聚类,如果一个点 P 的 e-领域包含多于 MinPts 个点,则创建一个 以 P 作为核心对象的新簇,然后,DBSCAN反复地寻找从这些核心对象直接密度可达的对象并加入该簇,直到没有新的点可以被添加。
参数: - input_data (DatasetVector or str) -- 输入的点数据集
- min_pile_point (int) -- 密度聚类点数目阈值,必须大于等于2。阈值越大表示能聚类为一簇的条件越苛刻。
- distance (float) -- 密度聚类半径。
- unit (Unit or str) -- 密度聚类半径的单位。
- class_field (str) -- 输入的点数据集中用于保存密度聚类的结果聚类类别的字段,如果不为空,则必须是点数据集中合法的字段名称。 要求字段类型为INT16, INT32 或 INT64,如果字段名有效但不存在,将会创建一个 INT32 的字段。 参数有效,则会将聚类类别保存在此字段中。
- out_data (Datasource or DatasourceConnectionInfo or st) -- 结果数据源信息,结果数据源信息不能与 class_field同时为空,如果结果数据源有效时,将会生成结果面对象。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称,如果输入的结果数据源为空,将会返回一个布尔值,True 表示聚类成功,False 表示聚类失败。
返回类型: DatasetVector or str or bool
>>> result = aggregate_points('E:/data.udb/point', 4, 100, 'Meter', 'SmUserID', out_data='E:/aggregate_out.udb')
-
iobjectspy.analyst.smooth_vector(input_data, smoothness, out_data=None, out_dataset_name=None, progress=None, is_save_topology=False)¶ 对矢量数据集进行光滑,支持线数据集、面数据集和网络数据集
光滑的目的
当折线或多边形的边界的线段过多时,就可能影响对原始特征的描述,不利用进一步的处理或分析,或显示和打印效果不够理想,因此需要对数据简化。简化的方法 一般有重采样(
resample_vector())和光滑。光滑是通过增加节点的方式使用曲线或直线段来代替原始折线的方法。需要注意,对折线进行光滑后, 其长度通常会变短,折线上线段的方向也会发生明显改变,但两个端点的相对位置不会变化;面对象经过光滑后,其面积通常会变小。光滑方法与光滑系数的设置
该方法采用 B 样条法对矢量数据集进行光滑。有关 B 样条法的介绍可参见 SmoothMethod 类。光滑系数(方法中对应 smoothness 参数)影响着光滑的程度, 光滑系数越大,结果数据越光滑。光滑系数的建议取值范围为[2,10]。该方法支持对线数据集、面数据集和网络数据集进行光滑。
- 对线数据集设置不同光滑系数的光滑效果:

- 对面数据集设置不同光滑系数的光滑效果:
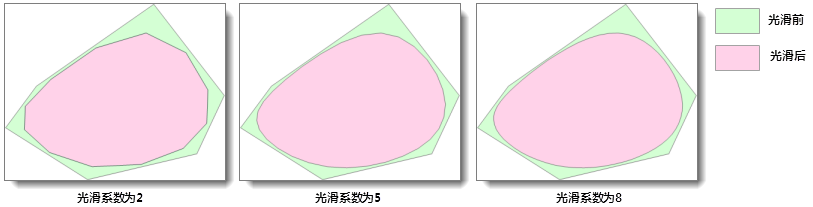
参数: - input_data (DatasetVector or str) -- 需要进行光滑处理的数据集,支持线数据集、面数据集和网络数据集
- smoothness (int) -- 指定的光滑系数。取大于等于 2 的值有效,该值越大,线对象或面对象边界的节点数越多,也就越光滑。建议取值范围为[2,10]。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源所在半径,如果此参数为空,将直接对原始数据做光滑,也就是会改变原始数据。如果此参数不为空,将会先复制原始数据到此数据源中, 再对复制得到的数据集进行光滑处理。out_data 所指向数据源可以与源数据集所在的数据源相同。
- out_dataset_name (str) -- 结果数据集名称,当 out_data 不为空时才有效。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - is_save_topology (bool) -- 是否保存对象拓扑关系
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.resample_vector(input_data, distance, resample_type=VectorResampleType.RTBEND, is_preprocess=True, tolerance=1e-10, is_save_small_geometry=False, out_data=None, out_dataset_name=None, progress=None, is_save_topology=False)¶ 对矢量数据集进行重采样,支持线数据集、面数据集和网络数据集。 矢量数据重采样是按照一定规则剔除一些节点,以达到对数据进行简化的目的(如下图所示), 其结果可能由于使用不同的重采样方法而不同。SuperMap 提供了两种重采样方法,具体参考
VectorResampleType
该方法可以对线数据集、面数据集和网络数据集进行重采样。对面数据集重采样时,实质是对面对象的边界进行重采样。对于多个面对象的公共边界,如果进行了 拓扑预处理只对其中一个多边形的该公共边界重采样一次,其他多边形的该公共边界会依据该多边形重采样的结果进行调整使之贴合,因此不会出现缝隙。
注意: 重采样容限过大时,可能影响数据正确性,如出现两多边形的公共边界处出现相交的情况。
参数: - input_data (DatasetVector or str) -- 需要进行重采样的矢量数据集,支持线数据集、面数据集和网络数据集
- distance (float) -- 设置重采样距离。单位与数据集坐标系单位相同。重采样距离可设置为大于 0 的浮点型数值。但如果设置的值小于默认值,将使用默认值。设置的重采样容限值越大,采样结果数据越简化
- resample_type (VectorResampleType or str) -- 重采样方法。重采样支持光栏采样算法和道格拉斯算法。具体参考
VectorResampleType。默认使用光栏采样。 - is_preprocess (bool) -- 是否进行拓扑预处理。只对面数据集有效,如果数据集不进行拓扑预处理,可能会导致缝隙,除非能确保数据中两个相邻面公共线部分的节点坐标完全一致。
- tolerance (float) -- 进行拓扑预处理时的节点捕捉容限,单位与数据集单位相同。
- is_save_small_geometry (bool) -- 是否保留小对象。小对象是指面积为0的对象,重采样过程有可能产生小对象。true 表示保留小对象,false 表示不保留。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源所在半径,如果此参数为空,将直接对原始数据做采样,也就是会改变原始数据。如果此参数不为空,将会先复制原始数据到此数据源中, 再对复制得到的数据集进行采样处理。out_data 所指向数据源可以与源数据集所在的数据源相同。
- out_dataset_name (str) -- 结果数据集名称,当 out_data 不为空时才有效。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - is_save_topology (bool) -- 是否保存对象拓扑关系
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.create_thiessen_polygons(input_data, clip_region, field_stats=None, out_data=None, out_dataset_name=None, progress=None)¶ 创建泰森多边形。 荷兰气候学家 A.H.Thiessen 提出了一种根据离散分布的气象站的降雨量来计算平均降雨量的方法,即将所有相邻气象站连成三角形,作这些三角形各边的垂直平分线, 于是每个气象站周围的若干垂直平分线便围成一个多边形。用这个多边形内所包含的一个唯一气象站的降雨强度来表示这个多边形区域内的降雨强度,并称这个多边形为泰森多边形。
泰森多边形的特性:
- 每个泰森多边形内仅含有一个离散点数据;
- 泰森多边形内的点到相应离散点的距离最近;
- 位于泰森多边形边上的点到其两边的离散点的距离相等。
- 泰森多边形可用于定性分析、统计分析、邻近分析等。例如,可以用离散点的性质来描述泰森多边形区域的性质;可用离散点的数据来计算泰森多边形区域的数据
- 判断一个离散点与其它哪些离散点相邻时,可根据泰森多边形直接得出,且若泰森多边形是n边形,则就与n个离散点相邻;当某一数据点落入某一泰森多边形中时,它与相应的离散点最邻近,无需计算距离。
邻近分析是 GIS 领域里又一个最为基础的分析功能之一,邻近分析是用来发现事物之间的某种邻近关系。邻近分析类所提供的进行邻近分析的方法都是实现泰森多边形的建立, 就是根据所提供的点数据建立泰森多边形,从而获得点之间的邻近关系。泰森多边形用于将点集合中的点的周围区域分配给相应的点,使位于这个点所拥有的区域(即该点所关联的泰森多边形) 内的任何地点离这个点的距离都要比离其他点的距离要小,同时,所建立的泰森多边形还满足上述所有的泰森多边形法的理论。
泰森多边形是如何创建的?利用下面的图示来理解泰森多边形建立的过程:
- 对待建立泰森多边形的点数据进行由左向右,由上到下的扫描,如果某个点距离之前刚刚扫描过的点的距离小于给定的邻近容限值,那么分析时将忽略该点;
- 基于扫描检查后符合要求的所有点建立不规则三角网,即构建 Delaunay 三角网;
- 画出每个三角形边的中垂线,由这些中垂线构成泰森多边形的边,而中垂线的交点是相应的泰森多边形的顶点;
- 用于建立泰森多边形的点的点位将成为相应的泰森多边形的锚点。
参数: - input_data (DatasetVector or Recordset or list[Point2D]) -- 输入的点数据,可以为点数据集、点记录集或
Point2D的列表 - clip_region (GeoRegion) -- 指定的裁剪结果数据的裁剪区域。该参数可以为空,如果为空,结果数据集将不进行裁剪
- field_stats (list[str,StatisticsType] or list[str,str] or str) -- 统计字段名称和对应的统计类型,输入为一个list,list中存储的每个元素为tuple,tuple的大小为2,第一个元素为被统计的字段名称,第二个元素为统计类型。 当 stats_fields 为 str 时,支持设置 ',' 分隔多个字段,例如 "field1:SUM, field2:MAX, field3:MIN"
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果面对象所在的数据源。如果 out_data 为空,则会将生成的泰森多边形面几何对象直接返回
- out_dataset_name (str) -- 结果数据集名称,当 out_data 不为空时才有效。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 如果 out_data 为空,将返回 list[GeoRegion],否则返回结果数据集或数据集名称。
返回类型: DatasetVector or str or list[GeoRegion]
-
iobjectspy.analyst.summary_points(input_data, radius, unit=None, stats=None, is_random_save_point=False, is_save_attrs=False, out_data=None, out_dataset_name=None, progress=None)¶ 根据指定的距离抽稀点数据集,即用一个点表示指定距离范围内的所有点。 该方法支持不同的单位,并且可以选择点抽稀的方式,还可以对抽稀点原始点集做统计。 在结果数据集 resultDatasetName 中,会新建SourceObjID 和 StatisticsObjNum 两个字段。SourceObjID 字段存储抽稀后得到的点对象在原始数据集 中的 SmID, StatisticsObjNum 表示当前点所代表的所有点数目,包括被抽稀的点和其自身。
参数: - input_data (DatasetVector or str or Recordset) -- 待抽稀的点数据集
- radius (float) -- 抽稀点的半径。任取一个坐标点,在此坐标点半径内的所有点坐标通过此点表示。需注意选择抽稀点的半径的单位。
- unit (Unit or str) -- 抽稀点半径的单位。
- stats (list[StatisticsField] or str) -- 对抽稀点原始点集做统计。需要设置统计的字段名,统计结果的字段名和统计模式。当该数组为空表示不做统计。当 stats 为 str 时,支持设置以 ';' 分隔多个 StatisticsField,每个 StatisticsField 使用 ',' 分隔 'source_field,stat_type,result_name',例如: 'field1,AVERAGE,field1_avg; field2,MINVALUE,field2_min'
- is_random_save_point (bool) -- 是否随机保存抽稀点。True表示从抽稀半径范围内的点集中随机取一个点保存,False表示取抽稀半径范围内点集中距点集内所有点的距离之和最小的点。
- is_save_attrs (bool) -- 是否保留属性字段
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.clip_vector(input_data, clip_region, is_clip_in_region=True, is_erase_source=False, out_data=None, out_dataset_name=None, progress=None)¶ 对矢量数据集进行裁剪,结果存储为一个新的矢量数据集。
参数: - input_data (DatasetVector or str) -- 指定的要进行裁剪的矢量数据集,支持点、线、面、文本、CAD 数据集。
- clip_region (GeoRegion) -- 指定的裁剪区域
- is_clip_in_region (bool) -- 指定是否对裁剪区内的数据集进行裁剪。若为 True,则对裁剪区域内的数据集进行裁剪,若为 False ,则对裁剪区域外的数据集进行裁剪。
- is_erase_source (bool) -- 指定是否擦除裁剪区域,若为 True,表示对裁剪区域进行擦除,若为 False,则不对裁剪区域进行擦除。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.update_attributes(source_data, target_data, spatial_relation, update_fields, interval=1e-06)¶ 矢量数据集属性更新,将 source_data 中的属性,根据 spatial_relation 指定的空间关系,更新到 target_data 数据集中。 例如,有一份点数据和面数据,需要将点数据集中的属性值取平均值,然后将值写到包含点的面对象中,可以通过以下代码实现:
>>> result = update_attributes('ds/points', 'ds/zones', 'WITHIN', [('trip_distance', 'mean'), ('', 'count')])
spatial_relation 参数是指源数据集( source_data)对目标被更新数据集(target_data)的空间关系。
参数: - source_data (DatasetVector or str) -- 源数据集。源数据集提供属性数据,将源数据集中的属性值根据空间关系更新到目标数据集中。
- target_data (DatasetVector or str) -- 目标数据集。被写入属性数据的数据集。
- spatial_relation (SpatialQueryMode or str) -- 空间关系类型,源数据(查询对象)对目标数据(被查询对象)的空间关系,具体参考
SpatialQueryMode - update_fields (list[tuple(str,AttributeStatisticsMode)] or list[tuple(str,str)] or str) -- 字段统计信息,可能有多个源数据中对象与目标数据对象满足空间关系,需要对源数据的属性字段值进行汇总统计,将统计的结果写入到目标数据集中 为一个list,list中每个元素为一个 tuple,tuple的大小为2,tuple的第一个元素为被统计的字段名称,tuple的第二个元素为统计类型。
- interval (float) -- 节点容限
返回: 是否属性更新成功。更新成功返回 True,否则返回 False。
返回类型: bool
-
iobjectspy.analyst.simplify_building(source_data, width_threshold, height_threshold, save_failed=False, out_data=None, out_dataset_name=None)¶ 面对象的直角多边形拟合 如果一串连续的节点到最小面积外接矩形的下界的距离大于 height_threshold,且节点的总宽度大于 width_threshold,则对连续节点进行拟合。
参数: - source_data (DatasetVector or str) -- 需要处理的面数据集
- width_threshold (float) -- 点到最小面积外接矩形的左右边界的阈值
- height_threshold (float) -- 点到最小面积外接矩形的上下边界的阈值
- save_failed (bool) -- 面对象进行直角化失败时,是否保存源面对象,如果为 False,则结果数据集中不含失败的面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据集的数据源。
- out_dataset_name (str) -- 结果数据集名称
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.resample_raster(input_data, new_cell_size, resample_mode, out_data=None, out_dataset_name=None, progress=None)¶ 栅格数据重采样,返回结果数据集。
栅格数据经过了配准或纠正、投影等几何操作后,栅格的像元中心位置通常会发生变化,其在输入栅格中的位置不一定是整数的行列号,因此需要根据输出栅格上每个格子在输入栅格中的位置,对输入栅格按一定规则进行重采样,进行栅格值的插值计算,建立新的栅格矩阵。不同分辨率的栅格数据之间进行代数运算时,需要将栅格大小统一到一个指定的分辨率上,此时也需要对栅格进行重采样。
栅格重采样有三种常用方法:最邻近法、双线性内插法和三次卷积法。有关这三种重采样方法较为详细的介绍,请参见 ResampleMode 类。
参数: - input_data (DatasetImage or DatasetGrid or str) -- 指定的用于栅格重采样的数据集。支持影像数据集,包括多波段影像
- new_cell_size (float) -- 指定的结果栅格的单元格大小
- resample_mode (ResampleMode or str) -- 重采样计算方法
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetImage or DatasetGrid or str
-
class
iobjectspy.analyst.ReclassSegment(start_value=None, end_value=None, new_value=None, segment_type=None)¶ 基类:
object栅格重分级区间类。该类主要用于重分级区间信息的相关设置,包括区间的起始值、终止值等。
该类用于设置在进行重分级时,重分级映射表中每个重分级区间的参数,重分级类型不同,需要设置的属性也有所不同。
- 当重分级类型为单值重分级时,需要通过
set_start_value()方法指定需要被重新赋值的源栅格的单值,并通过set_new_value()方法设置该值对应的新值。 - 当重分级类型为范围重分级时,需要通过
set_start_value()方法指定需要重新赋值的源栅格值区间的起始值,通过set_end_value()方法设置区间的终止值, 并通过set_new_value()方法设置该区间对应的新值,还可以由set_segment_type()方法设置区间类型是“左开右闭”还是“左闭右开”。
构造栅格重分级区间对象
参数: - start_value (float) -- 栅格重分级区间的起始值
- end_value (float) -- 栅格重分级区间的终止值
- new_value (float) -- 栅格重分级的区间值或旧值对应的新值
- segment_type (ReclassSegmentType or str) -- 栅格重分级区间类型
-
end_value¶ float -- 栅格重分级区间的终止值
-
from_dict(values)¶ 从dict中读取信息
参数: values (dict) -- 包含 ReclassSegment 信息的 dict 返回: self 返回类型: ReclassSegment
-
static
make_from_dict(values)¶ 从dict中读取信息构造 ReclassSegment 对象
参数: values (dict) -- 包含 ReclassSegment 信息的 dict 返回: 栅格重分级区间对象 返回类型: ReclassSegment
-
new_value¶ float -- 栅格重分级的区间值或旧值对应的新值
-
segment_type¶ ReclassSegmentType -- 栅格重分级区间类型
-
set_end_value(value)¶ 栅格重分级区间的终止值
参数: value (float) -- 栅格重分级区间的终止值 返回: self 返回类型: ReclassSegment
-
set_new_value(value)¶ 栅格重分级的区间值或旧值对应的新值
参数: value (float) -- 栅格重分级的区间值或旧值对应的新值 返回: self 返回类型: ReclassSegment
-
set_segment_type(value)¶ 设置栅格重分级区间类型
参数: value (ReclassSegmentType or str) -- 栅格重分级区间类型 返回: self 返回类型: ReclassSegment
-
set_start_value(value)¶ 设置栅格重分级区间的起始值
参数: value (float) -- 栅格重分级区间的起始值 返回: self 返回类型: ReclassSegment
-
start_value¶ float -- 栅格重分级区间的起始值
-
to_dict()¶ 将当前对象信息输出到 dict
返回: 包含当前对象信息的 dict 对象 返回类型: dict
- 当重分级类型为单值重分级时,需要通过
-
class
iobjectspy.analyst.ReclassMappingTable¶ 基类:
object栅格重分级映射表类。提供对源栅格数据集进行单值或范围的重分级,且包含对无值数据和未分级单元格的处理。
重分级映射表,用于说明源数据和结果数据值之间的对应关系。这种对应关系由这几部分内容表达:重分级类型、重分级区间集合、无值和未分级数据的处理。
重分级的类型 重分级有两种类型,单值重分级和范围重分级。单值重分级是对指定的某些单值进行重新赋值,如将源栅格中值为100的单元格,赋值为1输出到结果 栅格中;范围重分级将一个区间内的值重新赋值为一个值,如将源栅格中栅格值在[100,500)范围内的单元格,重新赋值为200输出到结果栅格中。通过该类的
set_reclass_type()方法来设置重分级类型。重分级区间集合 重分级的区间集合规定了源栅格某个栅格值或者一定区间内的栅格值与重分级后的新值的对应关系,通过该类的
set_segments()方法设置。 该集合由若干重分级区间(ReclassSegment)对象构成。该对象用于设置每个重分级区间的信息,包括要重新赋值的源栅格单值或区间的起始值、终止值,重分级区间的类型, 以及栅格重分级的区间值或源栅格单值对应的新值等,详见ReclassSegment类。无值和未分级数据的处理 对源栅格数据中的无值,可以通过该类的
set_retain_no_value()方法来设置是否保持无值,如果为 False,即不保持为无值,则可通过set_change_no_value_to()方法为无值数据指定一个值。对在重分级映射表中未涉及的栅格值,可以通过该类的
set_retain_missing_value()方法来设置是否保持其原值,如果为 False,即不保持原值,则可通过set_change_missing_valueT_to()方法为其指定一个值。
此外,该类还提供了将重分级映射表数据导出为 XML 字符串及 XML 文件的方法和导入 XML 字符串或文件的方法。当多个输入的栅格数据需要应用相同的分级范围时,可以将其导出为重分级映射表文件, 当对后续数据进行分级时,直接导入该重分级映射表文件,进而可以批量处理导入的栅格数据。有关栅格重分级映射表文件的格式和标签含义请参见 to_xml 方法。
-
change_missing_value_to¶ float -- 返回不在指定区间或单值内的栅格的指定值。
-
change_no_value_to¶ float -- 返回无值数据的指定值
-
from_dict(values)¶ 从 dict 对象中读取重分级映射表信息
参数: values (dict) -- 包含重分级映射表信息的 dict 对象 返回: self 返回类型: ReclassMappingTable
-
static
from_xml(xml)¶ 从存储在XML格式字符串中的参数值导入到映射表数据中,并返回一个新的对象。
参数: xml (str) -- XML格式字符串 返回: 栅格重分级映射表对象 返回类型: ReclassMappingTable
-
static
from_xml_file(xml_file)¶ 从已保存的XML格式的映射表文件中导入映射表数据,并返回一个新的对象。
参数: xml_file (str) -- XML文件 返回: 栅格重分级映射表对象 返回类型: ReclassMappingTable
-
is_retain_missing_value¶ bool -- 源数据集中不在指定区间或单值之外的数据是否保留原值
-
is_retain_no_value¶ bool -- 返回是否将源数据集中的无值数据保持为无值。
-
static
make_from_dict(values)¶ 从 dict 对象中读取重分级映射表信息构造新的对象
参数: values (dict) -- 包含重分级映射表信息的 dict 对象 返回: 重分级映射表对象 返回类型: ReclassMappingTable
-
reclass_type¶ ReclassType -- 返回栅格重分级类型
-
segments¶ list[ReclassSegment] -- 返回重分级区间集合。 每一个 ReclassSegment 就是一个区间范围或者是一个旧值和一个新值的对应关系。
-
set_change_missing_value_to(value)¶ 设置不在指定区间或单值内的栅格的指定值。如果
is_retain_no_value()为 True 时,则该设置无效。参数: value (float) -- 不在指定区间或单值内的栅格的指定值 返回: self 返回类型: ReclassMappingTable
-
set_change_no_value_to(value)¶ 设置无值数据的指定值。
is_retain_no_value()为 True 时,该设置无效。参数: value (float) -- 无值数据的指定值 返回: self 返回类型: ReclassMappingTable
-
set_reclass_type(value)¶ 设置栅格重分级类型
参数: value (ReclassType or str) -- 栅格重分级类型,默认值为 UNIQUE 返回: self 返回类型: ReclassMappingTable
-
set_retain_missing_value(value)¶ 设置源数据集中不在指定区间或单值之外的数据是否保留原值。
参数: value (bool) -- 源数据集中不在指定区间或单值之外的数据是否保留原值。 返回: self 返回类型: ReclassMappingTable
-
set_retain_no_value(value)¶ 设置是否将源数据集中的无值数据保持为无值。设置是否将源数据集中的无值数据保持为无值。 - 当 set_retain_no_value 方法设置为 True 时,表示保持源数据集中的无值数据为无值; - 当 set_retain_no_value 方法设置为 False 时,表示将源数据集中的无值数据设置为指定的值(
set_change_no_value_to())参数: value (bool) -- 返回: self 返回类型: ReclassMappingTable
-
set_segments(value)¶ 设置重分级区间集合
参数: value (list[ReclassSegment] or str) -- 重分级区间集合。当 value 为 str 时,支持使用 ';' 分隔多个ReclassSegment,每个 ReclassSegment使用 ','分隔 起始值、终止值、新值和分区类型。例如: '0,100,50,CLOSEOPEN; 100,200,150,CLOSEOPEN' 返回: self 返回类型: ReclassMappingTable
-
to_dict()¶ 将当前信息输出到 dict 中
返回: 包含当前信息的字典对象 返回类型: dict
-
to_xml()¶ 将当前对象信息输出为 xml 字符串
返回: xml 字符串 返回类型: str
-
to_xml_file(xml_file)¶ 该方法用于将对重分级映射表对象的参数设置写入一个 XML 文件,称为栅格重分级映射表文件,其后缀名为 .xml,下面是一个栅格重分级映射表文件的例子:
重分级映射表文件中各标签的含义如下:
- <SmXml:ReclassType></SmXml:ReclassType> 标签:重分级类型。1表示单值重分级,2表示范围重分级。
- <SmXml:SegmentCount></SmXml:SegmentCount> 标签:重分级区间集合,count 参数表示重分级的级数。
- <SmXml:Range></SmXml:Range> 标签:重分级区间,重分级类型为单值重分级,格式为:区间起始值--区间终止值:新值-区间类型。对于区间类型,0表示左开右闭,1表示左闭右开。
- <SmXml:Unique></SmXml:Unique> 标签:重分级区间,重分级类型为范围重分级,格式为:原值:新值。
- <SmXml:RetainMissingValue></SmXml:RetainMissingValue> 标签:未分级单元格是否保留原值。0表示不保留,1表示保留。
- <SmXml:RetainNoValue></SmXml:RetainNoValue> 标签:无值数据是否保持无值。0表示不保持,0表示不保持。
- <SmXml:ChangeMissingValueTo></SmXml:ChangeMissingValueTo> 标签:为未分级单元格的指定的值。
- <SmXml:ChangeNoValueTo></SmXml:ChangeNoValueTo> 标签:为无值数据的指定的值。
参数: xml_file (str) -- xml 文件路径 返回: 导出成功返回 True,否则返回 False 返回类型: bool
-
iobjectspy.analyst.reclass_grid(input_data, re_pixel_format, segments=None, reclass_type='UNIQUE', is_retain_no_value=True, change_no_value_to=None, is_retain_missing_value=False, change_missing_value_to=None, reclass_map=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格数据重分级,返回结果栅格数据集。 栅格重分级就是对源栅格数据的栅格值进行重新分类和按照新的分类标准赋值,其结果是用新的值取代了栅格数据的原栅格值。对于已知的栅格数据,有时为了便于看清趋势,找出栅格值的规律,或者为了方便进一步的分析,重分级是很必要的:
- 通过重分级,可以使用新值来替代单元格的旧值,以达到更新数据的目的。例如,在处理土地类型变更时,将已经开垦为耕地的荒地赋予新的栅格值;
- 通过重分级,可以对大量的栅格值进行分组归类,同组的单元格赋予相同的值来简化数据。例如,将旱地、水浇地、水田等都归为农业用地;
- 通过重分级,可以对多种栅格数据按照统一的标准进行分类。例如,某个建筑物的选址的影响因素包括土壤和坡度,则对输入的土壤类型和坡度的栅格数据,可以按照 1-10 的等级标准来进行重分级,便于进一步的选址分析;
- 通过重分级,可以将某些不希望参与分析的单元格设为无值,也可以为原先为无值的单元格补充新测定的值,便于进一步的分析处理。
例如,常常需要对栅格表面进行坡度分析得到坡度数据,来辅助与地形有关的分析。但我们可能需要知道坡度属于哪个等级而不是具体的坡度数值,来帮助我们了解地形的陡峭程度,从而辅助进一步的分析,如选址、分析道路铺设线路等。此时可以使用重分级,将不同的坡度划分到对应的等级中。
参数: - input_data (DatasetImage or DatasetGrid or str) -- 指定的用于栅格重采样的数据集。支持影像数据集,包括多波段影像
- re_pixel_format (ReclassPixelFormat) -- 结果数据集的栅格值的存储类型
- segments (list[ReclassSegment] or str) -- 重分级区间集合。重分级区间集合。当 segments 为 str 时,支持使用 ';' 分隔多个ReclassSegment,每个 ReclassSegment使用 ','分隔 起始值、终止值、新值和分区类型。例如: '0,100,50,CLOSEOPEN; 100,200,150,CLOSEOPEN'
- reclass_type (ReclassType or str) -- 栅格重分级类型
- is_retain_no_value (bool) -- 是否将源数据集中的无值数据保持为无值
- change_no_value_to (float) -- 无值数据的指定值。 is_retain_no_value 设置为 False 时,该设置有效,否则无效。
- is_retain_missing_value (bool) -- 源数据集中不在指定区间或单值之外的数据是否保留原值
- change_missing_value_to (float) -- 不在指定区间或单值内的栅格的指定值,is_retain_no_value 设置为 False 时,该设置有效,否则无效。
- reclass_map (ReclassMappingTable) -- 栅格重分级映射表类。如果该对象不为空,使用该对象设置的值进行栅格重分级。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or DatasetImage or str
-
iobjectspy.analyst.aggregate_grid(input_data, scale, aggregation_type, is_expanded, is_ignore_no_value, out_data=None, out_dataset_name=None, progress=None)¶ 栅格数据聚合,返回结果栅格数据集。 栅格聚合操作是以整数倍缩小栅格分辨率,生成一个新的分辨率较粗的栅格的过程。此时,每个像元由原栅格数据的一组像元聚合而成,其值由其包含的原栅格的值共 同决定,可以取包含栅格的和、最大值、最小值、平均值、中位数。如缩小n(n为大于1的整数)倍,则聚合后栅格的行、列的数目均为原栅格的1/n,也就是单元格 大小是原来的n倍。聚合可以通过对数据进行概化,达到清除不需要的信息或者删除微小错误的目的。
注意:如果原栅格数据的行列数不是 scale 的整数倍,使用 is_expanded 参数来处理零头。
- is_expanded 为 true,则在零头加上一个数,使之成为一个整数倍,扩大的范围其栅格值均为无值,因此,结果数据集的范围会比原始的大一些。
- is_expanded 为 false,去掉零头,结果数据集的范围会比原始的小一些。
参数: - input_data (DatasetGrid or str) -- 指定的进行聚合操作的栅格数据集。
- scale (int) -- 指定的结果栅格与输入栅格之间栅格大小的比例。取值为大于 1 的整型数值。
- aggregation_type (AggregationType) -- 聚合操作类型
- is_expanded (bool) -- 指定是否处理零头。当原栅格数据的行列数不是 scale 的整数倍时,栅格边界处则会出现零头。
- is_ignore_no_value (bool) -- 在聚合范围内含有无值数据时聚合操作的计算方式。如果为 True,使用聚合范围内除无值外的其余栅格值来计算;如果为 False,则聚合结果为无值。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.slice_grid(input_data, number_zones, base_output_zones, out_data=None, out_dataset_name=None, progress=None)¶ 自然分割重分级,适用于分布不均匀的数据。
Jenks自然间断法:
该重分级方法利用的是Jenks自然间断法。Jenks自然间断法基于数据中固有的自然分组,这是方差最小化分级的形式,间断通常不均匀,且间断 选择在值出现剧 烈变动的地方,所以该方法能对相似值进行恰当分组并可使各分级间差异最大化。Jenks间断点分级法会将相似值(聚类值)放置在同一类中,所以该方法适用于 分布不均匀的数据值。
参数: - input_data (DatasetGrid or str) -- 指定的进行重分级操作的栅格数据集。
- number_zones (int) -- 将栅格数据集重分级的区域数量。
- base_output_zones (int) -- 结果栅格数据集中最低区域的值
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
设置分级区域数为9,将待分级栅格数据的最小值到最大值自然分割为9份。最低区域值设为1,重分级后的值以1为起始值每级递增。
>>> slice_grid('E:/data.udb/DEM', 9, 1, 'E:/Slice_out.udb')
-
iobjectspy.analyst.compute_range_raster(input_data, count, progress=None)¶ 计算栅格像元值的自然断点中断值
参数: - input_data (DatasetGrid or str) -- 栅格数据集
- count (int) -- 自然分段的个数
- progress -- 进度信息处理函数,具体参考
StepEvent
返回: 自然分段的中断值(包括像元的最大和最小值)
返回类型: Array
-
iobjectspy.analyst.compute_range_vector(input_data, value_field, count, progress=None)¶ 计算矢量自然断点中断值
参数: - input_data (DatasetVector or str) -- 矢量数据集
- value_field (str) -- 分段的标准字段
- count (int) -- 自然分段的个数
- progress -- 进度信息处理函数,具体参考
StepEvent
返回: 自然分段的中断值(包括属性的最大和最小值)
返回类型: Array
-
class
iobjectspy.analyst.NeighbourShape¶ 基类:
object邻域形状基类。邻域按照形状可分为:矩形邻域、圆形邻域、环形邻域和扇形邻域。邻域形状的相关参数设置
-
shape_type¶ NeighbourShapeType -- 域分析的邻域形状类型
-
-
class
iobjectspy.analyst.NeighbourShapeRectangle(width, height)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.NeighbourShape矩形邻域形状类
构造矩形邻域形状类对象
参数: - width (float) -- 矩形邻域的宽
- height (float) -- 矩形邻域的高
-
height¶ float -- 矩形邻域的高
-
set_height(value)¶ 设置矩形邻域的高
参数: value (float) -- 矩形邻域的高 返回: self 返回类型: NeighbourShapeRectangle
-
set_width(value)¶ 设置矩形邻域的宽
参数: value (float) -- 矩形邻域的宽 返回: self 返回类型: NeighbourShapeRectangle
-
width¶ float -- 矩形邻域的宽
-
class
iobjectspy.analyst.NeighbourShapeCircle(radius)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.NeighbourShape圆形邻域形状类
构造圆形邻域形状类对象
参数: radius (float) -- 圆形邻域的半径 -
radius¶ float -- 圆形邻域的半径
-
set_radius(value)¶ 设置圆形邻域的半径
参数: value (float) -- 圆形邻域的半径 返回: self 返回类型: NeighbourShapeCircle
-
-
class
iobjectspy.analyst.NeighbourShapeAnnulus(inner_radius, outer_radius)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.NeighbourShape环形邻域形状类
构造环形邻域形状类对象
参数: - inner_radius (float) -- 内环半径
- outer_radius (float) -- 外环半径
-
inner_radius¶ float -- 内环半径
-
outer_radius¶ float -- 外环半径
-
set_inner_radius(value)¶ 设置内环半径
参数: value (float) -- 内环半径 返回: self 返回类型: NeighbourShapeAnnulus
-
set_outer_radius(value)¶ 设置外环半径
参数: value (float) -- 外环半径 返回: self 返回类型: NeighbourShapeAnnulus
-
class
iobjectspy.analyst.NeighbourShapeWedge(radius, start_angle, end_angle)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.NeighbourShape扇形邻域形状类
构造扇形邻域形状类对象
参数: - radius (float) -- 形邻域的半径
- start_angle (float) -- 扇形邻域的起始角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
- end_angle (float) -- 扇形邻域的终止角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
-
end_angle¶ float -- 扇形邻域的终止角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
-
radius¶ float -- 扇形邻域的半径
-
set_end_angle(value)¶ 设置扇形邻域的终止角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
参数: value (float) -- 返回: self 返回类型: NeighbourShapeWedge
-
set_radius(value)¶ 设置扇形邻域的半径
参数: value (float) -- 扇形邻域的半径 返回: self 返回类型: NeighbourShapeWedge
-
set_start_angle(value)¶ 设置扇形邻域的起始角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
参数: value (float) -- 扇形邻域的起始角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。 返回: self 返回类型: NeighbourShapeWedge
-
start_angle¶ float -- 扇形邻域的起始角度。单位为度。规定水平向右为 0 度,顺时针旋转计算角度。
-
iobjectspy.analyst.kernel_density(input_data, value_field, search_radius, resolution, bounds=None, out_data=None, out_dataset_name=None, progress=None)¶ 对点数据集或线数据集进行核密度分析,并返回分析结果。 核密度分析,即使用核函数,来计算点或线邻域范围内的每单位面积量值。其结果是中间值大周边值小的光滑曲面,在邻域边界处降为0。
参数: - input_data (DatasetVector or str) -- 需要进行核密度分析的点数据集或线数据集。
- value_field (str) -- 存储用于进行密度分析的测量值的字段名称。若传 None 则所有几何对象都按值为1处理。不支持文本类型的字段。
- search_radius (float) -- 栅格邻域内用于计算密度的查找半径。单位与用于分析的数据集的单位相同。当计算某个栅格位置的未知数值时,会以该位置 为圆心,以该属性设置的值为半径,落在这个范围内的采样对象都将参与运算,即该位置的预测值由该范围内采样对象的测量 值决定。查找半径越大,生成的密度栅格越平滑且概化程度越高。值越小,生成的栅格所显示的信息越详细。
- resolution (float) -- 密度分析结果栅格数据的分辨率
- bounds (Rectangle) -- 密度分析的范围,用于确定运行结果所得到的栅格数据集的范围
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
>>> kernel_density(data_dir + 'example_data.udb/taxi', 'passenger_count', 0.01, 0.001, out_data=out_dir + 'density_result.udb'
-
iobjectspy.analyst.point_density(input_data, value_field, resolution, neighbour_shape, neighbour_unit='CELL', bounds=None, out_data=None, out_dataset_name=None, progress=None)¶ 对点数据集进行点密度分析,并返回分析结果。 简单点密度分析,即计算每个点的指定邻域形状内的每单位面积量值。计算方法为指定测量值除以邻域面积。点的邻域叠加处,其密度值也相加。 每个输出栅格的密度均为叠加在栅格上的所有邻域密度值之和。结果栅格值的单位为原数据集单位的平方的倒数,即若原数据集单位为米,则结果栅格值的单位 为每平方米。注意对于地理坐标数据集,结果栅格值的单位为“每平方度”,是没有实际意义的。
参数: - input_data (DatasetVector or str) -- 需要进行核密度分析的点数据集或线数据集。
- value_field (str) -- 存储用于进行密度分析的测量值的字段名称。若传 None 则所有几何对象都按值为1处理。不支持文本类型的字段。
- resolution (float) -- 密度分析结果栅格数据的分辨率
- neighbour_shape (NeighbourShape or str) -- 计算密度的查找邻域形状。如果输入值为 str,则要求格式为: - 'CIRCLE,radius', 例如 'CIRCLE, 10' - 'RECTANGLE,width,height',例如 'RECTANGLE,5.0,10.0' - 'ANNULUS,inner_radius,outer_radius',例如 'ANNULUS,5.0,10.0' - 'WEDGE,radius,start_angle,end_angle',例如 'WEDGE,10.0,0,45'
- neighbour_unit (NeighbourUnitType or str) -- 邻域统计的单位类型。可以使用栅格坐标或地理坐标。
- bounds (Rectangle) -- 密度分析的范围,用于确定运行结果所得到的栅格数据集的范围
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
>>> point_density(data_dir + 'example_data.udb/taxi', 'passenger_count', 0.0001, 'CIRCLE,0.001', 'MAP', out_data=out_dir + 'density_result.udb')
-
iobjectspy.analyst.clip_raster(input_data, clip_region, is_clip_in_region=True, is_exact_clip=False, out_data=None, out_dataset_name=None, progress=None)¶ 对栅格或影像数据集进行裁剪,结果存储为一个新的栅格或影像数据集。有时,我们的研究范围或者感兴趣区域较小,仅涉及当前栅格数据 的一部分,这时可以对栅格数据进行裁剪,即通过一个 GeoRegion 对象作为裁剪区域对栅格数据进行裁剪,提取该区域内(外)的栅格数 据生成一个新的数据集,此外,还可以选择进行精确裁剪或显示裁剪。
参数: - input_data (DatasetGrid or DatasetImage or str) -- 指定的要进行裁剪的数据集,支持栅格数据集和影像数据集。
- clip_region (GeoRegion or Rectangle) -- 裁剪区域
- is_clip_in_region (bool) -- 是否对裁剪区内的数据集进行裁剪。若为 True,则对裁剪区域内的数据集进行裁剪,若为 False,则对裁剪区域外的数据集进行裁剪。
- is_exact_clip (bool) --
是否使用精确裁剪。若为 True,表示使用精确裁剪对栅格或影像数据集进行裁剪,False 表示使用显示裁剪:
- 采用显示裁剪时,系统会按照像素分块(详见 DatasetGrid.block_size_option、DatasetImage.block_size_option 方法)的大小, 对栅格或影像数据集进行裁剪。此时只有裁剪区域内的数据被保留,即如果裁剪区的边界没有恰好与单元格的边界重合,那么单元格将被分割, 位于裁剪区的部分会保留下来;位于裁剪区域外,且在被裁剪的那部分栅格所在块的总范围内的栅格仍有栅格值,但不显示。此种方式适用于大数据的裁剪。
- 采用精确裁剪时,系统在裁剪区域边界,会根据裁剪区域压盖的单元格的中心点的位置确定是否保留该单元格。如果使用区域内裁剪方式,单元格的中心点位于裁剪区内则保留,反之不保留。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源或直接生成 tif 文件
- out_dataset_name (str) -- 结果数据集名称。如果设置直接生成 tif 文件,则此参数无效。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称或第三方影像文件路径。
返回类型: DatasetGrid or DatasetImage or str
>>> clip_region = Rectangle(875.5, 861.2, 1172.6, 520.9) >>> result = clip_raster(data_dir + 'example_data.udb/seaport', clip_region, True, False, out_data=out_dir + 'clip_seaport.tif') >>> result = clip_raster(data_dir + 'example_data.udb/seaport', clip_region, True, False, out_data=out_dir + 'clip_out.udb')
-
class
iobjectspy.analyst.InterpolationDensityParameter(resolution, search_radius=0.0, expected_count=12, bounds=None)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.InterpolationParameter点密度差值(Density)插值参数类。点密度插值方法,用于表达采样点的密度分布情况。 点密度插值的结果栅格的分辨率设置需要结合点数据集范围大小来取值,一般结果栅格行列值(即结果栅格数据集范围除以分辨率)在 500 以内即可以较好的体现出密度走势。由于点密度插值暂时只支持定长搜索模式,因此搜索半径(search_radius)值设置较为重要,此值需要用户根据待插值点数据分布状况和点数据集范围进行设置。
构造点密度差值插值参数类对象
参数: - resolution (float) -- 插值运算时使用的分辨率
- search_radius (float) -- 查找参与运算点的查找半径
- expected_count (int) -- 期望参与插值运算的点数
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
-
expected_count¶ int -- 返回期望参与插值运算的点数,表示期望参与运算的最少样点数
-
search_mode¶ SearchMode -- 在插值运算时,查找参与运算点的方式,只支持定长查找(KDTREE_FIXED_RADIUS)方式
-
search_radius¶ float -- 查找参与运算点的查找半径
-
set_expected_count(value)¶ 设置期望参与插值运算的点数
参数: value (int) -- 表示期望参与运算的最少样点数 返回: self 返回类型: InterpolationDensityParameter
-
set_search_radius(value)¶ 设置查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置 的未知数值时,会以该位置为圆心,以search_radius为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
参数: value (float) -- 查找参与运算点的查找半径 返回: self 返回类型: InterpolationDensityParameter
-
class
iobjectspy.analyst.InterpolationIDWParameter(resolution, search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, power=1, bounds=None)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.InterpolationParameter距离反比权值插值(Inverse Distance Weighted)参数类,
构造 IDW 插值参数类。
参数: - resolution (float) -- 插值运算时使用的分辨率
- search_mode (SearchMode or str) -- 查找方式,不支持 QUADTREE
- search_radius (float) -- 查找参与运算点的查找半径
- expected_count (int) -- 期望参与插值运算的点数
- power (int) -- 距离权重计算的幂次,幂次值越低,内插结果越平滑,幂次值越高,内插结果细节越详细。此参数应为一个大于0的值。如果不指定此参数,方法缺省将其设置为1
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
-
expected_count¶ int -- 期望参与插值运算的点数,如果设置 search_mode 为 KDTREE_FIXED_RADIUS ,同时指定参与插值运算点的个数,当查找范围内的点数小于指定的点数时赋为空值。
-
power¶ int -- 距离权重计算的幂次
-
search_mode¶ SearchMode -- 在插值运算时,查找参与运算点的方式,不支持 QUADTREE
-
search_radius¶ float -- 查找参与运算点的查找半径
-
set_expected_count(value)¶ 设置期望参与插值运算的点数。如果设置 search_mode 为 KDTREE_FIXED_RADIUS ,同时指定参与插值运算点的个数,当查找范围内的点数小于指定的点数时赋为空值。
参数: value (int) -- 表示期望参与运算的最少样点数 返回: self 返回类型: InterpolationIDWParameter
-
set_power(value)¶ 设置距离权重计算的幂次。幂次值越低,内插结果越平滑,幂次值越高,内插结果细节越详细。此参数应为一个大于0的值。如果不指定此参数,方法缺省 将其设置为1。
参数: value (int) -- 距离权重计算的幂次 返回: self 返回类型: InterpolationIDWParameter
-
set_search_mode(value)¶ 设置在插值运算时,查找参与运算点的方式。不支持 QUADTREE
参数: value (SearchMode or str) -- 在插值运算时,查找参与运算点的方式 返回: self 返回类型: InterpolationIDWParameter
-
set_search_radius(value)¶ 设置查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置 的未知数值时,会以该位置为圆心,以search_radius为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
如果设置 search_mode 为KDTREE_FIXED_COUNT,同时指定查找参与运算点的范围,当查找范围内的点数小于指定的点数时赋为空值,当查找范围内的点数 大于指定的点数时,则返回距离插值点最近的指定个数的点进行插值。
参数: value (float) -- 查找参与运算点的查找半径 返回: self 返回类型: InterpolationIDWParameter
-
class
iobjectspy.analyst.InterpolationKrigingParameter(resolution, krighing_type=InterpolationAlgorithmType.KRIGING, search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, max_point_count_in_node=50, max_point_count_for_interpolation=200, variogram=VariogramMode.SPHERICAL, angle=0.0, mean=0.0, exponent=Exponent.EXP1, nugget=0.0, range_value=0.0, sill=0.0, bounds=None)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.InterpolationParameter克吕金(Kriging)内插法参数。
Kriging 法为地质统计学上一种空间资料内插处理方法,主要的目的是利用各数据点间变异数(variance)的大小来推求某一未知点与各已知点的权重关系,再 由各数据点的值和其与未知点的权重关系推求未知点的值。Kriging 法最大的特色不仅是提供一个最小估计误差的预测值,并且可明确的指出误差值的大小。一般 而言,许多地质参数,如地形面本身即具有连续的性质,故在一短距离内的任两点必有空间上的关系。反之,在一不规则面上的两点若相距甚远,则在统计意义上可 视为互为独立 (stastically indepedent),这种随距离而改变的空间上连续性,可用半变异图 (semivariogram) 来表现。因此,若想由已知的散乱点来 推求某一未知点的值,则可利用半变异图推求各已知点及欲求值点的空间关系。再由此空间参数推求半变异数,由各数据点间的半变异数可推求未知点与已知点间的 权重关系,进而推求出未知点的值。克吕金法的优点是以空间统计学作为其坚实的理论基础。物理含义明确;不但能估计测定参数的空间变异分布,而且还可以估算 参数的方差分布。克吕金法的缺点是计算步骤较烦琐,计算量大,且变异函数有时需要根据经验人为选定。
克吕金插值法可以采用两种方式来获取参与插值的采样点,进而获得相应位置点的预测值,一个是在待计算预测值位置点周围一定范围内,获取该范围内的所有采样 点,通过特定的插值计算公式获得该位置点的预测值;另一个是在待计算预测值位置点周围获取一定数目的采样点,通过特定的插值计算公式获得该位置点的预测值。
- 克吕金插值过程是一个多步骤的处理过程,包括:
- 创建变异图和协方差函数来估计统计相关(也称为空间自相关)的值;
- 预测待计算位置点的未知值。
- 半变异函数与半变异图:
- 计算所有采样点中相距 h 个单位的任意两点的半变异函数值,那么任意两点的距离 h 一般是唯一的,将所有的点对的距离与相应的半变函数值快速显示在以 h 为 X 坐标轴和以半变函数值为 Y 坐标轴的坐标空间内,就得到了半变异图。相距距离愈小的点其半变异数愈小,而随着距离的增加,任两点间的空间相依关系愈 小,使得半变异函数值趋向于一稳定值。此稳定值我们称之为基台值(Sill);而达到基台值时的最小 h 值称之为自相关阈值(Range)。
- 块金效应:
- 当点间距离为 0(比如,步长=0)时,半变函数值为 0。然而,在一个无限小的距离内,半变函数通常显示出块金效应,这是一个大于 0 的值。如果半变函数 在Y周上的截距式 2 ,则块金效应值为 2。
- 块金效应属于测量误差,或者是小于采样步长的小距离上的空间变化,或者两者兼而有之。测量误差主要是由于观测仪器的内在误差引起的。自然现象的空间变异 范围很大(可以在很小的尺度上,也可以在很大的尺度上)。小于步长尺度上的变化就表现为块金的一部分。
半变异图的获得是进行空间插值预测的关键步骤之一,克吕金法的主要应用之一就是预测非采样点的属性值,半变异图提供了采样点的空间自相关信息,根据半变 异图,选择合适的半变异模型,即拟合半变异图的曲线模型。
不同的模型将会影响所获得的预测结果,如果接近原点处的半变异函数曲线越陡,则较近领域对该预测值的影响就越大。因此输出表面就会越不光滑。
SuperMap 支持的半变函数模型有指数型、球型和高斯型。详细信息参见 VariogramMode 类
构造 克吕金插值参数对象。
参数: - resolution (float) -- 插值运算时使用的分辨率
- krighing_type (InterpolationAlgorithmType or str) -- 插值分析的算法类型。支持设置 KRIGING, SimpleKRIGING, UniversalKRIGING 三种,默认使用 KRIGING。
- search_mode (SearchMode or str) -- 查找模式。
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与 运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,search_radius 为半径,落在这个范围内的 采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
- expected_count (int) -- 期望参与插值运算的点数,当查找方式为变长查找时,表示期望参与运算的最多样点数。
- max_point_count_in_node (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
- max_point_count_for_interpolation (int) -- 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
- variogram (VariogramMode or str) -- 克吕金(Kriging)插值时的半变函数类型。默认值为 VariogramMode.SPHERICAL
- angle (float) -- 克吕金算法中旋转角度值
- mean (float) -- 插值字段的平均值,即采样点插值字段值总和除以采样点数目。
- exponent (Exponent or str) -- 用于插值的样点数据中趋势面方程的阶数
- nugget (float) -- 块金效应值。
- range_value (float) -- 自相关阈值。
- sill (float) -- 基台值
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
-
angle¶ float -- 克吕金算法中旋转角度值
-
expected_count¶ int -- 期望参与插值运算的点数
-
exponent¶ Exponent -- 用于插值的样点数据中趋势面方程的阶数
-
max_point_count_for_interpolation¶ int -- 块查找时,最多参与插值的点数
-
max_point_count_in_node¶ int -- 单个块内最多查找点数
-
mean¶ float -- 插值字段的平均值,即采样点插值字段值总和除以采样点数目。
-
nugget¶ float -- 块金效应值。
-
range¶ float -- 自相关阈值
-
search_mode¶ SearchMode -- 在插值运算时,查找参与运算点的方式
-
search_radius¶ float -- 查找参与运算点的查找半径
-
set_angle(value)¶ 设置克吕金算法中旋转角度值
参数: value (float) -- 克吕金算法中旋转角度值 返回: self 返回类型: InterpolationKrigingParameter
-
set_expected_count(value)¶ 设置期望参与插值运算的点数
参数: value (int) -- 表示期望参与运算的最少样点数 返回: self 返回类型: InterpolationIDWParameter
-
set_exponent(value)¶ 设置用于插值的样点数据中趋势面方程的阶数
参数: value (Exponent or str) -- 用于插值的样点数据中趋势面方程的阶数 返回: self 返回类型: InterpolationKrigingParameter
-
set_max_point_count_for_interpolation(value)¶ 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
参数: value (int) -- 块查找时,最多参与插值的点数 返回: self 返回类型: InterpolationKrigingParameter
-
set_max_point_count_in_node(value)¶ 设置单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
参数: value (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数 返回: self 返回类型: InterpolationKrigingParameter
-
set_mean(value)¶ 设置插值字段的平均值,即采样点插值字段值总和除以采样点数目。
参数: value (float) -- 插值字段的平均值,即采样点插值字段值总和除以采样点数目。 返回: self 返回类型: InterpolationKrigingParameter
-
set_nugget(value)¶ 设置块金效应值。
参数: value (float) -- 块金效应值。 返回: self 返回类型: InterpolationKrigingParameter
-
set_range(value)¶ 设置自相关阈值
参数: value (float) -- 自相关阈值 返回: self 返回类型: InterpolationKrigingParameter
-
set_search_mode(value)¶ 设置在插值运算时,查找参与运算点的方式
参数: value (SearchMode or str) -- 在插值运算时,查找参与运算点的方式 返回: self 返回类型: InterpolationIDWParameter
-
set_search_radius(value)¶ 设置查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置 的未知数值时,会以该位置为圆心,以 search_radius为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
查找模式设置为“变长查找”(KDTREE_FIXED_COUNT),将使用最大查找半径范围内的固定数目的样点值进行插值,最大查找半径为点数据集的区域范围对 应的矩形的对角线长度的 0.2 倍。
参数: value (float) -- 查找参与运算点的查找半径 返回: self 返回类型: InterpolationIDWParameter
-
set_sill(value)¶ 设置基台值
参数: value (float) -- 基台值 返回: self 返回类型: InterpolationKrigingParameter
-
set_variogram_mode(value)¶ 设置克吕金(Kriging)插值时的半变函数类型。默认值为 VariogramMode.SPHERICAL
参数: value (VariogramMode or) -- 克吕金(Kriging)插值时的半变函数类型 返回: self 返回类型: InterpolationKrigingParameter
-
sill¶ float -- 基台值
-
variogram_mode¶ VariogramMode -- 克吕金(Kriging)插值时的半变函数类型。默认值为 VariogramMode.SPHERICAL
-
class
iobjectspy.analyst.InterpolationRBFParameter(resolution, search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, max_point_count_in_node=50, max_point_count_for_interpolation=200, smooth=0.100000001490116, tension=40, bounds=None)¶ 基类:
iobjectspy._jsuperpy.analyst.sa.InterpolationParameter径向基函数 RBF(Radial Basis Function)插值法参数类
构造径向基函数插值法参数类对象。
参数: - resolution (float) -- 插值运算时使用的分辨率
- search_mode (SearchMode or str) -- 查找模式。
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与 运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,search_radius 为半径,落在这个范围内的 采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
- expected_count (int) -- 期望参与插值运算的点数,当查找方式为变长查找时,表示期望参与运算的最多样点数。
- max_point_count_in_node (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
- max_point_count_for_interpolation (int) -- 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
- smooth (float) -- 光滑系数,值域为 [0,1]
- tension (float) -- 张力系数
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
-
expected_count¶ int -- 期望参与插值运算的点数
-
max_point_count_for_interpolation¶ int -- 块查找时,最多参与插值的点数
-
max_point_count_in_node¶ int -- 单个块内最多查找点数
-
search_mode¶ SearchMode -- 在插值运算时,查找参与运算点的方式,不支持 KDTREE_FIXED_RADIUS
-
search_radius¶ float -- 查找参与运算点的查找半径
-
set_expected_count(value)¶ 设置期望参与插值运算的点数
参数: value (int) -- 表示期望参与运算的最少样点数 返回: self 返回类型: InterpolationRBFParameter
-
set_max_point_count_for_interpolation(value)¶ 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
参数: value (int) -- 块查找时,最多参与插值的点数 返回: self 返回类型: InterpolationRBFParameter
-
set_max_point_count_in_node(value)¶ 设置单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
参数: value (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数 返回: self 返回类型: InterpolationRBFParameter
-
set_search_mode(value)¶ 设置在插值运算时,查找参与运算点的方式。
参数: value (SearchMode or str) -- 在插值运算时,查找参与运算点的方式 返回: self 返回类型: InterpolationRBFParameter
-
set_search_radius(value)¶ 设置查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置 的未知数值时,会以该位置为圆心,以 search_radiu s为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
查找模式设置为“变长查找”(KDTREE_FIXED_COUNT),将使用最大查找半径范围内的固定数目的样点值进行插值,最大查找半径为点数据集的区域范围对 应的矩形的对角线长度的 0.2 倍。
参数: value (float) -- 查找参与运算点的查找半径 返回: self 返回类型: InterpolationRBFParameter
-
set_smooth(value)¶ 设置光滑系数
参数: value (float) -- 光滑系数 返回: self 返回类型: InterpolationRBFParameter
-
set_tension(value)¶ 设置张力系数
参数: value (float) -- 张力系数 返回: self 返回类型: InterpolationRBFParameter
-
smooth¶ float -- 光滑系数
-
tension¶ float -- 张力系数
-
iobjectspy.analyst.interpolate(input_data, parameter, z_value_field, pixel_format, z_value_scale=1.0, out_data=None, out_dataset_name=None, progress=None)¶ 插值分析类。该类提供插值分析功能,用于对离散的点数据进行插值得到栅格数据集。插值分析可以将有限的采样点数据,通过插值对采样点周围的数值情况进行预测, 从而掌握研究区域内数据的总体分布状况,而使采样的离散点不仅仅反映其所在位置的数值情况,而且可以反映区域的数值分布。
为什么要进行插值?
由于地理空间要素之间存在着空间关联性,即相互邻近的事物总是趋于同质,也就是具有相同或者相似的特征,举个例子,街道的一边下雨了,那么街道的另一边在大 多数情况下也一定在下雨,如果在更大的区域范围,一个乡镇的气候应当与其接壤的另一的乡镇的气候相同,等等,基于这样的推理,我们就可以利用已知地点的信息 来间接获取与其相邻的其他地点的信息,而插值分析就是基于这样的思想产生的,也是插值重要的应用价值之一。
将某个区域的采样点数据插值生成栅格数据,实际上是将研究区域按照给定的格网尺寸(分辨率)进行栅格化,栅格数据中每一个栅格单元对应一块区域,栅格单元的 值由其邻近的采样点的数值通过某种插值方法计算得到,因此,就可以预测采样点周围的数值情况,进而了解整个区域的数值分布情况。其中,插值方法主要有距离反 比权值插值法、克吕金(Kriging)内插法、径向基函数RBF(Radial Basis Function)插值。 利用插值分析功能能够预测任何地理点数据的未知值,如高程、降雨量、化学物浓度、噪声级等等。
参数: - input_data (DatasetVector or str or Recordset) -- 需要进行插值分析的点数据集或点记录集
- parameter (InterpolationParameter) -- 插值方法需要的参数信息
- z_value_field (str) -- 存储用于进行插值分析的值的字段名称。插值分析不支持文本类型的字段。
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- z_value_scale (float) -- 插值分析值的缩放比率
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.interpolate_points(points, values, parameter, pixel_format, prj, out_data, z_value_scale=1.0, out_dataset_name=None, progress=None)¶ 对点数组进行插值分析,并返回分析结果
参数: - points (list[Point2D]) -- 需要进行插值分析的点数据
- values (list[float]) -- 点数组对应的用于插值分析的值。
- parameter (InterpolationParameter) -- 插值方法需要的参数信息
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- prj (PrjCoordSys) -- 点数组的坐标系统。生成的结果数据集也参照该坐标系统。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- z_value_scale (float) -- 插值分析值的缩放比率
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
-
iobjectspy.analyst.idw_interpolate(input_data, z_value_field, pixel_format, resolution, search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, power=1, bounds=None, z_value_scale=1.0, out_data=None, out_dataset_name=None, progress=None)¶ 使用 IDW 插值方法对点数据集或记录集进行插值。具体参考
interpolate()和InterpolationIDWParameter参数: - input_data (DatasetVector or str or Recordset) -- 需要进行插值分析的点数据集或点记录集
- z_value_field (str) -- 存储用于进行插值分析的值的字段名称。插值分析不支持文本类型的字段。
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- resolution (float) -- 插值运算时使用的分辨率
- search_mode (SearchMode or str) -- 插值运算时,查找参与运算点的方式。不支持 QUADTREE
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,以search_radius为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。 如果设置 search_mode 为KDTREE_FIXED_COUNT,同时指定查找参与运算点的范围,当查找范围内的点数小于指定的点数时赋为空值,当查找范围内的点数大于指定的点数时,则返回距离插值点最近的指定个数的点进行插值。
- expected_count (int) -- 期望参与插值运算的点数。如果设置 search_mode 为 KDTREE_FIXED_RADIUS ,同时指定参与插值运算点的个数,当查找范围内的点数小于指定的点数时赋为空值。
- power (int) -- 距离权重计算的幂次。幂次值越低,内插结果越平滑,幂次值越高,内插结果细节越详细。此参数应为一个大于0的值。如果不指定此参数,方法缺省将其设置为1。
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
- z_value_scale (float) -- 插值分析值的缩放比率
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.density_interpolate(input_data, z_value_field, pixel_format, resolution, search_radius=0.0, expected_count=12, bounds=None, z_value_scale=1.0, out_data=None, out_dataset_name=None, progress=None)¶ 使用点密度插值方法对点数据集或记录集进行插值。具体参考
interpolate()和InterpolationDensityParameter参数: - input_data (DatasetVector or str or Recordset) -- 需要进行插值分析的点数据集或点记录集
- z_value_field (str) -- 存储用于进行插值分析的值的字段名称。插值分析不支持文本类型的字段。
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- resolution (float) -- 插值运算时使用的分辨率
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,以search_radius为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
- expected_count (int) -- 期望参与插值运算的点数
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
- z_value_scale (float) -- 插值分析值的缩放比率
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.kriging_interpolate(input_data, z_value_field, pixel_format, resolution, krighing_type='KRIGING', search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, max_point_count_in_node=50, max_point_count_for_interpolation=200, variogram_mode=VariogramMode.SPHERICAL, angle=0.0, mean=0.0, exponent=Exponent.EXP1, nugget=0.0, range_value=0.0, sill=0.0, bounds=None, z_value_scale=1.0, out_data=None, out_dataset_name=None, progress=None)¶ 使用克吕金插值方法对点数据集或记录集进行插值。具体参考
interpolate()和InterpolationKrigingParameter参数: - input_data (DatasetVector or str or Recordset) -- 需要进行插值分析的点数据集或点记录集
- z_value_field (str) -- 存储用于进行插值分析的值的字段名称。插值分析不支持文本类型的字段。
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- resolution (float) -- 插值运算时使用的分辨率
- krighing_type (InterpolationAlgorithmType or str) -- 插值分析的算法类型。支持设置 KRIGING, SimpleKRIGING, UniversalKRIGING 三种,默认使用 KRIGING。
- search_mode (SearchMode or str) -- 查找模式。
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与 运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,search_radius 为半径,落在这个范围内的 采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
- expected_count (int) -- 期望参与插值运算的点数,当查找方式为变长查找时,表示期望参与运算的最多样点数。
- max_point_count_in_node (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
- max_point_count_for_interpolation (int) -- 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
- variogram (VariogramMode or str) -- 克吕金(Kriging)插值时的半变函数类型。默认值为 VariogramMode.SPHERICAL
- angle (float) -- 克吕金算法中旋转角度值
- mean (float) -- 插值字段的平均值,即采样点插值字段值总和除以采样点数目。
- exponent (Exponent or str) -- 用于插值的样点数据中趋势面方程的阶数
- nugget (float) -- 块金效应值。
- range_value (float) -- 自相关阈值。
- sill (float) -- 基台值
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
- z_value_scale (float) -- 插值分析值的缩放比率
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.rbf_interpolate(input_data, z_value_field, pixel_format, resolution, search_mode=SearchMode.KDTREE_FIXED_COUNT, search_radius=0.0, expected_count=12, max_point_count_in_node=50, max_point_count_for_interpolation=200, smooth=0.100000001490116, tension=40, bounds=None, z_value_scale=1.0, out_data=None, out_dataset_name=None, progress=None)¶ 使用径向基函数(RBF) 插值方法对点数据集或记录集进行插值。具体参考
interpolate()和InterpolationRBFParameter参数: - input_data (DatasetVector or str or Recordset) -- 需要进行插值分析的点数据集或点记录集
- z_value_field (str) -- 存储用于进行插值分析的值的字段名称。插值分析不支持文本类型的字段。
- pixel_format (PixelFormat or str) -- 指定结果栅格数据集存储的像素,不支持 BIT64
- resolution (float) -- 插值运算时使用的分辨率
- search_mode (SearchMode or str) -- 查找模式。
- search_radius (float) -- 查找参与运算点的查找半径。单位与用于插值的点数据集(或记录集所属的数据集)的单位相同。查找半径决定了参与运算点的查找范围,当计算某个位置的未知数值时,会以该位置为圆心,search_radius 为半径,落在这个范围内的采样点都将参与运算,即该位置的预测值由该范围内采样点的数值决定。
- expected_count (int) -- 期望参与插值运算的点数,当查找方式为变长查找时,表示期望参与运算的最多样点数。
- max_point_count_in_node (int) -- 单个块内最多查找点数。当用QuadTree的查找插值点时,才可以设置块内最多点数。
- max_point_count_for_interpolation (int) -- 设置块查找时,最多参与插值的点数。注意,该值必须大于零。当用QuadTree的查找插值点时,才可以设置最多参与插值的点数
- smooth (float) -- 光滑系数,值域为 [0,1]
- tension (float) -- 张力系数
- bounds (Rectangle) -- 插值分析的范围,用于确定运行结果的范围
- z_value_scale (float) -- 插值分析值的缩放比率
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.vector_to_raster(input_data, value_field, clip_region=None, cell_size=None, pixel_format=PixelFormat.SINGLE, out_data=None, out_dataset_name=None, progress=None, no_value=-9999, is_all_touched=True)¶ 通过指定转换参数设置将矢量数据集转换为栅格数据集。
参数: - input_data (DatasetVector or str) -- 待转换的矢量数据集。支持点、线和面数据集
- value_field (str) -- 矢量数据集中存储栅格值的字段
- clip_region (GeoRegion or Rectangle) -- 转换的有效区域
- cell_size (float) -- 结果栅格数据集的单元格大小
- pixel_format (PixelFormat or str) -- 如果将矢量数据转为像素格式 为 UBIT1、UBIT4 和 UBIT8 的栅格数据集,矢量数据中值为 0 的对象在结果栅格中会丢失。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - no_value (float) -- 栅格数据集的无值
- is_all_touched (bool) -- 是否转换出所有与折线接触的栅格,默认为 True。如果为 False,则使用 brezenhams 栅格化方法。
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.raster_to_vector(input_data, value_field, out_dataset_type=DatasetType.POINT, back_or_no_value=-9999, back_or_no_value_tolerance=0.0, specifiedvalue=None, specifiedvalue_tolerance=0.0, valid_region=None, is_thin_raster=True, smooth_method=None, smooth_degree=0.0, out_data=None, out_dataset_name=None, progress=None)¶ 通过指定转换参数设置将栅格数据集转换为矢量数据集。
参数: - input_data (DatasetGrid or DatasetImage or str) -- 待转换的栅格数据集或影像数据集
- value_field (str) -- 结果矢量数据集中存储值的字段
- out_dataset_type (DatasetType or str) -- 结果数据集类型,支持点、线和面数据集。当结果数据集类型为线数据聚集时,is_thin_raster, smooth_method, smooth_degree 才有效。
- back_or_no_value (int or tuple) --
设置栅格的背景色或表示无值的值,只在栅格转矢量时有效。 允许用户指定一个值来标识那些不需要转换的单元格:
- 当被转换的栅格数据为栅格数据集时,栅格值为指定的值的单元格被视为无值,这些单元格不会被转换,而栅格的原无值将作为有效值来参与转换。
- 当被转化的栅格数据为影像数据集时,栅格值为指定的值的单元格被视为背景色,从而不参与转换。
需要注意,影像数据集中栅格值代表的是一个颜色或颜色的索引值,与其像素格式(PixelFormat)有关。对于 BIT32、UBIT32、RGBA、RGB 和 BIT16
格式的影像数据集,其栅格值对应为 RGB 颜色,可以使用一个 tuple 或 int 来表示 RGB 值 或 RGBA 值
对于 UBIT8 和 UBIT4 格式的影像数据集,其栅格值对应的是颜色的索引值,因此,应为该属性设置的值为被视为背景色的颜色对应的索引值。
- back_or_no_value_tolerance (int or float or tuple) --
栅格背景色的容限或无值的容限,只在栅格转矢量时有效。用于配合 back_or_no_value 方法(指定栅格无值或者背景色)来共同确定栅格数据中哪些值不被转换:
- 当被转换的栅格数据为栅格数据集时,如果指定为无值的值为 a,指定的无值的容限为 b,则栅格值在[a-b,a+b]范围内的单元格均被视为无值。需要注意,无值的容限是用户指定的无值的值的容限,与栅格中原无值无关。
- 当被转化的栅格数据为影像数据集时,该容限值为一个32位整型值或tuple,tuple用于表示 RGB值或RGBA值。
- 该值代表的意义与影像数据集的像素格式有关:对于栅格值对应 RGB 颜色的影像数据集,该值在系统内部被转为分别对应 R、G、B 的三个容限值, 例如,指定为背景色的颜色为(100,200,60),指定的容限值为329738,该值对应的 RGB 值为(10,8,5),则值在 (90,192,55) 和 (110,208,65) 之间的颜色均为背景色;对于栅格值为颜色索引值的影像数据集,该容限值为颜色索引值的容限,在该容限范围内的栅格值均视为背景色。
- specifiedvalue (int or float or tuple) -- 栅格按值转矢量时指定的栅格值。只将具有该值的栅格转为矢量。
- specifiedvalue_tolerance (int or float or tuple) -- 栅格按值转矢量时指定的栅格值的容限
- valid_region (GeoRegion or Rectangle) -- 转换的有效区域
- is_thin_raster (bool) -- 转换之前是否进行栅格细化。
- smooth_method (SmoothMethod or str) -- 光滑方法,只在栅格转为矢量线数据时有效
- smooth_degree (int) --
光滑度。光滑度的值越大,光滑度的值越大,则结果矢量线的光滑度越高。当 smooth_method 不为 NONE 时有效。光滑度的有效取值与光滑方法有关,光滑方法有 B 样条法和磨角法:
- 光滑方法为 B 样条法时,光滑度的有效取值为大于等于2的整数,建议取值范围为[2,10]。
- 光滑方法为磨角法时,光滑度代表一次光滑过程中磨角的次数,设置为大于等于1的整数时有效
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
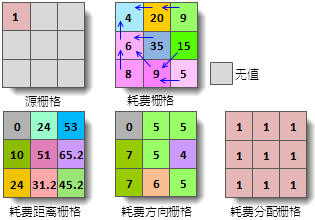
iobjectspy.analyst.cost_distance(input_data, cost_grid, max_distance=-1.0, cell_size=None, out_data=None, out_distance_grid_name=None, out_direction_grid_name=None, out_allocation_grid_name=None, progress=None)¶ 根据给定的参数,生成耗费距离栅格,以及耗费方向栅格和耗费分配栅格。
实际应用中,直线距离往往不能满足要求。例如,从 B 到最近源 A 的直线距离与从 C 到最近源 A 的直线距离相同,若 BA 路段交通拥堵,而 CA 路段交通畅 通,则其时间耗费必然不同;此外,通过直线距离对应的路径到达最近源时常常是不可行的,例如,遇到河流、高山等障碍物就需要绕行,这时就需要考虑其耗费距离。
该方法根据源数据集和耗费栅格生成相应的耗费距离栅格、耗费方向栅格(可选)和耗费分配栅格(可选)。源数据可以是矢量数据(点、线、面),也可以是栅格数据。 对于栅格数据,要求除标识源以外的单元格为无值。
耗费距离栅格的值表示该单元格到最近源的最小耗费值(可以是各种类型的耗费因子,也可以是各感兴趣的耗费因子的加权)。最近源 是当前单元格到达所有的源中耗费最小的一个源。耗费栅格中为无值的单元格在输出的耗费距离栅格中仍为无值。
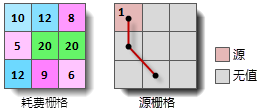
单元格到达源的耗费的计算方法是,从待计算单元格的中心出发,到达最近源的最小耗费路径在每个单元格上经过的距离乘以耗费栅格 上对应单元格的值,将这些值累加即为单元格到源的耗费值。因此,耗费距离的计算与单元格大小和耗费栅格有关。在下面的示意图中, 源栅格和耗费栅格的单元格大小(cell_size)均为2,单元格(2,1)到达源(0,0)的最小耗费路线如右图中红线所示:
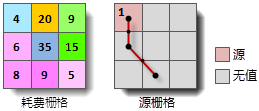
那么单元格(2,1)到达源的最小耗费(即耗费距离)为:
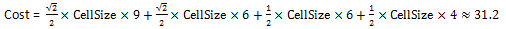
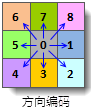
耗费方向栅格的值表达的是从该单元格到达最近的源的最小耗费路径的行进方向。在耗费方向栅格中,可能的行进方向共有八个(正北、 正南、正西、正东、西北、西南、东南、东北),使用1到8八个整数对这八个方向进行编码,如下图所示。注意,源所在的单元格在耗费 方向栅格中的值为0,耗费栅格中为无值的单元格在输出的耗费方向栅格中将被赋值为15。
耗费分配栅格的值为单元格的最近源的值(源为栅格时,为最近源的栅格值;源为矢量对象时,为最近源的 SMID),单元格到达最近的 源具有最小耗费距离。耗费栅格中为无值的单元格在输出的耗费分配栅格中仍为无值。
下图为生成耗费距离的示意图。其中,在耗费栅格上,使用蓝色箭头标识了单元格到达最近源的行进路线,耗费方向栅格的值即标示了 当前单元格到达最近源的最小耗费路线的行进方向。
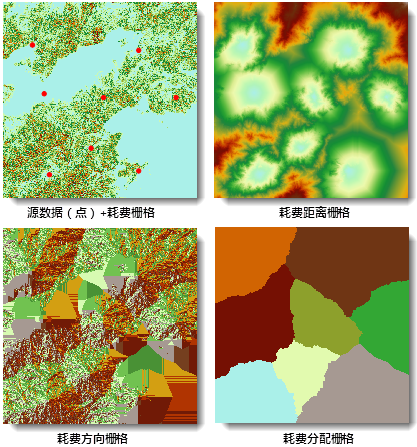
下图为生成耗费距离栅格的一个实例,其中源数据集为点数据集,耗费栅格为对应区域的坡度栅格的重分级结果,生成了耗费距离栅格、耗费方向栅格和耗费分配栅格。
参数: - input_data (DatasetVector or DatasetGrid or str) -- 生成距离栅格的源数据集。源是指感兴趣的研究对象或地物,如学校、道路或消防栓等。包含源的数据集,即为源数据集。源数据集可以为 点、线、面数据集,也可以为栅格数据集,栅格数据集中具有有效值的栅格为源,对于无值则视为该位置没有源。
- cost_grid (DatasetGrid) -- 耗费栅格。其栅格值不能为负值。该数据集为一个栅格数据集,每个单元格的值表示经过此单元格时的单位耗费。
- max_distance (float) -- 生成距离栅格的最大距离,大于该距离的栅格其计算结果取无值。若某个栅格单元格 A 到最近源之间的最短距离大于该值,则结果数据集中该栅格的值取无值。
- cell_size (float) -- 结果数据集的分辨率,是生成距离栅格的可选参数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_distance_grid_name (str) -- 结果距离栅格数据集的名称。如果名称为空,将自动获取有效的数据集名称。
- out_direction_grid_name (str) -- 方向栅格数据集的名称,如果为空,将不生成方向栅格数据集
- out_allocation_grid_name (str) -- 分配栅格数据集的名称,如果为空,将不生成 分配栅格数据集
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 如果生成成功,返回结果数据集或数据集名称的元组,其中第一个为距离栅格数据集,第二个为方向栅格数据集,第三个为分配栅格数据集,如果没有设置方向栅格数据集名称和 分配栅格数据集名称,对应的值为 None
返回类型: tuple[DataetGrid] or tuple[str]
-
iobjectspy.analyst.cost_path(input_data, distance_dataset, direction_dataset, compute_type, out_data=None, out_dataset_name=None, progress=None)¶ 根据耗费距离栅格和耗费方向栅格,分析从目标出发到达最近源的最短路径栅格。 该方法根据给定的目标数据集,以及通过“生成耗费距离栅格”功能得到的耗费距离栅格和耗费方向栅格,来计算每个目标对象到达最近的源的最短路径,也就是最小 耗费路径。该方法不需要指定源所在的数据集,因为源的位置在距离栅格和方向栅格中能够体现出来,即栅格值为 0 的单元格。生成的最短路径栅格是一个二值栅 格,值为 1 的单元格表示路径,其他单元格的值为 0。
例如,将购物商场(一个点数据集)作为源,各居民小区(一个面数据集)作为目标,分析从各居民小区出发,如何到达距其最近的购物商场。实现的过程是,首先 针对源(购物商场)生成距离栅格和方向栅格,然后将居民小区作为目标区域,通过最短路径分析,得到各居民小区(目标)到最近购物商场(源)的最短路径。该 最短路径包含两种含义:通过直线距离栅格与直线方向栅格,将得到最小直线距离路径;通过耗费距离栅格与耗费方向栅格,则得到最小耗费路径。
注意,该方法中要求输入的耗费距离栅格和耗费方向栅格必须是匹配的,也就是说二者应是同一次使用“生成耗费距离栅格”功能生成的。此外,有三种计算最短路径 的方式:像元路径、区域路径和单一路径,具体含义请参见
ComputeType类。参数: - input_data (DatasetVector or DatasetGrid or DatasetImage or str) -- 目标所在的数据集。可以为点、线、面或栅格数据集。如果是栅格数据,要求除标识目标以外的单元格为无值。
- distance_dataset (DatasetGrid or str) -- 耗费距离栅格数据集。
- direction_dataset (DatasetGrid or str) -- 耗费方向栅格数据集
- compute_type (ComputeType or str) -- 栅格距离最短路径分析的计算方式
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
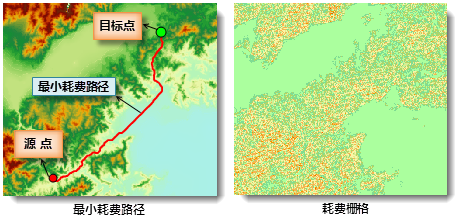
iobjectspy.analyst.cost_path_line(source_point, target_point, cost_grid, smooth_method=None, smooth_degree=0, progress=None, barrier_regions=None)¶ 根据给定的参数,计算源点和目标点之间的最小耗费路径(一个二维矢量线对象)。该方法用于根据给定的源点、目标点和耗费栅格,计算源点与目标点之间的最小耗费路径
下图为计算两点间最小耗费路径的实例。该例以 DEM 栅格的坡度的重分级结果作为耗费栅格,分析给定的源点和目标点之间的最小耗费路径。
参数: - source_point (Point2D) -- 指定的源点
- target_point (Point2D) -- 指定的目标点
- cost_grid (DatasetGrid) -- 耗费栅格。其栅格值不能为负值。该数据集为一个栅格数据集,每个单元格的值表示经过此单元格时的单位耗费。
- smooth_method (SmoothMethod or str) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的方法
- smooth_degree (int) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的光滑度。 光滑度的值越大,光滑度的值越大,则结果矢量线的光滑度越高。当 smooth_method 不为 NONE 时有效。光滑度的有效取值与光滑方法有关,光滑方法有 B 样条法和磨角法: - 光滑方法为 B 样条法时,光滑度的有效取值为大于等于2的整数,建议取值范围为[2,10]。 - 光滑方法为磨角法时,光滑度代表一次光滑过程中磨角的次数,设置为大于等于1的整数时有效
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - barrier_regions (DatasetVector or str or GeoRegion or list[GeoRegion]) -- 障碍面数据集或面对象,分析时将绕过障碍面。
返回: 返回表示最短路径的线对象和最短路径的花费
返回类型: tuple[GeoLine,float]
-
iobjectspy.analyst.path_line(target_point, distance_dataset, direction_dataset, smooth_method=None, smooth_degree=0)¶ 根据距离栅格和方向栅格,分析从目标点出发到达最近源的最短路径(一个二维矢量线对象)。 该方法根据距离栅格和方向栅格,分析给定的目标点到达最近源的最短路径。其中距离栅格和方向栅格可以是耗费距离栅格和耗费方向栅格,也可以是表面距离栅格和表面方向栅格。
- 当距离栅格为耗费距离栅格,方向栅格为耗费方向栅格时,该方法计算得出的是最小耗费路径。耗费距离栅格和耗费方向栅格可以通过 costDistance 方法生成。注意,此方法要求二者是同一次生成的结果。
- 当距离栅格为表面距离栅格,方向栅格为表面方向栅格时,该方法计算得出的是最短表面距离路径。表面距离栅格和表面方向栅格可以通过 surfaceDistance 方法生成。同样,此方法要求二者是同一次生成的结果。
源的位置在距离栅格和方向栅格中能够体现出来,即栅格值为 0 的单元格。源可以是一个,也可以有多个。当有多个源时,最短路径是目标点到达其最近的源的路径。
下图为源、表面栅格、耗费栅格和目标点,其中耗费栅格是对表面栅格计算坡度后重分级的结果。
使用如上图所示的源和表面栅格生成表面距离栅格和表面方向栅格,然后计算目标点到最近源的最短表面距离路径;使用源和耗费栅格生成耗费距离栅格和耗费方向栅格,然后计算目标点到最近源的最小耗费路径。得到的结果路径如下图所示:

参数: - target_point (Point2D) -- 指定的目标点。
- distance_dataset (DatasetGrid) -- 指定的距离栅格。可以是耗费距离栅格或表面距离栅格。
- direction_dataset (DatasetGrid) -- 指定的方向栅格。与距离栅格对应,可以是耗费方向栅格或表面方向栅格。
- smooth_method (SmoothMethod or str) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的方法
- smooth_degree (int) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的光滑度。 光滑度的值越大,光滑度的值越大,则结果矢量线的光滑度越高。当 smooth_method 不为 NONE 时有效。光滑度的有效取值与光滑方法有关,光滑方法有 B 样条法和磨角法: - 光滑方法为 B 样条法时,光滑度的有效取值为大于等于2的整数,建议取值范围为[2,10]。 - 光滑方法为磨角法时,光滑度代表一次光滑过程中磨角的次数,设置为大于等于1的整数时有效
返回: 返回表示最短路径的线对象和最短路径的花费
返回类型: tuple[GeoLine,float]
-
iobjectspy.analyst.straight_distance(input_data, max_distance=-1.0, cell_size=None, out_data=None, out_distance_grid_name=None, out_direction_grid_name=None, out_allocation_grid_name=None, progress=None)¶ 根据给定的参数,生成直线距离栅格,以及直线方向栅格和直线分配栅格。
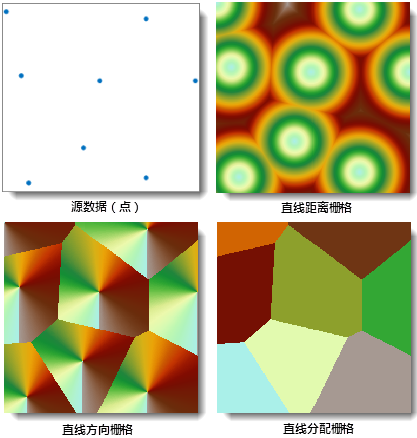
该方法用于对源数据集生成相应的直线距离栅格、直线方向栅格(可选)和直线分配栅格(可选),三个结果数据集的区域范围与源数据集的范围一致。生成直线距 离栅格的源数据可以是矢量数据(点、线、面),也可以是栅格数据。对于栅格数据,要求除标识源以外的单元格为无值。
直线距离栅格的值代表该单元格到最近的源的欧氏距离(即直线距离)。最近源是当前单元格到达所有源中直线距离最短的一个源。对于每个 单元格,它的中心与源的中心相连的直线即为单元格到源的距离,计算的方法是通过二者形成的直角三角形的两条直角边来计算,因此直线 距离的计算只与单元格大小(即分辨率)有关。下图为直线距离计算的示意图,其中源栅格的单元格大小(cell_size)为10。
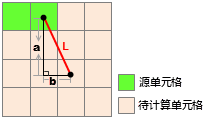
那么第三行第三列的单元格到源的距离L为:
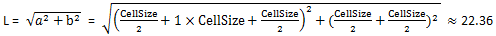
直线方向栅格的值表示该单元格到最近的源的方位角,单位为度。以正东方向为90度,正南为180度,正西为270度,正北为360度,顺时针方向旋转,范围为0-360度,并规定对应源的栅格值为0度。
直线分配栅格的值为单元格的最近源的值(源为栅格时,为最近源的栅格值;源为矢量对象时,为最近源的 SMID),因此从直线分配栅格中可以得知每个单元格的最近的源是哪个。
下图为生成直线距离的示意图。单元格大小均为2。
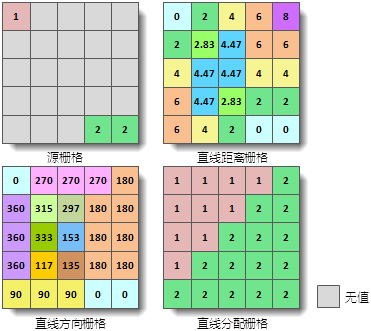
直线距离栅格通常用于分析经过的路线没有障碍或等同耗费的情况,例如,救援飞机飞往最近的医院时,空中没有障碍物,因此采用哪条路线的耗费均相同,此时通过直线距离栅格就可以确定从救援飞机所在地点到周围各医院的距离;根据直线分配栅格可以获知离救援飞机所在地点最近的医院;由直线方向栅格可以确定最近的医院在救援飞机所在地点的方位。
然而,在救援汽车开往最近医院的实例中,因为地表有各种类型的障碍物,采用不同的路线的耗费不尽相同,这时,就需要使用耗费距离栅格来进行分析。有关耗费距离栅格请参见 CostDistance 方法。
下图为生成直线距离栅格的一个实例,其中源数据集为点数据集,生成了直线距离栅格、直线方向栅格和直线分配栅格。
注意:当数据集的最小外接矩形(bounds)为某些特殊情形时,结果数据集的 Bounds 按以下规则取值:
- 当源数据集的 Bounds 的高和宽均为 0 (如只有一个矢量点)时,结果数据集的 Bounds 的高和宽,均取源数据集 Bounds 的左边界值(Left)和下边界值(Right)二者绝对值较小的一个。
- 当源数据集的 Bounds 的高为 0 而宽不为 0 (如只有一条水平线)时,结果数据集的 Bounds 的高和宽,均等于源数据集 Bounds 的宽。
- 当源数据集的 Bounds 的宽为 0 而高不为 0 (如只有一条竖直线)时,结果数据集的 Bounds 的高和宽,均等于源数据集 Bounds 的高。
参数: - input_data (DatasetVector or DatasetGrid or DatasetImage or str) -- 生成距离栅格的源数据集。源是指感兴趣的研究对象或地物,如学校、道路或消防栓等。包含源的数据集,即为源数据集。源数据集可以为 点、线、面数据集,也可以为栅格数据集,栅格数据集中具有有效值的栅格为源,对于无值则视为该位置没有源。
- max_distance (float) -- 生成距离栅格的最大距离,大于该距离的栅格其计算结果取无值。若某个栅格单元格 A 到最近源之间的最短距离大于该值,则结果数据集中该栅格的值取无值。
- cell_size (float) -- 结果数据集的分辨率,是生成距离栅格的可选参数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_distance_grid_name (str) -- 结果距离栅格数据集的名称。如果名称为空,将自动获取有效的数据集名称。
- out_direction_grid_name (str) -- 方向栅格数据集的名称,如果为空,将不生成方向栅格数据集
- out_allocation_grid_name (str) -- 分配栅格数据集的名称,如果为空,将不生成 分配栅格数据集
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 如果生成成功,返回结果数据集或数据集名称的元组,其中第一个为距离栅格数据集,第二个为方向栅格数据集,第三个为分配栅格数据集,如果没有设置方向栅格数据集名称和 分配栅格数据集名称,对应的值为 None
返回类型: tuple[DataetGrid] or tuple[str]
-
iobjectspy.analyst.surface_distance(input_data, surface_grid_dataset, max_distance=-1.0, cell_size=None, max_upslope_degrees=90.0, max_downslope_degree=90.0, out_data=None, out_distance_grid_name=None, out_direction_grid_name=None, out_allocation_grid_name=None, progress=None)¶ 根据给定的参数,生成表面距离栅格,以及表面方向栅格和表面分配栅格。 该方法根据源数据集和表面栅格生成相应的表面距离栅格、表面方向栅格(可选)和表面 分配栅格(可选)。源数据可以是矢量数据(点、线、面),也可以是栅格数据。对于栅格数据,要求除标识源以外的单元格为无值。
表面距离栅格的值表示表面栅格上该单元格到最近源的表面最短距离。最近源是指当前单元格到达所有的源中表面距离最短的一个源。表面栅格中为无值的单元格在输出的表面距离栅格中仍为无值。 从当前单元格(设为 g1)到达下一个单元格(设为 g2)的表面距离 d 的计算方法为:
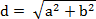
其中,b 为 g1 的栅格值(即高程)与 g2 的栅格值的差;a 为 g1 与 g2 的中心点之间的直线距离,其值考虑两种情况,当 g2 是与 g1 相邻的上、下、左、右四个单元格之一时,a 的值等于单元格大小;当 g2 是与 g1 对角相邻的四个单元格之一时,a 的值为单元格大小乘以根号 2。
当前单元格到达最近源的距离值就是沿着最短路径的表面距离值。在下面的示意图中,源栅格和表面栅格的单元格大小(CellSize)均为 1,单元格(2,1)到达源(0,0)的表面最短路径如右图中红线所示:
那么单元格(2,1)到达源的最短表面距离为:
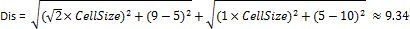
表面方向栅格的值表达的是从该单元格到达最近源的最短表面距离路径的行进方向。在表面方向栅格中,可能的行进方向共有八个(正北、 正南、正西、正东、西北、西南、东南、东北),使用 1 到 8 八个整数对这八个方向进行编码,如下图所示。注意,源所在的单元格在表面方向栅格中的值为 0,表面栅格中为无值的单元格在输出的表面方向栅格中将被赋值为 15。
表面分配栅格的值为单元格的最近源的值(源为栅格时,为最近源的栅格值;源为矢量对象时,为最近源的 SMID),单元格到达最近的源具有最短表面距离。表面栅格中为无值的单元格在输出的表面分配栅格中仍为无值。 下图为生成表面距离的示意图。其中,在表面栅格上,根据结果表面方向栅格,使用蓝色箭头标识了单元格到达最近源的行进方向。
SurfaceDistance_4.png
通过上面的介绍,可以了解到,结合表面距离栅格及对应的方向、分配栅格,可以知道表面栅格上每个单元格最近的源是哪个,表面距离是多少以及如何到达该最近源。
注意,生成表面距离时可以指定最大上坡角度(max_upslope_degrees)和最大下坡角度(max_downslope_degree),从而在寻找最近源时 避免经过上下坡角度超过指定值的单元格。从当前单元格行进到下一个高程更高的单元格为上坡,上坡角度即上坡方向与水平面的夹角,如果 上坡角度大于给定值,则不会考虑此行进方向;从当前单元格行进到下一个高程小于当前高程的单元格为下坡,下坡角度即下坡方向与水平面 的夹角,同样的,如果下坡角度大于给定值,则不会考虑此行进方向。如果由于上下坡角度限制,使得当前单元格没能找到最近源,那么在 表面距离栅格中该单元格的值为无值,在方向栅格和分配栅格中也为无值。
下图为生成表面距离栅格的一个实例,其中源数据集为点数据集,表面栅格为对应区域的 DEM 栅格,生成了表面距离栅格、表面方向栅格和表面分配栅格。

参数: - input_data (DatasetVector or DatasetGrid or DatasetImage or str) -- 生成距离栅格的源数据集。源是指感兴趣的研究对象或地物,如学校、道路或消防栓等。包含源的数据集,即为源数据集。源数据集可以为 点、线、面数据集,也可以为栅格数据集,栅格数据集中具有有效值的栅格为源,对于无值则视为该位置没有源。
- surface_grid_dataset (DatasetGrid or str) -- 表面栅格
- max_distance (float) -- 生成距离栅格的最大距离,大于该距离的栅格其计算结果取无值。若某个栅格单元格 A 到最近源之间的最短距离大于该值,则结果数据集中该栅格的值取无值。
- cell_size (float) -- 结果数据集的分辨率,是生成距离栅格的可选参数
- max_upslope_degrees (float) -- 最大上坡角度。单位为度,取值范围为大于或等于0。默认值为 90 度,即不考虑上坡角度。 如果指定了最大上坡角度,则选择路线的时候会考虑地形的上坡的角度。从当前单元格行进到下一个高程更高的单元格 为上坡,上坡角度即上坡方向与水平面的夹角。如果上坡角度大于给定值,则不会考虑此行进方向,即给出的路线不会 经过上坡角度大于该值的区域。可想而知,可能会因为该值的设置而导致没有符合条件的路线。此外,由于坡度的表示 范围为0到90度,因此,虽然可以指定为一个大于90度的值,但产生的效果与指定为90度相同,即不考虑上坡角度。
- max_downslope_degree (float) -- 设置最大下坡角度。单位为度,取值范围为大于或等于0。 如果指定了最大下坡角度,则选择路线的时候会考虑地形的下坡的角度。从当前单元格行进到下一个高程小于当前高 程的单元格为下坡,下坡角度即下坡方向与水平面的夹角。如果下坡角度大于给定值,则不会考虑此行进方向,即给 出的路线不会经过下坡角度大于该值的区域。可想而知,可能会因为该值的设置而导致没有符合条件的路线。此外, 由于坡度的表示范围为0到90度,因此,虽然可以指定为一个大于90度的值,但产生的效果与指定为90度相同,即不 考虑下坡角度。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_distance_grid_name (str) -- 结果距离栅格数据集的名称。如果名称为空,将自动获取有效的数据集名称。
- out_direction_grid_name (str) -- 方向栅格数据集的名称,如果为空,将不生成方向栅格数据集
- out_allocation_grid_name (str) -- 分配栅格数据集的名称,如果为空,将不生成 分配栅格数据集
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 如果生成成功,返回结果数据集或数据集名称的元组,其中第一个为距离栅格数据集,第二个为方向栅格数据集,第三个为分配栅格数据集,如果没有设置方向栅格数据集名称和 分配栅格数据集名称,对应的值为 None
返回类型: tuple[DataetGrid] or tuple[str]
-
iobjectspy.analyst.surface_path_line(source_point, target_point, surface_grid_dataset, max_upslope_degrees=90.0, max_downslope_degree=90.0, smooth_method=None, smooth_degree=0, progress=None, barrier_regions=None)¶ 根据给定的参数,计算源点和目标点之间的最短表面距离路径(一个二维矢量线对象)。该方法用于根据给定的源点、目标点和表面栅格,计算源点与目标点之间的最短表面距离路径。
设置最大上坡角度(max_upslope_degrees)和最大下坡角度(max_downslope_degree)可以使分析得出的路线不经过过于陡峭的地形。 但注意,如果指定了上下坡角度限制,也可能得不到分析结果,这与最大上下坡角度的值和表面栅格所表达的地形有关。下图展示了将最 大上坡角度和最大下坡角度分别均设置为 5 度、10 度和 90 度(即不限制上下坡角度)时的表面距离最短路径,由于对上下坡角度做出 了限制,因此表面距离最短路径是以不超过最大上下坡角度为前提而得出的。
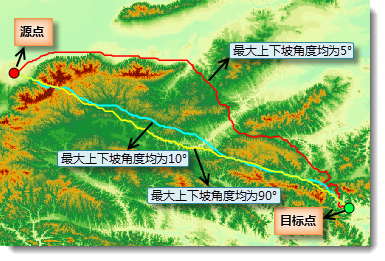
参数: - source_point (Point2D) -- 指定的源点。
- target_point (Point2D) -- 指定的目标点。
- surface_grid_dataset (DatasetGrid or str) -- 表面栅格
- max_upslope_degrees (float) -- 最大上坡角度。单位为度,取值范围为大于或等于0。默认值为 90 度,即不考虑上坡角度。 如果指定了最大上坡角度,则选择路线的时候会考虑地形的上坡的角度。从当前单元格行进到下一个高程更高的单元格 为上坡,上坡角度即上坡方向与水平面的夹角。如果上坡角度大于给定值,则不会考虑此行进方向,即给出的路线不会 经过上坡角度大于该值的区域。可想而知,可能会因为该值的设置而导致没有符合条件的路线。此外,由于坡度的表示 范围为0到90度,因此,虽然可以指定为一个大于90度的值,但产生的效果与指定为90度相同,即不考虑上坡角度。
- max_downslope_degree (float) -- 设置最大下坡角度。单位为度,取值范围为大于或等于0。 如果指定了最大下坡角度,则选择路线的时候会考虑地形的下坡的角度。从当前单元格行进到下一个高程小于当前高 程的单元格为下坡,下坡角度即下坡方向与水平面的夹角。如果下坡角度大于给定值,则不会考虑此行进方向,即给 出的路线不会经过下坡角度大于该值的区域。可想而知,可能会因为该值的设置而导致没有符合条件的路线。此外, 由于坡度的表示范围为0到90度,因此,虽然可以指定为一个大于90度的值,但产生的效果与指定为90度相同,即不 考虑下坡角度。
- smooth_method (SmoothMethod or str) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的方法
- smooth_degree (int) -- 计算两点(源和目标)间最短路径时对结果路线进行光滑的光滑度。 光滑度的值越大,光滑度的值越大,则结果矢量线的光滑度越高。当 smooth_method 不为 NONE 时有效。光滑度的有效取值与光滑方法有关,光滑方法有 B 样条法和磨角法: - 光滑方法为 B 样条法时,光滑度的有效取值为大于等于2的整数,建议取值范围为[2,10]。 - 光滑方法为磨角法时,光滑度代表一次光滑过程中磨角的次数,设置为大于等于1的整数时有效
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - barrier_regions (DatasetVector or GeoRegion or list[GeoRegion]) -- 障碍面,分析时将绕过障碍面。
返回: 返回表示最短路径的线对象和最短路径的花费
返回类型: tuple[GeoLine,float]
-
iobjectspy.analyst.calculate_hill_shade(input_data, shadow_mode, azimuth, altitude_angle, z_factor, out_data=None, out_dataset_name=None, progress=None)¶ 三维晕渲图是指通过模拟实际地表的本影与落影的方式反映地形起伏状况的栅格图。通过采用假想的光源照射地表,结合栅格数据得到的坡度坡向信息, 得到各像元 的灰度值,面向光源的斜坡的灰度值较高,背向光源的灰度值较低,即为阴影区,从而形象表现出实际地表的地貌和地势。 由栅格数据计算得出的这种山体阴影图 往往具有非常逼真的立体效果,因而称其为三维晕渲图。
三维晕渲图在描述地表三维状况和地形分析中都具有比较重要的价值,当将其他专题信息叠加在三维晕渲图之上时,将会更加提高三维晕渲图的应用价值和直观效果。
在生成三维晕渲图时,需要指定假想光源的位置,该位置由光源的方位角和高度角确定。方位角确定光源的方向,高度角是光源照射时倾斜角度。例如,当光源的方位角 为 315 度,高度角为 45 度时,其与地表的相对位置如下图所示。
三维晕渲图有三种类型:渲染阴影效果、渲染效果和阴影效果,通过
ShadowMode类来指定。>>> ds = open_datasource('/home/data/example_data.udbx') >>> calculate_hill_shade(ds['DEM'], ShadowMode.IllUMINATION, 315, 45, 0.001)
参数: - input_data (DatasetGrid or str) -- 指定的待生成三维晕渲图的栅格数据集
- shadow_mode (ShadowMode or str) -- 三维晕渲图的渲染类型
- azimuth (float) --
指定的光源方位角。用于确定光源的方向,是从光源所在位置的正北方向线起,依顺时针方向到光源与目标方向线 的夹角,范围为 0-360 度,以正北方向为 0 度,依顺时针方向递增。
- altitude_angle (float) --
指定的光源高度角。用于确定光源照射的倾斜角度,是光源与目标的方向线与水平面间的夹角,范围为 0-90 度。当光源高度角为 90 度时,光源正射地表。
- z_factor (float) -- 指定的高程缩放系数。该值是指在栅格中,栅格值(Z 坐标,即高程值)相对于 X 和 Y 坐标的单位变换系数。通常有 X,Y,Z 都参加的计算中,需要将高程值乘以一个高程缩放系数,使得三者单位一致。例如,X、Y 方向上的单位是米,而 Z 方向的单位是英尺,由于 1 英尺等于 0.3048 米,则需要指定缩放系数为 0.3048。如果设置为 1.0,表示不缩放。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.calculate_slope(input_data, slope_type, z_factor, out_data=None, out_dataset_name=None, progress=None)¶ 计算坡度,并返回坡度栅格数据集,即坡度图。 坡度是地表面上某一点的切面和水平面所成的夹角。坡度值越大,表示地势越陡峭
- 注意:
- 计算坡度时,要求待计算的栅格值(即高程)的单位与 x,y 坐标的单位相同。如果不一致,可通过高程缩放系数(方法中对应 zFactor 参数)来调整。 但注意,当高程值单位与坐标单位间的换算无法通过固定值来调节时,则需要通过其他途径对数据进行处理。最常见的情况之一是 DEM 栅格采用地理坐标系时, 单位为度,而高程值单位为米,此时建议对 DEM 栅格进行投影转换,将 x,y 坐标转换为平面坐标。
参数: - input_data (DatasetGrid or str) -- 指定的的待计算坡度的栅格数据集
- slope_type (SlopeType or str) -- 坡度的单位类型
- z_factor (float) -- 指定的高程缩放系数。该值是指在栅格中,栅格值(Z 坐标,即高程值)相对于 X 和 Y 坐标的单位变换系数。通常有 X,Y,Z 都参加的计算中,需要将高程值乘以一个高程缩放系数,使得三者单位一致。例如,X、Y 方向上的单位是米,而 Z 方向的单位是 英尺,由于 1 英尺等于 0.3048 米,则需要指定缩放系数为 0.3048。如果设置为 1.0,表示不缩放。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.calculate_aspect(input_data, out_data=None, out_dataset_name=None, progress=None)¶ 计算坡向,并返回坡向栅格数据集,即坡向图。 坡向是指坡面的朝向,它表示地形表面某处最陡的下坡方向。坡向反映了斜坡所面对的方向,任意斜坡的倾斜方向可取 0~360 度中的任意方向,所以坡向计算的 结果范围为 0~360 度。从正北方向(0 度)开始顺时针计算
参数: - input_data (DatasetGrid or str) -- 指定的待计算坡向的栅格数据集
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.compute_point_aspect(input_data, specified_point)¶ 计算 DEM 栅格上指定点处的坡向。 DEM 栅格上指定点处的坡向,与坡向图(calculate_aspect 方法)的计算方法相同,是将该点所在单元格与其周围的相 邻的八个单元格所形成的 3 × 3 平面作为计算单元,通过三阶反距离平方权差分法计算水平高程变化率和垂直高程变化率从而得出坡向。更多介绍,请参阅
calculate_aspect()方法。- 注意:
- 当指定点所在的单元格为无值时,计算结果为 -1,这与生成坡向图不同;当指定的点位于 DEM 栅格的数据集范围之外时,计算结果为 -1。
参数: - input_data (DatasetGrid or str) -- 指定的待计算坡向的栅格数据集
- specified_point (Point2D) -- 指定的地理坐标点。
返回: 指定点处的坡向。单位为度。
返回类型: float
-
iobjectspy.analyst.compute_point_slope(input_data, specified_point, slope_type, z_factor)¶ 计算 DEM 栅格上指定点处的坡度。 DEM 栅格上指定点处的坡度,与坡度图(calculate_slope 方法)的计算方法相同,是将该点所在单元格与其周围的相邻的八个单元格所形成的 3 × 3 平面作 为计算单元,通过三阶反距离平方权差分法计算水平高程变化率和垂直高程变化率从而得出坡度。更多介绍,请参阅 calculate_slope 方法。
- 注意:
- 当指定点所在的单元格为无值时,计算结果为 -1,这与生成坡度图不同;当指定的点位于 DEM 栅格的数据集范围之外时,计算结果为 -1。
参数: - input_data (DatasetGrid or str) -- 指定的待计算坡向的栅格数据集
- specified_point (Point2D) -- 指定的地理坐标点。
- slope_type (SlopeType or str) -- 指定的坡度单位类型。可以用角度、弧度或百分数来表示。以使用角度为例,坡度计算的结果范围为 0~90 度。
- z_factor (float) -- 指定的高程缩放系数。该值是指在 DEM 栅格中,栅格值(Z 坐标,即高程值)相对于 X 和 Y 坐标的单位变换系数。通常有 X,Y,Z 都参加的计算中,需要将高程值乘以一个高程缩放系数,使得三者单位一致。例如,X、Y 方向上的单位是米,而 Z 方向的单位是英尺,由于 1 英尺等于 0.3048 米,则需要指定缩放系数为 0.3048。如果设置为 1.0,表示不缩放。
返回: 指定点处的坡度。单位为 type 参数指定的类型。
返回类型: float
-
iobjectspy.analyst.calculate_ortho_image(input_data, colors, no_value_color, out_data=None, out_dataset_name=None, progress=None)¶ 根据给定的颜色集合生成正射三维影像。
正射影像是采用数字微分纠正技术,通过周边邻近栅格的高程得到当前点的合理日照强度,进行正射影像纠正。
>>> colors = Colors.make_gradient(32, ColorGradientType.YELLOWGREEN) >>> calculate_ortho_image(ds['DEM'], colors, 'white')
参数: - input_data (DatasetGrid or str) -- 指定的待计算三维正射影像的 DEM 栅格。
- colors (Colors or dict[float,tuple]) -- 三维投影后的颜色集合。输入如果为 dict,则表示高程值与颜色值的对应关系。 可以不必在高程颜色对照表中列出待计算栅格的所有栅格值(高程值)及其对应颜色,未在高程颜色对照表中列出的高程值,其在结果影像中的颜色将通过插值得出。
- no_value_color (tuple or int) -- 无值栅格的颜色
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.compute_surface_area(input_data, region)¶ 计算表面面积,即计算所选多边形区域内的 DEM 栅格拟合的三维曲面的总的表面面积。
参数: - input_data (DatasetGrid or str) -- 指定的待计算表面面积的 DEM 栅格。
- region (GeoRegion) -- 指定的用于计算表面面积的多边形
返回: 表面面积的值。单位为平方米。返回 -1 表示计算失败。
返回类型: float
-
iobjectspy.analyst.compute_surface_distance(input_data, line)¶ 计算栅格表面距离,即计算在 DEM 栅格拟合的三维曲面上沿指定的线段或折线段的曲面距离。
- 注意:
- 表面量算所量算的距离是曲面上的,因而比平面上的值要大。
- 当用于量算的线超出了 DEM 栅格的范围时,会先按数据集范围对线对象进行裁剪,按照位于数据集范围内的那部分线来计算表面距离。
参数: - input_data (DatasetGrid or str) -- 指定的待计算表面距离的 DEM 栅格。
- line (GeoLine) -- 用于计算表面距离的二维线。
返回: 表面距离的值。单位为米。
返回类型: float
-
iobjectspy.analyst.compute_surface_volume(input_data, region, base_value)¶ 计算表面体积,即计算所选多边形区域内的 DEM 栅格拟合的三维曲面与一个基准平面之间的空间上的体积。
参数: - input_data (DatasetGrid or str) -- 待计算体积的 DEM 栅格。
- region (GeoRegion) -- 用于计算体积的多边形。
- base_value (float) -- 基准平面的值。单位与待计算的 DEM 栅格的栅格值单位相同。
返回: 指定的基准平面的值。单位与待计算的 DEM 栅格的栅格值单位相同。
返回类型: float
-
iobjectspy.analyst.divide_math_analyst(first_operand, second_operand, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格除法运算。将输入的两个栅格数据集的栅格值逐个像元地相除。栅格代数运算的具体使用,参考
expression_math_analyst()如果输入两个像素类型(PixelFormat)均为整数类型的栅格数据集,则输出整数类型的结果数据集;否则,输出浮点型的结果数据集。如果输入的两个栅格数据集 的像素类型精度不同,则运算的结果数据集的像素类型与二者中精度较高者保持一致。
参数: - first_operand (DatasetGrid or str) -- 指定的第一栅格数据集。
- second_operand (DatasetGrid or str) -- 指定的第二栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.plus_math_analyst(first_operand, second_operand, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格加法运算。将输入的两个栅格数据集的栅格值逐个像元地相加。 栅格代数运算的具体使用,参考
expression_math_analyst()如果输入两个像素类型(PixelFormat)均为整数类型的栅格数据集,则输出整数类型的结果数据集;否则,输出浮点型的结果数据集。如果输入的两个栅格数据集 的像素类型精度不同,则运算的结果数据集的像素类型与二者中精度较高者保持一致。
参数: - first_operand (DatasetGrid or str) -- 指定的第一栅格数据集。
- second_operand (DatasetGrid or str) -- 指定的第二栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.minus_math_analyst(first_operand, second_operand, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格减法运算。逐个像元地从第一个栅格数据集的栅格值中减去第二个数据集的栅格值。进行此运算时,输入栅格数据集的顺序很重要,顺序不同,结果通常也是不相同的。栅格代数运算的具体使用,参考
expression_math_analyst()如果输入两个像素类型(PixelFormat)均为整数类型的栅格数据集,则输出整数类型的结果数据集;否则,输出浮点型的结果数据集。如果输入的两个栅格数据集 的像素类型精度不同,则运算的结果数据集的像素类型与二者中精度较高者保持一致。
参数: - first_operand (DatasetGrid or str) -- 指定的第一栅格数据集。
- second_operand (DatasetGrid or str) -- 指定的第二栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.multiply_math_analyst(first_operand, second_operand, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格乘法运算。将输入的两个栅格数据集的栅格值逐个像元地相乘。栅格代数运算的具体使用,参考
expression_math_analyst()如果输入两个像素类型(PixelFormat)均为整数类型的栅格数据集,则输出整数类型的结果数据集;否则,输出浮点型的结果数据集。如果输入的两个栅格数据集 的像素类型精度不同,则运算的结果数据集的像素类型与二者中精度较高者保持一致。
参数: - first_operand (DatasetGrid or str) -- 指定的第一栅格数据集。
- second_operand (DatasetGrid or str) -- 指定的第二栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.to_float_math_analyst(input_data, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格浮点运算。将输入的栅格数据集的栅格值转换成浮点型。 如果输入的栅格值为双精度浮点型,进行浮点运算后的结果栅格值也转换为单精度浮点型。
参数: - input_data (DatasetGrid or str) -- 指定的第一栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.to_int_math_analyst(input_data, user_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格取整运算。提供对输入的栅格数据集的栅格值进行取整运算。取整运算的结果是去除栅格值的小数部分,只保留栅格值的整数。如果输入栅格值为整数类型,进行取整运算后的结果与输入栅格值相同。
参数: - input_data (DatasetGrid or str) -- 指定的第一栅格数据集。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集的范围的交集作为计算区域。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.expression_math_analyst(expression, pixel_format, out_data, is_ingore_no_value=True, user_region=None, out_dataset_name=None, progress=None)¶ 栅格代数运算类。用于提供对一个或多个栅格数据集的数学运算及函数运算。
栅格代数运算的思想是运用代数学的观点对地理特征和现象进行空间分析。实质上,是对多个栅格数据集(DatasetGrid)进行数学运算以及函数运算。运算结果 栅格的像元值是由输入的一个或多个栅格同一位置的像元的值通过代数规则运算得到的。
栅格分析中很多功能都是基于栅格代数运算的,作为栅格分析的核心内容,栅格代数运算用途十分广泛,能够帮助我们解决各种类型的实际问题。如建筑工程中的计 算填挖方量,将工程实施前的DEM栅格与实施后的DEM栅格相减,就能够从结果栅格中得到施工前后的高程差,将结果栅格的像元值与像元所代表的实际面积相乘, 就可以得知工程的填方量与挖方量;又如,想要提取2000年全国范围内平均降雨量介于20毫米和50毫米的地区,可以通过“20<年平均降雨量<50”关系运算表达式, 对年平均降雨量栅格数据进行运算而获得。
通过该类的方法进行栅格代数运算主要有以下两种途径:
- 使用该类提供的基础运算方法。该类提供了六个用于进行基础运算的方法,包括 plus(加法运算)、minus(减法运算)、multiply(乘法运算)、 divide(除法运算)、to_int(取整运算)和 to_float(浮点运算)。使用这几个方法可以完成一个或多个栅格数据对应栅格值的算术运算。对于相 对简单的运算,可以通过多次调用这几个方法来实现,如 (A/B)-(A/C)。
- 执行运算表达式。使用表达式不仅可以对一个或多个栅格数据集实现运算符运算,还能够进行函数运算。运算符包括算术运算符、关系运算符和布尔运算符, 算术运算主要包括加法(+)、减法(-)、乘法(*)、除法(/);布尔运算主要包括和(And)、或(Or)、异或(Xor)、非(Not);关系运算主要包括 =、<、>、<>、>=、<=。注意,对于布尔运算和关系运算均有三种可能的输出结果:真=1、假=0及无值(只要有一个输入值为无值,结果即为无值)。
此外,还支持 21 种常用的函数运算,如下图所示:
执行栅格代数运算表达式,支持自定义表达式栅格运算,通过自定义表达式可以进行算术运算、条件运算、逻辑运算、函数运算(常用函数、三角函数)以及复合运算。 栅格代数运算表达式的组成需要遵循以下规则:
运算表达式应为一个形如下式的字符串:
[DatasourceAlias1.Raster1] + [DatasourceAlias2.Raster2] 使用“ [数据源别名.数据集名] ”来指定参加运算的栅格数据集;注意要使用方括号把名字括起来。
栅格代数运算支持四则运算符("+" 、"-" 、"*" 、"/" )、条件运算符(">" 、">=" 、"<" 、"<=" 、"<>" 、"==" )、逻辑运算符("|" 、"&" 、"Not()" 、"^" )和一些常用数学函数("abs()" 、"acos()" 、"asin()" 、"atan()" 、"acot()" 、"cos()" 、"cosh()" 、"cot()" 、"exp()" 、"floor()" 、"mod(,)" 、"ln()" 、"log()" 、"pow(,)" 、"sin()" 、"sinh()" 、"sqrt()" 、"tan()" 、"tanh()" 、"Isnull()" 、"Con(,,)" 、"Pick(,,,..)" )。
代数运算的表达式中各个函数之间可以嵌套使用,直接用条件运算符计算的栅格结果都为二值(如大于、小于等),即满足条件的用1代替,不满足的用0代替,若想使用其他值来表示满足条件和不满足条件的取值,可以使用条件提取函数Con(,,)。例如:"Con(IsNull([SURFACE_ANALYST.Dem3] ) ,100,Con([SURFACE_ANALYST.Dem3] > 100,[SURFACE_ANALYST.Dem3] ,-9999) ) " ,该表达式的含义是:栅格数据集 Dem3 在别名为 SURFACE_ANALYST 的数据源中,将其中无值栅格变为 100,剩余栅格中,大于100 的,值保持不变,小于等于 100 的,值改成 -9999。
如果栅格计算中有小于零的负值,注意要加小括号,如:[DatasourceAlias1.Raster1] - ([DatasourceAlias2.Raster2])。
表达式中,运算符连接的操作数可以是一个栅格数据集,也可以是数字或者数学函数。
数学函数的自变量可以为一个数值,也可以为某个数据集,或者是一个数据集或多个数据集的运算表达式。
表达式必须是没有回车的单行表达式。
表达式中必须至少含有一个输入栅格数据集。
注意:
- 参与运算的两个数据集,如果其像素类型(PixelFormat)不同,则运算的结果数据集的像素类型与二者中精度较高者保持一致。例如,一个为32位整型,一个为单精度浮点型,那么进行加法运算后,结果数据集的像素类型将为单精度浮点型。
- 对于栅格数据集中的无值数据,如果忽略无值,则无论何种运算,结果仍为无值;如果不忽略无值,意味着无值将参与运算。例如,两栅格数据集 A 和 B 相加,A 某单元格为无值,值为-9999,B 对应单元格值为3000,如果不忽略无值,则运算结果该单元格值为-6999。
参数: - expression (str) -- 自定义的栅格运算表达式。
- pixel_format (PixelFormat or str) -- 指定的结果数据集的像素格式。注意,如果指定的像素类型的精度低于参与运算的栅格数据集像素类型的精度,运算结果可能不正确。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- is_ingore_no_value (bool) -- 是否忽略无值栅格数据。true 表示忽略无值数据,即无值栅格不参与运算。
- user_region (GeoRegion) -- 用户指定的有效计算区域。如果为 None,则表示计算全部区域,如果参与运算的数据集范围不一致,将使用所有数据集 的范围的交集作为计算区域。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetGrid or str
-
class
iobjectspy.analyst.StatisticsField(source_field=None, stat_type=None, result_field=None)¶ 基类:
object对字段进行统计的信息。主要用于
summary_points()初始化对象
参数: - source_field (str) -- 被统计的字段名称
- stat_type (StatisticsFieldType or str) -- 统计类型
- result_field (str) -- 结果字段名称
-
result_field¶ str -- 结果字段名称
-
set_result_field(value)¶ 设置结果字段名称
参数: value (str) -- 结果字段名称 返回: self 返回类型: StatisticsField
-
set_source_field(value)¶ 设置被统计的字段名称
参数: value (str) -- 字段名称 返回: self 返回类型: StatisticsField
-
set_stat_type(value)¶ 设置字段统计类型
参数: value (StatisticsFieldType or str) -- 字段统计类型 返回: self 返回类型: StatisticsField
-
source_field¶ str -- 被统计的字段名称
-
stat_type¶ StatisticsFieldType -- 字段统计类型
-
iobjectspy.analyst.create_line_one_side_multi_buffer(input_data, radius, is_left, unit=None, segment=24, is_save_attributes=True, is_union_result=False, is_ring=True, out_data=None, out_dataset_name='BufferResult', progress=None)¶ 创建矢量线数据集单边多重缓冲区。缓冲区介绍请参考
create_buffer()。 线的单边多重缓冲区,是指在线对象的一侧生成多重缓冲区。左侧是指沿线对象的节点序列方向的左侧,右侧为节点序列方向的右侧。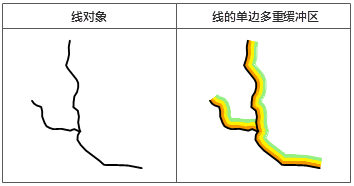
参数: - input_data (DatasetVector or Recordset) -- 指定的创建多重缓冲区的源矢量数据集。只支持线数据集或线记录集
- radius (list[float] or tuple[float] or str) -- 指定的多重缓冲区半径列表。单位由 unit 参数指定。
- is_left (bool) -- 是否生成左缓冲区。设置为 True,在线的左侧生成缓冲区,否则在右侧生成缓冲区。
- unit (BufferRadiusUnit) -- 指定的缓冲区半径单位。
- segment (int) -- 指定的弧段拟合数
- is_save_attributes (bool) -- 是否保留进行缓冲区分析的对象的字段属性。当合并结果面数据集时,该参数无效,即当 is_union_result 为 False 时有效。
- is_union_result (bool) -- 是否合并缓冲区,即是否将源数据各对象生成的所有缓冲区域进行合并运算后返回。
- is_ring (bool) -- 是否生成环状缓冲区。设置为 True,则生成多重缓冲区时外圈缓冲区是以环状区域与内圈数据相邻的;设置为 False,则外围缓冲区是一个包含了内圈数据的区域。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.create_multi_buffer(input_data, radius, unit=None, segment=24, is_save_attributes=True, is_union_result=False, is_ring=True, out_data=None, out_dataset_name='BufferResult', progress=None)¶ 创建矢量数据集多重缓冲区。缓冲区介绍请参考
create_buffer()参数: - input_data (DatasetVector or Recordset) -- 指定的创建多重缓冲区的源矢量数据集或记录集。支持点、线、面数据集和网络数据集。对网络数据集进行分析,是对其中的弧段作缓冲区。
- radius (list[float] or tuple[float]) -- 指定的多重缓冲区半径列表。单位由 unit 参数指定。
- unit (BufferRadiusUnit or str) -- 指定的缓冲区半径单位。
- segment (int) -- 指定的弧段拟合数。
- is_save_attributes (bool) -- 是否保留进行缓冲区分析的对象的字段属性。当合并结果面数据集时,该参数无效,即当 is_union_result 为 False 时有效。
- is_union_result (bool) -- 是否合并缓冲区,即是否将源数据各对象生成的所有缓冲区域进行合并运算后返回。
- is_ring (bool) -- 是否生成环状缓冲区。设置为 True,则生成多重缓冲区时外圈缓冲区是以环状区域与内圈数据相邻的;设置为 False,则外围缓冲区是一个包含了内圈数据的区域。
- out_data (Datasource) -- 存储结果数据的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.compute_min_distance(source, reference, min_distance, max_distance, out_data=None, out_dataset_name=None, progress=None)¶ 最近距离计算。求算“被计算记录集”中每一个对象到“参考记录集”中在查询范围内的所有对象的距离中的最小值(即最近距离),并将最近距离信息保存到一个新的属性表数据集中。 最近距离计算功能用于计算“被计算记录集”中每一个对象(称为“被计算对象”)到“参考记录集”中在查询范围内的所有对象(称为“参考对象”)的距离中的最小值,也就是最近距离,计算的结果为一个纯属性表数据集,记录了“被计算对象”到最近的“参考对象”的距离信息,使用三个属性字段存储,分别为:Source_ID(“被计算对象”的 SMID)、根据参考对象的类型可能为 Point_ID、Line_ID、Region_ID(“参考对象”的 SMID)以及 Distance(前面二者的距离值)。如果被计算对象与多个参考对象具有最近距离,则属性表中相应的添加多条记录。
支持的数据类型
“被计算记录集”仅支持二维点记录集,“参考记录集”可以是为从二维点、线、面数据集以及二维网络数据集获得的记录集。从二维网络数据集可以获得存有弧段的记录集,或存有结点的记录集(从网络数据集的子集获取),将这两种记录集作为“参考记录集”,可用于查找最近的弧段或最近的结点。
“被计算记录集”和“参考记录集”可以是同一个记录集,也可以是从同一个数据集查询出的不同记录集,这两种情况下,不会计算对象到自身的距离。
查询范围
查询范围由用户指定的一个最小距离和一个最大距离构成,用于过滤不参与计算的“参考对象”,即从“被计算对象”出发,只有与其距离介于最小距离和最大距离之间(包括等于)的“参考对象”参与计算。如果将查询范围设置为从“0”到“-1”,则表示计算到“参考记录集”中所有对象的最近距离。
如下图所示,红色圆点来自“被计算记录集”,方块来自“参考记录集”,粉色区域表示查询范围,则只有位于查询范围内的蓝色方块参与最近距离计算,也就是说本例的计算的结果只包含红色圆点与距其最近的蓝色方块的 SMID 和距离值
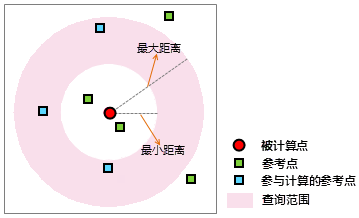
注意事项:
“被计算记录集”和“参考记录集”所属的数据集的必须具有相同的坐标系。
如下图所示,点到线对象的距离,是计算点到整个线对象的最小距离,即在线上找到一点与被计算点的距离最短;同样的,点到面对象的距离,是计算点到面对象的整个边界的最小距离。
计算两个对象间距离时,出现包含或(部分)重叠的情况时,距离均为 0。例如点对象在线对象上,二者间距离为 0。
参数: - source (DatasetVector or Recordset or str) -- 指定的被计算记录集。只支持二维点记录集和数据集
- reference (DatasetVector or Recordset or str) -- 指定的参考记录集。支持二维点、线、面记录集和数据集
- min_distance (float) -- 指定的查询范围的最小距离。取值范围为大于或等于 0。单位与被计算记录集所属数据集的单位相同。
- max_distance (float) -- 指定的查询范围的最大距离。取值范围为大于 0 的值及 -1。当设置为 -1 时,表示不限制最大距离。单位与被计算记录集所属数据集的单位相同。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 指定的用于存储结果属性表数据集的数据源。
- out_dataset_name (str) -- 指定的结果属性表数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型:
-
iobjectspy.analyst.compute_range_distance(source, reference, min_distance, max_distance, out_data=None, out_dataset_name=None, progress=None)¶ 范围距离计算。求算“被计算记录集”中每一个对象到“参考记录集”中在查询范围内的每一个对象的距离,并将距离信息保存到一个新的属性表数据集中。
该功能用于计算记录集 A 中每一个对象到记录集 B 中在查询范围内的每一个对象的距离,记录集 A 称为“被计算记录集”,当中的对象称作“被计算对象”,记录集 B 称为“参考记录集”,当中的对象称作“参考对象”。“被计算记录集”和“参考记录集”可以是同一个记录集,也可以是从同一个数据集查询出的不同记录集,这两种情况下,不会计算对象到自身的距离。
查询范围由一个最小距离和一个最大距离构成,用于过滤不参与计算的“参考对象”,即从“被计算对象”出发,只有与其距离介于最小距离和最大距离之间(包括等于)的“参考对象”参与计算。
如下图所示,红色圆点为“被计算对象”,方块为“参考对象”,粉色区域表示查询范围,则只有位于查询范围内的蓝色方块参与距离计算,也就是说本例的计算的结果只包含红色圆点与粉色区域内的蓝色方块的 SMID 和距离值。
范围距离计算的结果为一个纯属性表数据集,记录了“被计算对象”到“参考对象”的距离信息,使用三个属性字段存储,分别为:Source_ID(“被计算对象”的 SMID)、根据参考对象的类型可能为 Point_ID、Line_ID、Region_ID(“参考对象”的 SMID)以及 Distance(前面二者的距离值)。
注意事项:
“被计算记录集”和“参考记录集”所属的数据集的必须具有相同的坐标系。
如下图所示,点到线对象的距离,是计算点到整个线对象的最小距离,即在线上找到一点与被计算点的距离最短;同样的,点到面对象的距离,是计算点到面对象的整个边界的最小距离。
计算两个对象间距离时,出现包含或(部分)重叠的情况时,距离均为 0。例如点对象在线对象上,二者间距离为 0。
参数: - source (DatasetVector or Recordset or str) -- 指定的被计算记录集。只支持二维点记录集或数据集
- reference (DatasetVector or Recordset or str) -- 指定的参考记录集。只支持二维点、线、面记录集或数据集
- min_distance (float) -- 指定的查询范围的最小距离。取值范围为大于或等于 0。 单位与被计算记录集所属数据集的单位相同。
- max_distance (float) -- 指定的查询范围的最大距离。取值范围为大于或等于 0,且必须大于或等于最小距离。单位与被计算记录集所属数据集的单位相同。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 指定的用于存储结果属性表数据集的数据源。
- out_dataset_name (str) -- 指定的结果属性表数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型:
-
iobjectspy.analyst.integrate(source_dataset, tolerance, unit=None, precision_orders=None, progress=None)¶ - 对数据集进行数据整合,整合的过程包括节点捕捉和插点操作。与 py:func:.preprocess: 的具有相似的功能,能将数据中的拓扑错误处理掉,与
- py:func:.preprocess: 的差别在于,数据整合会进行多次迭代,直到数据中没有拓扑错误为止(不需要节点捕捉和插点)。
>>> ds = open_datasource('E:/data.udb') >>> integrate(ds['building'], 1.0e-6) True >>> integrate(ds['street'], 1.0, 'meter') True >>> integrate([ds['street'], ds['poi']], 1.0, 'meter', [0,1]) True
参数: - source_dataset (DatasetVector or str or list[DatasetVector] or list[str]) -- 被处理的数据集或数据集几何
- tolerance (float) -- 结点容限
- unit (Unit or str) -- 节点容限单位,当为 None 时使用数据集坐标系单位。如果数据集坐标系为投影坐标系,禁止使用角度单位。
- precision_orders (list[int] or tuple[int]) -- 数据精度等级数组。精度等级的值越小,代表对应数据集的精度越高,数据质量越好。在进行顶点捕捉时,低精度的数据集中 的点将被捕捉到高精度数据集中的点的位置上。精度等级数组必须与要与输入的数据集集合元素数量相同并一一对应。如果 为 None,则每个数据集的精度都相同。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 成功返回 True,否则返回False
返回类型: bool
-
iobjectspy.analyst.eliminate(source, region_tolerance, vertex_tolerance, is_delete_single_region=False, progress=None, group_fields=None, priority_fields=None)¶ 碎多边形合并,即将数据集中小于指定面积的多边形合并到相邻的多边形中。目前仅支持将碎多边形合并到与其相邻的具有最大面积的多边形中。
在数据制作和处理过程中,或对不精确的数据进行叠加后,都可能产生一些细碎而无用的多边形,称为碎多边形。可以通过“碎多边形合并” 功能将这些细碎多边形合并到相邻的多边形中,或删除孤立的碎多边形(没有与其他多边形相交或者相切的多边形),以达到简化数据的目的。
一般面积远远小于数据集中其他对象的多边形才被认为是“碎多边形”,通常是同一数据集中最大面积的百万分之一到万分之一间,但可以依 据实际研究的需求来设置最小多边形容限。如下图所示的数据中,在较大的多边形的边界上,有很多无用的碎多边形。
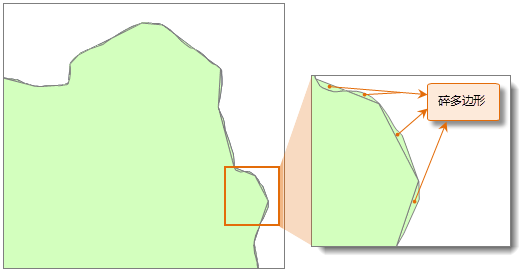
下图是对该数据进行“碎多边形合并”处理后的结果,与上图对比可以看出,碎多边形都被合并到了相邻的较大的多边形中。
注意:
- 该方法适用于两个面具有公共边界的情况,处理后会把公共边界去除。
- 进行碎多边形合并处理后,数据集内的对象数量可能减少。
参数: - source (DatasetVector or str) -- 指定的待进行碎多边形合并的数据集。只支持矢量二维面数据集,指定其他类型的数据集会抛出异常。
- region_tolerance (float) -- 指定的最小多边形容限。单位与系统计算的面积(SMAREA 字段)的单位一致。将 SMAREA 字段的值与该容限值对比,小于该值的多边形将被消除。取值范围为大于等于0,指定为小于0的值会抛出异常。
- vertex_tolerance (float) -- 指定的节点容限。单位与进行碎多边形合并的数据集单位相同。若两个节点之间的距离小于此容限值,则合并过程中会自动将这两个节点合并为一个节点。取值范围大于等于0,指定为小于0的值会抛出异常。
- is_delete_single_region (bool) -- 指定是否删除孤立的小多边形。如果为 true 会删除孤立的小多边形,否则不删除。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent - group_fields (list[str] or tuple[str] or str) -- 分组字段,字段值相同的多边形才可能进行合并
- priority_fields (list[str] or tuple[str] or str) --
合并对象的优先级字段,当分组字段不为空时有效。用户可以指定多个优先级字段或不指定,如果指定优先级字段,则按照字段的顺序, 当被合并的多边形的属性字段值等于相邻多边形的属性字段值,则合并到对应的多边形上,如果不相等,则比较下一个优先级字段的字段值, 如果所有的优先级字段值都不相等,则默认会合并到相邻的面积最大的多边形上。
- 例如用户指定了 A、B、C 三个优先级字段
- 当被合并的多边形 F1 中 A 字段值等于相邻对象 F2 的 A 字段值,则 F1 被合并到 F2 中
- 如果 A 字段不相等,则比较 B 字段值的值,如果 F1 的 B字段值等于相邻对象 F2 的 B 字段值,但 F1 的A 字段值又同时等于 F3 的 A 字段值,则将 F1 合并到 F3,因为靠前的字段具有较高的优先级。
- 如果有 F2 和 F3 两个对象的 A 字段值都等于 F1 的 A 字段值,则默认使用面积最大的多边形,即,如果 Area(F2) > Area(F3),则 F1 合并到 F2,否则合并到 F3中。
当优先级字段为空时,使用面积最大原则,即小多边形(被合并的多边形)将会合并到面积最大的多边形上。
返回: 整合成功返回 True,失败返回 False
返回类型: bool
-
iobjectspy.analyst.eliminate_specified_regions(source, small_region_ids, vertex_tolerance, exclude_region_ids=None, group_fields=None, priority_fields=None, is_max_border=False, progress=None)¶ 指定要被合并的多边形ID,进行碎多边形合并操作,关于碎多边形合并的相关介绍,具体参考
eliminate().参数: - source (DatasetVector or str) -- 指定的待进行碎多边形合并的数据集。只支持矢量二维面数据集,指定其他类型的数据集会抛出异常。
- small_region_ids (int or list[int] or tuple[int]) -- 指定被合并的小多边形的 ID,指定的对象如果找到符合要求临近对象,则会被合并到临近对象中,小多边形则会被删除。
- vertex_tolerance (float) -- 指定的节点容限。单位与进行碎多边形合并的数据集单位相同。若两个节点之间的距离小于此容限值,则合并过程中会自 动将这两个节点合并为一个节点。取值范围大于等于0,指定为小于0的值会抛出异常。
- exclude_region_ids (int or list[int] or tuple[int]) -- 指定要排除的多边形的 ID,即不参与运算的的对象 ID。
- group_fields (list[str] or tuple[str] or str) -- 分组字段,字段值相同的多边形才可能进行合并
- priority_fields (list[str] or tuple[str] or str) --
合并对象的优先级字段,当分组字段不为空时有效。用户可以指定多个优先级字段或不指定,如果指定优先级字段,则按照字段的顺序, 当被合并的多边形的属性字段值等于相邻多边形的属性字段值,则合并到对应的多边形上,如果不相等,则比较下一个优先级字段的字段值, 如果所有的优先级字段值都不相等,等默认会合并到相邻的面积最大的多边形上或公共边界最大的多边形上。
- 例如用户指定了 A、B、C 三个优先级字段
- 当被合并的多边形 F1 中 A 字段值等于相邻对象 F2 的 A 字段值,则 F1 被合并到 F2 中
- 如果 A 字段不相等,则比较 B 字段值的值,如果 F1 的 B字段值等于相邻对象 F2 的 B 字段值,但 F1 的A 字段值又同时等于 F3 的 A 字段值,则将 F1 合并到 F3,因为靠前的字段具有较高的优先级。
- 如果有 F2 和 F3 两个对象的 A 字段值都等于 F1 的 A 字段值,则默认使用面积最大的多边形或公共边界最大的多边形。
当优先级字段为空时,使用面积最大原则,即小多边形(被合并的多边形)将会合并到面积最大的多边形上或公共边界最大的多边形上。
- is_max_border (bool) -- 设置合并对象时是否以最大边界方式合并: - 如果为True,则指定的小多边形会被合并到临近的公共边界最长的多边形上 - 如果为False,则指定的小多边形会被合并到临近的面积最大的多边形上。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 整合成功返回 True,失败返回 False
返回类型: bool
-
iobjectspy.analyst.edge_match(source, target, edge_match_mode, tolerance=None, is_union=False, edge_match_line=None, out_data=None, out_dataset_name=None, progress=None)¶ 图幅接边,对两个二维线数据集进行自动接边。
参数: - source (DatasetVector) -- 接边源数据集。只能是二维线数据集。
- target (DatasetVector) -- 接边目标数据。只能是二维线数据集,与接边源数据有相同的坐标系。
- edge_match_mode (EdgeMatchMode or str) -- 接边模式。
- tolerance (float) -- 接边容限。单位与进行接边的数据集的单位相同。
- is_union (bool) -- 是否进行接边融合。
- edge_match_line (GeoLine) -- 数据接边的接边线。在接边方式为交点位置接边 EdgeMatchMode.THE_INTERSECTION 的时候用来计算交点, 不设置将按照数据集范围自动计算接边线来计算交点。 设置接边线后,发生接边关联的对象的端点将尽可能的靠到接边线上。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 接边关联数据所在的数据源。
- out_dataset_name (str) -- 接边关联数据的数据集名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 如果设置了接边关联数据集且接边成功,则返回接边关联数据集对象或数据集名称。如果没有设置接边关联数据集,将不会生成 接边关联数据集,则返回是否进行接边成功。
返回类型: DatasetVector or str or bool
-
iobjectspy.analyst.region_to_center_line(region_data, out_data=None, out_dataset_name=None, progress=None)¶ 提取面数据集或记录集的中心线,一般用于提取河流的中心线。
该方法用于提取面对象的中心线。如果面包含岛洞,提取时会绕过岛洞,采用最短路径绕过。如下图。
如果面对象不是简单的长条形,而是具有分叉结构,则提取的中心线是最长的一段。如下图所示。
参数: - region_data (Recordset or DatasetVector) -- 指定的待提取中心线的面记录集或面数据集
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源信息或数据源对象
- out_dataset_name (str) -- 结果中心线数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集对象或结果数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.dual_line_to_center_line(source_line, max_width, min_width, out_data=None, out_dataset_name=None, progress=None)¶ 根据给定的宽度从双线记录集或数据集中提取中心线。 该功能一般用于提取双线道路或河流的中心线。双线要求连续且平行或基本平行,提取效果如下图。
注意:
- 双线一般为双线道路或双线河流,可以是线数据,也可以是面数据。
- max_width 和 min_width 参数用于指定记录集中双线的最大宽度和最小宽度,用于提取最小和最大宽度之间的双线的中心线。小于最小宽度、大于最大宽度部分的双线不提取中心线,且大于最大宽度的双线保留,小于最小宽度的双线丢弃。
- 对于双线道路或双线河流中比较复杂的交叉口,如五叉六叉,或者双线的最大宽度和最小宽度相差较大的情形,提取的结果可能不理想。
参数: - source_line (DatasetVector or Recordset or str) -- 指定的双线记录集或数据集。要求为面类型的数据集或记录集。
- max_width (float) -- 指定的双线的最大宽度。要求为大于 0 的值。单位与双线记录集所属的数据集相同。
- min_width (float) -- 指定的双线的最小宽度。要求为大于或等于 0 的值。单位与双线记录集所属的数据集相同。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 指定的用于存储结果中心线数据集的数据源。
- out_dataset_name (str) -- 指定的结果中心线数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集对象或结果数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.grid_extract_isoline(extracted_grid, interval, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从栅格数据集中提取等值线,并将结果保存为数据集。
等值线是由一系列具有相同值的点连接而成的光滑曲线或折线,如等高线、等温线。等值线的分布反映了栅格表面上值的变化,等值线分布越密集的地方, 表示栅格表面值的变化比较剧烈,例如,如果为等高线,则越密集,坡度越陡峭,反之坡度越平缓。通过提取等值线,可以找到高程、温度、降水等的值相同的位置, 同时等值线的分布状况也可以显示出变化的陡峭和平缓区。
如下所示,上图为某个区域的 DEM 栅格数据,下图是从上图中提取的等高线。DEM 栅格数据的高程信息是存储在每一个栅格单元中的,栅格是有大小的,栅格的大小取决于栅格数据的分辨率 ,即每一个栅格单元代表实际地面上的相应地块的大小,因此,栅格数据不能很精确的反应每一位置上的高程信息 ,而矢量数据在这方面相对具有很大的优势,因此,从栅格数据中提取等高线 ,把栅格数据变成矢量数据,就可以突出显示数据的细节部分,便于分析,例如,从等高线数据中可以明显的区分地势的陡峭与舒缓的部位,可以区分出山脊山谷
SuperMap 提供两种方法来提取等值线:
- 通过设置基准值(datum_value)和等值距(interval)来提取等间距的等值线。该方法是以等值距为间隔向基准值的前后两个方向 计算提取哪些高程的等值线。例如,高程范围为15-165的 DEM 栅格数据,设置基准值为50,等值距为20,则提取等值线的高程分别 为:30、50、70、90、110、130和150。
- 通过 expected_z_values 方法指定一个 Z 值的集合,则只提取高程为集合中值的等值线/面。例如,高程范围为0-1000的 DEM 栅 格数据,指定 Z 值集合为[20,300,800],那么提取的结果就只有 20、300、800 三条等值线或三者构成的等值面。
- 注意:
- 如果同时调用了上面两种方法所需设置的属性,那么只有 expected_z_values 方法有效,即只提取指定的值的等值线。因此,想要 提取等间距的等值线,就不能调用 expected_z_values 方法。
参数: - extracted_grid (DatasetGrid or str) -- 指定的提取操作需要的参数。
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0.
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值线。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值线的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) --
重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。
重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值线或等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。等值线提取时,光滑度可自由设置
- clip_region (GeoRegion) -- 指定的裁剪面对象。如果不需要对操作结果进行裁剪,可以使用 None 值取代该参数。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。如果为空,则会直接返回等值线对象的列表。
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值线得到的数据集或数据集名称,或等值线对象列表。
返回类型: DatasetVector or str or list[GeoLine]
-
iobjectspy.analyst.grid_extract_isoregion(extracted_grid, interval, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从栅格数据集中提取等值面。
SuperMap 提供两种方法来提取等值面:
- 通过设置基准值(datum_value)和等值距(interval)来提取等间距的等值面。该方法是以等值距为间隔向基准值的前后两个方向计算 提取哪些高程的等值线。例如,高程范围为15-165的 DEM 栅格数据,设置基准值为50,等值距为20,则提取等值线的高程分别为: 30、50、70、90、110、130和150。
- 通过 expected_z_values 方法指定一个 Z 值的集合,则只提取高程为集合中值的等值面。例如,高程范围为0-1000的 DEM 栅格数据, 指定 Z 值集合为[20,300,800],那么提取的结果就只有20、300、800三者构成的等值面。
注意:
- 如果同时调用了上面两种方法所需设置的属性,那么只有 setExpectedZValues 方法有效,即只提取指定的值的等值面。 因此,想要提取等间距的等值面,就不能调用 expected_z_values 方法。
参数: - extracted_grid (指定的待提取的栅格数据集。) -- DatasetGrid or str
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值面。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值面的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) -- 重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。 重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。 对于等值面的提取,采用先提取等值线然后生成等值面的方式,若将光滑度设置为2, 则中间结果数据集,即等值线对象的点数将为原始数据集点数的2倍,当光滑度设定值不断增大时,点数将成2的指数倍 增长,这将大大降低等值面提取的效率甚至可能导致提取失败。
- clip_region (GeoRegion) -- 指定的裁剪面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。如果为空,则直接返回等值面对象列表
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值面得到的数据集或数据集名称,或等值面对象列表
返回类型: DatasetVector or str or list[GeoRegion]
-
iobjectspy.analyst.point_extract_isoline(extracted_point, z_value_field, resolution, interval, terrain_interpolate_type=None, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从点数据集中提取等值线,并将结果保存为数据集。方法的实现原理类似“从点数据集中提取等值线”的方法,不同之处在于, 这里的操作对象是点数据集,因此, 实现的过程是先对点数据集中的点数据使用 IDW 插值法('InterpolationAlgorithmType.IDW` ) 进行插值分析,得到栅格数据集(方法实现的中间结果,栅格值为单精度浮点型),然后从栅格数据集中提取等值线。
点数据中的点是分散分布,点数据能够很好的表现位置信息,但对于点本身的其他属性信息却表现不出来,例如,已经获取了某个研究区域的 大量采样点的高程信息,如下所示 (上图),从图上并不能看出地势高低起伏的趋势,看不出哪里地势陡峭、哪里地形平坦,如果我们运用 等值线的原理,将这些点数据所蕴含的信息以等值线的形式表现出来, 即将相邻的具有相同高程值的点连接起来 ,形成下面下图所示的等 高线图,那么关于这个区域的地形信息就明显的表现出来了。不同的点数据提取的等值线具有不同的含义,主要依据点数据多代表的信息而定, 如果点的值代表温度,那么提取的等值线就是等温线;如果点的值代表雨量,那么提取的等值线就是等降水量线,等等。

注意:
- 从点数据(点数据集/记录集/三维点集合)中提取等值线(面)时,插值得出的中间结果栅格的分辨率如果太小,会导致提取等值线(面) 失败。这里提供一个判断方法:使用点数据的 Bounds 的长和宽分别除以设置的分辨率,也就是中间结果栅格的行列数,如果行列数任何一 个大于10000,即认为分辨率设置的过小了,此时系统会抛出异常
参数: - extracted_point (DatasetVector or str or Recordset) -- 指定的待提取的点数据集或记录集
- z_value_field (str) -- 指定的用于提取操作的字段名称。提取等值线时,将使用该字段中的值,对点数据集进行插值分析。
- resolution (float) -- 指定的中间结果(栅格数据集)的分辨率。
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0
- terrain_interpolate_type (TerrainInterpolateType or str) -- 地形插值类型。
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值线。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值线的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) --
重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。
重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值线或等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。等值线提取时,光滑度可自由设置
- clip_region (GeoRegion) -- 指定的裁剪面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。 如果为空,则会直接返回等值线对象的列表。
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值线得到的数据集或数据集名称,或等值线对象列表
返回类型: DatasetVector or str or list[GeoLine]
-
iobjectspy.analyst.points_extract_isoregion(extracted_point, z_value_field, interval, resolution=None, terrain_interpolate_type=None, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从点数据集中提取等值面。方法的实现原理是先对点数据集使用 IDW 插值法(InterpolationAlgorithmType.IDW)进行插值分析, 得到栅格数据集(方法实现的中间结果,栅格值为单精度浮点型),接着从栅格数据集中提取等值线, 最终由等值线构成等值面。
等值面是由相邻的等值线封闭组成的面。等值面的变化可以很直观的表示出相邻等值线之间的变化,诸如高程、温度、降水、污染或大气压 力等用等值面来表示是非常直观、 有效的。等值面分布的效果与等值线的分布相同,也是反映了栅格表面上的变化,等值面分布越密集的地 方,表示栅格表面值有较大的变化,反之则表示栅格表面值变化较少; 等值面越窄的地方,表示栅格表面值有较大的变化,反之则表示栅格 表面值变化较少。
如下所示,上图为存储了高程信息的点数据集,下图为从上图点数据集中提取的等值面,从等值面数据中可以明显的分析出地形的起伏变化, 等值面越密集, 越狭窄的地方表示地势越陡峭,反之,等值面越稀疏,较宽的地方表示地势较舒缓,变化较小。

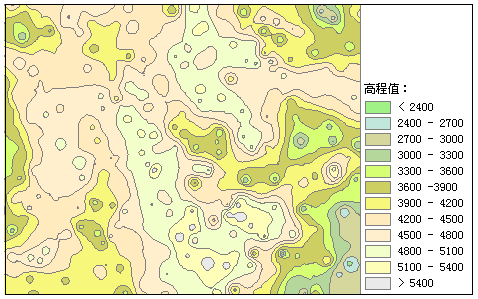
注意:
- 从点数据(点数据集/记录集/三维点集合)中提取等值面时,插值得出的中间结果栅格的分辨率如果太小,会导致提取等值面 失败。这里提供一个判断方法:使用点数据的 Bounds 的长和宽分别除以设置的分辨率,也就是中间结果栅格的行列数,如果行列数任何一个 大于10000,即认为分辨率设置的过小了,此时系统会抛出异常。
参数: - extracted_point (DatasetVector or str or Recordset) -- 指定的待提取的点数据集或记录集
- z_value_field (str) -- 指定的用于提取操作的字段名称。提取等值面时,将使用该字段中的值,对点数据集进行插值分析。
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0
- resolution (float) -- 指定的中间结果(栅格数据集)的分辨率。
- terrain_interpolate_type (TerrainStatisticType) -- 指定的地形插值类型。
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值面。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值面的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) -- 重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。 重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。 对于等值面的提取,采用先提取等值线然后生成等值面的方式,若将光滑度设置为2, 则中间结果数据集,即等值线对象的点数将为原始数据集点数的2倍,当光滑度设定值不断增大时,点数将成2的指数倍 增长,这将大大降低等值面提取的效率甚至可能导致提取失败。
- clip_region (GeoRegion) -- 指定的裁剪面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。如果为空,则直接返回等值面对象列表
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值面得到的数据集或数据集名称,或等值面对象列表
返回类型: DatasetVector or str or list[GeoRegion]
-
iobjectspy.analyst.point3ds_extract_isoline(extracted_points, resolution, interval, terrain_interpolate_type=None, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从三维点集合中提取等值线,并将结果保存为数据集。方法的实现原理是先利用点集合中存储的三维信息(高程或者温度等),也就是 除了点的坐标信息的数据, 对点数据进行插值分析,得到栅格数据集(方法实现的中间结果,栅格值为单精度浮点型),然后从栅格数据集 中提取等值线。
点数据提取等值线介绍参考
point_extract_isoline()注意:
- 从点数据(点数据集/记录集/三维点集合)中提取等值线(面)时,插值得出的中间结果栅格的分辨率如果太小,会导致提取等值线(面) 失败。这里提供一个判断方法:使用点数据的 Bounds 的长和宽分别除以设置的分辨率,也就是中间结果栅格的行列数,如果行列数任何一 个大于10000,即认为分辨率设置的过小了,此时系统会抛出异常
参数: - extracted_points (list[Point3D]) -- 指定的待提取等值线的点串,该点串中的点是三维点,每一个点存储了 X,Y 坐标信息和只有一个三维度的信息(例如:高程信息等)。
- resolution (float) -- 指定的中间结果(栅格数据集)的分辨率。
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0
- terrain_interpolate_type (TerrainInterpolateType or str) -- 地形插值类型。
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值线。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值线的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) -- 重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。 重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值线或等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。等值线提取时,光滑度可自由设置;
- clip_region (GeoRegion) -- 指定的裁剪面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。如果为空,则直接返回等值线对象列表
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值线得到的数据集或数据集名称,或等值线对象列表
返回类型: DatasetVector or str or list[GeoLine]
-
iobjectspy.analyst.point3ds_extract_isoregion(extracted_points, resolution, interval, terrain_interpolate_type=None, datum_value=0.0, expected_z_values=None, resample_tolerance=0.0, smooth_method='BSPLINE', smoothness=0, clip_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 用于从三维点集合中提取等值面,并将结果保存为数据集。方法的实现原理是先利用点集合中存储的第三维信息(高程或者温度等),也就 是除了点的坐标信息的数据, 对点数据使用 IDW 插值法(InterpolationAlgorithmType.IDW)进行插值分析,得到栅格数据集(方法实现 的中间结果,栅格值为单精度浮点型),接着从栅格数据集中提取等值面。
点数据提取等值面介绍,参考
points_extract_isoregion()参数: - extracted_points (list[Point3D]) -- 指定的待提取等值面的点串,该点串中的点是三维点,每一个点存储了 X,Y 坐标信息和只有一个第三维度的信息(例如:高程信息等)。
- resolution (float) -- 指定的中间结果(栅格数据集)的分辨率
- interval (float) -- 等值距,等值距是两条等值线之间的间隔值,必须大于0
- terrain_interpolate_type (TerrainInterpolateType or str) -- 指定的地形插值类型。
- datum_value (float) --
设置等值线的基准值。基准值与等值距(interval)共同决定提取哪些高程上的等值面。基准值作为一个生成等值 线的初始起算值,以等值距为间隔向其前后两个方向计算,因此并不一定是最小等值面的值。例如,高程范围为 220-1550 的 DEM 栅格数据,如果设基准值为 500,等值距为 50,则提取等值线的结果是:最小等值线值为 250, 最大等值线值为 1550。
当同时设置 expected_z_values 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- expected_z_values (list[float] or str) -- 期望分析结果的 Z 值集合。Z 值集合存储一系列数值,该数值为待提取等值线的值。即,仅高程值在Z值集 合中的等值线会被提取。 当同时设置 datum_value 时,只会考虑 expected_z_values 设置的值,即只提取高程为这些值的等值线。
- resample_tolerance (float) -- 重采样的距离容限系数。通过对提取出的等值线行重采样,可以简化最终提取的等值线数据。SuperMap 在 提取等值线/面时使用的重采样方法为光栏法(VectorResampleType.RTBEND),该方法需要一个重采样 距离容限进行采样控制。它的值由重采样的距离容限系数乘以源栅格分辨率得出,一般取值为源栅格分辨率 的 0~1 倍。 重采样的距离容限系数默认为 0,即不进行任何采样,保证结果正确,但通过设置合理的参数,可以加快执 行速度。容限值越大,等值线边界的控制点越少,此时可能出现等值线相交的情况。因此,推荐用户先使 用默认值来提取等值线。
- smooth_method (SmoothMethod or str) -- 滑处理所使用的方法
- smoothness (int) -- 设置等值面的光滑度。 光滑度为 0 或 1表示不进行光滑处理,值越大则光滑度越高。 对于等值面的提取,采用先提取等值线然后生成等值面的方式,若将光滑度设置为2, 则中间结果数据集,即等值线对象的点数将为原始数据集点数的2倍,当光滑度设定值不断增大时,点数将成2的指数倍 增长,这将大大降低等值面提取的效率甚至可能导致提取失败。
- clip_region (GeoRegion) -- 指定的裁剪面对象。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存放结果数据集的数据源。如果为空,则直接返回等值面对象列表
- out_dataset_name (str) -- 指定的提取结果数据集的名称。
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 提取等值面得到的数据集或数据集名称,或等值面对象列表
返回类型: DatasetVector or str or list[GeoRegion]
-
iobjectspy.analyst.grid_basic_statistics(grid_data, function_type=None, progress=None)¶ 栅格基本统计分析,可指定变换函数类型。用于对栅格数据集进行基本的统计分析,包括最大值、最小值、平均值和标准差等。
指定变换函数时,用来统计的数据是原始栅格值经过函数变换后得到的值。
参数: - grid_data (DatasetGrid or str) -- 待统计的栅格数据
- function_type (FunctionType or str) -- 变换函数类型
- progress (进度信息处理函数,具体参考
StepEvent) -- function
返回: 基本统计分析结果
返回类型:
-
class
iobjectspy.analyst.BasicStatisticsAnalystResult¶ 基类:
object栅格基本统计分析结果类
-
first_quartile¶ float -- 栅格基本统计分析计算所得的第一四分值
-
kurtosis¶ float -- 栅格基本统计分析计算所得的峰度
-
max¶ float -- 栅格基本统计分析计算所得的最大值
-
mean¶ float -- 栅格基本统计分析计算所得的最小值
-
median¶ float -- 栅格基本统计分析计算所得的中位数
-
min¶ float
-
skewness¶ float -- 栅格基本统计分析计算所得的偏度
-
std¶ float -- 栅格基本统计分析计算所得的均方差(标准差)
-
third_quartile¶ float -- 栅格基本统计分析计算所得的第三四分值
-
to_dict()¶ 输出为 dict 对象
返回类型: dict
-
-
iobjectspy.analyst.grid_common_statistics(grid_data, compare_datasets_or_value, compare_type, is_ignore_no_value, out_data=None, out_dataset_name=None, progress=None)¶ 栅格常用统计分析,将一个栅格数据集逐行逐列按照某种比较方式与一个(或多个)栅格数据集,或一个固定值进行比较,比较结果为“真”的像元值为 1,为“假”的像元值为 0。
关于无值的说明:
- 当待统计源数据集的栅格有无值时,如果忽略无值,则统计结果栅格也为无值,否则使用该无值参与统计;当各比较数据集的栅格有无值时, 如果忽略无值,则此次统计(待统计栅格与该比较数据集的计算)不计入结果,否则使用该无值进行比较。
- 当无值不参与运算(即忽略无值)时,统计结果数据集中无值的值,由结果栅格的像素格式决定,为最大像元值,例如,结果栅格数据集像素 格式为 PixelFormat.UBIT8,即每个像元使用 8 个比特表示,则无值的值为 255。在此方法中,结果栅格的像素格式是由比较栅格数据集 的数量来决定的。比较数据集得个数、结果栅格的像素格式和结果栅格中无值的值三者的对应关系如下所示:
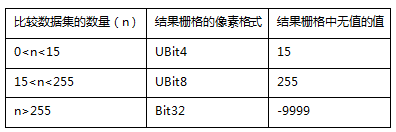
参数: - grid_data (DatasetGrid or str) -- 指定的待统计的栅格数据。
- compare_datasets_or_value (list[DatasetGrid] or list[str] or float) -- 指定的比较的数据集集合或固定值。指定固定值时,固定值的单位与待统计的栅格数据集的栅格值单位相同。
- compare_type (StatisticsCompareType or str) -- 指定的比较类型
- is_ignore_no_value (bool) -- 指定是否忽略无值。如果为 true,即忽略无值,则计算区域内的无值不参与计算,结果栅格值仍为无值;若为 false,则计算区域内的无值参与计算。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 统计结果栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.grid_neighbour_statistics(grid_data, neighbour_shape, is_ignore_no_value=True, grid_stat_mode='SUM', unit_type='CELL', out_data=None, out_dataset_name=None, progress=None)¶ 栅格邻域统计分析。
邻域统计分析,是对输入数据集中的每个像元的指定扩展区域中的像元进行统计,将运算结果作为像元的值。统计的方法包括:总和、 最大值、最小值、众数、少数、中位数等,请参见 GridStatisticsMode 枚举类型。目前提供的邻域范围类型(请参见 NeighbourShapeType 枚举类型)有:矩形、圆形、圆环和扇形。
下图为邻域统计的原理示意,假设使用“总和”作为统计方法做矩形邻域统计,邻域大小为 3×3,那么对于图中位于第二行第三列的单元格, 它的值则由以其为中心向周围扩散得到的一个 3×3 的矩形内所有像元值的和来决定。
邻域统计的应用十分广泛。例如:
对表示物种种类分布的栅格计算每个邻域内的生物种类(统计方法:种类),从而观察该地区的物种丰度;
对坡度栅格统计邻域内的坡度差(统计方法:值域),从而评估该区域的地形起伏状况;
邻域统计还用于图像处理,如统计邻域内的平均值(称为均值滤波)或中位数(称为中值滤波)可以达到平滑的效果,从而去除噪声或过多的细节,等等。
参数: - grid_data (DatasetGrid or str) -- 指定的待统计的栅格数据。
- neighbour_shape (NeighbourShape) -- 邻域形状
- is_ignore_no_value (bool) -- 指定是否忽略无值。如果为 true,即忽略无值,则计算区域内的无值不参与计算,结果栅格值仍为无值;若为 false,则计算区域内的无值参与计算。
- grid_stat_mode (GridStatisticsMode or str) -- 邻域分析的统计方法
- unit_type (NeighbourUnitType or str) -- 邻域统计的单位类型
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 统计结果栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.altitude_statistics(point_data, grid_data, out_data=None, out_dataset_name=None)¶ 高程统计,统计二维点数据集中每个点对应的栅格值,并生成一个三维点数据集,三维点对象的 Z 值即为被统计的栅格像素的高程值。
参数: - point_data (DatasetVector or str) -- 二维点数据集
- grid_data (DatasetGrid or str) -- 被统计的栅格数据集
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
返回: 统计三维数据集或数据集名称
返回类型: DatasetGrid or str
-
class
iobjectspy.analyst.GridHistogram(source_data, group_count, function_type=None, progress=None)¶ 基类:
object创建给定栅格数据集的直方图。
直方图,又称柱状图,由一系列高度不等的矩形块来表示一份数据的分布情况。一般横轴表示类别,纵轴表示分布情况。
栅格直方图的横轴表示栅格值的分组,栅格值将被划分到这 N(默认为 100)个组中,即每个组对应着一个栅格值范围;纵轴表示频数,即 栅格值在每组的值范围内的单元格的个数。
下图是栅格直方图的示意图。该栅格数据的最小值和最大值分别为 0 和 100,取组数为 10,得出每组的频数,绘制如下的直方图。矩形块 上方标注了该组的频数,例如,第 6 组的栅格值范围为 [50,60),栅格数据中值在此范围内的单元格共有 3 个,因此该组的频数为 3。
注:直方图分组的最后一组的值范围为前闭后闭,其余均为前闭后开。
在通过此方法获得栅格数据集的直方图(GridHistogram)对象后,可以通过该对象的 get_frequencies 方法返回每个组的频数,还可以通过 get_group_count 方法重新指定栅格直方图的组数,然后再通过 get_frequencies 方法返回每组的频数。
下图为创建栅格直方图的一个实例。本例中,最小栅格值为 250,最大栅格值为 1243,组数为 500,获取各组的频数,绘制出如右侧所示的 栅格直方图。从右侧的栅格直方图,可以非常直观的了解栅格数据集栅格值的分布情况。
构造栅格直方图对象
参数: - source_data (DatasetGrid or str) -- 指定的栅格数据集
- group_count (int) -- 指定的直方图的组数。必须大于 0。
- function_type (指定的变换函数类型。) -- FunctionType
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
-
class
HistogramSegmentInfo(count, max_value, min_value, range_max, range_min)¶ 基类:
object栅格直方图每个分段区间的信息类。
-
count¶ int -- 分段区间内容值的个数
-
max¶ float -- 分段区间内容值的最大值
-
min¶ float -- 分段区间内容值的最小值
-
range_max¶ float -- 分段区间的最大值
-
range_min¶ float -- 分段区间的最小值
-
-
get_frequencies()¶ 返回栅格直方图每个组的频数。直方图的每个组都对应了一个栅格值范围,值在这个范围内的所有单元格的个数即为该组的频数。
返回: 返回栅格直方图每个组的频数。 返回类型: list[int]
-
get_group_count()¶ 返回栅格直方图横轴上的组数。
返回: 返回栅格直方图横轴上的组数。 返回类型: int
-
get_segments()¶ 返回栅格直方图每个组的区间信息。
返回: 栅格直方图每个组的区间信息。 返回类型: list[GridHistogram.HistogramSegmentInfo]
-
set_group_count(count)¶ 设置栅格直方图横轴上的组数。
参数: count (int) -- 栅格直方图横轴上的组数。必须大于 0。 返回类型: self
-
iobjectspy.analyst.thin_raster(source, back_or_no_value, back_or_no_value_tolerance, out_data=None, out_dataset_name=None, progress=None)¶ 栅格细化,通常在将栅格转换为矢量线数据前使用。
栅格数据细化处理可以减少栅格数据中用于标识线状地物的单元格的数量,从而提高矢量化的速度和精度。一般作为栅格转线矢量数据之 前的预处理,使转换的效果更好。例如一幅扫描的等高线图上可能使用 5、6 个单元格来显示一条等高线的宽度,细化处理后,等高线的 宽度就只用一个单元格来显示了,有利于更好地进行矢量化。
关于无值/背景色及其容限的说明:
进行栅格细化时,允许用户标识那些不需要细化的单元格。对于栅格数据集,通过无值及其容限来确定这些值,对于影像数据集,则通过背景色及其容限来确定。
- 当对栅格数据集进行细化时,栅格值为 back_or_no_value 参数指定的值的单元格被视为无值,不参与细化,而栅格的原无值将作为有效值来参与细化; 同时,在 back_or_no_value_tolerance 参数指定的无值的容限范围内的单元格也不参与细化。例如,指定无值的值为 a,指定的无值的容限为 b, 则栅格值在 [a-b,a+b] 范围内的单元格均不参与细化。
- 当对影像数据集进行细化时,栅格值为指定的值的单元格被视为背景色,不参与细化;同时,在 back_or_no_value_tolerance 参数指 定的背景色的容限范围内的单元格也不参与细化。
需要注意,影像数据集中栅格值代表的是一个颜色值,因此,如果想要将某种颜色设为背景色,为 back_or_no_value 参数指定的值应为 将该颜色(RGB 值)转为 32 位整型之后的值,系统内部会根据像素格式再进行相应的转换。背景色的容限同样为一个 32 位整型值。该 值在系统内部被转为分别对应 R、G、B 的三个容限值,例如,指定为背景色的颜色为 (100,200,60),指定的容限值为 329738,该值对应 的 RGB 值为 (10,8,5),则值在 (90,192,55) 和 (110,208,65) 之间的颜色均不参与细化。
注意:对于栅格数据集,如果指定的无值的值,在待细化的栅格数据集的值域范围外,会分析失败,返回 None。
参数: - source (DatasetImage or DatasetGrid or str) -- 指定的待细化的栅格数据集。支持影像数据集。
- back_or_no_value (int or Color) -- 指定栅格的背景色或表示无值的值。可以使用一个 int 或 Color 来表示一个 RGB 或 RGBA 值。 输入的数据集为24位或32位影像数据集时才支持使用 Color 类型的 RGB 或 RGB 值。
- back_or_no_value_tolerance (float or Color) -- 栅格背景色的容限或无值的容限。可以使用一个 int 或 Color 来表示一个 RGB 或 RGBA 值。 输入的数据集为24位或32位影像数据集时才支持使用 Color 类型的 RGB 或 RGB 值。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: Dataset or str
-
iobjectspy.analyst.build_lake(dem_grid, lake_data, elevation, progress=None)¶ 挖湖,即修改面数据集区域范围内的 DEM 数据集的高程值为指定的数值。 挖湖是指根据已有的湖泊面数据,在 DEM 数据集上显示湖泊信息。如下图所示,挖湖之后,DEM 在湖泊面数据对应位置的栅格值变成指定的高程值,且整个湖泊区域栅格值相同。

参数: - dem_grid (DatasetGrid or str) -- 指定的待挖湖的 DEM 栅格数据集。
- lake_data (DatasetVector or str) -- 指定的湖区域,为面数据集。
- elevation (str or float) -- 指定的湖区域的高程字段或指定的高程值。如果为 str,则要求字段类型为数值型。如果指定为 None 或空字符串,或湖区域数据集中不存在指定的 字段,则按照湖区域边界对应 DEM 栅格上的最小高程进行挖湖。高程值的单位与 DEM 栅格数据集的栅格值单位相同。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 成功返回 True,否则返回 False
返回类型: bool
-
iobjectspy.analyst.build_terrain(source_datas, lake_dataset=None, lake_altitude_field=None, clip_data=None, erase_data=None, interpolate_type='IDW', resample_len=0.0, z_factor=1.0, is_process_flat_area=False, encode_type='NONE', pixel_format='SINGLE', cell_size=0.0, out_data=None, out_dataset_name=None, progress=None)¶ 根据指定的地形构建参数信息创建地形。 DEM(Digital Elevation Model,数字高程模型)主要用于描述区域地貌形态的空间分布,是地面特性为高程和海拔高程的数字地面模型(DTM), 通常通过高程测量点(或从等高线中进行采样提取高程点)进行数据内插而成。此方法用于构建地形,即对具有高程信息的点或线数据集通过插值生成 DEM 栅格。

可以通过 source_datas 参数指定用于构建地形的数据集,支持仅高程点、仅等高线以及支持高程点和等高线共同构建。
参数: - source_datas (dict[DatasetVector,str] or dict[str,str]) -- 用于构建的点数据集和线数据集,以及数据集的高程字段。要求数据集的坐标系相同。
- lake_dataset (DatasetVector or str) -- 湖泊面数据集。在结果数据集中,湖泊面数据集区域范围内的高程值小于周边相邻的高程值。
- lake_altitude_field (str) -- 湖泊面数据集的高程字段
- clip_data (DatasetVector or str) --
设置用于裁剪的数据集。构建地形时,仅位于裁剪区域内的 DEM 结果被保留,区域外的部分被赋予无值。
- erase_data (DatasetVector or str) --
用于擦除的数据集。构建地形时,位于擦除区域内的结果 DEM 栅格值为无值。仅在 interpolate_type 设置为 TIN 时有效。
- interpolate_type (TerrainInterpolateType or str) -- 地形插值类型。默认值为 IDW。
- resample_len (float) -- 采样距离。只对线数据集有效。单位与用于构建地形的线数据集单位一致。仅在 interpolate_type 设置为TIN时有效。 首先对线数据集进行重采样过滤掉一些比较密集的节点,然后再生成 TIN 模型,提高生成速度。
- z_factor (float) -- 高程缩放系数
- is_process_flat_area (bool) -- 是否处理平坦区域。等值线生成DEM能较好地处理山顶山谷,点生成DEM也可以处理平坦区域,但效 果没有等值线生成DEM处理的好,主要原因是根据点判断平坦区域结果较为粗糙。
- encode_type (EncodeType or str) -- 编码方式。对于栅格数据集,目前支持的编码方式有未编码、SGL、LZW 三种方式
- pixel_format (PixelFormat or str) -- 结果数据集的像素格式
- cell_size (float) -- 结果数据集的栅格单元的大小,如果指定为 0 或负数,则系统会使用 L/500(L 是指源数据集的区域范围对应的矩形的对角线长度)作为单元格大小。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: Dataset or str
-
iobjectspy.analyst.area_solar_radiation_days(grid_data, latitude, start_day, end_day=160, hour_start=0, hour_end=24, day_interval=5, hour_interval=0.5, transmittance=0.5, z_factor=1.0, out_data=None, out_total_grid_name='TotalGrid', out_direct_grid_name=None, out_diffuse_grid_name=None, out_duration_grid_name=None, progress=None)¶ 计算多天的区域太阳辐射总量,即整个DEM范围内每个栅格的太阳辐射情况。需要指定每天的开始时点、结束时点和开始日期、结束日期。
参数: - grid_data (DatasetGrid or str) -- 待计算太阳辐射的DEM栅格数据
- latitude (float) -- 待计算区域的平均纬度
- start_day (datetime.date or str or int) -- 起始日期,可以是 "%Y-%m-%d" 格式的字符串,如果为 int,则表示一年中的第几天
- end_day (datetime.date or str or int) -- 终止日期,可以是 "%Y-%m-%d" 格式的字符串,如果为 int,则表示一年中的第几天
- hour_start (float or str or datetime.datetime) -- 起始时点,如果输入float 时,可以输入一个 [0,24]范围内的数值,表示一天中的第几个小时。也可以输入一个 datetime.datatime 或 "%H:%M:%S" 格式的字符串
- hour_end (float or str or datetime.datetime) -- 终止时点,如果输入float 时,可以输入一个 [0,24]范围内的数值,表示一天中的第几个小时。也可以输入一个 datetime.datatime 或 "%H:%M:%S" 格式的字符串
- day_interval (int) -- 天数间隔,单位为天
- hour_interval (float) -- 小时间隔,单位为小时。
- transmittance (float) -- 太阳辐射穿过大气的透射率,值域为[0,1]。
- z_factor (float) -- 高程缩放系数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_total_grid_name (str) -- 总辐射量结果数据集名称,数据集名称必须合法
- out_direct_grid_name (str) -- 直射辐射量结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- out_diffuse_grid_name (str) -- 散射辐射量结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- out_duration_grid_name (str) -- 太阳直射持续时间结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回一个四个元素的 tuple:
- 第一个为总辐射量结果数据集,
- 如果设置了直射辐射量结果数据集名称,第二个为直射辐射量结果数据集,否则为 None,
- 如果设置散射辐射量结果数据集的名称,第三个为散射辐射量结果数据集,否则为 None
- 如果设置太阳直射持续时间结果数据集的名称,第四个为太阳直射持续时间结果数据集,否则为 None
返回类型: tuple[DatasetGrid] or tuple[str]
-
iobjectspy.analyst.area_solar_radiation_hours(grid_data, latitude, day, hour_start=0, hour_end=24, hour_interval=0.5, transmittance=0.5, z_factor=1.0, out_data=None, out_total_grid_name='TotalGrid', out_direct_grid_name=None, out_diffuse_grid_name=None, out_duration_grid_name=None, progress=None)¶ 计算一天内的太阳辐射,需要指定开始时点、结束时点及开始日期作为要计算的日期
参数: - grid_data (DatasetGrid or str) -- 待计算太阳辐射的DEM栅格数据
- latitude (float) -- 待计算区域的平均纬度
- day (datetime.date or str or int) -- 待计算的指定日期。可以是 "%Y-%m-%d" 格式的字符串,如果为 int,则表示一年中的第几天。
- hour_start (float or str or datetime.datetime) -- 起始时点,如果输入float 时,可以输入一个 [0,24]范围内的数值,表示一天中的第几个小时。也可以输入一个 datetime.datatime 或 "%H:%M:%S" 格式的字符串
- hour_end (float or str or datetime.datetime) -- 终止时点,如果输入float 时,可以输入一个 [0,24]范围内的数值,表示一天中的第几个小时。也可以输入一个 datetime.datatime 或 "%H:%M:%S" 格式的字符串
- hour_interval (float) -- 小时间隔,单位为小时。
- transmittance (float) -- 太阳辐射穿过大气的透射率,值域为[0,1]。
- z_factor (float) -- 高程缩放系数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_total_grid_name (str) -- 总辐射量结果数据集名称,数据集名称必须合法
- out_direct_grid_name (str) -- 直射辐射量结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- out_diffuse_grid_name (str) -- 散射辐射量结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- out_duration_grid_name (str) -- 太阳直射持续时间结果数据集名称,数据集名称必须合法,且接口内不会自动获取有效的数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回一个四个元素的 tuple:
- 第一个为总辐射量结果数据集,
- 如果设置了直射辐射量结果数据集名称,第二个为直射辐射量结果数据集,否则为 None,
- 如果设置散射辐射量结果数据集的名称,第三个为散射辐射量结果数据集,否则为 None
- 如果设置太阳直射持续时间结果数据集的名称,第四个为太阳直射持续时间结果数据集,否则为 None
返回类型: tuple[DatasetGrid] or tuple[str]
-
iobjectspy.analyst.raster_mosaic(inputs, back_or_no_value, back_tolerance, join_method, join_pixel_format, cell_size, encode_type='NONE', valid_rect=None, out_data=None, out_dataset_name=None, progress=None)¶ 栅格数据集镶嵌。支持栅格数据集和影像数据集。
栅格数据的镶嵌是指将两个或两个以上栅格数据按照地理坐标组成一个栅格数据。有时由于待研究分析的区域很大,或者感兴趣的目标对象 分布很广,涉及到多个栅格数据集或者多幅影像,就需要进行镶嵌。下图展示了六幅相邻的栅格数据镶嵌为一幅数据。
进行栅格数据镶嵌时,需要注意以下要点:
待镶嵌栅格必须具有相同的坐标系 镶嵌要求所有栅格数据集或影像数据集具有相同的坐标系,否则镶嵌结果可能出错。可以在镶嵌前通过投影转换统一所有带镶嵌栅格的 坐标系。
重叠区域的处理 镶嵌时,经常会出现两幅或多幅栅格数据之间有重叠区域的情况(如下图,两幅影像在红色框内的区域是重叠的),此时需要指定对重 叠区域栅格的取值方式。SuperMap 提供了五种重叠区域取值方式,使用者可根据实际需求选择适当的方式,详见
RasterJoinType类。
关于无值和背景色及其容限的说明 待镶嵌的栅格数据有两种:栅格数据集和影像数据集。对于栅格数据集,该方法可以指定无值及无值的容限,对于影像数据集,该方法 可以指定背景色及其容限。
待镶嵌数据为栅格数据集:
- 当待镶嵌的数据为栅格数据集时,栅格值为 back_or_no_value 参数所指定的值的单元格,以及在 back_tolerance 参数指定的容限范 围内的单元格被视为无值,这些单元格不会参与镶嵌时的计算(叠加区域的计算),而栅格的原无值单元格则不再是无值数据从而参与运算。
- 需要注意,无值的容限是用户指定的无值的值的容限,与栅格中原无值无关。
待镶嵌数据为影像数据集
- 当待镶嵌的数据为影像数据集时,栅格值为 back_or_no_value 参数所指定的值的单元格,以及在 back_tolerance 参数指定的容限 范围内单元格被视为背景色,这些单元格不参与镶嵌时的计算。例如,指定无值的值为 a,指定的无值的容限为 b,则栅格值在 [a-b,a+b] 范围内的单元格均不参与计算。
- 注意,影像数据集中栅格值代表的是一个颜色。影像数据集的栅格值对应为 RGB 颜色,因此,如果想要将某种颜色设为背景色, 为 back_or_no_value 参数指定的值应为将该颜色(RGB 值)转为 32 位整型之后的值,系统内部会根据像素格式再进行相应的转换。
- 对于背景色的容限值的设置,与背景色的值的指定方式相同:该容限值为一个 32 位整型值,在系统内部被转换为对应背景色 R、G、B 的三个容限值,例如,指定为背景色的颜色为 (100,200,60),指定的容限值为 329738,该值对应的 RGB 值为 (10,8,5),则值在 (90,192,55) 和 (110,208,65) 之间的颜色均被视为背景色,不参与计算。
注意:
将两个或以上高像素格式的栅格镶嵌成低像素格式的栅格时,结果栅格值可能超出值域,导致错误,因此不建议进行此种操作。
参数: - inputs (list[DatasetGrid] or list[DatasetImage] list[str] or str) -- 指定的待镶嵌的数据集的集合。
- back_or_no_value (float or tuple) -- 指定的栅格背景颜色或无值的值。可以使用一个 float 或 tuple 表示一个 RGB 或 RGBA 值
- back_tolerance (float or tuple) -- 指定的栅格背景颜色或无值的容限。可以使用一个 float 或 tuple 表示一个 RGB 或 RGBA 值
- join_method (RasterJoinType or str) -- 指定的镶嵌方法,即镶嵌时重叠区域的取值方式。
- join_pixel_format (RasterJoinPixelFormat or str) -- 指定的镶嵌结果栅格数据的像素格式。
- cell_size (float) -- 指定的镶嵌结果数据集的单元格大小。
- encode_type (EncodeType or str) -- 指定的镶嵌结果数据集的编码方式。
- valid_rect (Rectangle) -- 指定的镶嵌结果数据集的有效范围。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 指定的用于存储镶嵌结果数据集的数据源信息
- out_dataset_name (str) -- 指定的镶嵌结果数据集的名称。
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 镶嵌结果数据集
返回类型:
-
iobjectspy.analyst.zonal_statistics_on_raster_value(value_data, zonal_data, zonal_field, is_ignore_no_value=True, grid_stat_mode='SUM', out_data=None, out_dataset_name=None, out_table_name=None, progress=None)¶ 栅格分带统计,方法中值数据为栅格的数据集,带数据可以是矢量或栅格数据。
栅格分带统计,是以某种统计方法对区域内的单元格的值进行统计,将每个区域内的统计值赋给该区域所覆盖的所有单元格,从而得到结果栅格。栅格分带统计涉及两种数据,值数据和带数据。值数据即被统计的栅格数据,带数据为标识统计区域的数据,可以为栅格或矢量面数据。下图为使用栅格带数据进行分带统计的算法示意,其中灰色单元格代表无值数据。
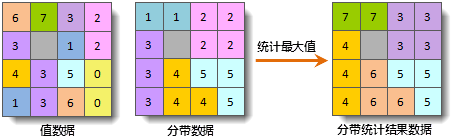
当带数据为栅格数据集时,连续的栅格值相同的单元格作为一个带(区域);当带数据为矢量面数据集时,要求其属性表中有一个标识带的字段,以数值来区分不同的带,如果两个及以上的面对象(可以相邻,也可以不相邻)的标识值相同,则进行分带统计时,它们将作为一个带进行统计,即在结果栅格中,这些面对象对应位置的栅格值都是这些面对象范围内的所有单元格的栅格值的统计值。
分带统计的结果包含两部分:一是分带统计结果栅格,每个带内的栅格值相同,即按照统计方法计算所得的值;二是一个记录了每个分带内统计信息的属性表,包含 ZONALID(带的标识)、PIXELCOUNT(带内单元格数)、MININUM(最小值)、MAXIMUM(最大值)、RANGE_VALUE(值域)、SUM_VALUE(和)、MEAN(平均值)、STD(标准差)、VARIETY(种类)、MAJORITY(众数)、MINORITY(少数)、MEDIAN(中位数)等字段。
下面通过一个实例来了解分带统计的应用。
- 如下图所示,左图是 DEM 栅格值,将其作为值数据,右图为对应区域的行政区划,将其作为带数据,进行分带统计;
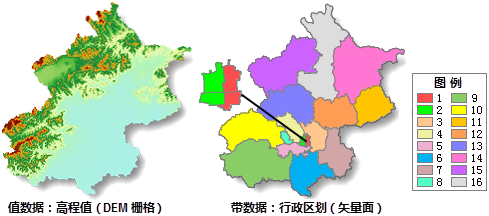
- 使用上面的数据,将最大值作为统计方法,进行分带统计。结果包括如下图所示的结果栅格,以及对应的统计信息属性表(略)。结果栅格中,每个带内的栅格值均相等,即在该带范围内的值栅格中最大的栅格值,也就是高程值。该例统计了该地区每个行政区内最高的高程。
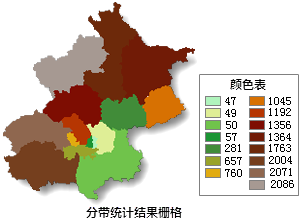
注意,分带统计的结果栅格的像素类型(PixelFormat)与指定的分带统计类型(通过 ZonalStatisticsAnalystParameter 类的 setStatisticsMode 方法设置)有关:
* 当统计类型为种类(VARIETY)时,结果栅格像素类型为 BIT32; * 当统计类型为最大值(MAX)、最小值(MIN)、值域(RANGE)时,结果栅格的像素类型与源栅格保持一致; * 当统计类型为平均值(MEAN)、标准差(STDEV)、总和(SUM)、众数(MAJORITY)、最少数(MINORITY)、中位数(MEDIAN)时,结果栅格的像素类型为 DOUBLE。
参数: - value_data (DatasetGrid or str) -- 需要被统计的值数据
- zonal_data (DatasetGrid or DatasetVector or str) -- 待统计的分带数据集。仅支持像素格式(PixelFormat)为 UBIT1、UBIT4、UBIT8 和 UBIT16 的栅格数据集或矢量面数据集。
- zonal_field (str) -- 矢量分带数据中用于标识带的字段。字段类型只支持32位整型。
- is_ignore_no_value (bool) -- 统计时是否忽略无值数据。 如果为 True,表示无值栅格不参与运算;若为 False,表示有无值参与的运算,结果仍为无值
- grid_stat_mode (GridStatisticsMode or str) -- 分带统计类型
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- out_table_name (str) -- 分析结果属性表的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回一个 tuple,tuple 有两个元素,第一个为结果数据集或名称,第二个为结果属性表数据集或名称
返回类型: tuple[DatasetGrid, DatasetGrid] or tuple[str,str]
-
iobjectspy.analyst.calculate_profile(input_data, line)¶ 剖面分析,根据给定线路查看 DEM 栅格沿该线路的剖面,返回剖面线和采样点坐标。 给定一条直线或者折线,查看 DEM 栅格沿此线的纵截面,称为剖面分析。剖面分析的结果包含两部分:剖面线和采样点集合。
- 采样点
剖面分析需要沿给定线路选取一些点,通过这些点所在位置的高程和坐标信息,来展现剖面效果,这些点称为采样点。采样点的选取依照以下规则, 可结合下图来了解。
- 给定路线途经的每个单元格内只选取一个采样点;
- 给定路线的节点都被作为采样点;
- 如果路线经过且节点不在该单元格内,则将线路与该单元格两条中心线中交角较大的一条的交点作为采样点。
- 剖面线和采样点坐标集合
剖面线是剖面分析的结果之一,是一条二维线(
GeoLine),它的节点与采样点一一对应,节点的 X 值表示当前采样点到给定线 路的起点(也是第一个采样点)的直线距离,Y 值为当前采样点所在位置的高程。而采样点集合给出了所有采样点的位置,使用一个二维集合线对 象来存储这些点。剖面线与采样点集合的点是一一对应的,结合剖面线和采样点集合可以知道在某位置的高程以及距离分析的起点的距离。下图展示了以剖面线的 X 值为横轴,Y 值为纵轴绘制二维坐标系下的剖面线示意图,通过剖面线可以直观的了解沿着给定的线路,地形的高程和地势。
注意:指定的线路必须在 DEM 栅格的数据集范围内,否则可能分析失败。如果采样点位于无值栅格上,则剖面线上对应的点的高程为0。
参数: - input_data (DatasetGrid or str) -- 指定的待进行剖面分析的 DEM 栅格。
- line (GeoLine) -- 指定的线路,为一条线段或折线。剖面分析给出沿该线路的剖面。
返回: 剖面分析结果,剖面线和采样点集合。
返回类型:
-
class
iobjectspy.analyst.CutFillResult(cut_area, cut_volume, fill_area, fill_volume, remainder_area, cut_fill_grid_result)¶ 基类:
object填挖方结果信息类。该对象用于获取对栅格数据集进行填方和挖方计算的结果,例如需要填方、挖方的面积、填方和挖方的体积数等。
关于填挖方结果面积和体积单位的说明:
填挖的面积单位为平方米,体积的单位为平方米乘以高程(即进行填挖的栅格值)的单位。但需注意,如果进行填挖方计算的栅格是地理坐标系,面积的值是一个近似转换到平方米单位的值。
内部构造函数,用户不需要使用
参数: - cut_area (float) -- 填挖方分析结果挖掘面积。单位为平方米。当进行填挖方的栅格为地理坐标系时,该值为近似转换
- cut_volume (float) -- 填挖方分析结果挖掘体积。单位为平方米乘以填挖栅格的栅格值(即高程值)的单位
- fill_area (float) -- 填挖方分析结果填充面积。单位为平方米。当进行填挖方的栅格为地理坐标系时,该值为近似转换。
- fill_volume (float) -- 填挖方分析结果填充体积。单位为平方米乘以填挖栅格的栅格值(即高程值)的单位。
- remainder_area (float) -- 填挖方分析中未进行填挖方的面积。单位为平方米。当进行填挖方的栅格为地理坐标系时,该值为近似转换。
- cut_fill_grid_result (DatasetGrid or str) -- 填挖方分析的结果数据集。 单元格值大于0表示要挖的深度,小于0表要填的深度。
-
iobjectspy.analyst.inverse_cut_fill(input_data, volume, is_fill, region=None, progress=None)¶ 反算填挖方,即根据给定的填方或挖方的体积计算填挖后的高程 反算填挖方用于解决这样一类实际问题:已知填挖前的栅格数据和该数据范围内要填或挖的体积,来推求填方或挖方后的高程值。例如,某建筑施 工地的一片区域需要填方,现得知某地可提供体积为 V 的土方,此时使用反算填挖方就可以计算出将这批土填到施工区域后,施工区域的高程是 多少。然后可判断是否达到施工需求,是否需要继续填方。
参数: - input_data (DatasetGrid or str) -- 指定的待填挖的栅格数据。
- volume (float) -- 指定的填或挖的体积。该值为一个大于0的值,如果设置为小于或等于0会抛出异常。单位为平方米乘以待填挖栅格的栅格值单位。
- is_fill (bool) -- 指定是否进行填方计算。如果为 true 表示进行填方计算,false 表示进行挖方计算。
- region (GeoRegion or Rectangle) -- 指定的填挖方区域。如果为 None 则填挖计算应用于整个栅格区域。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 填挖后的高程值。单位与待填挖栅格的栅格值单位一致。
返回类型: float
-
iobjectspy.analyst.cut_fill_grid(before_cut_fill_grid, after_cut_full_grid, out_data=None, out_dataset_name=None, progress=None)¶ 栅格填挖方计算,即对填挖方前、后两个栅格数据集对应像元的计算。 地表经常由于沉积和侵蚀等作用引起表面物质的迁移,表现为地表某些区域的表面物质增加,某些区域的表面物质减少。在工程中,通常将表面物质的减少称为“挖方”,而将表面物质的增加称为“填方”。
栅格填挖方计算要求输入两个栅格数据集:填挖方前的栅格数据集和填挖方后的栅格数据集,生成的结果数据集的每个像元值为其两个输入数据集对应像元值的变化值。如果像元值为正,表示该像元处的表面物质减少;如果像元值为负,表示该像元处的表面物质增加。填挖方的计算方法如下图所示:
通过该图可以发现,结果数据集=填挖方前栅格数据集-填挖方后栅格数据集。
对于输入的两个栅格数据集及结果数据集有几点内容需要注意:
- 要求两个输入的栅格数据集有相同的坐标和投影系统,以保证同一个地点有相同的坐标,如果两个输入的栅格数据集的坐标系统不一致,则很有可能产生错误的结果。
- 理论上,要求输入的两个栅格数据集的空间范围也是一致的。对于空间范围不一致的两个栅格数据集,只计算其重叠区域的表面填挖方的结果。
- 在其中一个栅格数据集的像元为空值处,计算结果数据集该像元值也为空值。
参数: - before_cut_fill_grid (DatasetGrid or str) -- 指定的填挖方前的栅格数据集
- after_cut_full_grid (DatasetGrid or str) -- 指定的填挖方后的栅格数据集。
- out_data (Datasource or str) -- 指定的存放结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 填挖方结果信息
返回类型:
-
iobjectspy.analyst.cut_fill_oblique(input_data, line3d, buffer_radius, is_round_head, out_data=None, out_dataset_name=None, progress=None)¶ 斜面填挖方计算。 斜面填挖方功能是统计在一个地形表面创建一个斜面所需要的填挖量。其原理与选面填挖方相似。
参数: - input_data (DatasetGrid or str) -- 指定的待填挖方的栅格数据集。
- line3d (GeoLine3D) -- 指定的填挖方路线
- buffer_radius (float) -- 指定的填挖方线路的缓冲区半径。单位与待填挖的栅格数据集的坐标系单位相同。
- is_round_head (bool) -- 指定是否使用圆头缓冲为填挖方路线创建缓冲区。
- out_data (Datasource or str) -- 指定的存放结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 填挖方结果信息
返回类型:
-
iobjectspy.analyst.cut_fill_region(input_data, region, base_altitude, out_data=None, out_dataset_name=None, progress=None)¶ 选面填挖方计算。 当需要将一个高低起伏的区域夷为平地时,用户可以通过指定高低起伏的区域以及夷为平地的高程,利用该方法进行选面填挖方计算,计算出填方 面积,挖方面积、 填方量以及挖方量。
参数: - input_data (DatasetGrid or str) -- 指定的待填挖的栅格数据集。
- region (GeoRegion or Rectangle) -- 指定的填挖方区域。
- base_altitude (float) -- 指定的填挖方区域的结果高程。单位与待填挖的栅格数据集的栅格值单位相同。
- out_data (Datasource or str) -- 指定的存放结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 填挖方结果信息
返回类型:
-
iobjectspy.analyst.cut_fill_region3d(input_data, region, out_data=None, out_dataset_name=None, progress=None)¶ 三维面填挖方计算。 一个高低起伏的区域,可以根据这个区域填挖方后的三维面,利用三维面填挖方计算出需要填方的面积,挖方的面积、填方量以及挖方量。
参数: - input_data (DatasetGrid or str) -- 指定的待填挖的栅格数据集。
- region (GeoRegion3D) -- 指定的填挖方区域。
- out_data (Datasource or str) -- 指定的存放结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 填挖方结果信息
返回类型:
-
iobjectspy.analyst.flood(input_data, height, region=None, progress=None)¶ 根据指定的高程计算 DEM 栅格的淹没区域。 淹没区域的计算基于 DEM 栅格数据,根据给定的一个淹没后的水位高程(由参数 height 指定),与 DEM 栅格的值(即高程值)进行比较,凡是高程值低于或等于给定水位的单元格均被划入淹没区域,然后将淹没区域转为矢量面输出,源 DEM 数据并不会被改变。通过淹没区域面对象,很容易统计出被淹没的范围、面积等。 下图是计算水位达到 200 时的淹没区域的一个实例,由原始 DEM 数据和淹没区域的矢量面数据集(紫色区域)叠加而成
注意:该方法返回的面对象是将所有淹没区域进行合并后的结果。
参数: - input_data (DatasetGrid or str) -- 指定的需要计算淹没区域的 DEM 数据。
- height (float) -- 指定的淹没后水位的高程值,DEM 数据中小于或等于该值的单元格会划入淹没区域。单位与待分析的 DEM 栅格的栅格值单位相同。
- region (GeoRegion or Rectangle) -- 指定的有效计算区域。指定该区域后,只在该区域内计算淹没区域。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 将所有淹没区域合并后的面对象
返回类型:
-
iobjectspy.analyst.thin_raster_bit(input_data, back_or_no_value, is_save_as_grid=True, out_data=None, out_dataset_name=None, progress=None)¶ 通过减少要素宽度的像元来对栅格化的线状要素进行细化,该方法是处理二值图像的细化方法,如果不是二值图像会先处理为二值图像,只需指定背景色的值,背景色以外的值都是需要细化的值。该方法的效率最快。
参数: - input_data (DatasetImage or DatasetGrid or str) -- 指定的待细化的栅格数据集。支持影像数据集。
- back_or_no_value (int or tuple) -- 指定栅格的背景色或表示无值的值。可以使用一个 int 或 tuple 来表示一个 RGB 或 RGBA 值。
- is_save_as_grid (bool) -- 是否保存为栅格数据集,Ture 表示保存为栅格数据集,False保存为原数据类型(栅格或影像)。保存为栅格数据集便于栅格矢量化时指定值矢量化,方便快速获取线数据。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: Dataset or str
-
class
iobjectspy.analyst.ViewShedType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了对多个观察点(被观察点)进行可视域分析时,可视域的类型常量。 :var ViewShedType.VIEWSHEDINTERSECT: 共同可视域,取多个观察点可视域范围的交集。 :var ViewShedType.VIEWSHEDUNION: 非共同可视域,取多个观察点可视域范围的并集。
-
VIEWSHEDINTERSECT= 0¶
-
VIEWSHEDUNION= 1¶
-
-
iobjectspy.analyst.NDVI(input_data, nir_index, red_index, out_data=None, out_dataset_name=None)¶ 归一化植被指数,也叫做归一化差分植被指数或者标准差异植被指数或生物量指标变化。可使植被从水和土中分离出来。
参数: - input_data (DatasetImage or str) -- 多波段影像数据集。
- nir_index (int) -- 近红外波段的索引
- red_index (int) -- 红波段的索引
- out_data (Datasource or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果数据集,用于保存NDVI值。NDVI值的范围在-1到1之间。
返回类型: DatasetGrid or str
-
iobjectspy.analyst.NDWI(input_data, nir_index, green_index, out_data=None, out_dataset_name=None)¶ 归一化水指数。NDWI一般用来提取影像中的水体信息,效果较好.
参数: - input_data (DatasetImage or str) -- 多波段影像数据集。
- nir_index (int) -- 近红外波段的索引
- green_index (int) -- 绿波段的索引
- out_data (Datasource or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果数据集,用于保存NDWI值。
返回类型: DatasetGrid or str
-
iobjectspy.analyst.compute_features_envelope(input_data, is_single_part=True, out_data=None, out_dataset_name=None, progress=None)¶ 计算几何对象的矩形范围面
参数: - input_data (DatasetVector or str) -- 待分析的数据集,仅支持线数据集和面数据集。
- is_single_part (bool) -- 有组合线或者组合面时,是否拆分子对象。默认为 True,拆分子对象。
- out_data (Datasource or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果数据集,返回每个对象的范围面。结果数据集中新增了字段"ORIG_FID"用于保存输入对象的ID值。
返回类型: DatasetVector or str
-
iobjectspy.analyst.calculate_view_shed(input_data, view_point, start_angle, view_angle, view_radius, out_data=None, out_dataset_name=None, progress=None)¶ 单点可视域分析,即分析单个观察点的可视范围。 单点可视域分析是在栅格表面数据集上,对于给定的一个观察点,查找其在给定的范围内(由观察半径、观察角度决定)所能观察到的区域,也就是给定点的通视区域范围。分析的结果为一个栅格数据集,其中可视区域保持原始栅格表面的栅格值,其他区域为无值。
如下图所示,图中绿色的点为观察点,叠加在原始栅格表面上的蓝色区域即为对其进行可视域分析的结果。
注意:如果指定的观察点的高程小于当前栅格表面对应位置的高程值,则观察点的高程值将被自动设置为当前栅格表面的对应位置的高程。
参数: - input_data (DatasetGrid or str) -- 指定的用于可视域分析的栅格表面数据集。
- view_point (Point3D) -- 指定的观察点位置。
- start_angle (float) -- 指定的起始观察角度,单位为度,以正北方向为 0 度,顺时针方向旋转。指定为负值或大于 360 度,将自动换算到 0 到 360 度范围内。
- view_angle (float) -- 指定的观察角度,单位为度,最大值为 360 度。观察角度基于起始角度,即观察角度范围为 [起始角度,起始角度+观察角度]。例如起始角度为 90 度,观察角度为 90 度,那么实际观察的角度范围是从 90 度到 180 度。但注意,当指定为 0 或负值时,无论起始角度为何值,观察角度范围都为 0 到 360 度
- view_radius (float) -- 指定的观察半径。该值限制了视野范围的大小,若观测半径小于等于 0 时,表示无限制。单位为米
- out_data (Datasource or str) -- 指定的用于存储结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 单点可视域分析结果数据集
返回类型: DatasetGrid or str
-
iobjectspy.analyst.calculate_view_sheds(input_data, view_points, start_angles, view_angles, view_radiuses, view_shed_type, out_data=None, out_dataset_name=None, progress=None)¶ 多点可视域分析,即分析多个观察点的可视范围,可以为共同可视域或非共同可视域。 多点可视域分析,是根据栅格表面,对给定的观察点集合中每一个观察点进行可视域分析,然后根据指定的可视域类型,计算所有观察点的可视域的交集(称为“共同可视域”)或者并集(称为“非共同可视域”),并将结果输出到一个栅格数据集中,其中可视区域保持原始栅格表面的栅格值,其他区域为无值。
如下图所示,图中绿色的点为观察点,叠加在原始栅格表面上的蓝色区域即为对其进行可视域分析的结果。左图展示了三个观察点的共同可视域,右图则是三个观察点的非共同可视域。
注意:如果指定的观察点的高程小于当前栅格表面对应位置的高程值,则观察点的高程值将被自动设置为当前栅格表面的对应位置的高程。
参数: - input_data (DatasetGrid or str) -- 指定的用于可视域分析的栅格表面数据集。
- view_points (list[Point3D]) -- 指定的观察点集合。
- start_angles (list[float]) -- 指定的起始观察角度集合,与观察点一一对应。单位为度,以正北方向为 0 度,顺时针方向旋转。指定为负值或大于 360 度,将自动换算到 0 到 360 度范围内。
- view_angles -- 指定的观察角度集合,与观察点和起始观察角度一一对应,单位为度,最大值为 360 度。观察角度基于起始角度,即观察角度范围为 [起始角度,起始角度+观察角度]。例如起始角度为 90 度,观察角度为 90 度,那么实际观察的角度范围是从 90 度到 180 度。 :type view_angles: list[float]
- view_radiuses (list[float]) -- 指定的观察半径集合,与观察点一一对应。该值限制了视野范围的大小,若观测半径小于等于 0 时,表示无限制。单位为米。
- view_shed_type (ViewShedType or str) -- 指定的可视域的类型,可以是多个观察点的可视域的交集,也可以是多个观察点可视域的并集。
- out_data (Datasource or str) -- 指定的用于存储结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 多点可视域分析结果数据集。
返回类型:
-
class
iobjectspy.analyst.VisibleResult(java_object)¶ 基类:
object可视性分析结果类。
该类给出了观察点与被观察点之间可视分析的结果,如果不可视的话,还会给出障碍点的相关信息。
-
barrier_alter_height¶ float -- 障碍点建议修改的最大高度值。若将障碍点所在栅格表面的单元格的栅格值(即高程)修改为小于或等于该值,则该点不再阻碍 视线,但注意,并不表示该点之后不存在其他障碍点。可通过 DatasetGrid 类的 set_value() 方法修改栅格值
-
barrier_point¶ Point3D -- 障碍点的坐标值。如果观察点与被观察点之间不可视,则该方法的返回值为观察点与被观察点之间的第一个障碍点。如果观察 点与被观察点之间可视时,障碍点坐标取默认值。
-
from_point_index¶ int -- 观察点的索引值。如果是两点之间进行可视性分析,则观察点的索引值为 0。
-
to_point_index¶ int -- 被观察点的索引值。如果是两点之间进行可视性分析,则被观察点的索引值为 0。
-
visible¶ bool -- 观察点与被观察点对之间是否可视
-
-
iobjectspy.analyst.is_point_visible(input_data, from_point, to_point)¶ 两点可视性分析,即判断两点之间是否相互可见。 基于栅格表面,判断给定的观察点与被观察点之间是否可见,称为两点间可视性分析。两点间可视性分析的结果有两种:可视与不可视。该方法返 回一个 VisibleResult 对象,该对象用于返回两点间可视性分析的结果,即两点是否可视,如果不可视,会返回第一个阻碍视线的障碍点,还会 给出该障碍点的建议高程值以使该点不再阻碍视线。
参数: - input_data (DatasetGrid or str) -- 指定的用于可视性分析的栅格表面数据集。
- from_point (Point3D) -- 指定的用于可视性分析的起始点,即观察点
- to_point (Point3D) -- 指定的用于可视性分析的终止点,即被观察点。
返回: 可视性分析的结果
返回类型:
-
iobjectspy.analyst.are_points_visible(input_data, from_points, to_points)¶ 多点可视性分析,即判断多点之间是否可两两通视。 多点可视性分析,是根据栅格表面,计算观察点与被观察点之间是否两两通视。两点间可视性分析请参阅另一重载方法 isVisible 方法的介绍。
如果有 m 个观测点和 n 个被观测点,将有 m * n 种观测组合。分析的结果通过一个 VisibleResult 对象数组返回,每个 VisibleResult 对象包括对应的两点是否可视,如果不可视,会给出第一个障碍点,以及该点的建议高程值以使该点不再阻碍视线。
注意:如果指定的观察点的高程小于当前栅格表面对应位置的高程值,则观察点的高程值将被自动设置为当前栅格表面的对应位置的高程。
参数: - input_data (DatasetGrid or str) -- 指定的用于可视性分析的栅格表面数据集。
- from_points (list[Point3D]) -- 指定的用于可视性分析的起始点,即观察点
- to_points (list[Point3D]) -- 指定的用于可视性分析的终止点,即被观察点。
返回: 可视性分析的结果
返回类型: list[VisibleResult]
-
iobjectspy.analyst.line_of_sight(input_data, from_point, to_point)¶ 计算两点间的通视线,即根据地形计算观察点到目标点的视线上的可视部分和不可视部分。 依据地形的起伏,计算从观察点看向目标点的视线上哪些段可视或不可视,称为计算两点间的通视线。观察点与目标点间的这条线称为通视线。 通视线可以帮助了解在给定点能够看到哪些位置,可服务于旅游线路规划、雷达站或信号发射站的选址,以及布设阵地、观察哨所设置等军事活动。
观察点和目标点的高程由其 Z 值确定。当观察点或目标点的 Z 值小于栅格表面上对应单元格的高程值时,则使用该单元格的栅格值作为观察点或 目标点的高程来计算通视线。
- 计算两点间通视线的结果为一个二维线对象数组,该数组的第 0 个元素为可视线对象,第 1 个元素为不可视线对象。该数组的长度可能为 1 或
- 2,这是因为不可视线对象有可能不存在,此时结果数组只包含一个对象,即可视线对象。由于可视线(或不可视线)可能不连续,因此可视线或 不可视线对象有可能是复杂线对象。
参数: - input_data (DatasetGrid or str) -- 指定的栅格表面数据集。
- from_point (Point3D) -- 指定的观察点,是一个三维点对象。
- to_point (Point3D) -- 指定的目标点,是一个三维点对象。
返回: 结果通视线,是一个二维线数组
返回类型: list[GeoLine]
-
iobjectspy.analyst.radar_shield_angle(input_data, view_point, start_angle, end_angle, view_radius, interval, out_data=None, out_dataset_name=None, progress=None)¶ 根据地形图和雷达中心点,返回各方位上最大的雷达遮蔽角的点数据集。方位角是顺时针与正北方向的夹角。
参数: - input_data (DatasetGrid or str or list[DatasetGrid] or list[str]) -- 删格数据集或DEM
- view_point (Point3D) -- 三维点对象,表示雷达中心点的坐标和雷达中心与地面的高度。
- start_angle (float) -- 雷达方位起始角度,单位为度,以正北方向为 0 度,顺时针方向旋转。范围为0到360度。如果设置为小于0,默认值 为0;如果该值大于360,默认为360。
- end_angle (float) -- 雷达方位终止角度,单位为度,最大值为 360 度。观察角度基于起始角度,即观察角度范围为 [起始角度,终止角度)。 该值必须大于起始角度。如果该值小于等于0,表示[0,360)。
- view_radius (float) -- 观察范围,单位为米。如果设置为小于0,表示整个地形图范围。
- interval (float) -- 方位角的间隔,即每隔多少度返回一个雷达遮蔽点。该值必须大于0且小于360。
- out_data (Datasource or str) -- 目标数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (funtion) -- 进度信息,具体参考
StepEvent
返回: 返回的三维点数据集,Z代表该点所在位置的地形高度。该数据集记录了每个方位上雷达遮蔽角最大的点,并增加了字段"ShieldAngle"、 "ShieldPosition"和"RadarDistance"分别记录了雷达遮蔽角、该点与正北方向的夹角和点与雷达中心的距离。
返回类型: DatasetVector or str
-
iobjectspy.analyst.majority_filter(source_grid, neighbour_number_method, majority_definition, out_data=None, out_dataset_name=None, progress=None)¶ 众数滤波,返回结果栅格数据集。 根据相邻像元值的众数替换栅格像元值。众数滤波工具必须满足两个条件才能执行替换。具有相同值的相邻像元数必须足够多(达到所有像元的半 数及以上),并且这些像元在滤波器内核周围必须是连续的。第二个条件与像元的空间连通性有关,目的是将像元的空间模式的破坏程度降到最低。
特殊情况:
- 角像元:4邻域情况下相邻像元2个,8邻域情况下相邻像元3个,此时必须连续两个及以上相同值才能发生替换;
- 边像元:4邻域情况下相邻像元3个,此时必须连续2个及以上相同值才能替换;8邻域情况下相邻像元5个,此时必须3个及以上并且至少一个像 元在边上才能发生替换。
- 半数相等:有两种值都为半数时其中一种和该像元相同时不替换,不同时随意替换。
下图为众数滤波的示意图。
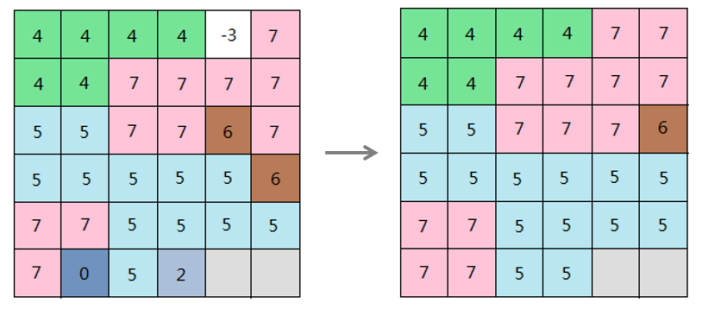
参数: - source_grid (DatasetGrid or str) -- 指定的待处理的数据集。输入栅格必须为整型。
- neighbour_number_method (str or NeighbourNumber) -- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选 择方法。
- majority_definition (str or MajorityDefinition) -- 众数定义,即在进行替换之前指定必须具有相同值的相邻(空间连接)像元数,具体参考
MajorityDefinition. - out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集
返回类型:
-
iobjectspy.analyst.expand(source_grid, neighbour_number_method, cell_number, zone_values, out_data=None, out_dataset_name=None, progress=None)¶ 扩展,返回结果栅格数据集。 按指定的像元数目展开指定的栅格区域。将指定的区域值视为前景区域,其余的区域值视为背景区域。通过此方法可使前景区域扩展到背景区域。 无值像元将始终被视为背景像元,因此任何值的相邻像元都可以扩展到无值像元,无值像元不会扩展到相邻像元。
注意:
- 只有一种类型区域值时,则扩展该值;
- 多种类型区域值时,首先扩展距离最近的;
- 距离相等的情况下,计算每个区域值的贡献值,扩展总贡献值最大的值(4邻域法和8邻域法的贡献值计算方式不同);
- 距离和贡献值相等,则扩展像元值最小的。
下图为扩展的示意图:
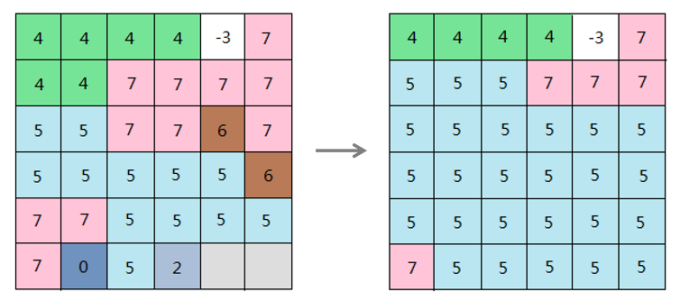
参数: - source_grid (DatasetGrid or str) -- 指定的待处理的数据集。输入栅格必须为整型。
- neighbour_number_method (NeighbourNumber or str) -- 邻域像元数,在这里指用于扩展所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像 元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种扩展方法。
- cell_number (int) -- 概化量。每个指定区域要扩展的像元数,类似于指定运行次数,其中上一次运行的结果是后续迭代的输入,该值必须为大 于1的整数。
- zone_values (list[int]) -- 区域值。要进行扩展的像元区域值。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果栅格数据集
返回类型:
-
iobjectspy.analyst.shrink(source_grid, neighbour_number_method, cell_number, zone_values, out_data=None, out_dataset_name=None, progress=None)¶ 收缩,返回结果栅格数据集。 按指定的像元数目收缩所选区域,方法是用邻域中出现最频繁的像元值替换该区域的值。将指定的区域值视为前景区域,其余的区域值视为背景区 域。通过此方法可用背景区域中的像元来替换前景区域中的像元。
注意:
- 收缩有多个值时,取出现最频繁的,如果多个值个数相同则取随机值;
- 两个相邻区域都是要收缩的像元,则在边界上没有任何变化;
- 无值为有效值,即与无值数据相邻的像元有可能被替换为无值。
下图为收缩的示意图:
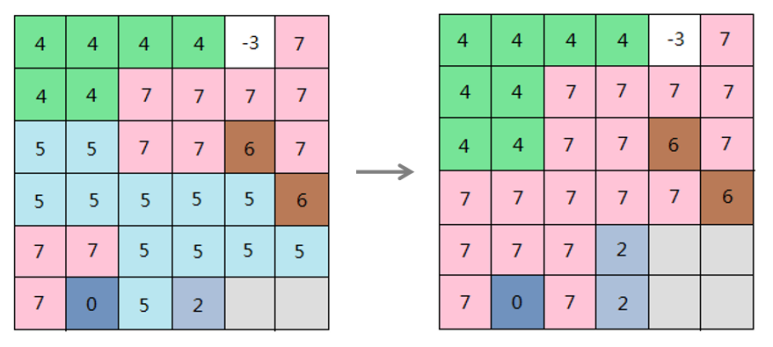
参数: - source_grid (DatasetGrid or str) -- 指定的待处理的数据集。输入栅格必须为整型。
- neighbour_number_method (NeighbourNumber or str) -- 邻域像元数,在这里指用于收缩所选区域的方法。有基于距离的方法,即上下左右4个像元作为邻近像 元(FOUR),和基于数学形态学的方法,即相邻8个像元作为邻近像元(EIGHT)两种收缩方法。
- cell_number (int) -- 概化量。要收缩的像元数,类似于指定运行次数,其中上一次运行的结果是后续迭代的输入,该值必须为大于0的整数。
- zone_values (list[int]) -- 区域值。要进行收缩的像元区域值。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果栅格数据集
返回类型:
-
iobjectspy.analyst.nibble(source_grid, mask_grid, zone_grid, is_mask_no_value, is_nibble_no_value, out_data=None, out_dataset_name=None, progress=None)¶ 蚕食,返回结果栅格数据集。
用最邻近点的值替换掩膜范围内的栅格像元值。蚕食可将最近邻域的值分配给栅格中的所选区域,可用于编辑某栅格中已知数据存在错误的区域。
一般来说掩膜栅格中值为无值的像元定义哪些像元被蚕食。输入栅格中任何不在掩膜范围内的位置均不会被蚕食。
下图为蚕食的示意图:
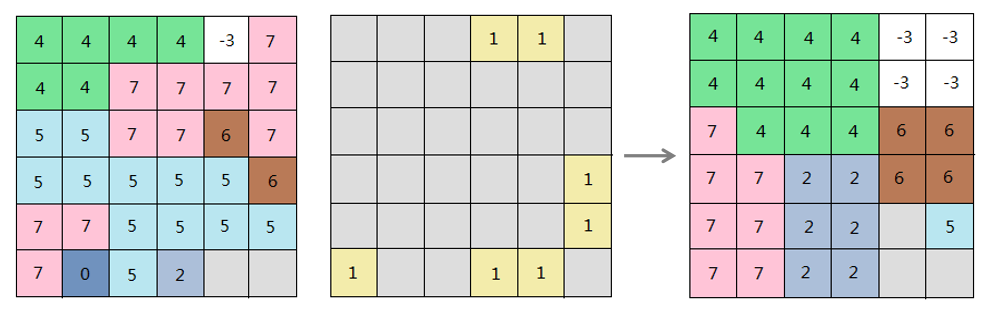
参数: - source_grid (DatasetGrid or str) -- 指定的待处理的数据集。输入栅格可以为整型,也可以为浮点型。
- mask_grid (DatasetGrid or str) -- 指定的作为掩膜的栅格数据集。
- zone_grid (DatasetGrid or str) -- 区域栅格。如果有区域栅格,掩膜内的像元只会被区域栅格中同一区域的最近像元(非掩膜的值)替换。区域是指栅格中具 有相同值
- is_mask_no_value (bool) -- 是否选择掩膜中无值像元被蚕食。True 表示选择无值像元被蚕食,即把掩膜中为无值的对应原栅格值替换为 最邻近区域的值,有值像元在原栅格中保持不变;False 表示选择有值像元被蚕食,即把掩膜中为有值的对应 原栅格值替换为最邻近区域的值,无值像元在原栅格中保持不变。一般使用第一种情况较多。
- is_nibble_no_value (bool) -- 是否修改原栅格中的无值数据。True表示输入栅格中的无值像元在输出中仍为无值;False表示输入栅格。 中处于掩膜内的无值像元可以被蚕食为有效的输出像元值
- out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回类型:
-
iobjectspy.analyst.region_group(source_grid, neighbour_number_method, is_save_link_value, is_link_by_neighbour=False, exclude_value=None, out_data=None, out_dataset_name=None, progress=None)¶ 区域分组。 记录输出中每个像元所属的连接区域的标识,系统为每个区域分配唯一编号,简单来说就是将连通的具有相同值的像元组成一个区域并编号。扫描 的第一个区域赋值为1,第二个区域赋值为2,依此类推,直到所有的区域均已赋值。扫描将按从左至右、从上至下的顺序进行。
下图为区域分组的示意图:
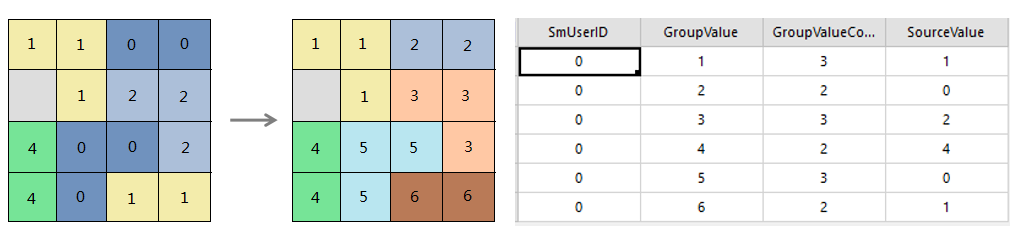
参数: - source_grid (DatasetGird or str) -- 指定的待处理的数据集。输入栅格必须为整型。
- neighbour_number_method (str or NeighbourNumber) -- 邻域像元数。有上下左右4个像元作为邻近像元(FOUR),和相邻8个像元作为邻近像元(EIGHT)两种选择方法。
- is_save_link_value (bool) -- 是否保留对应的栅格原始值。设置为true,属性表增加SourceValue项,连接输入栅格的每个像元的原始 值;如果不再需要每个区域的原始值,可以设置为false,会加速处理过程。
- is_link_by_neighbour (bool) -- 是否根据邻域连通。设置为true时,根据4邻域或8邻域法连通像元构成区域;设置为false时,必须设 置排除值excludedValue,此时除了排除值的连通区域都可以构成一个区域
- exclude_value (int) -- 排除值。排除的栅格值不参与计数,在输出栅格上,包含排除值的像元位置赋值为0。如果设置了排除值,结果属 性表中就没有连接信息。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源
- out_dataset_name (str) -- 指定的结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果栅格数据集和属性表
返回类型: tuple[DatasetGrid, DatasetVector]
-
iobjectspy.analyst.boundary_clean(source_grid, sort_type, is_run_two_times, out_data=None, out_dataset_name=None, progress=None)¶ 边界清理,返回结果栅格数据集。 通过扩展和收缩来平滑区域间的边界。将更改x和y方向上所有少于三个像元的区域。
下图为边界清理的示意图:
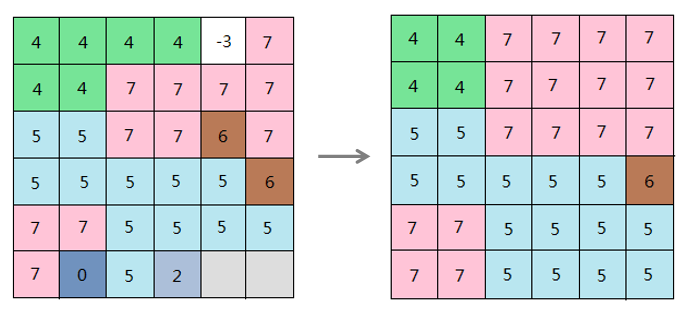
参数: - source_grid (DatasetGrid or str) -- 指定的待处理的数据集。输入栅格必须为整型。
- sort_type (BoundaryCleanSortType or str) -- 排序方法。指定要在平滑处理中使用的排序类型。包括NOSORT、DESCEND、ASCEND三种方法。
- is_run_two_times (bool) -- 发生平滑处理过程的次数是否为两次。True表示执行两次扩展-收缩过程,根据排序类型执行扩展和收缩,然后使 用相反的优先级多执行一次收缩和扩展;False表示根据排序类型执行一次扩展和收缩。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 指定的存储结果数据集的数据源。
- out_dataset_name (str) -- 结果数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果栅格数据集
返回类型:
-
class
iobjectspy.analyst.CellularAutomataParameter¶ 基类:
object元胞自动机参数设置类。包括设置起始栅格和空间变量栅格数据,及模拟过程的显示与输出配置(模拟结果迭代刷新、模拟结果输出)等
-
cell_grid¶ DatasetGrid -- 起始数据栅格
-
flush_file_path¶ str -- 用于界面刷新的文件路径
-
flush_frequency¶ int -- 迭代结果刷新频率
-
is_save¶ bool -- 是否保存中间迭代结果
-
iterations¶ int -- 迭代次数
-
output_dataset_name¶ str
-
output_datasource¶ Datasource -- 中间迭代结果保存数据源。
-
save_frequency¶ int -- 中间迭代结果保存频率
-
set_cell_grid(cell_grid)¶ 设置起始数据栅格。
参数: cell_grid (DatasetGrid or str) -- 起始数据栅格 返回: self 返回类型: CellularAutomataParameter
-
set_flush_file_path(value)¶ 设置用于界面刷新的文件路径。后缀名必须为 '.tif'
参数: value (str) -- 用于界面刷新的文件路径 返回: self 返回类型: CellularAutomataParameter
-
set_flush_frequency(flush_frequency)¶ 设置迭代结果刷新频率。即每隔多少次迭代刷新一次输出信息和图表。
参数: flush_frequency (int) -- 迭代结果刷新频率 返回: self 返回类型: CellularAutomataParameter
-
set_iterations(value)¶ 设置迭代次数
参数: value (int) -- 迭代次数 返回: self 返回类型: CellularAutomataParameter
-
set_output_dataset_name(dataset_name)¶ 设置中间迭代结果保存数据集名称
参数: dataset_name (str) -- 中间迭代结果保存数据集名称 返回: self 返回类型: CellularAutomataParameter
-
set_output_datasource(datasource)¶ 设置中间迭代结果保存数据源。
参数: datasource (Datasource or str or DatasourceConnectionInfo) -- 中间迭代结果保存数据源。 返回: self 返回类型: CellularAutomataParameter
-
set_save(save)¶ 设置是否保存中间迭代结果。即模拟过程中是否输出结果。
参数: save (bool) -- 是否保存中间迭代结果 返回: self 返回类型: CellularAutomataParameter
-
set_save_frequency(save_frequency)¶ 设置中间迭代结果保存频率。即每隔多少次迭代输出一次结果。
参数: save_frequency (int) -- 中间迭代结果保存频率 返回: self 返回类型: CellularAutomataParameter
-
set_simulation_count(simulation_count)¶ 设置转换数目。模拟转换数目是模拟过程所需参数,是指两个不同时段之间的城市增加的个数。
参数: simulation_count (int) -- 转换数目 返回: self 返回类型: CellularAutomataParameter
-
set_spatial_variable_grids(spatial_variable_grids)¶ 设置空间变量数据栅格数组。
参数: spatial_variable_grids (DatasetGrid or list[DatasetGrid] or tuple[DatasetGrid]) -- 空间变量数据栅格数组 返回: self 返回类型: CellularAutomataParameter
-
simulation_count¶ int -- 转换数目
-
spatial_variable_grids¶ list[DatasetGrid] -- 空间变量数据栅格数组
-
-
class
iobjectspy.analyst.PCACellularAutomataParameter¶ 基类:
object基于主成分分析的元胞自动机参数类。在进行基于主成分分析的元胞自动机过程时,需要生成主成分分析,这一过程需要设置主成分权重值、模拟 过程所需参数(非线性指数变换值、扩散指数)等。
-
alpha¶ int -- 扩散参数
-
cellular_automata_parameter¶ CellularAutomataParameter -- 元胞自动机参数
-
component_weights¶ list[float] -- 主成分权重数组
-
conversion_rules¶ dict[int,bool] -- 转换规则
-
conversion_target¶ int -- 转换目标
-
index_k¶ float -- 非线性指数变换值。
-
set_alpha(value)¶ 设置扩散参数。一般1-10。
参数: value (int) -- 扩散参数。 返回: self 返回类型: PCACAParameter
-
set_cellular_automata_parameter(value)¶ 设置元胞自动机参数。
参数: value (CellularAutomataParameter) -- 元胞自动机参数 返回: self 返回类型: PCACAParameter
-
set_component_weights(value)¶ 设置主成分权重数组。
参数: value (list[float] or tuple[float]) -- 主成分权重数组 返回: self 返回类型: PCACAParameter
-
set_conversion_rules(value)¶ 设置转换规则。例如在土地利用的变化中,水域为不可转变用地,农田为可转变用地。
参数: value (dict[int,bool]) -- 转换规则 返回: self 返回类型: PCACAParameter
-
set_conversion_target(value)¶ 设置转换目标。例如农田转换为城市用地中,城市用地为转换目标。
参数: value (int) -- 转换目标 返回: self 返回类型: PCACAParameter
-
set_index_k(value)¶ 设置非线性指数变换值。本系统为4。
参数: value (float) -- 非线性指数变换值。 返回: self 返回类型: PCACAParameter
-
-
class
iobjectspy.analyst.PCAEigenValue¶ 基类:
object主成分分析特征值结果类。
-
contribution_rate¶ float -- 贡献率
-
cumulative¶ float -- 累积贡献率
-
eigen_value¶ float -- 特征值
-
spatial_dataset_raster_name¶ str -- 空间变量数据名称
-
-
class
iobjectspy.analyst.PCAEigenResult¶ 基类:
object主成分分析结果类。主成分分析由于不同的抽样数目和主成分比例,导致得到的主成分数目不同,所以需要在主成分分析之后根据得到的结 果(主成分和贡献率等)进行权重设置,设置好权重之后就能利用元胞自动机进行模拟。
-
component_count¶ int -- 主成分数目
-
pca_eigen_values¶ list[PCAEigenValue] -- 主成分分析特征值结果数组
-
pca_loadings¶ list[float] -- 主成分贡献率
-
spatial_dataset_raster_names¶ list[str] -- 空间变量数据名称
-
-
class
iobjectspy.analyst.PCACellularAutomata¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase基于主成分分析的元胞自动机。
元胞自动机(cellular automata, CA)是一种时间、空间、状态都离散,空间相互作用和时间因果关系为局部的网络动力学模型,具有模拟复杂 系统时空演化过程的能力。
当地理模拟需要使用许多空间变量,这些空间变量往往是相关的,有必要采用主成分分析,可以有效地将多个空间变量压缩到少数的主成分中,减 少设置权重的难度,可以将基于主成分分析的元胞自动机应用在城市发展的空间模拟中。
-
pca(spatial_variable_grids, sample_count, component_radio, progress_func=None)¶ 对元胞数据集进行抽样和主成分分析。
该方法用于在进行基于主成分分析的元胞自动机分析之前,利用得到的主成分个数设置对应的权重值。
参数: - spatial_variable_grids (list[DatasetGrid] or tuple[DatasetGird]) -- 空间变量栅格数据集。
- sample_count (int) -- 抽样个数。在整个栅格数据中随机抽取样本指定的样本个数
- component_radio (float) -- 主成分比例,取值范围 [0,1],例如取值为0.8时,表示选取前n个累计贡献率达到80%的主成分。
- progress_func (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 主成分分析结果,包含主成分个数、贡献率、特征值和特征向量
返回类型:
-
pca_cellular_automata(parameter, out_data=None, out_dataset_name=None, progress_func=None, flush_func=None)¶ 基于主成分分析的元胞自动机。
参数: - parameter (PCACellularAutomataParameter) -- 基于主成分分析的元胞自动机的参数。
- out_data (Datasource or str) -- 输出结果数据集所在数据源。
- out_dataset_name (str) -- 输出结果数据集的名称。
- progress_func (function) -- 进度信息处理函数,具体参考
StepEvent - flush_func (function) -- 元胞自动机刷新信息处理函数,具体参考
CellularAutomataFlushedEvent
返回: 结果栅格数据集
返回类型:
-
-
class
iobjectspy.analyst.CellularAutomataFlushedEvent(flush_file_path=None)¶ 基类:
object元胞自动机刷新事务类。
参数: flush_file_path (str) -- 用于刷新的tif文件路径 -
flush_file_path¶ str -- 用于刷新的tif文件路径
-
-
class
iobjectspy.analyst.ANNTrainResult(java_object)¶ 基类:
object人工神经网络(ANN)训练结果
-
accuracy¶ float -- 训练正确率
-
convert_values¶ dict[int, error] -- 训练迭代结果, key 为迭代次数,value 为错误率
-
-
class
iobjectspy.analyst.ANNCellularAutomataParameter¶ 基类:
object基于人工神经网络的元胞自动机参数设置。
-
alpha¶ int -- 扩散参数
-
cellular_automata_parameter¶ CellularAutomataParameter -- 元胞自动机的参数
-
conversion_class_ids¶ list[int] -- 元胞自动机转换规则的分类ID(即栅格值)数组
-
conversion_rules¶ list[list[bool]] -- 元胞自动机转换规则
-
end_cell_grid¶ DatasetGrid -- 终止栅格数据集
-
is_check_result¶ bool -- 是否检测结果
-
set_alpha(value)¶ 设置扩散参数
参数: value (int) -- 扩散参数。一般1-10。 返回: self 返回类型: ANNCellularAutomataParameter
-
set_cellular_automata_parameter(value)¶ 设置元胞自动机的参数
参数: value (CellularAutomataParameter) -- 元胞自动机的参数 返回: self 返回类型: ANNCellularAutomataParameter
-
set_check_result(value)¶ 设置是否检测结果
参数: value (bool) -- 是否检测结果 返回: self 返回类型: ANNCellularAutomataParameter
-
set_conversion_class_ids(value)¶ 设置元胞自动机转换规则的分类 ID(即栅格值)数组
参数: value (list[int] or tuple[int]) -- 元胞自动机转换规则的分类ID(即栅格值)数组 返回: self 返回类型: ANNCellularAutomataParameter
-
set_conversion_rules(value)¶ 设置元胞自动机转换规则。
参数: value (list[list[bool]]) -- 设置元胞自动机转换规则 返回: self 返回类型: ANNCellularAutomataParameter
-
set_end_cell_grid(value)¶ 设置终止栅格数据集。当
is_check_result为 True 时必须设置参数: value (DatasetGrid or str) -- 终止栅格数据集 返回: self 返回类型: ANNCellularAutomataParameter
-
set_threshold(value)¶ 设置元胞转变概率阈值
参数: value (float) -- 元胞转变概率阈值 返回: self 返回类型: ANNCellularAutomataParameter
-
threshold¶ float -- 元胞转变概率阈值
-
-
class
iobjectspy.analyst.ANNCellularAutomata¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase基于人工神经网络的元胞自动机。
-
ann_cellular_automata(parameter, out_data=None, out_dataset_name=None, progress_func=None, flush_func=None)¶ 基于人工神经网络的元胞自动机。
参数: - parameter (ANNCellularAutomataParameter) -- 基于人工神经网络的元胞自动机参数。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 输出数据集所在数据源。
- out_dataset_name (str) -- 输出数据集的名称。
- progress_func (function) -- 进度信息处理函数,具体参考
StepEvent - flush_func (function) -- 胞自动机刷新信息处理函数,具体参考
CellularAutomataFlushedEvent
返回: 基于人工神经网络的元胞自动机的结果,包括土地类型(如果有)、准确率(如果有)、结果栅格数据集。
返回类型:
-
ann_train(error_rate, max_times)¶ 人工神经网络训练。
参数: - error_rate (float) -- 人工神经网络训练终止条件,误差期望值。
- max_times (int) -- 人工神经网络训练终止条件,迭代最大次数。
返回: 人工神经网络训练结果
返回类型:
-
initialize_ann(train_start_cell_grid, train_end_cell_grid, ann_train_values, spatial_variable_grids, ann_parameter)¶ 初始化基于人工神经网络的元胞自动机
参数: - train_start_cell_grid (DatasetGrid or str) -- 训练起始栅格数据集
- train_end_cell_grid (DatasetGrid or str) -- 训练终止栅格数据集
- ann_train_values (list[int] or tuple[int]) --
- spatial_variable_grids (list[DatasetGrid] or list[str]) -- 空间变量栅格数据集
- ann_parameter (ANNParameter) -- 人工神经网络训练参数设置。
返回: 是否初始化成功
返回类型: bool
-
-
class
iobjectspy.analyst.ANNCellularAutomataResult(convert_values, accuracies, result_dataset)¶ 基类:
object基于人工神经网络的元胞自动机结果
-
accuracies¶ list[float] -- 正确率
-
convert_values¶ list[float] -- 转换值数组,为转换规则的栅格类型
-
result_dataset¶ DatasetGrid -- 元胞自动机的栅格结果数据集
-
-
class
iobjectspy.analyst.ANNParameter(is_custom_neighborhood=False, neighborhood_number=7, custom_neighborhoods=None, learning_rate=0.2, sample_count=1000)¶ 基类:
object人工神经网络参数设置。
初始化对象
参数: - is_custom_neighborhood (bool) -- 是否自定义邻域范围
- neighborhood_number (int) -- 邻域范围
- custom_neighborhoods (list[list[bool]]) -- 自定义邻域范围。
- learning_rate (float) -- 学习速率
- sample_count (int) -- 抽样数目
-
custom_neighborhoods¶ list[list[bool]] -- 自定义领域范围
-
is_custom_neighborhood¶ bool -- 是否自定义邻域范围
-
learning_rate¶ float -- 学习速率
-
neighborhood_number¶ int -- 邻域范围
-
sample_count¶ int -- 抽样数目
-
set_custom_neighborhood(value)¶ 设置是否自定义邻域范围
参数: value (bool) -- 是否自定义邻域范围 返回: self 返回类型: ANNParameter
-
set_custom_neighborhoods(value)¶ 设置自定义领域范围
参数: value (list[list[bool]]) -- 自定义领域范围 返回: self 返回类型: ANNParameter
-
set_learning_rate(value)¶ 设置学习速率
参数: value (float) -- 学习速率 返回: self 返回类型: ANNParameter
-
set_neighborhood_number(value)¶ 设置邻域范围
参数: value (int) -- 邻域范围 返回: self 返回类型: ANNParameter
-
set_sample_count(value)¶ 设置抽样数目
参数: value (int) -- 抽样数目 返回: self 返回类型: ANNParameter
-
class
iobjectspy.analyst.MCECellularAutomata¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase基于多准则判断的元胞自动机。
-
get_kappa()¶ 获取 Kappa 系数。
返回: kappa 系数。用于一致性检验,可以用于衡量元胞转换准确度。 返回类型: float
-
mce_cellular_automata(parameter, out_data=None, out_dataset_name=None, progress_func=None, flush_func=None)¶ 基于多准则判断的元胞自动机。
>>> ds = open_datasource('/home/data/cellular.udbx') >>> para = CellularAutomataParameter() >>> para.set_cell_grid(ds['T2001']) >>> para.set_spatial_variable_grids((ds['x0'], ds['x1'], ds['x2'], ds['x3'], ds['x4'])) >>> para.set_simulation_count(1000).set_iterations(10) >>> para.set_output_datasource(ds).set_output_dataset_name('result') >>> ahp_v = [[1, 0.33333343, 0.2, 3], [3, 1, 0.333333343, 3], [5, 3, 1, 5], [0.333333343, 0.333333343, 0.2, 1]] >>> assert MCECellularAutomataParameter.check_ahp_consistent(ahp_v) is not None [0.13598901557207943, 0.24450549432771368, 0.5430402884352277, 0.0764652016649792] >>> >>> mce_parameter = MCECellularAutomataParameter().set_cellular_automata_parameter(para) >>> mce_parameter.set_conversion_rules({2: False, 3: True, 4: False, 5: True}) >>> mce_parameter.set_conversion_target(1).set_check_result(True).set_end_cell_grid(ds['T2006']) >>> mce_parameter.set_ahp_comparison_matrix(ahp_v).set_alpha(2) >>> def progress_function(step): >>> print('{}: {}'.format(step.title, step.message)) >>> >>> result_grid = mce_parameter.mce_cellular_automata(mce_parameter, progress_func=progress_function) >>>
参数: - parameter (MCECellularAutomataParameter) -- 基于多准则判断的元胞自动机的参数。
- out_data (Datasource or str) -- 输出结果数据集所在数据源。
- out_dataset_name (str) -- 输出结果数据集的名称。
- progress_func (function) -- 进度信息处理函数,具体参考
StepEvent - flush_func (function) -- 元胞自动机刷新信息处理函数,具体参考
CellularAutomataFlushedEvent
返回: 结果栅格数据集
返回类型:
-
-
class
iobjectspy.analyst.MCECellularAutomataParameter¶ 基类:
object基于多准则判断的元胞自动机参数类。
-
ahp_comparison_matrix¶ list[list[float]] -- 层次分析法一致性检验的判断矩阵
-
alpha¶ int -- 扩散参数
-
cellular_automata_parameter¶ CellularAutomataParameter -- 元胞自动机参数
-
static
check_ahp_consistent(ahp_comparison_matrix)¶ 层次分析法的一致性检验。
>>> values = [[1, 0.33333343, 0.2, 3], [3, 1, 0.333333343, 3], [5, 3, 1, 5], [0.333333343, 0.333333343, 0.2, 1]] >>> MCECellularAutomataParameter.check_ahp_consistent(values)
- :param ahp_comparison_matrix:判断矩阵。如果设置为 list,list 中每个元素必须为list,且元素值相等。如果系统中有 numpy 库,可以
- 输入二维 numpy 数组。
返回: 成功返回权重数组,失败返回 None 返回类型: list[float]
-
conversion_rules¶ dict[int,bool] -- 转换规则
-
conversion_target¶ int -- 转换目标
-
end_cell_grid¶ DatasetGrid -- 终止年份栅格数据集
-
global_value¶ float -- 全局因素影响比例
-
is_check_result¶ bool -- 是否对比检验输出结果和终止数据
-
local_value¶ float -- 邻域因素影响比例
-
set_ahp_comparison_matrix(value)¶ 设置层次分析法一致性检验的判断矩阵。
- :param value:层次分析法一致性检验的判断矩阵。如果设置为 list,list 中每个元素必须为list,且元素值相等。如果系统中有 numpy 库,可以
- 输入二维 numpy 数组。
返回: self 返回类型: MCECellularAutomataParameter
-
set_alpha(value)¶ 设置扩散参数。一般1-10。
参数: value (int) -- 扩散参数。 返回: self 返回类型: MCECellularAutomataParameter
-
set_cellular_automata_parameter(value)¶ 设置元胞自动机参数。
参数: value (CellularAutomataParameter) -- 元胞自动机参数 返回: self 返回类型: MCECellularAutomataParameter
-
set_check_result(value)¶ 设置是否对比检验输出结果和终止数据。默认为 False。
参数: value (bool) -- 是否对比检验输出结果和终止数据 返回: self 返回类型: MCECellularAutomataParameter
-
set_conversion_rules(value)¶ 设置转换规则。例如在土地利用的变化中,水域为不可转变用地,农田为可转变用地。
参数: value (dict[int,bool]) -- 转换规则 返回: self 返回类型: MCECellularAutomataParameter
-
set_conversion_target(value)¶ 设置转换目标。例如农田转换为城市用地中,城市用地为转换目标。
参数: value (int) -- 转换目标 返回: self 返回类型: MCECellularAutomataParameter
-
set_end_cell_grid(value)¶ 设置终止年份栅格数据集。
参数: value (DatasetGrid or str) -- 终止年份栅格数据集 返回: self 返回类型: MCECellularAutomataParameter
-
set_global_value(value)¶ 设置全局因素影响比例。默认值为 0.5。全局因素和领域因素影响比例和为1。
参数: value (float) -- 全局因素影响比例。 返回: self 返回类型: MCECellularAutomataParameter
-
set_local_value(value)¶ 设置邻域因素影响比例,默认值为 0.5。邻域因素和全局因素影响比例和为1
参数: value (float) -- 邻域因素影响比例 返回: self 返回类型: MCECellularAutomataParameter
-
-
iobjectspy.analyst.basin(direction_grid, out_data=None, out_dataset_name=None, progress=None)¶ 关于水文分析:
水文分析基于数字高程模型(DEM)栅格数据建立水系模型,用于研究流域水文特征和模拟地表水文过程,并对未来的地表水文情况做出预估。水文分析模型能够帮助我们分析洪水的范围,定位径流污染源,预测地貌改变对径流的影响等,广泛应用于区域规划、农林、灾害预测、道路设计等诸多行业和领域。
地表水的汇流情况很大程度上决定于地表形状,而 DEM 数据能够表达区域地貌形态的空间分布,在描述流域地形,如流域边界、坡度和坡向、河网提取等方面具有突出优势,因而非常适用于水文分析。
SuperMap 提供的水文分析主要内容有填充洼地、计算流向、计算流长、计算累积汇水量、流域划分、河流分级、连接水系及水系矢量化等。
水文分析的一般流程为:
如何获得栅格水系?
水文分析中很多功能都需要基于栅格水系数据,如提取矢量水系(
stream_to_line()方法)、河流分级(stream_order()方法)、 连接水系(:stream_link()方法)等。通常,可以从累积汇水量栅格中提取栅格水系数据。在累积汇水量栅格中,单元格的值越大,代表该区域的累积汇水量越大。累积汇水量 较高的单元格可视为河谷,因此,可以通过设定一个阈值,提取累积汇水量大于该值的单元格,这些单元格就构成栅格水系。值得说明的 是,对于不同级别的河谷、不同区域的相同级别的河谷,该值可能不同,因此该阈值的确定需要依据研究区域的实际地形地貌并通过不断的试验来确定。
在 SuperMap 中,要求用于进一步分析(提取矢量水系、河流分级、连接水系等)的栅格水系为一个二值栅格,这可以通过栅格代数运算 来实现,使大于或等于累积汇水量阈值的单元格为 1,否则为 0,如下图所示。
因此,提取栅格水系的过程如下:
- 获得累积汇水量栅格,可通过
flow_accumulation()方法实现。 - 通过栅格代数运算
expression_math_analyst()方法对累积汇水量栅格进行关系运算,就可以得到满足要求的栅格水系数据。假设设定 阈值为 1000,则运算表达式为:"[Datasource.FlowAccumulationDataset]>1000"。除此,使用 Con(x,y,z) 函数也可以得到想 要的结果,即表达式为:"Con([Datasource.FlowAccumulationDataset]>1000,1,0)"。
- 获得累积汇水量栅格,可通过
根据流向栅格计算流域盆地。流域盆地即为集水区域,是用于描述流域的方式之一。
计算流域盆地是依据流向数据为每个单元格分配唯一盆地的过程,如下图所示,流域盆地是描述流域的方式之一,展现了那些所有相互连接且处于同一流域盆地的栅格。
参数: - direction_grid (DatasetGrid or str) -- 流向栅格数据集。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 流域盆地栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.build_quad_mesh(quad_mesh_region, left_bottom, left_top, right_bottom, right_top, cols=0, rows=0, out_col_field=None, out_row_field=None, out_data=None, out_dataset_name=None, progress=None)¶ 对单个简单面对象进行网格剖分。 流体问题是一个连续性的问题,为了简化对其的研究以及建模处理的方便,对研究区域进行离散化处理,其思路就是建立离散的网格,网格划分就是对连续的物理区域进行剖分,把它分成若干个网格,并确定各个网格中的节点,用网格内的一个值来代替整个网格区域的基本情况,网格作为计算与分析的载体,其质量的好坏对后期的数值模拟的精度和计算效率有重要的影响。
网格剖分的步骤:
- 1.数据预处理,包含去除重复点等。给定一个合理的容限,去除重复点,使得最后的网格划分结果更趋合理,不会出现看起来从1个点
- (实际是重复点)出发有多条线的现象。
- 2.多边形分解:对于复杂的多边形区域,我们采用分块逐步划分的方法来进行网格的构建,将一个复杂的不规则多边形区域划分为多个简
- 单的单连通区域,然后对每个单连通区域执行网格划分程序,最后再将各个子区域网格拼接起来构成对整个区域的划分。
- 3.选择四个角点:这4个角点对应着网格划分的计算区域上的4个顶点,其选择会对划分的结果造成影响。其选择应尽量在原区域近似四边
形的四个顶点上,同时要考虑整体的流势。
4.为了使划分的网格呈现四边形的特征,构成多边形的顶点数据(不在同一直线上)需参与构网。
5.进行简单区域网格划分。
注:简单多边形:多边形内任何直线或边都不会交叉。
说明:
RightTopIndex 为右上角点索引号,LeftTopIndex 为左上角点索引号,RightBottomIndex 为右下角点索引号,LeftBottomIndex 为左下角点索引号。则 nCount1=(RightTopIndex- LeftTopIndex+1)和 nCount2=(RightBottomIndex- LeftBottomIndex+1), 如果:nCount1不等于nCount2,则程序不处理。水文分析的相关介绍,请参考
basin()参数: - quad_mesh_region (GeoRegion) -- 网格剖分的面对象
- left_bottom (Point2D) -- 网格剖分的区域多边形左下角点坐标。四个角点选择依据:4个角点对应着网格剖分的计算区域上的4个顶点, 其选择会对剖分的结果造成影响。其选择应尽量在原区域近似四边形的四个顶点上,同时要考虑整体的流势。
- left_top (Point2D) -- 网格剖分的区域多边形左上角点坐标
- right_bottom (Point2D) -- 网格剖分的区域多边形右下角点坐标
- right_top (Point2D) -- 网格剖分的区域多边形右上角点坐标
- cols (int) -- 网格剖分的列方向节点数。默认值为0,表示不参与处理;若不为0,但是此值若小于多边形列方向的最大点数减一,则 以多边形列方向的最大点数减一作为列数(cols);若大于多边形列方向的最大点数减一,则会自动加点,使列方 向的数目为 cols。 举例来讲:如果用户希望将一矩形面对象划分为2*3(高*宽)=6个小矩形,则列方向数目(cols)为3。
- rows (int) -- 网格剖分的行方向节点数。默认值为0,表示不参与处理;若不为0,但是此值小于多边形行方向的最大点数减一,则以 多边形行方向的最大点数减一作为行数(rows);若大于多边形行方向的最大点数减一,则会自动加点,使行方向的 数目为 rows。举例来讲:如果用户希望将一矩形面对象划分为2*3(高*宽)=6个小矩形,则行方向数目(rows)为2。
- out_col_field (str) -- 格网剖分结果对象的列属性字段名称。此字段用来保存剖分结果对象的列号。
- out_row_field (str) -- 格网剖分结果对象的行属性字段名称。此字段用来保存剖分结果对象的行号。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 存放剖分结果数据集的数据源。
- out_dataset_name (str) -- 剖分结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 剖分后的结果数据集,剖分出的多个面以子对象形式返回。
返回类型: DatasetVector or str
-
iobjectspy.analyst.fill_sink(surface_grid, exclude_area=None, out_data=None, out_dataset_name=None, progress=None)¶ 对 DEM 栅格数据填充伪洼地。 洼地是指周围栅格都比其高的区域,分为自然洼地和伪洼地。
* 自然洼地,是实际存在的洼地,是地表真实形态的反映,如冰川或喀斯特地貌、采矿区、坑洞等,一般远少于伪洼地; * 伪洼地,主要是由数据处理造成的误差、不合适的插值方法导致,在 DEM 栅格数据中很常见。
在确定流向时,由于洼地高程低于周围栅格的高程,一定区域内的流向都将指向洼地,导致水流在洼地聚集不能流出,引起汇水网络的中断, 因此,填充洼地通常是进行合理流向计算的前提。
在填充某处洼地后,有可能产生新的洼地,因此,填充洼地是一个不断重复识别洼地、填充洼地的过程,直至所有洼地被填充且不再产生新 的洼地。下图为填充洼地的剖面示意图。
该方法可以指定一个点或面数据集,用于指示的真实洼地或需排除的洼地,这些洼地不会被填充。使用准确的该类数据,将获得更为真实的 无伪洼地地形,使后续分析更为可靠。
用于指示洼地的数据,如果是点数据集,其中的一个或多个点位于洼地内即可,最理想的情形是点指示该洼地区域的汇水点;如果是面数据 集,每个面对象应覆盖一个洼地区域。
可以通过 exclude_area 参数,指定一个点或面数据集,用于指示的真实洼地或需排除的洼地,这些洼地不会被填充。使用准确的该类数据, 将获得更为真实的无伪洼地地形,使后续分析更为可靠。用于指示洼地的数据,如果是点数据集,其中的一个或多个点位于洼地内即可,最 理想的情形是点指示该洼地区域的汇水点;如果是面数据集,每个面对象应覆盖一个洼地区域。
如果 exclude_area 为 None,则会将 DEM 栅格中所有洼地填充,包括伪洼地和真实洼地
水文分析的相关介绍,请参考
basin()参数: - surface_grid (DatasetGrid or str) -- 指定的要进行填充洼地的 DEM 数据
- exclude_area (DatasetVector or str) -- 指定的用于指示已知自然洼地或要排除的洼地的点或面数据。如果是点数据集,一个或多个点所在的区域指示为洼地; 如果是面数据集,每个面对象对应一个洼地区域。如果为 None,则会将 DEM 栅格中所有洼地填充,包括伪洼地和真实洼地
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 无伪洼地的 DEM 栅格数据集或数据集名称。如果填充伪洼地失败,则返回 None。
返回类型: DatasetVector or str
-
iobjectspy.analyst.flow_accumulation(direction_grid, weight_grid=None, out_data=None, out_dataset_name=None, progress=None)¶ 根据流向栅格计算累积汇水量。可应用权重数据集计算加权累积汇水量。 累积汇水量是指流向某个单元格的所有上游单元格的水流累积量,是基于流向数据计算得出的。
累积汇水量的值可以帮助我们识别河谷和分水岭。单元格的累积汇水量较高,说明该地地势较低,可视为河谷;为0说明该地地势较高,可能为分水岭。因此,累积汇水量是提取流域的各种特征参数(如流域面积、周长、排水密度等)的基础。
计算累积汇水量的基本思路是:假定栅格数据中的每个单元格处有一个单位的水量,依据水流方向图顺次计算每个单元格所能累积到的水量(不包括当前单元格的水量)。
下图显示了由水流方向计算累积汇水量的过程。
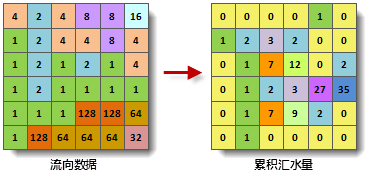
下图为流向栅格和基于其生成的累积汇水量栅格。
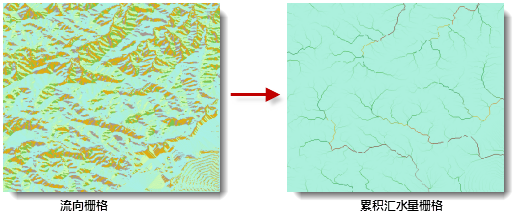
在实际应用中,每个单元格的水量不一定相同,往往需要指定权重数据来获取符合需求的累积汇水量。使用了权重数据后,累积汇水量的计算过程中,每个单元格的水量不再是一个单位,而是乘以权重(权重数据集的栅格值)后的值。例如,将某时期的平均降雨量作为权重数据,计算所得的累积汇水量就是该时期的流经每个单元格的雨量。
注意,权重栅格必须与流向栅格具有相同的范围和分辨率。
水文分析的相关介绍,请参考
basin()参数: - direction_grid (DatasetGrid or str) -- 流向栅格数据。
- weight_grid (DatasetGrid or str) -- 权重栅格数据。设置为 None 表示不使用权重数据集。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 累积汇水量栅格数据集或数据集名称。如果计算失败,则返回 None。
返回类型: DatasetVector or str
-
iobjectspy.analyst.flow_direction(surface_grid, force_flow_at_edge, out_data=None, out_dataset_name=None, out_drop_grid_name=None, progress=None)¶ 对 DEM 栅格数据计算流向。为保证流向计算的正确性,建议使用填充伪洼地之后的 DEM 栅格数据。
流向,即水文表面水流的方向。计算流向是水文分析的关键步骤之一。水文分析的很多功能需要基于流向栅格,如计算累积汇水量、计算流 长和流域等。
SuperMap 使用最大坡降法(D8,Deterministic Eight-node)计算流向。这种方法通过计算单元格的最陡下降方向作为水流的方向。中心 单元格与相邻单元格的高程差与距离的比值称为高程梯度。最陡下降方向即为中心单元格与高程梯度最大的单元格所构成的方向,也就是中 心栅格的流向。单元格的流向的值,是通过对其周围的8个邻域栅格进行编码来确定的。如下图所示,若中心单元格的水流方向是左边,则其 水流方向被赋值16;若流向右边,则赋值1。
在 SuperMap 中,通过对中心栅格的 8 个邻域栅格编码(如下图所示),中心栅格的水流方向便可由其中的某一值来确定。例如,若中心 栅格的水流方向是左边,则其水流方向被赋值 16;若流向右边,则赋值 1。
计算流向时,需要注意栅格边界单元格的处理。位于栅格边界的单元格比较特殊,通过 forceFlowAtEdge 参数可以指定其流向是否向外, 如果向外,则边界栅格的流向值如下图(左)所示,否则,位于边界上的单元格将赋为无值,如下图(右)所示。
计算 DEM 数据每个栅格的流向得到流向栅格。下图显示了基于无洼地的 DEM 数据生成的流向栅格。
水文分析的相关介绍,请参考
basin()参数: - surface_grid (DatasetGrid or str) -- 用于计算流向的 DEM 数据
- force_flow_at_edge (bool) -- 指定是否强制边界的栅格流向为向外。如果为 True,则 DEM 栅格边缘处的所有单元的流向都是从栅格向外流动。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果流向数据集的名称
- out_drop_grid_name (str) --
结果高程梯度栅格数据集名称。可选参数。用于计算流向的中间结果。中心单元格与相邻单元格的高程差与距离的比值称 为高程梯度。如下图所示,为流向计算的一个实例,该实例中生成了高程梯度栅格
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 返回一个2个元素的tuple,第一个元素为 结果流向栅格数据集或数据集名称,如果设置了结果高程梯度栅格数据集名称, 则第二个元素为结果高程梯度栅格数据集或数据集名称,否则为 None
返回类型: tuple[DatasetGrid,DatasetGrid] or tuple[str,str]
-
iobjectspy.analyst.flow_length(direction_grid, up_stream, weight_grid=None, out_data=None, out_dataset_name=None, progress=None)¶ 根据流向栅格计算流长,即计算每个单元格沿着流向到其流向起始点或终止点之间的距离。可应用权重数据集计算加权流长。
流长,是指每个单元格沿着流向到其流向起始点或终止点之间的距离,包括上游方向和下游方向的长度。水流长度直接影响地面径流的速度, 进而影响地面土壤的侵蚀力,因此在水土保持方面具有重要意义,常作为土壤侵蚀、水土流失情况的评价因素。
流长的计算基于流向数据,流向数据表明水流的方向,该数据集可由流向分析创建;权重数据定义了每个单元格的水流阻力。流长一般用于 洪水的计算,水流往往会受到诸如坡度、土壤饱和度、植被覆盖等许多因素的阻碍,此时对这些因素建模,需要提供权重数据集。
流长有两种计算方式:
- 顺流而下:计算每个单元格沿流向到下游流域汇水点之间的最长距离。
- 溯流而上:计算每个单元格沿流向到上游分水线顶点的最长距离。
下图分别为以顺流而下和溯流而上计算得出的流长栅格:

权重数据定义了每个栅格单元间的水流阻力,应用权重所获得的流长为加权距离(即距离乘以对应权重栅格的值)。例如,将流长分析应用 于洪水的计算,洪水流往往会受到诸如坡度、土壤饱和度、植被覆盖等许多因素的阻碍,此时对这些因素建模,需要提供权重数据集。
注意,权重栅格必须与流向栅格具有相同的范围和分辨率。
水文分析的相关介绍,请参考
basin()参数: - direction_grid (DatasetGrid or str) -- 指定的流向栅格数据。
- up_stream (bool) -- 指定顺流而下计算还是溯流而上计算。True 表示溯流而上,False 表示顺流而下。
- weight_grid (DatasetGrid or str) -- 指定的权重栅格数据。设置为 None 表示不使用权重数据集。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果流长栅格数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果流长栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.stream_order(stream_grid, direction_grid, order_type, out_data=None, out_dataset_name=None, progress=None)¶ 对河流进行分级,根据河流等级为栅格水系编号。
流域中的河流分为干流和支流,在水文学中,根据河流的流量、形态等因素对河流进行分级。在水文分析中,可以从河流的级别推断出河流的某些特征。
该方法以栅格水系为基础,依据流向栅格对河流分级,结果栅格的值即代表该条河流的等级,值越大,等级越高。SuperMap 提供两种河流 分级方法:Strahler 法和 Shreve 法。有关这两种方法的介绍请参见
StreamOrderType枚举类型。如下图所示,是河流分级的一个实例。根据 Shreve 河流分级法,该区域的河流被分为14个等级。
水文分析的相关介绍,请参考
basin()参数: - stream_grid (DatasetGrid or str) -- 栅格水系数据
- direction_grid (DatasetGrid or str) -- 流向栅格数据
- order_type (StreamOrderType or str) -- 流域水系编号方法
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果栅格数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 编号后的栅格流域水系网络,为一个栅格数据集。返回结果数据集或数据集名称。
返回类型: DatasetGrid or str
-
iobjectspy.analyst.stream_to_line(stream_grid, direction_grid, order_type, out_data=None, out_dataset_name=None, progress=None)¶ 提取矢量水系,即将栅格水系转化为矢量水系。
提取矢量水系是基于流向栅格,将栅格水系转化为矢量水系(一个矢量线数据集)的过程。得到矢量水系后,就可以进行各种基于矢量的计 算、处理和空间分析,如构建水系网络。下图为 DEM 数据以及对应的矢量水系。
通过该方法获得的矢量水系数据集,保留了河流的等级和流向信息。
- 在提取矢量水系的同时,系统计算每条河流的等级,并在结果数据集中自动添加一个名为“StreamOrder”的属性字段来存储该值。分级的方式可 通过 order_type 参数设置。
- 流向信息存储在结果数据集中名为“Direction”的字段中,以0或1来表示,0表示流向与该线对象的几何方向一致,1表示与线对象的几何 方向相反。通过该方法获得的矢量水系的流向均与其几何方向相同,即“Direction”字段值都为0。在对矢量水系构建水系网络后,可直接 使用(或根据实际需要进行修改)该字段作为流向字段。
水文分析的相关介绍,请参考
basin()参数: - stream_grid (DatasetGrid or str) -- 栅格水系数据
- direction_grid (DatasetGrid or str) -- 流向栅格数据
- order_type (StreamOrderType or str) -- 河流分级方法
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果矢量水系数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 矢量水系数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.stream_link(stream_grid, direction_grid, out_data=None, out_dataset_name=None, progress=None)¶ 连接水系,即根据栅格水系和流向栅格为每条河流赋予唯一值。 连接水系基于栅格水系和流向栅格,为水系中的每条河流分别赋予唯一值,值为整型。连接后的水系网络记录了水系节点的连接信息,体现了 水系的网络结构。
如下图所示,连接水系后,每条河段都有唯一的栅格值。图中红色的点为交汇点,即河段与河段相交的位置。河段是河流的一部分,它连接 两个相邻交汇点,或连接一个交汇点和汇水点,或连接一个交汇点和分水线。因此,连接水系可用于确定流域盆地的汇水点。
下图连接水系的一个实例。
水文分析的相关介绍,请参考
basin()参数: - stream_grid (DatasetGrid or str) -- 栅格水系数据
- direction_grid (DatasetGrid or str) -- 流向栅格数据
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果栅格数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 连接后的栅格水系,为一个栅格数据集。返回结果栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.watershed(direction_grid, pour_points_or_grid, out_data=None, out_dataset_name=None, progress=None)¶ 流域分割,即生成指定汇水点(汇水点栅格数据集)的流域盆地。
将一个流域划分为若干个子流域的过程称为流域分割。通过
basin()方法,可以获取较大的流域,但实际分析中,可能需要将较大的流域划 分出更小的流域(称为子流域)。确定流域的第一步是确定该流域的汇水点,那么,流域分割同样首先要确定子流域的汇水点。与使用 basin 方法计算流域盆地不同,子流 域的汇水点可以在栅格的边界上,也可能位于栅格的内部。该方法要求输入一个汇水点栅格数据,该数据可通过提取汇水点功能(
pour_points()方法) 获得。此外,还可以使用另一个重载方法,输入表示汇水点的二维点集合来分割流域。水文分析的相关介绍,请参考
basin()参数: - direction_grid (DatasetGrid or str) -- 流向栅格数据
- pour_points_or_grid (DatasetGrid or str or list[Point2D]) -- 汇水点栅格数据或指定的汇水点(二维点列表),汇水点使用地理坐标单位。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果汇水点的流域盆地栅格数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 汇水点的流域盆地栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.pour_points(direction_grid, accumulation_grid, area_limit, out_data=None, out_dataset_name=None, progress=None)¶ 根据流向栅格和累积汇水量栅格生成汇水点栅格。
汇水点位于流域的边界上,通常为边界上的最低点,流域内的水从汇水点流出,所以汇水点必定具有较高的累积汇水量。根据这一特点,就可以基于累积汇水量和流向栅格来提取汇水点。
汇水点的确定需要一个累积汇水量阈值,累积汇水量栅格中大于或等于该阈值的位置将作为潜在的汇水点,再依据流向最终确定汇水点的位置。该阈值的确定十分关键,影响着汇水点的数量、位置以及子流域的大小和范围等。合理的阈值,需要考虑流域范围内的土壤特征、坡度特征、气候条件等多方面因素,根据实际研究的需求来确定,因此具有较大难度。
获得了汇水点栅格后,可以结合流向栅格来进行流域的分割(
watershed()方法)。水文分析的相关介绍,请参考
basin()参数: - direction_grid (DatasetGrid or str) -- 流向栅格数据
- accumulation_grid (DatasetGrid or str) -- 累积汇水量栅格数据
- area_limit (int) -- 汇水量限制值
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果栅格数据集的名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果栅格数据集或数据集名称
返回类型: DatasetGrid or str
-
iobjectspy.analyst.snap_pour_point(pour_point_or_grid, accumulation_grid, snap_distance, pour_point_field=None, out_data=None, out_dataset_name=None, progress=None)¶ 捕捉汇水点。将汇水点捕捉到指定范围内累积流量最大的像元,用于把汇水点数据纠正到河流上。
汇水点一般可以用于桥梁、桥涵等水利设施的建设,但实际应用中汇水点不一定都是计算得到,即使用
pour_points()方法,可能通过其他方式, 比如矢量地图中的位置转为栅格数据,这时便需要捕捉汇水点功能进行修正,确保累积汇水量最大。与获得汇水点栅格一样,捕捉汇水点后,可以进一步结合流向栅格来进行流域的分割(
watershed()方法)。参数: - pour_point_or_grid (DatasetGrid or DatasetVector or str) -- 汇水点数据集,仅支持点数据集和栅格数据集
- accumulation_grid (DatasetGrid or str) -- 累积汇水量栅格数据集。可通过
flow_accumulation()得到。 - snap_distance (float) -- 捕捉距离,捕捉汇水点到该范围内最大汇水量栅格位置上,该距离与指定的汇水点数据集单位一致。
- pour_point_field (str) -- 用于为汇水点位置赋值的字段。当汇水点数据集为点数据集时,需指定汇水点栅格值字段。字段类型仅支持整型,如果非整型会 强制转为整型。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果汇水点的栅格数据集
返回类型: DatasetGrid or str
-
class
iobjectspy.analyst.ProcessingOptions(pseudo_nodes_cleaned=False, overshoots_cleaned=False, redundant_vertices_cleaned=False, undershoots_extended=False, duplicated_lines_cleaned=False, lines_intersected=False, adjacent_endpoints_merged=False, overshoots_tolerance=1e-10, undershoots_tolerance=1e-10, vertex_tolerance=1e-10, filter_vertex_recordset=None, arc_filter_string=None, filter_mode=None)¶ 基类:
object拓扑处理参数类。该类提供了关于拓扑处理的设置信息。
如果未通过 set_vertex_tolerance,set_overshoots_tolerance 和 set_undershoots_tolerance 方法设置节点容限、短悬线容限和长悬线容限, 或设置为0,系统将使用数据集的容限中相应的容限值进行处理
构造拓扑处理参数类
参数: - pseudo_nodes_cleaned (bool) -- 是否去除假结点
- overshoots_cleaned (bool) -- 是否去除短悬线。
- redundant_vertices_cleaned (bool) -- 是否去除冗余点
- undershoots_extended (bool) -- 是否进行长悬线延伸。
- duplicated_lines_cleaned (bool) -- 是否去除重复线
- lines_intersected (bool) -- 是否进行弧段求交。
- adjacent_endpoints_merged (bool) -- 是否进行邻近端点合并。
- overshoots_tolerance (float) -- 短悬线容限,该容限用于在去除短悬线时判断悬线是否是短悬线。
- undershoots_tolerance (float) -- 长悬线容限,该容限用于在长悬线延伸时判断悬线是否延伸。单位与进行拓扑处理的数据集单位相同。
- vertex_tolerance (float) -- 节点容限。该容限用于邻近端点合并、弧段求交、去除假结点和去除冗余点。单位与进行拓扑处理的数据集单位相同。
- filter_vertex_recordset (Recordset) -- 弧段求交的过滤点记录集,即此记录集中的点位置线段不进行求交打断。
- arc_filter_string (str) -- 弧段求交的过滤线表达式。 在进行弧段求交时,通过该属性可以指定一个字段表达式,符合该表达式的线对象将不被打断。 该表达式是否有效,与 filter_mode 弧段求交过滤模式有关
- filter_mode (ArcAndVertexFilterMode or str) -- 弧段求交的过滤模式。
-
adjacent_endpoints_merged¶ bool -- 是否进行邻近端点合并
-
arc_filter_string¶ str -- 弧段求交的过滤线表达式。 在进行弧段求交时,通过该属性可以指定一个字段表达式,符合该表达式的线对象将不被打断。该表达式是否有效,与 filter_mode 弧段求交过滤模式有关
-
duplicated_lines_cleaned¶ bool -- 是否去除重复线
-
filter_mode¶ ArcAndVertexFilterMode -- 弧段求交的过滤模式
-
filter_vertex_recordset¶ Recordset -- 弧段求交的过滤点记录集,即此记录集中的点位置线段不进行求交打断
-
lines_intersected¶ bool -- 是否进行弧段求交
-
overshoots_cleaned¶ bool -- 是否去除短悬线
-
overshoots_tolerance¶ float -- 短悬线容限,该容限用于在去除短悬线时判断悬线是否是短悬线
-
pseudo_nodes_cleaned¶ bool -- 是否去除假结点
-
redundant_vertices_cleaned¶ bool -- 是否去除冗余点
-
set_adjacent_endpoints_merged(value)¶ 设置是否进行邻近端点合并。
如果多条弧段端点的距离小于节点容限,那么这些点就会被合并成为一个结点,该结点位置是原有点的几何平均(即 X、Y 分别为所有原有点 X、Y 的平均值)。
用于判断邻近端点的节点容限,可通过
set_vertex_tolerance()设置,如果不设置或设置为0,将使用数据集的容限中的节点容限。需要注意的是,如果有两个邻近端点,那么合并的结果就会是一个假结点,还需要进行去除假结点的操作。
参数: value (bool) -- 是否进行邻近端点合并 返回: self 返回类型: ProcessingOptions
-
set_arc_filter_string(value)¶ 设置弧段求交的过滤线表达式。
在进行弧段求交时,通过该属性可以指定一个字段表达式,符合该表达式的线对象将不被打断。详细介绍请参见
set_lines_intersected()方法。参数: value (str) -- 弧段求交的过滤线表达式 返回: self 返回类型: ProcessingOptions
-
set_duplicated_lines_cleaned(value)¶ 设置是否去除重复线
重复线:两条弧段若其所有节点两两重合,则可认为是重复线。重复线的判断不考虑方向。
去除重复线的目的是为避免建立拓扑多边形时产生面积为零的多边形对象,因此,重复的线对象只应保留其中一个,多余的应删除。
通常,出现重复线多是由于弧段求交造成的。
参数: value (bool) -- 是否去除重复线 返回: self 返回类型: ProcessingOptions
-
set_filter_mode(value)¶ 设置弧段求交的过滤模式
参数: value (ArcAndVertexFilterMode) -- 弧段求交的过滤模式 返回: self 返回类型: ProcessingOptions
-
set_filter_vertex_recordset(value)¶ 设置弧段求交的过滤点记录集,即此记录集中的点位置线段不进行求交打断。
如果过滤点在线对象上或到线对象的距离在容限范围内,在过滤点到线对象的垂足位置上线对象不被打断。详细介绍请参见
set_lines_intersected()方法。注意:过滤点记录集是否有效,与
set_filter_mode()方法设置的弧段求交过滤模式有关。可参见ArcAndVertexFilterMode类。参数: value (Recordset) -- 弧段求交的过滤点记录集 返回: self 返回类型: ProcessingOptions
-
set_lines_intersected(value)¶ 设置是否进行弧段求交。
线数据建立拓扑关系之前,首先要进行弧段求交计算,根据交点分解成若干线对象,一般而言,在二维坐标系统中凡是与其他线有交点的线对象都需要从交点处打断,如十字路口。且此方法是后续错误处理方法的基础。 在实际应用中,相交线段完全打断的处理方式在很多时候并不能很好地满足研究需求。例如,一条高架铁路横跨一条公路,在二维坐标上来看是两个相交的线对象,但事实上并没有相交 ,如果打断将可能影响进一步的分析。在交通领域还有很多类似的实际场景,如河流水系与交通线路的相交,城市中错综复杂的立交桥等,对于某些相交点是否打断, 需要根据实际应用来灵活处理,而不能因为在二维平面上相交就一律打断。
这种情况可以通过设置过滤线表达式(
set_arc_filter_string())和过滤点记录集 (set_vertex_filter_recordset()) 来 确定哪些线对象以及哪些相交位置处不打断:- 过滤线表达式用于查询出不需要打断的线对象
- 过滤点记录集中的点对象所在位置处不打断
这两个参数单独或组合使用构成了弧段求交的四种过滤模式,还有一种是不进行过滤。过滤模式通过
set_filter_mode()方法设置。对于上面的例子,使用不同的过滤模式,弧段求交的结果也不相同。关于过滤模式的详细介绍请参阅ArcAndVertexFilterMode类。注意:进行弧段求交处理时,可通过
set_vertex_tolerance()方法设置节点容限(如不设置,将使用数据集的节点容限),用于判断过滤点是否有效。若过滤点到线对象的距离在设置的容限范围内,则线对象在过滤点到其的垂足位置上不被打断。参数: value (bool) -- 是否进行弧段求交 返回: self 返回类型: ProcessingOptions
-
set_overshoots_cleaned(value)¶ 设置是否去除短悬线。去除短悬线指如果一条悬线的长度小于悬线容限,则在进行去除短悬线操作时就会把这条悬线删除。通过 set_overshoots_tolerance 方法可以指定短悬线容限,如不指定则使用数据集的短悬线容限。
悬线:如果一个线对象的端点没有与其它任意一个线对象的端点相连,则这个端点称之为悬点。具有悬点的线对象称之为悬线。
参数: value (bool) -- 是否去除短悬线,True 表示去除,False 表示不去除。 返回: self 返回类型: ProcessingOptions
-
set_overshoots_tolerance(value)¶ 设置短悬线容限,该容限用于在去除短悬线时判断悬线是否是短悬线。单位与进行拓扑处理的数据集单位相同。
“悬线”的定义:如果一个线对象的端点没有与其它任意一个线对象的端点相连,则这个端点称之为悬点。具有悬点的线对象称之为悬线。
参数: value (float) -- 短悬线容限 返回: self 返回类型: ProcessingOptions
-
set_pseudo_nodes_cleaned(value)¶ 设置是否去除假结点。结点又称为弧段连接点,至少连接三条弧段的才可称为一个结点。如果弧段连接点只连接了一条弧段(岛屿的情况)或连接了两条弧段(即它是两条弧段的公共端点),则该结点被称为假结点
参数: value (bool) -- 是否去除假结点,True 表示去除,False 表示不去除。 返回: ProcessingOptions 返回类型: self
-
set_redundant_vertices_cleaned(value)¶ 设置是否去除冗余点。任意弧段上两节点之间的距离小于节点容限时,其中一个即被认为是一个冗余点,在进行拓扑处理时可以去除。
参数: value (bool) -- : 是否去除冗余点,True 表示去除,False 表示不去除。 返回: self 返回类型: ProcessingOptions
-
set_undershoots_extended(value)¶ 设置是否进行长悬线延伸。 如果一条悬线按其行进方向延伸了指定的长度(悬线容限)之后与某弧段有交点,则拓扑处理后会将该悬线自动延伸到某弧段上, 称为长悬线延伸。通过 set_undershoots_tolerance 方法可以指定长悬线容限,如不指定则使用数据集的长悬线容限。
参数: value (bool) -- 是否进行长悬线延伸 返回: self 返回类型: ProcessingOptions
-
set_undershoots_tolerance(value)¶ 设置长悬线容限,该容限用于在长悬线延伸时判断悬线是否延伸。单位与进行拓扑处理的数据集单位相同。
参数: value (float) -- 长悬线容限 返回: self 返回类型: ProcessingOptions
-
set_vertex_tolerance(value)¶ 设置节点容限。该容限用于邻近端点合并、弧段求交、去除假结点和去除冗余点。单位与进行拓扑处理的数据集单位相同。
参数: value (float) -- 节点容限 返回: self 返回类型: ProcessingOptions
-
undershoots_extended¶ bool -- 是否进行长悬线延伸
-
undershoots_tolerance¶ float -- 长悬线容限,该容限用于在长悬线延伸时判断悬线是否延伸。单位与进行拓扑处理的数据集单位相同
-
vertex_tolerance¶ float -- 节点容限。该容限用于邻近端点合并、弧段求交、去除假结点和去除冗余点。单位与进行拓扑处理的数据集单位相同
-
iobjectspy.analyst.topology_processing(input_data, pseudo_nodes_cleaned=True, overshoots_cleaned=True, redundant_vertices_cleaned=True, undershoots_extended=True, duplicated_lines_cleaned=True, lines_intersected=True, adjacent_endpoints_merged=True, overshoots_tolerance=1e-10, undershoots_tolerance=1e-10, vertex_tolerance=1e-10, filter_vertex_recordset=None, arc_filter_string=None, filter_mode=None, options=None, progress=None)¶ 根据拓扑处理选项对给定的数据集进行拓扑处理。将直接修改原始数据。
参数: - input_data (DatasetVector or str) -- 指定的拓扑处理的数据集。
- pseudo_nodes_cleaned (bool) -- 是否去除假结点
- overshoots_cleaned (bool) -- 是否去除短悬线。
- redundant_vertices_cleaned (bool) -- 是否去除冗余点
- undershoots_extended (bool) -- 是否进行长悬线延伸。
- duplicated_lines_cleaned (bool) -- 是否去除重复线
- lines_intersected (bool) -- 是否进行弧段求交。
- adjacent_endpoints_merged (bool) -- 是否进行邻近端点合并。
- overshoots_tolerance (float) -- 短悬线容限,该容限用于在去除短悬线时判断悬线是否是短悬线。
- undershoots_tolerance (float) -- 长悬线容限,该容限用于在长悬线延伸时判断悬线是否延伸。单位与进行拓扑处理的数据集单位相同。
- vertex_tolerance (float) -- 节点容限。该容限用于邻近端点合并、弧段求交、去除假结点和去除冗余点。单位与进行拓扑处理的数据集单位相同。
- filter_vertex_recordset (Recordset) -- 弧段求交的过滤点记录集,即此记录集中的点位置线段不进行求交打断。
- arc_filter_string (str) -- 弧段求交的过滤线表达式。 在进行弧段求交时,通过该属性可以指定一个字段表达式,符合该表达式的线对象将不被打断。 该表达式是否有效,与 filter_mode 弧段求交过滤模式有关
- filter_mode (ArcAndVertexFilterMode or str) -- 弧段求交的过滤模式。
- options (ProcessingOptions or None) -- 拓扑处理参数类,如果 options 不为空,拓扑处理将会使用此参数设置的值。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 是否拓扑处理成功
返回类型: bool
-
iobjectspy.analyst.topology_build_regions(input_data, out_data=None, out_dataset_name=None, progress=None)¶ 用于将线数据集或者网络数据集,通过拓扑处理来构建面数据集。在进行拓扑构面前,最好能使用拓扑处理
topology_processing()对数据集进行拓扑处理。参数: - input_data (DatasetVector or str) -- 指定的用于进行多边形拓扑处理的源数据集,只能是线数据集或网络数据集。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据集的数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.pickup_border(input_data, is_preprocess=True, extract_ids=None, out_data=None, out_dataset_name=None, progress=None)¶ 提取面(或线)的边界,并保存为线数据集。若多个面(或线)共边界(线段),该边界(线段)只会被提取一次。
不支持重叠面提取边界。
参数: - input_data (DatasetVector or str) -- 指定的面或线数据集。
- is_preprocess (bool) -- 是否进行拓扑预处理
- extract_ids (list[int] or str) -- 指定的面ID数组,可选参数,仅会提取给定ID数组对应的面对象边界。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据集的数据源。
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
class
iobjectspy.analyst.PreprocessOptions(arcs_inserted=False, vertex_arc_inserted=False, vertexes_snapped=False, polygons_checked=False, vertex_adjusted=False)¶ 基类:
object拓扑预处理参数类
构造拓扑预处理参数类对象
参数: - arcs_inserted (bool) -- 是否进行线段间求交插入节点
- vertex_arc_inserted (bool) -- 否进行节点与线段间插入节点
- vertexes_snapped (bool) -- 是否进行节点捕捉
- polygons_checked (bool) -- 是否进行多边形走向调整
- vertex_adjusted (bool) -- 是否进行节点位置调整
-
arcs_inserted¶ bool -- 是否进行线段间求交插入节点
-
polygons_checked¶ bool -- 是否进行多边形走向调整
-
set_arcs_inserted(value)¶ 设置是否进行线段间求交插入节点
参数: value (bool) -- 是否进行线段间求交插入节点 返回: self 返回类型: PreprocessOptions
-
set_polygons_checked(value)¶ 设置是否进行多边形走向调整
参数: value (bool) -- 是否进行多边形走向调整 返回: self 返回类型: PreprocessOptions
-
set_vertex_adjusted(value)¶ 设置是否进行节点位置调整
参数: value (bool) -- 是否进行节点位置调整 返回: self 返回类型: PreprocessOptions
-
set_vertex_arc_inserted(value)¶ 设置否进行节点与线段间插入节点
参数: value (bool) -- 否进行节点与线段间插入节点 返回: self 返回类型: PreprocessOptions
-
set_vertexes_snapped(value)¶ 设置是否进行节点捕捉
参数: value (bool) -- 是否进行节点捕捉 返回: self 返回类型: PreprocessOptions
-
vertex_adjusted¶ bool -- 是否进行节点位置调整
-
vertex_arc_inserted¶ bool -- 否进行节点与线段间插入节点
-
vertexes_snapped¶ bool -- 是否进行节点捕捉
-
iobjectspy.analyst.preprocess(inputs, arcs_inserted=True, vertex_arc_inserted=True, vertexes_snapped=True, polygons_checked=True, vertex_adjusted=True, precisions=None, tolerance=1e-10, options=None, progress=None)¶ 对给定的拓扑数据集进行拓扑预处理。
参数: - inputs (DatasetVector or list[DatasetVector] or str or list[str] or Recordset or list[Recordset]) -- 输入数据集或记录集,如果是数据集,不能是只读。
- arcs_inserted (bool) -- 是否进行线段间求交插入节点
- vertex_arc_inserted (bool) -- 否进行节点与线段间插入节点
- vertexes_snapped (bool) -- 是否进行节点捕捉
- polygons_checked (bool) -- 是否进行多边形走向调整
- vertex_adjusted (bool) -- 是否进行节点位置调整
- precisions (list[int]) -- 指定的精度等级数组。精度等级的值越小,代表对应记录集的精度越高,数据质量越好。在进行顶点捕捉时,低精度的记录集中的点将被捕捉到高精度记录集中的点的位置上。精度等级数组必须与要进行拓扑预处理的记录集集合元素数量相同并一一对应。
- tolerance (float) -- 指定的处理时需要的容限控制。单位与进行拓扑预处理的记录集单位相同。
- options (PreprocessOption) -- 拓扑预处理参数类对象,如果此参数不为空,将优先使用此参数为拓扑预处理参数
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 拓扑预处理是否成功
返回类型: bool
-
iobjectspy.analyst.topology_validate(source_data, validating_data, rule, tolerance, validate_region=None, out_data=None, out_dataset_name=None, progress=None)¶ 对数据集或记录集进行拓扑错误检查,返回含有拓扑错误的结果数据集。
该方法的 tolerance 参数用于指定使用 rule 参数指定的拓扑规则对数据集检查时涉及的容限。例如,使用“线内无打折”(TopologyRule.LINE_NO_SHARP_ANGLE)规则检查时,tolerance 参数设置的为尖角容限(一个角度值)。
对于以下拓扑检查算子在调用该方法对数据进行拓扑检查之前,建议先对相应的数据进行拓扑预处理(即调用
preprocess()方法),否则检查的结果可能不正确:- REGION_NO_OVERLAP_WITH
- REGION_COVERED_BY_REGION_CLASS
- REGION_COVERED_BY_REGION
- REGION_BOUNDARY_COVERED_BY_LINE
- REGION_BOUNDARY_COVERED_BY_REGION_BOUNDARY
- REGION_NO_OVERLAP_ON_BOUNDARY
- REGION_CONTAIN_POINT
- LINE_NO_OVERLAP_WITH
- LINE_BE_COVERED_BY_LINE_CLASS
- LINE_END_POINT_COVERED_BY_POINT
- POINT_NO_CONTAINED_BY_REGION
- POINT_COVERED_BY_LINE
- POINT_COVERED_BY_REGION_BOUNDARY
- POINT_CONTAINED_BY_REGION
- POINT_BECOVERED_BY_LINE_END_POINT
对于以下拓扑检查算法需要设置参考数据集或记录集:
- REGION_NO_OVERLAP_WITH
- REGION_COVERED_BY_REGION_CLASS
- REGION_COVERED_BY_REGION
- REGION_BOUNDARY_COVERED_BY_LINE
- REGION_BOUNDARY_COVERED_BY_REGION_BOUNDARY
- REGION_CONTAIN_POINT
- REGION_NO_OVERLAP_ON_BOUNDARY
- POINT_BECOVERED_BY_LINE_END_POINT
- POINT_NO_CONTAINED_BY_REGION
- POINT_CONTAINED_BY_REGION
- POINT_COVERED_BY_LINE
- POINT_COVERED_BY_REGION_BOUNDARY
- LINE_NO_OVERLAP_WITH
- LINE_NO_INTERSECT_OR_INTERIOR_TOUCH
- LINE_BE_COVERED_BY_LINE_CLASS
- LINE_NO_INTERSECTION_WITH
- LINE_NO_INTERSECTION_WITH_REGION
- LINE_EXIST_INTERSECT_VERTEX
- VERTEX_DISTANCE_GREATER_THAN_TOLERANCE
- VERTEX_MATCH_WITH_EACH_OTHER
参数: - source_data (DatasetVector or str or Recordset) -- 被检查的数据集或记录集
- validating_data (DatasetVector or str or Recordset) -- 用于检查的参考记录集。如果使用的拓扑规则不需要参考记录集,则设置为 None
- rule (TopologyRule or str) -- 拓扑检查类型
- tolerance (float) -- 指定的拓扑错误检查时使用的容限。单位与进行拓扑错误检查的数据集单位相同。
- validate_region (GeoRegion) -- 被检查区域,None,则默认对整个拓扑数据集(validating_data)进行检查,否则对 validate_region 区域进行拓扑检查。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.split_lines_by_regions(line_input, region_input, progress=None)¶ 用面对象分割线对象。在提取线对象的左右多边形(即 pickupLeftRightRegions() 方法)操作前,需要调用该方法分割线对象,否则会出现一个线对象对应多个左(右)多边形的情形。 如下图:线对象 AB,如果不用面对象进行分割,则 AB 的左多边形有两个,分别为1,3;右多边形也有两个,分别为1和3,进行分割操作后,线对象 AB 分割为 AC 与 CB,此时 AC 与 CB 各自对应的左、右多边形分别只有一个。
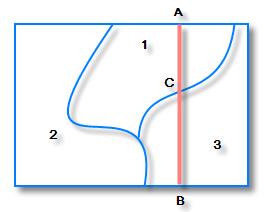
参数: - line_input (DatasetVector or Recordset) -- 指定的被分割的线记录集或数据集。
- region_input (DatasetVector or Recordset) -- 指定的用于分割线记录集的面记录集或数据集。
- progress (function) -- 处理进度信息的函数
返回: 成功返回 True,失败返回 False。
返回类型: bool
-
iobjectspy.analyst.integrate(source_dataset, tolerance, unit=None, precision_orders=None, progress=None) - 对数据集进行数据整合,整合的过程包括节点捕捉和插点操作。与 py:func:.preprocess: 的具有相似的功能,能将数据中的拓扑错误处理掉,与
- py:func:.preprocess: 的差别在于,数据整合会进行多次迭代,直到数据中没有拓扑错误为止(不需要节点捕捉和插点)。
>>> ds = open_datasource('E:/data.udb') >>> integrate(ds['building'], 1.0e-6) True >>> integrate(ds['street'], 1.0, 'meter') True >>> integrate([ds['street'], ds['poi']], 1.0, 'meter', [0,1]) True
参数: - source_dataset (DatasetVector or str or list[DatasetVector] or list[str]) -- 被处理的数据集或数据集几何
- tolerance (float) -- 结点容限
- unit (Unit or str) -- 节点容限单位,当为 None 时使用数据集坐标系单位。如果数据集坐标系为投影坐标系,禁止使用角度单位。
- precision_orders (list[int] or tuple[int]) -- 数据精度等级数组。精度等级的值越小,代表对应数据集的精度越高,数据质量越好。在进行顶点捕捉时,低精度的数据集中 的点将被捕捉到高精度数据集中的点的位置上。精度等级数组必须与要与输入的数据集集合元素数量相同并一一对应。如果 为 None,则每个数据集的精度都相同。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 成功返回 True,否则返回False
返回类型: bool
-
iobjectspy.analyst.measure_central_element(source, group_field=None, weight_field=None, self_weight_field=None, distance_method='EUCLIDEAN', stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 关于空间度量:
空间度量用来计算的数据可以是点、线、面。对于点、线和面对象,在距离计算中会使用对象的质心。对象的质心为所有子对象的加权 平均中心。点对象的加权项为1(即质心为自身),线对象的加权项是长度,而面对象的加权项是面积。
用户可以通过空间度量计算来解决以下问题:
- 数据的中心在哪里?
- 数据的分布呈什么形状和方向?
- 数据是如何分散布局?
空间度量包括中心要素(
measure_central_element())、方向分布(measure_directional())、 标准距离(measure_standard_distance())、方向平均值(measure_linear_directional_mean())、 平均中心(measure_mean_center())、中位数中心(measure_median_center())等。计算矢量数据的中心要素,返回结果矢量数据集。
- 中心要素是与其他所有对象质心的累积距离最小,位于最中心的对象。
- 如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。
- 实际上,距其他所有对象质心的累积距离最小的中心要素可能会有多个,但中心要素方法只会输出SmID 字段值最小的对象。
参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- group_field (str) -- 分组字段的名称
- weight_field (str) -- 权重字段的名称
- self_weight_field (str) -- 自身权重字段的名称
- distance_method (DistanceMethod or str) -- 距离计算方法类型
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个字典类型,字典类型的 key 为字段名,value 为统计类型。
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果矢量数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.measure_directional(source, group_field=None, ellipse_size='SINGLE', stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 计算矢量数据的方向分布,返回结果矢量数据集。
- 方向分布是根据所有对象质心的平均中心(有权重,为加权)为圆点,计算x和y坐标的标准差为轴得到的标准差椭圆。
- 标准差椭圆的圆心x和y坐标、两个标准距离(长半轴和短半轴)、椭圆的方向,分别储存在结果矢量数据集中的CircleCenterX、 CircleCenterY、SemiMajorAxis、SemiMinorAxis、RotationAngle字段中。如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。
- 椭圆的方向RotationAngle字段中的正值表示正椭圆(长半轴的方向为X轴方向, 短半轴的方向为Y轴方向))按逆时针旋转,负值表示 正椭圆按顺时针旋转。
- 输出的椭圆大小有三个级别:Single(一个标准差)、Twice(二个标准差)和Triple(三个标准差),详细介绍请参见
EllipseSize类。 - 用于计算方向分布的标准差椭圆算法是由D. Welty Lefever在1926年提出,用来度量数据的方向和分布。首先确定椭圆的圆心,即平均 中心(有权重,为加权);然后确定椭圆的方向;最后确定长轴和短轴的长度。

关于空间度量介绍,请参考
measure_central_element()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- group_field (str) -- 分组字段名称
- ellipse_size (EllipseSize or str) -- 椭圆大小类型
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个list类型,list 中存储2个元素的tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果矢量数据集
返回类型: DatasetVector or str
-
iobjectspy.analyst.measure_linear_directional_mean(source, group_field=None, weight_field=None, is_orientation=False, stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 计算线数据集的方向平均值,并返回结果矢量数据集。
- 线性方向平均值是根据所有线对象的质心的平均中心点为其中心、长度等于所有输入线对象的平均长度、方位或方向为由所有输入线对象 的起点和终点(每个线对象都只会使用起点和终点来确定方向)计算得到的平均方位或平均方向创建的线对象。
- 线对象的平均中心x和y坐标、平均长度、罗盘角、方向平均值、圆方差,分别储存在结果矢量数据集中的AverageX、AverageY、 AverageLength、CompassAngle、DirectionalMean、CircleVariance字段中。如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。
- 线对象的罗盘角(CompassAngle)字段表示以正北方为基准方向按顺时针旋转;方向平均值(DirectionalMean)字段表示以正东方为 基准方向按逆时针旋转;圆方差(CircleVariance)表示方向或方位偏离方向平均值的程度,如果输入线对象具有非常相似(或完全相同) 的方向则该值会非常小,反之则相反。
关于空间度量介绍,请参考
measure_central_element()参数: - source (DatasetVector or str) -- 待计算的数据集。为线数据集。
- group_field (str) -- 分组字段名称
- weight_field (str) -- 权重字段名称
- is_orientation (bool) -- 是否忽略起点和终点的方向。为 False 时,将在计算方向平均值时使用起始点和终止点的顺序;为 True 时,将忽略起始点和终止点的顺序。
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个list类型,list 中存储2个元素的tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.measure_mean_center(source, group_field=None, weight_field=None, stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 计算矢量数据的平均中心,返回结果矢量数据集。
- 平均中心是根据输入的所有对象质心的平均x和y坐标构造的点。
- 平均中心的x和y坐标分别储存在结果矢量数据集中的SmX和SmY字段中。如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。

关于空间度量介绍,请参考
measure_central_element()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- group_field (str) -- 分组字段
- weight_field (str) -- 权重字段
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个list类型,list 中存储2个元素的tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.measure_median_center(source, group_field, weight_field, stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 计算矢量数据的中位数中心,返回结果矢量数据集。
- 中位数中心是根据输入的所有对象质心,使用迭代算法找出到所有对象质心的欧式距离最小的点。
- 中位数中心的x和y坐标分别储存在结果矢量数据集中的SmX和SmY字段中。如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。
- 实际上,距所有对象质心的距离最小的点可能有多个,但中位数中心方法只会返回一个点。
- 用于计算中位数中心的算法是由Kuhn,Harold W.和Robert E. Kuenne在1962年提出的迭代加权最小二乘法(Weiszfeld算法),之后由 James E. Burt和Gerald M. Barber进一步概括。首先以平均中心(有权重,为加权)作为起算点,利用加权最小二乘法得到候选点,将 候选点重新作为起算点代入计算得到新的候选点,迭代计算直到候选点到所有对象质心的欧式距离最小为止。

关于空间度量介绍,请参考
measure_central_element()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- group_field (str) -- 分组字段
- weight_field (str) -- 权重字段
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个list类型,list 中存储2个元素的tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.measure_standard_distance(source, group_field, weight_field, ellipse_size='SINGLE', stats_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 计算矢量数据的标准距离,返回结果矢量数据集。
- 标准距离是根据所有对象质心的平均中心(有权重,为加权)为圆心,计算x和y坐标的标准距离为半径得到的圆。
- 圆的圆心x和y坐标、标准距离(圆的半径),分别储存在结果矢量数据集中的CircleCenterX、CircleCenterY、StandardDistance字 段中。如果设置了分组字段,则结果矢量数据集将包含 “分组字段名_Group” 字段。
- 输出的圆大小有三个级别:Single(一个标准差)、Twice(二个标准差)和Triple(三个标准差),详细介绍请参见
EllipseSize枚举类型。

关于空间度量介绍,请参考
measure_central_element()参数: - source (DatasetVector or str) -- 待计算的数据集。为线数据集
- group_field (str) -- 分组字段
- weight_field (str) -- 权重字段
- ellipse_size (EllipseSize or str) -- 椭圆大小类型
- stats_fields (list[tuple[str,SpatialStatisticsType]] or list[tuple[str,str]] or str) -- 统计字段的类型,为一个list类型,list 中存储2个元素的tuple,tuple的第一个元素为被统计的字段,第二个元素为统计类型
- out_data (DatasourceConnectionInfo or Datasource or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
class
iobjectspy.analyst.AnalyzingPatternsResult¶ 基类:
object分析模式结果类。该类用于获取分析模式计算的结果,包括结果指数、期望、方差、Z得分和P值等。
-
expectation¶ float -- 分析模式结果中的期望值
-
index¶ float -- 分析模式结果中的莫兰指数或GeneralG指数
-
p_value¶ float -- 分析模式结果中的P值
-
variance¶ float -- 分析模式结果中的方差值
-
z_score¶ float -- 分析模式结果中的Z得分
-
-
iobjectspy.analyst.auto_correlation(source, assessment_field, concept_model='INVERSEDISTANCE', distance_method='EUCLIDEAN', distance_tolerance=-1.0, exponent=1.0, k_neighbors=1, is_standardization=False, weight_file_path=None, progress=None)¶ 分析模式介绍:
分析模式可评估一组数据是形成离散空间模式、聚类空间模式或者随机空间模式。
分析模式用来计算的数据可以是点、线、面。对于点、线和面对象,在距离计算中会使用对象的质心。对象的质心为所有子对象的加权平均中心。点对象的加权项为1(即质心为自身),线对象的加权项是长度,而面对象的加权项是面积。
分析模式类采用推论式统计,会在进行统计检验时预先建立"零假设",假设要素或要素之间相关的值都表现为随机空间模式。
分析结果计算中会给出一个P值用来表示"零假设"的正确概率,用以判定是接受"零假设"还是拒绝"零假设"。
分析结果计算中会给出一个Z得分用来表示标准差的倍数,用以判定数据是呈聚类、离散或随机。
要拒绝"零假设",就必须要承担可能做出错误选择(即错误的拒绝"零假设")的风险。
下表显示了不同置信度下未经校正的临界P值和临界Z得分:

用户可以通过分析模式来解决以下问题:
- 数据集中的要素或数据集中要素关联的值是否发生空间聚类?
- 数据集的聚类程度是否会随时间变化?
分析模式包括空间自相关分析(
auto_correlation())、平均最近邻分析(average_nearest_neighbor())、 高低值聚类分析(high_or_low_clustering())、增量空间自相关分析(incremental_auto_correlation())等。对矢量数据集进行空间自相关分析,并返回空间自相关分析结果。空间自相关返回的结果包括莫兰指数、期望、方差、z得分、P值, 请参阅
AnalyzingPatternsResult类。
参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- assessment_field (str) -- 评估字段的名称。仅数值字段有效。
- concept_model (ConceptualizationModel or str) -- 空间关系概念化模型。默认值
ConceptualizationModel.INVERSEDISTANCE。 - distance_method (DistanceMethod or str) -- 距离计算方法类型
- distance_tolerance (float) --
中断距离容限。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.FIXEDDISTANCEBAND、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。为"反距离"和"固定距离"模型指定中断距离。"-1"表示计算并应用默认距离,此默认值为保证每个要 素至少有一个相邻的要素;"0"表示为未应用任何距离,则每个要素都是相邻要素。
- exponent (float) -- 反距离幂指数。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。 - k_neighbors (int) -- 相邻数目,目标要素周围最近的K个要素为相邻要素。仅对概念化模型设置为
ConceptualizationModel.KNEARESTNEIGHBORS时有效。 - is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- weight_file_path (str) -- 空间权重矩阵文件路径
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 空间自相关结果
返回类型:
-
iobjectspy.analyst.high_or_low_clustering(source, assessment_field, concept_model='INVERSEDISTANCE', distance_method='EUCLIDEAN', distance_tolerance=-1.0, exponent=1.0, k_neighbors=1, is_standardization=False, weight_file_path=None, progress=None)¶ 对矢量数据集进行高低值聚类分析,并返回高低值聚类分析结果。 高低值聚类返回的结果包括GeneralG指数、期望、方差、z得分、P值, 请参阅
AnalyzingPatternsResult类。
关于分析模式介绍,请参考
auto_correlation()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- assessment_field (str) -- 评估字段的名称。仅数值字段有效。
- concept_model (ConceptualizationModel or str) -- 空间关系概念化模型。默认值
ConceptualizationModel.INVERSEDISTANCE。 - distance_method (DistanceMethod or str) -- 距离计算方法类型
- distance_tolerance (float) --
中断距离容限。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.FIXEDDISTANCEBAND、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。为"反距离"和"固定距离"模型指定中断距离。"-1"表示计算并应用默认距离,此默认值为保证每个要 素至少有一个相邻的要素;"0"表示为未应用任何距离,则每个要素都是相邻要素。
- exponent (float) -- 反距离幂指数。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。 - k_neighbors (int) -- 相邻数目,目标要素周围最近的K个要素为相邻要素。仅对概念化模型设置为
ConceptualizationModel.KNEARESTNEIGHBORS时有效。 - is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- weight_file_path (str) -- 空间权重矩阵文件路径
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 高低值聚类结果
返回类型:
-
iobjectspy.analyst.average_nearest_neighbor(source, study_area, distance_method='EUCLIDEAN', progress=None)¶ 对矢量数据集进行平均最近邻分析,并返回平均最近邻分析结果数组。
- 平均最近邻返回的结果包括最近邻指数、预期平均距离、平均观测距离、z得分、P值,请参阅
AnalyzingPatternsResult类。 - 给定的研究区域面积大小必须大于等于0;如果研究区域面积等于0,则会自动生成输入数据集的最小面积外接矩形,用该矩形的面积来进行计算。 该默认值为: 0 。
- 距离计算方法类型可以指定相邻要素之间的距离计算方式(参阅
DistanceMethod)。如果输入数据集为地理坐标系,则会采用弦测量方法来 计算距离。地球表面上的任意两点,两点之间的弦距离为穿过地球体连接两点的直线长度。

关于分析模式介绍,请参考
auto_correlation()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- study_area (float) -- 研究区域面积
- distance_method (DistanceMethod or str) -- 距离计算方法
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 平均最近邻分析结果
返回类型: - 平均最近邻返回的结果包括最近邻指数、预期平均距离、平均观测距离、z得分、P值,请参阅
-
iobjectspy.analyst.incremental_auto_correlation(source, assessment_field, begin_distance=0.0, distance_method='EUCLIDEAN', incremental_distance=0.0, incremental_number=10, is_standardization=False, progress=None)¶ 对矢量数据集进行增量空间自相关分析,并返回增量空间自相关分析结果数组。增量空间自相关返回的结果包括增量距离、莫兰指数、期望、方差、z得分、P值, 请参阅
IncrementalResult类。增量空间自相关会为一系列的增量距离运行空间自相关方法(参考
auto_correlation()),空间关系概念化模型默认为固定距离 模型(参阅ConceptualizationModel.FIXEDDISTANCEBAND)关于分析模式介绍,请参考
auto_correlation()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- assessment_field (str) -- 评估字段的名称。仅数值字段有效。
- begin_distance (float) -- 增量空间自相关开始分析的起始距离。
- distance_method (DistanceMethod or str) -- 距离计算方法类型
- incremental_distance (float) -- 距离增量,增量空间自相关每次分析的间隔距离。
- incremental_number (int) -- 递增的距离段数目。为增量空间自相关指定分析数据集的次数,该值的范围为:2 ~ 30。
- is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 增量空间自相关分析结果列表。
返回类型: list[IncrementalResult]
-
class
iobjectspy.analyst.IncrementalResult¶ 基类:
iobjectspy._jsuperpy.analyst.ss.AnalyzingPatternsResult增量空间自相关结果类。该类用于获取增量空间自相关计算的结果,包括结果增量距离、莫兰指数、期望、方差、Z得分和P值等。
-
distance¶ float -- 增量空间自相关结果中的增量距离
-
-
iobjectspy.analyst.cluster_outlier_analyst(source, assessment_field, concept_model='INVERSEDISTANCE', distance_method='EUCLIDEAN', distance_tolerance=-1.0, exponent=1.0, is_FDR_adjusted=False, k_neighbors=1, is_standardization=False, weight_file_path=None, out_data=None, out_dataset_name=None, progress=None)¶ 聚类分布介绍:
聚类分布可识别一组数据具有统计显著性的热点、冷点或者空间异常值。
聚类分布用来计算的数据可以是点、线、面。对于点、线和面对象,在距离计算中会使用对象的质心。对象的质心为所有子对象的加权 平均中心。点对象的加权项为1(即质心为自身),线对象的加权项是长度,而面对象的加权项是面积。
用户可以通过聚类分布计算来解决以下问题:
- 聚类或冷点和热点出现在哪里?
- 空间异常值的出现位置在哪里?
- 哪些要素十分相似?
聚类分布包括聚类和异常值分析(
cluster_outlier_analyst())、热点分析(hot_spot_analyst())、 优化热点分析(optimized_hot_spot_analyst())等聚类和异常值分析,返回结果矢量数据集。
- 结果数据集中包括局部莫兰指数(ALMI_MoranI)、z得分(ALMI_Zscore)、P值(ALMI_Pvalue)和聚类和异常值类型(ALMI_Type)。
- z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的聚类和异常值。如果, 要素的Z得分是一个较高的正值,则表示周围的要素拥有相似值(高值或低值),聚类和异常值类型字段将具有统计显著性的高值聚类表示 为"HH",将具有统计显著性的低值聚类表示为"LL";如果,要素的Z得分是一个较低的负值值,则表示有一个具有统计显著性的空间数据异常 值,聚类和异常值类型字段将指出低值要素围绕高值要素表示为"HL",将高值要素围绕低值要素表示为"LH"。
- 在没有设置 is_FDR_adjusted,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。

参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- assessment_field (str) -- 评估字段的名称。仅数值字段有效。
- concept_model (ConceptualizationModel or str) -- 空间关系概念化模型。默认值
ConceptualizationModel.INVERSEDISTANCE。 - distance_method (DistanceMethod or str) -- 距离计算方法类型
- distance_tolerance (float) --
中断距离容限。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.FIXEDDISTANCEBAND、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。为"反距离"和"固定距离"模型指定中断距离。"-1"表示计算并应用默认距离,此默认值为保证每个要 素至少有一个相邻的要素;"0"表示为未应用任何距离,则每个要素都是相邻要素。
- exponent (float) -- 反距离幂指数。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。 - is_FDR_adjusted (bool) -- 是否进行FDR(错误发现率)校正。若进行FDR(错误发现率)校正,则统计显著性将以错误发现率校正为基础,否则,统计显著性将以P值和z得分字段为基础。
- k_neighbors (int) -- 相邻数目,目标要素周围最近的K个要素为相邻要素。仅对概念化模型设置为
ConceptualizationModel.KNEARESTNEIGHBORS时有效。 - is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- weight_file_path (str) -- 空间权重矩阵文件路径
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.hot_spot_analyst(source, assessment_field, concept_model='INVERSEDISTANCE', distance_method='EUCLIDEAN', distance_tolerance=-1.0, exponent=1.0, is_FDR_adjusted=False, k_neighbors=1, is_standardization=False, self_weight_field=None, weight_file_path=None, out_data=None, out_dataset_name=None, progress=None)¶ 热点分析,返回结果矢量数据集。
- 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl)。
- z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间 为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映置 信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
- 在没有设置 is_FDR_adjusted 方法的情况下,统计显著性以P值和Z字段为基础,否则,确定置信度的关键P值会降低以兼顾多重测试和空间依赖性。

关于聚类分布介绍,参考
cluster_outlier_analyst()参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- assessment_field (str) -- 评估字段的名称。仅数值字段有效。
- concept_model (ConceptualizationModel or str) -- 空间关系概念化模型。默认值
ConceptualizationModel.INVERSEDISTANCE。 - distance_method (DistanceMethod or str) -- 距离计算方法类型
- distance_tolerance (float) --
中断距离容限。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.FIXEDDISTANCEBAND、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。为"反距离"和"固定距离"模型指定中断距离。"-1"表示计算并应用默认距离,此默认值为保证每个要 素至少有一个相邻的要素;"0"表示为未应用任何距离,则每个要素都是相邻要素。
- exponent (float) -- 反距离幂指数。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。 - is_FDR_adjusted (bool) -- 是否进行 FDR(错误发现率)校正。若进行FDR(错误发现率)校正,则统计显著性将以错误发现率校正为基础,否则,统计显著性将以P值和z得分字段为基础。
- k_neighbors (int) -- 相邻数目,目标要素周围最近的K个要素为相邻要素。仅对概念化模型设置为
ConceptualizationModel.KNEARESTNEIGHBORS时有效。 - is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- self_weight_field (str) -- 自身权重字段的名称,仅数值字段有效。
- weight_file_path (str) -- 空间权重矩阵文件路径
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.optimized_hot_spot_analyst(source, assessment_field=None, aggregation_method='NETWORKPOLYGONS', aggregating_polygons=None, bounding_polygons=None, out_data=None, out_dataset_name=None, progress=None)¶ 优化的热点分析,返回结果矢量数据集。
- 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl),详细介绍请参阅
hot_spot_analyst()方法结果。 - z得分和P值都是统计显著性的度量,用于逐要素的判断是否拒绝"零假设"。置信区间字段会识别具有统计显著性的热点和冷点。置信区间 为+3和-3的要素反映置信度为99%的统计显著性,置信区间为+2和-2的要素反映置信度为95%的统计显著性,置信区间为+1和-1的要素反映 置信度为90%的统计显著性,而置信区间为0的要素的聚类则没有统计意义。
- 如果提供分析字段,则会直接执行热点分析; 如果未提供分析字段,则会利用提供的聚合方法(参阅
AggregationMethod)聚 合所有输入事件点以获得计数,从而作为分析字段执行热点分析。 - 执行热点分析时,默认概念化模型为
ConceptualizationModel.FIXEDDISTANCEBAND、错误发现率(FDR)为 True , 统计显著性将使用错误发现率(FDR)校正法自动兼顾多重测试和空间依赖性。

关于聚类分布介绍,参考
cluster_outlier_analyst()参数: - source (DatasetVector or str) -- 待计算的数据集。如果设置了评估字段,可以为点、线、面数据集,否则,则必须为点数据集。
- assessment_field (str) -- 评估字段的名称。
- aggregation_method (AggregationMethod or str) --
聚合方法。如果未设置提供分析字段,则需要为优化的热点分析提供的聚合方法。
- 如果设置为
AggregationMethod.AGGREGATIONPOLYGONS,则必须设置 aggregating_polygons - 如果设置为
AggregationMethod.NETWORKPOLYGONS,如果设置了 bounding_polygons,则使用 bounding_polygons 进行聚合,如果没有设置 bounding_polygons, 则使用点数据集的地理范围进行聚合。 - 如果设置为
AggregationMethod.SNAPNEARBYPOINTS, aggregating_polygons 和 bounding_polygons 都无效。
- 如果设置为
- aggregating_polygons (DatasetVector or str) -- 聚合事件点以获得事件计数的面数据集。如果未提供分析字段(assessment_field) 且 aggregation_method
设置为
AggregationMethod.AGGREGATIONPOLYGONS时,提供聚合事件点以获得事件计数的面数据集。 如果设置了评估字段,此参数无效。 - bounding_polygons (DatasetVector or str) -- 事件点发生区域的边界面数据集。必须为面数据集。如果未提供分析字段(assessment_field)且 aggregation_method
设置为
AggregationMethod.NETWORKPOLYGONS时,提供事件点发生区域的边界面数据集。 - out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源信息
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
- 结果数据集中包括z得分(Gi_Zscore)、P值(Gi_Pvalue)和置信区间(Gi_ConfInvl),详细介绍请参阅
-
iobjectspy.analyst.collect_events(source, out_data=None, out_dataset_name=None, progress=None)¶ 收集事件,将事件数据转换成加权数据。
- 结果点数据集中包含一个 Counts 字段,该字段会保存每个唯一位置所有质心的总和。
- 收集事件只会处理质心坐标完全相同的对象,并且只会保留一个质心,去除其余的重复点。
- 对于点、线和面对象,在距离计算中会使用对象的质心。对象的质心为所有子对象的加权平均中心。点对象的加权项为1(即质心为自身), 线对象的加权项是长度,而面对象的加权项是面积。
参数: - source (DatasetVector or str) -- 待收集的数据集。可以为点、线、面数据集。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果点数据集的数据源。
- out_dataset_name (str) -- 结果点数据集名称。
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.build_weight_matrix(source, unique_id_field, file_path, concept_model='INVERSEDISTANCE', distance_method='EUCLIDEAN', distance_tolerance=-1.0, exponent=1.0, k_neighbors=1, is_standardization=False, progress=None)¶ 构建空间权重矩阵。
- 空间权重矩阵文件旨在生成、存储、重用和共享一组要素之间关系的空间关系概念化模型。文件采用的是二进制文件格式创建,要素关系 存储为稀疏矩阵。
- 该方法会生成一个空间权重矩阵文件,文件格式为 ‘*.swmb’。生成的空间权重矩阵文件可用来进行分析,只要将空间关系概念化模型设
置为
ConceptualizationModel.SPATIALWEIGHTMATRIXFILE并且通过 weight_file_path 参数指定创建的空间权重矩阵 文件的完整路径。
参数: - source (DatasetVector or str) -- 待构建空间权重矩阵的数据集,支持点线面。
- unique_id_field (str) -- 唯一ID字段名,必须是数值型字段。
- file_path (str) -- 空间权重矩阵文件保存路径。
- concept_model (ConceptualizationModel or str) -- 概念化模型
- distance_method (DistanceMethod or str) -- 距离计算方法类型
- distance_tolerance (float) --
中断距离容限。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.FIXEDDISTANCEBAND、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。为"反距离"和"固定距离"模型指定中断距离。"-1"表示计算并应用默认距离,此默认值为保证每个要 素至少有一个相邻的要素;"0"表示为未应用任何距离,则每个要素都是相邻要素。
- exponent (float) -- 反距离幂指数。仅对概念化模型设置为
ConceptualizationModel.INVERSEDISTANCE、ConceptualizationModel.INVERSEDISTANCESQUARED、ConceptualizationModel.ZONEOFINDIFFERENCE时有效。 - k_neighbors (int) -- 相邻数目。仅对概念化模型设置为
ConceptualizationModel.KNEARESTNEIGHBORS时有效。 - is_standardization (bool) -- 是否对空间权重矩阵进行标准化。若进行标准化,则每个权重都会除以该行的和。
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 如果构建空间权重矩阵,返回 True,否则返回 False
返回类型: bool
-
iobjectspy.analyst.weight_matrix_file_to_table(file_path, out_data, out_dataset_name=None, progress=None)¶ 空间权重矩阵文件转换成属性表。
结果属性表包含源唯一ID字段(UniqueID)、相邻要素唯一ID字段(NeighborsID)、权重字段(Weight)。
参数: - file_path (str) -- 空间权重矩阵文件路径。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果属性表的数据源
- out_dataset_name (str) -- 结果属性表名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 结果属性表数据集或数据集名称。
返回类型: DatasetVector or str
-
iobjectspy.analyst.GWR(source, explanatory_fields, model_field, kernel_function='GAUSSIAN', band_width_type='AICC', distance_tolerance=0.0, kernel_type='FIXED', neighbors=2, out_data=None, out_dataset_name=None, progress=None, prediction_dataset=None, explanatory_fields_matching=None, out_predicted_name=None)¶ 空间关系建模介绍:
- 用户可以通过空间关系建模来解决以下问题:
- 为什么某一现象会持续的发生,是什么因素导致了这种情况?
- 导致某一事故发生率比预期的要高的因素有那些?有没有什么方法来减少整个城市或特定区域内的事故发生率?
- 对某种现象建模以预测其他地点或者其他时间的数值?
- 通过回归分析,你可以对空间关系进行建模、检查和研究,可以帮助你解释所观测到的空间模型后的诸多因素。比如线性关系是正或者 是负;对于正向关系,即存在正相关性,某一变量随着另一个变量增加而增加;反之,某一变量随着另一个变量增加而减小;或者两个变量无关系。
地理加权回归分析。
- 地理加权回归分析结果信息包含一个结果数据集和地理加权回归结果汇总(请参阅 GWRSummary 类)。
- 结果数据集包含交叉验证(CVScore)、预测值(Predicted)、回归系数(Intercept、C1_解释字段名)、残差(Residual)、标准误 (StdError)、系数标准误(SE_Intercept、SE1_解释字段名)、伪t值(TV_Intercept、TV1_解释字段名)和Studentised残差(StdResidual)等。
说明:
- 地理加权回归分析是一种用于空间变化关系的线性回归的局部形式,可用来在空间变化依赖和独立变量之间的关系研究。对地理要素所 关联的数据变量之间的关系进行建模,从而可以对未知值进行预测或者更好地理解可对要建模的变量产生影响的关键因素。回归方法使 你可以对空间关系进行验证并衡量空间关系的稳固性。
- 交叉验证(CVScore):交叉验证在回归系数估计时不包括回归点本身即只根据回归点周围的数据点进行回归计算。该值就是每个回归 点在交叉验证中得到的估计值与实际值之差,它们的平方和为CV值。作为一个模型性能指标。
- 预测值(Predicted):这些值是地理加权回归得到的估计值(或拟合值)。
- 回归系数(Intercept):它是地理加权回归模型的回归系数,为回归模型的回归截距,表示所有解释变量均为零时因变量的预测值。
- 回归系数(C1_解释字段名):它是解释字段的回归系数,表示解释变量与因变量之间的关系强度和类型。如果回归系数为正,则解释 变量与因变量之间的关系为正向的;反之,则存在负向关系。如果关系很强,则回归系数也相对较大;关系较弱时,则回归系数接近于0。
- 残差(Residual):这些是因变量无法解释的部分,是估计值和实际值之差,标准化残差的平均值为0,标准差为1。残差可用于确定模 型的拟合程度,残差较小表明模型拟合效果较好,可以解释大部分预测值,说明这个回归方程是有效的。
- 标准误(StdError):估计值的标准误差,用于衡量每个估计值的可靠性。较小的标准误表明拟合值与实际值的差异程度越小,模型拟合效果越好。
- 系数标准误(SE_Intercept、SE1_解释字段名):这些值用于衡量每个回归系数估计值的可靠性。系数的标准误差与实际系数相比较小 时,估计值的可信度会更高。较大的标准误差可能表示存在局部多重共线性问题。
- 伪t值(TV_Intercept、TV1_解释字段名):是对各个回归系数的显著性检验。当T值大于临界值时,拒绝零假设,回归系数显著即回归系 估计值是可靠的;当T值小于临界值时,则接受零假设,回归系数不显著。
- Studentised残差(StdResidual):残差和标准误的比值,该值可用来判断数据是否异常,若数据都在(-2,2)区间内,表明数据具 有正态性和方差齐性;若数据超出(-2,2)区间,表明该数据为异常数据,无方差齐性和正态性。
参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- explanatory_fields (list[str] or str) -- 解释字段的名称的集合
- model_field (str) -- 建模字段的名称
- kernel_function (KernelFunction or str) -- 核函数类型
- band_width_type (BandWidthType or str) -- 带宽确定方式
- distance_tolerance (float) -- 带宽范围
- kernel_type (KernelType or str) -- 带宽类型
- neighbors (int) -- 相邻数目。只有当带宽类型设置为
KernelType.ADAPTIVE且宽确定方式设置为BandWidthType.BANDWIDTH时有效。 - out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent - prediction_dataset (DatasetVector or str) -- 预测数据集
- explanatory_fields_matching (dict[str,str]) -- 预测数据集字段映射。表示模型的解释字段名称和与预测数据集字段名称的对应关系。 每个解释字段都应该在预测数据集中有对应的字段,如果没有设置对应关系,则预测数据集中 必须存在解释变量数组中的所有字段。
- out_predicted_name (str) -- 预测结果数据集的名称
返回: 返回一个三个元素的 tuple,tuple 的第一个元素为
GWRSummary,第二个元素为地理加权回归结果数据集, 第三个元素为地理加权回归预测结果数据集返回类型: tuple[GWRSummary, DatasetVector, DatasetVector]
- 用户可以通过空间关系建模来解决以下问题:
-
iobjectspy.analyst.GTWR(source, explanatory_fields, model_field, time_field, time_distance_unit='DAYS', kernel_function='GAUSSIAN', band_width_type='AICC', distance_tolerance=0.0, kernel_type='FIXED', neighbors=2, out_data=None, out_dataset_name=None, progress=None, prediction_dataset=None, prediction_time_field=None, explanatory_fields_matching=None, out_predicted_name=None)¶ 时空地理加权回归。
时空地理加权回归是经过扩展和改进的地理加权回归,能分析带有时间属性的空间坐标点,解决了模型总的时空非平稳性问题。 应用场景:
- 研究城市住宅在时间和空间方面的变化趋势 - 研究省域经济发展因素及其时空规律
>>> result = GTWR(ds['data'], 'FLOORSZ', 'PURCHASE', 'time_field', kernel_type='FIXED', kernel_function='GAUSSIAN', >>> band_width_type='CV', distance_tolerance=2000)
同时进行预测:
>>> result = GTWR(ds['data'], 'FLOORSZ', 'PURCHASE', 'time_field', kernel_type='FIXED', kernel_function='GAUSSIAN', >>> band_width_type='CV', distance_tolerance=2000, prediction_dataset=ds['predict'], >>> explanatory_fields_matching={'FLOORSZ': 'FLOORSZ'}, prediction_time_field='time_field')
参数: - source (DatasetVector or str) -- 待计算的数据集。可以为点、线、面数据集。
- explanatory_fields (list[str] or str) -- 解释字段的名称的集合
- model_field (str) -- 建模字段的名称
- time_field (str) -- 数据集时间字段名称
- time_distance_unit (TimeDistanceUnit or str) -- 时间距离单位。时间距离是 time_field 字段内两条记录的时间插值,时间距离需要统一转换到指定的时间距离单位下,比 如,时间间隔为60分钟,则相应的时间距离可以为:60 Minutes, 或1 Hours,或 1/24 Days等。不同的时间距离单位, 在不同的核函数中,权重可能不同。
- kernel_function (KernelFunction or str) -- 核函数类型
- band_width_type (BandWidthType or str) -- 带宽确定方式
- distance_tolerance (float) -- 带宽范围
- kernel_type (KernelType or str) -- 带宽类型
- neighbors (int) -- 相邻数目。只有当带宽类型设置为
KernelType.ADAPTIVE且宽确定方式设置为BandWidthType.BANDWIDTH时有效。 - out_data (Datasource or DatasourceConnectionInfo or str) -- 用于存储结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent - prediction_dataset (DatasetVector or str) -- 预测数据集
- prediction_time_field (str) -- 预测数据集时间字段名称。当设置了有效的预测数据集时才有效。
- explanatory_fields_matching (dict[str,str]) -- 预测数据集字段映射。表示模型的解释字段名称和与预测数据集字段名称的对应关系。 每个解释字段都应该在预测数据集中有对应的字段,如果没有设置对应关系,则预测数据集中 必须存在解释变量数组中的所有字段。
- out_predicted_name (str) -- 预测结果数据集的名称。当设置了有效的预测数据集时才有效。
返回: 返回一个三个元素的 tuple,tuple 的第一个元素为
GWRSummary,第二个元素为地理加权回归结果数据集, 第三个元素为地理加权回归预测结果数据集返回类型: tuple[GWRSummary, DatasetVector, DatasetVector]
-
class
iobjectspy.analyst.GWRSummary¶ 基类:
object地理加权回归结果汇总类。该类给出了地理加权回归分析的结果汇总,例如带宽、相邻数、残差平方和、AICc和判定系数等。
-
AIC¶ float -- 地理加权回归结果汇总中的AIC。与AICc类似,是衡量模型拟合优良性的一种标准,可以权衡所估计模型的复杂度和模型拟 合数据的优良性,在评价模型时是兼顾了简洁性和精确性。表明增加自由参数的数目提高了拟合的优良性,AIC鼓励数据的 拟合性,但是应尽量避免出现过度拟合的情况。所以优先考虑AIC值较小的,是寻找可以最好的解释数据但包含最少自由参 数的模型。
-
AICc¶ float -- 地理加权回归结果汇总中的AICc。当数据增加时,AICc收敛为AIC,也是模型性能的一种度量,有助与比较不同的回归模型。 考虑到模型复杂性,具有较低AICc值的模型将更好的拟合观测数据。AICc不是拟合度的绝对度量,但对于比较用于同一因变 量且具有不同解释变量的模型非常有用。如果两个模型的AICc值相差大于3,具有较低AICc值的模型将视为更佳的模型。
-
Edf¶ float -- 地理加权回归结果汇总中的有效自由度。数据的数目与有效的参数数量(EffectiveNumber)的差值,不一定是整数,可用 来计算多个诊断测量值。自由度较大的模型拟合度会较差,能够较好的反应数据的真实情况,统计量会变得比较可靠;反之, 拟合效果会较好,但是不能较好的反应数据的真实情况,模型数据的独立性被削弱,关联度增加。
-
R2¶ float -- 地理加权回归结果汇总中的判定系数(R2)。判定系数是拟合度的一种度量,其值在0.0和1.0范围内变化,值越大模型越好。 此值可解释为回归模型所涵盖的因变量方差的比例。R2计算的分母为因变量值的平方和,添加一个解释变量不会更改分母但是 会更改分子,这将出现改善模型拟合的情况,但是也可能假象。
-
R2_adjusted¶ float -- 地理加权回归结果汇总中的校正的判定系数。校正的判定系数的计算将按分子和分母的自由度对它们进行正规化。这具有对 模型中变量数进行补偿的效果,由于校正的R2值通常小于R2值。但是,执行校正时,无法将该值的解释作为所解释方差的比例。 自由度的有效值是带宽的函数,因此,AICc是对模型进行比较的首选方式。
-
band_width¶ float -- 地理加权回归结果汇总中的带宽范围。
- 用于各个局部估计的带宽范围,它控制模型中的平滑程度。通常,你可以选择默认的带宽范围,方法是:设置带宽确定
方式(kernel_type)方法选择
BandWidthType.AICC或BandWidthType.CV,这两个选项都将尝试识别最佳带宽范围。 - 由于"最佳"条件对于 AIC 和 CV 并不相同,都会得到相对的最优 AICc 值和 CV 值,因而通常会获得不同的最佳值。
- 可以通过设置带宽类型(kernel_type)方法提供精确的带宽范围。
- 用于各个局部估计的带宽范围,它控制模型中的平滑程度。通常,你可以选择默认的带宽范围,方法是:设置带宽确定
方式(kernel_type)方法选择
-
effective_number¶ float -- 地理加权回归结果汇总中的有效的参数数量。反映了估计值的方差与系数估计值的偏差之间的折衷,该值与带宽的选择有关, 可用来计算多个诊断测量值。对于较大的带宽,系数的有效数量将接近实际参数数量,局部系数估计值将具有较小的方差, 但是偏差将会非常大;对于较小的带宽,系数的有效数量将接近观测值的数量,局部系数估计值将具有较大的方差,但是偏 差将会变小。
-
neighbours¶ int -- 地理加权回归结果汇总中的相邻数目。
- 用于各个局部估计的相邻数目,它控制模型中的平滑程度。通常,你可以选择默认的相邻点值,方法是:设置带宽确定方式(kernel_type)
方法选择
BandWidthType.AICC或BandWidthType.CV,这两个选项都将尝试识别最佳自适应相邻点数目。 - 由于"最佳"条件对于 AIC 和 CV 并不相同,都会得到相对的最优 AICc 值和 CV 值,因而通常会获得不同的最佳值。
- 可以通过设置带宽类型(kernel_type)方法提供精确的自适应相邻点数目。
- 用于各个局部估计的相邻数目,它控制模型中的平滑程度。通常,你可以选择默认的相邻点值,方法是:设置带宽确定方式(kernel_type)
方法选择
-
residual_squares¶ float -- 地理加权回归结果汇总中的残差平方和。残差平方和为实际值与估计值(或拟合值)的平方之和。此测量值越小,模型越 拟合观测数据,即拟合程度越好。
-
sigma¶ float -- 地理加权回归结果汇总中的残差估计标准差。残差的估计标准差,为剩余平方和除以残差的有效自由度的平方根。此统计值 越小,模型拟合效果越好。
-
-
class
iobjectspy.analyst.OLSSummary(java_object)¶ 基类:
object普通最小二乘法结果汇总类。该类给出了普通最小二乘法分析的结果汇总,例如分布统计量、统计量概率、AICc和判定系数等。
-
AIC¶ float -- 普通最小二乘法结果汇总中的AIC。与AICc类似,是衡量模型拟合优良性的一种标准,可以权衡所估计模型的复杂度和模型拟合数 据的优良性,在评价模型时是兼顾了简洁性和精确性。表明增加自由参数的数目提高了拟合的优良性,AIC鼓励数据的拟合性,但是应尽量避 免出现过度拟合的情况。所以优先考虑AIC值较小的,是寻找可以最好的解释数据但包含最少自由参数的模型
-
AICc¶ float -- 普通最小二乘法结果汇总中的AICc。当数据增加时,AICc收敛为AIC,也是模型性能的一种度量,有助与比较不同的回归模型。 考虑到模型复杂性,具有较低AICc值的模型将更好的拟合观测数据。AICc不是拟合度的绝对度量,但对于比较用于同一因变量且具有不同解 释变量的模型非常有用。如果两个模型的AICc值相差大于3,具有较低AICc值的模型将视为更佳的模型。
-
F_dof¶ int -- 普通最小二乘法结果汇总中的联合F统计量自由度。
-
F_probability¶ float -- 普通最小二乘法结果汇总中的联合F统计量的概率。
-
JB_dof¶ int -- 普通最小二乘法结果汇总中的Jarque-Bera统计量自由度。
-
JB_probability¶ float -- 普通最小二乘法结果汇总中的Jarque-Bera统计量的概率
-
JB_statistic¶ float -- 普通最小二乘法结果汇总中的Jarque-Bera统计量。Jarque-Bera统计量能评估模型的偏差,用于指示残差是否呈正态分布。检 验的零假设为残差呈正态分布。对于大小为95%的置信度,联合F统计量概率小于0.05表示模型具有统计显著性,回归不会呈正态分布,模型有 偏差。
-
KBP_dof¶ int -- 普通最小二乘法结果汇总中的Koenker(Breusch-Pagan)统计量自由度。
-
KBP_probability¶ float -- 普通最小二乘法结果汇总中的Koenker(Breusch-Pagan)统计量的概率
-
KBP_statistic¶ float -- 普通最小二乘法结果汇总中的Koenker(Breusch-Pagan)统计量。Koenker(Breusch-Pagan)统计量能评估模型的稳态,用 于确定模型的解释变量是否在地理空间和数据空间中都与因变量具有一致的关系。检验的零假设为检验的模型是稳态的。对于大小为95%的 置信度,联合F统计量概率小于0.05表示模型具有统计显著异方差性或非稳态。当检验结果具有显著性时,则需要参考稳健系数标准差和 概率来评估每个解释变量的效果。
-
R2¶ float -- 普通最小二乘法结果汇总中的判定系数(R2)。
-
R2_adjusted¶ float -- 普通最小二乘法结果汇总中的校正的判定系数
-
VIF¶ list[float] -- 普通最小二乘法结果汇总中的方差膨胀因子
-
coefficient¶ list[float] -- 普通最小二乘法结果汇总中的系数。 系数表示解释变量和因变量之间的关系和类型。
-
coefficient_std¶ list[float] -- 普通最小二乘法结果汇总中的系数标准差
-
f_statistic¶ float -- 普通最小二乘法结果汇总中的联合F统计量。联合F统计量用于检验整个模型的统计显著性。只有在Koenker(Breusch-Pagan) 统计量不具有统计显著性时,联合F统计量才可信。检验的零假设为模型中的解释变量不起作用。对于大小为95%的置信度,联合F统计量概率小 于0.05表示模型具有统计显著性。
-
probability¶ list[float] -- 普通最小二乘法结果汇总中的t分布统计量概率
-
robust_Pr¶ list[float] -- 普通最小二乘法结果汇总中的稳健系数概率。
-
robust_SE¶ list[float] -- 获取普通最小二乘法结果汇总中的稳健系数标准差。
-
robust_t¶ list[float] -- 普通最小二乘法结果汇总中的稳健系数t分布统计量。
-
sigma2¶ float -- 普通最小二乘法结果汇总中的残差方差。
-
std_error¶ list[float] -- 普通最小二乘法结果汇总中的标准误差。
-
t_statistic¶ list[float] -- 普通最小二乘法结果汇总中的t分布统计量。
-
variable¶ list[float] -- 普通最小二乘法结果汇总中的变量数组
-
wald_dof¶ int -- 普通最小二乘法结果汇总中的联合卡方统计量自由度
-
wald_probability¶ float -- 普通最小二乘法结果汇总中的联合卡方统计量的概率
-
wald_statistic¶ float -- 普通最小二乘法结果汇总中的联合卡方统计量。联合卡方统计量用于检验整个模型的统计显著性。只有在 Koenker(Breusch-Pagan)统计量具有统计显著性时,联合F统计量才可信。检验的零假设为模型中的解释变量不起作用。对于大小为 95%的置信度,联合F统计量概率小于0.05表示模型具有统计显著性。
-
-
iobjectspy.analyst.ordinary_least_squares(input_data, explanatory_fields, model_field, out_data=None, out_dataset_name=None, progress=None)¶ 普通最小二乘法。 普通最小二乘法分析结果信息包含一个结果数据集和普通最小二乘法结果汇总。 结果数据集包含预测值(Estimated)、残差(Residual)、标准化残差(StdResid)等。
说明:
- 预测值(Estimated):这些值是普通最小二乘法得到的估计值(或拟合值)。
- 残差(Residual):这些是因变量无法解释的部分,是估计值和实际值之差,标准化残差的平均值为0,标准差为1。残差可用于确定模型的拟合程度,残差较小表明模型拟合效果较好,可以解释大部分预测值,说明这个回归方程是有效的。
- 标准化残差(StdResid):残差和标准误的比值,该值可用来判断数据是否异常,若数据都在(-2,2)区间内,表明数据具有正态性和方差齐性;若数据超出(-2,2)区间,表明该数据为异常数据,无方差齐性和正态性。
参数: - input_data (DatasetVector or str) -- 指定的待计算的数据集。可以为点、线、面数据集。
- explanatory_fields (list[str] or str) -- 解释字段的名称的集合
- model_field (str) -- 建模字段的名称
- out_data (Datasource or str) -- 指定的用于存储结果数据集的数据源。
- out_dataset_name (str) -- 指定的结果数据集名称
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 返回一个元组,元组的第一个元素为最小二乘法结果数据集或数据集名称,第二个元素为最小二乘法结果汇总
返回类型: tuple[DatasetVector, OLSSummary] or tuple[str, OLSSummary]
-
class
iobjectspy.analyst.InteractionDetectorResult(java_object)¶ 基类:
object交互作用探测器分析结果,用于获取对数据进行交互作用探测器得到的分析结果,包括不同解释变量之间交互作用的描述以及分析结果矩阵。 用户不能创建此对象。
-
descriptions¶ list[str] -- 交互作用探测器结果描述。评估不同解释变量共同作用时是否会增加或减弱对因变量的解释力,或这些因子对因变量的影响 是否相互独立,两个解释变量对因变量交互作用的类型包括:非线性减弱、单因子非线性减弱、双因子增强、独立及非线性增强。
-
interaction_values¶ pandas.DataFrame -- 交互作用探测器分析结果值。
-
-
class
iobjectspy.analyst.RiskDetectorMean(java_object)¶ 基类:
object风险探测器结果均值类,用于获取对数据进行风险区域探测器得到的不同解释变量字段的结果均值。
-
means¶ list[float] -- 风险探测器分析结果均值
-
unique_values¶ list[str] -- 风险探测器解释变量字段唯一值
-
variable¶ str -- 风险探测器解释变量名称
-
-
class
iobjectspy.analyst.RiskDetectorResult(java_object)¶ 基类:
object风险区探测器分析结果类,用于获取对数据进行风险区探测器得到的分析结果,包括结果均值、结果矩阵
-
means¶ list[iobjectspy.RiskDetectorMean] -- 风险区探测器结果均值
-
values¶ list[pandas.DataFrame] -- 风险探测器分析结果值
-
-
class
iobjectspy.analyst.GeographicalDetectorResult(java_object)¶ 基类:
object地理探测器结果类,用于获取地理探测器计算的结果,包括因子探测器、生态探测器、交互作用探测器、风险探测器分析结果。
-
ecological_detector_result¶ pandas.DataFrame -- 生态探测器分析结果。生态探测器用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,以 F 统计量来衡量。
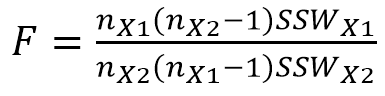
-
factor_detector_result¶ pandas.DataFrame -- 因子探测器分析结果。探测Y的空间分异性,以及探测某因子 X 多大程度上解释了属性Y的空间分异。用 q 值度量.
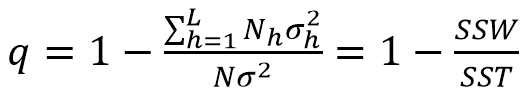
q 的值域为[0,1],值越大,说明 y 的空间分异越明显,如果分层是由自变量 X 生成的,则 q 值越大,表示 X 和 Y 的空间分布越一致, 自变量 X 对属性 Y 的解释力越强,反之则越弱。极端情况下,q 值为1表明在 X 的层内,Y的方差为0,即因子 X 完全控制了 Y 的空间分布, q 值为0 则表明 Y 按照 X 分层后的方差和与 Y 不分层的方差相等,Y 没有按照 X 进行分异,即因子 X 与 Y 没有任何关系。q 值 表示 X 解释了 100q% 的 Y。
-
interaction_detector_result¶ InteractionDetectorResult -- 交互作用探测器分析结果。识别不同风险因子 Xs 之间的交互作用,即评估因子 X1 和 X2 共同作用时 是否会增加或减弱对因变量Y的解释力,或这些因子对 Y 的影响是相互独立的?评估的方法是首先分别 计算两种因子 X1 和 X2 对 Y 的 q 值: q(Y|X1) 和 q(Y|X2)。然后叠加变量 X1 和 X2 两个图层相切所形成的新的层,计算 X1∩X2 对 Y 的 q 值: q(Y|X1∩X2)。最后,对 q(Y|X1)、q(Y|X2) 与 q(Y|X1∩X2) 的数值进行比较,判断交互作用。
- q(X1∩X2) < Min(q(X1),q(X2)) 非线性减弱
- Min(q(X1),q(X2)) < q(X1∩X2) < Max(q(X1),q(X2)) 单因子非线性减弱
- q(X1∩X2) > Max(q(X1),q(X2)) 双因子增强
- q(X1∩X2) = q(X1) + q(X2) 独立
- q(X1∩X2) > q(X1) + q(X2) 非线性增强
-
risk_detector_result¶ RiskDetectorResult -- 风险区探测器分析结果。用于判断两个子区域间的属性均值是否有显著的差别,用 t 统计量来检验。
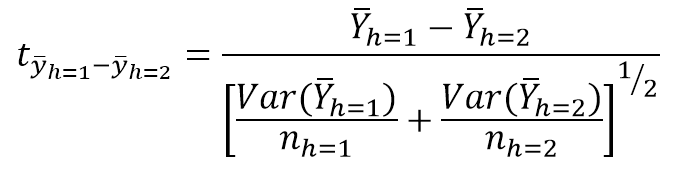
-
variables¶ list[str] -- 地理探测器解释变量
-
-
iobjectspy.analyst.geographical_detector(input_data, model_field, explanatory_fields, is_factor_detector=True, is_ecological_detector=True, is_interaction_detector=True, is_risk_detector=True, progress=None)¶ 对数据进行地理探测器分析,并返回地理探测器的结果。 地理探测器返回的结果包括因子探测器,生态探测器,交互探测器,风险探测器的分析结果
地理探测器是探测空间分异性,以及揭示其背后驱动力的一组统计学方法。其核心思想是基于这样的假设:如果某个自变量对某个因变量有重要影 响,那么自变量和因变量的空间分布应该具有相似性。地理分异既可以用分类算法来表达,例如环境遥感分类,也可以根据经验确定,例如胡焕庸线。 地理探测器擅长分析类型量,而对于顺序量、比值量或间隔量,只要进行适当的离散化,也可以利用地理探测器对其进行统计分析。 因此,地理探测器既可以探测数值型数据,也可以探测定性数据,这正是地理探测器的一大优势。地理探测器的另一个独特优势是探测两因子交互 作用于因变量。交互作用一般的识别方法是在回归模型中增加两因子的乘积项,检验其统计显著性。然而,两因子交互作用不一定就是相乘关系。 地理探测器通过分别计算和比较各单因子 q 值及两因子叠加后的 q 值,可以判断两因子是否存在交互作用,以及交互作用的强弱、方向、线性还是 非线性等。两因子叠加既包括相乘关系,也包括其他关系,只要有关系,就能检验出来。
参数: - input_data (DatasetVector or str) -- 待计算的矢量数据集
- model_field (str) -- 建模字段
- explanatory_fields (list[str] or str) -- 解释变量数组
- is_factor_detector (bool) -- 是否计算因子探测器
- is_ecological_detector (bool) -- 是否计算生态探测器
- is_interaction_detector (bool) -- 是否计算交互探测器
- is_risk_detector (bool) -- 是否进行风险探测器
- progress (function) -- 进度信息,具体参考
StepEvent
返回: 地理探测器结果
返回类型:
-
iobjectspy.analyst.density_based_clustering(input_data, min_pile_point_count, search_distance, unit, out_data=None, out_dataset_name=None, progress=None)¶ 密度聚类的DBSCAN实现
该方法根据给定的搜索半径(search_distance)和该范围内需包含的最少点数(min_pile_point_count)将空间点数据中密度足够大且空间相近的区域相连,并消除噪声的干扰,以达到较好的聚类效果。
参数: - input_data (DatasetVector or str) -- 指定的要聚类的矢量数据集,支持点数据集。
- min_pile_point_count (int) -- 每类包含的最少点数
- search_distance (int) -- 搜索邻域的距离
- unit (Unit) -- 搜索距离的单位
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.hierarchical_density_based_clustering(input_data, min_pile_point_count, out_data=None, out_dataset_name=None, progress=None)¶ 密度聚类的HDBSCAN实现
该方法是对DBSCAN方法的改进,只需给定空间邻域范围内的最少点数(min_pile_point_count)。在DBSCAN的基础上,计算不同的搜索半径选择最稳定的空间聚类分布作为密度聚类结果。
参数: - input_data (DatasetVector or str) -- 指定的要聚类的矢量数据集,支持点数据集。
- min_pile_point_count (int) -- 每类包含的最少点数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.ordering_density_based_clustering(input_data, min_pile_point_count, search_distance, unit, cluster_sensitivity, out_data=None, out_dataset_name=None, progress=None)¶ 密度聚类的OPTICS实现
该方法在DBSCAN的基础上,额外计算了每个点的可达距离,并基于排序信息和聚类系数(cluster_sensitivity)得到聚类结果。该方法对于搜索半径(search_distance)和该范围内需包含的最少点数(min_pile_point_count)不是很敏感,主要决定结果的是聚类系数(cluster_sensitivity)
概念定义: - 可达距离:取核心点的核心距离和其到周围临近点距离的最大值。 - 核心点:某个点在搜索半径内,存在点的个数不小于每类包含的最少点数(min_pile_point_count)。 - 核心距离:某个点成为核心点的最小距离。 - 聚类系数:为1~100的整数,是对聚类类别多少的标准量化,系数为1时聚类类别最少、100最多。
参数: - input_data (DatasetVector or str) -- 指定的要聚类的矢量数据集,支持点数据集。
- min_pile_point_count (int) -- 每类包含的最少点数
- search_distance (int) -- 搜索邻域的距离
- unit (Unit) -- 搜索距离的单位
- cluster_sensitivity (int) -- 聚类系数
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.analyst.spa_estimation(source_dataset, reference_dataset, source_unique_id_field, source_data_field, reference_unique_id_field, reference_data_fields, out_data=None, out_dataset_name=None, progress=None)¶ 单点地域估计(SPA)
参数: - source_dataset (DataetVector or str) -- 源数据集
- reference_dataset (DataetVector or str) -- 参考数据集
- source_unique_id_field (str) -- 源数据集唯一 ID 字段名称
- source_data_field (str) -- 源数据集数据字段名称
- reference_unique_id_field (str) -- 参考数据集唯一字段名称
- reference_data_fields (list[str] or tuple[str] or str) -- 参考数据集数据字段名称集合
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在数据源
- out_dataset_name (str) -- 输出数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果数据集
返回类型:
-
iobjectspy.analyst.bshade_estimation(source_dataset, historical_dataset, source_data_fields, historical_fields, estimate_method='TOTAL', out_data=None, out_dataset_name=None, progress=None)¶ BShade预测
参数: - source_dataset (DatasetVector or str) -- 源数据集
- historical_dataset (DatasetVector or str) -- 历史数据集
- source_data_fields (list[str] or tuple[str] or str) -- 源数据集数据字段名称集合
- historical_fields (list[str] or tuple[str] or str) -- 历史数据集数据字段名称集合
- estimate_method (BShadeEstimateMethod or str) -- 估计方法。包括总量和均值两种方法。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在数据源
- out_dataset_name (str) -- 输出数据集的名称。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 分析结果
返回类型:
-
iobjectspy.analyst.bshade_sampling(historical_dataset, historical_fields, parameter, progress=None)¶ BShade抽样。
参数: - historical_dataset (DatasetVector or str) -- 历史数据集。
- historical_fields (list[str] or tuple[str] or str) -- 历史数据集数据字段名称集合。
- parameter (BShadeSamplingParameter) -- 参数设置。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 分析结果。
返回类型: list[BShadeSamplingResult]
-
class
iobjectspy.analyst.BShadeSampleNumberMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - BShadeEstimateMethod.FIXED -- 使用固定字段数目。
- BShadeEstimateMethod.RANGE -- 使用范围字段抽样数目。
-
FIXED= 1¶
-
RANGE= 2¶
-
class
iobjectspy.analyst.BShadeEstimateMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - BShadeEstimateMethod.TOTAL -- 总量方法,即按照样本与总体之比值。
- BShadeEstimateMethod.MEAN -- 均值方法,即按照样本均值与总体均值的比值。
-
MEAN= 2¶
-
TOTAL= 1¶
-
class
iobjectspy.analyst.BShadeSamplingParameter¶ 基类:
objectBShade抽样参数。
在抽样过程中会用到模拟退火算法,该方法中将包含模拟退火算法的多个参数。模拟退火算法是用来求解函数最小值的。
-
bshade_estimate_method¶ BShadeEstimateMethod -- BShade估计方法
-
bshade_sample_number_method¶ BShadeSampleNumberMethod -- BShade抽样数目方法
-
cool_rate¶ float
-
initial_temperature¶ float -- 起始温度
-
max_consecutive_rejection¶ int -- 最大连续拒绝数目
-
max_full_combination¶ int -- 最大字段组合数目
-
max_success¶ int -- 在一个温度内的最大成功数目
-
max_try¶ int -- 最大尝试数目
-
min_energy¶ float -- 最小能量,即停止能量
-
min_temperature¶ float -- 最小温度,即停止温度
-
select_sample_number¶ int -- 选择样本数目
-
select_sample_range_lower¶ int -- 范围抽样数目下限
-
select_sample_range_step¶ int -- 范围抽样步长
-
select_sample_range_upper¶ int -- 范围抽样数目上限
-
set_bshade_estimate_method(value)¶ 设置BShade估计方法。即按照总量或者均值计算样本
参数: value (BShadeEstimateMethod or str) -- BShade估计方法,默认值为 TOTAL 返回: self 返回类型: BShadeSamplingParameter
-
set_bshade_sample_number_method(value)¶ 设置BShade抽样数目方法。默认值为 FIXED
参数: value (BShadeSampleNumberMethod or str) -- BShade抽样数目方法 返回: self 返回类型: BShadeSamplingParameter
-
set_cool_rate(value)¶ 设置退火速率
参数: value (float) -- 退火速率 返回: self 返回类型: BShadeSamplingParameter
-
set_initial_temperature(value)¶ 设置起始温度
参数: value (float) -- 起始温度 返回: self 返回类型: BShadeSamplingParameter
-
set_max_consecutive_rejection(value)¶ 设置最大连续拒绝数目
参数: value (int) -- 最大连续拒绝数目 返回: self 返回类型: BShadeSamplingParameter
-
set_max_full_combination(value)¶ 设置最大字段组合数目
参数: value (int) -- 最大字段组合数目 返回: self 返回类型: BShadeSamplingParameter
-
set_max_success(value)¶ 设置在一个温度内的最大成功数目
参数: value (int) -- 最大成功数目 返回: self 返回类型: BShadeSamplingParameter
-
set_max_try(value)¶ 设置最大尝试数目
参数: value (int) -- 最大尝试数目 返回: self 返回类型: BShadeSamplingParameter
-
set_min_energy(value)¶ 设置最小能量,即停止能量
参数: value (float) -- 最小能量,即停止能量 返回: self 返回类型: BShadeSamplingParameter
-
set_min_temperature(value)¶ 设置最小温度,即停止温度
参数: value (float) -- 最小温度,即停止温度 返回: self 返回类型: BShadeSamplingParameter
-
set_select_sample_number(value)¶ 设置选择样本数目
参数: value (int) -- 选择样本数目 返回: self 返回类型: BShadeSamplingParameter
-
set_select_sample_range_l(value)¶ 设置范围抽样数目下限
参数: value (int) -- 范围抽样数目下限 返回: self 返回类型: BShadeSamplingParameter
-
set_select_sample_range_step(value)¶ 设置范围抽样步长
参数: value (int) -- 范围抽样步长 返回: self 返回类型: BShadeSamplingParameter
-
set_select_sample_range_u(value)¶ 设置范围抽样数目上限
参数: value (int) -- 范围抽样数目上限 返回: self 返回类型: BShadeSamplingParameter
-
-
class
iobjectspy.analyst.BShadeSamplingResult¶ 基类:
objectBShade抽样结果
-
estimate_variance¶ float -- 估计方差
-
sample_number¶ int -- 抽样字段数目
-
solution_names¶ list[str] -- 字段名称数组
-
to_dict()¶ 转成 dict。
返回: 用于描述 BShade 抽样结果的字典对象 返回类型: dict[str, object]
-
weights¶ list[float] -- 权重数组
-
-
class
iobjectspy.analyst.BShadeEstimationResult¶ 基类:
objectBShade估计结果
-
dataset¶ DatasetVector -- BShade估计结果数据集
-
to_dict()¶ 转成 dict。
返回: 用于描述 BShade 估计结果的字典对象。 返回类型: dict[str, object]
-
variance¶ float -- 估计方差
-
weights¶ list[float] -- 权重数组
-
-
class
iobjectspy.analyst.WeightFieldInfo(weight_name, ft_weight_field, tf_weight_field)¶ 基类:
object权值字段信息类。
存储了网络分析中权值字段的相关信息,包括正向权值字段与反向权值字段。权值字段是表示花费的权重值的字段。正向权值字段值表示沿弧段的 起点到终点所需的耗费。反向权值字段值表示沿弧段的终点到起点所需的耗费。
初始化对象
参数: - weight_name (str) -- 权值字段信息的名称
- ft_weight_field (str) -- 正向权值字段或字段表达式
- tf_weight_field (str) -- 反向权值字段或字段表达式
-
ft_weight_field¶ str -- 正向权值字段或字段表达式
-
set_ft_weight_field(value)¶ 设置正向权值字段或字段表达式
参数: value (str) -- 正向权值字段或字段表达式 返回: self 返回类型: WeightFieldInfo
-
set_tf_weight_field(value)¶ 设置反向权值字段或字段表达式
参数: value (str) -- 反向权值字段或字段表达式 返回: self 返回类型: WeightFieldInfo
-
set_weight_name(value)¶ 设置权值字段信息的名称
参数: value (str) -- 权值字段信息的名称 返回: self 返回类型: WeightFieldInfo
-
tf_weight_field¶ str -- 反向权值字段或字段表达式
-
weight_name¶ str -- 权值字段信息的名称
-
class
iobjectspy.analyst.PathAnalystSetting¶ 基类:
object最佳路径分析环境设置,该类抽象基类,用户可以选择使用
SSCPathAnalystSetting或TransportationPathAnalystSetting-
network_dataset¶ DatasetVector -- 网络数据集
-
set_network_dataset(dataset)¶ 设置用于最佳路径分析的网络数据集
参数: dataset (DatasetVetor or str) -- 网络数据集 返回: 当前对象 返回类型: PathAnalystSetting
-
-
class
iobjectspy.analyst.SSCPathAnalystSetting(network_dt=None, ssc_file_path=None)¶ 基类:
iobjectspy._jsuperpy.analyst.na.PathAnalystSetting基于 SSC 文件的最佳路径分析环境设置
参数: - network_dt (DatasetVector) -- 网络数据集名称
- ssc_file_path (str) -- SSC 文件路径
-
set_ssc_file_path(value)¶ 设置 SSC 文件路径
参数: value (str) -- SSC 文件路径 返回: 当前对象 返回类型: SSCPathAnalystSetting
-
set_tolerance(value)¶ 设置节点容限
参数: value (float) -- 节点容限 返回: 当前对象 返回类型: SSCPathAnalystSetting
-
ssc_file_path¶ str -- SSC 文件路径
-
tolerance¶ float -- 节点容限
-
class
iobjectspy.analyst.TransportationPathAnalystSetting(network_dataset=None)¶ 基类:
iobjectspy._jsuperpy.analyst.na.PathAnalystSetting交通网络分析最佳路径分析环境。
初始化对象
参数: network_dataset (DatasetVector or str) -- 网络数据集 -
barrier_edge_ids¶ list[int] -- 障碍弧段的 ID 列表
-
barrier_node_ids¶ list[int] -- 障碍结点的 ID 列表
-
bounds¶ Rectangle -- 最佳路径分析的分析范围
-
edge_filter¶ str -- 交通网络分析中弧段过滤表达式
-
edge_id_field¶ str -- 网络数据集中标志弧段 ID 的字段
-
edge_name_field¶ str -- 道路名称字段
-
f_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
ft_single_way_rule_values¶ list[str] -- 用于表示正向单行线的字符串的数组
-
node_id_field¶ str -- 网络数据集中标识结点 ID 的字段
-
prohibited_way_rule_values¶ list[str] -- 表示禁行线的字符串的数组
-
rule_field¶ str -- 网络数据集中表示网络弧段的交通规则的字段
-
set_barrier_edge_ids(value)¶ 设置障碍弧段的 ID 列表
参数: value (str or list[int]) -- 障碍弧段的 ID 列表 返回: self 返回类型: TransportationPathAnalystSetting
-
set_barrier_node_ids(value)¶ 设置障碍结点的 ID 列表
参数: value (str or list[int]) -- 障碍结点的 ID 列表 返回: self 返回类型: TransportationPathAnalystSetting
-
set_bounds(value)¶ 设置最佳路径分析的分析范围
参数: value (Rectangle or str) -- 最佳路径分析的分析范围 返回: self 返回类型: TransportationPathAnalystSetting
-
set_edge_filter(value)¶ 设置交通网络分析中弧段过滤表达式
参数: value -- 交通网络分析中弧段过滤表达式 返回: self 返回类型: TransportationPathAnalystSetting
-
set_edge_id_field(value)¶ 设置网络数据集中标识结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段 ID 的字段 返回: self 返回类型: TransportationPathAnalystSetting
-
set_edge_name_field(value)¶ 设置道路名称字段
参数: value (str) -- 道路名称字段 返回: self 返回类型: TransportationPathAnalystSetting
-
set_f_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段起始结点 ID 的字段 返回: self 返回类型: TransportationPathAnalystSetting
-
set_ft_single_way_rule_values(value)¶ 设置用于表示正向单行线的字符串的数组
参数: value (str or list[str]) -- 用于表示正向单行线的字符串的数组 返回: self 返回类型: TransportationPathAnalystSetting
-
set_node_id_field(value)¶ 设置网络数据集标识结点ID的字段
参数: value (str) -- 网络数据集中标识结点 ID 的字段 返回: self 返回类型: TransportationPathAnalystSetting
-
set_prohibited_way_rule_values(value)¶ 设置表示禁行线的字符串的数组
参数: value (str or list[str]) -- 表示禁行线的字符串的数组 返回: self 返回类型: TransportationPathAnalystSetting
-
set_rule_field(value)¶ 设置网络数据集中表示网络弧段的交通规则的字段
参数: value (str) -- 网络数据集中表示网络弧段的交通规则的字段 返回: self 返回类型: TransportationPathAnalystSetting
-
set_t_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 返回: self 返回类型: TransportationPathAnalystSetting
-
set_tf_single_way_rule_values(value)¶ 设置表示逆向单行线的字符串的数组
参数: value (str or list[str]) -- 表示逆向单行线的字符串的数组 返回: self 返回类型: TransportationPathAnalystSetting
-
set_tolerance(value)¶ 设置节点容限
参数: value (float) -- 节点容限 返回: 当前对象 返回类型: TransportationPathAnalystSetting
-
set_two_way_rule_values(value)¶ 设置表示双向通行线的字符串的数组
参数: value (str or list[str]) -- 表示双向通行线的字符串的数组 返回: self 返回类型: TransportationPathAnalystSetting
-
set_weight_fields(value)¶ 设置权重字段
参数: value (list[WeightFieldInfo] or tuple[WeightFieldInfo]) -- 权重字段 返回: self 返回类型: TransportationPathAnalystSetting
-
t_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
tf_single_way_rule_values¶ list[str] -- 表示逆向单行线的字符串的数组
-
tolerance¶ float -- 节点容限
-
two_way_rule_values¶ list[str] -- 表示双向通行线的字符串的数组
-
weight_fields¶ list[WeightFieldInfo] -- 权重字段
-
-
class
iobjectspy.analyst.TransportationAnalystSetting(network_dataset=None)¶ 基类:
iobjectspy._jsuperpy.analyst.na.TransportationPathAnalystSetting交通网络分析环境设置类。该类用于提供交通网络分析时所需要的所有参数信息。交通网络分析环境设置类的各个参数的设置直接影响分析的结果。
在利用交通网络分析类(
TransportationAnalyst)进行各种交通网络分析时,都要首先设置交通网络分析的环境,而交通网络分析环境的设 置就是通过TransportationAnalyst类对象的TransportationAnalyst.set_analyst_setting()方法来完成的。初始化对象
参数: network_dataset (DatasetVector or str) -- 网络数据集
-
class
iobjectspy.analyst.PathInfo(path_info_items)¶ 基类:
object引导信息,通过该类,可以获得基于 SSC 路径分析后路线的导引信息
-
__getitem__(item)¶ 获取指定位置的行驶导引子项
参数: item (int) -- 指定的行驶导引索引下标 返回: 行驶导引子项 返回类型: PathInfoItem
-
__len__()¶ 返回行驶导引子项数目
返回: 行驶导引子项数目 返回类型: int
-
-
class
iobjectspy.analyst.PathInfoItem(java_object)¶ 基类:
object引导信息项
-
direction_to_swerve¶ int -- 返回到下一条道路的转弯方向。其中0表示直行,1表示左前转弯,2表示右前转弯,3表示左转弯,4表示右转弯,5表示左后转弯, 6表示右后转弯,7表示掉头,8表示右转弯绕行至左,9表示直角斜边右转弯,10表示环岛。
-
junction¶ Point2D -- 通过该接口可以返回到下一条道路的路口点坐标
-
length¶ float -- 返回当前道路的长度。
-
route_name¶ str -- 该接口可以返回当前道路的名称,当道路名称为“PathPoint”时,表示到达途径点。
-
-
class
iobjectspy.analyst.PathGuide(items)¶ 基类:
object行驶导引
行驶导引记录了如何从一条路径的起点一步步行驶到终点,其中路径上的每一个关键要素对应一个行驶导引子项。这些关键要素包括站点(用户输 入的用于分析的点,可以为普通点或结点),经过的弧段和网络结点。通过行驶导引子项对象,可以获取路径中关键要素的 ID、名称、序号、权 值、长度,还可以判断是弧段还是站点,以及行驶方向、转弯方向、花费等信息。按照行驶导引子项的序号对其存储的关键要素信息进行提取并 组织,就可以描绘出如何从路径起点到达终点。
下图是最近设施查找分析的一个实例,分析的结果给出了三条首选的路径。每一条路径的信息便由一个行驶导引对象来记录。如第二条路径,它由 站点(这里为起点和终点,可以为一般坐标点或网络结点)、路段(弧段)、路口(网络结点)等关键要素构成,从它对应的行驶导引的行驶导引 子项中可以获得这些关键要素的信息,从而使我们能够将该路径从起点如何行驶至终点描述清楚,如在什么路行驶多长距离向哪个方法转弯等。
-
__getitem__(item)¶ 获取指定位置的行驶导引子项
参数: item (int) -- 指定的行驶导引索引下标 返回: 行驶导引子项 返回类型: PathGuideItem
-
__len__()¶ 返回行驶导引子项数目
返回: 行驶导引子项数目 返回类型: int
-
-
class
iobjectspy.analyst.PathGuideItem(java_object)¶ 基类:
object在交通网络分析中,行驶导引子项可以归纳为以下几类:
站点:即用户选择的用于分析的点,如进行最佳路径分析时指定的要经过的各个点。
站点到网络的线段:当站点为普通的坐标点时,需要首先将站点归结到网络上,才能基于网络进行分析。请参见
TransportationPathAnalystSetting.tolerance方法的介绍。如下图所示,红色虚线即为站点到网络的最短直线距离。注意,当站点在网络弧段的边缘附近时,如右图所示,这段距离是指站点与弧段端点的连线距离。
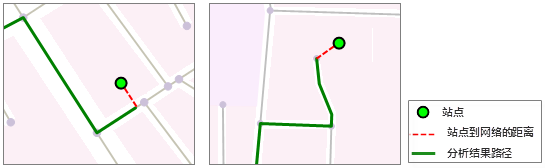
站点在网络上的对应点:与“站点到网络的线段”对应,这个点就是将站点(普通坐标点)归结到网络上时,网络上相应的点。上面左图所示的 情形,这个点就是站点在对应弧段上的垂足点;上面右图所示的情形,这个点则为弧段的端点。
路段:也就是行驶经过的一段道路。交通网络中用弧段模拟道路,因此行驶路段都位于弧段上。注意,多个弧段可能被合并为一个行驶导引子项, 合并的条件是它们的弧段名称相同,并且相邻弧段间的转角小于 30 度。需要强调,到达站点前的最后一个行驶路段和到达站点后的第一个行驶 路段,仅包含一条弧段或弧段的一部分,即使满足上述条件也不会与相邻弧段合并为一个行驶导引。
如下图所示,使用不同的颜色标示出了两个站点之间的行驶路段。其中,站点 1 之后的第一条路段(红色),虽然其所在弧段的名称与后面几条 弧段的名称相同,且转向角度都小于 30 度,但由于它是站点后的第一条路段,因此并未将它们合并。而蓝色路段所覆盖的三条弧段,由于弧段 名称相同且转角小于 30 度,故将它们合并为一个行驶导引子项;粉色路段由于与之前的路段具有不同的弧段名称,故成为另一个行驶导引子 项;绿色路段由于是到达站点前的最后一条路段,因此也单独作为一个行驶导引子项。
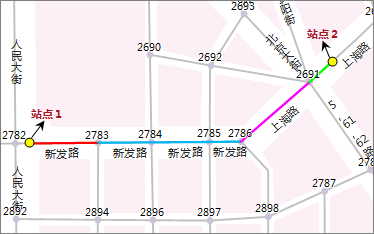
转向点:两个相邻的行驶路段之间的路口。路口是指有可能发生方向改变的实际道路的路口(如十字路口或丁字路口)。在转向点处行驶方向可 能发生改变。如上图中的结点 2783、2786 和 2691 都是转向点。转向点一定是网络结点。
通过 PathGuideItem 的各个方法返回的值,可以判断行驶导引子项属于哪种类型,下表总结了五种行驶导引子项的各个方法返回值的对照表,方 便用户理解和使用行驶导引。
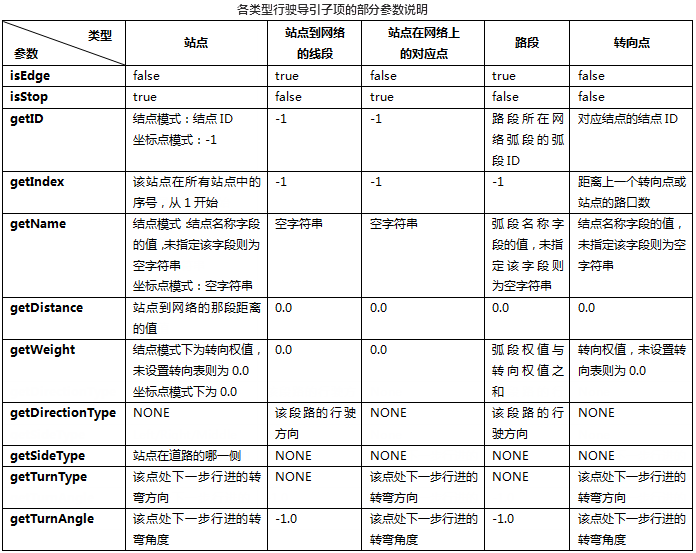
通过下面的实例,可以帮助用户理解行驶导引和行驶导引子项的内容和作用。下图中的蓝色虚线为最近设施查找分析的结果中的一条路径,在最近 设施查找的返回结果中,可以获得这条路径对应的行驶导引。
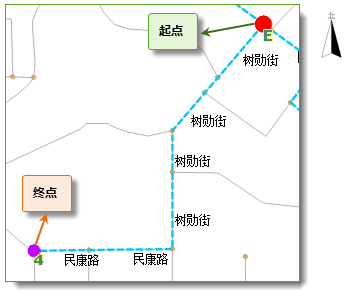
用于描述这条路径的行驶导引共包含7个子项。这7个行驶导引子项包含2个站点(即起点和终点,对应序号为0和6)、3个弧段(即路段,序号分别 为1、3、5)和2个网络结点(即转向点,序号分别为2、4)。下表列出了这7个行驶导引子项的信息,包括是否为站点(
is_stop)、 是否为弧段(is_edge)、序号(index)、行驶方向(direction_type)、转弯方向(turn_type) 及弧段名称(name)等信息。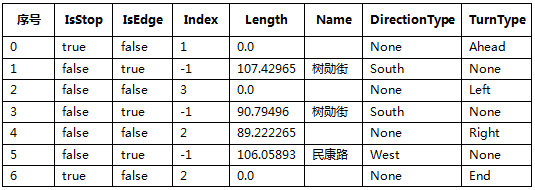
将行驶导引子项记录的信息进行组织,可以得到如下表所示的该路径的导引描述。
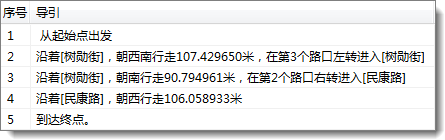
-
bounds¶ Rectangle -- 该行驶导引子项的范围。当行驶导引子项为线类型(即
is_edge返回 True)时,为线的最小外接矩形;为 点类型(即is_edge返回 False)时,则为点本身
-
distance¶ float -- 站点到网络的距离,仅当行驶导引子项为站点时有效。站点可能不在网络上(既不在弧段上也不在结点上),必须将站点归结到 网络上,才能基于网络进行分析。该距离是指站点到最近一条弧段的距离。如下图所示,桔色点代表网络结点,蓝色代表弧段, 灰色点为站点,红色线段代表距离。
当行驶导引子项是站点以外的其他类型时,该值为 0.0。
-
guide_line¶ GeoLineM -- 返回该行驶导引子项为线类型(即
is_edge返回 True )时,对应的行驶导引线段。 当is_edge返回 false 时,该方法返回 None。
-
index¶ int -- 行驶导引子项的序号。 除以下两种情形外,该方法均返回 -1:
- 当行驶导引子项为站点时,该值为该站点在所有站点中的序号,从 1 开始。例如某个站点是行驶路线经过的第 2 个站点,则此 站点的 Index 值为 2;
- 当行驶导引子项为转向点时,该值为该点距离上一个转向点或站点的路口数。例如某个转向点之前的两个路口是最近的一个站点, 则这个转向点的 Index 值为 2;当某个点同时为站点和转向点时,Index 为在整个行驶过程的所有站点中该站点的位置。
-
is_edge¶ bool -- 返回该行驶导引子项是线还是点类型。若为 True,表示为线类型,如站点到网络的线段、路段;若为 False,表示为点类型, 如站点、转向点或站点被归结到网络上的对应点。
-
is_stop¶ bool -- 返回该行驶导引子项是否为站点,或站点被归结到网络上的对应点。当 is_stop 返回 true 时,对应的行驶导引子项可能是站点,或当站点为坐标点时,被归结到网络上的对应点。
-
name¶ str -- 该行驶导引子项的名称。 除以下两种情形外,该方法均返回空字符串:
- 当行驶导引子项为站点(结点模式)或转向点时,该值根据交通网络分析环境中指定的结点名称字段的值 给出,如未设置则为空字符串;
- 当行驶导引子项为路段或站点到网络的线段时,该值根据交通网络分析环境中指定的结点名称字段的值 给出,如未设置则为空字符串。
-
node_edge_id¶ int -- 该行驶导引子项的 ID。 除以下三种情形外,该方法均返回 -1:
- 当行驶导引子项为结点模式下的站点时,站点为结点,返回该结点的结点 ID;
- 当行驶导引子项为转向点时,转向点为结点,返回该结点的结点 ID;
- 当行驶导引子项为路段时,返回路段对应的弧段的弧段 ID。如果该路段由多条弧段合并而成,则返回第一条弧段的 ID。
-
side_type¶ SideType -- 行驶导引子项为站点时,站点在道路的左侧、右侧还是在路上。当行驶导引子项为站点以外的类型时,该方法返回 NONE
-
turn_type¶ TurnType -- 返回该行驶导引子项为点类型(即
is_edge返回 False)时,该点处下一步行进的转弯方向。 当is_edge返回 True 时,该方法返回 None
-
weight¶ float -- 返回该行驶导引子项的权值,即行使导引对象子项的花费。单位与交通网络分析参数(TransportationAnalystParameter)所 指定的权值字段信息(
WeightFieldInfo)对象的权值字段的单位相同。 当行驶导引子项为路段、转向点或结点模式下的站点时,得到的花费才有意义,否则均为 0.0。- 当行驶导引子项为路段时,根据弧段权值和转向权值计算得出相应的花费。如果未设置转向表,则转向权值为 0;
- 当行驶导引子项为转向点或结点模式下的站点时(二者均为结点),为相应的转向权值。如果未设置转向表,则为 0.0。
-
class
iobjectspy.analyst.SSCPathAnalyst(path_analyst_setting)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase基于 SSC 文件的路径分析类。用户可以通过
compile_ssc_data()编译 ssc 文件。通常,使用 SSC 文件的路径分析性能要好于基于 网络数据集的交通网络路径分析性能。初始化对象
参数: path_analyst_setting (SSCPathAnalystSetting) -- 基于 SSC 路径分析环境参数对象。 -
find_path(start_point, end_point, midpoints=None, route_type='RECOMMEND', is_alternative=False)¶ 最佳路径分析
参数: 返回: 分析成功将返回 True,失败返回 False
返回类型: bool
-
get_alternative_path_length()¶ 返回备选分析结果的总长度。
返回: 备选分析结果的总长度。 返回类型: float
-
get_alternative_path_time()¶ 返回备选分析结果的行驶时间,单位为秒。如果想获取行驶时间,在编译 SSC 文件时需要指定正确的速度字段。
返回: 备选分析结果的行驶时间 返回类型: float
-
get_path_length()¶ 返回分析结果的总长度。请保证在调用该接口之前路径分析成功。
返回: 分析结果的总长度。 返回类型: float
-
get_path_time()¶ 返回分析结果的行驶时间,单位为秒。如果想获取行驶时间,在编译 SSC 文件时需要指定正确的速度字段。
返回: 分析结果的行驶时间 返回类型: float
-
set_analyst_setting(path_analyst_setting)¶ 设置路径分析环境参数
参数: path_analyst_setting (SSCPathAnalystSetting) -- 基于 SSC 路径分析环境参数对象。 返回: self 返回类型: SSCPathAnalyst
-
-
class
iobjectspy.analyst.SSCCompilerParameter¶ 基类:
object编译 SSC 文件的参数
-
edge_id_field¶ str -- 网络数据集中标志弧段 ID 的字段
-
edge_name_field¶ str -- 弧段的名称字段
-
f_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
file_path¶ str -- SSC文件的路径
-
ft_single_way_rule_values¶ list[str] -- 用于表示正向单行线的字符串的数组
-
level_field¶ str -- 道路等级字段
-
network_dataset¶ DatasetVector -- 网络数据集
-
node_id_field¶ str -- 网络数据集中标识结点 ID 的字段
-
prohibited_way_rule_values¶ list[str] -- 表示禁行线的字符串的数组
-
rule_field¶ str -- 网络数据集中表示网络弧段的交通规则的字段
-
set_edge_id_field(value)¶ 设置网络数据集中标识结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段 ID 的字段 返回: self 返回类型: SSCCompilerParameter
-
set_edge_name_field(value)¶ 设置弧段的字段名称
参数: value (str) -- 弧段的名称字段。 返回: self 返回类型: SSCCompilerParameter
-
set_f_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段起始结点 ID 的字段 返回: self 返回类型: SSCCompilerParameter
-
set_file_path(value)¶ 设置 SSC文件的路径
参数: value (str) -- SSC文件的路径。 返回: self 返回类型: SSCCompilerParameter
-
set_ft_single_way_rule_values(value)¶ 设置用于表示正向单行线的字符串的数组
参数: value (str or list[str]) -- 用于表示正向单行线的字符串的数组 返回: self 返回类型: SSCCompilerParameter
-
set_level_field(value)¶ 设置道路等级字段,取值范围为1-3,必须字段,其中3的道路等级最高(高速路等),1的道路等级最低(乡村道路等)。
参数: value (str) -- 道路等级字段 返回: self 返回类型: SSCCompilerParameter
-
set_network_dataset(dataset)¶ 设置网络数据集
参数: dataset (DatasetVetor or str) -- 网络数据集 返回: 当前对象 返回类型: SSCCompilerParameter
-
set_node_id_field(value)¶ 设置网络数据集标识结点ID的字段
参数: value (str) -- 网络数据集中标识结点 ID 的字段 返回: self 返回类型: SSCCompilerParameter
-
set_prohibited_way_rule_values(value)¶ 设置表示禁行线的字符串的数组
参数: value (str or list[str]) -- 表示禁行线的字符串的数组 返回: self 返回类型: SSCCompilerParameter
-
set_rule_field(value)¶ 设置网络数据集中表示网络弧段的交通规则的字段
参数: value (str) -- 网络数据集中表示网络弧段的交通规则的字段 返回: self 返回类型: SSCCompilerParameter
-
set_speed_field(value)¶ 设置道路速度字段,非必须字段。整数型字段,其中1的道路速度最高(150km/h),2的速度为130km/h,3的速度为100km/h,4的速度为90km/h, 5的速度为70km/h,6的速度为50km/h,7的速度为30km/h,其他值的速度统一为10km/h
参数: value (str) -- 道路速度字段 返回: self 返回类型: SSCCompilerParameter
-
set_t_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 返回: self 返回类型: SSCCompilerParameter
-
set_tf_single_way_rule_values(value)¶ 设置表示逆向单行线的字符串的数组
参数: value (str or list[str]) -- 表示逆向单行线的字符串的数组 返回: self 返回类型: SSCCompilerParameter
-
set_two_way_rule_values(value)¶ 设置表示双向通行线的字符串的数组
参数: value (str or list[str]) -- 表示双向通行线的字符串的数组 返回: self 返回类型: SSCCompilerParameter
-
set_weight_field(value)¶ 设置权重字段
参数: value (str) -- 权重字段 返回: self 返回类型: SSCCompilerParameter
-
speed_field¶ str -- 道路速度字段
-
t_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
tf_single_way_rule_values¶ list[str] -- 表示逆向单行线的字符串的数组
-
two_way_rule_values¶ list[str] -- 表示双向通行线的字符串的数组
-
weight_field¶ str -- 权重字段
-
-
class
iobjectspy.analyst.TrackPoint(point, t, key=0)¶ 基类:
object带时间的轨迹坐标点。
参数: - point (Point2D) -- 二维点坐标
- t (datetime.datetime) -- 时间值,表示坐标位置点的时间。
- key (int) -- 关键值,用于标识点唯一性
-
key¶ int -- 关键值,用于标识点唯一性
-
point¶ Point2D -- 二维点坐标
-
set_key(value)¶ 设置关键值,用于标识点唯一性
参数: value (int) -- 关键值 返回: self 返回类型: TrackPoint
-
set_point(value)¶ 设置位置点
参数: value (Point2D or str) -- 位置点 返回: self 返回类型: TrackPoint
-
set_time(value)¶ 设置时间值
参数: value (datetime.datetime or str) -- 时间值,表示坐标位置点的时间 返回: self 返回类型: TrackPoint
-
time¶ datetime.datetime -- 时间值,表示坐标位置点的时间
-
class
iobjectspy.analyst.TrajectoryPreprocessing¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase轨迹预处理类。用于处理轨迹数据中的异常点,包括轨迹分段,处理偏移点、重复点、尖角等异常情形。
-
is_remove_redundant_points¶ bool -- 是否去除空间位置相等的重复点
-
measurement_error¶ float -- 轨迹点误差值
-
prj_coordsys¶ PrjCoordSys -- 待处理点的坐标系
-
rectify(points)¶ 轨迹预处理结果
参数: points (list[TrackPoint] or tuple[TrackPoint]) -- 待处理的轨迹点数据。 返回: 处理后的轨迹点数据集。 返回类型: TrajectoryPreprocessingResult
-
rectify_dataset(source_dataset, id_field, time_field, split_time_milliseconds, out_data=None, out_dataset_name=None, result_track_index_field='TrackIndex')¶ 对数据集进行轨迹预处理,结果保存为点数据
参数: - source_dataset (DatasetVector or str) -- 原始轨迹点数据集
- id_field (str) -- 轨迹的 ID 字段,相同 ID 值相同的轨迹点属于一条轨迹,比如手机号、车牌号等。没有指定 ID 字段时,数据集 中所有点将归类为一条轨迹。
- time_field (str) -- 轨迹点的时间字段,必须为时间或时间戳类型字段
- split_time_milliseconds (float) -- 分割轨迹的时间间隔,如果时间相邻的两个点的时间间隔大于指定的分割轨迹的时间间隔,将 会从两个点间分割轨迹。
- out_data (Datasource or str) -- 保存结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- result_track_index_field (str) -- 保存轨迹索引的字段,轨迹分割后,一条轨迹可能分割为多条子轨迹,result_track_index_field 将会保存子轨迹的索引值,值从1开始。 因为结果数据集会保存源轨迹点数据集的所有字段, 所以必须确保 result_track_index_field 字段值在源轨迹点数据集中是没有被占用。
返回: 结果点数据集,预处理后的结果点数据集。
返回类型:
-
set_measurement_error(value)¶ 设置轨迹点误差值,比如 GPS误差值,单位为米。需要根据数据的质量指定一个合适的误差值。轨迹点偏移超过该误差值,则将其处理掉。
参数: value (float) -- 轨迹点误差值 返回: self 返回类型: TrajectoryPreprocessing
-
set_prj_coordsys(value)¶ 设置待处理点的坐标系
参数: value (PrjCoordSys) -- 待处理点的坐标系 返回: self 返回类型: TrajectoryPreprocessing
-
set_remove_redundant_points(value)¶ 设置是否去除空间位置相等的重复点
参数: value (bool) -- 是否去除空间位置相等的重复点 返回: self 返回类型: TrajectoryPreprocessing
-
set_sharp_angle(value)¶ 设置尖角角度值。单位为角度,当连续时间段内三个不相等的点的夹角小于指定的尖角角度值时,中间的点将会被纠偏处理成首尾两个点的 中点。当值小于等于0时,将不处理尖角。
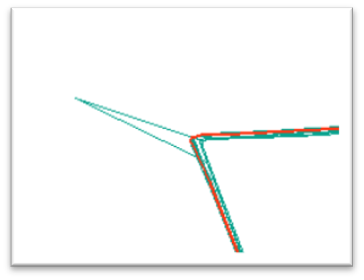
参数: value (float) -- 尖角角度值 返回: self 返回类型: TrajectoryPreprocessing
-
set_valid_region_dataset(value)¶ 设置有效面,只有落在有效面内的点才是有效点。
参数: value (DatasetVector or str) -- 有效面数据集 返回: self 返回类型: TrajectoryPreprocessing
-
sharp_angle¶ float -- 尖角角度值
-
valid_region_dataset¶ DatasetVector -- 有效面数据集。
-
-
class
iobjectspy.analyst.TransportationAnalystParameter¶ 基类:
object交通网络分析参数设置类。
该类主要用来对交通网络分析的参数进行设置。通过交通网络分析参数设置类可以设置障碍边、障碍点、权值字段信息的名字标识、分析途径的 点或结点,还可以对分析结果进行一些设置,即在分析结果中是否包含分析途经的以下内容:结点集合,弧段集合,路由对象集合以及站点集合。
-
barrier_edges¶ list[int] -- 障碍弧段 ID 列表
-
barrier_nodes¶ list[int] -- 障碍结点 ID 列表
-
barrier_points¶ list[Point2D] -- 障碍点列表
-
is_edges_return¶ bool -- 分析结果中是否包含途经弧段
-
is_nodes_return¶ bool -- 分析结果中是否包含途经结点
-
is_path_guides_return¶ bool -- 分析结果中是否包含行驶导引
-
is_routes_return¶ bool -- 返回分析结果中是否包含路由(
GeoLineM)对象
-
is_stop_indexes_return¶ bool -- 分析结果中是否要包含站点索引
-
nodes¶ list[int] -- 分析途经点
-
points¶ list[Point2D] -- 分析时途经点
-
set_barrier_edges(edges)¶ 设置障碍弧段 ID 列表。可选。此处指定的障碍弧段与交通网络分析环境(
TransportationAnalystSetting)中指定的障 碍弧段共同作用于交通网络分析。参数: edges (list[int] or tuple[int]) -- 障碍弧段 ID 列表 返回: self 返回类型: TransportationAnalystParameter
-
set_barrier_nodes(nodes)¶ 设置障碍结点 ID 列表。可选。此处指定的障碍结点与交通网络分析环境(
TransportationAnalystSetting)中指定的 障碍结点共同作用于交通网络分析。参数: nodes (list[int] or tuple[int]) -- 障碍结点 ID 列表 返回: self 返回类型: TransportationAnalystParameter
-
set_barrier_points(points)¶ 设置障碍结点的坐标列表。可选。指定的障碍点可以不在网络上(既不在弧段上也不在结点上),分析时将根据距离容限(
TransportationPathAnalystSetting.tolerance)把 障碍点归结到最近的网络上。目前支持最佳路径分析、最近设施查找、旅行商分析和物流配送分析。参数: points (list[Point2D] or tuple[Point2D]) -- 障碍结点的坐标列表 返回: self 返回类型: TransportationAnalystParameter
-
set_edges_return(value=True)¶ 设置分析结果中是否包含途经弧段
参数: value (bool) -- 指定分析结果中是否包含途经弧段。设置为 True,在分析成功后,可以从 TransportationAnalystResult 对象 TransportationAnalystResult.edges方法返回途经弧段;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter
-
set_nodes(nodes)¶ 设置分析途经点。必设,但与
set_points()方法互斥,如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点 集合,又指定了坐标点集合,然后分析,此时只对坐标点进行分析。参数: nodes (list[int] or tuple[int]) -- 途经结点 ID 返回: self 返回类型: TransportationAnalystParameter
-
set_nodes_return(value=True)¶ 设置分析结果中是否包含结点
参数: value (bool) -- 指定分析结果中是否包含途经结点。设置为 True,在分析成功后,可以从 TransportationAnalystResult 对象 TransportationAnalystResult.nodes方法返回途经结点;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter
-
set_path_guides_return(value=True)¶ 设置分析结果中是否包含行驶导引集合。
必须将该方法设置为 True,并且通过 TransportationAnalystSetting 类的
TransportationPathAnalystSetting.set_edge_name_field()方 法设置了弧段名称字段,分析结果中才会包含行驶导引集合,否则将不会返回行驶导引,但不影响分析结果中其他内容的获取。参数: value (bool) -- 分析结果中是否包含行驶导引。设置为 True,在分析成功后,可以从 TransportationAnalystResult 对 象 TransportationAnalystResult.path_guides方法返回行驶导引;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter
-
set_points(points)¶ 设置分析时途经点的集合。必设,但与
set_nodes()方法互斥,如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点集合,又 指定了坐标点集合,然后分析,此时只对坐标点进行分析。如果设置的途经点集合中的点不在网络数据集的范围内,则该点不会参与分析
参数: points (list[Point2D] or tuple[Point2D]) -- 途经点 返回: self 返回类型: TransportationAnalystParameter
-
set_routes_return(value=True)¶ 分析结果中是否包含路由(
GeoLineM)对象param bool value: 指定是否包含路由对象。设置为 True,在分析成功后,可以从 TransportationAnalystResult 对象 的 TransportationAnalystResult.route返回路由对象;为 False 则返回 Nonereturn: self rtype: TransportationAnalystParameter
-
set_stop_indexes_return(value=True)¶ 设置分析结果中是否要包含站点索引的
参数: value (bool) -- 指定分析结果中是否要包含站点索引。设置为 True,在分析成功后,可以从 TransportationAnalystResult 对象 TransportationAnalystResult.stop_indexes方法返回站点索引;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter
-
set_weight_name(name)¶ 设置权值字段信息的名称。如果未设置,则默认使用权值字段信息集合中的第一个权值字段信息对象的名称
参数: name (str) -- 权值字段信息的名字标识 返回: self 返回类型: TransportationAnalystParameter
-
weight_name¶ str -- 权值字段信息的名称
-
-
class
iobjectspy.analyst.TransportationAnalyst(analyst_setting)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase交通网络分析类。该类用于提供路径分析、旅行商分析、服务区分析、多旅行商(物流配送)分析、最近设施查找和选址分区分析等交通网络分析的功能。
交通网络分析是网络分析的重要组成部分,是基于交通网络模型的分析。与设施网络模型不同,交通网络是没有方向的,即使可以为网络边线指定 方向,但流通介质(行人或传输的资源)可以自行决定方向、速度和目的地。
初始化对象
参数: analyst_setting (TransportationAnalystSetting) -- 交通网络分析环境设置对象 -
allocate(supply_centers, demand_type=AllocationDemandType.BOTH, is_connected=True, is_from_center=True, edge_demand_field='EdgeDemand', node_demand_field='NodeDemand', weight_name=None)¶ 资源分配分析。 资源分配分析模拟现实世界网络中资源的供需关系模型,资源根据网络阻力值的设置,由供应点逐步向需求点(包括弧段或结点)分配,并确保 供应点能以最经济有效的方式为需求点提供资源。离中心点阻力值最小的需求点(包括弧段或结点)先得到资源,然后再分配剩余资源给阻力值 次小的需求点(包括弧段或结点),依此类推,直到中心点的资源耗尽,分配中止。
参数: - supply_centers (list[SupplyCenter] or tuple[SupplyCenter]) -- 资源供给中心集合
- demand_type (AllocationDemandType or str) -- 资源分配模式
- is_connected (bool) --
返回分析过程中生成的路由是否必须连通。进行资源分配分析过程中,允许某个中心点的资源穿越其他已完 成资源分配的中心点的服务范围而继续将自己的资源分配给需求对象,即该项设置为false,这样得到的结果 路由就不是连通的。如果设置为true,则在某个中心点的资源分配过程中,遇到已经被分配给其它中心的区域 则停止分配,这样就可能有多余的资源堆积在该资源中心点。
例如:电网送电问题是不允许有跨越情况的,它必须是相互连接的不能断开,而学生到学校上学的问题则允许 设置为跨越分配。
- is_from_center (bool) --
是否从资源供给中心开始分配资源。由于网络数据中的弧段具有正反阻力,即弧段的正向阻力值与其反向阻 力值可能不同,因此,在进行分析时, 从资源供给中心开始分配资源到需求点与从需求点向资源供给中心 分配这两种分配形式下,所得的分析结果会不同。
下面例举两个实际的应用场景,帮助进一步理解两种形式的差异,假设网络数据集中弧段的正反阻力值不同。
- 从资源供给中心开始分配资源到需求点:
如果你的资源中心是一些仓储中心,而需求点是各大超市,在实际的资源分配中,是将仓储中心的货物 运输到其服务的超市, 这种形式就是由资源供给中心向需求点分配,即分析时要将 is_from_center 设置为 true,即从资源供给中心开始分配。
- 不从资源供给中心开始分配资源:
如果你的资源中心是一些学校,而需求点是居民点,在实际的资源分配中,是学生从居民点出发去学校 上学,这种形式就不是从资源供给中心向外分配资源了, 即分析时要将 is_from_center 设置为 false,即不从资源供给中心开始分配。
- 从资源供给中心开始分配资源到需求点:
- edge_demand_field (str) -- 弧段需求量字段。该字段是网络数据集中,用于表示网络弧段作为需求地的所需资源量的字段名称。
- node_demand_field (str) -- 结点需求量字段。该字段是网络数据集中,用于表示网络结点作为需求地的所需资源量的字段名称。
- weight_name (str) -- 权值字段信息的名称
返回: 资源分配分析结果对象
返回类型: list[AllocationAnalystResult]
-
analyst_setting¶ TransportationAnalystSetting -- 交通网络分析环境设置对象
-
find_closest_facility(parameter, event_id_or_point, facility_count, is_from_event, max_weight)¶ 根据指定的参数进行最近设施查找分析,事件点为结点 ID 或坐标。
最近设施分析是指在网络上给定一个事件点和一组设施点,为事件点查找以最小耗费能到达的一个或几个设施点,结果为从事件点到设施点(或从设施点到事件点)的最佳路径。
设施点和事件点是最近设施查找分析的基本要素。设施点是提供服务的设施,如学校、超市、加油站等;事件点则是需要设施点的服务的事件位置。
例如,在某位置发生一起交通事故,要求查找在 10 分钟内最快到达的 3 家医院,超过 10 分钟能到达的都不予考虑。此例中,事故发生地即是一个事件点,周边的医院则是设施点。
事件点的指定方式有两种,一是通过坐标点来指定;二是以网络数据集中的结点 ID 指定,也就是将该网络结点看做事件点
设施点则是在 TransportationAnalystParameter 类型的参数 parameter 中指定的。通过 TransportationAnalystParameter 对象有 两种方式可以指定经过点:
- 使用该对象的
TransportationAnalystParameter.set_nodes()方法,以网络数据集中结点 ID 数组的形式指定设施点, 因此分析过程中使用到的设施点就是相应的网络结点; - 使用该对象的
TransportationAnalystParameter.set_points()方法,以坐标点串的形式指定设施点,因此分析过程中 使用到的设施点就是相应的坐标点。
注意:
事件点和设施点必须为相同的类型,即都以坐标点形式指定,或都以结点 ID 形式指定。本方法要求设施点与事件点均为坐标点,即需要通过 TransportationAnalystParameter 对象的TransportationAnalystParameter.set_points()方法来设置设施点。参数: - parameter (TransportationAnalystParameter) -- 交通网络分析参数对象。
- event_id_or_point (int or Point2D) -- 事件点坐标或结点ID
- facility_count (int) -- 要查找的设施点数量。
- is_from_event (bool) -- 是否从事件点到设施点进行查找。
- max_weight (float) -- 查找半径。单位同网络分析环境中设置的阻力字段,如果要查找整个网络,该值设为 0。
返回: 分析结果。结果数量与与查找到的最近设施点的数目相同
返回类型: - 使用该对象的
-
find_critical_edges(start_node, end_node)¶ 关键弧段查询。
关键弧段,表示两点间必定会经过的弧段。
通过调用该接口,可以获得两点间必定经过的弧段ID数组,如果返回值为空,则说明该两点不存在关键弧段。
参数: - start_node (int) -- 分析起点
- end_node (int) -- 分析终点
返回: 关键弧段ID数组。
返回类型: list[int]
-
find_critical_nodes(start_node, end_node)¶ 关键结点查询。 关键结点,表示两点间必定会经过的结点。
通过调用该接口,可以获得两点间必定经过的结点ID数组,如果返回值为空,则说明该两点不存在关键结点。
参数: - start_node (int) -- 分析起点
- end_node (int) -- 分析终点
返回: 关键结点ID数组。
返回类型: list[int]
-
find_group(terminal_points, center_points, max_cost, max_load, weight_name=None, barrier_nodes=None, barrier_edges=None, barrier_points=None, is_along_road=False)¶ 分组分析。
分组分析是基于网络分析模型,将分配点(
TerminalPoint)按照一定的规则(分配点到达中心点的距离不能大于最大耗费值 max_cost, 并且每一个中心点的负载量不能大于最大负载量 max_load)寻找出所属的中心点,每当一个中心点被分配了一个分配点,则中心点所在的分组的负载量会增加该分配点对应的负载量。参数: - terminal_points (list[TerminalPoint]) -- 分配点集合
- center_points (list[Point2D]) -- 中心点坐标集合
- max_cost (float) -- 最大耗费
- max_load (float) -- 最大负载
- weight_name (str) -- 权值字段信息的名称
- barrier_nodes (list[int] or tuple[int]) -- 障碍结点 ID 列表
- barrier_edges (list[int] or tuple[int]) -- 障碍弧段 ID 列表
- barrier_points (list[Point2D] or tuple[Point2D]) -- 障碍坐标点列表
- is_along_road (bool) -- 是否沿道路进行,如果为 True,分配点会找到最近道路上一个点(可能位投影点或弧段节点),从路上上的最近点 开始分析找到合理的中心点进行分簇,如果为False,则分配点会直接找到最近的中心点,再将各个中心点形成的小簇进行合并处理。
返回: 分组分析结果
返回类型:
-
find_location(supply_centers, expected_supply_center_number=0, is_from_center=True, weight_name=None)¶ 根据给定的参数进行选址分区分析。 选址分区分析是为了确定一个或多个待建设施的最佳位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅 是一个选址过程,还要将需求点的需求分配到相应的设施的服务区中,因此称之为选址与分区。
资源供给中心与需求点
资源供给中心:即中心点,是提供资源和服务的设施,对应于网络结点,资源供给中心的相关信息包括最大阻力值、资源供给中心类型,资源供 给中心在网络中所处结点的 ID 等。
需求点:通常是指需要资源供给中心提供的服务和资源的位置,也对应于网络结点。
最大阻力值用来限制需求点到资源供给中心的花费。如果需求点到此资源供给中心的花费大于最大阻力值,则该需求点被过滤掉,即该资源 供给中心不能服务到此需求点。
资源供给中心分为三种:非中心点,固定中心点和可选中心点。固定中心点是指网络中已经存在的、已建成或已确定要建立的服务设施(扮 演资源供给角色);可选中心点是指可以建立服务设施的资源供给中心,即待建服务设施将从这些可选中心点中选址;非中心点在分析时不 予考虑,在实际中可能是不允许建立这项设施或者已经存在了其他设施。
另外,分析过程中使用的需求点都为网络结点,即除了各种类型的中心点所对应的网络结点,所有网络结点都作为资源需求点参与选址分区 分析,如果要排除某部分结点,可以将其设置为障碍点。
是否从资源供给中心分配资源
址分区可以选择从资源供给中心开始分配资源,或不从资源供给中心分配:
从中心点开始分配(供给到需求)的例子:
电能是从电站产生,并通过电网传送到客户那里去的。在这里,电站就是网络模型中的中心,因为它可以提供电力供应。电能的客户沿 电网的线路(网络模型中的弧段)分布,他们产生了“需求”。在这种情况下,资源是通过网络由供方传输到需要来实现资源分配的。
不从中心点开始分配(需求到供给)的例子:
学校与学生的关系也构成一种在网络中供需分配关系。学校是资源提供方,它负责提供名额供适龄儿童入学。适龄儿童是资源的需求方, 他们要求入学。作为需求方的适龄儿童沿街道网络分布,他们产生了对作为供给方的学校的资源--学生名额的需求。
应用实例
某个区域目前有 3 所小学,根据需求,拟在该区域内再建立 3 所小学。选择了 9 个地点作为待选地点,将在这些待选点中选择 3 个最 佳地点建立新的小学。如图 1 所示,已有的 3 所小学为固定中心点,7 个候选位置为可选中心点。新建小学要满足的条件为:居民点中 的居民步行去学校的时间要在 30 分钟以内。选址分区分析会根据这一条件给出最佳的选址位置,并且圈出每个学校,包括已有的 3 所 学校的服务区域。如图 2 所示,最终序号为 5、6、8 的可选中心点被选为建立新学校的最佳地点。
注:下面两幅中的网络数据集的所有网络结点被看做是该区域的居民点全部参与选址分区分析,居民点中的居民数目即为该居民点所需服务 的数量。
参数: - supply_centers (list[SupplyCenter] or tuple[SupplyCenter]) -- 资源供给中心集合
- expected_supply_center_number (int) -- 期望用于最终设施选址的资源供给中心数量。当输入值为0时,最终设施选址的资源供给中 心数量默认为覆盖分析区域内的所需最少的供给中心数
- is_from_center (bool) --
是否从资源供给中心开始分配资源。由于网络数据中的弧段具有正反阻力,即弧段的正向阻力值与其反向阻 力值可能不同,因此,在进行分析时,从资源供给中心开始分配资源到需求点与从需求点向资源供给中心分 配这两种分配形式下,所得的分析结果会不同。 下面例举两个实际的应用场景,帮助进一步理解两种形式的差异,假设网络数据集中弧段的正反阻力值不同。
- 从资源供给中心开始分配资源到需求点:
如果你选址的对象是一些仓储中心,而需求点是各大超市,在实际的资源分配中,是将仓储中心的货物 运输到其服务的超市,这种形式就是由资源供给中心向需求点分配,即分析时要将 is_from_center 设置为 True, 即从资源供给中心开始分配。
- 不从资源供给中心开始分配资源:
如果你选址的对象是像邮局或者银行或者学校一类的服务机构,而需求点是居民点,在实际的资源分配 中,是居民点中的居民会主动去其服务机构办理业务,这种形式就不是从资源供给中心向外分配资源了, 即分析时要将 is_from_center 设置为 False,即不从资源供给中心开始分配。
- 从资源供给中心开始分配资源到需求点:
- weight_name (str) -- 权值字段信息的名称
返回: 选址分析结果对象
返回类型:
-
find_mtsp_path(parameter, center_nodes_or_points, is_least_total_cost=False)¶ 多旅行商(物流配送)分析,配送中心为点坐标串或结点ID数组
多旅行商分析也称为物流配送,是指在网络数据集中,给定 M 个配送中心点和 N 个配送目的地(M,N 为大于零的整数),查找经济有效的 配送路径,并给出相应的行走路线。如何合理分配配送次序和送货路线,使配送总花费达到最小或每个配送中心的花费达到最小,是物流配送所解决的问题。
配送中心点的指定方式有两种,一是通过坐标点集合指定,二是以网络结点 ID 数组指定。
配送目的地则是在 TransportationAnalystParameter 类型的参数 parameter 中指定。通过 TransportationAnalystParameter 对象有两种方式可以指定配送目的地:
- 使用该对象的
TransportationAnalystParameter.set_nodes()方法,以网络数据集中结点 ID 数组的形式指定配送目的 地,因此分析过程中使用到的配送目的地就是相应的网络结点; - 使用该对象的
TransportationAnalystParameter.set_points()方法,以坐标点串的形式指定配送目的地,因此分析过 程中使用到的配送目的地就是相应的坐标点。
注意:
配送中心点和配送目的地必须为相同的类型,即都以坐标点形式指定,或都以结点 ID 形式指定。本方法要求配送目的地与配送中心点均为 坐标点。
多旅行商分析的结果将给出每个配送中心所负责的配送目的地,以及这些配送目的地的经过顺序,和相应的行走路线,从而使该配送中心的配 送花费最少,或者使得所有的配送中心的总花费最小。并且,配送中心点在完成其所负责的配送目的地的配送任务后,最终会回到配送中心点。
应用实例:现有 50 个报刊零售地(配送目的地),和 4 个报刊供应地(配送中心),现寻求这 4 个供应地向报刊零售地发送报纸的最优路 线,属物流配送问题。
下图为报刊配送的分析结果,其中红色大一点的圆点代表 4 个报刊供应地(配送中心),而其他小一点的圆点代表报刊零售地(配送目的地), 每个配送中心的配送方案采用不同的颜色标示,包括它所负责的配送目的地、配送次序以及配送线路。
下图为上图中矩形框圈出的第 2 号配送中心的配送方案。蓝色的标有数字的小圆点是2号配送中心所负责的配送目的地(共有 18 个),2 号 配送中心将按照配送目的地上标有数字的顺序依次发送报纸,即先送 1 号报刊零售地,再送 2 号报刊零售地,依次类推,并且沿着分析得出 的蓝色线路完成配送,最终回到配送中心。
需要注意,由于物流配送的目的是寻找使配送总花费最小或每个配送中心的花费最小的方案,因此,分析结果中有可能某些物流配送中心点不参与配送。
参数: - parameter (TransportationAnalystParameter) -- 交通网络分析参数对象。
- center_nodes_or_points (list[Point2D] or list[int]) -- 配送中心点坐标串或结点 ID 数组
- is_least_total_cost (bool) -- 配送模式是否为总花费最小方案。若为 true,则按照总花费最小的模式进行配送,此时可能会出现 某些配送中心点配送的花费较多而其他的配送中心点的花费较少的情况。若为 false,则为局部最优, 此方案会控制每个配送中心点的花费,使各个中心点花费相对平均,此时总花费不一定最小。
返回: 多旅行商分析结果,结果数目为参与配送的中心点数。
返回类型: - 使用该对象的
-
find_path(parameter, is_least_edges=False)¶ 最佳路径分析。 最佳路径分析解决的问题是,在网络数据集中,给定 N 个点(N 大于等于2),找出按照给定点的次序依次经过这 N 个点的花费最小的路径。 “花费最小”有多种理解,如时间最短、费用最低、风景最好、路况最佳、过桥最少、收费站最少、经过乡村最多等。
最佳路径分析的经过点是在
TransportationAnalystParameter类型的参数 parameter 中指定的。通过 TransportationAnalystParameter 对象有两种方式可以指定经过点:- 使用该对象的
TransportationAnalystParameter.set_nodes()方法,以网络数据集中结点 ID 数组的形式指定最佳路径分析经过的点,因此分析过程中经过的点就是相应的网络结点; - 使用该对象的
TransportationAnalystParameter.set_points()方法,以坐标点串的形式指定最佳路径分析经过的点,因此分析过程中经过的点就是相应的坐标点。
此外,通过
TransportationAnalystParameter对象还可以指定最佳路径分析需要的其他信息,如障碍点(边),分析结果是否包含路由、 行驶导引、途经弧段或结点等。具体内容请参见 TransportationAnalystParameter 类。需要注意,网络分析中的旅行商分析(
find_tsp_path()方法)与最佳路径分析类似,都是在网络中寻找遍历所有经过点的花费 最少的路径。但二者具有明显的区别,即在遍历经过点时,二者对访问经过点的顺序处理有所不同:- 最佳路径分析:必须按照给定的经过点的次序访问所有点;
- 旅行商分析:需要确定最优次序来访问所有点,而并不一定按照给定的经过点的次序。
参数: - parameter (TransportationAnalystParameter or list[int] or list[Point2D]) -- 交通网络分析参数对象
- is_least_edges (bool) --
是否弧段数最少。true 代表按照弧段数最少进行查询,由于弧段数少不代表弧段长度短,所以此时查出的 结果可能不是最短路径。如下图所示,如果连接AB 的绿色路径的弧段数少于黄色路径,当本参数设置为 True 时, 绿色路径就是查询得到的路径,当参数设置为 false 时,黄色路径就是查询得到的路径。
返回: 最佳路径分析结果
返回类型: - 使用该对象的
-
find_service_area(parameter, weights, is_from_center, is_center_mutually_exclusive=False, service_area_type=ServiceAreaType.SIMPLEAREA)¶ 服务区分析。 服务区是以指定点为中心,在一定阻力范围内,包含所有可通达边、通达点的一个区域。服务区分析就是依据给定的阻力值(即服务半径)为 网络上提供某种特定服务的位置(即中心点)查找其服务的范围(即服务区)的过程。阻力可以是到达的时间、距离或其他任何花费。例如: 为网络上某点计算其 30 分钟的服务区,则结果服务区内,任意点出发到该点的时间都不会超过 30 分钟。
服务区分析的结果包含了每个服务中心点所能服务到的路由和区域。路由是指从服务中心点出发,按照阻力值不大于所指定的服务半径的原则, 沿网络弧段延伸出的路径;服务区则是按照一定算法将路由包围起来所形成的面状区域。如下图所示,红色圆点代表提供服务或资源的服务 中心点,各种颜色的面状区域就是以相应的服务中心点为中心,在给定的阻力范围内的服务区,每个服务中心点所服务到的路由也以对应的颜色标示。
- 服务中心点
通过
TransportationAnalystParameter对象有两种方式可以指定服务中心点的位置:- 使用
TransportationAnalystParameter.set_nodes()方法,以网络数据集中结点 ID 数组的形式指定服务中心点,因 此分析过程中使用到的服务中心点就是相应的网络结点。 - 使用
TransportationAnalystParameter.set_points()方法,以服务中心点的坐标点串的形式指定服务中心点,因此分 析过程中使用到的服务中心点就是相应的坐标点集合。
是否从中心点分析
是否从中心点开始分析,体现了服务中心和需要该服务的需求地的关系模式。从中心点开始分析,表示服务中心向服务需求地提供服务; 而不从中心点开始分析,则代表服务需求地主动到服务中心获得服务。例如:某个奶站向各个居民点送牛奶,如果要对这个奶站进行服务区 分析,查看这个奶站在允许的条件下所能服务的范围,那么在实际分析过程中应当使用从中心点开始分析的模式;另一个例子,如果想分析 一个区域的某个学校在允许的条件下所能服务的区域时,由于在现实中都是学生主动来到学校学习,接受学校提供的服务,那么在实际分析 过程中就应当使用不从中心点开始分析的模式。
服务区互斥
若两个或多个相邻的服务区有交集,可将它们进行互斥处理。互斥处理后,这些服务区不会有交叠。如图所示左图未进行互斥处理,右图进行了互斥处理。
参数: - parameter (TransportationAnalystParameter) -- 交通网络分析参数对象。
- weights (list[float]) -- 服务区半径数组。数组长度应与给定的服务中心点的数量一致,且数组元素按照顺序与中心点一一对应。服务区半径的单位与指定的权值信息中的正向、反向阻力字段的单位一致。
- is_from_center (bool) -- 是否从中心点开始分析。
- is_center_mutually_exclusive (bool) -- 是否进行服务区互斥处理。如果设置为 true,则进行互斥处理,设置为 false,则不进行互斥处理。
- service_area_type (ServiceAreaType or str) -- 服务区类型
返回: 服务区分析结果
返回类型: list[ServiceAreaResult]
-
find_tsp_path(parameter, is_end_node_assigned=False)¶ 旅行商分析。
旅行商分析是查找经过指定一系列点的路径,旅行商分析是无序的路径分析。旅行商可以自己决定访问结点的顺序,目标是旅行路线阻抗总和最小(或接近最小)。
旅行商分析的经过点是在 TransportationAnalystParameter 类型的参数 parameter 中指定的。通过 TransportationAnalystParameter 对象有两种方式可以指定经过点:
- 使用该对象的
TransportationAnalystParameter.set_nodes()方法,以网络数据集中结点 ID 数组的形式指定旅行商分 析经过的点,因此分析过程中经过的点就是相应的网络结点; - 使用该对象的
TransportationAnalystParameter.set_points()方法,以坐标点串的形式指定旅行商分析经过的点,因此 分析过程中经过的点就是相应的坐标点。
需要强调的是,此方法默认将给定的经过点集合中的第一个点(结点或坐标点)作为旅行商的起点。此外,用户还可以指定终点(对应方法中 的 is_end_node_assigned 参数)。如果选择指定终点,则给定的经过点集合的最后一个点为终点,此时旅行商从第一个给定点出发,到指 定的终点结束,而其他经过点的访问次序由旅行商自己决定。
另外,如果选择指定终点,终点可以与起点相同,即经过点集合中的最后一个点与第一个点相同。此时,旅行商分析的结果是一条闭合路径 ,即从起点出发,最终回到该点。
注意:使用该方法时,如果选择指定终点(对应方法中的 is_end_node_assigned 参数),指定的经过点集合的第一个点与最后一点可以 相同,也可以不同;其他点不允许有相同的点,否则会分析失败;当不指定终点时,不允许有相同的点,如果有相同点,分析会失败。
需要注意,网络分析中的旅行商分析(
find_path()方法)与最佳路径分析类似,都是在网络中寻找遍历所有经过点的花费 最少的路径。但二者具有明显的区别,即在遍历经过点时,二者对访问经过点的顺序处理有所不同:- 最佳路径分析:必须按照给定的经过点的次序访问所有点;
- 旅行商分析:需要确定最优次序来访问所有点,而并不一定按照给定的经过点的次序。
参数: - parameter (TransportationAnalystParameter) -- 交通网络分析参数对象。
- is_end_node_assigned (bool) -- 是否指定终点。指定为 true 表示指定终点,此时给定的经过点集合中最后一个点即为终点;否则不指定终点。
返回: 旅行商分析结果
返回类型: - 使用该对象的
-
find_vrp(parameter, vehicles, center_nodes_or_points, demand_points)¶ 物流配送分析。 该接口和之前的物流配送接口
find_mtsp_path()相比,多出了车辆信息、需求量等的设置,可以更充分的满足不同情况下的需求。物流配送分析参数对象
VRPAnalystParameter可以设置障碍边、障碍点、权值字段信息的名字标识、转向权值字段,还可以对分析结果进行 一些设置,即在分析结果中是否包含分析途经的以下内容:结点集合,弧段集合,路由对象集合以及站点集合。车辆信息
VehicleInfo中可以设置每辆车各自的负载量、最大耗费等条件。中心点信息 center_nodes_or_points 中可以设置包括中心的坐标或者结点ID;需求点信息 demand_points 中可以设置每个需求点的坐标或者结点ID,以及各自的需求量。
通过对车辆、需求点和中心点相关信息的设置,该接口可以根据这些条件来合理划分路线,完成相应的分配任务。
参数: - parameter (VRPAnalystParameter) -- 物流配送分析参数对象。
- vehicles (list[VehicleInfo] or tuple[VehicleInfo]) -- 车辆信息数组
- center_nodes_or_points (list[int] or list[Point2D] or tuple[int] or tuple[Point2D]) -- 中心点信息数组
- demand_points (list[DemandPointInfo] or tuple[DemandPointInfo]) -- 需求点信息数组
返回: 物流配送结果
返回类型: list[VRPAnalystResult]
-
load()¶ 加载网络模型。 该方法根据交通网络分析环境设置(TransportationAnalystSetting)对象中的环境参数,加载网络模型。在设置好交通网络分析环境的 参数后又修改了相关参数,只有调用该方法,所做的交通网络分析环境设置才会在交通网络分析的过程中生效。
返回: 加载成功返回 True,否则返回 False 返回类型: bool
-
set_analyst_setting(analyst_setting)¶ 设置交通网络分析环境设置对象 在利用交通网络分析类进行各种交通网络分析时,都要首先设置交通网络分析的环境,都要首先设置交通网络分析的环境
参数: analyst_setting (TransportationAnalystSetting) -- 交通网络分析环境设置对象 返回: self 返回类型: TransportationAnalyst
-
update_edge_weight(edge_id, from_node_id, to_node_id, weight_name, weight)¶ 该方法用来更新弧段的权值。 该方法用于对加载到内存中的网络模型的弧段权值进行修改,并不会修改网络数据集。
该方法可以更新弧段的正向权值或反向权值。正向权重是指从弧段的起始结点到达终止结点的花费,反向权值为从弧段的终止结点到达起始 结点的花费。因此,指定 from_node_id 为网络数据集中被更新弧段的起始结点 ID,to_node_id 为该弧段的终止结点 ID,则更新正向权值, 反之,指定 from_node_id 为网络数据集中该弧段的终止结点 ID,to_node_id 为该弧段的起始结点 ID,则更新反向权值。
注意,权值为负数表示弧段在该方向禁止通行。
参数: - edge_id (int) -- 被更新的弧段的 ID
- from_node_id (int) -- 被更新的弧段的起始结点 ID。
- to_node_id (int) -- 被更新的弧段的终止结点 ID。
- weight_name (str) -- 被更新的权值字段所属的权值字段信息对象的名称
- weight (float) -- 权值,即用该值更新旧值。单位与 weight_name 指定的权值信息字段对象中权值字段的单位相同。
返回: 成功返回更新前的权值。失败返回-1.7976931348623157e+308
返回类型: float
-
-
class
iobjectspy.analyst.TransportationAnalystResult(java_object, index)¶ 基类:
object交通网络分析结果类。
该类用于返回分析结果的路由集合、分析途经的结点集合以及弧段集合、行驶导引集合、站点集合和权值集合以及各站点的花费。通过该类的设置, 可以灵活地得到最佳路径分析、旅行商分析、物流配送和最近设施查找等分析的结果。
-
edges¶ list[int] -- 返回分析结果的途经弧段集合。注意,必须将 TransportationAnalystParameter 对象的
TransportationAnalystParameter.set_edges_return()方法设置为 True,分析结果中才会包含途经弧段集合,否则返回 None
-
nodes¶ list[int] -- 返回分析结果的途经结点集合。注意,必须将 TransportationAnalystParameter 对象的
TransportationAnalystParameter.set_nodes_return()方 法设置为 True,分析结果中才会包含途经结点集合,否则为一个空的数组。
-
path_guides¶ PathGuide -- 返回行驶导引。注意,必须将 TransportationAnalystParameter 对象的
TransportationAnalystParameter.set_path_guides_return()方 法设置为 True,分析结果中才会包含行驶导引,否则为一个空的数组。
-
route¶ GeoLineM -- 返回分析结果的路由对象。注意,必须将 TransportationAnalystParameter 对象的
TransportationAnalystParameter.set_routes_return()方 法设置为 true,分析结果中才会包含路由对象,否则返回 None
-
stop_indexes¶ list[int] -- 返回站点索引,该数组反映了站点在分析后的排列顺序。注意,必须将 TransportationAnalystParameter 对象 的
TransportationAnalystParameter.set_stop_indexes_return()方法设置为 True,分析结果中才会 包含站点索引,否则为一个空的数组。在不同的分析中,该方法的返回值代表的含义不一样:
最佳路径分析(
TransportationAnalyst.find_path()方法):- 结点模式:如设置的分析结点 ID 为 1,3,5 的三个结点,因为结果途经顺序必须为 1,3,5,所以元素值依 次为 0,1,2,即结果途经顺序在初始设置结点串中的索引。
- 坐标点模式:如设置的分析坐标点为 Pnt1,Pnt2,Pnt3,因为结果途经顺序必须为 Pnt1,Pnt2,Pnt3,所以元 素值依次为 0,1,2,即结果途经坐标点顺序在初始设置坐标点串中的索引。
旅行商分析(
TransportationAnalyst.find_tsp_path()方法):- 结点模式:如设置的分析结点 ID 为 1,3,5 的三个结点,而结果途经顺序为 3,5,1,则元素值依次为 1,2,0,即结果途经顺序在初始设置结点串中的索引。
- 坐标点模式:如设置的分析坐标点为 Pnt1,Pnt2,Pnt3,而结果途经顺序为 Pnt2,Pnt3,Pnt1,则元素值 依次为 1,2,0,即结果途经坐标点顺序在初始设置坐标点串中的索引。
多旅行商分析(
TransportationAnalyst.find_mtsp_path()方法):元素的含义与旅行商分析相同,表示对应的中心点的配送路径经过站点的次序。注意,配送模式为局部最优时,所有中 心点参与配送,为总花费最小模式时,参与配送的中心点数可能少于指定的中心点数。
对于最近设施查找分析(
TransportationAnalyst.find_closest_facility()方法),该方法无效。
-
stop_weights¶ list[float] -- 返回根据站点索引对站点排序后,站点间的花费(权值)。 该方法返回的是站点与站点间的耗费,这里的站点指的是用于分析结点或坐标点,而不是路径经过的所有结点或坐标点。 该方法返回的权值所关联的站点顺序与
stop_indexes方法中返回的站点索引值的顺序一致,但对于不同的分析功能需注意其细微差别。例如:- 最佳路径分析(
TransportationAnalyst.find_path()方法): 假设指定经过点 1、2、3,则二维元素依次 为:1 到 2 的耗费、2 到 3 的耗费; - 旅行商分析(
TransportationAnalyst.find_tsp_path()方法):假设指定经过点 1、2、3,分析结果中站点 索引为 1、0、2,则二维元素依次为:2 到 1 的耗费、1 到 3 的耗费; - 多旅行商分析(
TransportationAnalyst.find_mtsp_path()方法): 即物流配送,元素为该路径所经过的站点的之间的耗费, 需要注意的是,多旅行商分析的路径经过的站点是包括中心点的,且路径的起终点均是中心点。例如,一条结果路径是 从中心点 1 出发,经过站点 2、3、4,对应的站点索引为 1、2、0,则站点权重依次为:1 到 3 的耗费、3 到 4 的 耗费、4 到 2 的耗费和 2 到 1 的耗费。 - 对于最近设施查找分析(
TransportationAnalyst.find_closest_facility()方法),该方法无效。
- 最佳路径分析(
-
weight¶ float -- 花费的权值。
-
-
class
iobjectspy.analyst.MapMatching(path_analyst_setting=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase基于HMM(隐式马尔科夫链)的地图匹配。 将轨迹点按照标识字段进行划分,按时间字段进行排序和分割轨迹,找到每条轨迹最可能的经过路线。目的是基于轨迹点还原真实路径。
初始化对象
参数: path_analyst_setting (PathAnalystSetting) -- 最佳路径分析参数 -
batch_match(points)¶ 批量地图匹配,输入一连串点进行地图匹配。注意,本方法默认认为输入的点串同属于一条轨迹线路。
参数: points (list[TrackPoint] or tuple[TrackPoint]) -- 待匹配的轨迹点 返回: 地图匹配结果 返回类型: MapMatchingResult
-
batch_match_dataset(source_dataset, id_field, time_field, split_time_milliseconds, out_data=None, out_dataset_name=None, result_track_index_field='TrackIndex')¶ 对数据集进行地图匹配,结果保存为点数据
参数: - source_dataset (DatasetVector or str) -- 原始轨迹点数据集
- id_field (str) -- 轨迹的 ID 字段,相同 ID 值相同的轨迹点属于一条轨迹,比如手机号、车牌号等。没有指定 ID 字段时,数据集中所有点将归类为一条轨迹。
- time_field (str) -- 轨迹点的时间字段,必须为时间或时间戳类型字段
- split_time_milliseconds (float) -- 分割轨迹的时间间隔,如果时间相邻的两个点的时间间隔大于指定的分割轨迹的时间间隔,将从两个点间分割轨迹。
- out_data (Datasource or str) -- 保存结果数据集的数据源
- out_dataset_name (str) -- 结果数据集名称
- result_track_index_field (str) -- 保存轨迹索引的字段,轨迹分割后,一条轨迹可能分割为多条子轨迹, result_track_index_field 将会保存子轨迹的索引值,值从1开始。 因为结果数据集会保 存源轨迹点数据集的所有字段,所以必须确保 result_track_index_field 字段值在源轨 迹点数据集中是没有被占用。
返回: 结果轨迹点数据集,正确匹配到道路上的轨迹点。
返回类型:
-
match(point, is_new_track=False)¶ 实时地图匹配。实时地图匹配每次只输入一个轨迹点,但在这之前的轨迹点匹配的信息将会继续保留以用于当次匹配。 实时地图匹配返回的结果可能有多个,返回的结果数由当前点能匹配到的道路决定,返回的结果按照结果可能性从大到小排列。在轨迹线没有 完成匹配之前,当前结果返回的结果只反应当前轨迹点及之前点的可能结果。
当 is_new_track 为 True 时,表示将开启新的轨迹线,之前的匹配记录和信息将会清空,当前点将作为轨迹的第一个点。
参数: - point (TrackPoint) -- 待匹配轨迹点
- is_new_track (bool) -- 是否开启新的轨迹
返回: 实时地图匹配
返回类型: list[MapMatchingLikelyResult]
-
max_limited_speed¶ float -- 最大限制速度
-
measurement_error¶ float -- 轨迹点误差值
-
path_analyst_setting¶ PathAnalystSetting -- 最佳路径分析参数
-
set_max_limited_speed(value)¶ 设置最大限制速度。单位为km/h。对相邻两个点计算出来的速度值大于指定的限制速度时,则认为这两个点不可达,即没有有效的道路相通。 默认值为 150 km/h。
参数: value (float) -- 返回: self 返回类型: MapMatching
-
set_measurement_error(value)¶ 设置轨迹点误差值。比如 GPS误差值,单位为米。如果轨迹点到最近道路的距离超出误差值,则认为轨迹点非法。所以,设定一个合理的 误差值对地图匹配的结果有直接影响,如果得到的轨迹点精度高,设置 一个较小的值可以有效提升性能,例如,15米。默认值为 30米。
参数: value (float) -- 轨迹点误差值 返回: self 返回类型: MapMatching
-
set_path_analyst_setting(path_analyst_setting)¶ 设置最佳路径分析参数
参数: path_analyst_setting (PathAnalystSetting) -- 最佳路径分析参数 返回: self 返回类型: MapMatching
-
-
class
iobjectspy.analyst.MapMatchingResult(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase地图匹配结果类。包括匹配后得到的轨迹点、轨迹线、弧段id、匹配正确率、错误率等。
-
edges¶ list[int] -- 每条匹配路径经过的弧段ID
-
evaluate_error(truth_edges)¶ 评估当前地图匹配结果的错误率。 输入真实的道路线对象,计算匹配结果的错误率。
参数: truth_edges (list[GeoLine] or tuple[GeoLine]) -- 真实的道路线对象 返回: 当前结果的错误率 返回类型: float
-
evaluate_truth(truth_edges)¶ 评估当前地图匹配结果的正确性。 输入真实的道路线对象,计算匹配结果的正确性。
计算正确性的公式为:
参数: truth_edges (list[GeoLine] or tuple[GeoLine]) -- 真实的道路线对象 返回: 当前结果的正确性 返回类型: float
-
rectified_points¶ list[Point2D] -- 地图匹配后的轨迹点,它对应于每个输入点进行处理的点,数组大小等于输入点数目。
-
track_line¶ GeoLine -- 结果轨迹线对象。将
track_points构造成的线对象。
-
track_points¶ list[Point2D] -- 地图匹配后得到的轨迹点串,轨迹点串去掉了重复点以及一些匹配失败的点
-
-
class
iobjectspy.analyst.MapMatchingLikelyResult(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase实时地图匹配结果类
-
distance_to_road¶ float -- 原始轨迹点到当前轨迹路径的最近距离。
-
edges¶ list[int] -- 匹配路径经过的弧段ID
-
evaluate_error(truth_edges)¶ 评估当前地图匹配结果的错误率。 输入真实的道路线对象,计算匹配结果的错误率。
参数: truth_edges (list[GeoLine] or tuple[GeoLine]) -- 真实的道路线对象 返回: 当前结果的错误率 返回类型: float
-
evaluate_truth(truth_edges)¶ 评估当前地图匹配结果的正确性。 输入真实的道路线对象,计算匹配结果的正确性。
计算正确性的公式为:
参数: truth_edges (list[GeoLine] or tuple[GeoLine]) -- 真实的道路线对象 返回: 当前结果的正确性 返回类型: float
-
probability¶ float -- 实时地图匹配时,计算当前点归属哪条道路时,算法会生成该点到附近所有可能道路的匹配概率值,选择概率值最高的作为该 点的匹配道路
-
rectified_point¶ Point2D -- 地图匹配后的轨迹点,它对应于每个输入点进行处理的点,数组大小等于输入点数目。
-
track_line¶ GeoLine -- 结果轨迹线对象。将
track_points构造成的线对象。
-
track_points¶ list[Point2D] -- 地图匹配后得到的轨迹点串,轨迹点串去掉了重复点以及一些匹配失败的点
-
-
class
iobjectspy.analyst.TrajectoryPreprocessingResult(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase轨迹预处理结果类
-
rectified_points¶ list[Point2D] -- 处理后的轨迹点,它对应于每个输入点进行处理的点,数组大小等于输入点数目。
-
track_line¶ GeoLine -- 处理后轨迹点生成的轨迹线
-
track_points¶ list[Point2D] -- 处理后得到的轨迹点。比如将重复点都去掉后剩余的轨迹点
-
-
iobjectspy.analyst.split_track(track_points, split_time_milliseconds)¶ 轨迹切分,根据时间间隔,将轨迹进行分段。
参数: - track_points (list[TrackPoint] or tuple[TrackPoint]) -- 轨迹点串
- split_time_milliseconds (float) -- 时间间隔值,单位为毫秒。当时间连续的两个点之间的时间间隔大于指定的时间间隔值时,将会从 两个点之间将轨迹分割
返回: 结果轨迹段
返回类型: list[list[TrackPoint]]
-
iobjectspy.analyst.build_facility_network_directions(network_dataset, source_ids, sink_ids, ft_weight_field='SmLength', tf_weight_field='SmLength', direction_field='Direction', node_type_field='NodeType', progress=None)¶ 根据指定网络数据集中源与汇的位置,为网络数据集创建流向。创建流向以后的网络数据集才可以进行各种设施网络分析。 设施网络是具有方向的网络,因此,在创建网络数据集之后,必须为其创建流向,才能够用于进行各种设施网络路径分析、连通性分析、上下游追踪等。
流向是指网络中资源流动的方向。网络中的流向由源和汇决定:资源总是从源点流出,流向汇点。该方法通过给定的源和汇,以及设施网络分析参数 设置为网络数据集创建流向。创建流向成功后,会在网络数据集中写入两方面的信息:流向和结点类型。
流向
流向信息将写入网络数据集的子线数据集的流向字段中,如果不存在则会创建该字段。
流向字段的值共有四个:0,1,2,3,其含义如下图所示。以线段 AB 为例:
0 代表流向与数字化方向相同。线段 AB 的数字化方向为 A-->B,且 A 为源点,因此 AB 的流向为从 A 流到 B,即与其数字化方向相同。
1 代表流向与数字化方向相反。线段 AB 的数字化方向为 A-->B,且 A 为汇点,因此 AB 的流向为从 B 流向 A,即与其数字化方向相反。
2 代表无效方向,也称不确定流向。A 和 B 均为源点,则资源既可以从 A 流向 B,又可以从 B 流向 A,这就构成了一个无效的流向。
3 代表不连通边,也称未初始化方向。线段 AB 与源点、汇点所在的结点不连通,则称为不连通边。
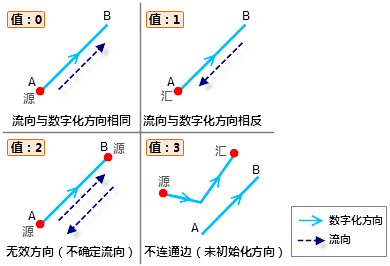
结点类型
建立流向后,系统还会将结点类型信息写入指定的网络数据集的子点数据集的结点类型字段中。结点类型分为源点、汇点和普通结点。 下表列出了结点类型字段的值及其含义:
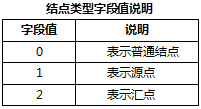
参数: - network_dataset (DatasetVector or str) -- 待创建流向的网络数据集,网络数据集必须可修改。
- source_ids (list[int] or tuple[int]) -- 源对应的网络结点 ID 数组。源与汇都是用来建立网络数据集的流向的。网络数据集的流向与源和汇的位置决定。
- sink_ids (list[int] or tuple[int]) -- 汇 ID 数组。汇对应的网络结点 ID 数组。源与汇都是用来建立网络数据集的流向的。网络数据集的流向与源和汇的位置决定。
- ft_weight_field (str) -- 正向权值字段或字段表达式
- tf_weight_field (str) -- 反向权值字段或字段表达式
- direction_field (str) -- 流向字段,用于保存网络数据集的流向信息
- node_type_field (str) -- 结点类型字段名称,结点类型分为源结点、交汇结点、普通结点。该字段是网络结点数据集中的字段,如果不存在则创建该字段。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 创建成功返回 true,否则 false
返回类型: bool
-
iobjectspy.analyst.build_network_dataset(lines, points=None, split_mode='NO_SPLIT', tolerance=0.0, line_saved_fields=None, point_saved_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 网络数据集是进行网络分析的数据基础。网络数据集由两个子数据集(一个线数据集和一个点数据集)构成,分别存储了网络模型的弧段和结点, 并且描述了弧段与弧段、弧段与结点、结点与结点间的空间拓扑关系。
此方法提供根据单个线数据集或多个线和点数据集构建网络数据集。如果用户的数据集已经有正确的网络关系,可以直接通过
build_network_dataset_known_relation()快 速的构建一个网络数据集。构建的网络数据集,可以通过
validate_network_dataset()检查网络拓扑关系是否正确。参数: - lines (DatasetVector or list[DatasetVector]) -- 用于构建网络数据集的线数据集,必须至少有一个线数据集。
- points (DatasetVector or list[DatasetVector]) -- 用于构建网络数据集的点数据集。
- split_mode (NetworkSplitMode) -- 打断模式,默认为不打断
- tolerance (float) -- 节点容限
- line_saved_fields (str or list[str]) -- 线数据集中需要保留的字段
- point_saved_fields (str or list[str]) -- 点数据集中需要保留的字段。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 保留结果网络数据集的数据源对象
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果网络数据集
返回类型:
-
iobjectspy.analyst.fix_ring_edge_network_errors(network_dataset, error_ids, edge_id_field=None, f_node_id_field=None, t_node_id_field=None, node_id_field=None)¶ 修复网络数据集拓扑错误中弧段的首尾结点相等这种拓扑错误,关于网络数据集的拓扑错误检查,具体参考
validate_network_dataset().对于首尾相等的弧段,会自动取弧段的中心点将弧段打断为两条。
参数: - network_dataset (str or DatasetVector) -- 待处理的网络数据集
- error_ids (list[int] or tuple[int] or str) -- 首尾相等弧段的 SmID。
- edge_id_field (str) -- 网络数据集的弧段 ID 字段,如果为空,则默认使用网络数据集中存储的弧段 ID字段。
- f_node_id_field (str) -- 网络数据集的起始结点 ID 字段,如果为空,则默认使用网络数据集中存储的起始结点 ID字段。
- t_node_id_field (str) -- 网络数据集的终止结点 ID 字段,如果为空,则默认使用网络数据集中存储的终止结点 ID字段。
- node_id_field (str) -- 网络数据集的结点 ID 字段,如果为空,则默认使用网络数据集中存储的结点 ID字段。
返回: 成功返回 True, 失败返回 False
返回类型: bool
-
iobjectspy.analyst.build_facility_network_hierarchies(network_dataset, source_ids, sink_ids, direction_field, is_loop_valid, ft_weight_field='SmLength', tf_weight_field='SmLength', hierarchy_field='Hierarchy', progress=None)¶ 为具有流向的网络数据集创建等级,并在指定的等级字段中写入网络数据集的等级信息。
为网络数据集建立等级,首先,该网络数据集必须已经建立了流向,即建立等级的方法所操作的网络数据集必须具有流向信息。
等级字段中以整数的形式记录等级,数值从 1 开始,等级越高数值越小,如河流建立等级后,一级河流的等级记录为 1,二级河流的等级记录 为 2,以此类推。注意,值为 0 表示未能确定等级,通常是由于该弧段为不连通弧段导致。
参数: - network_dataset (DatasetVector or str) -- 待创建等级的网络数据集,网络数据集必须可修改。
- source_ids (list[int]) -- 源 ID 数组
- sink_ids (list[int]) -- 汇 ID 数组
- direction_field (str) -- 流向字段
- is_loop_valid (bool) -- 指定环路是否有效。当该参数为 true 时,环路有效;而当参数为 false 时,环路无效。
- ft_weight_field (str) -- 正向权值字段或字段表达式
- tf_weight_field (str) -- 反向权值字段或字段表达式
- hierarchy_field (str) -- 给定的等级字段名称,用于存储等级信息。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 创建成功返回 true,否则 false
返回类型: bool
-
iobjectspy.analyst.build_network_dataset_known_relation(line, point, edge_id_field, from_node_id_field, to_node_id_field, node_id_field, out_data=None, out_dataset_name=None, progress=None)¶ 根据点、线数据及其已有的表达弧段结点拓扑关系的字段,构建网络数据集。 当已有的线、点数据集中的线、点对象分别对应着待构建网络的弧段和结点,并具有描述二者空间拓扑关系的信息,即线数据集含有弧段 ID、弧段 起始结点 ID 和终止结点 ID 字段,点数据集含有点对象的结点 ID 字段时,可以采用本方法构建网络数据集。
使用此方式构建网络数据集成功后,结果对象数与源数据的对象数一致,即线数据中一个线对象作为一个弧段写入,点数据中一个点对象作为一个 结点写入,并且保留点、线数据集的所有非系统字段到结果数据集中。
例如,对于用于建立管网而采集的管线、管点数据,管线和管点均使用唯一固定编码来标识。管网的特点之一是管点只位于管线的两端,因此管点 对应了待构建管网的所有结点,管线对应了待构建管网的所有弧段,不需要在管线与管线相交处打断。在管线数据中,记录了管线对象两端的管点 信息,即起始管点编码和终止管点编码,也就是说管线和管点数据中已经蕴含了二者空间拓扑关系的信息,因此适合使用此方法构建网络数据集。
注意,使用此方式构建的网络数据集的弧段 ID、弧段起始结点 ID、弧段终止结点 ID 和结点 ID 字段即为调用此方法时指定的字段,而不再 是 SmEdgeID、SmFNode、SmTNode、SmNodeID 等系统字段。具体可以通过 DatasetVector 的
DatasetVector.get_field_name_by_sign()方法获取到相应的字段。参数: - line (str or DatasetVector) -- 用于构建网络数据集的线数据集
- point (str or DatasetVector) -- 用于构建网络数据集的点数据集
- edge_id_field (str) -- 指定的线数据集中表示弧段 ID 的字段。如果指定为 null 或空字符串,或指定的字段不存在,则自动使用 SMID 作为弧段 ID。 仅支持 16 位整型、32 位整型字段。
- from_node_id_field (str) -- 指定的线数据集中表示弧段的起始结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- to_node_id_field (str) -- 指定的线数据集中表示弧段的终止结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- node_id_field (str) -- 指定的点数据集中表示结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 保留结果网络数据集的数据源对象
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果网络数据集
返回类型:
-
iobjectspy.analyst.append_to_network_dataset(network_dataset, appended_datasets, progress=None)¶ 向已有的网络数据集追加数据,可以追加点、线或网络。 网络数据集一般由线数据(以及点数据)构建而成。一旦构建网络的数据发生变化,原有网络就会过时,如果不及时更新网络,就可能影响分析 结果的正确性。通过将新增数据追加到原有网络的方式,可以不必重新构建网络而得到较新的网络。如下图所示,某区域新建了若干道路(红色线) ,将这些道路抽象为线数据,追加到扩建之前所构建的网络上,从而更新了路网。
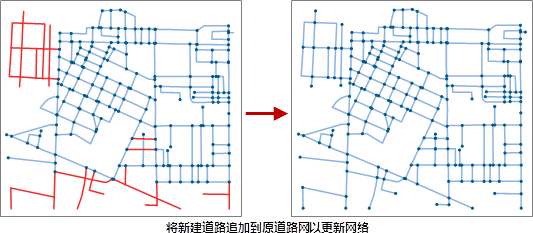
此方法支持向已有网络追加点、线以及网络数据集,并且可以同时追加多个相同或不同类型的数据集,例如,同时追加一份点数据和两份线数据。 注意,如果追加的数据具有多种类型,系统将按照先追加网络,再追加线,最后追加点的顺序来依次追加。下面分别介绍向网络中追加点、线和网络的方式和规则。
向已有网络追加点:
点被追加到已有网络后,将成为网络中新的结点。向已有网络追加点时,需要注意以下要点:
- 待追加的点必须在已有网络的弧段上。追加后,在弧段上该点位置处增加新的结点,该弧段将自动在新增结点处断开为两条弧段,如下图中的点 a、点 d。如果待追加的点不在网络上,即不在弧段上,也不与结点重叠,将被忽略,不会追加到网络上,因为孤立结点在网络中并无地学意义。下图中的点 b 就属于这种情况。
- 如果待追加的点与已有网络的结点重叠,则将待追加点与重叠结点合并,如下图中的点 c。
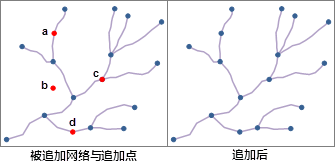
向已有网络追加线
线被追加到已有网络后,将成为网络中新的弧段,并且在线的端点、与其他线(或弧段)的交点处打断并增加新的结点。向已有网络追加点时,需要注意以下要点:
- 待追加的线不能存在与已有网络弧段重叠或部分重叠,否则会导致追加后的网络存在错误。
向已有网络追加另一网络
将一个网络追加到已有网络后,二者将成为一个网络,如下图所示。注意,与追加线相同,向已有网络中追加网络时,需要确保这两个网络不存在 弧段的重叠或部分重叠,否则会导致追加后的网络存在错误。
待追加网络与被追加网络叠加出现弧段相交的情形时,在相交处会添加新的结点,从而建立新的拓扑关系。
网络的连通性不影响网络的追加。如下例中,将待追加网络追加到原始网络后,结果是一个包含两个子网的网络数据集,并且两子网不连通。
注意:
- 该方法将直接修改被追加的网络数据集,不会生成新的网络数据集。
- 待追加的点、线或网络数据集必须与被追加的网络数据集具有相同的坐标系。
- 待追加的点、线或 网络数据集中,如果存在与网络数据集相同(名称和类型都必须相同)的属性字段,那么这些属性值会自动保留到追加后 的网络数据集中;如果不存在相同的字段,则不保留。其中,点数据集、网络数据集的结点数据集的属性,保留到被追加网络的结点属性表 中;线数据集的属性,保留到被追加网络的弧段属性表中。
参数: - network_dataset (DatasetVector or str) -- 被追加的网络数据集
- appended_datasets (list[DatasetVector]) -- 指定的待追加的数据,可以是点、线或网络数据集。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 是否追加成功。如果成功,返回 True,否则返回 False.
返回类型: bool
-
iobjectspy.analyst.validate_network_dataset(network_dataset, edge_id_field=None, f_node_id_field=None, t_node_id_field=None, node_id_field=None)¶ 该方法用于对网络数据集进行检查,给出错误信息,便于用户针对错误信息对数据进行修改,以避免由于数据错误导致网络分析错误。
对网络数据集进行检查的结果错误类型如下表所示:

参数: - network_dataset (DatasetVector or str) -- 被检查的网络数据集或三维网络数据集
- edge_id_field (str) -- 网络数据集的弧段 ID 字段,如果为空,则默认使用网络数据集中存储的弧段 ID字段。
- f_node_id_field (str) -- 网络数据集的起始结点 ID 字段,如果为空,则默认使用网络数据集中存储的起始结点 ID字段。
- t_node_id_field (str) -- 网络数据集的终止结点 ID 字段,如果为空,则默认使用网络数据集中存储的终止结点 ID字段。
- node_id_field (str) -- 网络数据集的结点 ID 字段,如果为空,则默认使用网络数据集中存储的结点 ID字段。
返回: 网络数据集错误结果信息。
返回类型:
-
iobjectspy.analyst.compile_ssc_data(parameter, progress=None)¶ 将网络数据编译为包含捷径信息的SSC文件
参数: - parameter (SSCCompilerParameter) -- SSC文件编译参数类。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 成功返回 True,失败返回 False
返回类型: bool
-
class
iobjectspy.analyst.AllocationDemandType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum资源分配需求模式
变量: - AllocationDemandType.NODE -- 结点需求模式。这种模式下,分析时只考虑结点对资源的需求量,将弧段的需求排除。例如在圣诞节,圣 诞老人给儿童派送礼物,圣诞老人的位置为固定中心点、礼物数为资源量,儿童住址为需求结点、某个 儿童对礼物数量的需求为该结点的结点需求字段值。很明显圣诞老人结儿童派送礼物时,我们只考虑礼物 的分配则这就是一个结点需求事件。
- AllocationDemandType.EDGE -- 弧段需求模式。这种模式下,分析时只考虑弧段对资源的需求量,将结点的需求排除。例如在圣诞节,圣 诞老人给儿童派送礼物,圣诞老人的位置为固定中心点、圣诞老人汽车汽油存量为资源量,儿童住址为需求 结点、从固定中心点至相邻儿童住址以及相邻儿童住址见的行驶油耗为弧段需求字段值。很明显圣诞老人结 儿童派送礼物时,我们只考虑行驶油耗的分配则这就是一个弧段需求事件。
- AllocationDemandType.BOTH -- 结点和弧段需求模式。同时考虑结点的需求和弧段的需求。例如在圣诞节,圣诞老人给儿童派送礼物,即 考虑礼物的分配又考虑行驶油耗则这就是一个结点和弧段需求事件。
-
BOTH= 3¶
-
EDGE= 2¶
-
NODE= 1¶
-
class
iobjectspy.analyst.AllocationAnalystResult(nodes, edges, demands, routes, node_id)¶ 基类:
object资源分配分析结果类。
-
demand_results¶ DemandResult -- 需求结果对象
-
edges¶ list[int] -- 分析结果中经过的弧段ID集合
-
nodes¶ list[int] -- 分析结果中经过的结点ID集合
-
static
parse(java_object, supply_centers)¶
-
routes¶ GeoLineM -- 资源分配分析出的分配路径路由结果。
-
supply_center_node_id¶ int -- 所属的资源供给中心点的 ID
-
-
class
iobjectspy.analyst.BurstAnalystResult(java_object)¶ 基类:
object爆管分析结果类。爆管分析结果返回关键设施点、普通设施点以及弧段。
-
critical_nodes¶ list[int] -- 爆管分析中影响爆管位置上下游的关键设施点。 关键设施点包括两种设施点:
- 爆管位置上游中所有对爆管位置直接影响的设施点。
- 下游中受爆管位置直接影响且有流出(即出度大于0)的设施点。
-
edges¶ list[int] -- 上下游影响爆管位置的弧段和受爆管位置影响的弧段。是从爆管位置进行双向搜索关键设施点和普通设施点遍历到的弧段。
-
normal_nodes¶ list[int] -- 爆管分析中受爆管位置影响的普通设施点。 普通设施点包括三种设施点:
- 受爆管位置直接影响且没有流出(出度为0)的设施点。
- 每个上游关键设施点的流出弧段直接影响的所有设施点A(除去所有关键设施点),且设施点A需要满足,上游关键设施点 到设施点A的影响弧段与上下游关键设施点的影响弧段有公共部分。
- 爆管位置下游受爆管位置直接影响的设施点A(关键设施点2和普通设施点1),设施点A上游中直接影响设施点A的设施 点B(除去所有关键设施点),且需要满足,设施点A到设施点B的影响弧段与上下游关键设施点的影响弧段有公共部分。
-
-
class
iobjectspy.analyst.DemandPointInfo¶ 基类:
object需求点信息类。存储了需求点的坐标或者结点ID,以及需求点的需求量。
-
demand_node¶ int -- 需求点ID
-
demand_point¶ Point2D -- 需求点坐标
-
demands¶ list[float] -- 需求点的需求量。
-
end_time¶ datetime.datetime -- 达到最晚时间,表示车辆到达该点的最晚时间点
-
set_demand_node(value)¶ 设置需求点ID
参数: value (int) -- 需求点ID 返回: self 返回类型: DemandPointInfo
-
set_demand_point(value)¶ 设置需求点坐标
参数: value (Point2D) -- 需求点坐标 返回: self 返回类型: DemandPointInfo
-
set_demands(value)¶ 设置需求点的需求量。需求量可以为多维,其维度必须和车辆负载维度和意义相同。若某目的地的需求量过大超过车辆最大负载,分析中会舍弃此点。
参数: value (list[float] or tuple[float]) -- 需求点的需求量。 返回: self 返回类型: DemandPointInfo
-
set_end_time(value)¶ 设置达到最晚时间
参数: value (datetime.datetime) -- 达到最晚时间,表示车辆到达该点的最晚时间点 返回: self 返回类型: DemandPointInfo
-
set_start_time(value)¶ 设置到达最早时间。
参数: value (datetime.datetime or str) -- 到达最早时间,表示车辆到达该点的最早时间点 返回: self 返回类型: DemandPointInfo
-
set_unload_time(value)¶ 设置卸载货物时间。
参数: value (int) -- 卸载货物时间,表示车辆在该点需要停留的时间。单位默认为分钟。 返回: self 返回类型: DemandPointInfo
-
start_time¶ datetime.datetime -- 到达最早时间,表示车辆到达该点的最早时间点
-
unload_time¶ int -- 卸载货物时间,表示车辆在该点需要停留的时间。单位默认为分钟。
-
-
class
iobjectspy.analyst.DirectionType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum方向,用于行驶导引
变量: - DirectionType.EAST -- 东
- DirectionType.SOUTH -- 南
- DirectionType.WEST -- 西
- DirectionType.NORTH -- 北
- DirectionType.NONE -- 结点没有方向
-
EAST= 0¶
-
NONE= 4¶
-
NORTH= 3¶
-
SOUTH= 1¶
-
WEST= 2¶
-
class
iobjectspy.analyst.VRPAnalystType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum物流分析中分析模式
变量: - VRPAnalystType.LEASTCOST -- 耗费最少模式
- VRPAnalystType.AVERAGECOST -- 平均耗费模式
- VRPAnalystType.AREAANALYST -- 区域分析模式
-
AREAANALYST= 2¶
-
AVERAGECOST= 1¶
-
LEASTCOST= 0¶
-
class
iobjectspy.analyst.VRPDirectionType¶ 基类:
iobjectspy._jsuperpy.enums.JEnumVRP分析路线的类型
变量: - VRPDirectionType.ROUNDROUTE -- 从中心点出发并回到中心点。
- VRPDirectionType.STARTBYCENTER -- 从中心点出发但不回到中心点。
- VRPDirectionType.ENDBYCENTER -- 不从中心点出发但回到中心点。
-
ENDBYCENTER= 2¶
-
ROUNDROUTE= 0¶
-
STARTBYCENTER= 1¶
-
class
iobjectspy.analyst.VRPAnalystParameter¶ 基类:
object物流配送分析参数设置类。
该类主要用来对物流配送分析的参数进行设置。通过交通网络分析参数设置类可以设置障碍边、障碍点、权值字段信息的名字标识,还可以对分析结果 进行一些设置,即在分析结果中是否包含分析途经的以下内容:结点集合,弧段集合,路由对象集合以及站点集合。
-
analyst_type¶ VRPAnalystType -- 物流分析中的分析模式
-
barrier_edges¶ list[int] -- 障碍弧段 ID 列表
-
barrier_nodes¶ list[int] -- 障碍结点 ID 列表
-
barrier_points¶ list[Point2D] -- 障碍结点的坐标列表
-
is_edges_return¶ bool -- 分析结果中是否包含途经弧段
-
is_nodes_return¶ bool -- 分析结果中是否包含结点
-
is_path_guides_return¶ bool -- 分析结果中是否包含行驶导引
-
is_routes_return¶ bool -- 分析结果中是否包含路由对象
-
is_stop_indexes_return¶ bool -- 是否包含站点索引
-
route_count¶ int -- 一次分析中派出车辆数目值
-
set_analyst_type(value=True)¶ 设置物流分析模式,包括 LEASTCOST 最小耗费模式(默认值)、AVERAGECOST 平均耗费模式、AREAANALYST 区域分析模式。
参数: value (VRPAnalystType or str) -- 物流分析模式 返回: self 返回类型: VRPAnalystParameter
-
set_barrier_edges(value=True)¶ 设置障碍弧段 ID 列表
参数: value (list[int]:) -- 障碍弧段 ID 列表 返回: self 返回类型: VRPAnalystParameter
-
set_barrier_nodes(value=True)¶ 设置障碍结点 ID 列表
参数: value (list[int]:) -- 障碍结点 ID 列表 返回: self 返回类型: VRPAnalystParameter
-
set_barrier_points(points=True)¶ 设置障碍结点的坐标列表
参数: points (list[Point2D] or tuple[Point2D]) -- 障碍结点的坐标列表 返回: self 返回类型: VRPAnalystParameter
-
set_edges_return(value=True)¶ 设置分析结果中是否包含途经弧段
参数: value (bool) -- 分析结果中是否包含途经弧段 返回: self 返回类型: VRPAnalystParameter
-
set_nodes_return(value=True)¶ 设置分析结果中是否包含结点
参数: value (bool) -- 分析结果中是否包含结点 返回: self 返回类型: VRPAnalystParameter
-
set_path_guides_return(value=True)¶ 设置分析结果中是否包含行驶导引。
参数: value (bool) -- 分析结果中是否包含行驶导引。必须将该方法设置为 True,并且通过 TransportationAnalystSetting类 的TransportationPathAnalystSetting.set_edge_name_field()方法设置了弧段名称字段,分析结果 中才会包含行驶导引集合,否则将不会返回行驶导引,但不影响分析结果中其他内容的获取。返回: self 返回类型: VRPAnalystParameter
-
set_route_count(value)¶ 设置一次分析中派出车辆数目值。按要求设置,此分析中以车辆数为前提得到线路数,线路数与实际派出车辆数相同;若不设置此参数,默认 派出车辆数不会超过可以提供的车辆总数 N(vehicleInfo[N])
参数: value (int) -- 派出车辆数目 返回: self 返回类型: VRPAnalystParameter
-
set_routes_return(value=True)¶ 设置分析结果中是否包含路由对象的集合
参数: value (bool) -- 分析结果中是否包含路由对象的集合 返回: self 返回类型: VRPAnalystParameter
-
set_stop_indexes_return(value=True)¶ 设置是否包含站点索引
参数: value (bool) -- 是否包含站点索引 返回: self 返回类型: VRPAnalystParameter
-
set_time_weight_field(value)¶ 设置时间字段信息的名称。
参数: value (str) -- 时间字段信息名称,设置的值是 TransportationAnalystSetting中权重字段信息的名称。返回: self 返回类型: VRPAnalystParameter
-
set_vrp_direction_type(value)¶ 设置物流分析路线的类型
参数: value (VRPDirectionType or str) -- 物流分析路线的类型 返回: self 返回类型: VRPAnalystParameter
-
set_weight_name(value)¶ 设置权值字段信息的名称
参数: value (str) -- 权值字段信息的名称 返回: self 返回类型: VRPAnalystParameter
-
time_weight_field¶ str -- 时间字段信息的名称
-
vrp_direction_type¶ VRPDirectionType -- 物流分析路线的类型
-
weight_name¶ str -- 权值字段信息的名称
-
-
class
iobjectspy.analyst.VRPAnalystResult(java_object, index)¶ 基类:
objectVRP分析结果类。
该类用于获取分析结果的路由集合、分析途经的结点集合以及弧段集合、行驶导引集合、站点集合和权值集合以及各站点的花费。以及VRP线路的时 间耗费与负载总耗费。
-
edges¶ list[int] -- 分析结果的途经弧段集合
-
nodes¶ list[int] -- 分析结果的途经结点集合
-
path_guides¶ list[PathGuideItem] -- 返回行驶导引
-
route¶ GeoLineM -- 分析结果的路由对象
-
stop_indexes¶ list[int] -- 站点索引,反映了站点在分析后的排列顺序。
根据不同的分析线路类型
VRPDirectionType,该数组的取值意义有所不同:- ROUNDROUTE: 第一个元素和最后一个元素为中心点索引,其他元素为需求点索引。
- STARTBYCENTER: 第一个元素为中心点索引,其他元素为需求点索引。
- ENDBYCENTER: 最后一个元素为中心点索引,其他元素为需求点索引。
-
stop_weights¶ list[float] -- 根据站点索引对站点排序后,站点间的花费(权值)
-
times¶ list[datetime.datetime] -- 返回物流配送每条线路中各配送点出发的时间(最后一个点除外,其表示到达的时间)
-
vehicle_index¶ int -- 物流配送中每条线路的车辆索引
-
vrp_demands¶ list[int] -- 物流配送中每条线路的负载量
-
weight¶ float -- 每条配送路线的总花费。
-
-
class
iobjectspy.analyst.FacilityAnalyst(analyst_setting)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase设施网络分析类。
设施网络分析类。它是网络分析功能类之一,主要用于进行各类连通性分析和追踪分析。
设施网络是具有方向的网络。即介质(水流、电流等)会根据网络本身的规则在网络中流动。
设施网络分析的前提是已经建立了用于设施网络分析的数据集,建立用于设施网络分析的数据集的基础是建立网络数据集,在此基础上利用
build_facility_network_directions()方法赋予网络数据集特有的用于进行设施网络分析的数据信息,也就是为网络数据集 建立流向,使原有的网络数据集具有了能够进行设施网络分析的最基本的条件 ,此时,就可以进行各种设施网络分析了。如果你的设施网络 具有等级信息,还可以进一步使用build_facility_network_hierarchies()方法添加等级信息。参数: analyst_setting (FacilityAnalystSetting) -- 设置网络分析的环境。 -
analyst_setting¶ FacilityAnalystSetting -- 设施网络分析的环境
-
burst_analyse(source_nodes, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 双向爆管分析,通过指定爆管弧段,查找爆管弧段上下游中对爆管位置产生直接影响的结点以及受爆管位置直接影响的结点
参数: - source_nodes (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 指定的弧段 ID 或 结点 ID,爆管位置。
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 爆管分析结果
返回类型: BurstAnalyseResult
-
check_loops()¶ 检查网络环路,返回构成环路的弧段 ID 数组。
施网络中,环路是指两条或两条以上流向值为 2(即不确定流向)的弧段构成的闭合路径。这意味着环路必须同时满足以下两个条件:
- 是由至少两条弧段构成的闭合路径;
- 构成环路的弧段的流向均为 2,即不确定流向。
有关流向请参阅
build_facility_network_directions()方法。下图是设施网络的一部分,使用不同的符号显示网络弧段的流向。对该网络进行环路检查,检查出两个环路,即图中的红色闭合路径。 而右上方有一条流向为 2 的弧段,由于它未与其他流向同样为 2 的弧段构成闭合路径,因此不是环路:
返回: 构成环路的弧段 ID 数组。 返回类型: list[int]
-
find_common_ancestors(edge_or_node_ids, is_uncertain_direction_valid=False, is_edge_ids=True)¶ 根据给定的弧段 ID 数组或结点 ID 数组,查找这些弧段的共同上游弧段,返回弧段 ID 数组。 共同上游是指多个结点(或弧段)的公共上游网络。该方法用于查找多条弧段的共同上游弧段,即取这些弧段的各自上游弧段的交集部分,结果返回这些弧段的弧段 ID。
如下图所示,流向如图中的箭头所示的方向,前两幅图分别是对结点 1 和结点 2 进行上游追踪的结果,查找出各自的上游弧段(绿色),第 三幅图则是对结点 1 和结点 2 查找共同上游弧段(橙色),容易看出,结点 1 和结点 2 的共同上游弧段,就是它们各自的上游弧段的交集。
参数: - edge_or_node_ids (list[int] or tuple[int]) -- 指定的弧段 ID 数组 或 结点 ID 数组
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_ids (bool) -- edge_or_node_ids 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 弧段 ID 数组
返回类型: list[int]
-
find_common_catchments(edge_or_node_ids, is_uncertain_direction_valid=False, is_edge_ids=True)¶ 根据指定的结点 ID 数组或弧段 ID 数组,查找这些结点的共同下游弧段,返回弧段 ID 数组。
共同下游是指多个结点(或弧段)的公共下游网络。该方法用于查找多个结点的共同下游弧段,即取这些结点的各自下游弧段的交集部分,结果返回这些弧段的弧段 ID。
如下图所示,流向如图中的箭头所示的方向,前两幅图分别是对结点 1 和结点 2 进行下游追踪的结果,查找出各自的下游弧段(绿色),第 三幅图则是对结点 1 和结点 2 查找共同下游弧段(橙色),容易看出,结点 1 和结点 2 的共同下游弧段,就是它们各自的下游弧段的交集。
参数: - edge_or_node_ids (list[int]) -- 指定的结点 ID 数组或弧段 ID 数组
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_ids (bool) -- edge_or_node_ids 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 给定结点的共同下游的弧段 ID 数组
返回类型: list[int]
-
find_connected_edges(edge_or_node_ids, is_edge_ids=True)¶ 根据给定的结点 ID 数组或弧段 ID 数组,查找与这些弧段(或结点)相连通的弧段,返回弧段 ID 数组。 该方法用于查找与给定弧段(或结点)相连通的弧段,查找出连通弧段后,可根据网络拓扑关系,即弧段的起始结点、终止结点查询出相应的连通结点。
参数: - edge_or_node_ids (list[int] or tuple[int]) -- 结点 ID 数组或弧段 ID 数组
- is_edge_ids (bool) -- edge_or_node_ids 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 给定结点的共同下游的弧段 ID 数组
返回类型: list[int]
-
find_critical_facilities_down(source_node_ids, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 下游关键设施查找,即查找给定弧段的关键下游设施结点,返回关键设施结点 ID 数组及给定弧段影响到的下游弧段 ID 数组。 在进行下游关键设施查找分析时,我们将设施网络的结点划分为普通结点和设施结点两类,其中设施结点认为是能够影响网络连通性的结点, 例如供水管网中的阀门;普通结点是不影响网络连通性的结点,如供水管网中的消防栓或三通等。
下游关键设施查找分析将从给定的设施结点中筛选出关键结点,这些关键结点是分析弧段与其下游保持连通性的最基本的结点,也就是说, 关闭这些关键结点后,分析结点与下游无法连通。同时,该分析的结果还包含给定弧段影响的下游弧段并集。
关键设施结点的查找方式可以归纳为:从分析弧段出发,向它的下游查找,每个方向上遇到的第一个设施结点,就是要查找的关键设施结点。
参数: - source_node_ids (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 指定的分析弧段 ID 或结点 ID
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 设施网络分析结果
返回类型:
-
find_critical_facilities_up(source_node_ids, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 上游关键设施查找,即查找给定弧段的上游中的关键设施结点,返回关键结点 ID 数组及其下游弧段 ID 数组。 在进行上游关键设施查找分析时,我们将设施网络的结点划分为普通结点和设施结点两类,其中设施结点认为是能够影响网络连通性的结点, 例如供水管网中的阀门;普通结点是不影响网络连通性的结点,如供水管网中的消防栓或三通等。上游关键设施查找分析需要指定设施结点和 分析结点,其中分析结点可以是设施结点也可以是普通结点。
上游关键设施查找分析将从给定的设施结点中筛选出关键结点,这些关键结点是分析弧段与其上游保持连通性的最基本的结点,也就是说, 关闭这些关键结点后,分析结点与上游无法连通。同时,该分析的结果还包含查找出的关键结点的下游弧段的并集。
关键设施结点的查找方式可以归纳为:从分析弧段出发,向它的上游回溯,每个方向上遇到的第一个设施结点,就是要查找的关键设施结点。 如下图所示,从分析弧段(红色)出发,查找到的关键设施结点包括:2、8、9 和 7。而结点 4 和 11 不是回溯方向上遇到的第一个设施结 点,因此不是关键设施结点。作为示意,这里仅给出了分析弧段的上游部分,但注意分析结果还会给出关键设施结点 2、8、9 和 7 的下游弧段。
- 应用实例
供水管网发生爆管后,可以将所有的阀门作为设施结点,将发生爆裂的管段或管点作为分析弧段或分析结点,进行上游关键设施查找分析, 迅速找到上游中需要关闭的最少数量的阀门。关闭这些阀门后,爆裂管段或管点与它的上游不再连通,从而阻止水的流出,防止灾情加重和 资源浪费。同时,分析得出需要关闭的阀门的下游弧段的并集,也就是关闭阀门后的影响范围,从而确定停水区域,及时做好通知工作和应急措施。
参数: - source_node_ids (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 分析弧段 ID 或结点 ID
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_loops(edge_or_node_ids, is_edge_ids=True)¶ 根据给定的结点 ID 数组或弧段 ID 数组,查找与这些结点(弧段)相连通的环路,返回构成环路的弧段 ID 数组。
参数: - edge_or_node_ids (list[int] or tuple[int]) -- 指定的结点或弧段 ID 数组。
- is_edge_ids (bool) -- edge_or_node_ids 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 与给定弧段相连通的环路的弧段 ID 数组。
返回类型: list[int]
-
find_path(start_id, end_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 设施网络路径分析,即根据给定的起始和终止结点 ID,查找其间耗费最小的路径,返回该路径包含的弧段、结点及耗费。
两结点间的最小耗费路径的查找过程为:从给定的起始结点出发,根据流向,查找到给定的终止结点的所有路径,然后从其中找出耗费最小的一条返回。
下图是两结点最小耗费路径的示意图。从起始结点 B 出发,沿着网络流向,有三条路径能够到达终止结点 P,分别为 B-D-L-P、B-C-G-I-J-K-P 和 E-E-F-H-M-N-O-P,其中路径 B-C-G-I-J-K-P 的耗费最小,为 105,因此该路径是结点 B 到 P 的最小耗费路径。
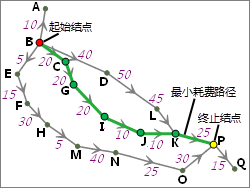
参数: - start_id (int) -- 起始结点 ID 或弧段 ID。
- end_id (int) -- 终止结点 ID 或弧段 ID。起始ID 和终止 ID 必须同时为结点 ID 或弧段 ID
- weight_name (str) -- 指定的权值字段信息对象的名称。
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
find_path_down(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 设施网络下游路径分析,根据给定的参与分析的结点 ID或弧段 ID,查询该结点(弧段)下游耗费最小的路径,返回该路径包含的弧段、结点及耗费。
下游最小耗费路径的查找过程可以理解为:从给定结点(或弧段)出发,根据流向,查找出该结点(或弧段)的所有下游路径,然后从其中找出 耗费最小的一条返回。 该方法用于查找给定结点的下游最小耗费路径。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 H 进行下游最小耗费路径分析。 首先从结点 H 出发,根据流向向下查找,找出结点 H 的所有下游路径,共有 4 条,包括:H-L-G、H-L-K、H-M-S 和 H-M-Q-R,然后根据 网络阻力(即权值)计算这些路径的耗费,可以得出 H-L-K 这条路径的耗费最小,为 11.1,因此,结点 H 的下最小耗费路径就是 H-L-K。
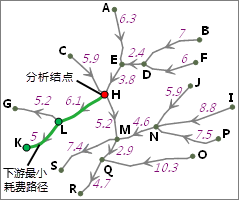
参数: - edge_or_node_id (int) -- 指定的结点 ID 或 弧段 ID
- weight_name (str) -- 指定的权值字段信息对象的名称。即设置网络分析环境中指定的
FacilityAnalystSetting.weight_fields中 具体某一个WeightFieldInfo的WeightFieldInfo.weight_name. - is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
find_path_up(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 设施网络上游路径分析,根据给定的结点 ID或弧段 ID,查询该结点(弧段)上游耗费最小的路径,返回该路径包含的弧段、结点及耗费。
上游最小耗费路径的查找过程可以理解为:从给定结点(或弧段)出发,根据流向,查找出该结点(或弧段)的所有上游路径,然后从其中找 出耗费最小的一条返回。 该方法用于查找给定结点的上游最小耗费路径。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 I 进行上游最小耗费路径分析。 首先从结点 I 出发,根据流向向上回溯,找出结点 I 的所有上游路径,共有 6 条,包括:E-F-I、A-F-I、B-G-J-I、D-G-J-I、C-G-J-I 和 H-J-I,然后根据网络阻力(即权值)计算这些路径的耗费,可以得出 E-F-I 这条路径的耗费最小,为 8.2,因此,结点 I 的上游最小 耗费路径就是 E-F-I。
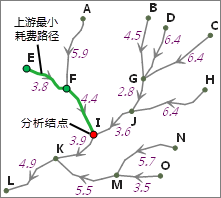
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_sink(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID或弧段 ID 查找汇,即从给定结点(弧段)出发,根据流向查找流出该结点的下游汇点,并返回给定结点到达该汇的最小耗费路径所包含的弧段、结点及耗费。 该方法从给定结点出发,按照流向,查找流出该结点的下游汇点,分析的结果为该结点到达查找到的汇的最小耗费路径所包含的弧段、结点及耗费。 如果网络中有多个汇,将查找最远的也就是从给定结点出发最小耗费最大的那个汇。为了便于理解,可将该功能的实现过程分为三步:
- 从给定结点出发,根据流向,找到该结点下游所有的汇点;
- 分析给定结点到每个汇的最小耗费路径并计算耗费;
- 选择上一步中计算出的耗费中的最大值所对应的路径作为结果,给出该路径上的弧段 ID 数组、结点 ID 数组以及该路径的耗费。
注意:分析结果中的结点 ID 数组不包括分析结点本身。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 D 进行查找汇分析。可以知道, 从 结点 D 出发,根据流向向下查找,共有 4 个汇,从结点 D 到达汇的最小耗费路径分别为:E-H-L-G、E-H-L-K、E-H-M-S 和 E-H-M-Q-R, 根据网络阻力,也就是弧段权值,可以计算得出 E-H-M-Q-R 这条路径的耗费最大,为 16.6,因此,结点 R 就是查找到的汇。
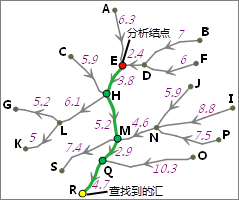
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_source(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID 或弧段 ID 查找源,即从给定结点(弧段)出发,根据流向查找流向该结点的网络源头,并返回该源到达给定结点的最小耗费路径所包含的弧段、结点及耗费。 该方法从给定结点出发,按照流向,查找流向该结点的网络源头结点(即源点),分析的结果为查找到的源到达给定结点的最小耗费路径所包 含的弧段、结点及耗费。 如果网络中有多个源,将查找最远的也就是到达给定结点的最小耗费最大的那个源。为了便于理解,可将该功能的实现过程分为三步:
- 从给定结点出发,根据流向,找到该结点上游所有的源点;
- 分析每个源到达给定结点的最小耗费路径并计算耗费;
- 选择上一步中计算出的耗费中的最大值所对应的路径作为结果,给出该路径上的弧段 ID 数组、结点 ID 数组以及该路径的耗费。
注意:分析结果中的结点 ID 数组不包括分析结点本身。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 M 进行查找源分析。可以知道, 从 结点 M 出发,根据流向向上回溯,共有 7 个源,从源到结点 M 的最小耗费路径分别为:C-H-M、A-E-H-M、B-D-E-H-M、F-D-E-H-M、 J-N-M、I-N-M 和 P-N-M,根据网络阻力,也就是弧段权值,可以计算得出 B-D-E-H-M 这条路径的耗费最大,为 18.4,因此,结点 B 就是查找到的源。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_unconnected_edges(edge_or_node_ids, is_edge_ids=True)¶ 根据给定的结点 ID 数组,查找与这些结点不相连通的弧段,返回弧段 ID 数组。 该方法用于查找与给定结点不连通的弧段,查找出连通弧段后,可根据网络拓扑关系,即弧段的起始结点、终止结点查询出相应的不连通结点。
参数: - edge_or_node_ids (list[int] or tuple[int]) -- 结点 ID 数组或弧段 ID 数组
- is_edge_ids (bool) -- edge_or_node_ids 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 弧段 ID 数组
返回类型: list[int]
-
is_load()¶ 判断网络数据集模型是否加载。
返回: 网络数据集模型加载返回 True,否则返回 False 返回类型: bool
-
load()¶ 根据设施网络分析环境设置加载设施网络模型。
- 注意,出现以下两种情况都必须重新调用 load 方法来加载网络模型,然后再进行分析。
- 对设施网络分析环境设置对象的参数进行了修改,需要重新调用该方法,否则所作修改不会生效从而导致分析结果错误;
- 对所使用的网络数据集进行了任何修改,包括修改网络数据集中的数据、替换数据集等,都需要重新加载网络模型,否则分析可能出错。
返回: 用于指示加载设施网络模型是否成功。如果成功返回 true,否则返回 false。 返回类型: bool
-
set_analyst_setting(value)¶ 设置设施网络分析的环境。
设施网络分析环境参数的设置,直接影响到设施网络分析的结果。设施网络分析所需要的参数包括:用于进行设施网络分析的数据集( 即 建立了流向的网络数据集或者同时建立了流向和等级的网络数据集,也就是说该方法对应的
FacilityAnalystSetting所指 定的网络数据集必须有流向或者流向和等级信息)、结点 ID 字段、弧段 ID 字段、弧段起始结点 ID 字段、弧段终止结点 ID 字段、权 值信息、点到弧段的距离容限、障碍结点、障碍弧段、流向等。参数: value (FacilityAnalystSetting) -- 设施网络分析环境参数 返回: self 返回类型: FacilityAnalyst
-
trace_down(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的弧段 ID 或结点 ID 进行下游追踪,即查找给定弧段(结点)的下游,返回下游包含的弧段、结点及总耗费。 下游追踪,是从给定结点(或弧段)出发,根据流向,查找其下游的过程。该方法用于查找给定弧段的下游,分析结果为其下游所包含的弧段、结点, 及流经整个下游的耗费。
下游追踪常用于影响范围的分析。例如:
- 自来水供水管道爆管后,通过下游追踪分析事故位置的所有下游管道,然后通过空间查询,确定受影响的供水区域,从而及时发放通知,并采 取应急措施, 如由消防车或自来水公司安排车辆为停水小区送水。
- 当发现河流的某个位置发生污染时,可以通过下游追踪,分析出可能受到影响的所有下游河段,如下图所示。在分析前,还可以根据污染物的 种类、 排放量等结合恰当的水质管理模型,分析出在污染清除前不会遭到污染的下游河段或位置,设置为障碍(在 FacilityAnalystSetting 中设置), 下游追踪时,到达障碍即追踪停止 ,这样可以缩小分析的范围。确定了可能受影响的河段后,通过空间查询和分析标记出位于结果河段附近的所 有用水单位和居民区 ,及时下发通知,并采取紧急措施,防止污染的危害进一步扩大。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
trace_up(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID 或弧段 ID 进行上游追踪,即查找给定结点的上游,返回上游包含的弧段、结点及总耗费。
上游和下游
对于设施网络的某个结点(或弧段)来说,网络中的资源最终流入该结点(或弧段)所经过的弧段和结点称为它的上游;从该结点(或弧段) 流出最终流入汇点所经过的弧段和网络称为它的下游。
下面以结点的上游和下游为例。下图是一个简单的设施网络的示意图,使用箭头标出了网络的流向。根据流向,可以看出,资源流经结点 2、4、3、7、8 以及弧段 10、9、3、4、8 最终流入结点 10,因此这些结点和弧段称为结点 10 的上游,其中的结点称为它的上游结点, 弧段称为它的上游弧段。同样的,资源从结点 10 流出,流经结点9、11、12 以及弧段 5、7、11 最终流出网络,因此,这些结点和弧段称 为结点 10 的下游,其中的结点称为它的下游结点,弧段称为它的下游弧段。
上游追踪与下游追踪
上游追踪,是从给定结点(或弧段)出发,根据流向,查找其上游的过程。类似的,下游追踪是从给定结点(或弧段)出发,根据流向, 查找其下游的过程。 FacilityAnalyst 类分别提供了从结点或弧段出发,进行上游或下游追踪的方法,分析的结果为查找到的上游或下 游所包含的弧段 ID 数组、结点 ID 数组,以及流经整个上游或者下游的耗费。本方法用于查找给定弧段的上游。
应用实例
上游追踪的一个常用应用是辅助定位河流水污染物来源。河流不仅是地球水循环的重要路径,也是人类最主要的淡水资源, 一旦河流发生 污染而没有及时发现污染源并消除 ,很可能影响人们的正常饮水和健康。由于河流受重力影响从高处向低处流动,因此当河流发生污染时, 应考虑其上游可能出现了污染源 ,如工业废水排放、生活污水排放、农药化肥污染等。河流水污染物来源追踪的大致步骤一般为:
- 当水质监测站的监测数据显示水质发生异常,首先确定发生异常的位置,从而在河流网络(网络数据集)上找出该位置所在(或最近)的弧段或结点, 作为上游追踪的起点;
- 如果知道在起点的上游中距离起点最近的水质监测正常的位置,可以将这些位置或其所在的河段设置为障碍,可以帮助进一步缩小分析的范围。因为可以认为, 水质监测正常的位置的上游,不可能存在此次调查的污染源。设置为障碍后,进行上游追踪分析,追踪到该位置后,将不会继续追踪该位置的上游;
- 进行上游追踪分析,查找到向发生水质异常位置所在河段汇流的所有河段;
- 使用空间查询、分析找出位于这些河段附近的所有可能的污染源,如化工厂、垃圾处理厂等;
- 根据发生水质异常的监测数据对污染源进行进一步筛选;
- 分析筛选出的污染源的排污负荷,按照其造成污染的可能性进行排序;
- 对可能的污染源按照顺序进行实地调查与研究,最终确定污染物来源。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
-
class
iobjectspy.analyst.TerminalPoint(point, load)¶ 基类:
object终端点,用于分组分析,终端点包含坐标信息和负载量
初始化对象
参数: - point (Point2D) -- 坐标点信息
- load (int) -- 负载量
-
load¶ int -- 负载量
-
point¶ Point2D -- 坐标点
-
set_load(load)¶ 设置负载量
参数: load (int) -- 负载量 返回: self 返回类型: TerminalPoint
-
set_point(point)¶ 设置坐标点
参数: point (Point2D) -- 坐标点 返回: self 返回类型: TerminalPoint
-
class
iobjectspy.analyst.FacilityAnalystResult(java_object)¶ 基类:
object设施网络分析结果类。该类用于获取查找源和汇、上下游追踪以及查找路径等设施网络分析的结果,包括结果弧段 ID 数组、结果结点 ID 数组以及耗费。
-
cost¶ float -- 设施网络分析结果中的耗费。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径的耗费。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径耗费。
- 上游追踪: 该值为分析弧段或结点的上游所包含的弧段的总耗费。
- 下游追踪: 该值为分析弧段或结点的下游所包含的弧段的总耗费。
- 路径分析: 该值为查找到的最小耗费路径的耗费。
- 上游路径分析: 该值为查找到的上游最小耗费路径的耗费。
- 下游路径分析: 该值为查找到的下游最小耗费路径的耗费。
-
edges¶ list[int] -- 设施网络分析结果中的弧段 ID 数组。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径所包含的弧段的弧段 ID 数组。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径所包含的弧段的弧段 ID 数组。
- 上游追踪: 该值为分析弧段或结点的上游所包含的弧段的弧段 ID 数组。
- 下游追踪: 该值为分析弧段或结点的下游所包含的弧段的弧段 ID 数组。
- 路径分析: 该值为查找到的最小耗费路径所经过的弧段的弧段 ID 数组。
- 上游路径分析: 该值为查找到的上游最小耗费路径所经过的弧段的弧段 ID 数组。
- 下游路径分析: 该值为查找到的下游最小耗费路径所经过的弧段的弧段 ID 数组。
-
nodes¶ list[int] -- 设施网络分析结果中的结点 ID 数组。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径所包含的结点的结点 ID 数组。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径所包含的结点的结点 ID 数组。
- 上游追踪: 该值为分析弧段或结点的上游所包含的结点的结点 ID 数组。
- 下游追踪: 该值为分析弧段或结点的下游所包含的结点的结点 ID 数组。
- 路径分析: 该值为查找到的最小耗费路径所经过的结点的结点 ID 数组。
- 上游路径分析: 该值为查找到的上游最小耗费路径所经过的结点的结点 ID 数组。
- 下游路径分析: 该值为查找到的下游最小耗费路径所经过的结点的结点 ID 数组。
-
-
class
iobjectspy.analyst.FacilityAnalystSetting¶ 基类:
object设施网络分析环境设置类。 设施网络分析环境设置类。该类用于提供设施网络分析时所需要的所有参数信息。设施网络分析环境设置类的各个参数的设置直接影响分析的结果。
-
barrier_edge_ids¶ list[int] -- 障碍弧段的 ID 列表
-
barrier_node_ids¶ list[int] -- 障碍结点的 ID 列表
-
direction_field¶ str -- 流向字段
-
edge_id_field¶ str -- 网络数据集中标志弧段 ID 的字段
-
f_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
network_dataset¶ DatasetVector -- 网络数据集
-
node_id_field¶ str -- 网络数据集中标识结点 ID 的字段
-
set_barrier_edge_ids(value)¶ 设置障碍弧段的 ID 列表
参数: value (str or list[int]) -- 障碍弧段的 ID 列表 返回: self 返回类型: FacilityAnalystSetting
-
set_barrier_node_ids(value)¶ 设置障碍结点的 ID 列表
参数: value (str or list[int]) -- 障碍结点的 ID 列表 返回: self 返回类型: FacilityAnalystSetting
-
set_direction_field(value)¶ 设置流向字段
参数: value (str) -- 流向字段 返回: self 返回类型: FacilityAnalystSetting
-
set_edge_id_field(value)¶ 设置网络数据集中标识结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段 ID 的字段 返回: self 返回类型: FacilityAnalystSetting
-
set_f_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段起始结点 ID 的字段 返回: self 返回类型: FacilityAnalystSetting
-
set_network_dataset(dt)¶ 设置网络数据集
参数: dt (DatasetVetor or str) -- 网络数据集 返回: self 返回类型: FacilityAnalystSetting
-
set_node_id_field(value)¶ 设置网络数据集标识结点ID的字段
参数: value (str) -- 网络数据集中标识结点 ID 的字段 返回: self 返回类型: FacilityAnalystSetting
-
set_t_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 返回: self 返回类型: FacilityAnalystSetting
-
set_tolerance(value)¶ 设置节点容限
参数: value (float) -- 节点容限 返回: self 返回类型: FacilityAnalystSetting
-
set_weight_fields(value)¶ 设置权重字段
参数: value (list[WeightFieldInfo] or tuple[WeightFieldInfo]) -- 权重字段 返回: self 返回类型: FacilityAnalystSetting
-
t_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
tolerance¶ float -- 节点容限
-
weight_fields¶ list[WeightFieldInfo] -- 权重字段
-
-
class
iobjectspy.analyst.SideType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum表示在路的左边、右边还是在路上。用于行驶导引。
变量: - SideType.NONE -- 无效值
- SideType.MIDDLE -- 在路上(即路的中间)
- SideType.LEFT -- 路的左侧
- SideType.RIGHT -- 路的右侧
-
LEFT= 1¶
-
MIDDLE= 0¶
-
NONE= -1¶
-
RIGHT= 2¶
-
class
iobjectspy.analyst.TurnType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum转弯方向,用于行驶导引
变量: - TurnType.NONE -- 无效值
- TurnType.END -- 终点,不转弯
- TurnType.LEFT -- 左转弯
- TurnType.RIGHT -- 右转弯
- TurnType.AHEAD -- 表示向前直行
- TurnType.BACK -- 掉头
-
AHEAD= 3¶
-
BACK= 4¶
-
END= 0¶
-
LEFT= 1¶
-
NONE= 255¶
-
RIGHT= 2¶
-
class
iobjectspy.analyst.ServiceAreaType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum服务区类型。用于服务区分析。
变量: - ServiceAreaType.SIMPLEAREA -- 简单服务区
- ServiceAreaType.COMPLEXAREA -- 复杂服务区
-
COMPLEXAREA= 1¶
-
SIMPLEAREA= 0¶
-
class
iobjectspy.analyst.VehicleInfo¶ 基类:
object车辆信息类。存储了车辆的最大耗费值、最大负载量等信息。
-
area_ratio¶ float -- 物流分析的区域系数
-
cost¶ float -- 车辆的最大耗费值
-
end_time¶ datetime.datetime -- 车辆最晚返回时间
-
load_weights¶ list[float] -- 车辆的负载量
-
se_node¶ int -- 物流分析单向路线中的起止结点ID
-
se_point¶ Point2D -- 物流分析单向路线中的起止点坐标
-
set_area_ratio(value)¶ 设置物流分析的区域系数。仅当
VRPAnalystType为VRPAnalystType.AREAANALYST时有效。参数: value (float) -- 物流分析的区域系数 返回: self 返回类型: VehicleInfo
-
set_cost(value)¶ 设置车辆的最大耗费值
参数: value (float) -- 车辆的最大耗费值。 返回: self 返回类型: VehicleInfo
-
set_end_time(value)¶ 设置车辆最晚返回时间
参数: value (datetime.datetime or int or str) -- 车辆最晚返回时间 返回: self 返回类型: VehicleInfo
-
set_load_weights(value)¶ 设置车辆的负载量。负载量可以为多维,例如可以同时设置最大承载重量和最大承载体积。要求分析中每一条线路的运输车辆负载量都不超过此值。
参数: value (list[float]) -- 车辆的负载量 返回: self 返回类型: VehicleInfo
-
set_se_node(value)¶ 设置物流分析单向路线中的起止结点ID。
设置该方法时,路线类型
VRPDirectionType必须为VRPDirectionType.STARTBYCENTER或 者VRPDirectionType.ENDBYCENTER该参数方起作用。当路线类型为
VRPDirectionType.STARTBYCENTER时,该参数表示车辆最终的停靠位置。当路线类型为
VRPDirectionType.ENDBYCENTER时,该参数表示车辆最初的起始位置。参数: value (int) -- 物流分析单向路线中的起止结点ID 返回: self 返回类型: VehicleInfo
-
set_se_point(value)¶ 设置物流分析单向路线中的起止点坐标。
设置该方法时,路线类型
VRPDirectionType必须为VRPDirectionType.STARTBYCENTER或 者VRPDirectionType.ENDBYCENTER该参数方起作用。当路线类型为
VRPDirectionType.STARTBYCENTER时,该参数表示车辆最终的停靠位置。当路线类型为
VRPDirectionType.ENDBYCENTER时,该参数表示车辆最初的起始位置。参数: value (Point2D) -- 物流分析单向路线中的起止点坐标 返回: self 返回类型: VehicleInfo
-
set_start_time(value)¶ 设置车辆最早发车时间
参数: value (datetime.datetime or int or str) -- 车辆最早发车时间 返回: self 返回类型: VehicleInfo
-
start_time¶ datetime.datetime -- 车辆最早发车时间
-
-
class
iobjectspy.analyst.NetworkDatasetErrors(java_errors)¶ 基类:
object网络数据集拓扑关系检查结果,包括网络数据集弧段错误信息、结点错误信息。
-
arc_errors¶ dict[int,int] -- 弧段错误信息。键为网络数据集中错误弧段的 SmID,值为错误类型。
-
node_errors¶ dict[int,int] -- 结点错误信息。键为网络数据集中错误结点的 SmID,值为错误类型。
-
-
class
iobjectspy.analyst.GroupAnalystResult(java_object)¶ 基类:
object分组分析结果类。该类用于返回分组分析的结果,包括未分配到的分配点集合和分析结果项集合。
-
error_terminal_point_indexes¶ list[int] -- 未分配到的分配点集合
-
groups¶ list[GroupAnalystResultItem] -- 分析结果项集合
-
-
class
iobjectspy.analyst.GroupAnalystResultItem(java_object)¶ 基类:
object分组分析结果项类。组分析结果项记录了每一个分组中中心点索引,该组包含的分配点索引集合,该分组中的总耗费,各个分配点到中心点的线 路集合以及该分组的总负载量。
-
center¶ int -- 分组结果的中心点索引
-
cost¶ float -- 分组结果的总耗费
-
lines¶ list[GeoLineM] -- 分组结果的各个分配点到中心点的线路集合
-
load_sum¶ float -- 分组结果的总负载量
-
members¶ list[int] -- 分组结果的分配点索引集合
-
-
class
iobjectspy.analyst.SupplyCenterType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum网络分析中资源中心点类型常量,主要用于资源分配和选址分区
变量: - SupplyCenterType.NULL -- 非中心点,在资源分配和选址分区时都不予考虑。
- SupplyCenterType.OPTIONALCENTER -- 可选中心点,用于选址分区
- SupplyCenterType.FIXEDCENTER -- 固定中心点,用于资源分配和选址分区。
-
FIXEDCENTER= 2¶
-
NULL= 0¶
-
OPTIONALCENTER= 1¶
-
class
iobjectspy.analyst.SupplyCenter(supply_center_type, center_node_id, max_weight, resource=0)¶ 基类:
object资源供给中心类。资源供给中心类,存储了资源供给中心的信息,包括资源供给中心的 ID、最大耗费和类型。
初始化对象
参数: - supply_center_type (SupplyCenterType or str) -- 资源供给中心点的类型包括非中心,固定中心和可选中心。固定中心用于资源分配分析;固定中心和可选中心用于选址分析, 非中心在两种网络分析时都不予考虑。
- center_node_id (int) -- 资源供给中心点的 ID。
- max_weight (float) -- 资源供给中心的最大耗费(阻值)
- resource (float) -- 资源供给中心的资源量
-
center_node_id¶ int -- 资源供给中心点的 ID
-
max_weight¶ float -- 资源供给中心的最大耗费。
-
resource¶ float -- 资源供给中心的资源量
-
set_center_node_id(value)¶ 设置资源供给中心点的 ID。
参数: value (int) -- 资源供给中心点的 ID 返回: self 返回类型: SupplyCenter
-
set_max_weight(value)¶ 设置 资源供给中心的最大耗费。中心点最大阻值设置越大,表示中心点所提供的资源可影响范围越大。 最大阻力值是用来限制需求点到中心点的花费。如果需求点(弧段或结点)到此中心的花费大于最大阻力值,则该需求点被过滤掉。最大阻力值可编辑。
参数: value (float) -- 资源供给中心的最大耗费(阻值) 返回: self 返回类型: SupplyCenter
-
set_resource(value)¶ 设置资源供给中心的资源量
参数: value (float) -- 资源供给中心的资源量 返回: self 返回类型: SupplyCenter
-
set_supply_center_type(value)¶ 设置网络分析中资源供给中心点的类型
参数: value (SupplyCenterType or str) -- 资源供给中心点的类型包括非中心,固定中心和可选中心。固定中心用于资源分配分析;固定中心和可选中心用于选址分析, 非中心在两种网络分析时都不予考虑。 返回: self 返回类型: SupplyCenter
-
supply_center_type¶ SupplyCenterType -- 络分析中资源供给中心点的类型
-
class
iobjectspy.analyst.SupplyResult(java_object)¶ 基类:
object资源供给中心点结果类。
该类提供了资源供给的结果,包括资源供给中心的类型、ID、最大阻值、需求点的数量、平均耗费和总耗费等。
-
average_weight¶ float -- 平均耗费,即总耗费除以需求点数
-
center_node_id¶ int -- 资源供给中心的 ID
-
demand_count¶ int -- 该资源供给中心所服务的需求结点的数量
-
max_weight¶ float -- 资源供给中心的最大耗费(阻值)。最大阻力值是用来限制需求点到中心点的花费。如果需求点(结点)到此中心的花费大于最 大阻力值,则该需求点被过滤掉。最大阻力值可编辑。
-
total_weight¶ float -- 总耗费量。当选址分区分析选择从资源供给中心分配资源时,总耗费为从该资源供给中心到其所服务的所有需求结点的耗费的总 和;反之,不从资源供给中心分配,则总耗费为该资源供给中心所服务的所有需求结点到该资源供给中心的耗费的总和。
-
type¶ SupplyCenterType -- 该资源供给中心的类型
-
-
class
iobjectspy.analyst.DemandResult(java_object)¶ 基类:
object需求结果类。该类用于返回需求结果的相关信息,包括需求结点 ID和资源供给中心 ID等。
-
actual_resource¶ float -- 实际被分配的资源量,仅对资源分配有效。
-
is_edge¶ bool -- 返回需求结果是否是弧段。如果不是弧段,则需求结果是结点。仅对资源分配有效,否则为 False。
-
supply_center_node_id¶ int -- 资源供给中心 ID
-
-
class
iobjectspy.analyst.LocationAnalystResult(java_object)¶ 基类:
object选址分区分析结果类。
-
demand_results¶ list[DemandResult] -- 需求结果对象数组
-
supply_results¶ list[SupplyResult] -- 资源供给结果对象数组
-
-
class
iobjectspy.analyst.RouteType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum最佳路径分析的分析模式,用于基于 SSC 的最佳路径分析。
变量: - RouteType.RECOMMEND -- 推荐模式
- RouteType.MINLENGTH -- 距离最短
- RouteType.NOHIGHWAY -- 不走高速
-
MINLENGTH= 2¶
-
NOHIGHWAY= 3¶
-
RECOMMEND= 0¶
-
class
iobjectspy.analyst.NetworkSplitMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum构建网络数据集打断模式。用来控制建立网络数据集时,处理线线打断或点线打断的模式
变量: - NetworkSplitMode.NO_SPLIT -- 不打断
- NetworkSplitMode.LINE_SPLIT_BY_POINT -- 点打断线
- NetworkSplitMode.LINE_SPLIT_BY_POINT_AND_LINE -- 线与线打断,同时点打断线
- NetworkSplitMode.TOPOLOGY_PROCESSING -- 拓扑处理方式。使用该方式时,首先会对用于构建的线数据集进行去除重复线、长悬线延伸、 弧段求交、去除短悬线、去除冗余点、邻近端点合并和去除假结点等拓扑处理操作,然后再构建网络数据集。
-
LINE_SPLIT_BY_POINT= 1¶
-
LINE_SPLIT_BY_POINT_AND_LINE= 2¶
-
NO_SPLIT= 0¶
-
TOPOLOGY_PROCESSING= 3¶
-
class
iobjectspy.analyst.NetworkSplitMode3D¶ 基类:
iobjectspy._jsuperpy.enums.JEnum构建三维网络数据集打断模式。用来控制建立网络数据集时,处理线线打断或点线打断的模式
变量: - NetworkSplitMode.NO_SPLIT -- 不打断
- NetworkSplitMode.LINE_SPLIT_BY_POINT -- 点打断线
- NetworkSplitMode.LINE_SPLIT_BY_POINT_AND_LINE -- 线与线打断,同时点打断线
-
LINE_SPLIT_BY_POINT= 1¶
-
LINE_SPLIT_BY_POINT_AND_LINE= 2¶
-
NO_SPLIT= 0¶
-
iobjectspy.analyst.build_network_dataset_known_relation_3d(line, point, edge_id_field, from_node_id_field, to_node_id_field, node_id_field, out_data=None, out_dataset_name=None, progress=None)¶ 根据点、线数据及其已有的表达弧段结点拓扑关系的字段,构建网络数据集。 当已有的线、点数据集中的线、点对象分别对应着待构建网络的弧段和结点,并具有描述二者空间拓扑关系的信息,即线数据集含有弧段 ID、弧段 起始结点 ID 和终止结点 ID 字段,点数据集含有点对象的结点 ID 字段时,可以采用本方法构建网络数据集。
使用此方式构建网络数据集成功后,结果对象数与源数据的对象数一致,即线数据中一个线对象作为一个弧段写入,点数据中一个点对象作为一个 结点写入,并且保留点、线数据集的所有非系统字段到结果数据集中。
例如,对于用于建立管网而采集的管线、管点数据,管线和管点均使用唯一固定编码来标识。管网的特点之一是管点只位于管线的两端,因此管点 对应了待构建管网的所有结点,管线对应了待构建管网的所有弧段,不需要在管线与管线相交处打断。在管线数据中,记录了管线对象两端的管点 信息,即起始管点编码和终止管点编码,也就是说管线和管点数据中已经蕴含了二者空间拓扑关系的信息,因此适合使用此方法构建网络数据集。
注意,使用此方式构建的网络数据集的弧段 ID、弧段起始结点 ID、弧段终止结点 ID 和结点 ID 字段即为调用此方法时指定的字段,而不再 是 SmEdgeID、SmFNode、SmTNode、SmNodeID 等系统字段。具体可以通过 DatasetVector 的
DatasetVector.get_field_name_by_sign()方法获取到相应的字段。参数: - line (str or DatasetVector) -- 用于构建网络数据集的三维线数据集
- point (str or DatasetVector) -- 用于构建网络数据集的三维点数据集
- edge_id_field (str) -- 指定的线数据集中表示弧段 ID 的字段。如果指定为 null 或空字符串,或指定的字段不存在,则自动使用 SMID 作为弧段 ID。 仅支持 16 位整型、32 位整型字段。
- from_node_id_field (str) -- 指定的线数据集中表示弧段的起始结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- to_node_id_field (str) -- 指定的线数据集中表示弧段的终止结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- node_id_field (str) -- 指定的点数据集中表示结点 ID 的字段。仅支持 16 位整型、32 位整型字段。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 保留结果网络数据集的数据源对象
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果网络数据集
返回类型:
-
iobjectspy.analyst.build_facility_network_directions_3d(network_dataset, source_ids, sink_ids, direction_field='Direction', node_type_field='NodeType', progress=None)¶ 根据指定网络数据集中源与汇的位置,为网络数据集创建流向。创建流向以后的网络数据集才可以进行各种设施网络分析。 设施网络是具有方向的网络,因此,在创建网络数据集之后,必须为其创建流向,才能够用于进行各种设施网络路径分析、连通性分析、上下游追踪等。
流向是指网络中资源流动的方向。网络中的流向由源和汇决定:资源总是从源点流出,流向汇点。该方法通过给定的源和汇,以及设施网络分析参数 设置为网络数据集创建流向。创建流向成功后,会在网络数据集中写入两方面的信息:流向和结点类型。
流向
流向信息将写入网络数据集的子线数据集的流向字段中,如果不存在则会创建该字段。
流向字段的值共有四个:0,1,2,3,其含义如下图所示。以线段 AB 为例:
0 代表流向与数字化方向相同。线段 AB 的数字化方向为 A-->B,且 A 为源点,因此 AB 的流向为从 A 流到 B,即与其数字化方向相同。
1 代表流向与数字化方向相反。线段 AB 的数字化方向为 A-->B,且 A 为汇点,因此 AB 的流向为从 B 流向 A,即与其数字化方向相反。
2 代表无效方向,也称不确定流向。A 和 B 均为源点,则资源既可以从 A 流向 B,又可以从 B 流向 A,这就构成了一个无效的流向。
3 代表不连通边,也称未初始化方向。线段 AB 与源点、汇点所在的结点不连通,则称为不连通边。
结点类型
建立流向后,系统还会将结点类型信息写入指定的网络数据集的子点数据集的结点类型字段中。结点类型分为源点、汇点和普通结点。 下表列出了结点类型字段的值及其含义:
参数: - network_dataset (DatasetVector or str) -- 待创建流向的三维网络数据集,三维网络数据集必须可修改。
- source_ids (list[int] or tuple[int]) -- 源对应的网络结点 ID 数组。源与汇都是用来建立网络数据集的流向的。网络数据集的流向与源和汇的位置决定。
- sink_ids (list[int] or tuple[int]) -- 汇 ID 数组。汇对应的网络结点 ID 数组。源与汇都是用来建立网络数据集的流向的。网络数据集的流向与源和汇的位置决定。
- direction_field (str) -- 流向字段,用于保存网络数据集的流向信息
- node_type_field (str) -- 结点类型字段名称,结点类型分为源结点、交汇结点、普通结点。该字段是网络结点数据集中的字段,如果不存在则创建该字段。
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 创建成功返回 true,否则 false
返回类型: bool
-
iobjectspy.analyst.build_network_dataset_3d(line, point=None, split_mode='NO_SPLIT', tolerance=0.0, line_saved_fields=None, point_saved_fields=None, out_data=None, out_dataset_name=None, progress=None)¶ 网络数据集是进行网络分析的数据基础。三维网络数据集由两个子数据集(一个三维线数据集和一个三维点数据集)构成,分别存储了网络模型的弧段和结点, 并且描述了弧段与弧段、弧段与结点、结点与结点间的空间拓扑关系。
此方法提供根据单个线数据集或单个线和单个点构建网络数据集。如果用户的数据集已经有正确的网络关系,可以直接通 过
build_network_dataset_known_relation_3d()快速的构建一个网络数据集。构建的网络数据集,可以通过
validate_network_dataset_3d()检查网络拓扑关系是否正确。参数: - line (DatasetVector) -- 用于构建网络数据集的线数据集
- point (DatasetVector) -- 用于构建网络数据集的点数据集。
- split_mode (NetworkSplitMode3D) -- 打断模式,默认为不打断
- tolerance (float) -- 节点容限
- line_saved_fields (str or list[str]) -- 线数据集中需要保留的字段
- point_saved_fields (str or list[str]) -- 点数据集中需要保留的字段。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 保留结果网络数据集的数据源对象
- out_dataset_name (str) -- 结果数据集名称
- progress (function) -- 进度信息处理函数,具体参考
StepEvent
返回: 结果三维网络数据集
返回类型:
-
class
iobjectspy.analyst.FacilityAnalystResult3D(java_object)¶ 基类:
object设施网络分析结果类。该类用于获取查找源和汇、上下游追踪以及查找路径等设施网络分析的结果,包括结果弧段 ID 数组、结果结点 ID 数组以及耗费。
-
cost¶ float -- 设施网络分析结果中的耗费。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径的耗费。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径耗费。
- 上游追踪: 该值为分析弧段或结点的上游所包含的弧段的总耗费。
- 下游追踪: 该值为分析弧段或结点的下游所包含的弧段的总耗费。
-
edges¶ list[int] -- 设施网络分析结果中的弧段 ID 数组。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径所包含的弧段的弧段 ID 数组。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径所包含的弧段的弧段 ID 数组。
- 上游追踪: 该值为分析弧段或结点的上游所包含的弧段的弧段 ID 数组。
- 下游追踪: 该值为分析弧段或结点的下游所包含的弧段的弧段 ID 数组。
-
nodes¶ list[int] -- 设施网络分析结果中的结点 ID 数组。 对于不同的设施网络分析功能,该方法的返回值含义有所不同:
- 查找源: 该值为分析弧段或结点到达源的最小耗费路径所包含的结点的结点 ID 数组。
- 查找汇: 该值为分析弧段或结点到达汇的最小耗费路径所包含的结点的结点 ID 数组。
- 上游追踪: 该值为分析弧段或结点的上游所包含的结点的结点 ID 数组。
- 下游追踪: 该值为分析弧段或结点的下游所包含的结点的结点 ID 数组。
-
-
class
iobjectspy.analyst.FacilityAnalystSetting3D¶ 基类:
object设施网络分析环境设置类。 设施网络分析环境设置类。该类用于提供设施网络分析时所需要的所有参数信息。 设施网络分析环境设置类的各个参数的设置直接影响分析的结果。
-
barrier_edge_ids¶ list[int] -- 障碍弧段的 ID 列表
-
barrier_node_ids¶ list[int] -- 障碍结点的 ID 列表
-
direction_field¶ str -- 流向字段
-
edge_id_field¶ str -- 网络数据集中标志弧段 ID 的字段
-
f_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
network_dataset¶ DatasetVector -- 网络数据集
-
node_id_field¶ str -- 网络数据集中标识结点 ID 的字段
-
set_barrier_edge_ids(value)¶ 设置障碍弧段的 ID 列表
参数: value (str or list[int]) -- 障碍弧段的 ID 列表 返回: self 返回类型: FacilityAnalystSetting3D
-
set_barrier_node_ids(value)¶ 设置障碍结点的 ID 列表
参数: value (str or list[int]) -- 障碍结点的 ID 列表 返回: self 返回类型: FacilityAnalystSetting3D
-
set_direction_field(value)¶ 设置流向字段
参数: value (str) -- 流向字段 返回: self 返回类型: FacilityAnalystSetting3D
-
set_edge_id_field(value)¶ 设置网络数据集中标识结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段 ID 的字段 返回: self 返回类型: FacilityAnalystSetting3D
-
set_f_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段起始结点 ID 的字段 返回: self 返回类型: FacilityAnalystSetting3D
-
set_network_dataset(dt)¶ 设置网络数据集
参数: dt (DatasetVetor or str) -- 网络数据集 返回: self 返回类型: FacilityAnalystSetting3D
-
set_node_id_field(value)¶ 设置网络数据集标识结点ID的字段
参数: value (str) -- 网络数据集中标识结点 ID 的字段 返回: self 返回类型: FacilityAnalystSetting3D
-
set_t_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 返回: self 返回类型: FacilityAnalystSetting3D
-
set_tolerance(value)¶ 设置节点容限
参数: value (float) -- 节点容限 返回: self 返回类型: FacilityAnalystSetting3D
-
set_weight_fields(value)¶ 设置权重字段
参数: value (list[WeightFieldInfo] or tuple[WeightFieldInfo]) -- 权重字段 返回: self 返回类型: FacilityAnalystSetting3D
-
t_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
tolerance¶ float -- 节点容限
-
weight_fields¶ list[WeightFieldInfo] -- 权重字段
-
-
class
iobjectspy.analyst.FacilityAnalyst3D(analyst_setting)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase设施网络分析类。
设施网络分析类。它是网络分析功能类之一,主要用于进行各类连通性分析和追踪分析。
设施网络是具有方向的网络。即介质(水流、电流等)会根据网络本身的规则在网络中流动。
设施网络分析的前提是已经建立了用于设施网络分析的数据集,建立用于设施网络分析的数据集的基础是建立网络数据集,在此基础上利用
build_facility_network_directions_3d()方法赋予网络数据集特有的用于进行设施网络分析的数据信息,也就是为网络数据集 建立流向,使原有的网络数据集具有了能够进行设施网络分析的最基本的条件 ,此时,就可以进行各种设施网络分析了。参数: analyst_setting (FacilityAnalystSetting3D) -- 设置网络分析的环境。 -
analyst_setting¶ FacilityAnalystSetting3D -- 设施网络分析的环境
-
burst_analyse(source_nodes, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 双向爆管分析,通过指定爆管弧段,查找爆管弧段上下游中对爆管位置产生直接影响的结点以及受爆管位置直接影响的结点
参数: - source_nodes (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 指定的弧段 ID 或 结点 ID,爆管位置。
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 爆管分析结果
返回类型:
-
find_critical_facilities_down(source_node_ids, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 下游关键设施查找,即查找给定弧段的关键下游设施结点,返回关键设施结点 ID 数组及给定弧段影响到的下游弧段 ID 数组。 在进行下游关键设施查找分析时,我们将设施网络的结点划分为普通结点和设施结点两类,其中设施结点认为是能够影响网络连通性的结点, 例如供水管网中的阀门;普通结点是不影响网络连通性的结点,如供水管网中的消防栓或三通等。
下游关键设施查找分析将从给定的设施结点中筛选出关键结点,这些关键结点是分析弧段与其下游保持连通性的最基本的结点,也就是说, 关闭这些关键结点后,分析结点与下游无法连通。同时,该分析的结果还包含给定弧段影响的下游弧段并集。
关键设施结点的查找方式可以归纳为:从分析弧段出发,向它的下游查找,每个方向上遇到的第一个设施结点,就是要查找的关键设施结点。
参数: - source_node_ids (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 指定的分析弧段 ID 或结点 ID
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID。
返回: 设施网络分析结果
返回类型:
-
find_critical_facilities_up(source_node_ids, edge_or_node_id, is_uncertain_direction_valid=False, is_edge_id=True)¶ 上游关键设施查找,即查找给定弧段的上游中的关键设施结点,返回关键结点 ID 数组及其下游弧段 ID 数组。 在进行上游关键设施查找分析时,我们将设施网络的结点划分为普通结点和设施结点两类,其中设施结点认为是能够影响网络连通性的结点, 例如供水管网中的阀门;普通结点是不影响网络连通性的结点,如供水管网中的消防栓或三通等。上游关键设施查找分析需要指定设施结点和 分析结点,其中分析结点可以是设施结点也可以是普通结点。
上游关键设施查找分析将从给定的设施结点中筛选出关键结点,这些关键结点是分析弧段与其上游保持连通性的最基本的结点,也就是说, 关闭这些关键结点后,分析结点与上游无法连通。同时,该分析的结果还包含查找出的关键结点的下游弧段的并集。
关键设施结点的查找方式可以归纳为:从分析弧段出发,向它的上游回溯,每个方向上遇到的第一个设施结点,就是要查找的关键设施结点。 如下图所示,从分析弧段(红色)出发,查找到的关键设施结点包括:2、8、9 和 7。而结点 4 和 11 不是回溯方向上遇到的第一个设施结 点,因此不是关键设施结点。作为示意,这里仅给出了分析弧段的上游部分,但注意分析结果还会给出关键设施结点 2、8、9 和 7 的下游弧段。
- 应用实例
供水管网发生爆管后,可以将所有的阀门作为设施结点,将发生爆裂的管段或管点作为分析弧段或分析结点,进行上游关键设施查找分析, 迅速找到上游中需要关闭的最少数量的阀门。关闭这些阀门后,爆裂管段或管点与它的上游不再连通,从而阻止水的流出,防止灾情加重和 资源浪费。同时,分析得出需要关闭的阀门的下游弧段的并集,也就是关闭阀门后的影响范围,从而确定停水区域,及时做好通知工作和应急措施。
参数: - source_node_ids (list[int] or tuple[int]) -- 指定的设施结点 ID 数组。不能为空。
- edge_or_node_id (int) -- 分析弧段 ID 或结点 ID
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_sink(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID或弧段 ID 查找汇,即从给定结点(弧段)出发,根据流向查找流出该结点的下游汇点,并返回给定结点到达该汇的最小耗费路径所包含的弧段、结点及耗费。 该方法从给定结点出发,按照流向,查找流出该结点的下游汇点,分析的结果为该结点到达查找到的汇的最小耗费路径所包含的弧段、结点及耗费。 如果网络中有多个汇,将查找最远的也就是从给定结点出发最小耗费最大的那个汇。为了便于理解,可将该功能的实现过程分为三步:
- 从给定结点出发,根据流向,找到该结点下游所有的汇点;
- 分析给定结点到每个汇的最小耗费路径并计算耗费;
- 选择上一步中计算出的耗费中的最大值所对应的路径作为结果,给出该路径上的弧段 ID 数组、结点 ID 数组以及该路径的耗费。
注意:分析结果中的结点 ID 数组不包括分析结点本身。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 D 进行查找汇分析。可以知道, 从 结点 D 出发,根据流向向下查找,共有 4 个汇,从结点 D 到达汇的最小耗费路径分别为:E-H-L-G、E-H-L-K、E-H-M-S 和 E-H-M-Q-R, 根据网络阻力,也就是弧段权值,可以计算得出 E-H-M-Q-R 这条路径的耗费最大,为 16.6,因此,结点 R 就是查找到的汇。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
find_source(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID 或弧段 ID 查找源,即从给定结点(弧段)出发,根据流向查找流向该结点的网络源头,并返回该源到达给定结点的最小耗费路径所包含的弧段、结点及耗费。 该方法从给定结点出发,按照流向,查找流向该结点的网络源头结点(即源点),分析的结果为查找到的源到达给定结点的最小耗费路径所包 含的弧段、结点及耗费。 如果网络中有多个源,将查找最远的也就是到达给定结点的最小耗费最大的那个源。为了便于理解,可将该功能的实现过程分为三步:
- 从给定结点出发,根据流向,找到该结点上游所有的源点;
- 分析每个源到达给定结点的最小耗费路径并计算耗费;
- 选择上一步中计算出的耗费中的最大值所对应的路径作为结果,给出该路径上的弧段 ID 数组、结点 ID 数组以及该路径的耗费。
注意:分析结果中的结点 ID 数组不包括分析结点本身。
下图是一个简单的设施网络,在网络弧段上使用箭头标示了网络的流向,在弧段旁标注了权值。对于分析结点 M 进行查找源分析。可以知道, 从 结点 M 出发,根据流向向上回溯,共有 7 个源,从源到结点 M 的最小耗费路径分别为:C-H-M、A-E-H-M、B-D-E-H-M、F-D-E-H-M、 J-N-M、I-N-M 和 P-N-M,根据网络阻力,也就是弧段权值,可以计算得出 B-D-E-H-M 这条路径的耗费最大,为 18.4,因此,结点 B 就是查找到的源。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果
返回类型:
-
is_load()¶ 判断网络数据集模型是否加载。
返回: 网络数据集模型加载返回 True,否则返回 False 返回类型: bool
-
load()¶ 根据设施网络分析环境设置加载设施网络模型。
- 注意,出现以下两种情况都必须重新调用 load 方法来加载网络模型,然后再进行分析。
- 对设施网络分析环境设置对象的参数进行了修改,需要重新调用该方法,否则所作修改不会生效从而导致分析结果错误;
- 对所使用的网络数据集进行了任何修改,包括修改网络数据集中的数据、替换数据集等,都需要重新加载网络模型,否则分析可能出错。
返回: 用于指示加载设施网络模型是否成功。如果成功返回 true,否则返回 false。 返回类型: bool
-
set_analyst_setting(value)¶ 设置设施网络分析的环境。
设施网络分析环境参数的设置,直接影响到设施网络分析的结果。设施网络分析所需要的参数包括:用于进行设施网络分析的数据集( 即 建立了流向的网络数据集或者同时建立了流向和等级的网络数据集,也就是说该方法对应的
FacilityAnalystSetting3D所指 定的网络数据集必须有流向或者流向和等级信息)、结点 ID 字段、弧段 ID 字段、弧段起始结点 ID 字段、弧段终止结点 ID 字段、权 值信息、点到弧段的距离容限、障碍结点、障碍弧段、流向等。参数: value (FacilityAnalystSetting3D) -- 设施网络分析环境参数 返回: self 返回类型: FacilityAnalyst3D
-
trace_down(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的弧段 ID 或结点 ID 进行下游追踪,即查找给定弧段(结点)的下游,返回下游包含的弧段、结点及总耗费。 下游追踪,是从给定结点(或弧段)出发,根据流向,查找其下游的过程。该方法用于查找给定弧段的下游,分析结果为其下游所包含的弧段、结点, 及流经整个下游的耗费。
下游追踪常用于影响范围的分析。例如:
- 自来水供水管道爆管后,通过下游追踪分析事故位置的所有下游管道,然后通过空间查询,确定受影响的供水区域,从而及时发放通知,并采 取应急措施, 如由消防车或自来水公司安排车辆为停水小区送水。
- 当发现河流的某个位置发生污染时,可以通过下游追踪,分析出可能受到影响的所有下游河段,如下图所示。在分析前,还可以根据污染物的 种类、 排放量等结合恰当的水质管理模型,分析出在污染清除前不会遭到污染的下游河段或位置,设置为障碍(在 FacilityAnalystSetting 中设置), 下游追踪时,到达障碍即追踪停止 ,这样可以缩小分析的范围。确定了可能受影响的河段后,通过空间查询和分析标记出位于结果河段附近的所 有用水单位和居民区 ,及时下发通知,并采取紧急措施,防止污染的危害进一步扩大。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
trace_up(edge_or_node_id, weight_name=None, is_uncertain_direction_valid=False, is_edge_id=True)¶ 根据给定的结点 ID 或弧段 ID 进行上游追踪,即查找给定结点的上游,返回上游包含的弧段、结点及总耗费。
上游和下游
对于设施网络的某个结点(或弧段)来说,网络中的资源最终流入该结点(或弧段)所经过的弧段和结点称为它的上游;从该结点(或弧段) 流出最终流入汇点所经过的弧段和网络称为它的下游。
下面以结点的上游和下游为例。下图是一个简单的设施网络的示意图,使用箭头标出了网络的流向。根据流向,可以看出,资源流经结点 2、4、3、7、8 以及弧段 10、9、3、4、8 最终流入结点 10,因此这些结点和弧段称为结点 10 的上游,其中的结点称为它的上游结点, 弧段称为它的上游弧段。同样的,资源从结点 10 流出,流经结点9、11、12 以及弧段 5、7、11 最终流出网络,因此,这些结点和弧段称 为结点 10 的下游,其中的结点称为它的下游结点,弧段称为它的下游弧段。
上游追踪与下游追踪
上游追踪,是从给定结点(或弧段)出发,根据流向,查找其上游的过程。类似的,下游追踪是从给定结点(或弧段)出发,根据流向, 查找其下游的过程。 FacilityAnalyst 类分别提供了从结点或弧段出发,进行上游或下游追踪的方法,分析的结果为查找到的上游或下 游所包含的弧段 ID 数组、结点 ID 数组,以及流经整个上游或者下游的耗费。本方法用于查找给定弧段的上游。
应用实例
上游追踪的一个常用应用是辅助定位河流水污染物来源。河流不仅是地球水循环的重要路径,也是人类最主要的淡水资源, 一旦河流发生 污染而没有及时发现污染源并消除 ,很可能影响人们的正常饮水和健康。由于河流受重力影响从高处向低处流动,因此当河流发生污染时, 应考虑其上游可能出现了污染源 ,如工业废水排放、生活污水排放、农药化肥污染等。河流水污染物来源追踪的大致步骤一般为:
- 当水质监测站的监测数据显示水质发生异常,首先确定发生异常的位置,从而在河流网络(网络数据集)上找出该位置所在(或最近)的弧段或结点, 作为上游追踪的起点;
- 如果知道在起点的上游中距离起点最近的水质监测正常的位置,可以将这些位置或其所在的河段设置为障碍,可以帮助进一步缩小分析的范围。因为可以认为, 水质监测正常的位置的上游,不可能存在此次调查的污染源。设置为障碍后,进行上游追踪分析,追踪到该位置后,将不会继续追踪该位置的上游;
- 进行上游追踪分析,查找到向发生水质异常位置所在河段汇流的所有河段;
- 使用空间查询、分析找出位于这些河段附近的所有可能的污染源,如化工厂、垃圾处理厂等;
- 根据发生水质异常的监测数据对污染源进行进一步筛选;
- 分析筛选出的污染源的排污负荷,按照其造成污染的可能性进行排序;
- 对可能的污染源按照顺序进行实地调查与研究,最终确定污染物来源。
参数: - edge_or_node_id (int) -- 结点 ID 或弧段 ID
- weight_name (str) -- 权值字段信息对象的名称
- is_uncertain_direction_valid (bool) -- 指定不确定流向是否有效。指定为 true,表示不确定流向有效,遇到不确定流向时分析 继续进行;指定为 false,表示不确定流向无效,遇到不确定流向将停止在该方向上继 续查找。流向字段的值为 2 时代表该弧段的流向为不确定流向。
- is_edge_id (bool) -- edge_or_node_id 是否表示弧段ID,True 表示为弧段ID,False表示为结点ID
返回: 设施网络分析结果。
返回类型:
-
-
class
iobjectspy.analyst.BurstAnalystResult3D(java_object)¶ 基类:
object爆管分析结果类。爆管分析结果返回关键设施点、普通设施点以及弧段。
-
critical_nodes¶ list[int] -- 爆管分析中影响爆管位置上下游的关键设施点。 关键设施点包括两种设施点:
- 爆管位置上游中所有对爆管位置直接影响的设施点。
- 下游中受爆管位置直接影响且有流出(即出度大于0)的设施点。
-
edges¶ list[int] -- 上下游影响爆管位置的弧段和受爆管位置影响的弧段。是从爆管位置进行双向搜索关键设施点和普通设施点遍历到的弧段。
-
normal_nodes¶ list[int] -- 爆管分析中受爆管位置影响的普通设施点。 普通设施点包括三种设施点:
- 受爆管位置直接影响且没有流出(出度为0)的设施点。
- 每个上游关键设施点的流出弧段直接影响的所有设施点A(除去所有关键设施点),且设施点A需要满足,上游关键设施点 到设施点A的影响弧段与上下游关键设施点的影响弧段有公共部分。
- 爆管位置下游受爆管位置直接影响的设施点A(关键设施点2和普通设施点1),设施点A上游中直接影响设施点A的设施 点B(除去所有关键设施点),且需要满足,设施点A到设施点B的影响弧段与上下游关键设施点的影响弧段有公共部分。
-
-
class
iobjectspy.analyst.TransportationAnalyst3D(analyst_setting)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase三维交通网络分析类。该类用于提供基于三维网络数据集的交通网络分析功能。目前只提供最佳路径分析。
道路、铁路、建筑物内通道、矿井巷道等可以使用交通网络进行模拟,与设施网络不同,交通网络是没有方向,即流通介质(行人或传输的资源) 可以自行决定方向、速度和目的地。当然,也可以进行一定的限制,例如设置交通规则,如单行线、禁行线等。
三维交通网络分析是基于三维网络数据集的分析,是三维网络分析的重要内容,目前提供了最佳路径分析。对于交通网络,尤其是对建筑物的内部 通道、矿井巷道这类在二维平面无法清晰展现的交通网络,三维网络能够更加真实的体现网络的空间拓扑结构和分析结果。
三维交通网络分析的一般步骤:
- 构建三维网络数据集。根据研究需求和已有数据选择合适的网络模型构建方法。SuperMap 提供了两种三维网络数据集的构建方法,具体介绍请
参阅
build_network_dataset_3d()或build_network_dataset_know_relation_3d(). - (可选)建议对用于分析的网络数据集进行数据检查(
validate_network_dataset_3d()). - 设置三维交通网络分析环境(set_analyst_setting 方法);
- 加载网络模型(load 方法);
- 使用 TransportationAnalyst3D 类提供的各种交通网络分析方法进行相应的分析。
初始化对象
参数: analyst_setting (TransportationAnalystSetting3D) -- 交通网络分析环境设置对象 -
analyst_setting¶ TransportationAnalystSetting3D -- 交通网络分析环境设置对象
-
find_path(parameter)¶ 最佳路径分析。 最佳路径分析,用于在网络数据集中,找出经过给定的 N 个点(N 大于等于 2)的最佳路径,这条最佳路径具有以下两个特征:
这条路径必须按照给定的 N 点的次序依次经过这 N 个点,也就是说,最佳路径分析中经过的点是有序的; 这条路径的耗费最小。耗费根据交通网络分析参数所指定的权重来决定。权重可以是长度、时间、路况、费用等,因此最佳路径可以是距离最 短的路径、花费时间最少的路径、路况最好的路径、费用最低的路径等等。
有两种方式来指定待分析的经过点:
- 结点方式:通过
TransportationAnalystParameter3D类的TransportationAnalystParameter3D.set_nodes()方 法指定最佳路径分析所经过的结点的 ID,此时,分析过程中经过的点就是相应的网络结点,而经过点的次序是网络结点在这个结点 ID 数组中的次序; - 任意坐标点方式:通过
TransportationAnalystParameter3D类的TransportationAnalystParameter3D.set_points()方 法指定最佳路径分析所经过的点的坐标,此时,分析过程中经过的点就是相应的坐标点集合,分析过程中经过点的次序是坐标点在点集合中的次序。
注意:两种方式只能选择一种使用,不能同时使用。
参数: parameter (TransportationAnalystParameter3D) -- 交通网络分析参数对象 返回: 最佳路径分析结果 返回类型: TransportationAnalystResult3D - 结点方式:通过
-
load()¶ 加载网络模型。 该方法根据交通网络分析环境设置(
TransportationAnalystSetting3D)对象中的环境参数,加载网络模型。在设置好交通网络分析环境的 参数后又修改了相关参数,只有调用该方法,所做的交通网络分析环境设置才会在交通网络分析的过程中生效。返回: 加载成功返回 True,否则返回 False 返回类型: bool
-
set_analyst_setting(analyst_setting)¶ 设置交通网络分析环境设置对象 在利用交通网络分析类进行各种交通网络分析时,都要首先设置交通网络分析的环境,都要首先设置交通网络分析的环境
参数: analyst_setting (TransportationAnalystSetting3D) -- 交通网络分析环境设置对象 返回: self 返回类型: TransportationAnalyst3D
- 构建三维网络数据集。根据研究需求和已有数据选择合适的网络模型构建方法。SuperMap 提供了两种三维网络数据集的构建方法,具体介绍请
参阅
-
class
iobjectspy.analyst.TransportationAnalystResult3D(java_object, index)¶ 基类:
object三维交通网络分析结果类。该类用于返回各种三维交通网络分析的结果,包括路由集合、分析途经的结点集合以及弧段集合、站点集合和权值集合 以及各站点的花费等。
-
edges¶ list[int] -- 返回分析结果的途经弧段集合。注意,必须将 TransportationAnalystParameter3D 对象的
TransportationAnalystParameter3D.set_edges_return()方法设置为 True,分析结果中才会包含途经弧段集合,否则返回 None
-
nodes¶ list[int] -- 返回分析结果的途经结点集合。注意,必须将 TransportationAnalystParameter3D 对象的
TransportationAnalystParameter3D.set_nodes_return()方 法设置为 True,分析结果中才会包含途经结点集合,否则为一个空的数组。
-
route¶ GeoLineM -- 返回分析结果的路由对象。注意,必须将 TransportationAnalystParameter3D 对象的
TransportationAnalystParameter3D.set_routes_return()方 法设置为 true,分析结果中才会包含路由对象,否则返回 None
-
stop_indexes¶ list[int] -- 返回站点索引,该数组反映了站点在分析后的排列顺序。注意,必须将 TransportationAnalystParameter3D 对象 的
TransportationAnalystParameter3D.set_stop_indexes_return()方法设置为 True,分析结果中才会 包含站点索引,否则为一个空的数组。最佳路径分析(
TransportationAnalyst3D.find_path()方法):- 结点模式:如设置的分析结点 ID 为 1,3,5 的三个结点,因为结果途经顺序必须为 1,3,5,所以元素值依 次为 0,1,2,即结果途经顺序在初始设置结点串中的索引。
- 坐标点模式:如设置的分析坐标点为 Pnt1,Pnt2,Pnt3,因为结果途经顺序必须为 Pnt1,Pnt2,Pnt3,所以元 素值依次为 0,1,2,即结果途经坐标点顺序在初始设置坐标点串中的索引。
-
stop_weights¶ list[float] -- 返回根据站点索引对站点排序后,站点间的花费(权值)。 该方法返回的是站点与站点间的耗费,这里的站点指的是用于分析结点或坐标点,而不是路径经过的所有结点或坐标点。 该方法返回的权值所关联的站点顺序与
stop_indexes方法中返回的站点索引值的顺序一致。- 最佳路径分析(
TransportationAnalyst3D.find_path()方法): 假设指定经过点 1、2、3,则二维元素依次 为:1 到 2 的耗费、2 到 3 的耗费;
- 最佳路径分析(
-
weight¶ float -- 花费的权值。
-
-
class
iobjectspy.analyst.TransportationAnalystParameter3D¶ 基类:
object三维交通网络分析参数类。
该类用于设置三维交通网络分析所需的各种参数,如分析时途经的结点(或任意点)的集合、权值信息、障碍点和障碍弧段,以及分析结果中是 否包含途经结点集合、经过弧段集合、路由对象等。
-
barrier_edges¶ list[int] -- 障碍弧段 ID 列表
-
barrier_nodes¶ list[int] -- 障碍结点 ID 列表
-
barrier_points¶ list[Point3D] -- 障碍点列表
-
is_edges_return¶ bool -- 分析结果中是否包含途经弧段
-
is_nodes_return¶ bool -- 分析结果中是否包含途经结点
-
is_routes_return¶ bool -- 返回分析结果中是否包含三维线(
GeoLine3D)对象
-
is_stop_indexes_return¶ bool -- 分析结果中是否要包含站点索引
-
nodes¶ list[int] -- 分析途经点
-
points¶ list[Point3D] -- 分析时途经点
-
set_barrier_edges(edges)¶ 设置障碍弧段 ID 列表。可选。此处指定的障碍弧段与交通网络分析环境(
TransportationAnalystSetting)中指定的障 碍弧段共同作用于交通网络分析。参数: edges (list[int] or tuple[int]) -- 障碍弧段 ID 列表 返回: self 返回类型: TransportationAnalystParameter3D
-
set_barrier_nodes(nodes)¶ 设置障碍结点 ID 列表。可选。此处指定的障碍结点与交通网络分析环境(
TransportationAnalystSetting)中指定的 障碍结点共同作用于交通网络分析。参数: nodes (list[int] or tuple[int]) -- 障碍结点 ID 列表 返回: self 返回类型: TransportationAnalystParameter3D
-
set_barrier_points(points)¶ 设置障碍结点的坐标列表。可选。指定的障碍点可以不在网络上(既不在弧段上也不在结点上),分析时将根据距离容限(
TransportationPathAnalystSetting.tolerance)把 障碍点归结到最近的网络上。目前支持最佳路径分析、最近设施查找、旅行商分析和物流配送分析。参数: points (list[Point2D] or tuple[Point2D]) -- 障碍结点的坐标列表 返回: self 返回类型: TransportationAnalystParameter3D
-
set_edges_return(value=True)¶ 设置分析结果中是否包含途经弧段
参数: value (bool) -- 指定分析结果中是否包含途经弧段。设置为 True,在分析成功后,可以从 TransportationAnalystResult3D 对象 TransportationAnalystResult3D.edges方法返回途经弧段;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter3D
-
set_nodes(nodes)¶ 设置分析途经点。必设,但与
set_points()方法互斥,如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点 集合,又指定了坐标点集合,然后分析,此时只对坐标点进行分析。参数: nodes (list[int] or tuple[int]) -- 途经结点 ID 返回: self 返回类型: TransportationAnalystParameter3D
-
set_nodes_return(value=True)¶ 设置分析结果中是否包含结点
参数: value (bool) -- 指定分析结果中是否包含途经结点。设置为 True,在分析成功后,可以从 TransportationAnalystResult3D 对象 TransportationAnalystResult3D.nodes方法返回途经结点;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter3D
-
set_points(points)¶ 设置分析时途经点的集合。必设,但与
set_nodes()方法互斥,如果同时设置,则只有分析前最后的设置有效。例如,先指定了结点集合,又 指定了坐标点集合,然后分析,此时只对坐标点进行分析。如果设置的途经点集合中的点不在网络数据集的范围内,则该点不会参与分析
参数: points (list[Point3D] or tuple[Point3D]) -- 途经点 返回: self 返回类型: TransportationAnalystParameter3D
-
set_routes_return(value=True)¶ 分析结果中是否包含三维线(
GeoLine3D)对象param bool value: 指定是否包含路由对象。设置为 True,在分析成功后,可以从 TransportationAnalystResult3D 对象 的 TransportationAnalystResult3D.route返回路由对象;为 False 则返回 Nonereturn: self rtype: TransportationAnalystParameter3D
-
set_stop_indexes_return(value=True)¶ 设置分析结果中是否要包含站点索引的
参数: value (bool) -- 指定分析结果中是否要包含站点索引。设置为 True,在分析成功后,可以从 TransportationAnalystResult3D 对象 TransportationAnalystResult3D.stop_indexes方法返回站点索引;为 False 则返回 None返回: self 返回类型: TransportationAnalystParameter3D
-
set_weight_name(name)¶ 设置权值字段信息的名称。如果未设置,则默认使用权值字段信息集合中的第一个权值字段信息对象的名称
参数: name (str) -- 权值字段信息的名字标识 返回: self 返回类型: TransportationAnalystParameter3D
-
weight_name¶ str -- 权值字段信息的名称
-
-
class
iobjectspy.analyst.TransportationAnalystSetting3D(network_dataset=None)¶ 基类:
object交通网络分析分析环境。
初始化对象
参数: network_dataset (DatasetVector or str) -- 网络数据集 -
barrier_edge_ids¶ list[int] -- 障碍弧段的 ID 列表
-
barrier_node_ids¶ list[int] -- 障碍结点的 ID 列表
-
edge_filter¶ str -- 交通网络分析中弧段过滤表达式
-
edge_id_field¶ str -- 网络数据集中标志弧段 ID 的字段
-
edge_name_field¶ str -- 道路名称字段
-
f_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
ft_single_way_rule_values¶ list[str] -- 用于表示正向单行线的字符串的数组
-
network_dataset¶ DatasetVector -- 网络数据集
-
node_id_field¶ str -- 网络数据集中标识结点 ID 的字段
-
prohibited_way_rule_values¶ list[str] -- 表示禁行线的字符串的数组
-
rule_field¶ str -- 网络数据集中表示网络弧段的交通规则的字段
-
set_barrier_edge_ids(value)¶ 设置障碍弧段的 ID 列表
参数: value (str or list[int]) -- 障碍弧段的 ID 列表 返回: self 返回类型: TransportationAnalystSetting3D
-
set_barrier_node_ids(value)¶ 设置障碍结点的 ID 列表
参数: value (str or list[int]) -- 障碍结点的 ID 列表 返回: self 返回类型: TransportationAnalystSetting3D
-
set_edge_filter(value)¶ 设置交通网络分析中弧段过滤表达式
参数: value -- 交通网络分析中弧段过滤表达式 返回: self 返回类型: TransportationAnalystSetting3D
-
set_edge_id_field(value)¶ 设置网络数据集中标识结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段 ID 的字段 返回: self 返回类型: TransportationAnalystSetting3D
-
set_edge_name_field(value)¶ 设置道路名称字段
参数: value (str) -- 道路名称字段 返回: self 返回类型: TransportationAnalystSetting3D
-
set_f_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 网络数据集中标志弧段起始结点 ID 的字段 返回: self 返回类型: TransportationAnalystSetting3D
-
set_ft_single_way_rule_values(value)¶ 设置用于表示正向单行线的字符串的数组
参数: value (str or list[str]) -- 用于表示正向单行线的字符串的数组 返回: self 返回类型: TransportationAnalystSetting3D
-
set_network_dataset(dataset)¶ 设置用于最佳路径分析的网络数据集
参数: dataset (DatasetVetor or str) -- 网络数据集 返回: 当前对象 返回类型: TransportationAnalystSetting3D
-
set_node_id_field(value)¶ 设置网络数据集标识结点ID的字段
参数: value (str) -- 网络数据集中标识结点 ID 的字段 返回: self 返回类型: TransportationAnalystSetting3D
-
set_prohibited_way_rule_values(value)¶ 设置表示禁行线的字符串的数组
参数: value (str or list[str]) -- 表示禁行线的字符串的数组 返回: self 返回类型: TransportationAnalystSetting3D
-
set_rule_field(value)¶ 设置网络数据集中表示网络弧段的交通规则的字段
参数: value (str) -- 网络数据集中表示网络弧段的交通规则的字段 返回: self 返回类型: TransportationAnalystSetting3D
-
set_t_node_id_field(value)¶ 设置网络数据集中标志弧段起始结点 ID 的字段
参数: value (str) -- 返回: self 返回类型: TransportationAnalystSetting3D
-
set_tf_single_way_rule_values(value)¶ 设置表示逆向单行线的字符串的数组
参数: value (str or list[str]) -- 表示逆向单行线的字符串的数组 返回: self 返回类型: TransportationAnalystSetting3D
-
set_tolerance(value)¶ 设置节点容限
参数: value (float) -- 节点容限 返回: 当前对象 返回类型: TransportationAnalystSetting3D
-
set_two_way_rule_values(value)¶ 设置表示双向通行线的字符串的数组
参数: value (str or list[str]) -- 表示双向通行线的字符串的数组 返回: self 返回类型: TransportationAnalystSetting3D
-
set_weight_fields(value)¶ 设置权重字段
参数: value (list[WeightFieldInfo] or tuple[WeightFieldInfo]) -- 权重字段 返回: self 返回类型: TransportationAnalystSetting3D
-
t_node_id_field¶ str -- 网络数据集中标志弧段起始结点 ID 的字段
-
tf_single_way_rule_values¶ list[str] -- 表示逆向单行线的字符串的数组
-
tolerance¶ float -- 节点容限
-
two_way_rule_values¶ list[str] -- 表示双向通行线的字符串的数组
-
weight_fields¶ list[WeightFieldInfo] -- 权重字段
-
-
iobjectspy.analyst.build_address_indices(output_directory, datasets, index_fields, save_fields=None, top_group_field=None, secondary_group_field=None, lowest_group_field=None, is_build_reverse_matching_indices=False, bin_distance=0.0, dictionary_file=None, is_append=False, is_traditional=False)¶ 构建地址匹配的索引文件
参数: - output_directory (str) -- 索引文件结果输出目录
- datasets (list[DatasetVector] or tuple[DatasetVector]) -- 保存地址信息,用来创建索引的数据集
- index_fields (str or list[str] or tuple[str]) -- 需要建立索引的字段,比如详细地址字段或地址名称等,该字段集合应该在每一个数据集中都存在
- save_fields (str or list[str] or tuple[str]) -- 需要存储的额外信息的字段,这些信息不用于地址匹配,但会在地址匹配结果中返回出来。
- top_group_field (str) -- 一级分组的字段名称,比如各个省名称。
- secondary_group_field (str) -- 二级分组的名称,比如各个市名称。
- lowest_group_field (str) -- 三级分组的名称,比如各个县名称。
- is_build_reverse_matching_indices (bool) -- 是否为逆向地址匹配创建索引
- bin_distance (float) -- 逆向地址匹配索引创建的间隔距离。距离单位和坐标系保持一致。
- dictionary_file (str) -- 字典文件地址,如果为空,则使用默认的字典文件。
- is_append (bool) -- 是否在原索引上追加,如果指定的输出索引文件目录上已经有索引文件,如果为 True,则在原索引文件上追加,但要求 追加新的数据时要求新的属性表结构与已加载数据的属性表结构相同。如果为 False,则创建新的索引文件。
- is_traditional (bool) -- 是否是繁体中文。
返回: 是否创建索引成功
返回类型: bool
-
class
iobjectspy.analyst.AddressItem(java_object)¶ 基类:
object中文地址模糊匹配结果类。中文地址模糊匹配结果类存储了与输入的中文地址相匹配的查询结果的详细信息,包括查询出来的地址,该地址所在的 数据集,该地址在源数据集中的 SmID,查询结果的评分值以及地址的地理位置信息。
-
address¶ str -- 匹配出来的地址
-
address_as_tuple¶ tuple[str] -- 匹配出来的地址的数组形式
-
dataset_index¶ int -- 查询出来的中文地址所在的数据集的索引
-
location¶ Point2D -- 查询出来的地址所在的地理位置
-
record_id¶ int -- 查询出来的地址在源数据集中所对应的 SMID
-
score¶ float -- 匹配的评分结果
-
-
class
iobjectspy.analyst.AddressSearch(search_directory)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase中文地址模糊匹配类。
中文地址模糊匹配的实现流程和注意事项:
- 指定中文地址库数据创建的地址索引的目录,创建一个中文地址匹配对象;
- 调用match对象,指定要搜索的地址所在城市,必须是中文地址数据库中市级字段中的值,再指定要搜索的中文地址和返回个数;
- 系统对待匹配的关键字进行分词,然后去匹配指定数据集中指定字段中的内容,通过一定的运算,返回匹配的结果。
初始化对象
参数: search_directory (str) -- 地址索引所在的目录 -
is_valid_lowest_group_name(value)¶ 判断指定的名称作为三级分组名称是否合法。
参数: value (str) -- 要判断的字段名称 返回: 合法返回 True,否则返回 False 返回类型: bool
-
is_valid_secondary_group_name(value)¶ 判断指定的名称作为二级分组名称是否合法。
参数: value (str) -- 要判断的字段名称 返回: 合法返回 True,否则返回 False 返回类型: bool
-
is_valid_top_group_name(value)¶ 判断指定的名称作为一级分组名称是否合法。
参数: value (str) -- 要判断的字段名称 返回: 合法返回 True,否则返回 False 返回类型: bool
-
match(address, is_address_segmented=False, is_location_return=True, max_result_count=10, top_group_name=None, secondary_group_name=None, lowest_group_name=None)¶ 地址匹配。该方法支持多线程。
参数: - address (str) -- 要检索的地名地址
- is_address_segmented (bool) -- 传入的中文地址是否已经被分割,即用“*”分隔符进行了分词。
- is_location_return (bool) -- 中文地址模糊匹配结果对象是否包含位置信息。
- max_result_count (int) -- 中文地址模糊匹配的搜索的匹配结果的最大数目
- top_group_name (str) -- 一级分组名称,前提是创建数据索引的时候设置了一级分组字段名称
- secondary_group_name (str) -- 二级分组名称,前提是创建数据索引的时候设置了二级分组字段名称
- lowest_group_name (str) -- 三级分组名称,前提是创建数据索引的时候设置了三级分组字段名称
返回: 中文地址模糊匹配结果集合
返回类型: list[AddressItem]
-
reverse_match(geometry, distance, max_result_count=10)¶ 逆向地址匹配。该方法支持多线程。
参数: 返回: 中文地址匹配结果集合
返回类型: list[AddressItem]
-
search_directory¶ str -- 地址索引所在的目录
-
set_search_directory(search_directory)¶ 设置地址索引所在的目录。地址索引使用
build_address_indices()方法创建。参数: search_directory (str) -- 地址索引所在的目录 返回: self 返回类型: AddressSearch
-
class
iobjectspy.analyst.TopologicalSchemaOrientation¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - TopologicalSchemaOrientation.LEFTTORIGHT -- 图形从左到右的布局走向。逻辑图将从左侧的根结点开始,并在右侧结束。
- TopologicalSchemaOrientation.RIGHTTOLEFT -- 图形从右到左的布局走向。逻辑图将从右侧的根结点开始,并在左侧结束。
- TopologicalSchemaOrientation.TOPTOBOTTOM -- 图形从上到下的布局走向。逻辑图将从顶部侧的根结点开始,并在底部结束。
- TopologicalSchemaOrientation.BOTTOMTOTOP -- 图形从下到上的布局走向。逻辑图将从底部的根结点开始,并在顶部结束。
-
BOTTOMTOTOP= 3¶
-
LEFTTORIGHT= 0¶
-
RIGHTTOLEFT= 1¶
-
TOPTOBOTTOM= 2¶
-
class
iobjectspy.analyst.NetworkEdge(edge_id, from_node_id, to_node_id, edge=None)¶ 基类:
object网络弧段对象,表示网络关系。由线对象、线对象的唯一标识以及组成线对象首尾两个结点的唯一标识组成。
参数: - edge_id (int) -- 网络弧段线对象ID
- from_node_id (int) -- 网络弧段线对象起始点ID
- to_node_id (int) -- 网络弧段线对象终止点ID
- edge (GeoLine) -- 网络弧段线对象
-
edge¶ GeoLine -- 网络关系中,弧段几何对象
-
edge_id¶ int -- 网络关系中,弧段对象的ID
-
from_node_id¶ int -- 网络关系中,弧段起始点的ID
-
set_edge_id(value)¶ 设置弧段对象的ID
参数: value (int) -- 弧段对象ID 返回: self 返回类型: NetworkEdgeID
-
set_from_node_id(value)¶ 设置弧段起始点的ID
参数: value (int) -- 弧段起始点ID 返回: self 返回类型: NetworkEdgeID
-
set_to_node_id(value)¶ 设置弧段终止点的ID
参数: value (int) -- 弧段终止点ID 返回: self 返回类型: NetworkEdgeID
-
to_node_id¶ int -- 网络关系中,弧段终止点ID
-
class
iobjectspy.analyst.NetworkNode(node_id, node)¶ 基类:
object网络弧段关系中结点对象,由表示网络弧段关系中的点对象和结点对象的唯一标识表示。
参数: - node_id (int) -- 网络结点ID
- node (GeoPoint) -- 网络结点对象
-
node¶ GeoPoint -- 网络结点对象
-
node_id¶ int -- 网络结点ID
-
set_node(value)¶ 设置网络结点对象
参数: value (GeoPoint or Point2D) -- 网络结点对象 返回: self 返回类型: NetworkNode
-
set_node_id(value)¶ 设置网络结点ID
参数: value (int) -- 网络结点ID 返回: self 返回类型: NetworkNode
-
class
iobjectspy.analyst.TopologicalHierarchicalSchema(node_spacing=30.0, rank_node_spacing=50.0, smooth=1, orientation=TopologicalSchemaOrientation.LEFTTORIGHT)¶ 基类:
object等级拓扑逻辑图。
等级图适用于类似有向的设施网络中,有明确的源的网络。如下图网络中只有一个源,也就是一个子网中,只有一个入口,其他均为出口,这种网络可以生成等级图:
参数: - node_spacing (float) -- 拓扑逻辑图结点距离
- rank_node_spacing (float) -- 拓扑逻辑图等级之间的距离
- smooth (int) -- 光滑系数
- orientation (TopologicalSchemaOrientation or str) -- 拓扑逻辑图的布局走向
-
node_spacing¶ float -- 拓扑逻辑图结点距离。默认为 30。
-
orientation¶ TopologicalSchemaOrientation -- 拓扑逻辑图的布局走向
-
rank_node_spacing¶ float -- 拓扑逻辑图等级之间的距离。默认为 50。
-
set_node_spacing(value)¶ 设置拓扑逻辑图结点距离。
如下图所示从结点①到结点②的结点距离为dy
参数: value (float) -- 拓扑逻辑图结点距离 返回: self 返回类型: TopologicalHierarchicalSchema
-
set_orientation(value)¶ 设置拓扑逻辑图的布局走向,默认为从左到右布局。
参数: value (TopologicalSchemaOrientation or str) -- 拓扑逻辑图的布局走向 返回: self 返回类型: TopologicalHierarchicalSchema
-
set_rank_node_spacing(value)¶ 设置拓扑逻辑图等级之间的距离。
如下图所示从结点①到结点②为两个等级,dz即为等级间的距离
参数: value (float) -- 拓扑逻辑图等级之间的距离 返回: self 返回类型: TopologicalHierarchicalSchema
-
set_smooth(value)¶ 设置光滑系数。如果需要对结果进行光滑处理,可以设置大于1的光滑系数,默认不进行光滑处理,即值为1。
参数: value (int) -- 光滑系数 返回: self 返回类型: TopologicalHierarchicalSchema
-
smooth¶ int -- 光滑系数。默认为 1。
-
class
iobjectspy.analyst.TopologicalTreeSchema(node_spacing=30.0, level_spacing=20.0, break_radio=0.5, orientation=TopologicalSchemaOrientation.LEFTTORIGHT)¶ 基类:
object树形拓扑逻辑图。
树形图和等级图一样。都适用于类似有向的设施网络中,有明确的源的网络。
在一个子网中,只支持单源或单汇点情形,也就是一个子网中,只能有一个源点,汇点不做要求。也支持只有一个汇点,源点不做要求。
参数: - node_spacing (float) -- 拓扑逻辑图结点距离
- level_spacing (float) -- 树形图层级之间的距离
- break_radio (float) -- 获取折线打断比例,值域为[0,1]
- orientation (TopologicalSchemaOrientation or str) -- 拓扑逻辑图的布局走向
-
break_radio¶ float -- 折线打断比例。默认为 0.5.
-
level_spacing¶ float -- 树形图层级之间的距离
-
node_spacing¶ float -- 拓扑逻辑图结点距离,默认值为30.
-
orientation¶ TopologicalSchemaOrientation -- 拓扑逻辑图的布局走向
-
set_break_radio(value)¶ 设置折线打断比例。 如下图所示从结点①到结点②的连接折线,即为要打断的折线,设置打断距离为0.7,得到如图效果
参数: value (float) -- 折线打断比例 返回: self 返回类型: TopologicalTreeSchema
-
set_level_spacing(value)¶ 设置树形图层级之间的距离。 下图所示从结点①到结点②为两个层级,dx即为层级间的距离
参数: value (float) -- 树形图层级之间的距离 返回: self 返回类型: TopologicalTreeSchema
-
set_node_spacing(value)¶ 设置拓扑逻辑图结点距离。 如下图所示从结点①到结点②的结点距离为dy
参数: value (float) -- 拓扑逻辑图结点距离 返回: self 返回类型: TopologicalTreeSchema
-
set_orientation(value)¶ 设置拓扑逻辑图的布局走向
参数: value (TopologicalSchemaOrientation or str) -- 拓扑逻辑图的布局走向 返回: self 返回类型: TopologicalTreeSchema
-
class
iobjectspy.analyst.TopologicalOrthogonalSchema(node_spacing=10.0)¶ 基类:
object直角正交拓扑逻辑图。
直角正交图对数据要求比较少,但要求数据不能有自循环(即在一条网络弧段中,起点等于终点)的弧段。
参数: node_spacing (float) -- 拓扑逻辑图结点距离 -
node_spacing¶ float -- 拓扑逻辑图结点距离
-
set_node_spacing(value)¶ 设置拓扑逻辑图结点之间的距离。默认值为 10 个单位。
参数: value (float) -- 拓扑逻辑图结点距离 返回: self 返回类型: TopologicalOrthogonalSchema
-
-
iobjectspy.analyst.build_topological_schema(schema_param, network_dt_or_edges, network_nodes=None, is_merge=False, tolerance=1e-10, out_data=None, out_dataset_name=None)¶ 构建拓扑逻辑图。
拓扑逻辑图,是基于网络数据集生成体现自身逻辑结构的示意图,将复杂的网络以一种直观的方式进行表达,简化了网络的表现形式。可应用于电信、交通、管线、 电力等行业的资源管理,通过拓扑逻辑图查看网络,能够有效评估现有的网络资源分布,预测和规划后续资源的配置等。
SuperMap 支持根据网络弧段和网络结点表示的网络关系,构建拓扑逻辑图,方便检查网络连通性及获取网络数据的逻辑示意图。
>>> network_dt = open_datasource('/home/iobjectspy/data/example_data.udbx')['network_schema']
构建等级图:
>>> hierarchical_schema_result = build_topological_schema(TopologicalHierarchicalSchema(smooth=3), network_dt)
构建树形图:
>>> tree_schema_result = build_topological_schema(TopologicalTreeSchema(), network_dt)
构建直角正交图:
>>> orthogonal_schema_result = build_topological_schema(TopologicalOrthogonalSchema(), network_dt)
通过网络关系构建拓扑图:
>>> network_edges = list() >>> network_edges.append(NetworkEdge(1, 1, 2)) >>> network_edges.append(NetworkEdge(2, 1, 3)) >>> network_edges.append(NetworkEdge(3, 2, 4)) >>> network_edges.append(NetworkEdge(4, 2, 5)) >>> network_edges.append(NetworkEdge(5, 3, 6)) >>> network_edges.append(NetworkEdge(6, 3, 7)) >>> out_ds = create_mem_datasource() >>> tree_schema_result_2 = build_topological_schema(TopologicalTreeSchema(), network_edges, out_data=out_ds)
通过网络弧段和网络结点构建拓扑图:
>>> edges = [] >>> nodes = [] >>> edge_rd = network_dt.get_recordset() >>> while edge_rd.has_next(): >>> edge_id = edge_rd.get_value('SmEdgeID') >>> f_node = edge_rd.get_value('SmFNode') >>> t_node = edge_rd.get_value('SmTNode') >>> edges.append(NetworkEdge(edge_id, f_node, t_node, edge_rd.get_geometry())) >>> edge_rd.move_next() >>> edge_rd.close() >>> node_rd = network_dt.child_dataset.get_recordset() >>> while node_rd.has_next(): >>> node_id = node_rd.get_value('SmNodeID') >>> nodes.append(NetworkNode(node_id, node_rd.get_geometry())) >>> node_rd.move_next() >>> node_rd.close() >>> >>> tree_schema_result_2 = build_topological_schema(TopologicalTreeSchema(), edges, nodes, is_merge=True, >>> tolerance=1.0e-6, out_data=out_ds, out_dataset_name='SchemaRes') >>>
参数: - schema_param (TopologicalHierarchicalSchema or TopologicalTreeSchema or TopologicalOrthogonalSchema) -- 拓扑逻辑图参数类对象
- network_dt_or_edges (DatasetVector or list[NetworkEdge]) -- 二维网络数据集或者虚拟网络弧段
- network_nodes (list[NetworkNode]) -- 虚拟网络结点,当
network_dt_or_edges为 list[NetworkEdge] 时,可以设置虚拟网络结点对象,以表达 完整的网络关系。 当不设置 network_nodes 时,可以单独使用 list[NetworkEdge] 同样能表达网络关系。且 NetworkEdge 可以不需要 网络弧段空间对象。 - is_merge (bool) -- 是否设置合并空间位置上重复的网络弧段和网络结点对象。网络关系中,如果存在空间位置上的重复弧段和重复结点, 如果设置此参 数为 True ,则会提取一份公共的弧段关系构建逻辑图,在构建的拓扑逻辑图也含有空间位置上的重复弧段和结点。如果设置此参数 为 False ,则计算拓扑逻辑图时对每条正确的网络拓扑关系都正常处理。 只有在设置了有效的 :py:attr:`network_nodes`时,is_merge 才有效。
- tolerance (float) -- 节点容限,用于空间计算中节点对象比较。如果
is_merge为 True 才有效 - out_data (Datasource) -- 存储结果数据的数据源。当
network_dt_or_edges不是网络数据集时,必须设置有效的结果数据源。 - out_dataset_name (str) -- 结果数据集名称
返回: 用于表示拓扑逻辑图的二维网络数据集
返回类型:
iobjectspy.conversion module¶
conversion 模块提供基本的数据导入和导出功能,通过使用 conversion 模块可以快速的将第三方的文件导入到 SuperMap 的数据源中,也可以将 SuperMap 数据源 中的数据导出为 第三方文件。
在 conversion 模块中,所有导入数据的接口中,output 参数输入结果数据集的数据源信息,可以为 Datasource 对象,也可以为 DatasourceConnectionInfo 对象, 同时,也支持当前工作空间下数据源的别名,也支持 UDB 文件路径,DCF 文件路径等。
>>> ds = Datasource.create(':memory:')
>>> alias = ds.alias
>>> shape_file = 'E:/Point.shp'
>>> result1 = import_shape(shape_file, ds)
>>> result2 = import_shape(shape_file, alias)
>>> result3 = import_shape(shape_file, 'E:/Point_Out.udb')
>>> result4 = import_shape(shape_file, 'E:/Point_Out_conn.dcf')
而导入数据的结果返回一个 Dataset 或 str 的列表对象。当导入数据只生成一个数据集时,列表的个数为1,当导入数据生成多个数据集时,列表的个数可能大于1。 列表中返回 Dataset 还是 str 是由输入的 output 参数决定的,当输入的 output 参数可以直接在当前工作空间中获取到数据源对象时,将会返回 Dataset 的列表, 如果输入的 output 参数无法直接在当前工作空间中获取到数据源对象时,程序将自动尝试打开数据源或新建数据源(只支持新建 UDB 数据源),此时,返回的结果将是 结果数据集的数据集名称,而完成数据导入后,结果数据源也会被关闭。所以如果用户需要继续基于导入后的结果数据集进行操作,则需要根据结果数据集名称和数据源信息再次开发数据源以获取数据集。
所有导出数据集的接口,data 参数是被导出的数据集信息,data 参数接受输入一个数据集对象(Dataset)或数据源别名与数据集名称的组合(例如,'alias/dataset_name', 'alias\dataset_name'), ,也支持数据源连接信息与数据集名称的组合(例如, 'E:/data.udb/dataset_name'),值得注意的是,当输入的是数据源信息时,程序会自动打开数据源,但是不会自动关闭数据源,也就是打开后的数据源 会存在当前工作空间中
>>> export_to_shape('E:/data.udb/Point', 'E:/Point.shp', is_over_write=True)
>>> ds = Datasource.open('E:/data.udb')
>>> export_to_shape(ds['Point'], 'E:/Point.shp', is_over_write=True)
>>> export_to_shape(ds.alias + '|Point', 'E:/Point.shp', is_over_write=True)
>>> ds.close()
-
iobjectspy.conversion.import_shape(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=False, is_import_empty=False, source_file_charset=None, is_import_as_3d=False, progress=None)¶ 导入 shape 文件到数据源中。支持导入文件目录。
参数: - source_file (str) -- 被导入的 shape 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式类型,可以为 ImportMode 枚举值或名称
- is_ignore_attrs (bool) -- 是否忽略属性信息,默认值为 False
- is_import_empty (bool) -- 否导入空的数据集,默认是不导入的。默认为 False
- source_file_charset (Charset or str) -- shape 文件的原始字符集类型
- is_import_as_3d (bool) -- 是否导入为 3D 数据集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
>>> result = import_shape( 'E:/point.shp', 'E:/import_shp_out.udb') >>> print(len(result) == 1) >>> print(result[0])
-
iobjectspy.conversion.import_dbf(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, source_file_charset=None, progress=None)¶ 导入 dbf 文件到数据源中。支持导入文件目录。
参数: - source_file (str) -- 被导入的 dbf 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式类型,可以为 ImportMode 枚举值或名称
- is_import_empty (bool) -- 否导入空的数据集,默认是不导入的。默认为 False
- source_file_charset (Charset or str) -- dbf 文件的原始字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
>>> result = import_dbf( 'E:/point.dbf', 'E:/import_dbf_out.udb') >>> print(len(result) == 1) >>> print(result[0])
-
iobjectspy.conversion.import_csv(source_file, output, out_dataset_name=None, import_mode=None, separator=', ', head_is_field=True, fields_as_point=None, field_as_geometry=None, is_import_empty=False, source_file_charset=None, progress=None)¶ 导入 CSV 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 csv 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式类型,可以为 ImportMode 枚举值或名称
- separator (str) -- 源 CSV 文件中字段的分隔符。默认以 ',' 作为分隔符
- head_is_field (bool) -- CSV 文件的首行是否为字段名称
- fields_as_point (list[str] or list[int]) -- 指定字段为X、Y或者X、Y、Z坐标,如果符合条件,则生成点或者三维点数据集
- field_as_geometry (int) -- 指定WKT串的Geometry索引位置
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False,即不导入
- source_file_charset (Charset or str) -- CSV 文件的原始字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_mapgis(source_file, output, out_dataset_name=None, import_mode=None, is_import_as_cad=True, color_index_file_path=None, import_network_topology=False, source_file_charset=None, progress=None)¶ 导入 MapGIS 文件,Linux 平台不支持导入 MapGIS 文件。
参数: - source_file (str) -- 被导入的 MAPGIS 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- color_index_file_path (str) -- MAPGIS 导入数据时的颜色索引表文件路径,默认文件路径为系统路径下的 MapGISColor.wat
- import_network_topology (bool) -- 导入时是否导入网络数据集
- source_file_charset (Charset or str) -- MAPGIS 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_aibingrid(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 AIBinGrid 文件, Linux 平台不支持导入 AIBinGrid 文件。
参数: - source_file (str) -- 被导入的 AIBinGrid 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_bmp(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, world_file_path=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 BMP 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 BMP 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- BMP 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- world_file_path (str) -- 导入的源影像文件的坐标参考文件路径
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_dgn(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=True, style_map_file=None, is_import_by_layer=False, is_cell_as_point=False, progress=None)¶ 导入 DGN 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 dgn 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_empty (bool) -- 是否导入空数据集,默认为 False
- is_import_as_cad (bool) -- 是否导入为 CAD 数据集,默认为 True
- style_map_file (str) -- 设置风格对照表的存储路径。 风格对照表是指 SuperMap 系统与其它系统风格(包括:符号、线型、填充等)的对照文件。风格对照表只对 CAD 类型的数据,如 DXF、DWG、DGN 起作用。在设置风格对照表之前,必须保证数据是以CAD方式导入,且不忽略风格。
- is_import_by_layer (bool) -- 是否在导入后的数据中合并源数据中的 CAD 图层信息,CAD 是以图层信息来存储的,默认为 False,即所有 的图层信息都合并到了一个 CAD 数据集, 否则对应源数据中的每一个图层生成一个 CAD 数据集。
- is_cell_as_point (bool) -- 是否将 cell(单元)对象导入为点对象(cell header)还是除 cell header 外的所有要素对象。 默认导入为除 cell header 外的所有要素对象。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_dwg(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=True, is_import_by_layer=False, ignore_block_attrs=True, block_as_point=False, import_external_data=False, import_xrecord=True, import_invisible_layer=False, keep_parametric_part=False, ignore_lwpline_width=False, shx_paths=None, curve_segment=73, style_map_file=None, progress=None)¶ 导入 DWG 文件,Linux 平台不支持导入 DWG 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 dwg 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False,即不导入
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- is_import_by_layer (bool) -- 是否在导入后的数据中合并源数据中的 CAD 图层信息,CAD 是以图层信息来存储的,默认为 False,即所有的图层信息都合并到了一个 CAD 数据集, 否则对应源数据中的每一个图层生成一个 CAD 数据集。
- ignore_block_attrs (bool) -- 是否数据导入时是否忽略块儿属性。默认为 True
- block_as_point (bool) -- 将符号块导入为点对象还是复合对象,默认为 False, 即将原有的符号块作为复合对象导入,否则在符号块的位置用点对象代替。
- import_external_data (bool) -- 否导入外部数据,外部数据为 CAD 中类似属性表的数据导入后格式为一些额外的字段,默认为 False,否则将外部数据追加在默认字段后面。
- import_xrecord (bool) -- 是否将用户自定义的字段以及属性字段作为扩展记录导入。
- import_invisible_layer (bool) -- 是否导入不可见图层
- keep_parametric_part (bool) -- 是否保留Acad数据中的参数化部分
- ignore_lwpline_width (bool) -- 是否忽略多义线宽度,默认为 False。
- shx_paths (list[str]) -- shx 字体库的路径
- curve_segment (int) -- 曲线拟合精度,默认为 73
- style_map_file (str) -- 风格对照表的存储路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_dxf(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=True, is_import_by_layer=False, ignore_block_attrs=True, block_as_point=False, import_external_data=False, import_xrecord=True, import_invisible_layer=False, keep_parametric_part=False, ignore_lwpline_width=False, shx_paths=None, curve_segment=73, style_map_file=None, progress=None)¶ 导入 DXF 文件,Linux 平台不支持导入 DXF 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 dxf 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False,即不导入
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- is_import_by_layer (bool) -- 是否在导入后的数据中合并源数据中的 CAD 图层信息,CAD 是以图层信息来存储的,默认为 False,即所有的图层信息都合并到了一个 CAD 数据集, 否则对应源数据中的每一个图层生成一个 CAD 数据集。
- ignore_block_attrs (bool) -- 是否数据导入时是否忽略块儿属性。默认为 True
- block_as_point (bool) -- 将符号块导入为点对象还是复合对象,默认为 False, 即将原有的符号块作为复合对象导入,否则在符号块的位置用点对象代替。
- import_external_data (bool) -- 否导入外部数据,外部数据为 CAD 中类似属性表的数据导入后格式为一些额外的字段,默认为 False,否则将外部数据追加在默认字段后面。
- import_xrecord (bool) -- 是否将用户自定义的字段以及属性字段作为扩展记录导入。
- import_invisible_layer (bool) -- 是否导入不可见图层
- keep_parametric_part (bool) -- 是否保留Acad数据中的参数化部分
- ignore_lwpline_width (bool) -- 是否忽略多义线宽度,默认为 False。
- shx_paths (list[str]) -- shx 字体库的路径
- curve_segment (int) -- 曲线拟合精度,默认为 73
- style_map_file (str) -- 风格对照表的存储路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_e00(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=True, source_file_charset=None, progress=None)¶ 导入 E00 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 E00 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_ignore_attrs (bool) -- 是否忽略属性信息
- source_file_charset (Charset or str) -- E00 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_ecw(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, progress=None)¶ 导入 ECW 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 ECW 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- ECW 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_geojson(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=False, source_file_charset=None, progress=None)¶ 导入 GeoJson 文件
参数: - source_file (str) -- 被导入的 GeoJson 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False
- is_import_as_cad (bool) -- 是否导入为 CAD 数据集
- source_file_charset (Charset or str) -- GeoJson 文件的原始字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_gif(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, world_file_path=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 GIF 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 GIF 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- GIF 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- world_file_path (str) -- 导入的源影像文件的坐标参考文件路径
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_grd(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 GRD 文件
参数: - source_file (str) -- 被导入的 GRD 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_img(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 Erdas Image 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 IMG 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- Erdas Image 的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_jp2(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_import_as_grid=False, progress=None)¶ 导入 JP2 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 JP2 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_jpg(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, world_file_path=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 JPG 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 JPG 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- world_file_path (str) -- 导入的源影像文件的坐标参考文件路径
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_kml(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=False, is_ignore_invisible_object=True, source_file_charset=None, progress=None)¶ 导入 KML 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 KML 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- is_import_empty (bool) -- 是否导入空的数据集
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- is_ignore_invisible_object (bool) -- 是否忽略不可见对象
- source_file_charset (Charset or str) -- KML 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_kmz(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_import_as_cad=False, is_ignore_invisible_object=True, source_file_charset=None, progress=None)¶ 导入 KMZ 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 KMZ 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_empty (bool) -- 是否导入空的数据集
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- is_ignore_invisible_object (bool) -- 是否忽略不可见对象
- source_file_charset (Charset or str) -- KMZ 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_mif(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=True, is_import_as_cad=False, style_map_file=None, source_file_charset=None, progress=None)¶ 导入 MIF 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 mif 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_ignore_attrs (bool) -- 导入 MIF 格式数据时是否忽略该数据的属性,包括矢量数据的属性信息。
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- source_file_charset (Charset or str) -- mif 文件的原始字符集
- style_map_file (str) -- 风格对照表的存储路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_mrsid(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, progress=None)¶ 导入 MrSID 文件, Linux 平台不支持导入 MrSID 文件。
参数: - source_file (str) -- 被导入的 MrSID 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- MrSID 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_osm(source_file, output, out_dataset_name=None, import_mode=None, source_file_charset=None, progress=None)¶ 导入 OSM 矢量数据, Linux 平台不支持 OSM 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 OSM 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- source_file_charset (Charset or str) -- OSM 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_png(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, world_file_path=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 Portal Network Graphic (PNG) 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 PNG 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- PNG 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- world_file_path (str) -- 导入的源影像文件的坐标参考文件路径
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_simplejson(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, source_file_charset=None, progress=None)¶ 导入 SimpleJson 文件
参数: - source_file (str) -- 被导入的 SimpleJson 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_empty (bool) -- 是否导入空数据集
- source_file_charset (Charset or str) -- SimpleJson 文件的原始字符集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_sit(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, password=None, progress=None)¶ 导入 SIT 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 SIT 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- SIT 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- password (str) -- 密码
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_tab(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=True, is_import_empty=False, is_import_as_cad=False, style_map_file=None, source_file_charset=None, progress=None)¶ 导入 TAB 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 TAB 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_ignore_attrs (bool) -- 导入 TAB 格式数据时是否忽略该数据的属性,包括矢量数据的属性信息。
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False,即不导入
- is_import_as_cad (bool) -- 是否以 CAD 数据集方式导入
- source_file_charset (Charset or str) -- mif 文件的原始字符集
- style_map_file (str) -- 风格对照表的存储路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_tif(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, world_file_path=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 TIF 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 TIF 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- Tiff/BigTIFF/GeoTIFF 文件的忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- world_file_path (str) -- 导入的源影像文件的坐标参考文件路径
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[DatasetImage] or list[str]
-
iobjectspy.conversion.import_usgsdem(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 USGSDEM 文件。
参数: - source_file (str) -- 被导入的 USGS DEM 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_vct(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, source_file_charset=None, layers=None, progress=None)¶ 导入 VCT 文件。支持导入文件目录。
参数: - source_file (str) -- 被导入的 VCT 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 数据集导入模式
- is_import_empty (bool) -- 是否导入空数据集
- source_file_charset (Charset or str) -- VCT 文件的原始字符集
- layers (str or list[str]) -- 需要导入的图层名称,设置为 None 时将全部导入。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_bil(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 BIL 文件。
参数: - source_file (str) -- 被导入的 BIL 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_bip(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 BIP 文件。
参数: - source_file (str) -- 被导入的 BIP 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_orange_tab(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=False, fields_as_point=None, progress=None)¶ 导入 Orange tab 文件。只支持 Windows.
参数: - source_file (str) -- 被导入的 Orange tab 文件。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_ignore_attrs (bool) -- 是否忽略属性信息
- fields_as_point (list[str] or str) -- 指定字段为 X、Y 或者 X、Y、Z 坐标。如果符合条件,生成二维点或三维点数据集。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_bsq(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 BSQ 文件。
参数: - source_file (str) -- 被导入的 BSQ 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_gpkg(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=False, progress=None)¶ 导入 OGC Geopackage 矢量文件。只支持 Windows.
参数: - source_file (str) -- 被导入的 OGC Geopackage 矢量文件。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_ignore_attrs (bool) -- 是否忽略属性信息
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_gbdem(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 GBDEM 文件。
参数: - source_file (str) -- 被导入的 GBDEM 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_grib(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 GRIB 文件。
参数: - source_file (str) -- 被导入的 GRIB 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_egc(source_file, output, out_dataset_name=None, scale=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 EGC 文件。
参数: - source_file (str) -- 被导入的 EGC 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- scale (int) -- 比例尺,当数据的文件名称是按标准命名时,一般不用设置比例尺。否则,用户根据数据的比例尺设置。
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_raw(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, is_build_pyramid=True, progress=None)¶ 导入 RAW 文件。
参数: - source_file (str) -- 被导入的 RAW 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_vrt(source_file, output, out_dataset_name=None, ignore_mode='IGNORENONE', ignore_values=None, multi_band_mode=None, is_import_as_grid=False, is_build_pyramid=True, progress=None)¶ 导入 GDAL Virtual (VRT) 文件。
参数: - source_file (str) -- 被导入的 VRT 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- ignore_mode (IgnoreMode or str) -- 忽略颜色值的模式
- ignore_values (list[float] 要忽略的颜色值) -- 要忽略的颜色值
- multi_band_mode (MultiBandImportMode or str) -- 多波段导入模式,可以导入为多个单波段数据集、单个多波段数据集或单个单波段数据集。
- is_import_as_grid (bool) -- 是否导入为 Grid 数据集
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_lidar(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=False, is_import_as_3d=False, progress=None)¶ 导入激光雷达文件。只支持 Windows.
参数: - source_file (str) -- 被导入的激光雷达文件。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_ignore_attrs (bool) -- 是否忽略属性信息
- is_import_as_3d (bool) -- 是否导入为 3D 数据集
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_gjb(source_file, output, out_dataset_name=None, import_mode=None, layers=None, config_file=None, is_import_empty=False, progress=None)¶ 导入 GJB 文件。只支持 Windows.
参数: - source_file (str) -- 被导入的 GJB 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- layers (str or list[str]) -- 需要导入的图层名称,设置为 None 时将全部导入。
- config_file (str) -- 对照文本字体大小、颜色透明度的特定格式的配置文件路径
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_tems_clutter(source_file, output, out_dataset_name=None, is_build_pyramid=True, progress=None)¶ 导入电信行业影像数据(TEMSClutter) 文件。设置的文件地址必须指定为 .b 格式文件。
>>> import_tems_clutter('/home/data/TEMSClutter/demo.b', '/home/data/result.udb')
参数: - source_file (str) -- 被导入的 电信行业影像数据(TEMSClutter) 文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- is_build_pyramid (bool) -- 是否自动建立影像金字塔
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetGrid] or list[str]
-
iobjectspy.conversion.import_tems_vector(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, progress=None)¶ 导入电信矢量线数据。
参数: - source_file (str) -- 被导入的电信矢量地物标注。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_empty (bool) -- 是否导入空数据集。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_tems_building_vector(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, is_char_separator=False, progress=None)¶ 导入电信矢量面数据。
参数: - source_file (str) -- 被导入的电信矢量面数据。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_empty (bool) -- 是否导入空数据集。
- is_char_separator (bool) -- 是否按字符分割字段,默认为 False,按空格分割。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_file_gdb_vector(source_file, output, out_dataset_name=None, import_mode=None, is_ignore_attrs=False, is_import_empty=False, progress=None)¶ 导入 Esri Geodatabase 交换文件。只支持 Windows.
参数: - source_file (str) -- 被导入的 Esri Geodatabase 交换文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_ignore_attrs (bool) -- 是否忽略属性信息。
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_personal_gdb_vector(source_file, output, out_dataset_name=None, import_mode=None, is_import_3d_as_2d=False, is_import_empty=False, progress=None)¶ 导入 Esri Personal Geodatabase 矢量文件。只支持 Windows。如果导入失败,请确认是否安装 64 位 AccessDatabaseEngine。
参数: - source_file (str) -- 被导入的 Esri Personal Geodatabase 矢量文件
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_3d_as_2d (bool) -- 三维对象是否导入为二维对象。
- is_import_empty (bool) -- 是否导入空的数据集,默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.import_tems_text_labels(source_file, output, out_dataset_name=None, import_mode=None, is_import_empty=False, progress=None)¶ 导入电信矢量地物标注。
参数: - source_file (str) -- 被导入的电信矢量地物标注。
- output (Datasource or DatasourceConnectionInfo or str) -- 结果数据源
- out_dataset_name (str) -- 结果数据集名称
- import_mode (ImportMode or str) -- 导入模式
- is_import_empty (bool) -- 是否导入空数据集。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 导入后的结果数据集或结果数据集名称
返回类型: list[DatasetVector] or list[str]
-
iobjectspy.conversion.export_to_bmp(data, output, is_over_write=False, world_file_path=None, progress=None)¶ 导出数据集到 BMP 文件中
参数: - data (DatasetImage or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- world_file_path (str) -- 导出的影像数据的坐标文件路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_gif(data, output, is_over_write=False, world_file_path=None, progress=None)¶ 导出数据集到 GIF 文件中
参数: - data (DatasetImage or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- world_file_path (str) -- 导出的影像数据的坐标文件路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_grd(data, output, is_over_write=False, progress=None)¶ 导出数据集到 GRD 文件中
参数: - data (DatasetGrid or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_img(data, output, is_over_write=False, progress=None)¶ 导出数据集到 IMG 文件中
参数: - data (DatasetImage or DatasetGrid or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_jpg(data, output, is_over_write=False, world_file_path=None, compression=None, progress=None)¶ 导出数据集到 JPG 文件中
参数: - data (DatasetImage or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- world_file_path (str) -- 导出的影像数据的坐标文件路径
- compression (int) -- 影像文件的压缩率,单位:百分比
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_png(data, output, is_over_write=False, world_file_path=None, progress=None)¶ 导出数据集到 PNG 文件中
参数: - data (DatasetImage or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- world_file_path (str) -- 导出的影像数据的坐标文件路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_sit(data, output, is_over_write=False, password=None, progress=None)¶ 导出数据集到 SIT 文件中
参数: - data (DatasetImage or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- password (str) -- 密码
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_tif(data, output, is_over_write=False, export_as_tile=False, export_transform_file=True, progress=None)¶ 导出数据集到 TIF 文件中
参数: - data (DatasetImage or DatasetGrid or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- export_as_tile (bool) -- 是否以块的方式导出,默认为 False
- export_transform_file (bool) -- 是否将仿射转换信息导出外部文件,默认为 True,即导出到外部的 tfw 文件中,否则投影信息会导出到 tiff 文件中
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_csv(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, is_export_field_names=True, is_export_point_as_wkt=False, progress=None)¶ 导出数据集到 csv 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- is_export_field_names (bool) -- 是否写出字段名称。
- is_export_point_as_wkt (bool) -- 是否将点以 WKT 方式写出。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_dbf(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 dbf 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集,只支持导出属性表数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_dwg(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, cad_version=CADVersion.CAD2007, is_export_border=False, is_export_xrecord=False, is_export_external_data=False, style_map_file=None, progress=None)¶ 导出数据集到 DWG 文件中, Linux 平台不支持导出数据集为 DWG 文件。
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- cad_version (CADVersion or str) -- 导出的 DWG 文件的版本。
- is_export_border (bool) -- 导出cad面对像或矩形对象时是否导出边界。
- is_export_xrecord (bool) -- 是否将用户自定义的字段以及属性字段作为扩展记录导出
- is_export_external_data (bool) -- 是否导出扩展字段
- style_map_file (str) -- 风格对照表的路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_dxf(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, cad_version=CADVersion.CAD2007, is_export_border=False, is_export_xrecord=False, is_export_external_data=False, progress=None)¶ 导出数据集到 DXF 文件中,Linux 平台不支持导出数据集为 DXF 文件
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- cad_version (CADVersion or str) -- 导出的 DWG 文件的版本。
- is_export_border (bool) -- 导出cad面对像或矩形对象时是否导出边界。
- is_export_xrecord (bool) -- 是否将用户自定义的字段以及属性字段作为扩展记录导出
- is_export_external_data (bool) -- 是否导出扩展字段
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_e00(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, double_precision=False, progress=None)¶ 导出数据集到 E00 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- double_precision (bool) -- 是否以双精度方式导出 E00,默认为 False。
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_kml(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 KML 文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集集合
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_kmz(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 KMZ 文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集集合
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_geojson(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 GeoJson 文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集集合
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_mif(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 MIF 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_shape(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 Shape 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_simplejson(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 SimpleJson 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_tab(data, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, style_map_file=None, progress=None)¶ 导出数据集到 TAB 文件中
参数: - data (DatasetVector or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- style_map_file (str) -- 导出的风格对照表路径
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_vct(data, config_path, version, output, is_over_write=False, attr_filter=None, ignore_fields=None, target_file_charset=None, progress=None)¶ 导出数据集到 VCT 文件中
参数: - data (DatasetVector or str or list[DatasetVector] or str) -- 被导出的数据集集合
- config_path (str) -- VCT 配置文件路径
- version (VCTVersion or str) -- VCT 版本
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- attr_filter (str) -- 导出目标文件的过滤信息
- ignore_fields (list[str]) -- 需要忽略的字段
- target_file_charset (Charset or str) -- 需要导出的文件的字符集类型
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_egc(data, output, is_over_write=False, progress=None)¶ 导出数据集到 EGC 文件中
参数: - data (DatasetGrid or str) -- 被导出的数据集
- output (str) -- 结果文件路径,例如 'E:/data/J4901220.egc'
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_gjb(data, output, is_over_write=False, progress=None)¶ 导出数据集到 GJB 文件中
参数: - data (dict[GJBLayerType,DatasetVector] or dict[GJBLayerType, list[DatasetVector]]) --
被导出的数据集以及图层信息。GJB 文件有固定的图层,导出时需要指定图层类型以及导出的数据集。
GJBLayerType.GJB_S元数据图层只能设置一个属性表数据集导出位元数据GJBLayerType.GJB_R元数据图层只能设置多个文本数据集- 其他图层可以设置多个点线面数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
- data (dict[GJBLayerType,DatasetVector] or dict[GJBLayerType, list[DatasetVector]]) --
-
iobjectspy.conversion.export_to_tems_vector(data, output, is_over_write=False, progress=None)¶ 导出数据集到电信矢量线数据文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_tems_clutter(data, output, is_over_write=False, progress=None)¶ 导出数据集到电信行业影像文件中。
>>> export_to_tems_clutter('/home/data/image.udb/dem', '/home/data/TEMSClutter/dem')
参数: - data (DatasetGrid or str) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_tems_text_labels(data, output, label_field, is_over_write=False, progress=None)¶ 导出数据集到电信矢量地物标注文件中。
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集
- output (str) -- 结果文件路径
- label_field (str) -- 需要导出的文本字段名称
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_tems_building_vector(data, output, is_over_write=False, progress=None)¶ 导出数据集到电信矢量面数据文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_file_gdb_vector(data, output, is_over_write=False, progress=None)¶ 导出数据集到 ESRI GDB 交换格式文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
-
iobjectspy.conversion.export_to_personal_gdb_vector(data, output, is_over_write=False, progress=None)¶ 导出数据集到 ESRI Personal GDB 文件中
参数: - data (DatasetVector or str or list[DatasetVector] or list[str]) -- 被导出的数据集
- output (str) -- 结果文件路径
- is_over_write (bool) -- 导出目录中存在同名文件时,是否强制覆盖。默认为 False
- progress (function) -- 进度信息处理函数,请参考
StepEvent
返回: 是否导出成功
返回类型: bool
iobjectspy.data module¶
-
class
iobjectspy.data.DatasourceConnectionInfo(server=None, engine_type=None, alias=None, is_readonly=None, database=None, driver=None, user=None, password=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase数据源连接信息类。包括了进行数据源连接的所有信息,如所要连接的服务器名称,数据库名称、用户名、密码等。当保存工作空间时,工作空间中的数据源的 连接信息都将存储到工作空间文件中。对于不同类型的数据源,其连接信息有所区别。所以在使用该类所包含的成员时,请注意该成员所适用的数据源类型。
- 例如::
>>> conn_info = DatasourceConnectionInfo('E:/data.udb') >>> print(conn_info.server) 'E:\data.udb' >>> print(conn_info.type) EngineType.UDB
创建 OraclePlus 数据库连接信息:
>>> conn_info = (DatasourceConnectionInfo(). >>> set_type(EngineType.ORACLEPLUS). >>> set_server('server'). >>> set_database('database'). >>> set_alias('alias'). >>> set_user('user'). >>> set_password('password')) >>> print(conn_info.database) 'server'
构造数据源连接对象
参数: - server (str) --
数据库服务器名、文件名或服务地址:
- 对于 MEMORY, 为 ':memory:'
- 对于 UDB 文件,为其文件的绝对路径。注意:当绝对路径的长度超过 UTF-8 编码格式的260字节长度,该数据源无法打开。
- 对于 Oracle 数据库,其服务器名为其 TNS 服务名称;
- 对于 SQL Server 数据库,其服务器名为其系统的 DSN(Database Source Name)名称;
- 对于 PostgreSQL 数据库,其服务器名为"IP:端口号",默认的端口号是 5432;
- 对于 DB2 数据库,已经进行了编目,所以不需要进行服务器的设置;
- 对于 Kingbase 数据库,其服务器名为其 IP 地址;
- 对于 GoogleMaps 数据源,为其服务地址,默认设置为 "http://maps.google.com",且不可更改;
- 对于 SuperMapCloud 数据源,为其服务地址;
- 对于 MAPWORLD 数据源,为其服务地址,默认设置为 "http://www.tianditu.cn",且不可更改;
- 对于 OGC 和 REST 数据源,为其服务地址。
- 若用户设置为 IMAGEPLUGINS 时,将此方法的参数设置为地图缓存配置文件(SCI)名称,则用户可以实现对地图缓存的加载
- engine_type (EngineType or str) -- 数据源连接的引擎类型,可以使用 EngineType 枚举值和名称
- alias (str) -- 数据源别名。别名是数据源的唯一标识。该标识不区分大小写
- is_readonly (bool) -- 是否以只读方式打开数据源。如果以只读方式打开数据源,数据源的相关信息以及其中的数据都不可修改。
- database (str) -- 数据源连接的数据库名
- driver (str) --
数据源连接所需的驱动名称:
- 对于SQL Server 数据库,它使用 ODBC 连接,返回的驱动程序名为 SQL Server 或 SQL Native Client。
- 对于 iServer 发布的 WMTS 服务,返回的驱动名称为 WMTS。
- user (str) -- 登录数据库的用户名。对于数据库类型数据源适用。
- password (str) -- 登录数据源连接的数据库或文件的密码。对于 GoogleMaps 数据源,如果打开的是基于早期版本的数据源,则返回的密码为用户在 Google 官网注册后获取的密钥
-
alias¶ str -- 数据源别名,别名是数据源的唯一标识。该标识不区分大小写
-
database¶ str -- 数据源连接的数据库名
-
driver¶ str -- 数据源连接所需的驱动名称
-
from_dict(values)¶ 从 dict 对象中读取数据库数据源连接信息。读取后会覆盖当前对象中的值。
参数: values (dict) -- 包含数据源连接信息的 dict. 返回: self 返回类型: DatasourceConnectionInfo
-
static
from_json(value)¶ 从 json 字符串构造数据源连接信息对象。
参数: value (str) -- json 字符串 返回: 数据源连接信息对象 返回类型: DatasourceConnectionInfo
-
is_readonly¶ bool -- 是否以只读方式打开数据源
-
is_same(other)¶ 判断当前对象与指定的数据库连接信息对象是否是指向同一个数据源对象。 如果两个数据库连接信息指向同一个数据源,则必须:
- 数据库引擎类型 (type) 相同
- 数据库服务器名、文件名或服务地址 (server) 相同
- 数据库连接的数据库名称 (database) 相同如果需要设置。
- 数据库的用户名 (user) 相同,如果需要设置。
- 数据源连接的数据库或文件的密码 (password) 相同,如果需要设置。
- 是否以只读方式打开 (is_readonly) 相同,如果需要设置。
参数: other (DatasourceConnectionInfo) -- 需要比较的数据库连接信息对象。 返回: 返回 True 表示与指定的数据库连接信息是指向同一个数据源对象。否则为 False 返回类型: bool
-
static
load_from_dcf(file_path)¶ 从 dcf 文件中加载数据库连接信息,返回一个新的数据库连接信息对象。
参数: file_path (str) -- dcf 文件路径。 返回: 数据源连接信息对象 Type: DatasourceConnectionInfo
-
static
load_from_xml(xml)¶ 从指定的 xml 字符串中加载数据库连接信息,并返回一个新的数据库连接信息对象。
参数: xml (str) -- 导入的数据源的连接信息的 xml 字符串 返回: 数据源连接信息对象 Type: DatasourceConnectionInfo
-
static
make(value)¶ 构造数据库连接信息对象。
参数: value (str or DatasourceConnectionInfo or dict) -- 包含数据源连接信息的对象:
- 如果是 DatasourceConnectionInfo 对象,则直接返回对象。
- 如果是 dict, 参考 make_from_dict
- 如果是 str,可以是:
- ':memory:',返回内存数据源引擎的数据库连接信息
- udb 或 udd 文件, 返回UDB数据源引擎的数据库连接信息
- dcf 文件,参考 save_as_dcf
- xml 字符串,参考 to_xml
返回: 数据源连接信息对象 返回类型: DatasourceConnectionInfo
-
static
make_from_dict(values)¶ 从 dict 对象中构造数据源连接对象。返回一个新的数据库连接信息对象。
参数: values (dict) -- 包含数据源连接信息的 dict. 返回: 数据源连接信息对象 返回类型: DatasourceConnectionInfo
-
password¶ str -- 登录数据源连接的数据库或文件的密码
-
save_as_dcf(file_path)¶ 将当前数据集连接信息对象保存到 dcf 文件中。
参数: file_path (str) -- dcf 文件路径。 返回: 成功保存返回 True, 否则返回 False Type: bool
-
server¶ str -- 数据库服务器名、文件名或服务地址
-
set_alias(value)¶ 设置数据源别名
参数: value (str) -- 别名是数据源的唯一标识。该标识不区分大小写 返回: self 返回类型: DatasourceConnectionInfo
-
set_database(value)¶ 设置数据源连接的数据库名。对于数据库类型数据源适用
参数: value (str) -- 数据源连接的数据库名。 返回: self 返回类型: DatasourceConnectionInfo
-
set_driver(value)¶ 设置数据源连接所需的驱动名称。
参数: value (str) -- 数据源连接所需的驱动名称:
- 对于SQL Server 数据库,它使用 ODBC 连接,所设置的驱动程序名为 SQL Server 或 SQL Native Client。
- 对于 iServer 发布的 WMTS 服务,设置的驱动名称为 WMTS,并且该方法必须调用该方法设置其驱动名称。
返回: self 返回类型: DatasourceConnectionInfo
-
set_password(value)¶ 设置登录数据源连接的数据库或文件的密码
参数: value (str) -- 登录数据源连接的数据库或文件的密码。对于 GoogleMaps 数据源,如果打开的是基于早期版本的数据源,则需要输入密码,其密码为用户在 Google 官网注册后获取的密钥。 返回: self 返回类型: DatasourceConnectionInfo
-
set_readonly(value)¶ 设置是否以只读方式打开数据源。
参数: value (bool) -- 指定是否以只读方式打开数据源。对于 UDB 数据源,如果其文件属性为只读的,必须设置为只读时才能打开。 返回: self 返回类型: DatasourceConnectionInfo
-
set_server(value)¶ 设置数据库服务器名、文件名或服务地址
参数: value (str) -- 数据库服务器名、文件名或服务地址:
- 对于 MEMORY, 为 ':memory:'
- 对于 UDB 文件,为其文件的绝对路径。注意:当绝对路径的长度超过 UTF-8 编码格式的260字节长度,该数据源无法打开。
- 对于 Oracle 数据库,其服务器名为其 TNS 服务名称;
- 对于 SQL Server 数据库,其服务器名为其系统的 DSN(Database Source Name)名称;
- 对于 PostgreSQL 数据库,其服务器名为"IP:端口号",默认的端口号是 5432;
- 对于 DB2 数据库,已经进行了编目,所以不需要进行服务器的设置;
- 对于 Kingbase 数据库,其服务器名为其 IP 地址;
- 对于 GoogleMaps 数据源,为其服务地址,默认设置为"http://maps.google.com",且不可更改;
- 对于 SuperMapCloud 数据源,为其服务地址;
- 对于 MAPWORLD 数据源,为其服务地址,默认设置为"http://www.tianditu.cn",且不可更改;
- 对于 OGC 和 REST 数据源,为其服务地址。
- 若用户设置为 IMAGEPLUGINS 时,将此方法的参数设置为地图缓存配置文件(SCI)名称,则用户可以实现对地图缓存的加载
返回: self 返回类型: DatasourceConnectionInfo
-
set_type(value)¶ 设置数据源连接的引擎类型。
参数: value (EngineType or str) -- 数据源连接的引擎类型 返回: self 返回类型: DatasourceConnectionInfo
-
set_user(value)¶ 设置登录数据库的用户名。对于数据库类型数据源适用
参数: value (str) -- 登录数据库的用户名 返回: self 返回类型: DatasourceConnectionInfo
-
to_dict()¶ 将当前数据源连接信息输出为 dict 对象。
返回: 包含数据源连接信息的 dict 返回类型: dict - 示例::
>>> conn_info = (DatasourceConnectionInfo(). >>> set_type(EngineType.ORACLEPLUS). >>> set_server('oracle_server'). >>> set_database('database_name'). >>> set_alias('alias_name'). >>> set_user('user_name'). >>> set_password('password_123')) >>> >>> print(conn_info.to_dict()) {'type': 'ORACLEPLUS', 'alias': 'alias_name', 'server': 'oracle_server', 'user': 'user_name', 'is_readonly': False, 'password': 'password_123', 'database': 'database_name'}
-
to_json()¶ 输出为 json 格式字符串
返回: json 格式字符串 返回类型: str
-
to_xml()¶ 将当前数据集连接信息输出为 xml 字符串
返回: 由当前数据源连接信息对象转换而得到的 XML 字符串。 返回类型: str
-
type¶ EngineType -- 数据源类型
-
user¶ str -- 登录数据库的用户名
-
class
iobjectspy.data.Datasource¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase数据源定义了一致的数据访问接口和规范。数据源的物理存储既可以是文件方式,也可以是数据库方式。区别不同存储方式的主要依据是其所采用的数据引擎类型: 采用 UDB 引擎时,数据源以文件方式存储(.udb,.udd)——文件型数据源文件用.udb 文件存储空间数据,采用空间数据库引擎时,数据源存储在指定的 DBMS 中。每个数据源都存在于一个工作空间中,不同的数据源通过数据源别名进行区分。通过数据源对象,可以对数据集进行创建、删除、复制等操作。
使用 create_vector_dataset 快速创建矢量数据集:
>>> ds = Datasource.create('E:/data.udb') >>> location_dt = ds.create_vector_dataset('location', 'Point') >>> print(location_dt.name) location
追加数据到点数据集中:
>>> location_dt.append([Point2D(1,2), Point2D(2,3), Point2D(3,4)]) >>> print(location_dt.get_record_count()) 3
数据源可以直接写入几何对象,要素对象,点数据等:
>>> rect = location_dt.bounds >>> location_coverage = ds.write_spatial_data([rect], 'location_coverage') >>> print(location_coverage.get_record_count()) 1 >>> ds.delete_all() >>> ds.close()
-
alias¶ str -- 数据源的别名。别名用于在工作空间中唯一标识数据源,可以通过它访问数据源。数据源的别名在创建数据源或打开数据源时给定, 打开同一个数据源可以使用不同的别名。
-
change_password(old_password, new_password)¶ 修改已经打开的数据源的密码
参数: - old_password (str) -- 旧密码
- new_password (str) -- 新的密码
返回: 成功返回True,否则返回False
返回类型: bool
-
close()¶ 关闭当前数据源。
返回: 成功关闭返回 True,否则返回 False 返回类型: bool
-
connection_info¶ DatasourceConnectionInfo -- 数据源连接信息
-
contains(name)¶ 检查当前数据源中是否有指定名称的数据集
参数: name (str) -- 数据集名称 返回: 当前数据源含有指定名称的数据集返回 True,否则返回 False 返回类型: bool
-
copy_dataset(source, out_dataset_name=None, encode_type=None, progress=None)¶ 复制数据集。复制数据集之前必须保证当前数据源已经打开而且可写。复制数据集时,可通过 EncodeType 参数来对数据集的编码方式进行修改。 有关数据集存储的编码方式请参见 EncodeType 枚举类型。由于CAD数据集不支持任何编码,对 CAD 数据集进行复制操作时设置的 EncodeType 无效
参数: - source (Dataset or str) --
要复制的源数据集。可以为数据集对象,也可以是数据源别名和数据集名称的组合,数据源名称和数据集名称组合可以使用 "|","\","/"任意一种。 例如:
>>> source = 'ds_alias/point_dataset'
或者:
>>> source = 'ds_alias|point_dataset'
- out_dataset_name (str) -- 目标数据集的名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
- encode_type (EncodeType or str) -- 数据集的编码方式。可以为
EncodeType枚举值或名称。 - progress (function) -- 处理进度信息的函数,具体参考
StepEvent。
返回: 复制成功返回结果数据集对象,否则返回 None
返回类型: - source (Dataset or str) --
-
static
create(conn_info)¶ 根据指定的数据源连接信息,创建新的数据源。
参数: conn_info (str or dict or DatasourceConnectionInfo) -- 数据源连接信息,具体可以参考 DatasourceConnectionInfo.make()返回: 数据源对象 返回类型: Datasource
-
create_dataset(dataset_info, adjust_name=False)¶ 创建数据集。根据指定的数据集信息创建数据集,如果数据集名称不合法或者已经存在,创建数据集会失败,用户可以设定 adjust_name 为 True 自动 获取一个合法的数据集名称。
参数: - dataset_info (DatasetVectorInfo or DatasetImageInfo or DatasetGridInfo) -- 数据集信息
- adjust_name (bool) -- 当数据集名称不合法时,是否自动调整数据集名称,使用一个合法的数据集名称。默认为 False。
返回: 创建成功则返回结果数据集对象,否则返回None
返回类型:
-
create_dataset_from_template(template, name, adjust_name=False)¶ 根据指定的模板数据集,创建新的数据集对象。
参数: - template (Dataset) -- 模板数据集
- name (str) -- 数据集名称
- adjust_name (bool) -- 当数据集名称不合法时,是否自动调整数据集名称,使用一个合法的数据集名称。默认为 False。
返回: 创建成功则返回结果数据集对象,否则返回None
返回类型:
-
create_mosaic_dataset(name, prj_coordsys=None, adjust_name=False)¶ 根据数据集名称和投影信息,创建镶嵌数据集对象。
参数: - name (str) -- 数据集名称
- prj_coordsys (int or str or PrjCoordSys or PrjCoordSysType) -- 指定镶嵌数据集的投影信息。支持 epsg 编码,PrjCoordSys 对象,PrjCoordSysType 类型,xml 或 wkt或投影信息文件。 注意,如果传入整型值,必须是 epsg 编码,不能是 PrjCoordSysType 类型的整型值。
- adjust_name (bool) -- 数据集名称不合法时,是否自动调整数据集名称,使用一个合法的数据集名称。默认为 False。
返回: 创建成功则返回结果数据集对象,否则返回None
返回类型:
-
create_vector_dataset(name, dataset_type, adjust_name=False)¶ 根据数据集名称和类型,创建矢量数据集对象。
参数: - name (str) -- 数据集名称
- dataset_type (DatasetType or str) -- 数据集类型,可以为数据集类型枚举值或名称。支持 TABULAR, POINT, LINE, REGION, TEXT, CAD, POINT3D, LINE3D, REGION3D
- adjust_name (bool) -- 当数据集名称不合法时,是否自动调整数据集名称,使用一个合法的数据集名称。默认为 False。
返回: 创建成功则返回结果数据集对象,否则返回None
返回类型:
-
datasets¶ list[Dataset] -- 当前数据源中所有的数据集对象
-
delete(item)¶ 删除指定的数据集,可以为数据集名称或序号
参数: item (str or int) -- 要删除的数据集的名称或序号 返回: 删除数据集成功返回True,否则返回False 返回类型: bool
-
delete_all()¶ 删除当前数据源下所有的数据集
-
description¶ str -- 返回用户添加的关于数据源的描述信息
-
field_to_point_dataset(source_dataset, x_field, y_field, out_dataset_name=None)¶ 从一个矢量数据集的属性表中的 X、Y 坐标字段创建点数据集。即以该矢量数据集的属性表中的 X 、Y 坐标字段作为数据集的 X、Y 坐标来创建点数据集。
参数: - source_dataset (DatasetVector or str) -- 关联属性表中带有坐标字段的矢量数据集
- x_field (str) -- 表示点横坐标的字段。
- y_field (str) -- 表示点纵坐标的字段。
- out_dataset_name (str) -- 目标数据集的名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
返回: 成功返回一个点数据集,否则返回None
返回类型:
-
flush(dataset_name=None)¶ 将内存中暂未写入数据库中的数据保存到数据库
参数: dataset_name (str) -- 需要刷新的数据集名称。当传入长度为空的字符串或None,表示对所有数据集进行刷新;否则对指定名字的数据集进行刷新。 返回: 成功返回True,否则返回False 返回类型: bool
-
static
from_json(value)¶ 从 json 格式字符串打开数据源。json 串格式为 DatasourceConnectionInfo 的 json 字符串格式。具体参
DatasourceConnectionInfo.to_json()和to_json()参数: value (str) -- json 字符串格式 返回: 数据源对象 返回类型: Datasource
-
get_available_dataset_name(name)¶ 返回一个数据源中未被使用的数据集的名称。数据集的名称限制:数据集名称的长度限制为30个字符(也就是可以为30个英文字母或者15个汉字), 组成数据集名称的字符可以为字母、汉字、数字和下划线,数据集名称不可以用数字和下划线开头,数据集名称不可以和数据库的保留关键字冲突。
参数: name (str) -- 数据集名称 返回: 合法的数据集名称 返回类型: str
-
get_count()¶ 获取数据集的个数
返回类型: int
-
index_of(name)¶ 返回给定数据集名称对应的数据集在数据集集合中所处的索引值
参数: name (str) -- 数据集名称 返回类型: int
-
inner_point_to_dataset(source_dataset, out_dataset_name=None)¶ 创建矢量数据集的内点数据集,并把矢量数据集中几何对象的属性复制到相应的点数据集属性表中
参数: - source_dataset (DatasetVector or str) -- 要计算内点数据集的矢量数据集
- out_dataset_name (str) -- 目标数据集的名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
返回: 创建成功返回内点数据集。创建失败返回 None
返回类型:
-
is_available_dataset_name(name)¶ 判断用户传进来的数据集的名称是否合法。创建数据集时应检查其名称的合法性。
参数: name (str) -- 待检查的数据集名称 返回: 如果数据集名称合法,返回 True,否则返回 False 返回类型: bool
-
is_opened()¶ 返回数据源是否打开的状态,如果数据源处于打开状态,返回 true,如果数据源被关闭,则返回 false。
返回: 数据源是否打开的状态 返回类型: bool
-
is_readonly()¶ 返回数据源是否以只读方式打开。对文件型数据源,如果只读方式打开,就是共享的,可以打开多次;如果以非只读方式打开,则只能打开一次。 对于影像数据源(IMAGEPLUGINS 引擎类型)只会以只读方式打开。
返回: 数据源是否以只读方式打开 返回类型: bool
-
label_to_text_dataset(source_dataset, text_field, text_style=None, out_dataset_name=None)¶ 用于将数据集的属性字段生成一个文本数据集。通过此方法生成的文本数据集中的文本对象,均以其对应的空间对象的内点作为对应的锚点, 对应的空间对象即当前文本对象的内容来源于相应空间对象的属性值。
参数: - source_dataset (DatasetVector or str) -- 要计算内点数据集的矢量数据集
- text_field (str) -- 要转换的属性字段的名称。
- text_style (TextStyle) -- 结果文本对象的风格
- out_dataset_name (str) -- 目标数据集的名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
返回: 成功返回一个文本数据集,否则返回None
返回类型:
-
last_date_updated()¶ 获取数据源最后更新的时间
返回类型: datetime.datetime
-
static
open(conn_info)¶ 根据数据源连接信息打开数据源。如果设置的连接信息是UDB类型数据源。则会直接返回。不支持直接打开内存数据源,要使用内存数据源,需要使用
create()。参数: conn_info (str or dict or DatasourceConnectionInfo) -- 数据源连接信息,具体可以参考 DatasourceConnectionInfo.make()返回: 数据源对象 返回类型: Datasource
-
prj_coordsys¶ PrjCoordSys -- 获取数据源的投影信息
-
refresh()¶ 对数据库类型的数据源进行刷新
-
set_description(description)¶ 设置用户添加的关于数据源的描述信息。用户可以在描述信息里加入你想加入的任何信息,例如建立数据源的人员、数据的来源、数据的主要内容、 数据的精度、质量等信息,这些信息对于维护数据具有重要的意义
参数: description (str) -- 用户添加的关于数据源的描述信息
-
set_prj_coordsys(prj)¶ 设置数据源的投影信息
参数: prj (PrjCoordSys) -- 投影信息
-
to_json()¶ 将数据源返回为 json 格式字符串。具体返回数据源连接信息的 json 字符串,即使用
DatasourceConnectionInfo.to_json。返回类型: str
-
type¶ EngineType -- 数据源引擎类型
-
workspace¶ Workspace -- 当前数据源所属的工作空间对象
-
write_attr_values(data, out_dataset_name=None)¶ 写入属性数据到属性数据集(DatasetType.TABULAR)中。
参数: - data (list or tuple) --
待写入的数据。data 必须为一个 list 或者 tuple 或者 set, list(或tuple) 中每个元素项,可以为 list or tuple, 此时 data 相当于一个二维的数组,例如:
>>> data = [[1,2.0,'a1'], [2,3.0,'a2'], [3,4.0,'a3']]
或者:
>>> data = [(1,2.0,'a1'), (2,3.0,'a2'), (3,4.0,'a3')]
data 中元素项如果不是 list 和 tuple,将会被当作一个元素对待。例如:
>>> data = [1,2,3]
或:
>>> data = ['test1','test2','test3']
则最后结果数据集将会含有1列3行的数据集。而对于data中的元素项为 dict 这种,则会将每个 dict 对象作为一个字符串写入:
>>> data = [{1:'a'}, {2:'b'}, {3:'c'}]
等价于写入了:
>>> data = ["{1: 'a'}", "{2: 'b'}", "{3: 'c'}"]
另外,用户需要确保list中每个元素项结构相同。程序内部会自动采样最多20条记录,根据采样的字段值类型计算合理的字段类型,具体对应为:
- int: FieldType.INT64
- str: FieldType.WTEXT
- float: FieldType.DOUBLE
- bool: FieldType.BOOLEAN
- datetime.datetime: FieldType.DATETIME
- bytes: FieldType.LONGBINARY
- bytearray: FieldType.LONGBINARY
- 其他: FieldType.WTEXT
- out_dataset_name (str) -- 结果数据集名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
返回: 写入数据成功返回 DatasetVector,否则返回 None
返回类型: - data (list or tuple) --
-
write_features(data, out_dataset_name=None)¶ 将要素对象写入到数据集中。
参数: 返回: 写入成功返回结果数据集对象,否则返回 None
返回类型:
-
write_recordset(source, out_dataset_name=None)¶ 将一个记录集对象或数据集对象写到当前数据源中。
参数: - source -- 待写入的记录集或数据集对象
- out_dataset_name (str) -- 结果数据集名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
返回: 写入数据成功返回 DatasetVector,否则返回 None
返回类型:
-
write_spatial_data(data, out_dataset_name=None, values=None)¶ 将空间数据(Point2D, Point3D, Rectangle, Geometry) 等写入到矢量数据集中。
参数: - data (list o tuple) -- 待写入的数据。data 必须为一个 list 或者 tuple 或者 set, list(或tuple) 中每个元素项,可以为 Point2D, Point, GeoPoint, GeoLine, GeoRegion, Rectangle: - 如果 data 中所有的元素都是 Point2D 或 GeoPoint,则会创建一个点数据集 - 如果 data 中所有的元素都是 Point3D 或 GeoPoint3D,则会创建一个三维点数据集 - 如果 data 中所有的元素都是 GeoLine,则会创建一个线数据集 - 如果 data 中所有的元素都是 Rectangle 或 GeoRegion,则会创建一个面数据集 - 否则,将会创建一个 CAD 数据集。
- out_dataset_name (str) -- 结果数据集名称。当名称为空或者不合法时,会自动获取到一个合法的数据集名称
- values --
空间数据要写到数据集中的属性字段值。如果不为 None,必须为 list 或 tuple,且长度必须与 data 长度相同。 values 中每个元素项可以为 list 或 tuple,此时 values 相当于一个二维的数组,例如:
>>> values = [[1,2.0,'a1'], [2,3.0,'a2'], [3,4.0,'a3']]
或者
>>> values = [(1,2.0,'a1'), (2,3.0,'a2'), (3,4.0,'a3')]
values 中元素项如果不是 list 和 tuple,将会被当作一个元素对待。例如:
>>> values = [1,2,3]
或:
>>> values = ['test1','test2','test3']
则最后结果数据集将会含有1列3行的数据集。而对于data中的元素项为 dict 这种,则会将每个 dict 对象作为一个字符串写入:
>>> data = [{1:'a'}, {2:'b'}, {3:'c'}]
等价于写入了:
>>> values = ["{1: 'a'}", "{2: 'b'}", "{3: 'c'}"]
另外,用户需要确保list中每个元素项结构相同。程序内部会自动采样最多20条记录,根据采样的字段值类型计算合理的字段类型,具体对应为:
- int: FieldType.INT64
- str: FieldType.WTEXT
- float: FieldType.DOUBLE
- bool: FieldType.BOOLEAN
- datetime.datetime: FieldType.DATETIME
- bytes: FieldType.LONGBINARY
- bytearray: FieldType.LONGBINARY
- 其他: FieldType.WTEXT
返回: 写入数据成功返回 DatasetVector,否则返回 None
返回类型:
-
-
class
iobjectspy.data.Dataset¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase数据集(矢量数据集,栅格数据集,影像数据集等)的基类,提供各种数据集数据集公共的属性,方法。 数据集一般为存储在一起的相关数据的集合;根据数据类型的不同,分为矢量数据集和栅格数据集,以及为了处理特定问题而设计的如拓扑数据集,网络数据集 等。数据集是 GIS 数据组织的最小单位。其中矢量数据集是由同种类型空间要素组成的集合,所以也可以称为要素集。根据要素的空间特征的不同,矢量数据集 又分为点数据集,线数据集,面数据集等,各矢量数据集是空间特征和性质相同而组织在一起的数据的集合。而栅格数据集由像元阵列组成,在表现要素上比矢量 数据集欠缺,但是可以很好的表现空间现象的位置关系。
-
bounds¶ Rectangle -- 返回数据集中包含所有对象的最小外接矩形。对于矢量数据集来说,为数据集中所有对象的最小外接矩形;对于栅格数据集来说,为当前栅格或影像的 地理范围。
-
close()¶ 用于关闭当前数据集
-
datasource¶ Datasource -- 返回当前数据集所属的数据源对象
-
description¶ str -- 返回用户加入的对数据集的描述信息。
-
encode_type¶ EncodeType -- 返回此数据集数据存储时的编码方式。对数据集采用压缩编码方式,可以减少数据存储所占用的空间,降低数据传输时的网络负载和服务器的负载。矢量数 据集支持的编码方式有Byte,Int16,Int24,Int32,SGL,LZW,DCT,也可以指定为不使用编码方式。光栅数据支持的编码方式有DCT,SGL,LZW 或不使用编码方式。具体请参见
EncodeType类型
-
static
from_json(value)¶ 从数据集的 json 字符串中获取数据集,如果数据源没有打开,将自动打开数据源。
参数: value (str) -- json 字符串 返回: 数据集对象 返回类型: Dataet
-
is_open()¶ 判断数据集是否已经打开,数据集打开返回 True,否则返回 False
返回类型: bool
-
is_readonly()¶ 判断数据集是否是只读。如果数据集是只读,无法进行任何改写数据集的操作。 数据集是只读返回 True,否则返回 False。
返回类型: bool
-
name¶ str -- 返回数据集名称
-
open()¶ 打开数据集, 打开数据集成功返返回 True,否则返回 False
返回类型: bool
-
prj_coordsys¶ PrjCoordSys -- 返回数据集的投影信息.
-
rename(new_name)¶ 修改数据集名称
参数: new_name (str) -- 新的数据集名称 返回: 修改成功返回True,否则返回False 返回类型: bool
-
set_bounds(rc)¶ 设置数据集中包含所有对象的最小外接矩形。对于矢量数据集来说,为数据集中所有对象的最小外接矩形;对于栅格数据集来说,为 当前栅格或影像的地理范围。
参数: rc (Rectangle) -- 数据集中包含所有对象的最小外接矩形。 返回: self 返回类型: Dataset
-
set_description(value)¶ 设置用户加入的对数据集的描述信息。
参数: value (str) -- 用户加入的对数据集的描述信息。
-
set_prj_coordsys(value)¶ 设置数据集的投影信息
参数: value (PrjCoordSys) -- 投影信息
-
table_name¶ str -- 返回数据集的表名。对数据库型数据源,返回此数据集在数据库中所对应的数据表名称;对文件型数据源,返回此数据集的存储属性的表名称.
-
to_json()¶ 输出数据集的信息到 json 字符串中。数据集的 json 串内容包括数据源的连接信息和数据集名称两项。
返回类型: str - 示例::
>>> ds = Workspace().get_datasource('data') >>> print(ds[0].to_json()) {"name": "location", "datasource": {"type": "UDB", "alias": "data", "server": "E:/data.udb", "is_readonly": false}}
-
type¶ DatasetType -- 返回数据集类型
-
-
class
iobjectspy.data.DatasetVector¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset矢量数据集类。用于对矢量数据集进行描述,并对之进行相应的管理和操作。对矢量数据集的操作主要包括数据查询、修改、删除、建立索引等。
-
append(data, fields=None)¶ 往当前数据集中追加记录。写入的数据可以:
Recordset 或 Recordset 的列表。需要确保被写入的 Recordset 的数据集类型与当前数据集类型相同,属性表结构与当前数据集的属性表结构相同,否则,可能会导致属性数据写入失败
DatasetVector 或 DatasetVector 的列表。需要确保被写入的 DatasetVector 的数据集类型与当前数据集类型相同,属性表结构与当前数据集的属性表结构相同,否则,可能会导致属性数据写入失败
Point2D or Point2D 的列表。写入数据为 Point2D 时不支持设置 fields。当前数据集必须为点数据集或 CAD 数据集。
Rectangle or Rectangle 的列表。写入数据为 Rectangle 时不支持设置 fields。当前数据集必须为面数据集或 CAD 数据集。
Geometry or Geometry 的列表。写入数据为 Geometry 时不支持设置 fields。当 Geometry 类型为:
- 点,当前数据集必须为点数据集或 CAD 数据集。
- 线,当前数据集必须为线数据集或 CAD 数据集
- 面,当前数据集必须为面数据集或 CAD 数据集
- 文本,当前数据集必须为文本数据集或 CAD 数据集
Feature 或 Feature 的列表。当设置了 fields 时必须确保 fields 中 Feature 的字段类型与数据集的字段是匹配的,否则可能导致写入属性丢 失。当 fields 为空时,必须确保 Feature 中字段与当前数据集的属性字段完全匹配。当 Feature 含有空间对象时,空间对象的类型为:
- 点,当前数据集必须为点数据集或 CAD 数据集。
- 线,当前数据集必须为线数据集或 CAD 数据集
- 面,当前数据集必须为面数据集或 CAD 数据集
- 文本,当前数据集必须为文本数据集或 CAD 数据集
参数: 返回: 写入数据成功返回 True,否则返回 False
返回类型: bool
-
append_fields(source, source_link_field, target_link_field, source_fields, target_fields=None)¶ 从源数据集向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。
注意:
- 如果指定的源数据集中被追加到目标数据集的字段名集合的某字段在源数据集中不存在,则忽略此字段,只追加源数据集中存在的字段;
- 如果指定了追加字段在目标数据集中相对应的字段名集合,则按所指定的字段名在目标数据集中创建所追加的字段;当指定的字段名在目标数据集中已存在时,则自动加_x(1、2、3...)进行字段的创建;
- 如果在目标数据集中创建字段失败,则忽略此字段,继续追加其它字段;
- 必须指定源字段名集合,否则追加不成功;
- 可以不必指定目标字段名集合,一旦指定目标字段名集合,则此集合中字段名必须与源字段名集合中的字段名一一对应。
参数: - source (DatasetVector or str) -- 源数据集
- source_link_field (str) -- 源数据集中的与目标数据集的关联字段。
- target_link_field (str) -- 目标数据集中的与源数据集的关联字段。
- source_fields (list[str] or str) -- 源数据集中被追加到目标数据集的字段名集合。
- target_fields (list[str] or str) -- 追加字段在目标数据集中相对应的字段名集合。
返回: 一个布尔值,表示追加字段是否成功,成功返回 true,否则返回 false。
返回类型: bool
-
build_field_index(field_names, index_name)¶ 为数据集的非空间字段创建索引
参数: - field_names (list[str] or str) -- 非空间字段名称
- index_name (str) -- 索引名称
返回: 创建成功返回 true,否则返回 false
返回类型: bool
-
build_spatial_index(spatial_index_info)¶ 根据指定的空间索引信息或索引类型为矢量数据集创建空间索引。 注意:
- 数据库中的点数据集不支持四叉树(QTree)索引和 R 树索引(RTree);
- 网络数据集不支持任何类型的空间索引;
- 属性数据集不支持任何类型的空间索引;
- 路由数据集不支持图幅索引(TILE);
- 复合数据集不支持多级网格索引;
- 数据库记录要大于1000条时才可以创建索引。
参数: spatial_index_info (SpatialIndexInfo or SpatialIndexType) -- 空间索引信息,或者空间索引类型,当为空间索引类型时,可以为枚举值或名称 返回: 创建索引成功返回 True,否则返回 False。 返回类型: bool
-
charset¶ Charset -- 矢量数据集的字符集
-
child_dataset¶ DatasetVector -- 矢量数据集的子数据集。主要用于网络数据集
-
create_field(field_info)¶ 创建字段
参数: field_info (FieldInfo) -- 字段信息,如果字段的类型是必填字段,必须设置默认值,没有设置默认值时,添加失败。 返回类型: bool 返回: 创建字段成功返回 True,否则返回 False
-
create_fields(field_infos)¶ 创建多个字段
参数: field_infos (list[FieldInfo]) -- 字段信息集合 返回: 创建字段成功返回 True,否则返回 False 返回类型: bool
-
delete_records(ids)¶ 通过 ID 数组删除数据集中的记录。
参数: ids (list[int]) -- 待删除记录的 ID 数组 返回: 删除成功返回 True,否则返回 False 返回类型: bool
-
drop_field_index(index_name)¶ 根据索引名指定字段,删除该字段的索引
参数: index_name (str) -- 字段索引名称 返回: 删除成功返回 True,否则返回 False 返回类型: bool
-
drop_spatial_index()¶ 删除空间索引,删除成功返回 True,否则返回 False
返回类型: bool
-
field_infos¶ list[FieldInfo] -- 数据集的所有字段信息
-
get_available_field_name(name)¶ 根据传入参数生成一个合法的字段名。
参数: name (str) -- 字段名称 返回类型: str
-
get_features(attr_filter=None, has_geometry=True, fields=None)¶ 根据指定的属性过滤条件获取要素对象
参数: - attr_filter (str) -- 属性过滤条件,默认为 None,即返回当前数据集的所有要素对象
- has_geometry (bool) -- 是否获取几何对象,为 False 时将只返回字段值
- fields (list[str] or str) -- 结果字段名称
返回: 满足指定条件的所有要素对象
返回类型: list[Feature]
-
get_field_count()¶ 返回数据集所有的字段的数目
返回类型: int
-
get_field_indexes()¶ 返回当前数据集属性表建的索引与建索引的字段的关系映射对象。其中键值为索引值,映射值为索引所在字段。
返回类型: dict
-
get_field_name_by_sign(field_sign)¶ 根据字段标识获取字段名。
参数: field_sign (FieldSign or str) -- 字段标识类型 返回: 字段类型 返回类型: str
-
get_field_values(fields)¶ 获取指定字段的字段值
参数: fields (str or list[str]) -- 字段名称列表 返回: 获取得到的字段值,每个字段名称对应一个列表 返回类型: dist[str,list]
-
get_geometries(attr_filter=None)¶ 根据指定的属性过滤条件获取几何对象
参数: attr_filter (str) -- 属性过滤条件,默认为 None,即返回当前数据集的所有几何对象 返回: 满足指定条件的所有几何对象 返回类型: list[Geometry]
-
get_record_count()¶ 返回矢量数据集中全部记录的数目。
返回类型: int
-
get_recordset(is_empty=False, cursor_type=CursorType.DYNAMIC, fields=None)¶ 根据给定的参数来返回空的记录集或者返回包括所有记录的记录集对象。
参数: - is_empty (bool) -- 是否返回空的记录集参数。为 true 时返回空记录集。为 false 时返回包含所有记录的记录集合对象。
- cursor_type (CursorType or str) -- 游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。可以为枚举值或名称
- fields (list[str] or str) -- 需要输出的结果字段名称,如果为 None 则保留所有的字段
返回: 满足条件的记录集对象
返回类型:
-
get_spatial_index_type()¶ 获取空间索引类型
返回类型: SpatialIndexType
-
get_tolerance_dangle()¶ 获取短悬线容限
返回类型: float
-
get_tolerance_extend()¶ 获取长悬线容限
返回类型: float
-
get_tolerance_grain()¶ 获取颗粒容限
返回类型: float
-
get_tolerance_node_snap()¶ 获取节点容限
返回类型: float
-
get_tolerance_small_polygon()¶ 获取最小多边形容限
返回类型: float
-
index_of_field(name)¶ 获取指定字段名称序号
参数: name (str) -- 字段名称 返回: 如果字段存在返回字段的序号,否则返回 -1 返回类型: int
-
is_available_field_name(name)¶ 判断指定的字段名称是否是合法而且没有被占用的字段名称
参数: name (str) -- 字段名称 返回: 字段名称合法且没有被占用返回 True,否则返回 False 返回类型: bool
-
is_file_cache()¶ 返回是否使用文件形式的缓存。文件形式的缓存可以提高浏览速度。 注意:文件形式的缓存只对 Oracle 数据源下已创建图幅索引的矢量数据集有效。
返回类型: bool
-
is_spatial_index_dirty()¶ 判断当前数据集的空间索引是否需要重建。因为在修改数据过程后,可能需要重建空间索引。 注意:
- 当矢量数据集无空间索引时,如果其记录条数已达到建立空间索引的要求,则返回 True,建议用户创建空间索引;否则返回 False。
- 如果矢量数据集已有空间索引(图库索引除外),但其记录条数已经不能达到建立空间索引的要求时,返回 True。
返回类型: bool
-
is_spatial_index_type_supported(spatial_index_type)¶ 判断当前数据集是否支持指定的类型的空间索引。
参数: spatial_index_type (SpatialIndexType or str) -- 空间索引类型,可以为枚举值或名称 返回: 如果支持指定的空间索引类型,返回值为 true,否则为 false。 返回类型: bool
-
parent_dataset¶ DatasetVector -- 矢量数据集的父数据集。主要用于网络数据集
-
query(query_param=None)¶ 通过设置查询条件对矢量数据集进行查询,该方法默认查询空间信息与属性信息。
参数: query_param (QueryParameter) -- 查询条件 返回: 满足查询条件的结果记录集 返回类型: Recordset
-
query_with_bounds(bounds, attr_filter=None, cursor_type=CursorType.DYNAMIC)¶ 根据地理范围查询记录集
参数: - bounds (Rectangle) -- 已知的空间范围
- attr_filter (str) -- 查询过滤条件,相当于 SQL 语句中的 Where 子句部分
- cursor_type (CursorType or str) -- 游标类型,可以为枚举值或名称
返回: 满足查询条件的结果记录集
返回类型:
-
query_with_distance(geometry, distance, unit=None, attr_filter=None, cursor_type=CursorType.DYNAMIC)¶ 用于查询数据集中落在指定空间对象的缓冲区内,并且满足一定条件的记录。
参数: - geometry (Geometry or Point2D or Rectangle) -- 用于查询的空间对象。
- distance (float) -- 查询半径
- unit (Unit or str) -- 查询半径的单位,如果为 None 则查询半径的单位与数据集的单位相同。
- attr_filter (str) -- 查询过滤条件,相当于 SQL 语句中的 Where 子句部分
- cursor_type (CursorType or str) -- 游标类型,可以为枚举值或名称
返回: 满足查询条件的结果记录集
返回类型:
-
query_with_filter(attr_filter=None, cursor_type=CursorType.DYNAMIC, result_fields=None, has_geometry=True)¶ 根据指定的属性过滤条件查询记录集
参数: - attr_filter (str) -- 查询过滤条件,相当于 SQL 语句中的 Where 子句部分
- cursor_type (CursorType or str) -- 游标类型,可以为枚举值或名称
- result_fields (list[str] or str) -- 结果字段名称
- has_geometry (bool) -- 是否包含几何对象
返回: 满足查询条件的结果记录集
返回类型:
-
query_with_ids(ids, id_field_name='SmID', cursor_type=CursorType.DYNAMIC)¶ 根据跟定的 ID 数组,查询满足记录的记录集
参数: - ids (list[int]) -- ID 数组
- id_field_name (str) -- 数据集中用于表示 ID 的字段名称。默认为 “SmID”
- cursor_type (CursorType or str) -- 游标类型
返回: 满足查询条件的结果记录集
返回类型:
-
re_build_spatial_index()¶ 在原有的空间索引的基础上进行重建,如果原来的空间索引被破坏,那么重建成功之后还可以继续使用。
返回: 重建索引成功返回 Ture,否则返回 False。 返回类型: bool
-
remove_field(item)¶ 删除指定的字段
参数: item (int or str) -- 字段名称或序号 返回: 删除成功返回 True,否则返回 False 返回类型: bool
-
reset_tolerance_as_default()¶ 将所有的容限设为缺省值,单位与矢量数据集坐标系单位相同:
- 节点容限的默认值为数据集宽度的1/1000000;
- 颗粒容限的默认值为数据集宽度的1/1000;
- 短悬线容限的默认值为数据集宽度的1/10000;
- 长悬线容限的默认值为数据集宽度的1/10000;
- 最小多边形容限的默认值为0。
-
set_file_cache(value)¶ 设置是否使用文件形式的缓存。
参数: value (bool) -- 是否使用文件形式的缓存
-
set_tolerance_dangle(value)¶ 设置短悬线容限
参数: value (float) -- 短悬线容限
-
set_tolerance_extend(value)¶ 设置长悬线容限
参数: value (float) -- 长悬线容限
-
set_tolerance_grain(value)¶ 设置颗粒容限
参数: value (float) -- 颗粒容限
-
set_tolerance_node_snap(value)¶ 设置节点容限
参数: value (float) -- 节点容限
-
set_tolerance_small_polygon(value)¶ 设置最小多边形容限
参数: value (float) -- 最小多边形容限
-
stat(item, stat_mode)¶ 对指定的字段按照给定的方式进行统计。 当前版本提供了6种统计方式。统计字段的最大值,最小值,平均值,总和,标准差,以及方差。 当前版本支持的统计字段类型为布尔,字节,双精度,单精度,16位整型,32位整型。
参数: - item (str or int) -- 字段名称或序号
- stat_mode (StatisticMode or str) -- 字段统计模式
返回: 统计结果
返回类型: float
-
truncate()¶ 清除矢量数据集中的所有记录。
返回: 清除记录是否成功,成功返回 True,失败返回 False。 返回类型: bool
-
update_field(item, value, attr_filter=None)¶ 根据指定的需要更新的字段名称,用指定的用于更新的字段值更新符合 attributeFilter 条件的所有记录的字段值。需要更新的字段不能够为系统字段, 也就是说待更新字段不可以为 sm 开头的字段(smUserID 除外)。
参数: - item (str or int) -- 字段名称或序号
- value (int or float or str or datetime.datetime or bytes or bytearray) -- 指定用于更新的字段值。
- attr_filter (str) -- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录
返回: 更新字段成功返回 True,否则返回 False
返回类型: bool
-
update_field_express(item, express, attr_filter=None)¶ 根据指定的需要更新的字段名,用指定的表达式计算结果更新符合查询条件的所有记录的字段值。需要更新的字段不能够为系统字段,也就是说不可以为 Sm 开头的字段(smUserID 除外)。
参数: - item (str or int) -- 字段名称或序号
- express (str) -- 指定的表达式,表达式可以是字段的运算或函数的运算。例如:"SMID" 、"abs(SMID)"、"SMID+1"、 " '字符串'"。
- attr_filter (str) -- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录
返回: 更新字段成功返回 True,否则返回 False
返回类型: bool
-
-
class
iobjectspy.data.DatasetVectorInfo(name=None, dataset_type=None, encode_type=None, is_file_cache=True)¶ 基类:
object矢量数据集信息类。包括了矢量数据集的信息,如矢量数据集的名称,数据集的类型,编码方式,是否选用文件缓存等。文件缓存只针对图幅索引而言
构造矢量数据集信息类
参数: - name (str) -- 数据集名称
- dataset_type (DatasetType or str) -- 数据集类型
- encode_type (EncodeType or str) -- 数据集的压缩编码方式。支持四种压缩编码方式,即单字节,双字节,三字节和四字节编码方式
- is_file_cache (bool) -- 是否使用文件形式的缓存。文件形式的缓存只针对图幅索引有用
-
encode_type¶ EncodeType -- 数据集的压缩编码方式。支持四种压缩编码方式,即单字节,双字节,三字节和四字节编码方式
-
from_dict(values)¶ 从 dict 中读取 DatasetVectorInfo 对象
参数: values (dict) -- 包含矢量数据集信息的 dict 对象,具体查看 to_dict()返回类型: self 返回类型: DatasetVectorInfo
-
is_file_cache¶ bool -- 是否使用文件形式的缓存。文件形式的缓存只针对图幅索引有用
-
static
make_from_dict(values)¶ 从 dict 中构造 DatasetVectorInfo 对象
参数: values (dict) -- 包含矢量数据集信息的 dict 对象,具体查看 to_dict()返回类型: DatasetVectorInfo
-
name¶ str -- 数据集名称,数据集的名称限制:数据集名称的长度限制为30个字符(也就是可以为30个英文字母或者15个汉字),组成数据集名称的字符可以 为字母、汉字、数字和下划线,数据集名称不可以用数字和下划线开头,如果用字母开头,数据集名称不可以和数据库的保留关键字冲突。
-
set_encode_type(value)¶ 设置数据集的压缩编码方式
参数: value (EncodeType or str) -- 数据集的压缩编码方式 返回: self 返回类型: DatasetVectorInfo
-
set_file_cache(value)¶ 设置是否使用文件形式的缓存。文件形式的缓存只针对图幅索引有用。
参数: value (bool) -- 是否使用文件形式的缓存 返回: self 返回类型: DatasetVectorInfo
-
set_name(value)¶ 设置数据集的名称
参数: value (str) -- 数据集名称 返回: self 返回类型: DatasetVectorInfo
-
set_type(value)¶ 设置数据集的类型
参数: value (DatasetType or str) -- 数据集类型 返回: self 返回类型: DatasetVectorInfo
-
to_dict()¶ 将当前对象的信息输出为 dict 对象
返回类型: dict
-
type¶ DatasetType -- 数据集类型
-
class
iobjectspy.data.DatasetImageInfo(name=None, width=None, height=None, pixel_format=None, encode_type=None, block_size_option=BlockSizeOption.BS_256, band_count=None)¶ 基类:
object影像数据集信息类,该类用于设置影像数据集的创建信息,包括名称、宽度、高度、波段数和存储分块大小等。
通过该类设置影像数据集的创建信息时,需要注意:
- 需要指定影像的波段数,波段数可以设置为 0,创建之后可以再向影像中添加波段;
- 所有波段被设置为相同的像素格式和编码方式,创建影像成功后,可以根据需求,再为每个波段设置不同的像素格式和其编码类型。
构造影像数据集信息对象
参数: - name (str) -- 数据集名称
- width (int) -- 数据集的宽度,单位为像素
- height (int) -- 数据集的高度,单位为像素
- pixel_format (PixelFormat or str) -- 数据集存储的像素格式
- encode_type (EncodeType or str) -- 数据集存储的编码方式
- block_size_option (BlockSizeOption) -- 数据集的像素分块类型
- band_count (int) -- 波段数目
-
band_count¶ int -- 波段数目
-
block_size_option¶ BlockSizeOption -- 数据集的像素分块类型
-
bounds¶ Rectangle -- 影像数据集的地理范围.
-
encode_type¶ EncodeType -- 返回影像数据集数据存储时的编码方式。对数据集采用压缩编码方式,可以减少数据存储所占用的空间,降低数据传输时的网络负载和服务器的负载。 光栅数据支持的编码方式有 DCT,SGL,LZW 或不使用编码方式
-
from_dict(values)¶ 从 dict 中读取 DatasetImageInfo 信息
参数: values (dict) -- 返回: self 返回类型: DatasetImageInfo
-
height¶ int -- 影像数据集的影像数据的高度。单位为像素
-
static
make_from_dict(values)¶ 从 dict 中读取信息构建 DatasetImageInfo 对象
参数: values (dict) -- 返回类型: DatasetImageInfo
-
name¶ str -- 数据集名称
-
pixel_format¶ PixelFormat -- 影像数据存储的像素格式。每个象素采用不同的字节进行表示,单位是比特(bit)。
-
set_band_count(value)¶ 设置影像数据集的波段数目。创建影像数据集时,波段数可以设置为 0,此时,像素格式(pixel_format)和编码格式(encode_type)的设置是无效的 ,因为这些信息是针对波段而言,因此波段为 0 时无法保存。此影像数据集的像素格式和编码格式,将以向其中添加的第一个波段的相关信息为准。
参数: value (int) -- 波段数目。 返回: self 返回类型: DatasetImageInfo
-
set_block_size_option(value)¶ 设置数据集的像素分块类型。以正方形方式进行分块存储。其中在进行分块过程中,如果果影像数据不足以进行完整地分块,那么采用空格补充完整进行存储。默认值为 BlockSizeOption.BS_256。
参数: value (BlockSizeOption or str) -- 影像数据集的像素分块 返回: self 返回类型: DatasetImageInfo
-
set_bounds(value)¶ 设置影像数据集的地理范围。
参数: value (Rectangle) -- 影像数据集的地理范围。 返回: self 返回类型: DatasetImageInfo
-
set_encode_type(value)¶ 设置影像数据集数据存储时的编码方式。对数据集采用压缩编码方式,可以减少数据存储所占用的空间,降低数据传输时的网络负载和服务器的负载。 光栅数据支持的编码方式有 DCT,SGL,LZW 或不使用编码方式。
参数: value (EncodeType or str) -- 像数据集数据存储时的编码方式 返回: self 返回类型: DatasetImageInfo
-
set_height(value)¶ 设置影像数据集的影像数据的高度。单位为像素。
参数: value (int) -- 影像数据集的影像数据的高度。单位为像素。 返回: self 返回类型: DatasetImageInfo
-
set_name(value)¶ 设置数据集的名称
参数: value (str) -- 数据集名称 返回: self 返回类型: DatasetImageInfo
-
set_pixel_format(value)¶ 设置影像数据集的存储的像素格式。影像数据集不支持 DOUBLE、SINGLE、BIT64 类型的像素格式。
参数: value (PixelFormat or str) -- 影像数据集的存储的像素格式 返回: self 返回类型: DatasetImageInfo
-
set_width(value)¶ 设置影像数据集的影像数据的宽度。单位为像素。
参数: value (int) -- 影像数据集的影像数据的宽度。单位为像素。 返回: self 返回类型: DatasetImageInfo
-
to_dict()¶ 将当前对象信息输出为 dict
返回类型: dict
-
width¶ int -- 影像数据集的影像数据的宽度。单位为像素
-
class
iobjectspy.data.DatasetGridInfo(name=None, width=None, height=None, pixel_format=None, encode_type=None, block_size_option=BlockSizeOption.BS_256)¶ 基类:
object栅格数据集信息类。该类包括了返回和设置栅格数据集的相应的设置信息等,例如栅格数据集的名称、宽度、高度、像素格式、编码方式、存储分块大小和空值等。
构造栅格数据集信息对象
参数: - name (str) -- 数据集名称
- width (int) -- 数据集的宽度,单位为像素
- height (int) -- 数据集的高度,单位为像素
- pixel_format (PixelFormat or str) -- 数据集存储的像素格式
- encode_type (EncodeType or str) -- 数据集存储的编码方式
- block_size_option (BlockSizeOption) -- 数据集的像素分块类型
-
block_size_option¶ BlockSizeOption -- 数据集的像素分块类型
-
bounds¶ Rectangle -- 栅格数据集的地理范围.
-
encode_type¶ EncodeType -- 返回栅格数据集数据存储时的编码方式。对数据集采用压缩编码方式,可以减少数据存储所占用的空间,降低数据传输时的网络负载和服务器的负载。 光栅数据支持的编码方式有 DCT,SGL,LZW 或不使用编码方式
-
from_dict(values)¶ 从 dict 中读取 DatasetGridInfo 信息
参数: values (dict) -- 返回: self 返回类型: DatasetGridInfo
-
height¶ int -- 栅格数据集的栅格数据的高度。单位为像素
-
static
make_from_dict(values)¶ 从 dict 中读取信息构建 DatasetGridInfo 对象
参数: values (dict) -- 返回类型: DatasetGridInfo
-
max_value¶ float -- 栅格数据集栅格行列中的最大值
-
min_value¶ float -- 格数据集栅格行列中的最小值
-
name¶ str -- 数据集名称
-
no_value¶ float -- 栅格数据集的空值,当此数据集为空值时,用户可采用-9999来表示
-
pixel_format¶ PixelFormat -- 栅格数据存储的像素格式。每个象素采用不同的字节进行表示,单位是比特(bit)。
-
set_block_size_option(value)¶ 设置数据集的像素分块类型。以正方形方式进行分块存储。其中在进行分块过程中,如果 栅格数据不足以进行完整地分块,那么采用空格补充完整进行存储。默认值为 BlockSizeOption.BS_256。
参数: value (BlockSizeOption or str) -- 栅格数据集的像素分块 返回: self 返回类型: DatasetGridInfo
-
set_bounds(value)¶ 设置栅格数据集的地理范围。
参数: value (Rectangle) -- 栅格数据集的地理范围。 返回: self 返回类型: DatasetGridInfo
-
set_encode_type(value)¶ 设置格栅格数据集数据存储时的编码方式。对数据集采用压缩编码方式,可以减少数据存储所占用的空间,降低数据传输时的网络负载和服务器的负载。 光栅数据支持的编码方式有 DCT,SGL,LZW 或不使用编码方式。
参数: value (EncodeType or str) -- 栅格数据集数据存储时的编码方式 返回: self 返回类型: DatasetGridInfo
-
set_height(value)¶ 设置栅格数据集的栅格数据的高度。单位为像素。
参数: value (float) -- 栅格数据集的栅格数据的高度 返回: self 返回类型: DatasetGridInfo
-
set_max_value(value)¶ 设置栅格数据集栅格行列中的最大值。
参数: value (float) -- 栅格数据集栅格行列中的最大值 返回: self 返回类型: DatasetGridInfo
-
set_min_value(value)¶ 设置栅格数据集栅格行列中的最小值
参数: value (float) -- 栅格数据集栅格行列中的最小值 返回: self 返回类型: DatasetGridInfo
-
set_name(value)¶ 设置数据集的名称
参数: value (str) -- 数据集名称 返回: self 返回类型: DatasetGridInfo
-
set_no_value(value)¶ 设置栅格数据集的空值,当此数据集为空值时,用户可采用-9999来表示。
参数: value (float) -- 栅格数据集的空值 返回: self 返回类型: DatasetGridInfo
-
set_pixel_format(value)¶ 设置栅格数据集的存储的像素格式
参数: value (PixelFormat or str) -- 栅格数据集的存储的像素格式 返回: self 返回类型: DatasetGridInfo
-
set_width(value)¶ 设置栅格数据集的栅格数据的宽度。单位为像素。
参数: value (int) -- 栅格数据集的栅格数据的宽度。单位为像素。 返回: self 返回类型: DatasetGridInfo
-
to_dict()¶ 将当前对象信息输出为 dict
返回类型: dict
-
width¶ int -- 栅格数据集的栅格数据的宽度。单位为像素
-
class
iobjectspy.data.DatasetImage¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset影像数据集类。 影像数据集类,该类用于描述影像数据,不具备属性信息,例如影像地图、多波段影像和实物地图等。 光栅数据采用网格形式组织并使用二维栅格 的像素值来记录数据,每个栅格(cell)代表一个像素要素,栅格值可以描述各种数据信息。影像数据集中每一个栅格存储的是一个颜色值或颜色的索引值(RGB 值)。
-
add_band(datasets, indexes=None)¶ 向指定的多波段影像数据集中按照指定的索引追加多个波段
参数: - datasets (list[DatasetImage] or DatasetImage) -- 影像数据集合
- indexes (list[int]) -- 要追加的波段索引,当输入的是单个 DatasetImage 数据才有效。
返回: 添加的波段个数
返回类型: int
-
band_count¶ int -- 返回波段数目
-
block_size_option¶ BlockSizeOption -- 数据集的像素分块类型
-
build_pyramid(progress=None)¶ 给影像数据集创建金字塔。目的是提高影像数据集的显示速度。金字塔只能针对原始的数据进行创建;一次仅能给一个数据集创建金字塔,当显示该影像数据集的 时候,已创建的金字塔都将被访问。
参数: progress (function) -- 进度信息处理函数,参考 StepEvent返回: 创建是否成功,成功返回 True,失败返回 False 返回类型: bool
-
build_statistics()¶ 对影像数据集执行统计操作,返回该影像数据集的统计结果对象。统计的结果包括影像数据集的最大值、最小值、均值、中值、众数、稀数、方差、标准差等。
返回: 返回一个dict,dict中包含每个波段的统计结果,统计结果为包含最大值、最小值、均值、中值、众数、稀数、方差、标准差 的 dict 对象。其中 dict 中的 key 值: - average : 平均值
- majority : 众数
- minority : 稀数
- max : 最大值
- median : 中值
- min : 最小值
- stdDev : 标准差
- var : 方差
- is_dirty : 是否为“脏”数据
返回类型: dict[dict]
-
calculate_extremum(band=0)¶ 计算影像数据指定波段的极值,即最大值和最小值。
参数: band (int) -- 要计算极值的影像数据的波段序号。 返回: 如果计算成功返回 true,否则返回 false。 返回类型: bool
-
clip_region¶ GeoRegion -- 影像数据集的显示区域
-
delete_band(start_index, count=1)¶ 根据指定索引号删除某个波段
参数: - start_index (int) -- 指定删除波段的开始索引号。
- count (int) -- 要删除的波段的个数。
返回: 删除成功返回 true;否则返回 false。
返回类型: bool
-
get_band_index(name)¶ 获取指定波段名称所在的序号
参数: name (str) -- 波段名称 返回: 波段所在的序号 返回类型: int
-
get_band_name(band)¶ 返回指定序号的波段的名称。
参数: band (int) -- 波段序号 返回: 波段名称 返回类型: str
-
get_max_value(band=0)¶ 获取影像数据集指定波段的最大像素值
参数: band (int) -- 指定的波段索引号,从 0 开始。 返回: 影像数据集指定波段的最大像素值 返回类型: float
-
get_min_value(band=0)¶ 获取影像数据集指定波段的最小像素值
参数: band (int) -- 指定的波段索引号,从 0 开始。 返回: 影像数据集指定波段的最小像素值 返回类型: float
-
get_no_value(band=0)¶ 返回影像数据集指定波段的无值。
参数: band (int) -- 指定的波段索引号,从 0 开始 返回: 影像数据集中指定波段的无值 返回类型: float
-
get_palette(band=0)¶ 获取影像数据集指定波段的颜色调色板
参数: band (int) -- 指定的波段索引号,从 0 开始。 返回: 影像数据集指定波段的颜色调色板 返回类型: Colors
-
get_pixel_format(band)¶ 返回影像数据集指定波段的像素格式。
参数: band (int) -- 指定的波段索引号,从 0 开始。 返回: 影像数据集指定波段的像素格式。 返回类型: PixelFormat
-
get_value(col, row, band)¶ 根据给定的行数和列数返回影像数据集的栅格所对应的像素值。注意:该方法的参数值的行、列数从零开始计数。
参数: - col (int) -- 指定的影像数据集的列。
- row (int) -- 指定的影像数据集的行。
- band (int) -- 指定的波段数
返回: 影像数据集中所对应的像素值。
返回类型: float or tuple
-
has_pyramid()¶ 影像数据集是否已创建金字塔。
返回类型: bool
-
height¶ int -- 影像数据集的影像数据的高度。单位为像素
-
image_to_xy(col, row)¶ 根据指定的行数和列数所对应的影像点转换为地理坐标系下的点,即 X, Y 坐标。
参数: - col (int) -- 指定的列
- row (int) -- 指定的行
返回: 地理坐标系下的对应的点坐标。
返回类型:
-
remove_pyramid()¶ 影像已创建的金字塔
返回类型: bool
-
set_band_name(band, name)¶ 设置指定序号的波段的名称。
参数: - band (int) -- 波段序号
- name (str) -- 波段名称
-
set_clip_region(region)¶ 设置影像数据集的显示区域。 当用户设置此方法后,影像格数据集就按照给定的区域进行显示,区域之外的都不显示。
注意:
- 当用户所设定的影像数据集的地理范围(即调用
set_geo_reference()方法)与所设定的裁剪区域无重叠区域,影像数据集不显示。 - 当重新设置影像数据集的地理范围,不自动修改影像数据集的裁剪区域。
参数: region (GeoRegion or Rectangle) -- 影像数据集的显示区域。 - 当用户所设定的影像数据集的地理范围(即调用
-
set_no_value(value, band)¶ 设置影像数据集指定波段的无值。
参数: - value (float or tuple[int,int,int] or tuple[int,int,int,int]) -- 指定的无值。
- band (int) -- 指定的波段索引号,从 0 开始。
-
set_palette(colors, band)¶ 设置影像数据集指定波段的颜色调色板
参数: - colors (Colors) -- 颜色调色板。
- band (int) -- 指定的波段索引号,从 0 开始。
-
set_value(col, row, value, band)¶ 根据给定的行数和列数设置影像数据集的所对应的像素值。注意:该方法的参数值的行、列数从零开始计数。
参数: - col (int) -- 指定的影像数据集的列。
- row (int) -- 指定的影像数据集的行。
- value (tuple or float) -- 指定的影像数据集的所对应的像素值。
- band (int) -- 指定的波段序号
返回: 影像数据集中所对应的修改之前的像素值。
返回类型: float
-
update(dataset)¶ 根据指定的影像数据集更新。 注意:指定的影像数据集和被更新的影像数据集的编码方式(EncodeType)和像素类型(PixelFormat)必须保持一致。
参数: dataset (DatasetImage or str) -- 指定的影像数据集。 返回: 如果更新成功,返回 True,否则返回 False。 返回类型: bool
-
update_pyramid(rect)¶ 指定范围更新影像数据集影像金字塔。
参数: rect (Rectangle) -- 更新金字塔的指定影像范围 返回: 更新成功,返回 True,否则返回 False。 返回类型: bool
-
width¶ int -- 影像数据集的影像数据的宽度。单位为像素
-
-
class
iobjectspy.data.DatasetGrid¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset栅格数据集类。栅格数据集类,该类用于描述栅格数据,例如高程数据集和土地利用图。栅格数据采用网格形式组织并使用二维的栅格的像素值来记录数据,每个栅 格(cell)代表一个像素要素,栅格值可以描述各种数据信息。栅格数据集中每一个栅格(cell)存储的是表示地物的属性值,属性值可以是土壤类型、密度值、 高程、温度、湿度等。
-
block_size_option¶ BlockSizeOption -- 数据集的像素分块类型
-
build_pyramid(resample_method=None, progress=None)¶ 给栅格数据创建指定类型的金字塔,目的是提高栅格数据的显示速度。。金字塔只能针对原始的数据进行创建;用户仅能给一个数据集创建一次金字塔,如果想 再次创建需要将原来创建的金字塔进行删除,当该栅格数据集显示的时候,已创建的金字塔都将被访问。下图所示为不同比例尺下金字塔的建立过程。
参数: - resample_method (ResamplingMethod or str) -- 建金字塔方法的类型
- progress (function) -- 进度信息处理函数,参考
StepEvent
返回: 创建是否成功,成功返回 True,失败返回 False
返回类型: bool
-
build_statistics()¶ 对栅格数据集执行统计操作,返回该栅格数据集的统计结果对象。统计的结果包括栅格数据集的最大值、最小值、均值、中值、众数、稀数、方差、标准差等。
返回: 包含 最大值、最小值、均值、中值、众数、稀数、方差、标准差 的 dict 对象。其中 dict 中的 key 值: - average : 平均值
- majority : 众数
- minority : 稀数
- max : 最大值
- median : 中值
- min : 最小值
- stdDev : 标准差
- var : 方差
- is_dirty : 是否为“脏”数据
返回类型: dict
-
build_value_table(out_data=None, out_dataset_name=None)¶ 创建栅格值属性表,其类型为属性表数据集类型TABULAR。 栅格数据集的像素格式为SINGLE 和 DOUBLE ,无法创建属性表,即调用该方法返回为 None。 返回属性表数据集含有系统字段和两个记录栅格信息字段,GRIDVALUE 记录栅格值,GRIDCOUNT 记录栅格值对应的像元个数。
参数: - out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果数据集或数据集名称
返回类型: DatasetVector or str
-
calculate_extremum()¶ 计算栅格数据集的极值,即最大值和最小值。建议:栅格数据集在一些分析或者操作之后,建议调用此接口,计算一下最大最小值。
返回: 如果计算成功返回 true,否则返回 false。 返回类型: bool
-
clip_region¶ GeoRegion -- 栅格数据集的显示区域
-
color_table¶ Colors -- 数据集的颜色表
-
column_block_count¶ int -- 栅格数据集分块后的所得到的总列数。
-
get_value(col, row)¶ 根据给定的行数和列数返回栅格数据集的栅格所对应的栅格值。注意:该方法的参数值的行、列数从零开始计数。
参数: - col (int) -- 指定的栅格数据集的列。
- row (int) -- 指定栅格数据集的行。
返回: 栅格数据集的栅格所对应的栅格值。
返回类型: float
-
grid_to_xy(col, row)¶ 根据指定的行数和列数所对应的栅格点转换为地理坐标系下的点,即 X, Y 坐标。
参数: - col (int) -- 指定的列
- row (int) -- 指定的行
返回: 地理坐标系下的对应的点坐标。
返回类型:
-
has_pyramid()¶ 栅格数据集是否已创建金字塔。
返回类型: bool
-
height¶ int -- 栅格数据集的栅格数据的高度。单位为像素
-
max_value¶ float -- 栅格数据集中栅格值的最大值。
-
min_value¶ float -- 栅格数据集中栅格值的最小值
-
no_value¶ float -- 栅格数据集的空值,当此数据集为空值时,用户可采用-9999来表示
-
pixel_format¶ PixelFormat -- 栅格数据存储的像素格式。每个象素采用不同的字节进行表示,单位是比特(bit)。
-
remove_pyramid()¶ 删除已创建的金字塔
返回类型: bool
-
row_block_count¶ int -- 栅格数据经过分块后所得到的总行数。
-
set_clip_region(region)¶ 设置栅格数据集的显示区域。 当用户设置此方法后,栅格数据集就按照给定的区域进行显示,区域之外的都不显示。
注意:
- 当用户所设定的栅格数据集的地理范围(即调用
set_geo_reference()方法)与所设定的裁剪区域无重叠区域,栅格数据集不显示。 - 当重新设置栅格数据集的地理范围,不自动修改栅格数据集的裁剪区域。
参数: region (GeoRegion or Rectangle) -- 栅格数据集的显示区域。 - 当用户所设定的栅格数据集的地理范围(即调用
-
set_no_value(value)¶ 设置栅格数据集的空值,当此数据集为空值时,用户可采用-9999来表示
参数: value (float) -- 空值
-
set_value(col, row, value)¶ 根据给定的行数和列数设置栅格数据集的栅格所对应的栅格值。注意:该方法的参数值的行、列数从零开始计数。
参数: - col (int) -- 指定的栅格数据集的列。
- row (int) -- 指定栅格数据集的行。
- value (float) -- 指定的栅格数据集的栅格所对应的栅格值。
返回: 栅格数据集的栅格所对应的修改之前的栅格值。
返回类型: float
-
update(dataset)¶ 根据指定的栅格数据集更新。 注意:指定的栅格数据集和被更新的栅格数据集的编码方式(EncodeType)和像素类型(PixelFormat)必须保持一致
参数: dataset (DatasetGrid or str) -- 指定的栅格数据集。 返回: 如果更新成功,返回 True,否则返回 False。 返回类型: bool
-
update_pyramid(rect)¶ 指定范围更新栅格数据集影像金字塔。
参数: rect (Rectangle) -- 更新金字塔的指定影像范围 返回: 更新成功,返回 True,否则返回 False。 返回类型: bool
-
width¶ int -- 栅格数据集的栅格数据的宽度。单位为像素
-
-
class
iobjectspy.data.DatasetTopology¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset
-
class
iobjectspy.data.DatasetMosaic¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset镶嵌数据集。用于高效管理和显示海量影像数据。 如今,影像的获取已越来越便捷、高效,针对海量影像的管理、服务发布的需求也越来越普遍。为了更便捷高效地 完成这一工作,SuperMap GIS提供了基于镶嵌数据集的解决方案。镶嵌数据集采用元数据+原始影像文件的方式进行管理。把影像数据添加到镶嵌数据集时,只会 在镶嵌数据集中记录影像文件的路径、轮廓、分辨率等元信息,在使用时才会根据元信息加载所需的影像文件。该模式相比传统的入库管理方式,大大提升了入库的 速度,同时也减少了磁盘的占用。
-
add_files(directory_paths, extension=None, clip_file_extension=None)¶ 向镶嵌数据集中添加影像,实质是将给定路径下的指定扩展名的所有影像的文件名添加并记录,即镶嵌数据集并没有对影像文件进行拷贝入库,只是记录了影像的全路径(绝对路径)信息。
参数: - directory_paths (str or list[str]) -- 指定添加影像的路径,即要添加的影像所在的文件夹路径(绝对路径)或 要添加的多个影像文件的全路径(绝对路径)列表。
- extension (str) -- 影像文件的扩展名,当 directory_paths 为文件夹路径时(即 directory_paths 类型为 str 时),用来过滤文件夹内影像文件。 当 directory_paths 类型为 list 时,该参数不生效。
- :param clip_file_extension:裁剪形状文件的后缀名,如.shp,该文件中的对象将作为该影像的裁剪显示范围。影像的裁剪显示一般用于:
- 当影像经过校正后产生无值区域,通过裁剪形状绘制影像的有效值区域,经过裁剪显示后达到去除无值区域的目的。 另外,影像与裁剪形状是一一对应的关系,因此,裁剪形状文件必须存储在 directory_path 参数指定的路径下, 即裁剪形状文件与影像文件在同一目录下。
返回: 添加影像是否成功,True表示成功;False表示失败。 返回类型: bool
-
bound_count¶ int -- 镶嵌数据集波段数
-
boundary_dataset¶ DatasetVector -- 镶嵌数据集的边界子数据集
-
build_pyramid(resample_type=PyramidResampleType.NONE, is_skip_exists=True)¶ 为镶嵌数据集中的所有影像创建影像金字塔。
参数: - resample_type (PyramidResampleType or str) -- 金字塔重采样方式
- is_skip_exists (bool) -- 一个布尔值,指示如果影像已经创建了金字塔是否忽略,True 表示忽略,即不再重新创建金字塔;False 表示对已经 创建金字塔的影像重新创建金字塔。
返回: 成功创建返回 True;否则返回 False
返回类型: bool
-
clip_dataset¶ DatasetVector -- 镶嵌数据集的裁剪子数据集
-
footprint_dataset¶ DatasetVector -- 镶嵌数据集的轮廓子数据集
-
list_files()¶ 获取镶嵌数据集的所有栅格文件
返回: 镶嵌数据集的所有栅格文件 返回类型: list[str]
-
pixel_format¶ PixelFormat -- 镶嵌数据集的位深
-
-
class
iobjectspy.data.DatasetVolume¶ 基类:
iobjectspy._jsuperpy.data.dt.Dataset
-
class
iobjectspy.data.Colors(seq=None)¶ 基类:
object颜色集合类。该类主要作用是提供颜色序列。提供各种渐变色和随机色的生成,以及 SuperMap 预定义渐变色的生成。
-
append(value)¶ 添加一个颜色值到颜色集合中
参数: value (tuple[int] or int) -- RGB 颜色值或 RGBA 颜色值
-
clear()¶ 清空所有颜色值
-
extend(iterable)¶ 添加一个颜色值的集合
参数: iterable (range[int] or range[tuple]) -- 颜色值集合
-
index(value, start=None, end=None)¶ 返回颜色值的序号
参数: - value (tuple[int] or int) -- RGB 颜色值或 RGBA 颜色值
- start (int) -- 开始查找位置
- end (int) -- 终止查找位置
返回: 满足条件的颜色值所在的位置
返回类型: int
-
insert(index, value)¶ 添加颜色到指定的位置
参数: - index (int) -- 指定的位置
- value (tuple[int] or int) -- RGB 颜色值或 RGBA 颜色值
-
static
make_gradient(count, gradient_type, reverse=False, gradient_colors=None)¶ 给定颜色的数量和控制颜色生成一组渐变色,或生成生成系统预定义渐变色。gradient_colors 和 gradient_type 不能同时有效,但 gradient_type 有效时 会优先使用 gradient_type 生成系统预定义的渐变色。
参数: - count (int) -- 要生成的渐变色的颜色总数。
- gradient_type (ColorGradientType or str) -- 渐变颜色的类型。
- reverse (bool) -- 是否反向生成渐变色,即是否从终止色到起始色生成渐变色。仅对 gradient_type 有效时起作用。
- gradient_colors (Colors) -- 渐变颜色集。即生成渐变色的控制颜色。
返回: 返回类型:
-
static
make_random(count, colors=None)¶ 用于生成一定数量的随机颜色。
参数: - count (int) -- 间隔色个数
- colors (Colors) -- 控制色集合。
返回: 由间隔色个数和控制色集合生成的随机颜色表。
返回类型:
-
pop(index=None)¶ 删除指定位置的颜色值,并返回颜色值。当 index 为 None 时删除最后一个颜色值
参数: index (int) -- 指定的位置 返回: 被删除的颜色值 返回类型: tuple
-
remove(value)¶ 删除指定的颜色值
参数: value (tuple[int] or int) -- 被删除的颜色值
-
values()¶ 返回所有的颜色值
返回类型: list[tuple]
-
-
class
iobjectspy.data.JoinItem(name=None, foreign_table=None, join_filter=None, join_type=None)¶ 基类:
object连接信息类。用于矢量数据集与外部表的连接。外部表可以为另一个矢量数据集(其中纯属性数据集中没有空间几何信息)所对应的DBMS表,也可以是用户自建 的业务表。需要注意的是,矢量数据集与外部表必须属于同一数据源。当两个表格之间建立了连接,通过对主表进行操作,可以对外部表进行查询,制作专题图以 及分析等。当两个表格之间是一对一或多对一的关系时,可以使用join连接。当为多对一的关系时,允许指定多个字段之间的关联。该类型的实例可被创建。
数据集表之间的联系的建立有两种方式,一种是连接(join),一种是关联(link)。连接的相关设置是通过 JoinItem 类实现的,关联的相关设置是通过 LinkItem 类实现的,另外,用于建立连接的两个数据集表必须在同一个数据源下,而用于建立关联关系的两个数据集表可以不在同一个数据源下。
下面通过查询的例子来说明连接和关联的区别,假设用来进行查询的数据集表为 DatasetTableA,被关联或者连接的表为 DatasetTableB,现通过建立 DatasetTableA 与 DatasetTableB 的连接或关联关系来查询 DatasetTableA 中满足查询条件的记录:
- 连接(join)
- 设置将 DatasetTableB 连接 DatasetTableA 的连接信息,即建立 JoinItem 类并设置其属性,当执行 DatasetTableA 的查询操作时, 系统将根据连接条件及查询条件,将满足条件的 DatasetTableA 中的内容与满足条件的 DatasetTableB 中的内容构成一个查询结果表,并且这个 查询表保存在内存中,需要返回结果时,再从内存中取出相应的内容。
- 关联(link)
- 设置将 DatasetTableB (副表)关联到 DatasetTableA (主表)的关联信息,即建立 LinkItem 类并设置其属性,DatasetTableA 与 DatasetTableB 是通过主表 DatasetTableA 的外键(LinkItem.foreign_keys)和副表 DatasetTableB 的主键 (LinkItem.primary_keys 方法)实现关联的,当执行 DatasetTableA 的查询操作时,系统将根据关联信息中的过滤条件及查询条件, 分别查询 DatasetTableA 与 DatasetTableB 中满足条件的内容,DatasetTableA 的查询结果与 DatasetTableB 的查询结果分别作为独立 的两个结果表保存在内存中,当需要返回结果时,SuperMap 将对两个结果进行拼接并返回,因此,在应用层看来,连接和关联操作很相似。
- LinkItem 只支持左连接,UDB、PostgreSQL 和 DB2 数据源不支持 LinkItem,即对 UDB、PostgreSQL 和 DB2 类型的数据引擎设置 LinkItem 不起作用;
- JoinItem 目前支持左连接和内连接,不支持全连接和右连接,UDB 引擎不支持内连接;
- 使用 LinkItem 的约束条件:空间数据和属性数据必须有关联条件,即主空间数据集与外部属性表之间存在关联字段。主空间数据集:用来与外部表进行关联的数据集。外部属性表:用户通过 Oracle 或者 SQL Server 创建的数据表,或者是另一个矢量数据集所对应的 DBMS 表。
示例:
>>> ds = Workspace().get_datasource('data') >>> dataset_world = ds['World'] >>> dataset_capital = ds['Capital'] >>> foreign_table_name = dataset_capital.table_name >>> >>> join_item = JoinItem() >>> join_item.set_foreign_table(foreign_table_name) >>> join_item.set_join_filter('World.capital=%s.capital' % foreign_table_name) >>> join_item.set_join_type(JoinType.LEFTJOIN) >>> join_item.set_name('Connect') >>> query_parameter = QueryParameter() >>> query_parameter.set_join_items([join_item]) >>> recordset = dataset_world.query(query_parameter) >>> print(recordset.get_record_count()) >>> recordset.close()
构造 JoinItem 对象
参数: - name (str) -- 连接信息对象的名称
- foreign_table (str) -- 外部表的名称
- join_filter (str) -- 与外部表之间的连接表达式,即设定两个表之间关联的字段
- join_type (str) -- 两个表之间连接的类型
-
foreign_table¶ str -- 外部表的名称
-
from_dict(values)¶ 从 dict 读取JoinItem 信息
参数: values (dict) -- 含有 JoinItem 信息的 dict,具体查看 to_dict 返回: self 返回类型: JoinItem
-
static
from_json(value)¶ 从 json 字符串中解析 JoinItem 信息,构造一个新的 JoinItem 对象
参数: value (str) -- json 字符串 返回类型: JoinItem
-
join_filter¶ str -- 与外部表之间的连接表达式,即设定两个表之间关联的字段
-
join_type¶ JoinType -- 两个表之间连接的类型
-
static
make_from_dict(values)¶ 从 dict 读取信息构造 JoinItem 对象。
参数: values (dict) -- 含有 JoinItem 信息的 dict,具体查看 to_dict 返回类型: JoinItem
-
name¶ str -- 连接信息对象的名称
-
set_join_filter(value)¶ 设置与外部表之间的连接表达式,即设定两个表之间关联的字段。例如,将一个房屋的面数据集(Building)的 district 字段与一个房屋拥有者的纯属 性数据集(Owner)的 region 字段相连接,两个数据集对应的表名称分别为 Table_Building 和 Table_Owner,则连接表达式为 Table_Building.district = Table_Owner.region,当有多个字段相连接时,用 AND 将多个表达式相连。
参数: value (str) -- 与外部表之间的连接表达式,即设定两个表之间关联的字段 返回: self 返回类型: JoinItem
-
set_join_type(value)¶ 设置两个表之间连接的类型。连接类型用于对两个连接的表进行查询时,决定了返回的记录的情况。
参数: value (JoinType or str) -- 两个表之间连接的类型 返回: self 返回类型: JoinItem
-
to_dict()¶ 将当前对象信息输出为 dict
返回类型: dict
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
class
iobjectspy.data.LinkItem(foreign_keys=None, name=None, foreign_table=None, primary_keys=None, link_fields=None, link_filter=None, connection_info=None)¶ 基类:
object关联信息类,用于矢量数据集与其它数据集的关联。关联数据集可以为另一个矢量数据集(其中纯属性数据集中没有空间几何信息)所对应的 DBMS 表,用户自 建业务表需要外挂到 SuperMap 数据源中。需要注意的是,矢量数据集与关联数据集可以属于不同的数据源。数据集表之间的联系的建立有两种方式,一种是 连接(join),一种是关联(link)。连接的相关设置是通过 JoinItem 类实现的,关联的相关设置是通过 LinkItem 类实现的,另外,用于建立连接的两 个数据集表必须在同一个数据源下,而用于建立关联关系的两个数据集表可以不在同一个数据源下。 下面通过查询的例子来说明连接和关联的区别,假设用来进行查询的数据集表为 DatasetTableA,被关联或者连接的表为 DatasetTableB,现通过建立 DatasetTableA 与 DatasetTableB 的连接或关联关系来查询 DatasetTableA 中满足查询条件的记录:
- 连接(join)
- 设置将 DatasetTableB 连接 DatasetTableA 的连接信息,即建立 JoinItem 类并设置其属性,当执行 DatasetTableA 的查询操作时, 系统将根据连接条件及查询条件,将满足条件的 DatasetTableA 中的内容与满足条件的 DatasetTableB 中的内容构成一个查询结果表,并且这个 查询表保存在内存中,需要返回结果时,再从内存中取出相应的内容。
- 关联(link)
- 设置将 DatasetTableB (副表)关联到 DatasetTableA (主表)的关联信息,即建立 LinkItem 类并设置其属性,DatasetTableA 与 DatasetTableB 是通过主表 DatasetTableA 的外键(LinkItem.foreign_keys)和副表 DatasetTableB 的主键 (LinkItem.primary_keys 方法)实现关联的,当执行 DatasetTableA 的查询操作时,系统将根据关联信息中的过滤条件及查询条件, 分别查询 DatasetTableA 与 DatasetTableB 中满足条件的内容,DatasetTableA 的查询结果与 DatasetTableB 的查询结果分别作为独立 的两个结果表保存在内存中,当需要返回结果时,SuperMap 将对两个结果进行拼接并返回,因此,在应用层看来,连接和关联操作很相似。
- LinkItem 只支持左连接,UDB、PostgreSQL 和 DB2 数据源不支持 LinkItem,即对 UDB、PostgreSQL 和 DB2 类型的数据引擎设置 LinkItem 不起作用;
- JoinItem 目前支持左连接和内连接,不支持全连接和右连接,UDB 引擎不支持内连接;
- 使用 LinkItem 的约束条件:空间数据和属性数据必须有关联条件,即主空间数据集与外部属性表之间存在关联字段。主空间数据集:用来与外部表进行关联的数据集。外部属性表:用户通过 Oracle 或者 SQL Server 创建的数据表,或者是另一个矢量数据集所对应的 DBMS 表。
- 示例:
# 'source' 数据集为主数据集,source 数据集用于关联的字段为 'LinkID','lind_dt' 数据集为外表数据集,即被关联的数据集,link_dt 中用于关联的字段为 'ID'
>>> ds_db1 = Workspace().get_datasource('data_db_1') >>> ds_db2 = Workspace().get_datasource('data_db_2') >>> source_dataset = ds_db1['source'] >>> linked_dataset = ds_db2['link_dt'] >>> linked_dataset_name = linked_dataset.name >>> linked_dataset_table_name = linked_dataset.table_name >>> >>> link_item = LinkItem() >>> >>> link_item.set_connection_info(ds_db2.connection_info) >>> link_item.set_foreign_table(linked_dataset_name) >>> link_item.set_foreign_keys(['LinkID']) >>> link_item.set_primary_keys(['ID']) >>> link_item.set_link_fields([linked_dataset_table_name+'.polulation']) >>> link_item.set_link_filter('ID < 100') >>> link_item.set_name('link_name')
构造 LinkItem 对象
参数: - foreign_keys (list[str]) -- 主数据集用于关联外表的字段
- name (str) -- 关联信息对象的名称
- foreign_table (str) -- 外表的数据集名称,即被关联的数据集名称
- primary_keys (list[str]) -- 外表数据集中用于关联的字段
- link_fields (list[str]) -- 外表数据集中被查询的字段名称
- link_filter (str) -- 外表数据集的查询条件
- connection_info (DatasourceConnectionInfo) -- 外表数据集所在数据源的连接信息
-
connection_info¶ DatasourceConnectionInfo -- 外表数据集所在数据源的连接信息
-
foreign_keys¶ list[str] -- 主数据集用于关联外表的字段
-
foreign_table¶ str -- 外表的数据集名称,即被关联的数据集名称
-
from_dict(values)¶ 从 dict 读取信息构造 LinkItem 对象。
参数: values (dict) -- 含有 LinkItem 信息的 dict,具体查看 to_dict 返回: self 返回类型: LinkItem
-
link_fields¶ list[str] -- 外表数据集中被查询的字段名称
-
link_filter()¶ str: 外表数据集的查询条件
-
static
make_from_dict(values)¶ 从 dict 读取信息构造 LinkItem 对象,构造一个新的 LinkItem 对象
参数: values (dict) -- 含有 LinkItem 信息的 dict,具体查看 to_dict 返回类型: LinkItem
-
name¶ str -- 关联信息对象的名称
-
primary_keys¶ list[str] -- 外表数据集中用于关联的字段
-
set_connection_info(value)¶ 设置外表数据集所在数据源的连接信息
参数: value (DatasourceConnectionInfo) -- 外表数据集所在数据源的连接信息 返回: self 返回类型: LinkItem
-
set_foreign_keys(value)¶ 设置主数据集用于关联外表的字段
参数: value (list[str]) -- 主数据集用于关联外表的字段 返回: self 返回类型: LinkItem
-
set_foreign_table(value)¶ 设置外表的数据集名称,即被关联的数据集名称
参数: value (str) -- 外表的数据集名称,即被关联的数据集名称 返回: self 返回类型: LinkItem
-
set_link_fields(value)¶ 设置外表数据集中被查询的字段名称
参数: value (list[str]) -- 外表数据集中被查询的字段名称 返回: self 返回类型: LinkItem
-
set_primary_keys(value)¶ 设置外表数据集中用于关联的字段
参数: value (list[str]) -- 外表数据集中用于关联的字段 返回: self 返回类型: LinkItem
-
to_dict()¶ 将当前对象的信息输出到dict中
返回类型: dict
-
to_json()¶ 将当前对象信息输出到 json 字符串中,具体查看 to_dict.
返回类型: str
-
class
iobjectspy.data.SpatialIndexInfo(index_type=None)¶ 基类:
object空间索引信息类。该类提供了创建空间索引的所需信息,包括空间索引的类型、叶结点个数、图幅字段、图幅宽高和多级网格的大小等信息。
构造数据集空间索引信息类。
参数: index_type (SpatialIndexType or str) -- 数据集空间索引类型 -
from_dict(values)¶ - 从 dict 中读取 SpatialIndexInfo 信息
参数: values (dict) -- 返回: self 返回类型: SpatialIndexInfo
-
grid_center¶ Point2D -- 网格索引的中心点。一般为数据集的中心点。
-
grid_size0¶ float -- 多级网格索引的第一层网格的大小
-
grid_size1¶ float -- 多级网格索引的第二层网格的大小
-
grid_size2¶ float -- 多级网格索引的第三层网格的大小
-
leaf_object_count¶ int -- R 树空间索引中叶结点的个数
-
static
make_from_dict(values)¶ 从 dict 中读取信息构造 SpatialIndexInfo 对象。
参数: values (dict) -- 返回类型: SpatialIndexInfo
-
static
make_mgrid(center, grid_size0, grid_size1, grid_size2)¶ 构建多级网格索引
多级网格索引,又叫动态索引。 多级网格索引结合了 R 树索引与四叉树索引的优点,提供非常好的并发编辑支持,具有很好的普适性。若不能确定数据适用于哪种空间索引,可为其建立多级 网格索引。采用划分多层网格的方式来组织管理数据。网格索引的基本方法是将数据集按照一定的规则划分成相等或不相等的网格,记录每一个地理对象所占的 网格位置。在 GIS 中常用的是规则网格。当用户进行空间查询时,首先计算出用户查询对象所在的网格,通过该网格快速查询所选地理对象,可以优化查询操作。
参数: - center (Point2D) -- 指定的网格中心点
- grid_size0 (float) -- 一级网格的大小。单位与数据集同
- grid_size1 (float) -- 二级网格的大小。单位与数据集同
- grid_size2 (float) -- 三级网格的大小。单位与数据集同
返回: 多级网格索引信息
返回类型:
-
static
make_qtree(level)¶ 构建四叉树索引信息。 四叉树索引。四叉树是一种重要的层次化数据集结构,主要用来表达二维坐标下空间层次关系,实际上它是一维二叉树在二维空间的扩展。那么,四叉树索引 就是将一张地图四等分,然后再每一个格子中再四等分,逐层细分,直至不能再分。现在在 SuperMap 中四叉树最多允许分成13层。基于希尔伯特 (Hilbert)编码的排序规则,从四叉树中可确定索引类中每个对象实例的被索引属性值是属于哪个最小范围。从而提高了检索效率
参数: level (int) -- 四叉树的层级,最大为13级 返回: 四叉树索引信息 返回类型: SpatialIndexInfo
-
static
make_rtree(leaf_object_count)¶ 构建 R 树索引信息。 R 树索引是基于磁盘的索引结构,是 B 树(一维)在高维空间的自然扩展,易于与现有数据库系统集成,能够支持各种类型的空间查询处理操作,在实践中得 到了广泛的应用,是目前最流行的空间索引方法之一。R 树空间索引方法是设计一些包含空间对象的矩形,将一些空间位置相近的目标对象,包含在这个矩形 内,把这些矩形作为空间索引,它含有所包含的空间对象的指针。
在进行空间检索的时候,首先判断哪些矩形落在检索窗口内,再进一步判断哪些目标是被检索的内容。这样可以提高检索速度。
参数: leaf_object_count (int) -- R 树空间索引中叶结点的个数 返回: R 树索引信息 返回类型: SpatialIndexInfo
-
static
make_tile(tile_width, tile_height)¶ 构建图幅索引信息。 在 SuperMap 中根据数据集的某一属性字段或根据给定的一个范围,将空间对象进行分类,通过索引进行管理已分类的空间对象,以此提高查询检索速度
参数: - tile_width (float) -- 图幅宽度
- tile_height (float) -- 图幅高度
返回: 图幅索引信息
返回类型:
-
quad_level¶ int -- 四叉树索引的层级
-
set_grid_center(value)¶ 设置网格索引的中心点。一般为数据集的中心点。
参数: value (Point2D) -- 网格索引的中心点 返回: self 返回类型: SpatialIndexInfo
-
set_grid_size0(value)¶ 设置多级格网索引中第一级格网的大小。
参数: value (float) -- 多级格网索引中第一级格网的大小。 返回: self 返回类型: SpatialIndexInfo
-
set_grid_size1(value)¶ 设置多级网格索引的第二级索引网格的大小。单位与数据集的单位一致
参数: value (float) -- 多级网格索引的第二级索引网格的大小 返回: self 返回类型: SpatialIndexInfo
-
set_grid_size2(value)¶ 设置多级格网索引中第三级格网的大小。
参数: value (float) -- 三级网格的大小。单位与数据集同 返回: self 返回类型: SpatialIndexInfo
-
set_leaf_object_count(value)¶ 设置 R 树空间索引中叶结点的个数。
参数: value (int) -- R 树空间索引中叶结点的个数 返回: self 返回类型: SpatialIndexInfo
-
set_quad_level(value)¶ 设置四叉树索引的层级,最大值为13
参数: value (int) -- 四叉树索引的层级 返回: self 返回类型: SpatialIndexInfo
-
set_tile_height(value)¶ 设置空间索引的图幅高度。单位与数据集范围的单位一致
参数: value (float) -- 空间索引的图幅高度 返回: self 返回类型: SpatialIndexInfo
-
set_tile_width(value)¶ 设置空间索引的图幅宽度。单位与数据集范围的单位一致。
参数: value (float) -- 空间索引的图幅宽度 返回: self 返回类型: SpatialIndexInfo
-
set_type(value)¶ 设置空间索引类型
参数: value (SpatialIndexType or str) -- 空间索引类型 返回: self 返回类型: SpatialIndexInfo
-
tile_height¶ float -- 空间索引的图幅高度
-
tile_width¶ float -- 空间索引的图幅宽度
-
to_dict()¶ 将当前对象输出到 dict 中
返回类型: dict
-
type¶ SpatialIndexType -- 空间索引的类型
-
-
class
iobjectspy.data.QueryParameter(attr_filter=None, cursor_type=CursorType.DYNAMIC, has_geometry=True, result_fields=None, order_by=None, group_by=None)¶ 基类:
object查询参数类。 用于描述一个条件查询的限制条件,如所包含的 SQL 语句,游标方式,空间数据的位置关系条件设定等。条件查询,是查询满足一定条件的所 有要素的记录,其查询得到的结果是记录集。查询参数类是用来设置条件查询的查询条件从而得到记录集。条件查询包括两种最主要的查询方式,一种为 SQL 查询,又称属性查询,即通过构建包含属性字段、运算符号和数值的 SQL 条件语句来选择记录,从而得到记录集;另一种为空间查询,即根据要素间地理或空间 的关系来查询记录来得到记录集。
QueryParameter 包含以下参数:
- attribute_filter : str
查询所构建的 SQL 条件语句,即 SQL WHERE clause 语句。SQL 查询又称为属性查询,是通过一个或多个 SQL 条件语句来查询记录。 SQL 语句是包含属性字段、运算符号和数值的条件语句。例如,你希望查询一个商业区内去年的年销售额超过30万的服装店,则构建的 SQL 查询语句为:
>>> attribute_filter = 'Sales > 30,0000 AND SellingType = ‘Garment’'
对于不同引擎的数据源,不同函数的适用情况及函数用法有所不同,对于数据库型数据源(Oracle Plus、SQL Server Plus、PostgreSQL 和 DB2 数据源),函数的用法请参见数据库相关文档。
- cursor_type : CursorType
查询所采用的游标类型。SuperMap 支持两种类型的游标,分别为动态游标和静态游标。使用动态游标查询时,记录集会动态的刷新,耗费很多的资源, 而当使用静态游标时,查询的为记录集的静态副本,效率较高。推荐在查询时使用静态游标,使用静态游标获得的记录集是不可编辑的。 详细信息请参见 CursorType 类型。 默认使用 DYNAMIC 类型。
- has_geometry : bool
查询结果是否包含几何对象字段。 若查询时不取空间数据,即只查询属性信息,则在返回的 Recordset 中,凡是对记录集的空间对象进行操作的方法, 都将无效,例如,调用
Recordset.get_geometry()将返回空。
- result_fields : list of str
设置查询结果字段集合。对于查询结果的记录集中,可以设置其中所包含的字段,如果为空,则查询所有字段。
- order_by : list of str
SQL 查询排序的字段。 对于 SQL 查询得到的记录集中的各记录,可以根据指定的字段进行排序,并可以指定为升序排列或是降序排列,其中 asc 表示升序,desc 表示降序。用于排序的字段必须为数值型。例如按 SmID 降序排序,可以设置为:
>>> query_paramater.set_order_by(['SmID desc'])
- group_by : list of str
SQL 查询分组条件的字段。对于 SQL 查询得到的记录集中的各字段,可以根据指定的字段进行分组,指定的字段值相同的记录将被放置在一起。 注意:
- 空间查询不支持 group_by ,否则可能导致空间查询的结果不正确
- 只有 cursor_type 为 STATIC 时, group_by 才有效
- spatial_query_mode : SpatialQueryMode
空间查询模式
- spatial_query_object : DatasetVector or Recordset or Geometry or Rectangle or Point2D
空间查询的搜索对象。 若搜索对象是数据集或是记录集类型,则必须同被搜索图层对应的数据集的地理坐标系一致。 当搜索数据集/记录集中存在对象重叠的情况时,空间查询的结果可能不正确,建议采用遍历搜索数据集/记录集,逐个使用单对象查询的方式进行空间查询。
- time_conditions : list of TimeCondition
时空模型查询条件。具体查看
TimeCondition说明。
- link_items : list of LinkItem
关联查询的信息。当被查询的矢量数据集有相关联的外部表时,查询得到的结果中会包含相关联的外部表中满足条件的记录。具体查看
LinkItem说明
- join_items: list of JoinItem
连接查询的信息。当被查询的矢量数据集有相连接的外部表时,查询得到的结果中会包含相连接的外部表中满足条件的记录。具体查看
JoinItem说明
- 示例::
# 进行 SQL 查询
>>> parameter = QueryParameter('SmID < 100', 'STATIC', False) >>> ds = Datasource.open('E:/data.udb') >>> dt = ds['point'] >>> rd = dt.query(parameter) >>> print(rd.get_record_count()) 99 >>> rd.close()
# 进行空间查询
>>> geo = dt.get_geometries('SmID = 1')[0] >>> query_geo = geo.create_buffer(10, dt.prj_coordsys, 'meter') >>> parameter.set_spatial_query_mode('contain').set_spatial_query_object(query_geo) >>> rd2 = dt.query(parameter) >>> print(rd2.get_record_count()) 10 >>> rd2.close()
-
attribute_filter¶ str -- 查询所构建的 SQL 条件语句,即 SQL WHERE clause 语句。
-
cursor_type¶ CursorType -- 查询所采用的游标类型
-
from_dict(values)¶ 从 dict 中读取查询参数
参数: values (dict) -- 包含查询参数的 dict 对象。具体查看 to_dict()返回: self 返回类型: QueryParameter
-
static
from_json(value)¶ 从 json 字符串中构造数据集查询参数对象
参数: value (str) -- json 字符串 返回类型: QueryParameter
-
group_by¶ list[str] -- SQL 查询分组条件的字段
-
has_geometry¶ bool -- 查询结果是否包含几何对象字段
-
join_items¶ list[JoinItem] -- 连接查询的信息。当被查询的矢量数据集有相连接的外部表时,查询得到的结果中会包含相连接的外部表中满足条件的记录。具体查看
JoinItem说明
-
link_items¶ list[LinkItem] -- 关联查询的信息。当被查询的矢量数据集有相关联的外部表时,查询得到的结果中会包含相关联的外部表中满足条件的记录。具体查看
LinkItem说明
-
static
make_from_dict(values)¶ 从 dict 中构造数据集查询参数对象
参数: values (dict) -- 包含查询参数的 dict 对象。具体查看 to_dict()返回类型: QueryParameter
-
order_by¶ list[str] -- SQL 查询排序的字段。
-
result_fields¶ list[str] -- 查询结果字段集合。对于查询结果的记录集中,可以设置其中所包含的字段,如果为空,则查询所有字段。
-
set_attribute_filter(value)¶ 设置属性查询条件
参数: value (str) -- 属性查询条件 返回: self 返回类型: QueryParameter
-
set_cursor_type(value)¶ 设置查询所采用的游标类型。默认为 DYNAMIC
参数: value (CursorType or str) -- 游标类型 返回: self 返回类型: QueryParameter
-
set_group_by(value)¶ 设置 SQL 查询分组条件的字段。
参数: value (list[str]) -- SQL 查询分组条件的字段 返回: self 返回类型: QueryParameter
-
set_has_geometry(value)¶ 设置是否查询几何对象。如果设置为 False,将不会返回几何对象,默认为 True
参数: value (bool) -- 查询是否包含几何对象。 返回: self 返回类型: QueryParameter
-
set_join_items(value)¶ 设置连接查询的查询条件
参数: value (list[JoinItem]) -- 接查询的查询条件 返回: self 返回类型: QueryParameter
-
set_link_items(value)¶ 设置关联查询的查询条件
参数: value (list[LinkItem]) -- 关联查询的查询条件 返回: self 返回类型: QueryParameter
-
set_order_by(value)¶ 设置 SQL 查询排序的字段
参数: value (list[str]) -- SQL查询排序的字段 返回: self 返回类型: QueryParameter
-
set_result_fields(value)¶ 设置查询结果字段
参数: value (list[str]) -- 查询结果字段 返回: self 返回类型: QueryParameter
-
set_spatial_query_mode(value)¶ 设置空间查询模式,具体查看
SpatialQueryMode说明参数: value (SpatialQueryMode or str) -- 空间查询的查询模式。 返回: self 返回类型: QueryParameter
-
set_spatial_query_object(value)¶ 设置空间查询的搜索对象
参数: value (DatasetVector or Recordset or Geometry or Rectangle or Point2D) -- 空间查询的搜索对象 返回: self 返回类型: QueryParameter
-
set_time_conditions(value)¶ 设置时间字段进行时空查询的查询条件
参数: value (list[TimeCondition]) -- 时空查询的查询条件 返回: self 返回类型: QueryParameter
-
spatial_query_mode¶ SpatialQueryMode -- 空间查询模式。
-
spatial_query_object¶ DatasetVector or Recordset or Geometry or Rectangle or Point2D -- 空间查询的搜索对象。
-
time_conditions¶ list[TimeCondition] -- 时空模型查询条件。具体查看
TimeCondition说明。
-
to_dict()¶ 将数据集查询参数信息输出到 dict 中
返回类型: dict
-
to_json()¶ 将查询参数输出为 json 字符串
返回类型: str
-
class
iobjectspy.data.TimeCondition(field_name=None, time=None, condition=None, back_condition=None)¶ 基类:
object定义了单时间字段时空模型管理查询功能接口
构造时空模型查询条件对象
参数: - field_name (str) -- 字段名称
- time (datetime.datetime) -- 查询条件的时间
- condition (str) -- 查询时间的条件操作符。例如:>、<、>=、<=、=
- back_condition (str) -- 指定的后一个条件操作符,例如:and、or
-
back_condition¶ 指定的后一个条件操作符,例如:and、or
-
condition¶ str -- 查询时间的条件操作符。例如:>、<、>=、<=、=
-
field_name¶ str -- 字段名称
-
from_dict(values)¶ 从 dict 对象中读取 TimeCondition 信息。
参数: values (dict) -- 包含 TimeCondition 信息的 dict,具体参考 to_dict 返回类型: TimeCondition 返回类型: TimeCondition
-
static
from_json(value)¶ 从 json 字符串中构造 TimeCondition。
参数: value (str) -- json 字符串 返回类型: TimeCondition
-
static
make_from_dict(values)¶ 从 dict 对象中构造 TimeCondition 对象
参数: values (dict) -- 包含 TimeCondition 信息的 dict,具体参考 to_dict 返回类型: TimeCondition
-
set_back_condition(value)¶ 查询条件的后一个条件操作符。例如:and、or
参数: value (str) -- 查询条件的后一个条件操作符 返回: self 返回类型: TimeCondition
-
set_condition(value)¶ 设置查询条件的条件操作符。
参数: value (str) -- 查询条件的条件操作符,>、<、>=、<=、= 返回: self 返回类型: TimeCondition
-
set_field_name(value)¶ 设置查询条件的字段名
参数: value (str) -- 查询条件的字段名 返回: self 返回类型: TimeCondition
-
set_time(value)¶ 设置查询条件的时间值
参数: value (datetime.datetime) -- 时间值 返回: self 返回类型: TimeCondition
-
time¶ datetime.datetime -- 作为查询条件的时间
-
to_dict()¶ 将当前对象输出为 dict 对象
返回类型: dict
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
iobjectspy.data.combine_band(red_dataset, green_dataset, blue_dataset, out_data=None, out_dataset_name=None)¶ 三个单波段数据集合成RGB数据集
参数: - red_dataset (Dataset or str) -- 单波段数据集R。
- green_dataset (Dataset or str) -- 单波段数据集G
- blue_dataset (Dataset or str) -- 单波段数据集B
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源,为空时使用 red_dataset 数据集所在的数据源
- out_dataset_name (str) -- 合成RGB数据集的名称。
返回: 合成成功返回数据集对象或数据集名称,失败返回 None
返回类型:
-
class
iobjectspy.data.Recordset¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase记录集类。 通过此类,可以实现对矢量数据集中的数据进行操作。 数据源有文件型和数据库型,数据库型数据中空间几何信息和属性信息一体化存储,一个矢量数 据集对应一个 DBMS 表,其几何形状以及属性信息都一体化存储其中,表中的几何字段存储要素的空间几何信息。对于矢量数据集中的纯属性数据集,其中没有几 何字段,记录集为 DBMS 表的一个子集;而在文件型数据中空间几何信息和属性信息是分别存储的,记录集的应用可能比较让人费解,实际上,操作时是屏蔽掉文 件型和数据库型数据的区别,将数据都看成是一个空间信息和属性信息一体化存储的表,而记录集是从其中取出的用来操作的一个子集。记录集中的一条记录,即一 行,对应着一个要素,包含该要素的空间几何信息和属性信息。记录集中的一列对应一个字段的信息。
记录集可以直接从矢量数据集中获得一个记录集,有两种方法:用户可以通过
DatasetVector.get_recordset()方法直接从矢量数据集中返回 记录集,也可以通过查询语句返回记录集,所不同的是前者得到的记录集包含该类集合的全部空间几何信息和属性信息,而后者得到的是经过查询语句条件过滤的记录集。以下代码演示从记录集中读取数据以及批量写入数据到新的记录集中:
>>> dt = Datasource.open('E:/data.udb')['point'] >>> rd = dt.query_with_filter('SmID < 100 or SmID > 1000', 'STATIC') >>> all_points = [] >>> while rd.has_next(): >>> geo = rd.get_geometry() >>> all_points.append(geo.point) >>> rd.move_next() >>> rd.close() >>> >>> new_dt = dt.datasource.create_vector_dataset('new_point', 'Point', adjust_name=True) >>> new_dt.create_field(FieldInfo('object_time', FieldType.DATETIME)) >>> new_rd = new_dt.get_recordset(True) >>> new_rd.batch_edit() >>> for point in all_points: >>> new_rd.add(point, {'object_time': datetime.datetime.now()} ) >>> new_rd.batch_update() >>> print(new_rd.get_record_count()) >>> new_rd.close()
-
add(data, values=None)¶ 向记录集中新增一条记录。记录集必须开启编辑模式,具体查看
edit()和batch_edit()参数: 返回: 写入成功返回 True,否则返回 False
返回类型: bool
-
batch_edit()¶ 批量更新操作开始。批量更新操作完成后,需要使用
batch_update()来提交修改的记录。可以使用set_batch_record_max()修改 批量更新操作结果提交的最大记录数,具体查看set_batch_record_max()
-
batch_update()¶ 批量更新操作的统一提交。调用该方法后,之前进行的批量更新操作才会生效,同时更新状态将变为单条更新,如果需要之后的操作批量进行,还需再次调用
batch_edit()方法。
-
bounds¶ Rectangle -- 返回记录集的属性数据表中所有记录对应的几何对象的外接矩形。
-
close()¶ 释放记录集,记录集完成操作不再使用后必须释放记录集
-
dataset¶ DatasetVector -- 记录集所在的数据集
-
datasource¶ Datasource -- 记录集所在的数据源
-
delete()¶ 用于删除数据集中的当前记录,成功则返回 true。
返回类型: bool
-
delete_all()¶ 物理性删除指定记录集中的所有记录,即把记录从计算机的物理存储介质上删除,无法恢复。
返回类型: bool
-
dispose()¶ 释放记录集,记录集完成操作不再使用后必须释放记录集, 与 close 功能相同
-
edit()¶ 锁定并编辑记录集的当前记录,成功则返回 True。用该方法编辑后,一定要用
update()方法更新记录集,而且在update()之 前不能移动当前记录的位置,否则编辑失败,记录集也可能被损坏。返回类型: bool
-
field_infos¶ list[FieldInfo] -- 数据集的所有字段信息
-
get_batch_record_max()¶ int: 返回批量更新操作结果自动提交的最大记录数
-
get_field_count()¶ 获取字段数目
返回类型: int
-
get_id()¶ 返回数据集的属性表中当前记录对应的几何对象的 ID 号(即 SmID 字段的值)。
返回类型: int
-
get_query_parameter()¶ 获取当前记录集对应的查询参数
返回类型: QueryParameter
-
get_record_count()¶ 返回记录集中记录数目
返回类型: int
-
get_value(item)¶ 获取当前记录中指定的属性字段的字段值
参数: item (str or int) -- 字段名称或序号 返回类型: int or float or str or datetime.datetime or bytes or bytearray
-
get_values(exclude_system=True, is_dict=False)¶ 获取当前记录的属性字段值。
参数: - exclude_system (bool) -- 是否包含系统字段。所有 "Sm" 开头的字段都是系统字段。默认为 True
- is_dict (bool) -- 是否以 dict 形式返回,如果返回 dict,则 dict 的 key 为字段名称, value 为属性字段值。否则以 list 形式返回字段值。默认为 False
返回: 属性字段值
返回类型: dict or list
-
has_next()¶ 记录集是否还有下一条记录可以读取,如果有返回 True,否则返回 False
返回类型: bool
-
index_of_field(name)¶ 获取指定字段名称序号
参数: name (str) -- 字段名称 返回: 如果字段存在返回字段的序号,否则返回 -1 返回类型: int
-
is_bof()¶ 判断当前记录的位置是否在记录集中第一条记录的前面(当然第一条记录的前面是没有数据的),如果是返回 True;否则返回 False。
返回类型: bool
-
is_close()¶ 判断记录集是否已经被关闭。被关闭返回 True,否则返回 False。
返回类型: bool
-
is_empty()¶ 判断记录集中是否有记录。True 表示该记录集中无数据
返回类型: bool
-
is_eof()¶ 记录集是否到达末尾,如果到达末尾返回 True,否则返回 False
返回类型: bool
-
is_readonly()¶ 判断记录集是否是只读的,只读返回 True,否则返回 False
返回类型: bool
-
move(count)¶ 将当前记录位置移动 count 行,将该位置的记录设置为当前记录。成功返回 True。count 小于0表示向前移,大于0表示向后移动,等于0时不移动。如 果移动的行数太多,超出了 Recordset 的范围,将会返回 False,当前记录不移动。
参数: count (int) -- 移动的记录数 返回类型: bool
-
move_first()¶ 用于移动当前记录位置到第一条记录,使第一条记录成为当前记录。成功则返回 True。
返回类型: bool
-
move_last()¶ 用于移动当前记录位置到最后一条记录,使最后一条记录成为当前记录。成功则返回 True
返回类型: bool
-
move_next()¶ 动当前记录位置到下一条记录,使该记录成为当前记录。成功则返回 True,否则返回 False
返回类型: bool
-
move_prev()¶ 移动当前记录位置到上一条记录,使该记录成为当前记录。成功则返回 True。
返回类型: bool
-
move_to(position)¶ 用于移动当前记录位置到指定的位置,将该指定位置的记录作为当前记录。成功则返回 True。
参数: position (int) -- 移动到的位置,即第几条记录 返回类型: bool
-
refresh()¶ 刷新当前记录集,用来反映数据集中的变化。如果成功返回 True,否则返回 False。此方法与
update()的区别在于 update 方法是提交 修改结果,而 refresh 方法是动态刷新记录集,在多用户并发操作时,为了动态显示数据集中的变化,经常用到 refresh 方法。返回类型: bool
-
seek_id(value)¶ 在记录中搜索指定 ID 号的记录,并定位该记录为当前记录。成功则返回 true,否则返回 false
参数: value (int) -- 要搜索的 ID 号 返回类型: bool
-
set(data, values=None)¶ 修改当前记录。记录集必须开启编辑模式,具体查看
edit()和batch_edit()参数: 返回: 写入成功返回 True,否则返回 False
返回类型: bool
-
set_batch_record_max(count)¶ 设置批量更新操作结果提交的最大记录数,当所有需要更新的记录批量更新完成后,在提交更新结果时,如果更新的记录数超过了这个最大记录数时,系统将分 批提交更新的结果,即每次提交最大记录数目个记录,直到所有的更新记录都提交完毕。例如,如果设定提交的最大记录数为1000,而需要更新的记录数为3800, 那么批量更新记录后,在提交结果时,系统将分四次提交更新结果,即第一次提交1000条记录,第二次1000条,第三次1000条,第四次800条。
参数: count (int) -- 批量更新操作结果提交的最大记录数。
-
set_value(item, value)¶ 写入字段值到指定的字段中。记录集必须开启编辑模式,具体查看
edit()和batch_edit()参数: - item (str or int) -- 字段名称或序号,不能为系统字段。
- value (bool or int or float or datetime.datetime or bytes or bytearray or str) --
待写入的字段值。字段类型与值类型对应关系为:
- BOOLEAN: bool
- BYTE: int
- INT16: int
- INT32: int
- INT64: int
- SINGLE: float
- DOUBLE: float
- DATETIME: datetime.datetime 或 int(时间戳,单位为秒)或满足 ”%Y-%m-%d %H:%M:%S“ 格式的 字符串
- LONGBINARY: bytearray or bytes
- TEXT: str
- CHAR: str
- WTEXT: str
- JSONB: str
返回: 成功返回 True,否则返回 False
返回类型: bool
-
set_values(values)¶ 设置字段值。记录集必须开启编辑模式,具体查看
edit()和batch_edit()参数: values (dict) -- 要写入的属性字段值。必须是 dict,dict 的键值为字段名称,dict 的值为字段值 返回: 返回成功写入的字段数目 返回类型: int
-
statistic(item, stat_mode)¶ 通过字段名称或序号,对指定字段进行诸如最大值、最小值、平均值,总和,标准差和方差等方式的统计。
参数: - item (str or int) -- 字段名称或序号
- stat_mode (StatisticMode or str) -- 统计方式
返回: 统计结果。
返回类型: float
-
to_json()¶ 将当前记录集的数据集和查询参数输出为 json 字符串。注意,使用 Recordset 的 to_json 只保存数据集信息的查询参数,只适用于使用 DatasetVector 入口查询得到的结果记录集,包括
DatasetVector.get_recordset(),DatasetVector.query(),DatasetVector.query_with_bounds(),DatasetVector.query_with_distance(),DatasetVector.query_with_filter()和DatasetVector.query_with_ids()。 如果是由其他功能内部查询得到的记录集,可能无法完全确保查询参数的是否与查询时输入的查询参数是否一致。返回类型: str
-
-
exception
iobjectspy.data.DatasourceReadOnlyError(message)¶ 基类:
Exception数据源为只读时的异常。在进行某些功能需要写入数据到数据源或修改数据源中数据,而数据源为只读时将会返回该异常信息。
-
exception
iobjectspy.data.DatasourceOpenedFailedError(message)¶ 基类:
Exception数据源打开失败异常
-
exception
iobjectspy.data.ObjectDisposedError(message)¶ 基类:
RuntimeError对象被释放后的异常对象。在检查 Python 实例中绑定的 java 对象被释放后会抛出该异常。
-
exception
iobjectspy.data.DatasourceCreatedFailedError(message)¶ 基类:
Exception数据源创建失败异常
-
class
iobjectspy.data.FieldInfo(name=None, field_type=None, max_length=None, default_value=None, caption=None, is_required=False, is_zero_length_allowed=True)¶ 基类:
object字段信息类。字段信息类用来存储字段的名称、类型、默认值以及长度等相关信息。 每一个字段对应一个 FieldInfo。对于矢量数据集的每一个字段,只有字段的 别名(caption)可以被修改,其他属性的修改需要依据具体引擎是否支持。
构造字段信息对象
参数: - name (str) -- 字段名称。字段的名称只能由数字、字母和下划线组成,但不能以数字或下划线开头;用户新建字段时,字段名称不能以 SM 作为前 缀,以 SM 作为前缀的都是 SuperMap 系统字段,另外,字段的名称不能超过30个字符,且字段的名称不区分大小写。名称用于 唯一标识该字段,所以字段不可重名。
- field_type (FieldType or str) -- 字段类型
- max_length (int) -- 字段值的最大长度,只对文本字段有效
- default_value (int or float or datetime.datetime or str or bytes or bytearray) -- 字段的默认值
- caption (str) -- 字段别名
- is_required (bool) -- 是否是必填字段
- is_zero_length_allowed (bool) -- 是否允许零长度。只对文本类型(TEXT,WTEXT,CHAR)字段有效
-
caption¶ str -- 字段别名
-
default_value¶ int or float or datetime.datetime or str or bytes or bytearray -- 字段的默认值
-
from_dict(values)¶ 从 dict 对象中读取字段信息
参数: values (dict) -- 包含 FieldInfo 字段信息的 dict 对象 返回: self 返回类型: FieldInfo
-
is_required¶ bool -- 字段是否为必填字段
-
is_system_field()¶ 判断当前对象是否是系统字段。对于所有以 Sm 开头(不区分大小写)的字段都是系统系统。
返回类型: bool
-
is_zero_length_allowed¶ bool -- 是否允许零长度。只对文本类型(TEXT,WTEXT,CHAR)字段有效
-
static
make_from_dict(values)¶ 从 dict 对象中构造一个新的 FieldInfo 对象
参数: values (dict) -- 包含 FieldInfo 字段信息的 dict 对象 返回类型: FieldInfo
-
max_length¶ int -- 字段值的最大长度,只对文本字段有效
-
name¶ str -- 字段名称,字段的名称只能由数字、字母和下划线组成,但不能以数字或下划线开头;用户新建字段时,字段名称不能以 SM 作为前缀,以 SM 作为前 缀的都是 SuperMap 系统字段,另外,字段的名称不能超过30个字符,且字段的名称不区分大小写。名称用于唯一标识该字段,所以字段不可重名。
-
set_caption(value)¶ 设置此字段的别名。别名可以不唯一,即不同的字段可以有相同的别名,而名称是用来唯一标识一个字段的,所以不可重名
参数: value (str) -- 字段别名。 返回: self 返回类型: FieldInfo
-
set_default_value(value)¶ 设置字段的默认值。当添加一条记录时,如果该字段未被赋值,则以该默认值作为该字段的值。
参数: value (bool or int or float or datetime.datetime or str or bytes or bytearray) -- 字段的默认值 返回: self 返回类型: FieldInfo
-
set_name(value)¶ 设置字段名称。字段的名称只能由数字、字母和下划线组成,但不能以数字或下划线开头;用户新建字段时,字段名称不能以 SM 作为前缀,以 SM 作为前缀 的都是 SuperMap 系统字段,另外,字段的名称不能超过30个字符,且字段的名称不区分大小写。名称用于唯一标识该字段,所以字段不可重名。
参数: value (str) -- 字段名称 返回: self 返回类型: FieldInfo
-
set_zero_length_allowed(value)¶ 设置字段是否允许零长度。只对文本字段有效。
参数: value (bool) -- 字段是否允许零长度。允许字段零长度设置为True,否则为False。默认值为True。 返回: self 返回类型: FieldInfo
-
to_dict()¶ 将当前对象输出到 dict 对象中
返回类型: dict
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
type¶ FieldType -- 字段类型
-
class
iobjectspy.data.Point2D(x=None, y=None)¶ 基类:
object二维点对象,使用两个浮点数分别表示 x 和 y 轴的位置。
使用 x 和 y 值构造二维点对象。
参数: - x (float) -- x 坐标轴值
- y (float) -- y 坐标值
-
equal(other, tolerance=0.0)¶ 判断当前点与指定点在容限范围内是否相等
参数: - other (Point2D) -- 待判断的点
- tolerance (float) -- 容限值
返回类型: bool
-
static
make(p)¶ 构造一个二维点对象
参数: p (tuple[float,float] or list[float,float] or GeoPoint or Point2D or dict) -- x 和 y 值 返回类型: Point2D
-
to_dict()¶ 输出为 dict 对象
返回类型: dict
-
to_json()¶ 将当前二维点对象输出为 json 字符串
返回类型: str
-
class
iobjectspy.data.Point3D(x=None, y=None, z=None)¶ 基类:
object-
static
make(p)¶ 构造一个三维点对象
参数: p (tuple[float,float,float] or list[float,float,float] or GeoPoint3D or Point3D or dict) -- x,y 和 z 值 返回类型: Point3D
-
static
make_from_dict(value)¶ 从 dict 中读取点信息构造三维点坐标
参数: value (dict) -- 包含 x、y 和z值的 dict 返回: self 返回类型: Point3D
-
to_dict()¶ 输出为 dict 对象
返回类型: dict
-
to_json()¶ 将当前三维点对象输出为 json 字符串
返回类型: str
-
static
-
class
iobjectspy.data.PointM(x=None, y=None, m=None)¶ 基类:
object-
static
make(p)¶ 构造一个路由点对象
参数: p (tuple[float,float,float] or list[float,float,float] or PointM or dict) -- x,y 和 m 值 返回类型: PointM
-
static
make_from_dict(value)¶ 从 dict 中读取点信息构造路由点坐标
参数: value (dict) -- 包含 x、y 和m值的 dict 返回: self 返回类型: PointM
-
to_dict()¶ 输出为 dict 对象
返回类型: dict
-
to_json()¶ 将当前路由点对象输出为 json 字符串
返回类型: str
-
static
-
class
iobjectspy.data.Rectangle(left=None, bottom=None, right=None, top=None)¶ 基类:
object矩形对象使用四个浮点数表示一个矩形的范围。其中 left 代表 x 方向的最小值,top 代表 y 方向的最大值, right 代表 x 方向的最大值,bottom 代表 y 方向的最小值。当使用矩形表示一个地理范围时,通常 left 表示经度的最小值, right 表示经度的最大值,top 表示纬度的最大值,bottom表示维度的最小值 该类的对象通常用于确定范围,可用来表示几何对象的最小外接矩形、地图窗口的可视范围,数据集的范围等,另外在进行矩形选择,矩形查询等时也会用到此类的对象。
-
__eq__(other)¶ 判断当前矩形对象与指定矩形对象是否相同。只有当上下左右边界完全相同时才能判断为相同。
参数: other (Rectangle) -- 待判断的矩形对象。 返回: 如果当前对象与矩形对象相同,返回True,否则返回False 返回类型: bool
-
__getitem__(item)¶ 当矩形对象使用四个二维坐标点描述具体的坐标位置时,返回点坐标值。
参数: item (int) -- 0,1,2,3值 返回: 根据 item 的值,分别返回左上点,右上点,右下点,左下点 返回类型: float
-
__len__()¶ 返回: 当矩形对象使用四个二维坐标点描述具体的坐标位置时,返回点的数目。固定为4. 返回类型: int
-
bottom¶ float -- 返回当前矩形对象下边界的坐标值
-
center¶ Point2D -- 返回当前矩形对象的中心点
-
contains(item)¶ 判断一个点对象或矩形矩形是否在当前矩形对象内部
参数: item (Point2D) -- 二维点对象(含有x和y两个属性)或矩形对象。矩形对象要求非空(矩形对象是否为空,可以参考 @Rectangle.is_empty) 返回: 待判断的对象在当前矩形内部返回 True,否则为 False 返回类型: bool >>> rect = Rectangle(1.0, 20, 2.0, 3) >>> rect.contains(Point2D(1.1,10)) True >>> rect.contains(Point2D(0,0)) False >>> rect.contains(Rectangle(1.0,10,1.5,5)) True
-
from_dict(value)¶ 从一个字典对象中读取矩形对象的边界值。读取成功后将会覆盖矩形对象现有的值。
参数: value (dict) -- 字典对象,字典对象的keys 必须有 'left', 'top', 'right', 'bottom' 返回: 返回当前对象,self 返回类型: Rectangle
-
static
from_json(value)¶ 从 json 字符串中构造一个矩形对象。
参数: value (str) -- json 字符串 返回: 矩形对象 返回类型: Rectangle >>> s = '{"rectangle": [1.0, 1.0, 2.0, 2.0]}' >>> Rectangle.from_json(s) (1.0, 1.0, 2.0, 2.0)
-
has_intersection(item)¶ 判断一个二维点、矩形对象或空间几何对象是否与当前矩形对象相交。待判断的对象只要与当前矩形对象有相交区域或者接触都会判定为相交。
参数: item (Point2D) -- 待判断的二维点对象、矩形对象和空间几何对象,空间几何对象支持点线面和文本对象。 返回: 判断相交返回True,否则返回False 返回类型: bool >>> rc = Rectangle(1,2,2,1) >>> rc.has_intersection(Rectangle(0,1.5,1.5,0)) True >>> rc.has_intersection(GeoLine([Point2D(0,0),Point2D(3,3)])) True
-
height¶ float -- 返回当前矩形对象的高度值
-
inflate(dx, dy)¶ 对当前矩形对象在垂直(y方向)和水平(x方向)进行缩放。缩放完成后将会改变当前对象上下或左右值,但中心点不变。
参数: - dx (float) -- 水平方向缩放量
- dy (float) -- 垂直方向缩放量
返回: self
返回类型: >>> rc = Rectangle(1,2,2,1) >>> rc.inflate(3,None) (-2.0, 1.0, 5.0, 2.0) >>> rc.left == -2 True >>> rc.right == 5 True >>> rc.top == 2 True >>> rc.inflate(0, 2) (-2.0, -1.0, 5.0, 4.0) >>> rc.left == -2 True >>> rc.top == 4 True
-
intersect(rc)¶ 指定矩形对象与当前对象求交集,并改变当前矩形对象。
参数: rc (Rectangle) -- 用于进行求交操作的矩形 返回: 当前对象,self 返回类型: Rectangle >>> rc = Rectangle(1,1,2,2) >>> rc.intersect(Rectangle(0,0,1.5,1.5)) (1.0, 1.0, 1.5, 1.5)
-
is_empty()¶ 判断矩形对象是否为空,当矩形的上下左右边界值有一个为 None 时,矩形为空。当矩形的上下左右边界值有 一个为 -1.7976931348623157e+308 时矩形为空
返回: 矩形为空,返回True,否则返回False 返回类型: bool
-
left¶ float -- 返回当前矩形对象左边界的坐标值
-
static
make(value)¶ 构造一个二维矩形对象
参数: value (Rectangle or list or str or dict) -- 含有二维矩形对象左、下、右、上的信息 返回: 返回类型:
-
static
make_from_dict(value)¶ 从一个字典对象中构造出矩形对象。
参数: value -- 字典对象,字典对象的keys 必须有 'left', 'top', 'right', 'bottom' 返回类型: Rectangle
-
offset(dx, dy)¶ 将此矩形在 x 方向平移 dx,在 y 方向平移 dy,此方法将改变当前对象。
参数: - dx (float) -- 水平偏移该位置的量。
- dy (float) -- 垂直偏移该位置的量。
返回: self
返回类型: >>> rc = Rectangle(1,2,2,1) >>> rc.offset(2,3) (3.0,4.0, 4.0, 5.0)
-
points¶ tuple[Point2D] -- 获取矩形四个顶点坐标值,返回一个4个二维点(Point2D)的元组。其中第一个点表示左上点,第二个点表示右上点,第三个点表示右下点,第四个点表示左下点。
>>> rect = Rectangle(1.0, 3, 2.0, 20) >>> points = rect.points >>> len(points) 4 >>> points[0] == Point2D(1.0,20) True >>> points[2] == Point2D(2.0,3) True
-
right¶ float -- 返回当前矩形对象右边界的坐标值
-
set_bottom(value)¶ 设置当前矩形对象的下边界值。如果上下边界值都有效,当下边界值大于上边界值,会将上下边界值互换
参数: value (float) -- 下边界值 返回: self 返回类型: Rectangle
-
set_left(value)¶ 设置当前矩形对象的左边界值。如果左右边界值都有效,当左边界值大于右边界值,会将左右边界值互换
参数: value (float) -- 左边界值 返回: self 返回类型: Rectangle
-
set_right(value)¶ 设置当前矩形对象的右边界值。如果左右边界值都有效,当左边界值大于右边界值,会将左右边界值互换
参数: value (float) -- 右边界值 返回: self 返回类型: Rectangle >>> rc = Rectangle(left=10).set_right(5.0) >>> rc.right, rc.left (10.0, 5.0)
-
set_top(value)¶ 设置当前矩形对象的上边界值。如果上下边界值都有效,当下边界值大于上边界值,会将上下边界值互换
参数: value (float) -- 上边界值 返回: self 返回类型: Rectangle >>> rc = Rectangle(bottom=10).set_top(5.0) >>> rc.top, rc.bottom (10.0, 5.0)
-
to_dict()¶ 将矩形对象返回为一个字典对象
返回类型: dict
-
to_json()¶ 得到矩形对象的 json 字符串形式
返回类型: str >>> Rectangle(1,1,2,2).to_json() '{"rectangle": [1.0, 1.0, 2.0, 2.0]}'
-
to_region()¶ 用一个几何面对象表示矩形对象所表示的范围。返回的面对象的点坐标顺序为:第一个点表示左上点,第二个点表示右上点,第三个点表示右下点, 第四个点表示左下点,第五个点与第一个点坐标相同。
返回: 返回由矩形范围所表示的几何面对象 返回类型: GeoRegion >>> rc = Rectangle(2.0, 20, 3.0, 10) >>> geoRegion = rc.to_region() >>> print(geoRegion.area) 10.0
-
to_tuple()¶ 得到一个元组对象,元组对象的元素分别为矩形的左、下、右、上
返回类型: tuple
-
top¶ float -- 返回当前矩形对象上边界的坐标值
-
union(rc)¶ 当前矩形对象合并指定的矩形对象,合并完成后,矩形的范围将会是合并前的矩形与指定的矩形对象的并集。
参数: rc (Rectangle) -- 指定的用于合并的矩形对象 返回: self 返回类型: Rectangle >>> rc = Rectangle(1,1,2,2) >>> rc.union(Rectangle(0,-2,1,0)) (0.0, -2.0, 2.0, 2.0)
-
width¶ float -- 返回当前矩形对象的宽度值
-
-
class
iobjectspy.data.Geometry¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase几何对象基类,用于表示地理实体的空间特征。并提供相关的处理方法。根据地理实体的空间特征不同,分别用点(GeoPoint),线(GeoLine),面(GeoRegion)等加以描述
-
bounds¶ Rectangle -- 返回几何对象的最小外接矩形。点对象的最小外接矩形退化为一个点,即矩形的左边界坐标值等于其右边界坐标值,上边界坐标值等于其 下边界的坐标值,分别为该点的 x 坐标和 y 坐标。
-
static
from_geojson(geojson)¶ 从 geojson 中读取信息构造一个几何对象
参数: geojson (str) -- geojson 字符串 返回: 几何对象 返回类型: Geometry
-
from_xml(xml)¶ 根据传入的 XML 字符串重新构造几何对象。该 XML 必须符合 GML3.0 规范。 调用该方法时,首先将该几何对象的原始数据清空,然后根据传入的 XML 字符串重新构造该几何对象。 GML (Geography Markup Language)即地理标识语言, GML 能够表示地理空间对象的空间数据和非空间属性数据。GML 是基于 XML 的空间信息编码 标准,由开放式地理信息系统协会 OpenGIS Consortium (OGC) 提出,得到了许多公司的大力支持,如 Oracle、Galdos、MapInfo、CubeWerx 等。 GML 作为一个空间数据编码规范,提供了一套基本的标签、公共的数据模型,以及用户构建应用模式(GML Application Schemas)的机制。
参数: xml (str) -- XML 格式的字符串 返回: 构造成功返回 True,否则返回 False。 返回类型: bool
-
hit_test(point, tolerance)¶ 测试在指定容限允许的范围内,指定的点是否在几何对象的范围内。即判断以测试点为圆心,以指定的容限为半径的圆是否与该几何对象有交集,若有交集, 则返回 True;否则返回 False。
参数: - point (Point2D) -- 测试点
- tolerance (float) -- 容限值,单位与数据集的单位相同
返回类型: bool
-
id¶ int -- 返回几何对象的 ID
-
is_empty()¶ 判断几何对象是否为空值,不同的几何对象的是否为空的条件各异。
返回类型: bool
-
linear_extrude(height=0.0, twist=0.0, scaleX=1.0, scaleY=1.0, bLonLat=False)¶ 线性拉伸,支持二维和三维矢量面,二三维圆,GeoRectangle :param height: 拉伸高度 :param twist: 旋转角度 :param scaleX: 绕X轴缩放 :param scaleY: 绕Y轴缩放 :param bLonLat: 是否是经纬度 :return: 返回GeoModel3D对象
-
offset(dx, dy)¶ 将此几何对象偏移指定的量。
参数: - dx (float) -- 偏移 X 坐标的量
- dy (float) -- 偏移 Y 坐标的量
返回: self
返回类型:
-
resize(rc)¶ 缩放此几何对象,使其最小外接矩形等于指定的矩形对象。 对于几何点,该方法只改变其位置,将其移动到指定的矩形的中心点;对于文本对象,该方法将缩放文本大小。
参数: rc (Rectangle) -- 调整大小后几何对象的范围。
-
rotate(base_point, angle)¶ 以指定点为基点将此几何对象旋转指定角度,逆时针方向为正方向,角度以度为单位。
参数: - base_point (Point2D) -- 旋转的基点。
- angle (float) -- 旋转的角度,单位为度
-
rotate_extrude(angle, slices)¶ 旋转拉伸,支持二维和三维矢量面,必须在平面坐标系下构建且不能跨Y轴 :param angle: 旋转角度 :return: 返回GeoModel3D对象
-
set_empty()¶ 清空几何对象中的空间数据,但几何对象的标识符和几何风格保持不变。
-
to_geojson()¶ 将当前对象信息以 geojson 格式返回。只支持点、线和面对象。
返回类型: str
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
to_xml()¶ 根据 GML 3.0 规范,将该几何对象的空间数据输出为 XML 字符串。 注意:几何对象输出的 XML 字符串只含有该几何对象的地理坐标值,不含有该几何对象的风格和 ID 等信息。
返回类型: str
-
type¶ GeometryType -- 返回几何对象类型
-
-
class
iobjectspy.data.GeoPoint(point=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry点几何对象类。 该类一般用于描述点状地理实体。Point2D 和 GeoPoint 都可用来表示二维点,所不同的是 GeoPoint 描述的是地物实体,而 Point2D 描述的是一个位 置点;当赋予 GeoPoint 不同的几何风格,即可用于表示不同的地物实体,而 Point2D 则是广泛用于定位的坐标点
构造一个点几何对象。
参数: point (Point2D or GeoPoint or tuple[float] or list[float]) -- 点对象 -
bounds¶ Rectangle -- 获取点几何对象的地理范围
-
create_buffer(distance, prj=None, unit=None)¶ 在当前位置点构造一个缓冲区对象
参数: - distance (float) -- 缓冲区半径。如果设置了 prj 和 unit,将使用 unit 的单位作为缓冲区半径的单位。
- prj (PrjCoordSys) -- 描述点几何对象的投影信息
- unit (Unit or str) -- 缓冲区半径单位
返回: 缓冲区半径
返回类型:
-
get_x()¶ 获取点几何对象的 X 坐标值
返回类型: float
-
get_y()¶ 获取点几何对象的 Y 坐标值
返回类型: float
-
to_json()¶ 将当前点对象以 simple json 格式返回。
例如:
>>> geo = GeoPoint((10,20)) >>> print(geo.to_json()) {"Point": [10.0, 20.0], "id": 0}
返回: simple json 格式字符串 返回类型: str
-
-
class
iobjectspy.data.GeoPoint3D(point=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry点几何对象类。 该类一般用于描述点状地理实体。Point3D 和 GeoPoint3D 都可用来表示三维点,所不同的是 GeoPoint3D 描述的是地物实体,而 Point3D 描述的是一个位 置点;当赋予 GeoPoint3D 不同的几何风格,即可用于表示不同的地物实体,而 Point3D 则是广泛用于定位的坐标点
构造一个点几何对象。
参数: point (Point3D or GeoPoint3D or tuple[float] or list[float]) -- 点对象 -
bounds¶ Rectangle -- 获取点几何对象的地理范围
-
get_x()¶ 获取点几何对象的 X 坐标值
返回类型: float
-
get_y()¶ 获取点几何对象的 Y 坐标值
返回类型: float
-
get_z()¶ 获取点几何对象的 Z 坐标值
返回类型: float
-
set_x(x)¶ 设置点几何对象的 X 坐标
参数: x (float) -- X 坐标值 返回: self 返回类型: GeoPoint3D
-
set_y(y)¶ 设置点几何对象的 Y 坐标
参数: y (float) -- Y 坐标值 返回: self 返回类型: GeoPoint3D
-
set_z(z)¶ 设置点几何对象的 z 坐标
参数: z (float) -- Z 坐标值 返回: self 返回类型: GeoPoint3D
-
to_json()¶ 将当前点对象以 simple json 格式返回。
例如:
>>> geo = GeoPoint3D((10,20,15)) >>> print(geo.to_json()) {"Point3D": [10.0, 20.0], "id": 0}
返回: simple json 格式字符串 返回类型: str
-
-
class
iobjectspy.data.GeoLine(points=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry线几何对象类。 该类用于描述线状地理实体,如河流,道路,等值线等,一般用一个或多个有序坐标点集合来表示。线的方向决定于有序坐标点的顺序,也可以通过调用 reverse 方法来改变线的方向。线对象由一个或多个部分组成,每个部分称为线对象的一个子对象,每个子对象用一个有序坐标点集合来表示。可以对子对象进行添加,删除, 修改等操作。
构造一个线几何对象
参数: points (list[Point2D] or tuple[Point2D] or GeoLine or GeoRegion or Rectangle) -- 包含点串信息的对象,可以为 list[Point2D] 、tuple[Point2D] 、 GeoLine 、GeoRegion 和 Rectangle -
convert_to_region()¶ 将当前线对象转换为面几何对象 - 对于没有封闭的线对象,转换为面对象时,会把首尾自动连起来 - GeoLine 对象实例的某个子对象的点数少于 3 时将失败
返回类型: GeoRegion
-
create_buffer(distance, prj=None, unit=None)¶ 构建当前线对象的缓冲区对象。将会构建线对象的圆头全缓冲区。
参数: - distance (float) -- 缓冲区半径。如果设置了 prj 和 unit,将使用 unit 的单位作为缓冲区半径的单位。
- prj (PrjCoordSys) -- 描述点几何对象的投影信息
- unit (Unit or str) -- 缓冲区半径单位
返回: 缓冲区半径
返回类型:
-
find_point_on_line_by_distance(distance)¶ 在线上以指定的距离找点,查找的起始点为线的起始点。 - 当 distance 大于 Length 时,返回线最后一个子对象的终点。 - 当 distance=0 时,返回线几何对象的起始点; - 当线几何对象具有多个子对象的时候,按照子对象的序号依次查找
参数: distance (float) -- 要找点的距离 返回: 查找成功返回要找的点,否则返回 None 返回类型: Point2D
-
get_part(item)¶ 返回此线几何对象中指定序号的子对象,以有序点集合的方式返回该子对象。 当二维线对象是简单线对象时,如果传入参数0,得到的是此线对象的节点的集合。
参数: item (int) -- 子对象的序号。 返回: 子对象的的节点 返回类型: list[Point2D]
-
get_part_count()¶ 获取子对象的个数
返回类型: int
-
get_parts()¶ 获取当前几何对象的所有点坐标。每个子对象使用一个 list 存储
>>> points = [Point2D(1,2),Point2D(2,3)] >>> geo = GeoLine(points) >>> geo.add_part([Point2D(3,4),Point2D(4,5)]) >>> print(geo.get_parts()) [[(1.0, 2.0), (2.0, 3.0)], [(3.0, 4.0), (4.0, 5.0)]]
返回: 包含所有点坐标list 返回类型: list[list[Point2D]]
-
insert_part(item, points)¶ 此线几何对象中的指定位置插入一个子对象。成功则返回 True,否则返回 False
参数: - item (int) -- 插入的位置
- points (list[Point2D]) -- 插入的有序点集合
返回类型: bool
-
length¶ float -- 返回线对象的长度
-
remove_part(item)¶ 删除此线几何对象中的指定序号的子对象。
参数: item (int) -- 指定的子对象的序号 返回: 成功则返回 true,否则返回 false 返回类型: bool
-
to_json()¶ 将当前对象输出为 Simple Json 字符串
>>> points = [Point2D(1,2), Point2D(2,3), Point2D(1,5), Point2D(1,2)] >>> geo = GeoLine(points) >>> print(geo.to_json()) {"Line": [[[1.0, 2.0], [2.0, 3.0], [1.0, 5.0], [1.0, 2.0]]], "id": 0}
返回类型: str
-
-
class
iobjectspy.data.GeoLineM(points=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry路由对象。是一组具有 X,Y 坐标与线性度量值的点组成的线性地物对象。M 值是所谓的 Measure 值,即度量值。在交通网络分析中常用于 标注一条线路的不同点距离某一点的距离。比如高速公路上的里程碑,交通管制部门经常使用高速公路上的里程碑来标注并管理高速公路的路况、 车辆的行驶限速和高速事故点等。
构造一个路由对象
参数: points (list[PointM] 、tuple[PointM] 、 GeoLineM) -- 包含点串信息的对象,可以为 list[PointM] 、tuple[PointM] 、 GeoLineM -
convert_to_region()¶ 将当前对象转换为面几何对象 - 对于没有封闭的对象,转换为面对象时,会把首尾自动连起来 - GeoLineM 对象实例的某个子对象的点数少于 3 时将失败
返回类型: GeoRegion
-
find_point_on_line_by_distance(distance)¶ 在线上以指定的距离找点,查找的起始点为线的起始点。 - 当 distance 大于 Length 时,返回线最后一个子对象的终点。 - 当 distance=0 时,返回线几何对象的起始点; - 当线几何对象具有多个子对象的时候,按照子对象的序号依次查找
参数: distance (float) -- 要找点的距离 返回: 查找成功返回要找的点,否则返回 None 返回类型: Point2D
-
get_distance_at_measure(measure, is_ignore_gap=True, sub_index=-1)¶ 返回指定 M 值对应的点对象到指定路由子对象起点的距离。
参数: - measure (float) -- 指定的 M 值。
- is_ignore_gap (bool) -- 指定是否忽略子对象之间的距离。
- sub_index (int) -- 指定的路由子对象的索引值。如果为 -1,则从第一个子对象开始计算,否则从指定的子对象开始计算
返回: 指定 M 值对应的点对象到指定路由子对象起点的距离。单位与该路由对象所属数据集的单位相同。
返回类型: float
-
get_max_measure()¶ 返回最大线性度量值
返回类型: float
-
get_measure_at_distance(distance, is_ignore_gap=True, sub_index=-1)¶ 返回指定距离处的点对象的 M 值。
参数: - distance (float) -- 指定的距离。该距离指的是到路由线路起点的距离。单位与该路由对象所属数据集的单位相同。
- is_ignore_gap (bool) -- 是否忽略子对象之间的距离。
- sub_index (int) -- 待返回的路由子对象的序号。如果为 -1,则从第一个对象开始计算,否则从指定的子对象开始计算。
返回: 指定距离处的点对象的 M 值。
返回类型: float
-
get_measure_at_point(point, tolerance, is_ignore_gap)¶ 返回路由对象指定点处的 M 值。
参数: - point (Point2D) -- 指定的点对象。
- tolerance (float) -- 容限值。用于判断指定的点是否在路由对象上,若点到路由对象垂足的距离大于该值,则视为指定的点无效, 不执行返回。单位与该路由对象所属数据集的单位相同。
- is_ignore_gap (bool) -- 是否忽略子对象之间的间距。
返回: 路由对象指定点处的 M 值。
返回类型: float
-
get_min_measure()¶ 返回最小线性度量值。
返回类型: float
-
get_part(item)¶ 返回当前对象中指定序号的子对象,以有序点集合的方式返回该子对象。 当当前对象是简单路由对象时,如果传入参数0, 得到的是此对象的节点的集合。
参数: item (int) -- 子对象的序号。 返回: 子对象的的节点 返回类型: list[PointM]
-
get_part_count()¶ 获取子对象的个数
返回类型: int
-
insert_part(item, points)¶ 在当前对中的指定位置插入一个子对象。成功则返回 True,否则返回 False
参数: - item (int) -- 插入的位置
- points (list[PointM]) -- 插入的有序点集合
返回类型: bool
-
length¶ float -- 返回当前对象的长度
-
remove_part(item)¶ 删除此对象中的指定序号的子对象。
参数: item (int) -- 指定的子对象的序号 返回: 成功则返回 true,否则返回 false 返回类型: bool
-
to_json()¶ 将当前对象输出为 Simple Json 字符串
返回类型: str
-
-
class
iobjectspy.data.GeoRegion(points=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry面几何对象类,派生于 Geometry 类。
该类用于描述面状地理实体,如行政区域,湖泊,居民地等,一般用一个或多个有序坐标点集合来表示。面几何对象由一个或多个部分组成,每个部分称为面几何对 象的一个子对象,每个子对象用一个有序坐标点集合来表示,其起始点和终止点重合。可以对子对象进行添加,删除,修改等操作。
构造一个面几何对象
参数: points (list[Point2D] or tuple[Point2D] or GeoLine or GeoRegion or Rectangle) -- 包含点串信息的对象,可以为 list[Point2D] 、tuple[Point2D] 、 GeoLine 、GeoRegion 和 Rectangle -
area¶ float -- 返回面对象的面积
-
contains(point)¶ 判断点是否在面内
参数: point (Point2D or GeoPoint) -- 待判断的二维点对象 返回: 点在面内返回 True,否则返回 False 返回类型: bool
-
create_buffer(distance, prj=None, unit=None)¶ 构建当前面对象的缓冲区对象
参数: - distance (float) -- 缓冲区半径。如果设置了 prj 和 unit,将使用 unit 的单位作为缓冲区半径的单位。
- prj (PrjCoordSys) -- 描述点几何对象的投影信息
- unit (Unit or str) -- 缓冲区半径单位
返回: 缓冲区半径
返回类型:
-
get_part(item)¶ 返回此面几何对象中指定序号的子对象,以有序点集合的方式返回该子对象。
参数: item (int) -- 子对象的序号。 返回: 子对象的的节点 返回类型: list[Point2D]
-
get_part_count()¶ 获取子对象的个数
返回类型: int
-
get_parts()¶ 获取当前几何对象的所有点坐标。每个子对象使用一个 list 存储
>>> points = [Point2D(1,2), Point2D(2,3), Point2D(1,5), Point2D(1,2)] >>> geo = GeoRegion(points) >>> geo.add_part([Point2D(2,3), Point2D(4,3), Point2D(4,2), Point2D(2,3)]) >>> geo.get_parts() [[(1.0, 2.0), (2.0, 3.0), (1.0, 5.0), (1.0, 2.0)], [(2.0, 3.0), (4.0, 3.0), (4.0, 2.0), (2.0, 3.0)]]
返回: 包含所有点坐标list 返回类型: list[list[Point2D]]
-
get_parts_topology()¶ 判断面对象的子对象之间的岛洞关系。 岛洞关系数组是由 1 和 -1 两个数值组成,数组大小与面对象的子对象相同。其中, 1 表示子对象为岛, -1 表示子对象为洞。
返回类型: list[int]
-
get_precise_area(prj)¶ 精确计算投影参考系下多边形的面积
参数: prj (PrjCoordSys) -- 指定的投影坐标系 返回: 二维面几何对象的面积 返回类型: float
-
insert_part(item, points)¶ 此面几何对象中的指定位置插入一个子对象。成功则返回 True,否则返回 False
参数: - item (int) -- 插入的位置
- points (list[Point2D]) -- 插入的有序点集合
返回类型: bool
-
is_counter_clockwise(sub_index)¶ 判断面对象的子对象的走向。true 表示走向为逆时针,false 表示走向为顺时针。
返回类型: bool
-
perimeter¶ float -- 返回面对象的周长
-
protected_decompose()¶ 面对象保护性分解。区别于组合对象将子对象进行简单分解,保护性分解将复杂的具有多层岛洞嵌套关系的面对象分解成只有一层嵌套关系的面对象。 面对象 中有子对象部分交叠的情形不能保证分解的合理性。
返回: 保护性分解后得到的对象。 返回类型: list[GeoRegion]
-
remove_part(item)¶ 删除此面几何对象中的指定序号的子对象。
参数: item (int) -- 指定的子对象的序号 返回: 成功则返回 true,否则返回 false 返回类型: bool
-
to_json()¶ 将当前对象输出为 Simple Json 字符串
>>> points = [Point2D(1,2), Point2D(2,3), Point2D(1,5), Point2D(1,2)] >>> geo = GeoRegion(points) >>> print(geo.to_json()) {"Region": [[[1.0, 2.0], [2.0, 3.0], [1.0, 5.0], [1.0, 2.0]]], "id": 0}
返回类型: str
-
-
class
iobjectspy.data.TextPart(text=None, anchor_point=None, rotation=None)¶ 基类:
object文本子对象类。 用于表示文本对象
GeoText的子对象,其存储子对象的文本,旋转角度,锚点等信息并提供对子对象进行处理的相关方法。构造文本子对象。
参数: - text (str) -- 文本子对象实例的文本内容。
- anchor_point (Point2D) -- 文本子对象实例的锚点。
- rotation (float) -- 文本子对象的旋转角度,以度为单位,逆时针为正方向。
-
anchor_point¶ 文本子对象实例的锚点。该锚点与文本的对齐方式共同决定该文本子对象的显示位置。关于锚点与文本的对齐方式如何确定文本子对象的显示位置, 请参见
TextAlignment类。
-
rotation¶ 文本子对象的旋转角度,以度为单位,逆时针为正方向。
-
set_anchor_point(value)¶ 设置此文本子对象的锚点。该锚点与文本的对齐方式共同决定该文本子对象的显示位置。关于锚点与文本的对齐方式如何确定文本子对象的显示位置,请参见
TextAlignment类。参数: value (Point2D) -- 文本子对象的锚点 返回: self 返回类型: TextPart
-
set_rotation(value)¶ 设置此文本子对象的旋转角度。逆时针为正方向,单位为度。 文本子对象通过数据引擎存储后返回的旋转角度,精度为 0.1 度;通过构造函数直接构造的文本子对象,返回的旋转角度精度不变。
参数: value (float) -- 文本子对象的旋转角度 返回: self 返回类型: TextPart
-
text¶ str -- 此文本子对象的文本内容
-
to_dict()¶ 将当前子对象输出为 dict
返回类型: dict
-
to_json()¶ 将当前子对象输出为 json 字符串
返回类型: str
-
x¶ float -- 文本子对象锚点的横坐标,默认值为0
-
y¶ float -- 文本子对象锚点的纵坐标,默认值为0
-
class
iobjectspy.data.GeoText(text_part=None, text_style=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry文本类,派生于 Geometry 类。该类主要用于对地物要素进行标识和必要的注记说明。文本对象由一个或多个部分组成,每个部分称为文本对象的一个子对象,每 个子对象都是一个 TextPart 的实例。同一个文本对象的所有子对象都使用相同的文本风格,即使用该文本对象的文本风格进行显示。
构造文本对象
参数: -
get_part(index)¶ 获取指定的文本子对象
参数: index (int) -- 文本子对象的序号 返回: 返回类型: int
-
get_part_count()¶ 获取文本子对象的数目
返回类型: int
-
get_text()¶ 文本对象的内容。 如果该对象有多个子对象时,其值为子对象字符串之和。
返回类型: str
-
remove_part(index)¶ 删除此文本对象的指定序号的文本子对象。
参数: index (int) -- 返回: 如果删除成功返回 True,否则返回 False。 返回类型: bool
-
set_part(index, text_part)¶ 修改此文本对象的指定序号的子对象,即用新的文本子对象来替换原来的文本子对象。
参数: - index (int) -- 文本子对象序号
- text_part (TextPart) -- 文本子对象
返回: 设置成功返回 True,否则返回 False。
返回类型: bool
-
set_text_style(text_style)¶ 设置文本对象的文本风格。文本风格用于指定文本对象显示时的字体、宽度、高度和颜色等。
参数: text_style (TextStyle) -- 文本对象的文本风格。 返回: self 返回类型: GeoText
-
text_style¶ TextStyle -- 文本对象的文本风格。文本风格用于指定文本对象显示时的字体、宽度、高度和颜色等。
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
-
class
iobjectspy.data.TextStyle¶ 基类:
object文本风格类。 用于设置
GeoText类对象的风格-
alignment¶ TextAlignment -- 文本的对齐方式。
-
back_color¶ tuple -- 文本的背景色,默认颜色为黑色
-
border_spacing_width¶ int -- 返回文字背景矩形框边缘与文字边缘的间隔,单位为:像素
-
font_height¶ float -- 文本字体的高度。在固定大小时单位为1毫米,否则使用地理坐标单位。默认值为 6。
-
font_name¶ str -- 返回文本字体的名称。如果在Windows平台下对地图中的文本图层指定了某种字体,并且该地图数据需要在Linux平台下进行应用,那么请确保您 的Linux平台下也存在同样的字体,否则,文本图层的字体显示效果会有问题。文本字体的名称的默认值为 "Times New Roman"。
-
font_scale¶ float -- 注记字体的缩放比例
-
font_width¶ float -- 文本的宽度。字体的宽度以英文字符为标准,由于一个中文字符相当于两个英文字符。在固定大小时单位为1毫米,否则使用地理坐标单位。
-
fore_color¶ tuple -- 文本的前景色,默认色为黑色。
-
is_back_opaque¶ bool -- 文本背景是否不透明,True 表示文本背景不透明。 默认不透明
-
is_bold¶ bool -- 返回文本是否为粗体字,True 表示为粗体
-
is_italic¶ bool -- 文本是否采用斜体,True 表示采用斜体
-
is_outline¶ bool -- 返回是否以轮廓的方式来显示文本的背景
-
is_shadow¶ bool -- 文本是否有阴影。True 表示给文本增加阴影
-
is_size_fixed¶ bool -- 文本大小是否固定。False,表示文本为非固定尺寸的文本
-
is_strikeout¶ bool -- 文本字体是否加删除线。True 表示加删除线。
-
is_underline¶ bool -- 文本字体是否加下划线。True 表示加下划线。
-
italic_angle¶ float -- 返回字体倾斜角度,正负度之间,以度为单位,精确到0.1度。当倾斜角度为0度,为系统默认的字体倾斜样式。 正负度是指以纵轴为起始零度线,其纵轴左侧为正,右侧为负。允许的最大角度为60,最小-60。大于60按照60处理,小于-60按照-60处理。
-
static
make_from_dict(values)¶ 从 dict 中读取文本风格信息构造 TextStyle
参数: values (dict) -- 包含文本风格信息的 dict 返回类型: TextStyle
-
opaque_rate¶ int -- 设置注记文字的不透明度。不透明度的范围为0-100。
-
outline_width¶ float -- 文本轮廓的宽度,数值的单位为:像素,数值范围是从0到5之间的任意整数。
-
rotation¶ float -- 文本旋转的角度。逆时针方向为正方向,单位为度。
-
set_alignment(value)¶ 设置文本的对齐方式
参数: value (TextAlignment or str) -- 文本的对齐方式 返回: self 返回类型: TextStyle
-
set_back_opaque(value)¶ 设置文本背景是否不透明,True 表示文本背景不透明
参数: value (bool) -- 文本背景是否不透明 返回: self 返回类型: TextStyle
-
set_border_spacing_width(value)¶ 设置文字背景矩形框边缘与文字边缘的间隔,单位为:像素。
参数: value (int) -- 返回: self 返回类型: TextStyle
-
set_font_height(value)¶ 设置文本字体的高度。在固定大小时单位为1毫米,否则使用地理坐标单位。
参数: value (float) -- 文本字体的高度 返回: self 返回类型: TextStyle
-
set_font_name(value)¶ 设置文本字体的名称。 如果在Windows平台下对地图中的文本图层指定了某种字体,并且该地图数据需要在Linux平台下进行应用,那么请确保您的Linux 平台下也存在同样的字体,否则,文本图层的字体显示效果会有问题。
参数: value (str) -- 文本字体的名称。文本字体的名称的默认值为 "Times New Roman"。 返回: self 返回类型: TextStyle
-
set_font_width(value)¶ 设置文本的宽度。字体的宽度以英文字符为标准,由于一个中文字符相当于两个英文字符。在固定大小时单位为1毫米,否则使用地理坐标单位。
参数: value (float) -- 文本的宽度 返回: self 返回类型: TextStyle
-
set_italic_angle(value)¶ 设置字体倾斜角度,正负度之间,以度为单位,精确到0.1度。当倾斜角度为0度,为系统默认的字体倾斜样式。 正负度是指以纵轴为起始零度线,其纵轴左侧为正,右侧为负。允许的最大角度为60,最小-60。大于60按照60处理,小于-60按照-60处理。
参数: value (float) -- 字体倾斜角度,正负度之间,以度为单位,精确到0.1度 返回: self 返回类型: TextStyle
-
set_opaque_rate(value)¶ 设置注记文字的不透明度。不透明度的范围为0-100。
参数: value (int) -- 注记文字的不透明度 返回: self 返回类型: TextStyle
-
set_outline(value)¶ 设置是否以轮廓的方式来显示文本的背景。false,表示不以轮廓的方式来显示文本的背景。
参数: value (bool) -- 是否以轮廓的方式来显示文本的背景 返回: self 返回类型: TextStyle
-
set_outline_width(value)¶ 设置文本轮廓的宽度,数值的单位为:像素,数值范围是从0到5之间的任意整数,其中设置为0值时表示没有轮廓。 必须通过方法
is_outline()为 True 时,文本轮廓的宽度设置才有效。参数: value (int) -- 文本轮廓的宽度,数值的单位为:像素,数值范围是从0到5之间的任意整数,其中设置为0值时表示没有轮廓。 返回: self 返回类型: TextStyle
-
set_size_fixed(value)¶ 设置文本大小是否固定。False,表示文本为非固定尺寸的文本。
参数: value (bool) -- 文本大小是否固定。False,表示文本为非固定尺寸的文本。 返回: self 返回类型: TextStyle
-
set_string_alignment(value)¶ 设置文本的排版方式,可以对多行文本设置左对齐、右对齐、居中对齐、两端对齐
参数: value (StringAlignment) -- 文本的排版方式 返回: self 返回类型: TextStyle
-
set_underline(value)¶ 设置文本字体是否加下划线。True 表示加下划线。
参数: value (bool) -- 文本字体是否加下划线。True 表示加下划线 返回: self 返回类型: TextStyle
-
set_weight(value)¶ 设置文本字体的磅数,表示粗体的具体数值。取值范围为从0-900之间的整百数,如400表示正常显示,700表示为粗体,可参见微软 MSDN 帮助中关于 LOGFONT 类的介绍
参数: value (int) -- 文本字体的磅数。 返回: self 返回类型: TextStyle
-
string_alignment¶ StringAlignment -- 文本的排版方式
-
to_dict()¶ 将当前对象输出为 dict
返回类型: dict
-
to_json()¶ 输出为 json 字符串
返回类型: str
-
weight¶ float -- 文本字体的磅数,表示粗体的具体数值。取值范围为从0-900之间的整百数,如400表示正常显示,700表示为粗体,可参见微软 MSDN 帮助中 关于 LOGFONT 类的介绍。默认值为400
-
-
class
iobjectspy.data.GeoRegion3D(points=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D面几何对象类,派生于 Geometry3D 类。
该类用于描述面状地理实体,如行政区域,湖泊,居民地等,一般用一个或多个有序坐标点集合来表示。面几何对象由一个或多个部分组成,每个部分称为面几何对 象的一个子对象,每个子对象用一个有序坐标点集合来表示,其起始点和终止点重合。可以对子对象进行添加,删除,修改等操作。
构造一个面几何对象
参数: points (list[Point2D] or tuple[Point2D] or GeoLine or GeoRegion or Rectangle) -- 包含点串信息的对象,可以为 list[Point2D] 、tuple[Point2D] 、 GeoLine 、GeoRegion 和 Rectangle -
area¶ float -- 返回面对象的面积
-
contains(point)¶ 判断点是否在面内 :param point: 待判断的点对象 :type point: Point3D or GeoPoint3D :return: 点在面内返回 True,否则返回 False :return type: bool
-
get_part(item)¶ 返回此面几何对象中指定序号的子对象,以有序点集合的方式返回该子对象。
参数: item (int) -- 子对象的序号。 返回: 子对象的的节点 返回类型: list[Point3D]
-
get_part_count()¶ 获取子对象的个数 :rtype: int
-
get_parts()¶ 获取当前几何对象的所有点坐标。每个子对象使用一个 list 存储
>>> points = [Point3D(1,2,0), Point3D(2,3,0), Point3D(1,5,0), Point3D(1,2,0)] >>> geo = GeoRegion(points) >>> geo.add_part([Point3D(2,3,0), Point3D(4,3,0), Point3D(4,2,0), Point3D(2,3,0)]) >>> geo.get_parts() :return: 包含所有点坐标list :rtype: list[list[Point2D]]
-
insert_part(item, points)¶ 此面几何对象中的指定位置插入一个子对象。成功则返回 True,否则返回 False :param int item: 插入的位置 :param list[Point3D] points: 插入的有序点集合 :rtype: bool
-
perimeter¶ float -- 返回面对象的周长
-
remove_part(item)¶ 删除此面几何对象中的指定序号的子对象。 :param int item: 指定的子对象的序号 :return: 成功则返回 true,否则返回 false :rtype: bool
-
to_json()¶ 将当前对象输出为 Simple Json 字符串
>>> points = [Point2D(1,2), Point2D(2,3), Point2D(1,5), Point2D(1,2)] >>> geo = GeoRegion(points) >>> print(geo.to_json()) {"Region": [[[1.0, 2.0], [2.0, 3.0], [1.0, 5.0], [1.0, 2.0]]], "id": 0}
返回类型: str
-
translate(dx=0.0, dy=0.0, dz=0.0)¶ 将面对象进行偏移,面中的每一个点都加上该偏移量 :param dx: X 方向偏移量 :param dy: Y 方向偏移量 :param dz: Z 方向偏移量 :return:
-
-
class
iobjectspy.data.GeoModel3D(poin3dValues=None, faceIndices=None, bLonLat=False)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D三维模型对象类
:由顶点,顶点索引构建三维模型对象 :param poin3dValues:顶点包 :param faceIndices:Face索引集合,需要注意的是顶点索引每个元素应该是一个个数大于等于4(第一个和最后一个相同)的list 即每个Face顶点连接顺序。应当注意的是Face应是一个平面 :return 三维模型对象 例如构建一个中心点在原点的盒子三维模型 8个顶点 point3ds = [Point3D(-1,-1,-1), Point3D(1,-1,-1), Point3D(1,-1,1), Point3D(-1,-1,1),Point3D(-1,1,-1), Point3D(1, 1, -1), Point3D(1, 1, 1), Point3D(-1, 1, 1)] 6个面 faceIndices=[
[3,2,1,0,3],#front [0,1,5,4,0],#bottom [0,4,7,3,0],#right [1,5,6,2,1],#left [2,3,7,6,2],#top [5,4,7,6,5] #back ]geo=GeoModel3D(point3ds, faceIndices)
-
IsLonLat¶
-
Mirror(plane)¶ :镜像 :param plane:镜像面 :return:返回self关于plane镜像的模型对象
-
SetMatrix(basePoint, matrix)¶ 模型变换 :param basePoint:基准点 :param matrix:变换矩阵 :return:矩阵变换后的GeoModel3D
-
max_z¶ 获得模型z方向的最大值
-
mergeSkeleton()¶
-
min_z¶ 获取模型z方向的最小值
-
set_IsLonLat(value)¶
-
set_color(value)¶ 设置模型材质颜色,所有骨架都为该颜色 :param value: 材质颜色 :return:
-
translate(x=0, y=0, z=0)¶ 模型平移 :param x: X方向平移量 :param y: Y方向平移量 :param z: Z方向平移量 :return: 返回平移后的模型
-
-
class
iobjectspy.data.GeoBox(len=0.0, width=None, height=None, position=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D长方体几何对象类
-
height¶
-
length¶
-
set_height(value)¶
-
set_length(value)¶
-
set_width(value)¶
-
width¶
-
-
class
iobjectspy.data.GeoLine3D(points=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D线几何对象类。 该类用于描述线状地理实体,如河流,道路,等值线等,一般用一个或多个有序坐标点集合来表示。线的方向决定于有序坐标点的顺序,也可以通过调用 reverse 方法来改变线的方向。线对象由一个或多个部分组成,每个部分称为线对象的一个子对象,每个子对象用一个有序坐标点集合来表示。可以对子对象进行添加,删除, 修改等操作。
构造一个线几何对象
参数: points (list[Point3D] or tuple[Point3D] or GeoLine3d or GeoRegion) -- 包含点串信息的对象,可以为 list[Point3D] 、tuple[Point3D] 、 GeoLine3D 、GeoRegion3D -
convert_to_region()¶ 将当前线对象转换为面几何对象 - 对于没有封闭的线对象,转换为面对象时,会把首尾自动连起来 - GeoLine 对象实例的某个子对象的点数少于 3 时将失败
返回类型: GeoRegion3D
-
get_part(item)¶ 返回此线几何对象中指定序号的子对象,以有序点集合的方式返回该子对象。 当二维线对象是简单线对象时,如果传入参数0,得到的是此线对象的节点的集合。
参数: item (int) -- 子对象的序号。 返回: 子对象的的节点 返回类型: list[Point2D]
-
get_part_count()¶ 获取子对象的个数
返回类型: int
-
get_parts()¶ 获取当前几何对象的所有点坐标。每个子对象使用一个 list 存储
>>> points = [Point3D(1,2,0),Point3D(2,3,0)] >>> geo = GeoLine3D(points) >>> geo.add_part([Point3D(3,4,0),Point3D(4,5,0)]) >>> print(geo.get_parts()) [[(1.0, 2.0, 0.0), (2.0, 3.0, 0.0)], [(3.0, 4.0, 0.0), (4.0, 5.0, 0.0)]]
返回: 包含所有点坐标list 返回类型: list[list[Point3D]]
-
insert_part(item, points)¶ 此线几何对象中的指定位置插入一个子对象。成功则返回 True,否则返回 False
参数: - item (int) -- 插入的位置
- points (list[Point2D]) -- 插入的有序点集合
返回类型: bool
-
length¶ float -- 返回线对象的长度
-
remove_part(item)¶ 删除此线几何对象中的指定序号的子对象。
参数: item (int) -- 指定的子对象的序号 返回: 成功则返回 true,否则返回 false 返回类型: bool
-
to_json()¶ 将当前对象输出为 Simple Json 字符串
>>> points = [Point3D(1,2,0), Point3D(2,3,0), Point3D(1,5,0), Point3D(1,2,0)] >>> geo = GeoLine(points) >>> print(geo.to_json()) {"Line3D": [[[1.0, 2.0, 0.0], [2.0, 3.0, 0.0], [1.0, 5.0, 0.0], [1.0, 2.0, 0.0]]], "id": 0}
返回类型: str
-
-
class
iobjectspy.data.GeoCylinder(topRadius=0.0, bottomRadius=None, height=1.0, position=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D圆台几何对象类,继承于 Geometry3D类。 如果设置该类对象的底面圆的半径和顶面圆的半径相等,就是圆柱几何对象
-
bottomRadius¶
-
height¶
-
set_bottomRadius(value)¶
-
set_height(value)¶
-
set_topRadius(value)¶
-
topRadius¶
-
-
class
iobjectspy.data.GeoCircle3D(r=0.0, position=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.Geometry3D三维圆面几何对象类
-
radius¶
-
set_radius(value)¶
-
-
class
iobjectspy.data.GeoStyle3D¶ 基类:
object三维场景中的几何对象风格类。该类主要用于设置三维场景中几何对象的显示风格
-
fillForeColor¶
-
from_dict(values)¶ 从 dict 中读取风格信息 :param dict values: 包含风格信息的 dict :return: self :rtype: GeoStyle3D
-
static
from_json(value)¶ 从 json 字符串中构建 GeoStyle3D 对象 :param str value: :rtype: GeoStyle3D
-
lineColor¶
-
lineWidth¶
-
static
make_from_dict(values)¶ 从 dict 中读取文本风格信息构造 GeoStyle3D :param dict values: 包含文本风格信息的 dict :rtype: GeoStyle3D
-
markerColor¶
-
markerSize¶
-
set_fillForeColor(value)¶
-
set_lineColor(value)¶
-
set_lineWidth(value)¶
-
set_markerColor(value)¶
-
set_markerSize(value)¶
-
to_dict()¶ 将当前对象输出为 dict :rtype: dict
-
to_json()¶ 输出为 json 字符串 :rtype: str
-
-
class
iobjectspy.data.Plane(points=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase平面对象类。此平面为数学意义上无限延展的平面,主要用于三维模型进行截面投影和平面投影 用法: p1 = Point3D(1, 1, 1) p2 = Point3D(0, 3, 4) p3 = Point3D(7, 4, 3) plane = Plane([p1, p2, p3]) 或者: plane = Plane(PlaneType.PLANEXY)
-
get_normal()¶ - 获取面的法向量
返回: 返回法向量Point3D
-
set_normal(p)¶ 设置面的法向量 :param p:法向量,可以是Point3D,tuple[float,float,float] or list[float,float,float] :return:
-
set_type(planeType)¶ 设置平面类型 :param planeType: :return:
-
-
class
iobjectspy.data.Matrix(arrayValue=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase4X4矩阵类,主要用于三维模型矩阵变换 如果需要连续变换,应该用静态方法Multiply相乘
-
static
identity()¶
-
static
invert(matrix)¶
-
static
multiply(value, matrix)¶ :矩阵乘法,第一个参数可以是Point3D,也可以是Matrix :param value:可以是Point3D,也可以是4X4矩阵, :param matrix:矩阵 :return: 当第一个参数是Point3D时,返回值为Point3D;当是Matrix时,返回值为Matrix
-
static
rotate(rotationX, rotationY, rotationZ)¶ :旋转,单位:度 :param rotationX:绕X轴旋转的角度 :param rotationY:绕Y轴旋转的角度 :param rotationZ:绕Z轴旋转的角度 :return: 返回一个新的具有rotationX, rotationY, rotationZ缩放的矩阵
-
static
scale(scaleX, scaleY, scaleZ)¶ :缩放 :param scaleX:X方向缩放 :param scaleY:Y方向缩放 :param scaleZ:Z方向缩放 :return: 返回一个新的具有scaleX, scaleY, scaleZ缩放的矩阵
-
set_ArrayValue(value)¶ :设置矩阵 :param value:长度为16的数组
-
static
translate(translateX, translateY, translateZ)¶ :平移 :param translateX:X方向平移 :param translateY:Y方向平移 :param translateZ:Z方向平移 :return: 返回一个新的具有translateX, translateY, translateZ平移的矩阵
-
static
-
class
iobjectspy.data.Feature(geometry=None, values=None, id_value='0', field_infos=None)¶ 基类:
object特征要素对象,特征要素对象可以用于描述空间信息和属性信息,也可以只用于属性信息的描述。
参数: -
add_field_info(field_info)¶ 增加一个属性字段。增加一个属性字段后,如果没有属性字段没有设置默认值,将会将属性值设为 None
参数: field_info (FieldInfo) -- 属性字段信息 返回: 添加成功返回True,否则返回False 返回类型: bool
-
bounds¶ Rectangle -- 获取几何对象的地理范围。如果几何对象为空,则返回空
-
feature_id¶ str -- 返回 Feature ID
-
field_infos¶ list[FieldInfo] -- 返回要素对象的所有字段信息
-
geometry¶ Geometry -- 返回几何对象
-
get_value(item)¶ 获取当前对象中指定的属性字段的字段值
参数: item (str or int) -- 字段名称或序号 返回类型: int or float or str or datetime.datetime or bytes or bytearray
-
get_values(exclude_system=True, is_dict=False)¶ 获取当前对象的属性字段值。
参数: - exclude_system (bool) -- 是否包含系统字段。所有 "Sm" 开头的字段都是系统字段。默认为 True
- is_dict (bool) -- 是否以 dict 形式返回,如果返回 dict,则 dict 的 key 为字段名称, value 为属性字段值。否则以 list 形式返回字段值。默认为 False
返回: 属性字段值
返回类型: dict or list
-
remove_field_info(name)¶ 删除指定字段名称或序号的字段。删除字段后,字段值也会被删除
参数: name (int or str) -- 字段名称或序号 返回: 删除成功返回 True,否则返回 False 返回类型: bool
-
set_feature_id(fid)¶ 设置 Feature ID
参数: fid (str) -- feature ID 值,一般用于表示要素对象的唯一的ID值 返回: 返回类型:
-
set_field_infos(field_infos)¶ 设置属性字段信息
参数: field_infos (list[FieldInfo]) -- 属性字段信息 返回: self 返回类型: Feature
-
set_value(item, value)¶ 设置当前对象中指定的属性字段的字段值
参数: - item (str or int) -- 字段名称或序号
- value (int or float or str or datetime.datetime or bytes or bytearray) -- 字段值
返回类型: bool
-
set_values(values)¶ 设置字段值.
参数: values (dict) -- 要写入的属性字段值。必须是 dict,dict 的键值为字段名称,dict 的值为字段值 返回: 返回成功写入的字段数目 返回类型: int
-
to_json()¶ 将当前对象输出为 json 字符串
返回类型: str
-
-
class
iobjectspy.data.GeometriesRelation(tolerance=1e-10, gridding_level='NONE')¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase几何对象关系判断类,区别与空间查询的是,此类用于几何对象的判断,而不是数据集,实现原理上与空间查询相同。
下面示例代码展示面查询点的功能,通过讲多个面对象(regions)插入到 GeometriesRelation 后,可以判断每个点对象被哪个面对象包含, 自然可以得到每个面对象包含的所有点对象,在需要处理大量的点对象时,此种方式具有比较好的性能:
>>> geos_relation = GeometriesRelation() >>> for index in range(len(regions)) >>> geos_relation.insert(regions[index], index) >>> results = dict() >>> for point in points: >>> region_values = geos_relation.matches(point, 'Contain') >>> for region_value in region_values: >>> region = regions[region_value] >>> if region in results: >>> results[region].append(point) >>> else: >>> results[region] = [point] >>> del geos_relation
参数: - tolerance (float) -- 节点容限
- gridding_level (GriddingLevel or str) -- 面对象格网化等级。
-
get_gridding()¶ 获取面对象格网化等级。默认不做面对象格网化
返回类型: GriddingLevel
-
get_sources_count()¶ 获取 GeometriesRelation 中所有插入的几何对象数目
返回类型: int
-
get_tolerance()¶ 获取节点容限
返回类型: float
-
insert(data, value)¶ 插入一个用于被匹配的几何对象,被匹配对象在空间查询模式中为查询对象,例如,要进行面包含点对象查询,需要插入面对象到 GeometriesRelation 中,然后依次匹配得到与点对象满足包含关系的面对象。
参数: - data (Geometry or Point2D or Rectangle, Recordset, DatasetVector) -- 被匹配的几何对象,必须是点线面,或点线面记录集或数据集
- value (int) -- 被匹配的值,是一个唯一值,且必须大于等于0,比如几何对象的 ID 等。如果传入的是 Recordset 或 DatasetVector, 则 value 为有表示对象唯一整型值且值大于等于0的字段名称,如果为 None,则使用对象的 SmID 值。
返回: 插入成功返回 True,否则返回 False。
返回类型: bool
-
intersect_extents(rc)¶ 返回与指定矩形范围相交的所有对象,即对象的矩形范围相交。
参数: rc (Rectangle) -- 指定的矩形范围 返回: 与指定的矩形范围相交的对象的值 返回类型: list[int]
-
is_match(data, src_value, mode)¶ 判断对象是否与指定对象满足空间关系
参数: - data (Geometry or Point2D or Rectangle) -- 要进行匹配的对象
- src_value (int) -- 被匹配对象的值
- mode (SpatialQueryMode or str) -- 匹配的空间查询模式
返回: 如果指定对象与指定对象满足空间关系返回 True,否则为 False。
返回类型: bool
-
matches(data, mode, excludes=None)¶ 找出与匹配对象满足空间关系的所有被匹配对象的值。
参数: - data (Geometry or Point2D or Rectangle) -- 匹配空间对象
- mode (SpatialQueryMode or str) -- 匹配的空间查询模式
- excludes (list[int]) -- 排除的值,即不参与匹配运算
返回: 被匹配对象的值
返回类型: list[int]
-
set_gridding(gridding_level)¶ 设置面对象格网化等级。默认不做面对象格网化。
参数: gridding_level (GriddingLevel or str) -- 格网化等级 返回: self 返回类型: GeometriesRelation
-
set_tolerance(tolerance)¶ 设置节点容限
参数: tolerance (float) -- 节点容限 返回: self 返回类型: GeometriesRelation
-
iobjectspy.data.aggregate_points_geo(points, min_pile_point_count, distance, unit='Meter', prj=None, as_region=False)¶ 对点集合进行密度聚类。密度聚类算法介绍参考
iobjectspy.aggregate_points()参数: - points (list[Point2D] or tuple[Point2D]) -- 输入的点集合
- min_pile_point_count (int) -- 密度聚类点数目阈值,必须大于等于2。阈值越大表示能聚类为一簇的条件越苛刻。推荐值为4。
- distance (float) -- 密度聚类半径。
- unit (Unit or str) -- 密度聚类半径的单位。如果空间参考坐标系prjCoordSys无效,此参数也无效
- prj (PrjCoordSys) -- 点集合的空间参考坐标系
- as_region (bool) -- 是否返回聚类后的面对象
返回: 当 as_region 为 False 时,返回一个list,list中每个值代表点对象的聚类类别,聚类类别从1开始,0表示为无效聚类。 当 as_region 为 True 时,将返回每一簇点集聚集成的多边形对象
返回类型: list[int] or list[GeoRegion]
-
iobjectspy.data.can_contain(geo_search, geo_target)¶ 判断搜索几何对象是否包含被搜索几何对象。包含则返回 True。 注意,如果存在包含关系,则:
搜索几何对象的外部和被搜索几何对象的内部的交集为空;
两个几何对象的内部交集不为空或者搜索几何对象的边界与被搜索几何对象的内部交集不为空;
点查线,点查面,线查面,不存在包含情况;
与
is_within()是逆运算;该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
参数: 返回: 搜索几何对象包含被搜索几何对象返回 True;否则返回 False。
返回类型: bool
-
iobjectspy.data.has_intersection(geo_search, geo_target, tolerance=None)¶ 判断被搜索几何对象与搜索几何对象是否有面积相交。相交返回 true。 注意:
被搜索几何对象和搜索几何对象必须有一个为面对象;
该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
参数: 返回: 两对象面积相交返回 True,否则为 False
返回类型: bool
-
iobjectspy.data.has_area_intersection(geo_search, geo_target, tolerance=None)¶ 判断对象是否面积相交,查询对象和目标对象至少有一个对象是面对象,相交的结果不包括仅接触的情形。支持点、线、面和文本对象。
参数: 返回: 两对象面积相交返回 True,否则为 False
返回类型: bool
-
iobjectspy.data.has_cross(geo_search, geo_target)¶ 判断搜索几何对象是否穿越被搜索几何对象。穿越则返回 True。 注意,如果两个几何对象存在穿越关系则:
搜索几何对象内部与被搜索几何对象的内部的交集不为空且搜索几何对象的内部与被搜索几何对象的外部的交集不为空。
被搜索几何对象为线时,搜索几何对象内部与被搜索几何对象的内部的交集不为空但是边界交集为空;
该关系适合的几何对象类型:
- 搜索几何对象:线;
- 被搜索几何对象:线、面。
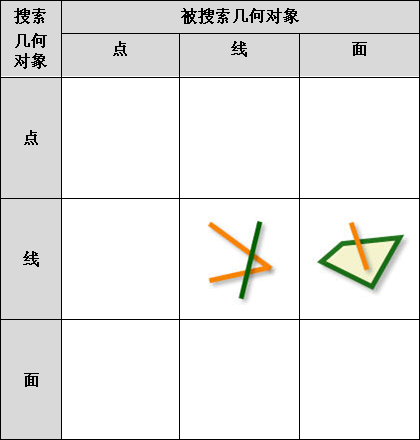
参数: 返回: 搜索几何对象穿越被搜索对象返回 True;否则返回 False。
返回类型: bool
-
iobjectspy.data.has_overlap(geo_search, geo_target, tolerance=None)¶ 判断被搜索几何对象是否与搜索几何对象部分重叠。有部分重叠则返回 true。 注意:
点与任何一种几何对象都不存在部分重叠的情况;
被搜索几何对象与搜索几何对象的维数要求相同,即只可以是线查询线或者面查询面;
该关系适合的几何对象类型:
- 搜索几何对象:线、面;
- 被搜索几何对象:线、面。
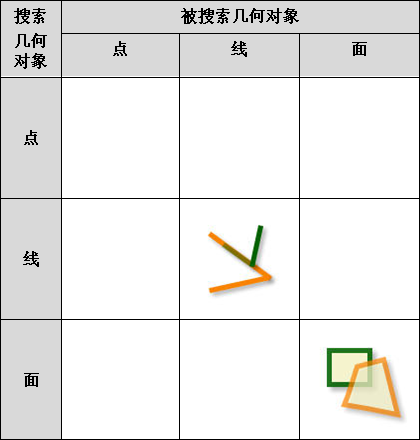
参数: 返回: 被搜索几何对象与搜索几何对象部分重叠返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.has_touch(geo_search, geo_target, tolerance=None)¶ 判断被搜索几何对象的边界是否与搜索几何对象的边界相触。相触时搜索几何对象和被搜索几何对象的内部交集为空。 注意:
点与点不存在边界接触的情况;
该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
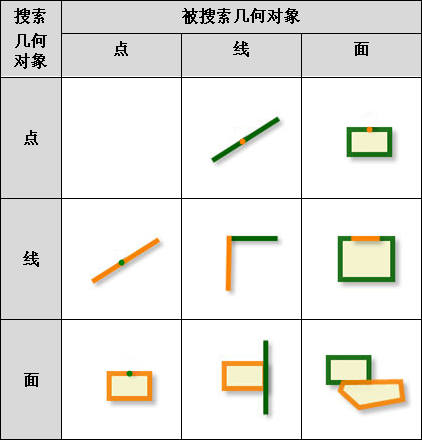
参数: 返回: 被搜索几何对象的边界与搜索几何对象边界相触返回 True;否则返回 False。
返回类型: bool
-
iobjectspy.data.has_common_point(geo_search, geo_target)¶ 判断搜索几何对象是否与被搜索几何对象有共同节点。有共同节点返回 true。
参数: 返回: 搜索几何对象与被搜索几何对象有共同节点返回 true;否则返回 false。
返回类型: bool
-
iobjectspy.data.has_common_line(geo_search, geo_target)¶ 判断搜索几何对象是否与被搜索几何对象有公共线段。有公共线段返回 True。
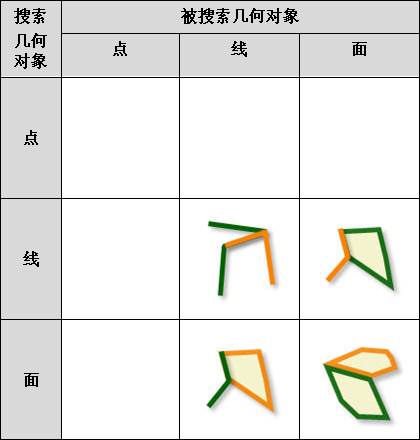
参数: 返回: 搜索几何对象与被搜索几何对象有公共线段返回 True;否则返回 False。
返回类型: bool
-
iobjectspy.data.has_hollow(geometry)¶ 判断指定的面对象是否包含有洞类型的子对象
参数: geometry (GeoRegion) -- 待判断的面对象,目前只支持二维面对象 返回: 面对象是否含有洞类型的子对象,包含则返回 True,否则返回 False 返回类型: bool
-
iobjectspy.data.is_disjointed(geo_search, geo_target)¶ 判断被搜索几何对象是否与搜索几何对象分离。分离返回 true。 注意:
搜索几何对象和被搜索几何对象分离,即无任何交集;
该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
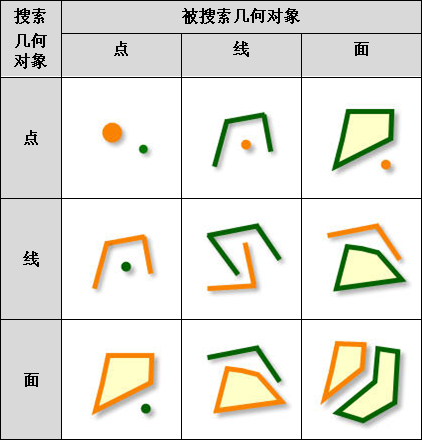
参数: 返回: 两个几何对象分离返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.is_identical(geo_search, geo_target, tolerance=None)¶ 判断被搜索几何对象是否与搜索几何对象完全相等。即几何对象完全重合、对象节点数目相等,正序或逆序对应的坐标值相等。 注意:
被搜索几何对象与搜索几何对象的类型必须相同;
该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
参数: 返回: 两个对象完全相等返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.is_within(geo_search, geo_target, tolerance=None)¶ 判断搜索几何对象是否在被搜索几何对象内。如果在则返回 True。 注意:
线查询点,面查询线或面查询点都不存在 Within 情况;
与 can_contain 是逆运算;
该关系适合的几何对象类型:
- 搜索几何对象:点、线、面;
- 被搜索几何对象:点、线、面。
参数: 返回: 搜索几何对象在被搜索几何对象内返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.is_left(point, start_point, end_point)¶ 判断点是否在线的左侧。
参数: 返回: 如果点在线的左侧,返回 True,否则返回 False
返回类型: bool
-
iobjectspy.data.is_right(point, start_point, end_point)¶ 判断点是否在线的右侧。
参数: 返回: 如果点在线的右侧,返回 True,否则返回 False
返回类型: bool
-
iobjectspy.data.is_on_same_side(point1, point2, start_point, end_point)¶ 判断两点是否在线的同一侧。
参数: 返回: 如果点在线的同一侧,返回 True,否则返回 False
返回类型: bool
-
iobjectspy.data.is_parallel(start_point1, end_point1, start_point2, end_point2)¶ 判断两条线是否平行。
参数: 返回: 平行返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.is_point_on_line(point, start_point, end_point, is_extended=True)¶ 判断已知点是否在已知线段(直线)上,点在线上返回 True, 否则返回 False。
参数: 返回: 点在线上返回 True;否则返回 False
返回类型: bool
-
iobjectspy.data.is_project_on_line_segment(point, start_point, end_point)¶ 判断已知点到已知线段的垂足是否在该线段上,如果在,返回 True, 否则返回 False。
参数: 返回: 点与线段的垂足是否在线段上。如果在,返回 True,否则返回 False。
返回类型: bool
-
iobjectspy.data.is_perpendicular(start_point1, end_point1, start_point2, end_point2)¶ 判断两条直线是否垂直。
参数: 返回: 垂直返回 True;否则返回 False。
返回类型: bool
-
iobjectspy.data.nearest_point_to_vertex(vertex, geometry)¶ 从几何对象上找一点与给定的点距离最近。
参数: 返回: 几何对象上与指定点距离最近的一点。
返回类型:
-
iobjectspy.data.clip(geometry, clip_geometry, tolerance=None)¶ 生成被操作对象经过操作对象裁剪后的几何对象。 注意:
被操作几何对象只有落在操作几何对象内的那部分才会被输出为结果几何对象;
clip 与 intersect 在空间处理上是一致的。
该操作适合的几何对象类型:
- 操作几何对象:面;
- 被操作几何对象:线、面。
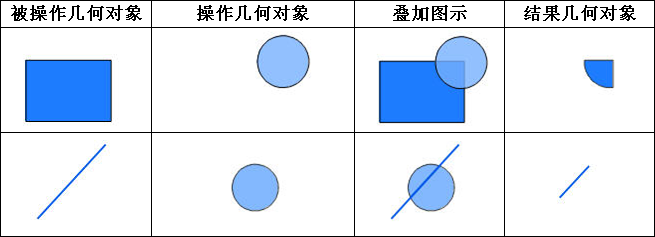
参数: 返回: 裁剪结果对象
返回类型:
-
iobjectspy.data.erase(geometry, erase_geometry, tolerance=None)¶ 在被操作对象上擦除掉与操作对象相重合的部分。 注意:
如果对象全部被擦除了,则返回 None;
操作几何对象定义了擦除区域,凡是落在操作几何对象区域内的被操作几何对象都将被去除,而落在区域外的特征要素都将被输出为结果几何对象,与 Clip 运算相反;
该操作适合的几何对象类型:
- 操作几何对象:面;
- 被操作几何对象:点、线、面。
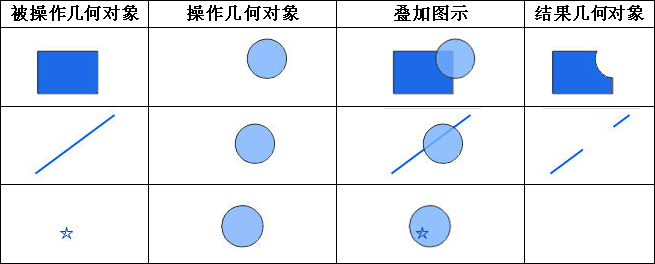
参数: 返回: 擦除操作后的几何对象。
返回类型:
-
iobjectspy.data.identity(geometry, identity_geometry, tolerance=None)¶ 对被操作对象进行同一操作。即操作执行后,被操作几何对象包含来自操作几何对象的几何形状。 注意:
同一运算就是操作几何对象与被操作几何对象先求交,然后求交结果再与被操作几何对象求并的运算。
- 如果被操作几何对象为点类型,则结果几何对象为被操作几何对象;
- 如果被操作几何对象为线类型,则结果几何对象为被操作几何对象,但是与操作几何对象相交的部分将被打断;
- 如果被操作几何对象为面类型,则结果几何对象保留以被操作几何对象为控制边界之内的所有多边形,并且把与操作几何对象相交的地方分割成多个对象。
- 该操作适合的几何对象类型:
操作几何对象:面; 被操作几何对象:点、线、面。
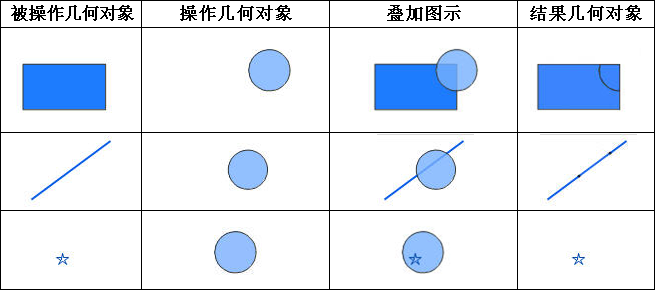
参数: 返回: 同一操作后的几何对象
返回类型:
-
iobjectspy.data.intersect(geometry1, geometry2, tolerance=None)¶ 对两个几何对象求交,返回两个几何对象的交集。目前仅支持线线求交、面面求交。 目前仅支持面面求交和线线求交,如下图示所示:
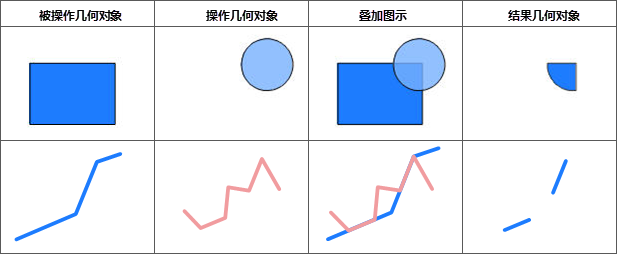
注意,如果两对象有多个相离的公共部分,求交的结果将是一个复杂对象。
参数: 返回: 求交操作后的几何对象。
返回类型:
-
iobjectspy.data.intersect_line(start_point1, end_point1, start_point2, end_point2, is_extended)¶ 返回两条线段(直线)的交点。
参数: 返回: 两条线段(直线)的交点。
返回类型:
-
iobjectspy.data.intersect_polyline(points1, points2)¶ 返回两条折线的交点。
参数: 返回: 点串构成的折线的交点。
返回类型: list[Point2D]
-
iobjectspy.data.union(geometry1, geometry2, tolerance=None)¶ 对两个对象进行合并操作。进行合并后,两个面对象在相交处被多边形分割。 注意:
进行求并运算的两个几何对象必须是同类型的,目前版本只支持面、线类型的合并。
该操作适合的几何对象类型:
- 操作几何对象:面、线;
- 被操作几何对象:面、线。
参数: 返回: 合并操作后的几何对象。
返回类型:
-
iobjectspy.data.update(geometry, update_geometry, tolerance=None)¶ 对被操作对象进行更新操作。用操作几何对象替换与被操作几何对象的重合部分,是一个先擦除后粘贴的过程。操作对象和被操作对象必须都是面对象。
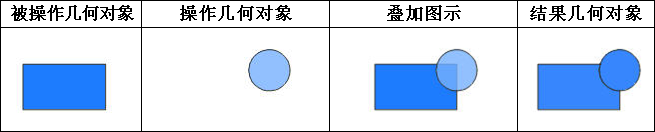
参数: 返回: 更新操作后的几何对象。
返回类型:
-
iobjectspy.data.xor(geometry1, geometry2, tolerance=None)¶ 对两个对象进行异或运算。即对于每一个被操作几何对象,去掉其与操作几何对象相交的部分,而保留剩下的部分。 进行异或运算的两个几何对象必须是同类型的,只支持面面。
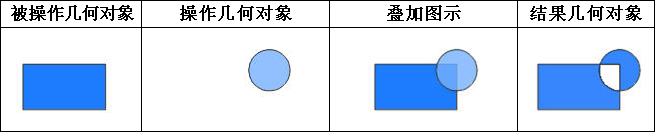
参数: 返回: 进行异或运算的结果几何对象。
返回类型:
-
iobjectspy.data.compute_concave_hull(points, angle=45.0)¶ 计算点集的凹闭包。
参数: 返回: 返回可以包含指定点集中所有点的凹多边形。
返回类型:
-
iobjectspy.data.compute_convex_hull(points)¶ 计算几何对象的凸闭包,即最小外接多边形。返回一个简单凸多边形。
参数: points (list[Point2D] or tuple[Point2D] or Geometry) -- 点集 返回: 最小外接多边形。 返回类型: GeoRegion
-
iobjectspy.data.compute_geodesic_area(geometry, prj)¶ 计算经纬度面积。
注意:
- 使用该方法计算经纬度面积,在通过 prj 参数指定投影坐标系类型对象(PrjCoordSys)时,必须通过该对象的 set_type 方法设置投影坐 标系类型为地理经纬坐标系( PrjCoordSysType.PCS_EARTH_LONGITUDE_LATITUDE),否则计算结果错误。
参数: - geometry (GeoRegion) -- 指定的需要计算经纬度面积的面对象。
- prj (PrjCoordSys) -- 指定的投影坐标系类型
返回: 经纬度面积
返回类型: float
-
iobjectspy.data.compute_geodesic_distance(points, major_axis, flatten)¶ 计算测地线的长度。 曲面上两点之间的短程线称为测地线。球面上的测地线即是大圆。 测地线又称“大地线”或“短程线”,是地球椭球面上两点间的最短曲线。在大地线上,各点的主曲率方向均与该点上曲面法线相合。它在圆球面上为 大圆弧, 在平面上就是直线。在大地测量中,通常用大地线来代替法截线,作为研究和计算椭球面上各种问题。
测地线是在一个曲面上,每一点处测地曲率均为零的曲线。
参数: 返回: 测地线的长度。
返回类型: float
-
iobjectspy.data.compute_geodesic_line(start_point, end_point, prj, segment=18000)¶ 根据指定起始终止点计算测地线,返回结果线对象。
参数: - start_point (Point2D) -- 输入的测地线起始点。
- end_point (Point2D) -- 输入的测地线终止点。
- prj (PrjCoordSys) -- 空间参考坐标系。
- segment (int) -- 用来拟合半圆的弧段个数
返回: 构造测地线成功,返回测地线对象,否则返回 None
返回类型:
-
iobjectspy.data.compute_geodesic_line2(start_point, angle, distance, prj, segment=18000)¶ 根据指定起始点、方位角度以及距离计算测地线,返回结果线对象。
参数: - start_point (Point2D) -- 输入的测地线起始点。
- angle (float) -- 输入的测地线方位角。正负均可。
- distance (float) -- 输入的测地线长度。单位为米。
- prj (PrjCoordSys) -- 空间参考坐标系。
- segment (int) -- 用来拟合半圆的弧段个数
返回: 构造测地线成功,返回测地线对象,否则返回 None
返回类型:
-
iobjectspy.data.compute_parallel(geo_line, distance)¶ 根据距离求已知折线的平行线,返回平行线。
参数: - geo_line (GeoLine) -- 已知折线对象。
- distance (float) -- 所求平行线间的距离。
返回: 平行线。
返回类型:
-
iobjectspy.data.compute_parallel2(point, start_point, end_point)¶ 求经过指定点与已知直线平行的直线。
参数: 返回: 平行线
返回类型:
-
iobjectspy.data.compute_perpendicular(point, start_point, end_point)¶ 计算已知点到已知线的垂线。
参数: 返回: 点到直线的垂线
返回类型:
-
iobjectspy.data.compute_perpendicular_position(point, start_point, end_point)¶ 计算已知点到已知线的垂足。
参数: 返回: 点在直线上的垂足
返回类型:
-
iobjectspy.data.compute_distance(geometry1, geometry2)¶ 求两个几何对象之间的距离。 注意:几何对象的类型只能是点、线和面。这里的距离指的是两个几何对象边线间最短距离。例如:点到线的最短距离就是点到该线的垂直距离。
参数: 返回: 两个几何对象之间的距离
返回类型: float
-
iobjectspy.data.point_to_segment_distance(point, start_point, end_point)¶ 计算已知点到已知线段的距离。
参数: 返回: 点到线段的距离。如果点到线段的垂足不在线段上,则返回点到线段较近的端点的距离。
返回类型: float
-
iobjectspy.data.resample(geometry, distance, resample_type='RTBEND')¶ 对几何对象进行重采样。 对几何对象重采样是按照一定规则剔除一些节点,以达到对数据进行简化的目的(如下图所示),其结果可能由于使用不同的重采样方法而不同。 SuperMap 提供两种方法对几何对象进行重采样,分别为光栏法和道格拉斯-普克法。有关这两种方法的详细介绍,请参见
VectorResampleType类。
参数: - geometry (GeoLine or GeoRegion) -- 指定的要进行重采样的几何对象。支持线对象和面对象。
- distance (float) -- 指定的重采样容限。
- resample_type (VectorResampleType or str) -- 指定的重采样方法。
返回: 重采样后的几何对象。
返回类型:
-
iobjectspy.data.smooth(points, smoothness)¶ 对指定的点串对象进行光滑处理
有关光滑的更多内容,可以参考
jsupepry.analyst.smooth()方法的介绍。参数: 返回: 光滑处理结果点串。
返回类型:
-
iobjectspy.data.compute_default_tolerance(prj)¶ 计算坐标系默认容限。
参数: prj (PrjCoordSys) -- 指定的投影坐标系类型对象。 返回: 返回指定的投影坐标系类型对象的默认容限值。 返回类型: float
-
iobjectspy.data.split_line(source_line, split_geometry, tolerance=1e-10)¶ 使用点、线或面对象对线对象进行分割(打断)。 该方法可用于使用点、线、面对象对线对象进行打断或分割。下面以一个简单线对象对这三种情况进行说明:
- 点对象打断线对象。使用点对象对线对象进行打断,原线对象在点对象位置打断为两个线对象。如下图所示,使用点(黑色)对线(蓝色)进行打断,结果为两个线对象(红色线和绿色线 )。

使用点、线或面对象对线对象进行分割(打断)。 该方法可用于使用点、线、面对象对线对象进行打断或分割。下面以一个简单线对象 对这三种情况进行说明
- 当分割线为线段时,操作线将会在其与分割线的交点处被分割为两个线对象。如下图所示,图中黑色线为分割线,分割后原线对象被分为两个线对象(红色线和绿色线 )。
- 当分割线为折线时,可能与操作线有多个交点,此时会在所有交点处将操作线打断,然后按顺序将位于奇数和偶数次序的线段分别合并,产生两个线对象。也就是说, 使用 折线分割线时,可能会产生复杂线对象。下图展示的就是这种情况,分割后,红色的线和绿色的线分别为一个复杂线对象。
面对象分割线对象。面对象分割线对象与线分割线类似,会在分割面和操作线的所有交点处将操作线打断,然后分别将位于奇数和偶数位置的线合并,产生两个线对象。 这种情况会产生至少一个复杂线对象。下图中,面对象(浅橙色)将线对象分割为红色和绿色两个复杂线对象。
注意:
- 如果被分割的线对象为复杂对象,那么如果分割线经过子对象,则会将该子对象分割为两个线对象,因此,分割复杂线对象可能产生多个线对象。
- 用于分割的线对象或者面对象如果有自相交,分割不会失败,但分割的结果可能不正确。因此,应尽量使用没有自相交的线或面对象来分割线。
参数: 返回: 分割后的线对象数组。
返回类型: list[GeoLine]
-
iobjectspy.data.split_region(source_region, split_geometry)¶ 用线或面几何对象分割面几何对象。 注意:参数中的分割对象与被分割对象必须至少有两个交点,否则的话会分割失败。
参数: 返回: 返回分割后的面对象,正确分隔后会得到两个面对象。
返回类型: tuple[GeoRegion]
-
iobjectspy.data.georegion_to_center_line(source_region, pnt_from=None, pnt_to=None)¶ 提取面对象的中心线,一般用于提取河流的中心线。 该方法用于提取面对象的中心线。如果面包含岛洞,提取时会绕过岛洞,采用最短路径绕过。如下图。
如果面对象不是简单的长条形,而是具有分叉结构,则提取的中心线是最长的一段。如下图所示。
如果提取的不是期望的中心线,可以通过指定起点和终点,提取面对象的中心线,一般用于提取河流的中心线。尤其是河流干流的中心线, 并且可以指定提取的起点和终点。如果面包含岛洞,提取时会绕过岛洞,采用的是最短路径绕过。如下图。
pnt_from 参数和 pnt_to 参数所指定起点和终点,是作为提取的参考点,也就是说,系统提取的中心线可能不会严格从指定的起点出发,到指定的终点结束。系统一般会在指定的起点和终点的附近,找到一个较近的点作为提取的起点或终点。 同时需要注意:
- 如果将起点和终点指定为相同的点,即等同于不指定提取的起点和终点,则提取的是面对象的最长的一条中心线。
- 如果指定的起点或终点在面对象的外面,则提取失败。
参数: 返回: 提取的中心线,是一个二维线对象
返回类型:
-
iobjectspy.data.orthogonal_polygon_fitting(geometry, width_threshold, height_threshold)¶ 面对象的直角多边形拟合 如果一串连续的节点到最小面积外接矩形的下界的距离大于 height_threshold, 且节点的总宽度大于 width_threshold,则对连续节点进行拟合。
参数: 返回: 进行直角化的多边形对象,如果失败,返回 None
返回类型:
-
class
iobjectspy.data.PrjCoordSys(prj_type=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase投影坐标系类。投影坐标系统由地图投影方式、投影参数、坐标单位和地理坐标系组成。SuperMap Objects Java 中提供了很多预定义的投影系统,用户可以 直接使用,此外,用户还可以定制自己投影系统。投影坐标系是定义在二维平面上的,不同于地理坐标系用经纬度定位地面点,投影坐标系是用 X、Y 坐标来定位 的。每一个投影坐标系都基于一个地理坐标系。
构造投影坐标系对象
参数: prj_type (PrjCoordSysType or str) -- 投影坐标系类型 -
clone()¶ 拷贝一个对象
返回类型: PrjCoordSys
-
coord_unit¶ Unit -- 返回投影系统坐标单位。投影系统的坐标单位与距离单位(distance_unit)可以不同,例如经纬度坐标下的坐标单位是度,距离单位可以是米、 公里等;即使是普通平面坐标或者投影坐标,这两个单位同样可不同。
-
distance_unit¶ Unit -- 距离(长度)单位
-
static
from_epsg_code(code)¶ 由 EPSG 编码构造投影坐标系对象
参数: code (int) -- EPSG 编码 返回类型: PrjCoordSys
-
from_file(file_path)¶ 从 xml 文件或 prj 文件中读取投影坐标信息
参数: file_path (str) -- 文件路径 返回: 构建成功返回 True,否则返回 False 返回类型: bool
-
static
from_wkt(wkt)¶ 从 WKT 字符串中构建投影坐标系对象
参数: wkt (str) -- WKT 字符串 返回类型: PrjCoordSys
-
from_xml(xml)¶ 从 xml 字符串中读取投影信息
参数: xml (str) -- xml 字符串 返回: 如果构建成功返回 True,否则返回 False。 返回类型: bool
-
geo_coordsys¶ GeoCoordSys -- 投影坐标系的地理坐标系统对象
-
static
make(prj)¶ 构造 PrjCoordSys 对象,支持从 epsg 编码,PrjCoordSysType 类型,xml 或者 wkt,或者投影信息文件中构造。注意,如果传入整型值, 必须是 epsg 编码,不能是 PrjCoordSysType 类型的整型值。
参数: prj (int or str or PrjCoordSysType) -- 投影信息 返回: 投影对象 返回类型: PrjCoordSys
-
name¶ str -- 投影坐标系对象的名称
-
prj_parameter¶ PrjParameter -- 投影坐标系统对象的投影参数
-
projection¶ Projection -- 投影坐标系统的投影方式。投影方式如等角圆锥投影、等距方位投影等等。
-
set_geo_coordsys(geo_coordsys)¶ 设置投影坐标系的地理坐标系统对象。每个投影系都要依赖于一个地理坐标系。该方法仅在坐标系类型为自定义投影坐标系和自定义地理坐标系时有效。
参数: geo_coordsys (GeoCoordSys) -- 返回: self 返回类型: PrjCoordSys
-
set_name(name)¶ 设置投影坐标系对象的名称
参数: name (str) -- 投影坐标系对象的名称 返回: self 返回类型: PrjCoordSys
-
set_prj_parameter(parameter)¶ 设置投影坐标系统对象的投影参数。
参数: parameter (PrjParameter) -- 投影坐标系统对象的投影参数 返回: self 返回类型: PrjCoordSys
-
set_projection(projection)¶ 设置投影坐标系统的投影方式。投影方式如等角圆锥投影、等距方位投影等等。
参数: projection (Projection) -- 返回: self 返回类型: PrjCoordSys
-
set_type(prj_type)¶ 设置投影坐标系类型
参数: prj_type (PrjCoordSysType or str) -- 投影坐标系类型 返回: self 返回类型: PrjCoordSys
-
to_epsg_code()¶ 返回当前对象的 EPSG 编码
返回类型: int
-
to_file(file_path)¶ 将投影坐标信息输出到文件中。只支持输出为 xml 文件。
参数: file_path (str) -- XML 文件的全路径。 返回: 导出成功返回 True,否则返回 False。 返回类型: bool
-
to_wkt()¶ 将当前投影信息输出为 WKT 字符串
返回类型: str
-
to_xml()¶ 将投影坐标系类的对象转换为 XML 格式的字符串。
返回: 表示投影坐标系类的对象的 XML 字符串 返回类型: str
-
type¶ PrjCoordSysType -- 投影坐标系类型
-
-
class
iobjectspy.data.GeoCoordSys¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase地理坐标系类。
地理坐标系由大地参照系、中央子午线、坐标单位组成。在地理坐标系中,单位一般用度来表示,也可以用度分秒表示。东西向(水平方向)的范围为-180度至180 度。南北向(垂直方向)的范围为-90度至90度。
地理坐标是用经纬度表示地面点位置的球面坐标。在球形系统中,赤道面的平行面同地球椭球面相交所截的圈称为纬圈,也叫纬线,表示东西方向,通过地球旋转轴 的面与椭球面相交所截的圈为子午圈,也称经线,表示南北方向,这些包围着地球的网格称为经纬格网。
经纬线一般用度来表示(必要时也用度分秒表示)。经度是指地面上某点所在的经线面与本初子午面所成的二面角,规定本初子午线的经度为 0 度,从本初子午线 向东 0 到 180 度为“东经”,以“E”表示,向西 0 到 -180 度为“西经”,以字母“W”表示;纬度是指地面上某点与地球球心的连线和赤道面所成的线面角,规 定赤道的纬度为 0 度,从赤道向北 0 到 90 度为“北纬”,以字母“N”表示,向南 0 到 -90 度为“南纬”,以字母“S”表示。
-
clone()¶ 复制对象
返回类型: GeoCoordSys
-
coord_unit¶ Unit -- 返回地理坐标系的单位。默认值为 DEGREE
-
from_xml(xml)¶ 从指定的 XML 字符串中构建地理坐标系类的对象,成功返回 True
参数: xml (str) -- XML 字符串 返回类型: bool
-
geo_datum¶ GeoDatum -- 返回大地参照系对象
-
geo_prime_meridian¶ GeoPrimeMeridian -- 返回中央子午线对象
-
geo_spatial_ref_type¶ GeoSpatialRefType -- 返回空间坐标系类型。
-
name¶ str -- 返回地理坐标系对象的名称
-
set_coord_unit(unit)¶ 设置地理坐标系的单位。
参数: unit (Unit or str) -- 地理坐标系的单位 返回: self 返回类型: GeoCoordSys
-
set_geo_datum(datum)¶ 设置大地参照系对象
参数: datum (GeoDatum) -- 返回: self 返回类型: GeoCoordSys
-
set_geo_prime_meridian(prime_meridian)¶ 设置中央子午线对象
参数: prime_meridian (GeoPrimeMeridian) -- 返回: self 返回类型: GeoCoordSys
-
set_geo_spatial_ref_type(spatial_ref_type)¶ 设置空间坐标系类型。
参数: spatial_ref_type (GeoSpatialRefType or str) -- 空间坐标系类型 返回: self 返回类型: GeoCoordSys
-
set_name(name)¶ 设置地理坐标系对象的名称
参数: name (str) -- 地理坐标系对象的名称 返回: self 返回类型: GeoCoordSys
-
set_type(coord_type)¶ 设置地理坐标系类型
参数: coord_type (GeoCoordSysType or str) -- 地理坐标系类型 返回: self 返回类型: GeoCoordSys
-
to_xml()¶ 将地理坐标系类的对象转换为 XML 格式的字符串。
返回类型: str
-
type¶ GeoCoordSysType -- 返回地理坐标系类型
-
-
class
iobjectspy.data.GeoDatum(datum_type=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase大地参照系类。 该类包含有地球椭球参数。 地球椭球体仅仅是描述了地球的大小及形状,为了更准确地描述地球上的地物的具体位置,需要引入大地参照系。大地参照系确定了地球椭球体相对于地球球心的位置,为地表地物的测量提供了一个参照框架,确定了地表经纬网线的原点和方向。大地参照系把地球椭球体的球心当作原点。一个地区的大地参照系的地球椭球体或多或少地偏移了真正的地心,地表上的地物坐标都是相对于该椭球体的球心的。目前被广泛利用的是 WGS84,它被当着大地测量的基本框架。不同的大地参照系适用于不同的国家和地区,一个大地参照系并不适合于所有的地区。
构造大地参照系对象
参数: datum_type (GeoDatumType or str) -- 大地参照系类型 -
from_xml(xml)¶ 据 XML 字符串构建 GeoDatum 对象,成功返回 True。
参数: xml (str) -- 返回类型: bool
-
geo_spheroid¶ GeoSpheroid -- 地球椭球体对象
-
name¶ str -- 大地参照系对象的名称
-
set_geo_spheroid(geo_spheroid)¶ 设置地球椭球体对象。只当大地参照系类型为自定义类型时才可以设置。 人们通常用球体或椭球体来描述地球的形状和大小,有时为了计算方便,可以将地球看作一个球体,但更多的时候是把它看作椭球体。一般情况下在地图比例尺 小于1:1,000,000 时,假设地球形状为一球体,因为在这种比例尺下球体和椭球体的差别几乎无法分辨;而在1:1,000,000 甚至更高精度要求的大比例 尺时,则需用椭球体逼近地球。椭球体是以椭圆为基础的,所以用两个轴来表述地球球体的大小,即长轴(赤道半径)和短轴(极地半径)。
参数: geo_spheroid (GeoSpheroid) -- 地球椭球体对象 返回: self 返回类型: GeoSpheroid
-
set_type(datum_type)¶ 设置大地参照系的类型。 当大地参照系为自定义时,用户需另外指定椭球体参数;其它的值为系统预定义,用户不必指定椭球体参数。参见
GeoDatumType。参数: datum_type (GeoDatumType or str) -- 大地参照系的类型 返回: self 返回类型: GeoDatum
-
to_xml()¶ 将大地参照系类的对象转换为 XML 格式的字符串
返回类型: str
-
type¶ GeoDatumType -- 大地参照系的类型
-
-
class
iobjectspy.data.GeoSpheroid(spheroid_type=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase地球椭球体参数类。 该类主要用来描述地球的长半径和扁率。
人们通常用球体或椭球体来描述地球的形状和大小,有时为了计算方便,可以将地球看作一个球体,但更多的时候是把它看作椭球体。一般情况下在地图比例尺小 于1:1,000,000 时,假设地球形状为一球体,因为在这种比例尺下球体和椭球体的差别几乎无法分辨;而在1:1,000,000 甚至更高精度要求的大比例尺时, 则需用椭球体逼近地球。椭球体是以椭圆为基础的,所以用两个轴来表述地球球体的大小,即长轴(赤道半径)和短轴(极地半径)。
因为同一个投影方法,不同的椭球体参数,相同的数据投影出来的结果可能相差很大,所以需要选择合适的椭球参数。不同年代、不同国家和地区使用的地球椭球参 数有可能不同,中国目前主要用的是克拉索夫斯基椭球参数;北美大陆及英法等主要用的是克拉克椭球参数。
构造地球椭球体参数类对象
参数: spheroid_type (GeoSpheroidType or str) -- 地球椭球体参数对象类型 -
axis¶ float -- 返回地球椭球体的长半径
-
clone()¶ 复制对象
返回类型: GeoSpheroid
-
flatten¶ float -- 返回地球椭球体的扁率
-
from_xml(xml)¶ 从指定的 XML 字符串中构建地球椭球体参数类的对象。
参数: xml (str) -- XML 字符串 返回: 如果构建成功返回 True,否则返回 False 返回类型: bool
-
name¶ str -- 地球椭球体对象的名称
-
set_axis(value)¶ 设置地球椭球体的长半径。地球椭球体的长半径也叫地球赤道半径,通过它和地球扁率可以求得地球椭球体的极地半径、第一偏心率、第二偏心率等等。只当 地球椭球体的类型为自定义类型时,长半径才可以被设置。
参数: value (float) -- 地球椭球体的长半径 返回: self 返回类型: GeoSpheroid
-
set_flatten(value)¶ 设置地球椭球体的扁率。只当地球椭球体的类型为自定义类型时,扁率才可以被设置。地球椭球体的扁率反映了地球椭球体的圆扁情况, 一般为地球长短半轴 之差与长半轴之比。
参数: value (float) -- 返回: self 返回类型: GeoSpheroid
-
set_name(name)¶ 设置地球椭球体对象的名称
参数: name (str) -- 地球椭球体对象的名称 返回: self 返回类型: GeoSpheroid
-
set_type(spheroid_type)¶ 设置地球椭球体的类型。该地球椭球体类型为自定义类型时,用户需另外指定椭球体的长半径和扁率;其余的值为系统预定义,用户不必指定长半径和扁率。 可参见地球椭球体
GeoSpheroidType枚举类。参数: spheroid_type (GeoSpheroidType or str) -- 返回: self 返回类型: GeoSpheroid
-
to_xml()¶ 将地球椭球参数类的对象转换为 XML 格式的字符串。
返回类型: str
-
type¶ GeoSpheroidType -- 返回地球椭球体的类型
-
-
class
iobjectspy.data.GeoPrimeMeridian(meridian_type=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase中央子午线类。 该对象主要应用于地理坐标系中,地理坐标系由三部分组成:中央子午线、参照系或者大地基准(Datum)和角度单位。
构造中央子午线对象
参数: meridian_type (GeoPrimeMeridianType or str) -- 中央经线类型 -
clone()¶ 复制对象
返回类型: GeoPrimeMeridian
-
from_xml(xml)¶ 指定的 XML 字符串构建 GeoPrimeMeridian 对象
参数: xml (str) -- XML 字符串 返回: 返回类型: bool
-
longitude_value¶ float -- 中央经线值,单位为度
-
name¶ str -- 中央经线对象的名称
-
set_longitude_value(value)¶ 设置中央经线值,单位为度
参数: value (float) -- 中央经线值,单位为度 返回: self 返回类型: GeoPrimeMeridian
-
set_name(name)¶ 设置中央经线对象的名称
参数: name (str) -- 中央经线对象的名称 返回: self 返回类型: GeoPrimeMeridian
-
set_type(meridian_type)¶ 设置中央经线类型
参数: meridian_type (GeoPrimeMeridianType or str) -- 中央经线类型 返回: self 返回类型: GeoPrimeMeridian
-
to_xml()¶ 返回表示 GeoPrimeMeridian 对象的 XML 字符串
返回类型: str
-
type¶ GeoPrimeMeridianType -- 中央经线类型
-
-
class
iobjectspy.data.Projection(projection_type=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase投影坐标系地图投影类。 地图投影就是将球面坐标转化为平面坐标的过程。
一般来说,地图投影按变形性质可以分为等角投影、等距投影和等积投影,适于不同的用途,如果是航海图,等角投影是很常用。还有一种是各类变形介于这几种之 间的任意投影,一般用作参考用途和教学地图。地图投影也可以按照构成方法分成两大类,分别为几何投影和非几何投影。几何投影是把椭球面上的经纬线网投影到 几何面上,然后将几何面展为平面而得的,包括方位投影、圆柱投影和圆锥投影;非几何投影不借助几何面,根据某些条件有数学解析法确定球面与平面之间点与点 的函数关系,包括伪方位投影、伪圆柱投影、伪圆锥投影和多圆锥投影。有关投影方式类型的详细信息请参考
ProjectionType参数: projection_type (ProjectionType or str) -- -
clone()¶ 复制对象
返回类型: Projection
-
from_xml(xml)¶ 根据 XML 字符串构建投影坐标方式对象,成功返回 True。
参数: xml (str) -- 指定的 XML 字符串 返回类型: bool
-
name¶ str -- 投影方式对象的名称
-
set_name(name)¶ 为您的自定义投影设置的名称
参数: name (str) -- 自定义投影的名称 返回: self 返回类型: Projection
-
set_type(projection_type)¶ 设置投影坐标系统的投影方式的类型。
参数: projection_type (ProjectionType or str) -- 投影坐标系统的投影方式的类型 返回: self 返回类型: Projection
-
to_xml()¶ 返回投影方式对象的 XML 字符串表示。
返回类型: str
-
type¶ ProjectionType -- 投影坐标系统的投影方式的类型
-
-
class
iobjectspy.data.PrjParameter¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase地图投影参数类。 地图投影的参数,比如中央经线、原点纬度、双标准纬线的第一和第二条纬线等
-
azimuth¶ float -- 方位角
-
central_meridian¶ float -- 中央经线角度值。单位:度。 取值范围为-180度至180度
-
central_parallel¶ float -- 返回坐标原点对应纬度值。单位:度。 取值范围为-90度至90度,在圆锥投影中通常就是投影区域最南端的纬度值。
-
clone()¶ 复制对象
返回类型: PrjParameter
-
false_easting¶ float -- 坐标水平偏移量。单位:米
-
false_northing¶ float -- 坐标垂直偏移量
-
first_point_longitude¶ float -- 返回第一个点的经度。用于方位投影或斜投影。单位:度
-
from_xml(xml)¶ 根据传入的 XML 字符串构建 PrjParameter 对象
参数: xml (str) -- 返回: 如果构建成功返回 True,否则返回 False 返回类型: bool
-
rectified_angle¶ float -- 返回改良斜正射投影(ProjectionType.RectifiedSkewedOrthomorphic)参数中的纠正角,单位为弧度
-
scale_factor¶ float -- 返回投影转换的比例因子。 用于减少投影变换的误差。墨卡托、高斯--克吕格和 UTM 投影的值一般为0.9996
-
second_point_longitude¶ float -- 返回第二个点的经度。用于方位投影或斜投影。单位:度
-
set_azimuth(value)¶ 设置方位角。主要用于斜轴投影。单位:度
参数: value (float) -- 方位角 返回: self 返回类型: PrjParameter
-
set_central_meridian(value)¶ 设置中央经线角度值。单位:度。 取值范围为-180度至180度。
参数: value (float) -- 中央经线角度值。单位:度 返回: self 返回类型: PrjParameter
-
set_central_parallel(value)¶ 设置坐标原点对应纬度值。单位:度。 取值范围为-90度至90度,在圆锥投影中通常就是投影区域最南端的纬度值。
参数: value (float) -- 坐标原点对应纬度值 返回: self 返回类型: PrjParameter
-
set_false_easting(value)¶ 设置坐标水平偏移量。单位:米。 此方法的参数值是为了避免系统坐标出现负值而加上的一个偏移量。通常用于高斯--克吕格、UTM 和墨卡托投影中。一般的值为500000米。
参数: value (float) -- 坐标水平偏移量。单位:米。 返回: self 返回类型: PrjParameter
-
set_false_northing(value)¶ 设置坐标垂直偏移量。单位:米。此方法的参数值是为了避免系统坐标出现负值而加上的一个偏移量。通常用于高斯--克吕格、UTM 和墨卡托投影中。一般的值为1000000米。
参数: value (float) -- 坐标垂直偏移量。单位:米 返回: self 返回类型: PrjParameter
-
set_first_point_longitude(value)¶ 设置第一个点的经度。用于方位投影或斜投影。单位:度
参数: value (float) -- 第一个点的经度。单位:度 返回: self 返回类型: PrjParameter
-
set_rectified_angle(value)¶ 设置改良斜正射投影(ProjectionType.RectifiedSkewedOrthomorphic)参数中的纠正角,单位为弧度。
参数: value (float) -- 改良斜正射投影(ProjectionType.RectifiedSkewedOrthomorphic)参数中的纠正角,单位为弧度 返回: self 返回类型: PrjParameter
-
set_scale_factor(value)¶ 设置投影转换的比例因子。 用于减少投影变换的误差。墨卡托、高斯--克吕格和 UTM 投影的值一般为0.9996。
参数: value (float) -- 投影转换的比例因 返回: self 返回类型: PrjParameter
-
set_second_point_longitude(value)¶ 设置第二个点的经度。用于方位投影或斜投影。单位:度。
参数: value (float) -- 第二个点的经度。单位:度 返回: self 返回类型: PrjParameter
-
set_standard_parallel1(value)¶ 设置第一标准纬线的纬度值。单位:度。主要应用于圆锥投影中。如果是单标准纬线,则第一标准纬线与第二标准纬线的纬度值相同。
参数: value (float) -- 第一标准纬线的纬度值 返回: self 返回类型: PrjParameter
-
set_standard_parallel2(value)¶ 设置第二标准纬线的纬度值。单位:度。 主要应用于圆锥投影中。如果是单标准纬线,则第一标准纬线与第二标准纬线的纬度值相同;如果是双标准纬线,则 其值不能与第一标准纬线的值相同。
参数: value (float) -- 第二标准纬线的纬度值。单位:度。 返回: self 返回类型: PrjParameter
-
standard_parallel1¶ float -- 返回第一标准纬线的纬度值。单位:度。主要应用于圆锥投影中。如果是单标准纬线,则第一标准纬线与第二标准纬线的纬度值相同。
-
standard_parallel2¶ float -- 返回第二标准纬线的纬度值。单位:度。主要应用于圆锥投影中。如果是单标准纬线,则第一标准纬线与第二标准纬线的纬度值相同;如果是双 标准纬线,则其值不能与第一标准纬线的值相同。
-
to_xml()¶ 返回 PrjParameter 对象的 XML 字符串表示
返回类型: str
-
-
class
iobjectspy.data.CoordSysTransParameter¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase投影转换参照系转换参数类,通常包括平移、旋转和比例因子。
在进行投影转换时,如果源投影和目标投影的地理坐标系不同,则需要进行参照系转换。SuperMap 提供常用的六种参照系转换方法,详见 CoordSysTransMethod 方法。不同的参照系转换方法需要指定不同的转换参数:
- 三参数转换法(GeocentricTranslation)、莫洛金斯基转换法(Molodensky)、简化的莫洛金斯基转换法(MolodenskyAbridged)属于精度较低的 几种转换方法,在数据精度要求不高的情况下一般可以采用这几种方法。这三种转换法需要给定三个平移转换参数:X 轴坐标偏移量(set_translate_x)、Y轴 坐标偏移量(set_translate_y)和 Z 轴坐标偏移量(set_translate_z)。
- 位置矢量法(PositionVector)、基于地心的七参数转换法(CoordinateFrame)、布尔莎方法(BursaWolf)属于精度较高的几种转换方法。需要七个 参数来进行调整和转换,包括除上述的三个平移转换参数外,还需要设置三个旋转转换参数(X 轴旋转角度(set_rotate_x)、Y 轴旋转角度(set_rotate_y) 和 Z 轴旋转角度(set_rotate_z))和投影比例尺差参数(set_scale_difference)。
-
clone()¶ 复制对象
返回类型: CoordSysTransParameter
-
from_xml(xml)¶ 根据 XML 字符串构建 CoordSysTransParameter 对象,成功返回 True
参数: xml (str) -- 返回类型: bool
-
rotate_x¶ float -- X 轴的旋转角度
-
rotate_y¶ float -- Y 轴的旋转角度
-
rotate_z¶ float -- Z 轴的旋转角度
-
rotation_origin_x¶ float -- 旋转原点的X坐标
-
rotation_origin_y¶ float -- 旋转原点的 Y 坐标的量
-
rotation_origin_z¶ float -- 旋转原点的Z坐标的量
-
scale_difference¶ float -- 投影比例尺差。单位为百万分之一。用于不同大地参照系之间的转换
-
set_rotate_x(value)¶ 设置 X 轴的旋转角度。用于不同大地参照系之间的转换。单位为弧度。
参数: value (float) -- X 轴的旋转角度 返回: self 返回类型: CoordSysTransParameter
-
set_rotate_y(value)¶ 设置 Y 轴的旋转角度。用于不同大地参照系之间的转换。单位为弧度。
参数: value (float) -- Y 轴的旋转角度 返回: self 返回类型: CoordSysTransParameter
-
set_rotate_z(value)¶ 设置 Z 轴的旋转角度。用于不同大地参照系之间的转换。单位为弧度。
参数: value (float) -- Z 轴的旋转角度 返回: self 返回类型: CoordSysTransParameter
-
set_rotation_origin_x(value)¶ 设置旋转原点的 X 坐标的量
参数: value (float) -- 旋转原点的 X 坐标的量 返回: self 返回类型: CoordSysTransParameter
-
set_rotation_origin_y(value)¶ 设置旋转原点的 Y 坐标的量
参数: value (float) -- 旋转原点的 Y 坐标的量 返回: self 返回类型: CoordSysTransParameter
-
set_rotation_origin_z(value)¶ 设置旋转原点的 Z 坐标的量
参数: value (float) -- 旋转原点的 Z 坐标的量 返回: self 返回类型: CoordSysTransParameter
-
set_scale_difference(value)¶ 设置投影比例尺差。单位为百万分之一。用于不同大地参照系之间的转换
参数: value (float) -- 投影比例尺差 返回: self 返回类型: CoordSysTransParameter
-
set_translate_x(value)¶ 设置 X 轴的坐标偏移量。单位为米
参数: value (float) -- X 轴的坐标偏移量 返回: self 返回类型: CoordSysTransParameter
-
set_translate_y(value)¶ 设置 Y 轴的坐标偏移量。单位为米
参数: value (float) -- Y 轴的坐标偏移量 返回: self 返回类型: CoordSysTransParameter
-
set_translate_z(value)¶ 设置 Z 轴的坐标偏移量。单位为米
参数: value (float) -- Z 轴的坐标偏移量 返回: self 返回类型: CoordSysTransParameter
-
to_xml()¶ 将该 CoordSysTransParameter 对象输出为 XML 字符串。
返回类型: str
-
translate_x¶ float -- 返回 X 轴的坐标偏移量。单位为米
-
translate_y¶ float -- 返回 Y 轴的坐标偏移量。单位为米
-
translate_z¶ float -- 返回 Z 轴的坐标偏移量。单位为米
-
class
iobjectspy.data.CoordSysTranslator¶ 基类:
object投影转换类。主要用于投影坐标之间及投影坐标系之间的转换。
投影转换一般有三种工作方式:地理(经纬度)坐标和投影坐标之间的转换使用 forward() 方法、投影坐标和地理(经纬度)坐标之间的转换使用inverse() 方法 、 两种投影坐标系之间的转换使用convert() 方法。
注意:当前版本不支持光栅数据的投影转换。即在同一数据源中,投影转换只转换矢量数据部分。地理坐标系(Geographic coordinate system)也称为地理 坐标系统,是以经纬度为地图的存储单位的。很明显,地理坐标系是球面坐标系统。如果将地球上的数字化信息存放到球面坐标系统上,就需要有这样的椭球体具有 如下特点:可以量化计算的,具有长半轴(Semimajor Axis),短半轴(Semiminor Axis),偏心率(Flattening),中央子午线(prime meridian)及大地基准面(datum)。
投影坐标系统(Projection coordinate system)实质上便是平面坐标系统,其地图单位通常为米。将球面坐标转化为平面坐标的过程便称为投影。所以每一个 投影坐标系统都必定会有地理坐标系统(Geographic Coordinate System)参数。 因此就存在着投影坐标之间的转换以及投影坐标系之间的转换。
在进行投影转换时,对文本对象(GeoText)投影转换后,文本对象的字高和角度会相应地转换,如果用户不需要这样的改变,需要对转换后的文本对象修正其字高和角度。
-
static
convert(source_data, target_prj_coordsys, coordsys_trans_parameter, coord_sys_trans_method, source_prj_coordsys=None, out_data=None, out_dataset_name=None)¶ 根据源投影坐标系与目标投影坐标系对输入数据进行投影转换。根据是否设置了有效的结果数据源信息,可以直接修改源数据或者将转换后的结果数据存储到结果数据源中。
参数: - source_data (DatasetVector or Geometry or list[Point2D] or list[Geometry]) -- 被转换的数据。直接将数据集、几何对象,二维点序列和几何对象序列进行转换。
- target_prj_coordsys (PrjCoordSys) -- 目标投影坐标系对象。
- coordsys_trans_parameter (投影坐标系转换参数。包括坐标的平移量、旋转角度、投影比例尺差,详情请参见
CoordSysTransParameter类。) -- - coord_sys_trans_method (CoordSysTransMethod) -- 投影转换的方法。详情参见
CoordSysTransMethod。在进行投影转换时,如果源投影和目标投影的地理坐标系相同,该参数的设置不起作用。 - source_prj_coordsys (PrjCoordSys) -- 源投影坐标系对象。当被转换的数据为数据集对象时,此参数无效,会使用数据集的投影坐标系信息。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源。当结果数据源有效时,会将转换后的结果存储到新的结果数据集中,否则将直接修改原数据的点坐标。
- out_dataset_name (str) -- 结果数据集名称。当 out_datasource 有效时才起作用
返回: 根据是否设置了结果数据源对象:
- 如果设置了结果数据源对象,转换成功,会把转换后的结果写到结果数据集中并返回结果数据集名称或结果数据集对象,如果转换失败,返回 None。
- 如果没设置结果数据源对象,转换成功,会直接修改输入的源数据的点坐标并返回 True,否则返回 False。
返回类型: DatasetVector or str or bool
-
static
forward(data, prj_coordsys, out_data=None, out_dataset_name=None)¶ 在同一地理坐标系下,该方法用于将指定的 Point2D 列表中的点二维点对象从地理坐标转换到投影坐标
参数: - data (list[Point2D] or tuple[Point2D]) -- 被转换的二维点列表
- prj_coordsys (PrjCoordSys) -- 二维点对象所在的投影坐标系
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源对象,可以选择将转换后得到的点保存到数据源中。如果为空,将返回转换后得到点的列表
- out_dataset_name (str) -- 结果数据集名称,out_datasource 有效时才起作用
返回: 转换失败返回None,转换成功,如果设置了有效的 out_datasource,返回结果数据集或数据集名称,否则,返回转换后得到的点的列表。
返回类型: DatasetVector or str or list[Point2D]
-
static
inverse(data, prj_coordsys, out_data=None, out_dataset_name=None)¶ 在同一投影坐标系下,该方法用于将指定的 Point2D 列表中的二维点对象从投影坐标转换到地理坐标。
参数: - data (list[Point2D] or tuple[Point2D]) -- 被转换的二维点列表
- prj_coordsys (PrjCoordSys) -- 二维点对象所在的投影坐标系
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据源对象,可以选择将转换后得到的点保存到数据源中。如果为空,将返回转换后得到点的列表
- out_dataset_name (str) -- 结果数据集名称,out_datasource 有效时才起作用
返回: 转换失败返回None,转换成功,如果设置了有效的 out_datasource,返回结果数据集或数据集名称,否则,返回转换后得到的点的列表。
返回类型: DatasetVector or str or list[Point2D]
-
static
-
class
iobjectspy.data.StepEvent(title=None, message=None, percent=None, remain_time=None, cancel=None)¶ 基类:
object指示进度条的事件。当监听器的目标进度发生变化时触发该事件。 某些功能能返回当前任务执行的进度信息,进度信息通过 StepEvent 返回,用户可以从 StepEvent 中获取当前任务进行的状态。
例如,用户可以定义一个函数来显示缓冲区分析的进度信息。
>>> def progress_function(step_event): print('%s-%s' % (step_event.title, step_event.message)) >>> >>> ds = Workspace().open_datasource('E:/data.udb') >>> dt = ds['point'].query('SmID < 1000') >>> buffer_dt = create_buffer(dt, 10, 10, progress=progress_function)
-
is_cancel¶ bool -- 事件的取消状态
-
message¶ str -- 正在进行操作的信息
-
percent¶ int -- 当前操作完成的百分比
-
remain_time¶ int -- 完成当前操作预计的剩余时间,单位为秒
-
set_cancel(value)¶ 设置事件的取消状态。操作进行时如果设置为取消,则任务会中断执行。
参数: value (bool) -- 事件取消的状态,如果为true,则中断执行
-
title¶ str -- 进度信息的标题
-
-
class
iobjectspy.data.WorkspaceConnectionInfo(server=None, workspace_type=None, version=None, driver=None, database=None, name=None, user=None, password=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase工作空间连接信息类。包括了进行工作空间连接的所有信息,如所要连接的服务器名称,数据库名称,用户名,密码等。对不同类型的工作空间,所以在使用该类所 包含的成员时,请注意该成员所适用的工作空间类型。
初始化工作空间链接信息对象。
参数: - server (str) -- 数据库服务器名或文件名
- workspace_type (WorkspaceType or str) -- 工作空间的类型
- version (WorkspaceVersion or str) -- 工作空间的版本
- driver (str) -- 设置使用 ODBC 连接的数据库的驱动程序名,对目前支持的数据库工作空间中,SQL Server 数据库使用 ODBC 连接,SQL Server 数据库的驱动程序名如为 SQL Server 或 SQL Native Client
- database (str) -- 工作空间连接的数据库名
- name (str) -- 工作空间在数据库中的名
- user (str) -- 登录数据库的用户名
- password (str) -- 登录工作空间连接的数据库或文件的密码。
-
database¶ str -- 工作空间连接的数据库名。对数据库类型工作空间适用
-
driver¶ str -- 使用 ODBC 连接的数据库的驱动程序名
-
name¶ str -- 工作空间在数据库中的名称,对文件型的工作空间,此名称为空
-
password¶ str -- 登录工作空间连接的数据库或文件的密码
-
server¶ str -- 数据库服务器名或文件名
-
set_database(value)¶ 设置工作空间连接的数据库名。对数据库类型工作空间适用
参数: value (str) -- 工作空间连接的数据库名 返回: self 返回类型: WorkspaceConnectionInfo
-
set_driver(value)¶ 设置 使用 ODBC 连接的数据库的驱动程序名。对目前支持的数据库工作空间中,SQL Server 数据库使用 ODBC 连接,SQL Server 数据库的驱动 程序名如为 SQL Server 或 SQL Native Client。
参数: value (str) -- 使用 ODBC 连接的数据库的驱动程序名 返回: self 返回类型: WorkspaceConnectionInfo
-
set_name(value)¶ 设置工作空间在数据库中的名称。
参数: value (str) -- 工作空间在数据库中的名称,对文件型的工作空间,此名称设为空 返回: self 返回类型: WorkspaceConnectionInfo
-
set_password(value)¶ 设置登录工作空间连接的数据库或文件的密码。此密码的设置只对 Oracle 和 SQL 数据源有效,对本地(UDB)数据源无效。
参数: value (str) -- 登录工作空间连接的数据库或文件的密码 返回: self 返回类型: WorkspaceConnectionInfo
-
set_server(value)¶ 设置数据库服务器名或文件名。
参数: value (str) -- 对于 Oracle 数据库,其服务器名为其 TNS 服务名称; 对于 SQL Server 数据库,其服务器名为其系统的 DNS(Database Source Name)名称;对于 SXWU 和 SMWU 文件,其服务器名称为其文件名称,其中包括路径名称和文件的后缀名。特别地,此处的路径为绝对路径。 返回: self 返回类型: WorkspaceConnectionInfo
-
set_type(value)¶ 设置工作空间的类型。
参数: value (WorkspaceType or str) -- 工作空间的类型 返回: self 返回类型: WorkspaceConnectionInfo
-
set_user(value)¶ 设置登录数据库的用户名。对数据库类型工作空间适用。
参数: value (str) -- 登录数据库的用户名 返回: self 返回类型: WorkspaceConnectionInfo
-
set_version(value)¶ 设置工作空间版本。
参数: value (WorkspaceVersion or str) -- 工作空间的版本 返回: self 返回类型: WorkspaceConnectionInfo 例如,设置工作空间版本为 UGC60:
>>> conn_info = WorkspaceConnectionInfo() >>> conn_info.set_version('UGC60') >>> print(conn_info.version) WorkspaceVersion.UGC60
-
type¶ WorkspaceType -- 工作空间的类型。工作空间可以存储在文件中,也可以存储在数据库中。目前支持的文件型的工作空间的类型为 SXWU 格式和 SMWU 格式的工作空间; 数据库型工作空间为 ORACLE 格式和 SQL 格式的工作空间;默认的工作空间类型为未存储的工作空间
-
user¶ str -- 登录数据库的用户名
-
version¶ WorkspaceVersion -- 工作空间的版本。默认为 UGC70.
-
class
iobjectspy.data.Workspace¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase工作空间是用户的工作环境,主要完成数据的组织和管理,包括打开、关闭、创建、保存工作空间文件。工作空间(Workspace)是 SuperMap 中的一个重要的 概念,工作空间存储了一个工程项目(同一个事务过程)中所有的数据源,地图的组织关系。通过工作空间对象可以管理数据源和地图。工作空间中只存储数据源的 连接信息和位置等,实际的数据源都是存储在数据库或者 UDB 中。工作空间只存储地图的一些配置信息,如地图包含图层的个数,图层引用的数据集,地图范围, 背景风格等。在当前版本中,一个程序只能存在一个工作空间对象,如果用户没有打开特定的工作空间,程序将默认创建一个工作空间对象。用户如果需要打开新的 工作空间对象,需要先将当前工作空间保存和关闭,否则,存储在工作空间中的一些信息可能会丢失。
例如,创建数据源对象:
>>> ws = Workspace() >>> ws.create_datasource(':memory:') >>> print(len(ws.datasources)) 1 >>> ws_a = Workspace() >>> ws_a.create_datasource(':memory:') >>> ws == ws_a True >>> print(len(ws_a.datasources)) 2 >>> ws.close()
-
add_map(map_name, map_or_xml)¶ 添加 Map 到当前工作空间中
参数: - map_name (str) -- 地图名称
- map_or_xml (Map or str) -- 地图对象或地图的 XML 描述
返回: 新添加的地图在此地图集合对象中的序号。
返回类型: int
-
caption¶ str -- 工作空间显示名称,便于用户做一些标识。
-
classmethod
close()¶ 关闭工作空间,关闭工作空间将会销毁当前工作空间的实例对象。工作空间的关闭之前确保使用的该工作空间的地图等内容关闭或断开链接。 如果工作空间是在 Java 端注册的,将不会实际关闭工作空间对象,只会解除对 Java 工作空间对象的绑定关系,后续将不能继续操作 Java 的工作空间对象,除非使用 Workspace() 构造新的实例。
-
close_all_datasources()¶ 关闭所有的数据源
-
close_datasource(item)¶ 关闭指定的数据源。
参数: item (str or int) -- 数据源的别名或序号 返回: 关闭成功返回 True,否则返回 False 返回类型: bool
-
connection_info¶ WorkspaceConnectionInfo -- 工作空间的连接信息
-
classmethod
create(conn_info, save_existed=True, saved_connection_info=None)¶ 创建一个新的工作空间对象。在创建新的工作空间前,用户可以通过设定 save_existed 为 True 先保存当前工作空间对象,也可以设定 saved_connection_info 将当前工作空间另存为指定的位置。
参数: - conn_info (WorkspaceConnectionInfo) -- 工作空间的连接信息
- save_existed (bool) -- 是否保存当前的工作空间工作。如果设置为 True,则会先将当前工作空间保存然后再关闭当前工作空间,否则会直接关闭当前工作空间,然后再打开新的工作空间对象。save_existed 只适合用于当前工作空间不在内存中的情形。默认为 True。
- saved_connection_info (WorkspaceConnectionInfo) -- 选择将当前工作另存到 saved_connection_info 指定的工作空间中。 默认为 None。
返回: 新的工作空间对象
返回类型:
-
create_datasource(conn_info)¶ 根据指定的数据源连接信息,创建新的数据源。
参数: conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息: - 数据源连接信息。具体可以参考 DatasourceConnectionInfo.make()- 如果 conn_info 为 str 时,可以为 ':memory:', udb 文件路径,udd 文件路径,dcf 文件路径,数据源连接信息的 xml 字符串 - 如果 conn_info 为 dict,为DatasourceConnectionInfo.to_dict()的返回结果。返回: 数据源对象 返回类型: Datasource
-
datasources¶ list[Datasource] -- 当前工作空间下的所有数据源对象。
-
description¶ str -- 用户加入的对当前工作空间的描述或说明性信息
-
get_datasource(item)¶ 获取指定的数据源对象。
参数: item (str or int) -- 数据源的别名或序号 返回: 数据源对象 返回类型: Datasource
-
get_map_xml(index_or_name)¶ 返回指定名称或序号的地图的 XML 描述
参数: index_or_name (int or str) -- 指定的地图名称或序号 返回: 地图的 XML 描述 返回类型: str
-
index_of_datasource(alias)¶ 查找指定的数据源别名所在序号。不存在将抛出异常。
参数: alias (str) -- 数据源别名 返回: 数据源所在的序号 返回类型: int 引发: ValueError -- 不存在指定的数据源别名时抛出异常。
-
insert_map(index, map_name, map_or_xml)¶ 在指定序号的位置处添加一个地图,地图的内容由 XML 字符串来确定。
参数: - index (int) -- 指定的序号。
- map_name (str) -- 指定的地图名称。该名称不区分大小写。
- map_or_xml (Map or str) -- 用来表示待插入地图或地图的 XML 字符串。
返回: 如果插入地图成功,返回 true;否则返回 false。
返回类型: bool
-
is_contains_datasource(item)¶ 是否存在指定序号或者数据源别名的数据源
参数: item (str or int) -- 数据源的别名或序号 返回: 存在返回 True,否则返回 False 返回类型: bool
-
is_modified()¶ 返回工作空间的内容是否有改动,如果对工作空间的内容进行了一些修改,则返回 True,否则返回 False。工作空间负责管理数据源、地图,其中任何 一项内容发生变动,此属性都会返回 True,在关闭整个应用程序时,先用此属性判断工作空间是否已有改动,可用于提示用户是否需要存盘。
返回: 对工作空间的内容进行了一些修改,则返回 True,否则返回 False 返回类型: bool
-
modify_datasource_alias(old_alias, new_alias)¶ 修改数据源的别名。数据源别名不区分大小写
参数: - old_alias (str) -- 待修改的数据源别名
- new_alias (str) -- 数据源的新别名
返回: 如果对数据源修改别名成功,则返回 True,否则返回 False
返回类型: bool
-
classmethod
open(conn_info, save_existed=True, saved_connection_info=None)¶ 打开一个新的工作空间对象。在打开新的工作空间前,用户可以通过设定 save_existed 为 True 先保存当前工作空间对象,也可以设定 saved_connection_info 将当前工作空间另存为指定的位置。
参数: - conn_info (WorkspaceConnectionInfo) -- 工作空间的连接信息
- save_existed (bool) -- 是否保存当前的工作空间工作。如果设置为 True,则会先将当前工作空间保存然后再关闭当前工作空间,否则会直接关闭当前工作空间,然后再打开新的工作空间对象。save_existed 只适合用于当前工作空间不在内存中的情形。默认为 True。
- saved_connection_info (WorkspaceConnectionInfo) -- 选择将当前工作另存到 saved_connection_info 指定的工作空间中。 默认为 None。
返回: 新的工作空间对象
返回类型:
-
open_datasource(conn_info, is_get_existed=True)¶ 根据数据源连接信息打开数据源。如果设置的连接信息是UDB类型数据源,或者 is_get_existed 为 True,如果工作空间中已经存在对应的数据源,则 会直接返回。不支持直接打开内存数据源,要使用内存数据源,需要使用
create_datasource()创建内存数据源。参数: - conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息:
- 数据源连接信息。具体可以参考
DatasourceConnectionInfo.make()- 如果 conn_info 为 str 时,可以为 ':memory:', udb 文件路径,udd 文件路径,dcf 文件路径,数据源连接信息的 xml 字符串 - 如果 conn_info 为 dict,为DatasourceConnectionInfo.to_dict()的返回结果。 - is_get_existed (bool) -- is_get_existed 为 True,如果工作空间中已经存在对应的数据源,则会直接返回。为 false 时,则会打开新的数据源。对于 UDB 类型数据源,无论 is_get_existed 为 True 还是 False,都会优先返回工作空间中的数据源。判断 DatasourceConnectionInfo 是否与工作空间中的数据源是同一个数据源,可以查看
DatasourceConnectionInfo.is_same()
返回: 数据源对象
返回类型: >>> ws = Workspace() >>> ds = ws.open_datasource('E:/data.udb') >>> print(ds.type) EngineType.UDB
- conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息:
- 数据源连接信息。具体可以参考
-
remove_map(index_or_name)¶ 删除此地图集合对象中指定序号或名称的地图
参数: index_or_name (str or int) -- 待删除地图的序号或名称 返回: 删除成功,返回 true;否则返回 false。 返回类型: bool
-
rename_map(old_name, new_name)¶ 修改地图对象的名称
参数: - old_name (str) -- 地图对象当前的名称
- new_name (str) -- 指定的新的地图名称
返回: 修改成功返回 True,否则返回 False
返回类型: bool
-
classmethod
save()¶ 用于将现存的工作空间存盘,不改变原有的名称
返回: 保存成功返回 True,否则返回 False 返回类型: bool
-
classmethod
save_as(conn_info)¶ 用指定的工作空间连接信息对象来保存工作空间文件。
参数: conn_info (WorkspaceConnectionInfo) -- 工作空间连接信息对象 返回: 另存成功返回 True,否则返回 False 返回类型: bool
-
set_caption(caption)¶ 设置工作空间显示名称。
参数: caption (str) -- 工作空间显示名称
-
set_description(description)¶ 设置用户加入的对当前工作空间的描述或说明性信息
参数: description (str) -- 用户加入的对当前工作空间的描述或说明性信息
-
-
iobjectspy.data.open_datasource(conn_info, is_get_existed=True)¶ 根据数据源连接信息打开数据源。如果设置的连接信息是UDB类型数据源,或者 is_get_existed 为 True,如果工作空间中已经存在对应的数据源,则 会直接返回。不支持直接打开内存数据源,要使用内存数据源,需要使用
create_datasource()创建内存数据源。具体参考
Workspace.open_datasource()参数: - conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息:
- 数据源连接信息。具体可以参考
DatasourceConnectionInfo.make()- 如果 conn_info 为 str 时,可以为 ':memory:', udb 文件路径,udd 文件路径,dcf 文件路径,数据源连接信息的 xml 字符串 - 如果 conn_info 为 dict,为DatasourceConnectionInfo.to_dict()的返回结果。 - is_get_existed (bool) -- is_get_existed 为 True,如果工作空间中已经存在对应的数据源,则会直接返回。为 false 时,则会打开新的数据源。对于 UDB 类型数据源,无论 is_get_existed 为 True 还是 False,都会优先返回工作空间中的数据源。判断 DatasourceConnectionInfo 是否与工作空间中的数据源是同一个数据源,可以查看
DatasourceConnectionInfo.is_same()
返回: 数据源对象
返回类型: - conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息:
- 数据源连接信息。具体可以参考
-
iobjectspy.data.get_datasource(item)¶ 获取指定的数据源对象。
具体参考
Workspace.get_datasource()参数: item (str or int) -- 数据源的别名或序号 返回: 数据源对象 返回类型: Datasource
-
iobjectspy.data.close_datasource(item)¶ 关闭指定的数据源。
具体参考
Workspace.close_datasource()参数: item (str or int) -- 数据源的别名或序号 返回: 关闭成功返回 True,否则返回 False 返回类型: bool
-
iobjectspy.data.list_datasources()¶ 返回当前工作空间下的所有数据源对象。
返回: 当前工作空间下的所有数据源对象 返回类型: list[Datasource]
-
iobjectspy.data.create_datasource(conn_info)¶ 根据指定的数据源连接信息,创建新的数据源。
参数: conn_info (str or dict or DatasourceConnectionInfo) -- udb文件路径或数据源连接信息: - 数据源连接信息。具体可以参考 DatasourceConnectionInfo.make()- 如果 conn_info 为 str 时,可以为 ':memory:', udb 文件路径,udd 文件路径,dcf 文件路径,数据源连接信息的 xml 字符串 - 如果 conn_info 为 dict,为DatasourceConnectionInfo.to_dict()的返回结果。返回: 数据源对象 返回类型: Datasource
-
iobjectspy.data.create_mem_datasource()¶ 创建一个内存数据源
返回: 数据源对象 返回类型: Datasource
-
iobjectspy.data.dataset_dim2_to_dim3(source, z_field_or_value, line_to_z_field=None, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维数据集转换为三维数据集,二维的点、线和面数据集将会分别转换为三维的点、线和面数据集。
参数: - source (DatasetVector or str) -- 二维数据集,支持点、线和面数据集
- z_field_or_value (str or float) -- z 值的来源字段名称或指定的 z 值,如果为字段,则必须是数值型字段。
- line_to_z_field (str) -- 当输入的是二维线数据集时,用于指定终止 z 值的字段名称,则 z_field_or_value 则作为起始 z 值的字段的名称。 line_to_z_field 必须为字段名称,不支持指定的 z 值。
- saved_fields (list[str] or str) -- 将要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果三数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_dim3_to_dim2(source, out_z_field='Z', saved_fields=None, out_data=None, out_dataset_name=None)¶ 将三维的点、线和面数据集转换为二维的点、线和面数据集。
参数: - source (DatasetVector or str) -- 三维数据集,支持三维点、线和面数据集
- out_z_field (str) -- 保留 Z 值的字段,如果为 None 或不合法,将会获取到一个有效的字段用于存储对象的 Z 值
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_point_to_line(source, group_fields=None, order_fields=None, field_stats=None, out_data=None, out_dataset_name=None)¶ 将二维点数据集中点对象,根据分组字段进行分组构造线对象,返回一个二维线数据集
参数: - source (DatasetVector or str) -- 二维点数据集
- group_fields (list[str]) -- 二维点数据集中用于分组的字段名称,只有分组字段名称的字段值都相等时才会将点连接成线。
- order_fields (list[str] or str) -- 排序字段,同一分组内的点,按照排序字段的字段值的升序进行排序,再连接成线。如果为 None,则默认使用 SmID 字段进行排序。
- field_stats (list[tuple(str,AttributeStatisticsMode)] or list[tuple(str,str)] or str) -- 字段统计信息,同一分组内的点属性进行字段统计。为一个list,list中每个元素为一个 tuple,tuple的大小为2,tuple的第一个元素为被统计的字段名称,tuple的第二个元素为统计类型。
注意,不支持
AttributeStatisticsMode.MAXINTERSECTAREA - out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 二维点数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_line_to_point(source, mode='VERTEX', saved_fields=None, out_data=None, out_dataset_name=None)¶ 将线数据集转换为点数据集
参数: - source (DatasetVector or str) -- 二维线数据集
- mode (LineToPointMode or str) -- 线对象转换为点对象的方式
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维点数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_line_to_region(source, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将线数据集转换为面数据集。此方法将线对象直接转换为面对象,如果线对象不是首位相接,可能会转换失败。如果要将线数据集转换为面数据集,更 可靠的方式的是拓扑构面
topology_build_regions()参数: - source (DatasetVector or str) -- 二维线数据集
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源信息
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维面数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_region_to_line(source, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维面对象转换为线数据集。此方法会将每个点对象直接转换为线对象,如果需要提取不包含重复线的线数据集,可以使用
pickup_border()参数: - source (DatasetVector or str) -- 二维面数据集
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果线数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_region_to_point(source, mode='INNER_POINT', saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维面数据集转换为点数据集
参数: - source (DatasetVector or str) -- 二维面数据集
- mode (RegionToPointMode or str) -- 面对象转换为点对象的方式
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源信息
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维点数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_field_to_text(source, field, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将点数据集转换为文本数据集
参数: - source (DatasetVector or str) -- 输入的二维点数据集
- field (str) -- 包含文本信息的字段,用于构造文本几何对象的文本信息。
- saved_fields (list[str] or str) -- 需要保留的字段名称
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 结果文本数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_text_to_field(source, out_field='Text')¶ 将二维文本数据集的文本信息存储到字段中。文本对象的文本信息将会存储在指定的 out_field 字段中。
参数: - source (DatasetVector or str) -- 输入的二维文本数据集。
- out_field (str) -- 存储文本信息的字段名称。如果 out_field 指定的字段名称已经存在,必须为文本型字段。如果不存在,将会新建一个文本型字段。
返回: 成功返回 True,否则返回 False。
返回类型: bool
-
iobjectspy.data.dataset_text_to_point(source, out_field='Text', saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维文本数据集转换为点数据集,文本对象的文本信息将会存储在指定的 out_field 字段中
参数: - source (DatasetVector or str) -- 输入的二维文本数据集
- out_field (str) -- 存储文本信息的字段名称。如果 out_field 指定的字段名称已经存在,必须为文本型字段。如果不存在,将会新建一个文本型字段。
- saved_fields (list[str] or str) -- 需要保留的字段名称。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 二维点数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_field_to_point(source, x_field, y_field, z_field=None, saved_fields=None, out_data=None, out_dataset_name=None)¶ 根据数据集中字段,构造二维点数据集或三维点数据集。如果指定了有效的 z_field将会得到三维点数据集,否则将会得到二维点数据集
参数: - source (DatasetVector or str) -- 提供数据的数据集,可以为属性表或点、线、面等数据集
- x_field (str) -- x 坐标值的来源字段,必须有效。
- y_field (str) -- y 坐标值的来源字段,必须有效。
- z_field (str) -- z 坐标值的来源字段,可选。
- saved_fields (list[str] or str) -- 需要保留的字段名称。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源
- out_dataset_name (str) -- 结果数据集名称
返回: 二维点或三维点数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_network_to_line(source, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维网络数据集的转换为线数据集,网络数据集的 SmEdgeID、SmFNode和SmTNode 字段值将会存储在结果数据集的 EdgeID、FNode和TNode 字段 中,如果 EdgeID、FNode 或 TNode 已被占用,会获取到一个有效的字段。
参数: - source (DatasetVector or str) -- 被转换的二维网络数据集
- saved_fields (list[str] or str) -- 需要保存的字段名称。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源信息
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维线数据集或数据集名称
返回类型: DatasetVector or str
-
iobjectspy.data.dataset_network_to_point(source, saved_fields=None, out_data=None, out_dataset_name=None)¶ 将二维网络数据集的点子数据集转换为点数据集,网络数据集的 SmNodeID 字段值将会存储在结果数据集的 NodeID 字段中,如果 NodeID 已被占用,会获取到一个有效的字段。
参数: - source (DatasetVector or str) -- 被转换的二维网络数据集
- saved_fields (list[str] or str) -- 需要保存的字段名称。
- out_data (Datasource or DatasourceConnectionInfo or str) -- 结果数据集所在的数据源信息
- out_dataset_name (str) -- 结果数据集名称
返回: 结果二维点数据集或数据集名称
返回类型: DatasetVector or str
-
class
iobjectspy.data.Color(seq=(0, 0, 0))¶ 基类:
tuple定义RGB 颜色对象,用户可以通过指定一个三个元素的元组指定 RGB 颜色值,也可以使用使用四个元素的元组指定 RGBA 颜色值。 默认情形下,Alpha 值为255。

通过 tuple 构造一个 Color
参数: seq (tuple[int,int,int] or tuple[int,int,int,int]) -- 指定的 RGB 或 RGBA 颜色值 -
A¶ int -- 获取 Color 的 A 值
-
B¶ int -- 获取 Color 的 B 值
-
G¶ int -- 获取 Color 的 G 值
-
R¶ int -- 获取 Color 的 R 值
-
static
make(value)¶ 构造 Color 对象
参数: value (Color or str or tuple[int,int,int] or tuple[int,int,int,int]) -- 用于构造 Color 对象的值,如果是 str,可以是使用 ','拼接的字符串,例如:'0,255,232' or '0,255,234,54' 返回: 颜色对象 返回类型: Color
构造颜色值 (255, 222, 173)
返回: 颜色值 (255, 222, 173) 返回类型: Color
构造颜色值 (0, 0, 128)
返回: 颜色值 (0, 0, 128) 返回类型: Color
-
static
rgb(red, green, blue, alpha=255)¶ 通过指定 R、G、B、A 值构造 Color 对象
参数: - red (int) -- Red 值
- green (int) -- Green 值
- blue (int) -- Blue 值
- alpha (int) -- Alpha 值
返回: 颜色对象
返回类型:
-
-
class
iobjectspy.data.GeoStyle¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase几何风格类。用于定义点状符号、线状符号、填充符号及其相关设置。对于文本对象只能设置文本风格,不能设置几何风格。 除复合数据集(CAD 数据集)之外,其他类型数据集都不存储几何对象的风格信息。 填充模式分为普通填充模式和渐变填充模式。在普通填充模式下,可以使用图片或矢量符号等进行填充;在渐变填充模式下,有四种渐变类型可供选择:线性渐变填充,辐射渐变填充,圆锥渐变填充和四角渐变填充
-
fill_back_color¶ Color -- 填充符号的背景色。当填充模式为渐变填充时,该颜色为填充终止色。默认值 Color(255,255,255,255)
-
fill_fore_color¶ Color -- 填充符号的前景色。当填充模式为渐变填充时,该颜色为渐变填充起始色。默认值 Color(189,235,255,255)
-
fill_gradient_angle¶ float -- 渐变填充的旋转角度,单位为0.1度,逆时针方向为正方向。
-
fill_gradient_mode¶ FillGradientMode -- 返回渐变填充风格的渐变类型。关于各渐变填充类型的定义,请参见
FillGradientMode
-
fill_gradient_offset_ratio_x¶ float -- 返回渐变填充中心点相对于填充区域范围中心点的水平偏移百分比。设填充区域范围中心点的坐标为(x0,y0),填充中心点的坐 标为(x,y),填充区域范围的宽度为 a,水平偏移百分比为 dx,则 x=x0 + a*dx/100 该百分比可以为负,当其为负时,填充中心点相对 于填充区域范围中心点向 x 轴负方向偏移。该方法对辐射渐变、圆锥渐变、四角渐变和线性渐变填充有效。
-
fill_gradient_offset_ratio_y¶ float -- 返回填充中心点相对于填充区域范围中心点的垂直偏移百分比。设填充区域范围中心点的坐标为(x0,y0),填充中心点的坐标为 (x,y),填充区域范围的高度为 b,垂直偏移百分比为 dy,则 y=y0 + b*dy/100 该百分比可以为负,当其为负时,填充中心点相对于填 充区域范围中心点向 y 轴负方向偏移。该方法对辐射渐变、圆锥渐变、四角渐变和线性渐变填充有效。
-
fill_opaque_rate¶ int -- 返回填充不透明度,合法值0-100的数值。其值为0表示完全透明;若其值为100表示完全不透明。赋值小于0时按照0处理,大于100时按照100处理。
-
fill_symbol_id¶ int -- 返回填充符号的编码。此编码用于唯一标识各普通填充风格的填充符号。填充符号可以用户自定义,也可以使用系统自带的符号库。
-
static
from_xml(xml)¶ 根据 xml 描述信息构造 GeoStyle 对象
参数: xml (str) -- 描述 GeoStyle 的 xml 信息。具体参考 to_xml()返回: 几何对象风格 返回类型: GeoStyle
-
is_fill_back_opaque¶ bool -- 当前填充背景是否不透明。当前填充背景是不透明的,则为 True,否则为 False。
-
line_color¶ Color -- 线状符号型风格或点状符号的颜色。
-
static
line_style(line_id=0, line_width=0.1, color=(0, 0, 0))¶ 构造一个线对象的对象风格
参数: - line_id (int) -- 线状符号的编码。此编码用于唯一标识各线状符号。线状符号可以用户自定义,也可以使用系统自带的符号库。
- line_width (float) -- 线状符号的宽度。单位为毫米,精度到0.1。
- color (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 状符号型风格
返回: 线对象的对象风格
返回类型:
-
line_symbol_id¶ int -- 线状符号的编码。此编码用于唯一标识各线状符号。线状符号可以用户自定义,也可以使用系统自带的符号库。
-
line_width¶ float -- 线状符号的宽度。单位为毫米,精度到0.1。
-
marker_angle¶ float -- 点状符号的旋转角度,以度为单位,精确到0.1度,逆时针方向为正方向。此角度可以作为普通填充风格中填充符号的旋转角度。
-
marker_size¶ tuple[float,float] -- 点状符号的大小,单位为毫米,精确到0.1毫米。
-
marker_symbol_id¶ int -- 点状符号的编码。此编码用于唯一标识各点状符号。点状符号可以用户自定义,也可以使用系统自带的符号库。
-
static
point_style(marker_id=0, marker_angle=0.0, marker_size=(4, 4), color=(0, 0, 0))¶ 构造一个点对象的对象风格
参数: - marker_id (int) -- 点状符号的编码。此编码用于唯一标识各点状符号。点状符号可以用户自定义,也可以使用系统自带的符号库。所指定的符号的 ID 值必须是符号库中已存在的 ID 值。
- marker_angle (float) -- 点状符号的旋转角度。以度为单位,精确到0.1度,逆时针方向为正方向。此角度可以作为普通填充风格中填充符号的旋转角度。
- marker_size (tuple[int,int]) -- 状符号的大小,单位为毫米,精确到0.1毫米。其值必须大于等于0。如果为0,则表示不显示,如果是小于0,会抛出异常。
- color (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 点状符号的颜色。
返回: 点对象的对象风格
返回类型:
-
set_fill_back_color(value)¶ 设置填充符号的背景色。当填充模式为渐变填充时,该颜色为渐变填充终止色。
参数: value (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 用来设置填充符号的背景色。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_back_opaque(value)¶ 设置当前填充背景是否不透明。
参数: value (bool) -- 当前填充背景是否透明,true 为不透明。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_fore_color(value)¶ 设置填充符号的前景色。当填充模式为渐变填充时,该颜色为渐变填充起始颜色。
参数: value (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 用来设置填充符号的前景色 返回: 对象自身 返回类型: GeoStyle
-
set_fill_gradient_angle(value)¶ 设置渐变填充的旋转角度,单位为0.1度,逆时针方向为正方向。有关各渐变填充风格类型的定义,请参见 FillGradientMode。 对于不同的渐变填充,其旋转的后的效果各异,但都是以最小外接矩形的中心为旋转中心,逆时针旋转的:
- 线性渐变
当设置的角度为0-360度的任意角度时,经过起始点和终止点的线以最小外接矩形的中心为旋转中心逆时针旋转,渐变风格随之旋转,依然从 线的起始端渐变到终止端的线性渐变。如下列举在特殊角度的渐变风格:当渐变填充角度设置为0度或者360度的时候,那么渐变填充风格为由左到右从起始色到终止色的线性渐变,如图所示起始色为黄色,终止色为粉红色;
当渐变填充角度设置为180度时,渐变填充风格与1中描述的风格正好相反,即从右到左,从起始色到终止色线性渐变;
当渐变填充角度设置为90度时,渐变填充风格为由下到上,起始色到终止色的线性渐变;
当渐变填充角度设置为270度时,渐变填充风格与3中描述的风格正好相反,即从上到下,起始色到终止色线性渐变。
- 辐射渐变
渐变填充角度设置为任何角度(不超出正常范围)时,将定义辐射渐变的圆形按照设置的角度进行旋转,由于圆是关于填充范围的最小外接矩 形的中心点对称的,所以旋转之后的渐变填充的风格始终保持一样,即从中心点到填充范围的边界,从前景色到背景色的辐射渐变。- 圆锥渐变
当渐变角度设置为0-360度之间的任何角度,该圆锥的所有母线将发生旋转,以圆锥的中心点,即填充区域的最小外接矩形的中心为旋转中心, 逆时针方向旋转。如图所示的例子中,旋转角度为90度,所有的母线都从起始位置(旋转角度为零的位置)开始旋转到指定角度,以经过起始点的母线为例,其从0度位置旋转到90度位置。
- 四角渐变
根据给定的渐变填充角度,将发生渐变的正方形以填充区域范围的中心为中心进行相应的旋转,所有正方形都是从初始位置即旋转角度为零的 默认位置开始旋转。渐变依然是从内部的正方形到外部的正方形发生从起始色到终止色的渐变.参数: value (float) -- 来设置渐变填充的旋转角度 返回: 对象自身 返回类型: GeoStyle
-
set_fill_gradient_mode(value)¶ 设置渐变填充风格的渐变类型
参数: value (FillGradientMode or str) -- 渐变填充风格的渐变类型。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_gradient_offset_ratio_x(value)¶ 设置渐变填充中心点相对于填充区域范围中心点的水平偏移百分比。设填充区域范围中心点的坐标为(x0,y0),填充中心点的坐标为(x,y), 填充区域范围的宽度为 a,水平偏移百分比为 dx,则 x=x0 + a*dx/100 该百分比可以为负,当其为负时,填充中心点相对于填充区域范围 中心点向 x 轴负方向偏移。该方法对辐射渐变、圆锥渐变、四角渐变和线性渐变填充有效。
参数: value (float) -- 用于设置填充中心点的水平偏移量的值。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_gradient_offset_ratio_y(value)¶ 设置填充中心点相对于填充区域范围中心点的垂直偏移百分比。设填充区域范围中心点的坐标为(x0,y0),填充中心点的坐标为(x,y), 填充区域范围的高度为 b,垂直偏移百分比为 dy,则 y=y0 + b*dy/100 该百分比可以为负,当其为负时,填充中心点相对于填充区域范围 中心点向 y 轴负方向偏移。该方法对辐射渐变、圆锥渐变、四角渐变和线性渐变填充有效。
参数: value (float) -- 用来设置填充中心点的垂直偏移量的值。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_opaque_rate(value)¶ 设置填充不透明度,合法值0-100的数值。其值为0表示空填充;若其值为100表示完全不透明。赋值小于0时按照0处理,大于100时按照100处理。
参数: value (int) -- 用来设置填充不透明度的整数值。 返回: 对象自身 返回类型: GeoStyle
-
set_fill_symbol_id(value)¶ 设置填充符号的编码。此编码用于唯一标识各普通填充风格的填充符号。填充符号可以用户自定义,也可以使用系统自带的符号库。所指定的填充符号的 ID 值必须是符号库中已存在的 ID 值。
参数: value (int) -- 一个整数用来设置填充符号的编码。 返回: 对象自身 返回类型: GeoStyle
-
set_line_color(value)¶ 设置线状符号型风格或点状符号的颜色
参数: value (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 一个 Color 对象用来设置线状符号型风格或点状符号的颜色。 返回: 对象自身 返回类型: GeoStyle
-
set_line_symbol_id(value)¶ 设置线状符号的编码。此编码用于唯一标识各线状符号。 线状符号可以用户自定义,也可以使用系统自带的符号库。所指定的线型符号的 ID 值必须是符号库中已存在的 ID 值。
参数: value (int) -- 一个用来设置线型符号的编码的整数值。 返回: 对象自身 返回类型: GeoStyle
-
set_marker_angle(value)¶ 设置点状符号的旋转角度,以度为单位,精确到0.1度,逆时针方向为正方向。此角度可以作为普通填充风格中填充符号的旋转角度。
参数: value (float) -- 点状符号的旋转角度。 返回: 对象自身 返回类型: GeoStyle
-
set_marker_size(width, height)¶ 设置点状符号的大小,单位为毫米,精确到0.1毫米。其值必须大于等于0。如果为0,则表示不显示,如果是小于0,会抛出异常。
当对点矢量图层设置风格时,如果使用的点符号为 TrueType 字体,在指定点符号的宽高尺寸时,不支持设置宽高值不相等的符号大小,即符号的宽高比例始终为 1:1。当用户设置了宽高值不相等的符号大小时,系统自动将符号大小的宽高值取为相等的值,并且等于用户所指定的高度值。
参数: - width (float) -- 宽度
- height (float) -- 高度
返回: 对象自身
返回类型:
-
set_marker_symbol_id(value)¶ 设置点状符号的编码。此编码用于唯一标识各点状符号。 点状符号可以用户自定义,也可以使用系统自带的符号库。 所指定的线型符号的 ID 值必须是符号库中已存在的 ID 值。
参数: value (int) -- 点状符号的编码。 返回: 对象自身 返回类型: GeoStyle
-
to_xml()¶ 返回表示 GeoStyle 对象的 XML 字符串。
返回类型: str
-
-
iobjectspy.data.remove_map(index_or_name)¶ 删除此地图集合对象中指定序号或名称的地图
参数: index_or_name (str or int) -- 待删除地图的序号或名称 返回: 删除成功,返回 true;否则返回 false。 返回类型: bool
-
iobjectspy.data.add_map(map_name, map_or_xml)¶ 添加 Map 到当前工作空间中
参数: - map_name (str) -- 地图名称
- map_or_xml (Map or str) -- 地图对象或地图的 XML 描述
返回: 新添加的地图在此地图集合对象中的序号。
返回类型: int
-
iobjectspy.data.get_map(index_or_name)¶ 获取指定名称或序号的地图对象
参数: index_or_name (int or str) -- 指定的地图名称或序号 返回: 地图对象 返回类型: Map
-
iobjectspy.data.zoom_geometry(geometry, center_point, scale_x, scale_y)¶ 几何对象的比例变换(缩放),支持点、线和面几何对象。 对几何对象上任意一点 point:
x 方向上的比例变换:result_point.x = point.x * scala_x + center_point.x * (1-scala_x) y 方向上的比例变换:result_point.y = point.y * scala_y + center_point.y * (1-scala_y)参数: 返回: 成功返回缩放后的几何对象,失败返回None
返回类型:
-
iobjectspy.data.divide_polygon(polygon, divide_type='PART', orientation='NORTH', angle=90.0, divide_parts=3, divide_area=0.0, divide_area_unit='SQUAREMETER', remainder_area=None, prj=None)¶ 用于国土宗地数据的对象切割,可以按面积切割或数量切割,比如,把一块大的宗地,分割出一块10亩的地块出来。也可以将整块宗地分割为10份,每份的面积都相同。
>>> ds = open_datasource('E:/data.udb') >>> dt = ds['dltb'] >>> polygon = dt.get_geometries('SmID == 1')[0] >>> #等份切割为 5 份 >>> divide_result = divide_polygon(polygon, 'PART', 'NORTH', angle=45, divide_parts=5, prj=dt.prj_coordsys) >>> print(len(divide_result)) 5 >>> #按面积切割,切割得到一个面积为500平方米的面对象 >>> divide_result = divide_polygon(polygon, 'AREA', 'EAST', 0.0, divide_parts=1, divide_area=500, >>> divide_area_unit='SQUAREMETER', prj=dt.prj_coordsys) >>> print(len(divide_result)) 2 >>> print(divide_result[0].area) 500.0
参数: - polygon (GeoRegion or Rectangle) -- 被分割的二维面对象,不能为空
- divide_type (DividePolygonType or str) -- 面切割类型,默认为 'PART'
- orientation (DividePolygonOrientation or str) -- 面切割的方位,默认为 'NORTH'
- angle (float) -- 切割方位角,与正北方向的顺时针夹角。 如果切割方位角为0或180度,则切割方位不能为北和南,如果切割方位角为90或270度,切 割方位不能为东和西。
- divide_parts (int) -- 面切割数目。对于面积切割,切割数目不能大于(切割前面对象面积/切割面积),如果是等份切割,则表示最终切割后面数目。
- divide_area (float) -- 切割面积,当切割类型为面切割时,必须设置此参数。
- divide_area_unit (AreaUnit or str) -- 切割面积的单位,当设置了 divide_area 时,需同时设置此参数。
- remainder_area (float) -- 当切割类型为面积切割时,有可能会剩余小块面对象,可以通过此参数,将小块面对象合并到相邻的对象中。如果剩余面积 小于当前指定的面积值,才做合并。当值大于0时才有效,如果小于等于0,则不合并。
- prj (PrjCoordSys or str) -- 被分割的面对象的空间参考坐标系。不支持地理坐标系,因为切割面对象需要按照面积进行切割(等份切割需要转换为等面积切割),在经纬度下无法 直接计算出有效面积,必须转换为投影坐标系才能计算出面积,但转为投影系后数据会有较大的变形,导致最后结果可能存在错误。
返回: 分割后得到的面对象数组
返回类型: list[GeoRegion]
-
class
iobjectspy.data.CSGNode(other=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBaseCSGNode基类
-
__add__(other)¶ :布尔并,other可以是CSGNode、CSGEntity、Point3D :当other是CSGNode时,构造新的CSGBoolNode :当other是CSGEntity时,构造新的CSGBoolNode :当other是Point3D时,平移当前node
-
__mul__(other)¶ :布尔差,other可以是CSGNode、CSGEntity、Point3D、Matrix :当other是CSGNode时,构造新的CSGBoolNode :当other是CSGEntity时,构造新的CSGBoolNode :当other是Point3D时,当前node平移 :当other是Matrix时,矩阵变换当前Node
-
__sub__(other)¶ :布尔差,other可以是CSGNode、CSGEntity :构造新的CSGBoolNode
-
clone()¶ 子类实现 :return:
-
static
from_json(str_json)¶ 从json解析
-
matrix¶
-
rotate(_rotate)¶ :旋转
-
set_Matrix(value)¶
-
to_json()¶ 输出为json
-
type¶ type -- 返回CSGNodeType
-
-
class
iobjectspy.data.CSGEntity(other=None)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase-
__add__(other)¶ :布尔并,other可以是CSGNode、CSGEntity、Point3D :当other是CSGNode时,构造CSGBoolNode并返回 :当other是CSGEntity时,构造CSGBoolNode并返回 :当other是Point3D时,构造SimpleNode平移并返回
-
__mul__(other)¶ :布尔交,other可以是CSGNode、CSGEntity、Point3D、Matrix :当other是CSGNode时,构造CSGBoolNode并返回 :当other是CSGEntity时,构造CSGBoolNode并返回 :当other是Point3D时,构造SimpleNode缩放并返回 :当other是Matrix时,构造SimpleNode变换并返回
-
__sub__(other)¶ :布尔差,other可以是CSGNode、CSGEntity :当other是CSGNode时,构造CSGBoolNode并返回 :当other是CSGEntity时,构造CSGBoolNode并返回
-
area¶
-
clone()¶ 克隆 :return:新实例对象
-
copy_j_object()¶ 根据当前实体类型创建java对象 :return:java实例对象
-
rotate(_rotate)¶ :旋转
-
type¶
-
volume¶
-
-
class
iobjectspy.data.CSGBooleanNode(left=None, right=None, boolType=CSGBooleanType.BOOL_UNION)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGNode:用左右两个节点构造, left,right可以同时为CSGNode、CSGEntity,也可一个是CSGNode、一个是CSGEntity
-
bool_type¶
-
clone()¶ 子类实现 :return:
-
left_node¶
-
right_node¶
-
set_bool_type(value)¶
-
set_left_node(value)¶
-
set_right_node(value)¶
-
type()¶ type: 返回CSGNodeType
-
-
class
iobjectspy.data.CSGSimpleNode(data=None)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGNode:可以用None、Entity或CSGSimpleNode初始化
-
clone()¶ 子类实现 :return:
-
get_entity()¶
-
set_entity(entity)¶
-
type()¶ type: 返回CSGNodeType
-
-
class
iobjectspy.data.Box(_length=10, _width=10, _height=10)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity立方体
:length width ,height 长宽高
-
height¶
-
length¶
-
set_height(value)¶
-
set_length(value)¶
-
set_width(value)¶
-
width¶
-
-
class
iobjectspy.data.Sphere(dradius=10.0)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity球体
:半径
-
radius¶
-
set_radius(value)¶
-
-
class
iobjectspy.data.Cylinder(top_radius=10, bottom_radius=10, height=50)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity圆柱体(上下半径可以不一致)
:上下底面半径可不同
-
bottom_radius¶
-
height¶
-
set_bottom_radius(value)¶
-
set_height(value)¶
-
set_top_radius(value)¶
-
top_radius¶
-
-
class
iobjectspy.data.Cone(radius=10, height=50)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity圆锥体
:param radius:底面半径 :param height: 高
-
height¶
-
radius¶
-
set_height(value)¶
-
set_radius(value)¶
-
-
class
iobjectspy.data.Ellipsoid(semiAxis_x=10, semiAxis_y=10, semiAxis_z=10)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity椭球体
:param semiAxis_x:x半轴 :param semiAxis_y:y半轴 :param semiAxis_z:z半轴
-
semiAxis_X¶
-
semiAxis_Y¶
-
semiAxis_Z¶
-
set_semiAxis_X(value)¶
-
set_semiAxis_Y(value)¶
-
set_semiAxis_Z(value)¶
-
-
class
iobjectspy.data.Torus(_ring_radius=10, _pipe_radius=1, _sweep_angle=360, _start_angle=0)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity圆环体
:param ring_radius:环半径 :param pipe_radius:管半径 :param sweep_angle:扫略角度 :param start_angle:起始角度
-
pipe_radius¶
-
ring_radius¶
-
set_pipe_radius(value)¶
-
set_ring_radius(value)¶
-
set_start_angle(value)¶
-
set_sweep_angle(value)¶
-
start_angle¶
-
sweep_angle¶
-
-
class
iobjectspy.data.TruncatedCone(_top_radius=10, _bottom_radius=20, _height=20, _top_offset=Point2D(0.000000, 0.000000))¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity圆台体
:param _top_radius:顶部半径 :param _bottom_radius:底部半径 :param _height:高度 :param _top_offset:顶面圆心偏移(Point2D)
-
bottom_radius¶
-
height¶
-
set_bottom_radius(value)¶
-
set_height(value)¶
-
set_top_offset(value)¶
-
set_top_radius(value)¶
-
top_offset¶
-
top_radius¶
-
-
class
iobjectspy.data.Table3D(_bottom_length=10, _bottom_length1=10, _top_length=5, _top_length1=5, _height=6)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity棱台体
:param _bottom_length:底面对角线长度1(与X轴重合) :param _bottom_length1:底面对角线长度2(与Y轴重合) :param _top_length:顶面对角线长度1(与X轴平行) :param _top_length1:顶面对角线长度2(与Y轴平行) :param _height:高度
-
bottom_length¶
-
bottom_length1¶
-
height¶
-
set_bottom_length(value)¶
-
set_bottom_length1(value)¶
-
set_height(value)¶
-
set_top_length(value)¶
-
set_top_length1(value)¶
-
top_length¶
-
top_length1¶
-
-
class
iobjectspy.data.Wedge(_bottom_length=10, _bottom_Width=8, _top_length=8, _topWidth=0, _height=15, _top_offset=Point2D(1.000000, 4.000000))¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity楔形体
:param _bottom_length:底面对角线长度1(与X轴重合) :param _bottom_length1:底面对角线长度2(与Y轴重合) :param _top_length:顶面对角线长度1(与X轴平行) :param _top_length1:顶面对角线长度2(与Y轴平行) :param _top_offset:顶面偏移 :param _height:高度
-
bottom_length¶
-
bottom_width¶
-
height¶
-
set_bottom_length(value)¶
-
set_bottom_width(value)¶
-
set_height(value)¶
-
set_top_length(value)¶
-
set_top_offset(value)¶
-
set_top_width(value)¶
-
top_length¶
-
top_offset¶
-
top_width¶
-
-
class
iobjectspy.data.Pyramid(_length=10, _width=10, _height=10)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity棱锥体
:length width ,height 长宽高
-
height¶
-
length¶
-
set_height(value)¶
-
set_length(value)¶
-
set_width(value)¶
-
width¶
-
-
class
iobjectspy.data.EllipticRing(_semi_major_axis=10, _semi_minor_axis=8, _pipe_padius=1)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity椭圆环
:param semi_major_axis:长半轴 :param _semi_minor_axis:短半轴 :param _pipe_padius:管半径
-
pipe_radius¶
-
semi_major_axis¶
-
semi_minor_axis¶
-
set_pipe_radius(value)¶
-
set_semi_major_axis(value)¶
-
set_semi_minor_axis(value)¶
-
-
class
iobjectspy.data.RectangularRing(_length=10, _width=8, _pipe_radius=1)¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity矩形环
:param _length:长 :param _width:宽 :param _pipe_radius:管半径
-
length¶
-
pipe_radius¶
-
set_length(value)¶
-
set_pipe_radius(value)¶
-
set_width(value)¶
-
width¶
-
-
class
iobjectspy.data.SlopedCylinder(_bottom_radius=10, _top_radius=10, _height=50, _top_slope=Point2D(0.000000, 0.000000), _bottom_slope=Point2D(0.000000, 0.000000))¶ 基类:
iobjectspy._jsuperpy.data.geo.CSGEntity斜口圆柱
:param _bottom_radius:底部半径 :param _top_radius:顶部半径 :param _height:高 :param _top_angle:顶部坡度(与X、Y轴角度) :param _bottom_angle:底部坡度(与X、Y轴角度)
-
bottom_radius¶
-
bottom_slope¶
-
height¶
-
set_bottom_radius(value)¶
-
set_bottom_slope(value)¶
-
set_height(value)¶
-
set_top_radius(value)¶
-
set_top_slope(value)¶
-
top_radius¶
-
top_slope¶
-
iobjectspy.enums module¶
-
class
iobjectspy.enums.PixelFormat¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了栅格与影像数据存储的像素格式类型常量。
光栅数据结构实际上就是像元的阵列,像元(或像素)是光栅数据的最基本信息存储单位。在 SuperMap 中有两种类型的光栅数据:栅格数据集(DatasetGrid) 和影像数据集(DatasetImage),栅格数据集多用来进行栅格分析,因而其像元值为地物的属性值,如高程,降水量等;而影像数据集一般用来进行显示或作为底 图,因而其像元值为颜色值或颜色的索引值。
变量: - PixelFormat.UNKONOWN -- 未知的像素格式
- PixelFormat.UBIT1 -- 每个像元用 1 个比特表示。对栅格数据集来说,可表示 0 和 1 两种值;对影像数据集来说,可表示黑白两种颜色,对应单色影像数据。
- PixelFormat.UBIT4 -- 每个像元用 4 个比特表示。对栅格数据集来说,可表示 0 到 15 共 16 个整数值;对影像数据集来说,可表示 16 种颜色,这 16 种颜色为索引色,在其颜色表中定义,对应 16 色的影像数据。
- PixelFormat.UBIT8 -- 每个像元用 8 个比特,即 1 个字节表示。对栅格数据集来说,可表示 0 到 255 共 256 个整数值;对影像数据集来说,可表示 256 种渐变的颜色,这 256 种颜色为索引色,在其颜色表中定义,对应 256 色的影像数据。
- PixelFormat.BIT8 -- 每个像元用 8 个比特,即 1 个字节来表示。对栅格数据集来说,可表示 -128 到 127 共 256 个整数值。每个像元用 8 个比特,即 1 个字节来表示。对栅格数据集来说,可表示 -128 到 127 共 256 个整数值。
- PixelFormat.BIT16 -- 每个像元用 16 个比特,即 2 个字节表示。对栅格数据集来说,可表示 -32768 到 32767 共 65536 个整数值;对影像数据集来说,16 个比特中,红,绿,蓝各用 5 比特来表示,剩余 1 比特未使用,对应彩色的影像数据。
- PixelFormat.UBIT16 -- 每个像元用 16 个比特,即 2 个字节来表示。对栅格数据集来说,可表示 0 到 65535 共 65536 个整数值
- PixelFormat.RGB -- 每个像元用 24 个比特,即 3 个字节来表示。仅提供给影像数据集使用,24 比特中红、绿、蓝各用 8 比特来表示,对应真彩色的影像数据。
- PixelFormat.RGBA -- 每个像元用 32 个比特,即 4 个字节来表示。仅提供给影像数据集使用,32 比特中红、绿、蓝和 alpha 各用 8 比特来表示,对应增强真彩色的影像数据。
- PixelFormat.BIT32 -- 每个像元用 32 个比特,即 4 个字节来表示。对栅格数据集来说,可表示 -231 到 (231-1) 共 4294967296 个整数值;对影像数据集来说,32 比特中,红,绿,蓝和 alpha 各用 8 比特来表示,对应增强真彩色的影像数据。该格式支持 DatasetGrid,DatasetImage(仅支持多波段)。
- PixelFormat.UBIT32 -- 每个像元用 32 个比特,即 4 个字节来表示,可表示 0 到 4294967295 共 4294967296 个整数值。
- PixelFormat.BIT64 -- 每个像元用 64 个比特,即 8 个字节来表示。可表示 -263 到 (263-1) 共 18446744073709551616 个整数值。。
- PixelFormat.SINGLE -- 每个像元用 4 个字节来表示。可表示 -3.402823E+38 到 3.402823E+38 范围内的单精度浮点数。
- PixelFormat.DOUBLE -- 每个像元用 8 个字节来表示。可表示 -1.79769313486232E+308 到 1.79769313486232E+308 范围内的双精度浮点数。
-
BIT16= 16¶
-
BIT32= 320¶
-
BIT64= 64¶
-
BIT8= 80¶
-
DOUBLE= 6400¶
-
RGB= 24¶
-
RGBA= 32¶
-
SINGLE= 3200¶
-
UBIT1= 1¶
-
UBIT16= 160¶
-
UBIT32= 321¶
-
UBIT4= 4¶
-
UBIT8= 8¶
-
UNKONOWN= 0¶
-
class
iobjectspy.enums.BlockSizeOption¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该枚举定义了像素分块的类型常量。用于栅格数据集或影像数据:
变量: - BlockSizeOption.BS_64 -- 表示64像素*64像素的分块
- BlockSizeOption.BS_128 -- 表示128像素*128像素的分块
- BlockSizeOption.BS_256 -- 表示256像素*256像素的分块
- BlockSizeOption.BS_512 -- 表示512像素*512像素的分块。
- BlockSizeOption.BS_1024 -- 表示1024像素*1024像素的分块。
-
BS_1024= 1024¶
-
BS_128= 128¶
-
BS_256= 256¶
-
BS_512= 512¶
-
BS_64= 64¶
-
class
iobjectspy.enums.AreaUnit¶ 基类:
iobjectspy._jsuperpy.enums.JEnum面积单位类型:
变量: - AreaUnit.SQUAREMILLIMETER -- 公制单位,平方毫米。
- AreaUnit.SQUARECENTIMETER -- 公制单位,平方厘米。
- AreaUnit.SQUAREDECIMETER -- 公制单位,平方分米。
- AreaUnit.SQUAREMETER -- 公制单位,平方米。
- AreaUnit.SQUAREKILOMETER -- 公制单位,平方千米。
- AreaUnit.HECTARE -- 公制单位,公顷。
- AreaUnit.ARE -- 公制单位,公亩。
- AreaUnit.QING -- 市制单位,顷。
- AreaUnit.MU -- 市制单位,亩。
- AreaUnit.SQUAREINCH -- 英制单位,平方英寸。
- AreaUnit.SQUAREFOOT -- 英制单位,平方尺。
- AreaUnit.SQUAREYARD -- 英制单位,平方码。
- AreaUnit.SQUAREMILE -- 英制单位,平方英里。
- AreaUnit.ACRE -- 英制单位,英亩。
-
ACRE= 14¶
-
ARE= 7¶
-
HECTARE= 6¶
-
MU= 9¶
-
QING= 8¶
-
SQUARECENTIMETER= 2¶
-
SQUAREDECIMETER= 3¶
-
SQUAREFOOT= 11¶
-
SQUAREINCH= 10¶
-
SQUAREKILOMETER= 5¶
-
SQUAREMETER= 4¶
-
SQUAREMILE= 13¶
-
SQUAREMILLIMETER= 1¶
-
SQUAREYARD= 12¶
-
class
iobjectspy.enums.Unit¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了表示单位的类型常量。
变量: - Unit.MILIMETER -- 毫米
- Unit.CENTIMETER -- 厘米
- Unit.DECIMETER -- 分米
- Unit.METER -- 米
- Unit.KILOMETER -- 千米
- Unit.INCH -- 英寸
- Unit.FOOT -- 英尺
- Unit.YARD -- 码
- Unit.MILE -- 英里
- Unit.SECOND -- 秒,角度单位
- Unit.MINUTE -- 分,角度单位
- Unit.DEGREE -- 度,角度单位
- Unit.RADIAN -- 弧度,弧度单位
-
CENTIMETER= 100¶
-
DECIMETER= 1000¶
-
DEGREE= 1001745329¶
-
FOOT= 3048¶
-
INCH= 254¶
-
KILOMETER= 10000000¶
-
METER= 10000¶
-
MILE= 16090000¶
-
MILIMETER= 10¶
-
MINUTE= 1000029089¶
-
RADIAN= 1100000000¶
-
SECOND= 1000000485¶
-
YARD= 9144¶
-
class
iobjectspy.enums.EngineType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了空间数据库引擎类型常量。 空间数据库引擎是在常规数据库管理系统之上的,除具备常规数据库管理系统所必备的功能之外,还提供特定的针对空间数据的存储和管理能力。 SuperMap SDX+ 是 supermap 的空间数据库技术,也是 SuperMap GIS 软件数据模型的重要组成部分。各种空间几何对象和影像数据都可以通过 SDX+ 引擎,存放到关系型数据库中,形成空间数据和属性数据一体化的空间数据库
变量: - EngineType.IMAGEPLUGINS -- 影像只读引擎类型,对应的枚举值为 5。针对通用影像格式如 BMP,JPG,TIFF 以及超图自定义影像格式 SIT,二维地图缓存配置文件格式SCI等。用户在进行二维地图缓存加载的时候,需要设置为此引擎类型,另外还需要使用
DatasourceConnectionInfo.set_server()方法,将参数设置为二维地图缓存配置文件(SCI)。对于MrSID和ECW,只读打开为了快速原则,以合成波段的方式打开,非灰度数据会默认为RGB或者RGBA的方式显示,灰度数据按原始方式显示。 - EngineType.ORACLEPLUS -- Oracle 引擎类型
- EngineType.SQLPLUS -- SQL Server 引擎类型,仅在 Windows 平台版本中支持
- EngineType.DB2 -- DB2 引擎类型
- EngineType.KINGBASE -- Kingbase 引擎类型,针对 Kingbase 数据源,不支持多波段数据
- EngineType.MEMORY -- 内存数据源。
- EngineType.OGC -- OGC 引擎类型,针对于 Web 数据源,对应的枚举值为 23。目前支持的类型有 WMS,WFS,WCS 和 WMTS。WMTS服务中默认BoundingBox和TopLeftCorner标签读取方式为(经度,纬度)。而一部分服务提供商提供的坐标格式为(纬度,经度),当你遇到这个情况时,为了保证坐标数据读取的正确性,请对SuperMap.xml文件(该文件位于Bin目录下)中相应的内容进行正确的修改。通常出现该情况的表现是本地矢量数据与发布的WMTS服务数据无法叠加到一起。
- EngineType.MYSQL -- MYSQL 引擎类型,支持 MySQL 5.6.16以上版本
- EngineType.MONGODB -- MongoDB 引擎类型,目前支持的认证方式为Mongodb-cr
- EngineType.BEYONDB -- BeyonDB 引擎类型
- EngineType.GBASE -- GBase 引擎类型
- EngineType.HIGHGODB -- HighGoDB 引擎类型
- EngineType.UDB -- UDB 引擎类型
- EngineType.POSTGRESQL -- PostgreSQL 引擎类型
- EngineType.GOOGLEMAPS -- GoogleMaps 引擎类型,该引擎为只读引擎,且不能创建。该常量仅在 Windows 32 位平台版本中支持,在 Linux版本中不提供
- EngineType.SUPERMAPCLOUD -- 超图云服务引擎类型,该引擎为只读引擎,且不能创建。该常量仅在 Windows 32 位平台版本中支持,在 Linux版本中不提供。
- EngineType.ISERVERREST -- REST 地图服务引擎类型,该引擎为只读引擎,且不能创建。针对基于 REST 协议发布的地图服务。该常量仅在 Windows 32 位平台版本中支持,在 Linux版本中不提供。
- EngineType.BAIDUMAPS -- 百度地图服务引擎类型
- EngineType.BINGMAPS -- 必应地图服务引擎类型
- EngineType.GAODEMAPS -- 高德地图服务引擎类型
- EngineType.OPENSTREETMAPS -- OpenStreetMap 引擎类型。该常量仅在 Windows 32 位平台版本中支持,在 Linux版本中不提供
- EngineType.SCV -- 矢量缓存引擎类型
- EngineType.DM -- 第三代DM引擎类型
- EngineType.ORACLESPATIAL -- Oracle Spatial 引擎类型
- EngineType.SDE --
ArcSDE 引擎类型:
- 支持ArcSDE 9.2.0 及以上版本
- 支持ArcSDE 9.2.0 及以上版本的点、线、面、文本和栅格数据集5种数据类型的读取,不支持写。
- 不支持读取ArcSDE文本的风格,ArcSDE默认存放文本的字段“TEXTSTRING”不能删,否则我们读取不到文本。
- 不支持ArcSDE 2bit位深的栅格的读取,其它位深均支持,并可拉伸显示。
- 不支持多线程。
- 使用SDE引擎,需要ArcInfo的许可,并把ArcSDE安装目录bin下的 sde.dll 、sg.dll 和 pe.dll这三个dll拷贝到SuperMap产品下的Bin目录(即SuSDECI.dll 和 SuEngineSDE.sdx 同级目录)
- 支持平台:Windows 32位 ,Windows 64位。
- EngineType.ALTIBASE -- Altibase 引擎类型
- EngineType.KDB -- KDB 引擎类型
- EngineType.SRDB -- 上容关系数据库引擎类型
- EngineType.MYSQLPlus -- MySQLPlus数据库引擎类型,实质上为MySQL+Mongo
- EngineType.VECTORFILE -- 矢量文件引擎类型。针对通用矢量格式如 shp,tab,Acad等,支持矢量文件的编辑和保存,如果是FME支持的类型则需要对应的FME许可,目前没有FME许可不支持FileGDBVector格式。
- EngineType.PGGIS -- PostgreSQL的空间数据扩展PostGIS 引擎类型
- EngineType.ES -- Elasticsearch 引擎类型
- EngineType.SQLSPATIAL -- SQLSpatial 引擎类型
- EngineType.UDBX -- UDBX 引擎类型
- EngineType.TIBERO -- Tibero 引擎类型
- EngineType.SHENTONG -- 神州通用引擎类型
- EngineType.HWPOSTGRESQL -- 华为 PostgreSQL 引擎类型
- EngineType.GANOS -- 阿里 PolarDB 数据库引擎类型
- EngineType.XUGU -- 虚谷引擎类型
- EngineType.ATLASDB -- AtlasDB 引擎类型
-
ALTIBASE= 2004¶
-
ATLASDB= 2059¶
-
BAIDUMAPS= 227¶
-
BEYONDB= 2001¶
-
BINGMAPS= 230¶
-
DB2= 18¶
-
DM= 17¶
-
ES= 2011¶
-
GANOS= 2057¶
-
GAODEMAPS= 232¶
-
GBASE= 2002¶
-
GOOGLEMAPS= 223¶
-
HIGHGODB= 2003¶
-
HWPOSTGRESQL= 2056¶
-
IMAGEPLUGINS= 5¶
-
ISERVERREST= 225¶
-
KDB= 2005¶
-
KINGBASE= 19¶
-
MEMORY= 20¶
-
MONGODB= 401¶
-
MYSQL= 32¶
-
MYSQLPlus= 2007¶
-
OGC= 23¶
-
OPENSTREETMAPS= 228¶
-
ORACLEPLUS= 12¶
-
ORACLESPATIAL= 10¶
-
PGGIS= 2012¶
-
POSTGRESQL= 221¶
-
SCV= 229¶
-
SDE= 4¶
-
SHENTONG= 2055¶
-
SQLPLUS= 16¶
-
SQLSPATIAL= 2013¶
-
SRDB= 2006¶
-
SUPERMAPCLOUD= 224¶
-
TIBERO= 2014¶
-
UDB= 219¶
-
UDBX= 2054¶
-
VECTORFILE= 101¶
-
XUGU= 2058¶
- EngineType.IMAGEPLUGINS -- 影像只读引擎类型,对应的枚举值为 5。针对通用影像格式如 BMP,JPG,TIFF 以及超图自定义影像格式 SIT,二维地图缓存配置文件格式SCI等。用户在进行二维地图缓存加载的时候,需要设置为此引擎类型,另外还需要使用
-
class
iobjectspy.enums.DatasetType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了数据集类型常量。数据集一般为存储在一起的相关数据的集合;根据数据类型的不同,分为矢量数据集、栅格数据集和影像数据集,以及为了处理特定问题而设计的如拓扑数据集,网络 数据集等。根据要素的空间特征的不同,矢量数据集又分为点数据集,线数据集,面数据集,复合数据集,文本数据集,纯属性数据集等。
变量: - DatasetType.UNKNOWN -- 未知类型数据集
- DatasetType.TABULAR -- 纯属性数据集。用于存储和管理纯属性数据,纯属性数据用来描述地形地物特征、形状等信息,如河流的长度、宽度等。该数据 集没有空间图形数据。即纯属性数据集不能作为图层被添加到地图窗口中显示。
- DatasetType.POINT -- 点数据集。用于存储点对象的数据集类,例如离散点的分布。
- DatasetType.LINE -- 线数据集。用于存储线对象的数据集,例如河流、道路、国家边界线的分布。
- DatasetType.REGION -- 多边形数据集。用于存储面对象的数据集,例如表示房屋的分布、行政区域等。
- DatasetType.TEXT -- 文本数据集。用于存储文本对象的数据集,那么文本数据集中只能存储文本对象,而不能存储其他几何对象。例如表示注记的文本对象。
- DatasetType.CAD -- 复合数据集。指可以存储多种几何对象的数据集,即用来存储点、线、面、文本等不同类型的对象的集合。CAD 数据集中各对象可以 有不同的风格,CAD 数据集为每个对象存储风格。
- DatasetType.LINKTABLE -- 数据库表。即外挂属性表,不包含系统字段(以 SM 开头的字段)。与一般的属性数据集一样使用,但该数据集只具有只读功能。
- DatasetType.NETWORK -- 网络数据集。网络数据集是用于存储具有网络拓扑关系的数据集。如道路交通网络等。网络数据集和点数据集、线数据集不同, 它既包含了网络线对象,也包含了网络结点对象,还包含了两种对象之间的空间拓扑关系。基于网络数据集,可以进行路径分析、 服务区分析、最近设施查找、选址分区、公交换乘以及邻接点、通达点分析等多种网络分析。
- DatasetType.NETWORK3D -- 三维网络数据集,用于存储三维网络对象的数据集。
- DatasetType.LINEM -- 路由数据集。是由一系列空间信息中带有刻度值Measure的线对象构成。通常可应用于线性参考模型或者作为网络分析的结果数据。
- DatasetType.PARAMETRICLINE -- 复合参数化线数据集,用于存储复合参数化线几何对象的数据集。
- DatasetType.PARAMETRICREGION -- 复合参数化面数据集,用于存储复合参数化面几何对象的数据集。
- DatasetType.GRIDCOLLECTION -- 存储栅格数据集集合对象的数据集。对栅格数据集集合对象的详细描述请参考
DatasetGridCollection。 - DatasetType.IMAGECOLLECTION -- 存储影像数据集集合对象的数据集。对影像数据集集合对象的详细描述请参考
DatasetImageCollection。 - DatasetType.MODEL -- 模型数据集。
- DatasetType.TEXTURE -- 纹理数据集,模型数据集的子数据集。
- DatasetType.IMAGE -- 影像数据集。不具备属性信息,例如影像地图、多波段影像和实物地图等。其中每一个栅格存储的是一个颜色值或颜色的索引值(RGB 值)。
- DatasetType.WMS -- WMS 数据集,是 DatasetImage 的一种类型。WMS (Web Map Service),即 Web 地图服务。WMS 利用具有地理空间位置 信息的数据制作地图。Web 地图服务返回的是图层级的地图影像。其中将地图定义为地理数据可视的表现。
- DatasetType.WCS -- WCS 数据集,是 DatasetImage 的一种类型。 WCS( Web Coverage Service),即 Web 覆盖服务,面向空间影像数据, 它将包含地理位置值的地理空间数据作为“覆盖(Coverage)”在网上相互交换。
- DatasetType.GRID -- 栅格数据集。例如高程数据集和土地利用图。其中每一个栅格存储的是表示地物的属性值(例如高程值)。
- DatasetType.VOLUME -- 栅格体数据集合,以切片采样方式对三维体数据进行表达,例如指定空间范围的手机信号强度、雾霾污染指数等。
- DatasetType.TOPOLOGY -- 拓扑数据集。拓扑数据集实际上是一个对拓扑错误提供综合管理能力的容器。它覆盖了拓扑关联数据集、拓扑规则、拓扑预处理、 拓扑错误生成以及定位修改、脏区自动维护等拓扑错误检查的关键要素,为拓扑错误检查提供了一套完整的解决方案。脏区指的 是未进行拓扑检查的区域,就已经进行了拓扑检查的区域,若用户在局部对数据进行了部分编辑时,则在此局部区域又将生成新的脏区。
- DatasetType.POINT3D -- 三维点数据集,用于存储三维点对象的数据集。
- DatasetType.LINE3D -- 三维线数据集,用于存储三维线对象的数据集。
- DatasetType.REGION3D -- 三维面数据集,用于存储三维面对象的数据集。
- DatasetType.POINTEPS -- 清华山维点数据集,用于存储清华山维点对象的数据集。
- DatasetType.LINEEPS -- 清华山维线数据集,用于存储清华山维线对象的数据集。
- DatasetType.REGIONEPS -- 清华山维面数据集,用于存储清华山维面对象的数据集。
- DatasetType.TEXTEPS -- 清华山维文本数据集,用于存储清华山维文本对象的数据集。
- DatasetType.VECTORCOLLECTION -- 矢量数据集集合,用于存储多个矢量数据集,仅支持 PostgreSQL 引擎。
- DatasetType.MOSAIC -- 镶嵌数据集
-
CAD= 149¶
-
GRID= 83¶
-
GRIDCOLLECTION= 199¶
-
IMAGE= 81¶
-
IMAGECOLLECTION= 200¶
-
LINE= 3¶
-
LINE3D= 103¶
-
LINEEPS= 158¶
-
LINEM= 35¶
-
LINKTABLE= 153¶
-
MODEL= 203¶
-
MOSAIC= 206¶
-
NETWORK= 4¶
-
NETWORK3D= 205¶
-
PARAMETRICLINE= 8¶
-
PARAMETRICREGION= 9¶
-
POINT= 1¶
-
POINT3D= 101¶
-
POINTEPS= 157¶
-
REGION= 5¶
-
REGION3D= 105¶
-
REGIONEPS= 159¶
-
TABULAR= 0¶
-
TEXT= 7¶
-
TEXTEPS= 160¶
-
TEXTURE= 204¶
-
TOPOLOGY= 154¶
-
UNKNOWN= -1¶
-
VECTORCOLLECTION= 201¶
-
VOLUME= 89¶
-
WCS= 87¶
-
WMS= 86¶
-
class
iobjectspy.enums.FieldType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了字段类型常量。 定义一系列常量表示存储不同类型值的字段。
变量: - FieldType.BOOLEAN -- 布尔类型
- FieldType.BYTE -- 字节型字段
- FieldType.INT16 -- 16位整型字段
- FieldType.INT32 -- 32位整型字段
- FieldType.INT64 -- 64位整型字段
- FieldType.SINGLE -- 32位精度浮点型字段
- FieldType.DOUBLE -- 64位精度浮点型字段
- FieldType.DATETIME -- 日期型字段
- FieldType.LONGBINARY -- 二进制型字段
- FieldType.TEXT -- 变长的文本型字段
- FieldType.CHAR -- 长的文本类型字段,例如指定的字符串长度为10,那么输入的字符串只有3个字符,则其他都用0来占位
- FieldType.WTEXT -- 宽字符类型字段
- FieldType.JSONB -- JSONB 类型字段(PostgreSQL独有字段)
-
BOOLEAN= 1¶
-
BYTE= 2¶
-
CHAR= 18¶
-
DATETIME= 23¶
-
DOUBLE= 7¶
-
INT16= 3¶
-
INT32= 4¶
-
INT64= 16¶
-
JSONB= 129¶
-
LONGBINARY= 11¶
-
SINGLE= 6¶
-
TEXT= 10¶
-
WTEXT= 127¶
-
class
iobjectspy.enums.GeometryType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了一系列几何对象的类型常量。
-
GEOARC= 24¶
-
GEOBOX= 1205¶
-
GEOBSPLINE= 29¶
-
GEOCARDINAL= 27¶
-
GEOCHORD= 23¶
-
GEOCIRCLE= 15¶
-
GEOCIRCLE3D= 1210¶
-
GEOCOMPOUND= 1000¶
-
GEOCONE= 1207¶
-
GEOCONSTRUCTIVESOLID= 1234¶
-
GEOCURVE= 28¶
-
GEOCYLINDER= 1206¶
-
GEOELLIPSE= 20¶
-
GEOELLIPSOID= 1212¶
-
GEOELLIPTICARC= 25¶
-
GEOHEMISPHERE= 1204¶
-
GEOLEGEND= 2011¶
-
GEOLINE= 3¶
-
GEOLINE3D= 103¶
-
GEOLINEEPS= 4001¶
-
GEOLINEM= 35¶
-
GEOMAP= 2001¶
-
GEOMAPBORDER= 2009¶
-
GEOMAPSCALE= 2005¶
-
GEOMODEL= 1201¶
-
GEOMODEL3D= 1218¶
-
GEOMULTIPOINT= 2¶
-
GEONORTHARROW= 2008¶
-
GEOPARAMETRICLINE= 16¶
-
GEOPARAMETRICLINECOMPOUND= 8¶
-
GEOPARAMETRICREGION= 17¶
-
GEOPARAMETRICREGIONCOMPOUND= 9¶
-
GEOPARTICLE= 1213¶
-
GEOPICTURE= 1101¶
-
GEOPICTURE3D= 1202¶
-
GEOPIE= 21¶
-
GEOPIE3D= 1209¶
-
GEOPIECYLINDER= 1211¶
-
GEOPLACEMARK= 108¶
-
GEOPOINT= 1¶
-
GEOPOINT3D= 101¶
-
GEOPOINTEPS= 4000¶
-
GEOPYRAMID= 1208¶
-
GEORECTANGLE= 12¶
-
GEOREGION= 5¶
-
GEOREGION3D= 105¶
-
GEOREGIONEPS= 4002¶
-
GEOROUNDRECTANGLE= 13¶
-
GEOSPHERE= 1203¶
-
GEOTEXT= 7¶
-
GEOTEXT3D= 107¶
-
GEOTEXTEPS= 4003¶
-
GEOUSERDEFINED= 1001¶
-
GRAPHICOBJECT= 3000¶
-
-
class
iobjectspy.enums.WorkspaceType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了工作空间类型常量。
SuperMap 支持的文件型工作空间的类型有四种,SSXWU 格式和 SMWU 格式;SuperMap 支持的数据库型工作空间的类型有两种:Oracle 工作空间 和 SQL Server 工作空间。
变量: - WorkspaceType.DEFAULT -- 默认值, 表示工作空间未被保存时的工作空间类型。
- WorkspaceType.ORACLE -- Oracle 工作空间。工作空间保存在 Oracle 数据库中。
- WorkspaceType.SQL -- SQL Server 工作空间。工作空间保存在 SQL Server 数据库中。该常量仅在 Windows 平台版本中支持,在 Linux版本中不提供。
- WorkspaceType.DM -- DM 工作空间。工作空间保存在DM 数据库中。
- WorkspaceType.MYSQL -- MYSQL 工作空间。工作空间保存在MySQL 数据库中。
- WorkspaceType.PGSQL -- PostgreSQL 工作空间。工作空间保存在PostgreSQL 数据库中。
- WorkspaceType.MONGO -- MongoDB 工作空间。工作空间保存在 MongoDB 数据库中。
- WorkspaceType.SXWU -- SXWU工作空间,只有 6R 版本的工作空间能存成类型为 SXWU 的工作空间文件。另存为 6R 版本的工作空间时,文件型工作空间只能存为 SXWU 或是 SMWU。
- WorkspaceType.SMWU -- SMWU工作空间,只有 6R 版本的工作空间能存成类型为 SMWU 的工作空间文件。另存为 6R 版本的工作空间时,文件型工作空间只能存为 SXWU 或是 SMWU。该常量仅在 Windows 平台版本中支持,在 Linux版本中不提供。
-
DEFAULT= 1¶
-
DM= 12¶
-
MONGO= 15¶
-
MYSQL= 13¶
-
ORACLE= 6¶
-
PGSQL= 14¶
-
SMWU= 9¶
-
SQL= 7¶
-
SXWU= 8¶
-
class
iobjectspy.enums.WorkspaceVersion¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了工作空间版本类型常量。
变量: - WorkspaceVersion.UGC60 -- SuperMap UGC 6.0 工作空间
- WorkspaceVersion.UGC70 -- SuperMap UGC 7.0 工作空间
-
UGC60= 20090106¶
-
UGC70= 20120328¶
-
class
iobjectspy.enums.EncodeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了数据集存储时的压缩编码方式类型常量。
对矢量数据集,支持四种压缩编码方式,即单字节,双字节,三字节和四字节编码方式,这四种压缩编码方式采用相同的压缩编码机制,但是压缩的比率不同。 其均为有损压缩。需要注意的是点数据集、纯属性数据集以及 CAD 数据集不可压缩编码。对光栅数据,可以采用四种压缩编码方式,即 DCT、SGL、LZW 和 COMPOUND。其中 DCT 和 COMPOUND 为有损压缩编码方式,SGL 和 LZW 为无损压缩编码方式。
对于影像和栅格数据集,根据其像素格式(PixelFormat)选择合适的压缩编码方式,对提高系统运行的效率,节省存储空间非常有利。下表列出了影像和栅格数 据集不同像素格式对应的合理的编码方式:
变量: - EncodeType.NONE -- 不使用编码方式
- EncodeType.BYTE -- 单字节编码方式。使用1个字节存储一个坐标值。(只适用于线和面数据集)
- EncodeType.INT16 -- 双字节编码方式。使用2个字节存储一个坐标值。(只适用于线和面数据集)
- EncodeType.INT24 -- 三字节编码方式。使用3个字节存储一个坐标值。(只适用于线和面数据集)
- EncodeType.INT32 -- 四字节编码方式。使用4个字节存储一个坐标值。(只适用于线和面数据集)
- EncodeType.DCT -- DCT(Discrete Cosine Transform),离散余弦编码。是一种广泛应用于图像压缩中的变换编码方法,这种变换方法在信息的压 缩能力、重构图像质量、适应范围和算法复杂性等方面之间提供了一种很好的平衡,成为目前应用最广泛的图像压缩技术。其原理是通 过变换降低图像原始空间域表示中存在的非常强的相关性,使信号更紧凑地表达。该方法有很高的压缩率和性能,但编码是有失真的。 由于影像数据集一般不用来进行精确的分析,所以 DCT 编码方式是影像数据集存储的压缩编码方式。(适用于影像数据集)
- EncodeType.SGL -- SGL(SuperMap Grid LZW),SuperMap 自定义的一种压缩存储格式。其实质是改进的 LZW 编码方式。SGL 对 LZW 进行了改 进,是一种更高效的压缩存储方式。目前 SuperMap 中的对 Grid 数据集和 DEM 数据集压缩存储采用的就是 SGL 的压缩编码方 式,这是一种无损压缩。(适用于栅格数据集)
- EncodeType.LZW -- LZW 是一种广泛采用的字典压缩方法,其最早是用在文字数据的压缩方面。LZW的编码的原理是用代号来取代一段字符串,后续的相同 的字符串就使用相同代号,所以该编码方式不仅可以对重复数据起到压缩作用,还可以对不重复数据进行压缩操作。适用于索引色影像 的压缩方式,这是一种无损压缩编码方式。(适用于栅格和影像数据集)
- EncodeType.PNG -- PNG 压缩编码方式,支持多种位深的图像,是一种无损压缩方式。(适用于影像数据集)
- EncodeType.COMPOUND -- 数据集复合编码方式,其压缩比接近于 DCT 编码方式,主要针对 DCT 压缩导致的边界影像块失真的问题。(适用于 RGB 格式的影像数据集)
-
BYTE= 1¶
-
COMPOUND= 17¶
-
DCT= 8¶
-
INT16= 2¶
-
INT24= 3¶
-
INT32= 4¶
-
LZW= 11¶
-
NONE= 0¶
-
PNG= 12¶
-
SGL= 9¶
{kind=link}
-
class
iobjectspy.enums.CursorType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum游标类型:
变量: - CursorType.DYNAMIC -- 动态游标类型。支持各种编辑操作,速度慢。动态游标含义:可以看见其他用户所作的添加、更改和删除。允许在记录集中进行前后移动, (但不包括 数据提供者不支持的书签操作,书签操作主要针对于 ADO 而言)。此类型的游标功能很强大,但同时也是耗费系统资源最多的游标。动态游标可以知道记录 集(Recordset)的所有变化。使用动态游标的用户可以看到其他用户对数据集所做的编辑、增加、删除等操作。如果数据提供者允许这种类型的游标,那么它 是通过每隔一段时间从数据源重取数据来动态刷新查询的记录集的。毫无疑问这会需要很多的资源。
- CursorType.STATIC -- 静态游标类型。静态游标含义:可以用来查找数据或生成报告的记录集合的静态副本。另外,对其他用户所作的添加、更改或删除不可见。静态游标只 是数据的一幅快照。也就是说,它无法看到自从被创建以后其他用户对记录集(Recordset)所做的编辑操作。 采用这类游标你可以向前和向后回溯。由于其功能简单,资源的耗费比动态游标(DYNAMIC)要小!)
-
DYNAMIC= 2¶
-
STATIC= 3¶
-
class
iobjectspy.enums.Charset¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了矢量数据集的字符集类型常量。
变量: - Charset.ANSI -- ASCII 字符集
- Charset.DEFAULT -- 扩展的 ASCII 字符集。
- Charset.SYMBOL -- 符号字符集。
- Charset.MAC -- Macintosh 使用的字符
- Charset.SHIFTJIS -- 日语字符集
- Charset.HANGEUL -- 朝鲜字符集的其它常用拼写
- Charset.JOHAB -- 朝鲜字符集
- Charset.GB18030 -- 在中国大陆使用的中文字符集
- Charset.CHINESEBIG5 -- 在中国香港特别行政区和台湾最常用的中文字符集
- Charset.GREEK -- 希腊字符集
- Charset.TURKISH -- 土耳其语字符集
- Charset.VIETNAMESE -- 越南语字符集
- Charset.HEBREW -- 希伯来字符集
- Charset.ARABIC -- 阿拉伯字符集
- Charset.BALTIC -- 波罗的海字符集
- Charset.RUSSIAN -- 俄语字符集
- Charset.THAI -- 泰语字符集
- Charset.EASTEUROPE -- 东欧字符集
- Charset.OEM -- 扩展的 ASCII 字符集
- Charset.UTF8 -- UTF-8(8 位元 Universal Character Set/Unicode Transformation Format)是针对Unicode 的一种可变长度字符编码。它可以用来表示 Unicode 标准中的任何字符,而且其编码中的第一个字节仍与 ASCII 相容,使得原来处理 ASCII 字符的软件无需或只作少部份修改后,便可继续使用。
- Charset.UTF7 -- UTF-7 (7-位元 Unicode 转换格式(Unicode Transformation Format,简写成 UTF)) 是一种可变长度字符编码方式,用以将 Unicode 字符以 ASCII 编码的字符串来呈现。
- Charset.WINDOWS1252 -- 英文常用的编码。Windows1252(Window 9x标准for西欧语言)。
- Charset.KOREAN -- 韩语字符集
- Charset.UNICODE -- 在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准。
- Charset.CYRILLIC -- Cyrillic (Windows)
- Charset.XIA5 -- IA5
- Charset.XIA5GERMAN -- IA5 (German)
- Charset.XIA5SWEDISH -- IA5 (Swedish)
- Charset.XIA5NORWEGIAN -- IA5 (Norwegian)
-
ANSI= 0¶
-
ARABIC= 178¶
-
BALTIC= 186¶
-
CHINESEBIG5= 136¶
-
CYRILLIC= 135¶
-
DEFAULT= 1¶
-
EASTEUROPE= 238¶
-
GB18030= 134¶
-
GREEK= 161¶
-
HANGEUL= 129¶
-
HEBREW= 177¶
-
JOHAB= 130¶
-
KOREAN= 131¶
-
MAC= 77¶
-
OEM= 255¶
-
RUSSIAN= 204¶
-
SHIFTJIS= 128¶
-
SYMBOL= 2¶
-
THAI= 222¶
-
TURKISH= 162¶
-
UNICODE= 132¶
-
UTF7= 7¶
-
UTF8= 250¶
-
VIETNAMESE= 163¶
-
WINDOWS1252= 137¶
-
XIA5= 3¶
-
XIA5GERMAN= 4¶
-
XIA5NORWEGIAN= 6¶
-
XIA5SWEDISH= 5¶
-
class
iobjectspy.enums.OverlayMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum叠加分析模式类型
裁剪(CLIP)
用于对数据集进行擦除方式的叠加分析,将第一个数据集中包含在第二个数据集内的对象裁剪并删除。
- 裁剪数据集(第二数据集)的类型必须是面,被剪裁的数据集(第一数据集)可以是点、线、面。
- 在被裁剪数据集中,只有落在裁剪数据集多边形内的对象才会被输出到结果数据集中。
- 裁剪数据集、被裁剪数据集以及结果数据集的地理坐标系必须一致。
- clip 与 intersect 在空间处理上是一致的,不同在于对结果记录集属性的处理,clip 分析只是用来做裁剪,结果记录集与第一个记录集的属性表结构相同,此处叠加分析参数对象设置无效。而 intersect 求交分析的结果则可以根据字段设置情况来保留两个记录集的字段。
- 所有叠加分析的结果都不考虑数据集的系统字段。
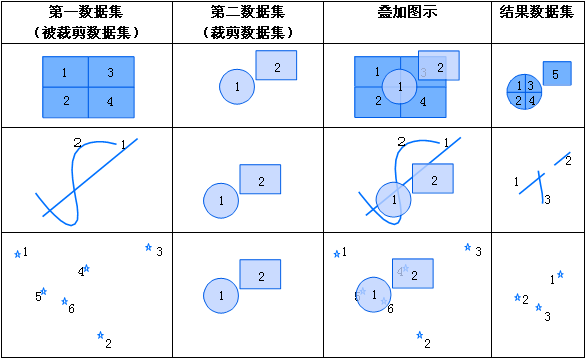
擦除(ERASE)
用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的数据集相交的对象。
- 擦除数据集(第二数据集)的类型必须是面,被擦除的数据集(第一数据集)可以是点、线、面数据集。
- 擦除数据集中的多边形集合定义了擦除区域,被擦除数据集中凡是落在这些多边形区域内的特征都将被去除,而落在多边形区域外的特征要素都将被输出到结果数据集中,与 clip 运算相反。
- 擦除数据集、被擦除数据集以及结果数据集的地理坐标系必须一致。
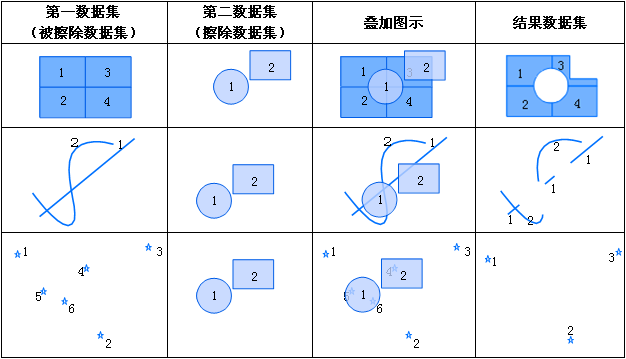
同一(IDENTITY)
用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的数据集相交的对象。
- 同一运算就是第一数据集与第二数据集先求交,然后求交结果再与第一数据集求并的一个运算。其中,第二数据集的类型必须是面,第一数据集的类型可以是点、线、面数据集。如果第一个数据集为点数集,则新生成的数据集中保留第一个数据集的所有对象;如果第一个数据集为线数据集,则新生成的数据集中保留第一个数据集的所有对象,但是把与第二个数据集相交的对象在相交的地方打断;如果第一个数据集为面数据集,则结果数据集保留以第一数据集为控制边界之内的所有多边形,并且把与第二个数据集相交的对象在相交的地方分割成多个对象。
- identiy 运算与 union 运算有相似之处,所不同之处在于 union 运算保留了两个数据集的所有部分,而 identity 运算是把第一个数据集中与第二个数据集不相交的部分进行保留。identity 运算的结果属性表来自于两个数据集的属性表。
- 用于进行同一运算的数据集、被同一运算的数据集以及结果数据集的地理坐标系必须一致。
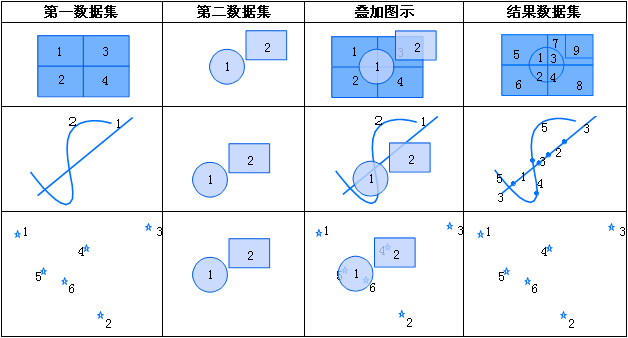
相交(INTERSECT)
进行相交方式的叠加分析,将被相交叠加分析的数据集中不包含在用来相交叠加分析的数据集中的对象切割并删除。即两个数据集中重叠的部分将被输出到结果数据集中,其余部分将被排除。
- 被相交叠加分析的数据集可以是点类型、线类型和面类型,用来相交叠加分析的数据集必须是面类型。第一数据集的特征对象(点、线和面)在与第二数据集中的多边形相交处被分裂(点对象除外),分裂结果被输出到结果数据集中。
- 求交运算与裁剪运算得到的结果数据集的空间几何信息相同的,但是裁剪运算不对属性表做任何处理,而求交运算可以让用户选择需要保留的属性字段。
- 用于相交叠加分析的数据集、被相交叠加分析的数据集以及结果数据集的地理坐标系必须一致。
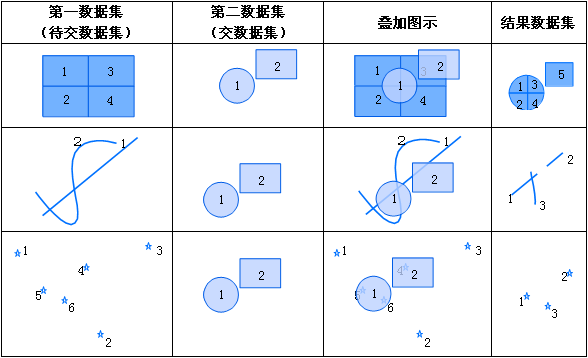
对称差(XOR)
对两个面数据集进行对称差分析运算。即交集取反运算。
- 用于对称差分析的数据集、被对称差分析的数据集以及结果数据集的地理坐标系必须一致。
- 对称差运算是两个数据集的异或运算。操作的结果是,对于每一个面对象,去掉其与另一个数据集中的几何对象相交的部分,而保留剩下的部分。对称差运算的输出结果的属性表包含两个输入数据集的非系统属性字段。

合并(UNION)
用于对两个面数据集进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的数据集和用于合并叠加分析的数据集中的全部对象,并且对相交部分进行求交和分割运算。 注意:
- 合并是求两个数据集并的运算,合并后的图层保留两个数据集所有图层要素,只限于两个面数据集之间进行。
- 进行 union 运算后,两个面数据集在相交处多边形被分割,且两个数据集的几何和属性信息都被输出到结果数据集中。
- 用于合并叠加分析的数据集、被合并叠加分析的数据集以及结果数据集的地理坐标系必须一致。

更新(UPDATE)
用于对两个面数据集进行更新方式的叠加分析, 更新运算是用用于更新的数据集替换与被更新数据集的重合部分,是一个先擦除后粘贴的过程。
- 用于更新叠加分析的数据集、被更新叠加分析的数据集以及结果数据集的地理坐标系必须一致。
- 第一数据集与第二数据集的类型都必须是面数据集。结果数据集中保留了更新数据集的几何形状和属性信息。
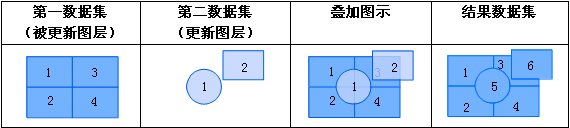
变量: - OverlayMode.CLIP -- 裁剪
- OverlayMode.ERASE -- 擦除
- OverlayMode.IDENTITY -- 同一
- OverlayMode.INTERSECT -- 相交
- OverlayMode.XOR -- 对称差
- OverlayMode.UNION -- 合并
- OverlayMode.UPDATE -- 更新
-
CLIP= 1¶
-
ERASE= 2¶
-
IDENTITY= 3¶
-
INTERSECT= 4¶
-
UNION= 6¶
-
UPDATE= 7¶
-
XOR= 5¶
-
class
iobjectspy.enums.SpatialIndexType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了空间索引类型常量。
空间索引用于提高数据空间查询效率的数据结构。在 SuperMap 中提供了 R 树索引,四叉树索引,图幅索引和多级网格索引。以上几种索引仅适用于矢量数据集。
同时,一个数据集在一种时刻只能使用一种索引,但是索引可以切换,即当对数据集创建完一种索引之后,必须删除旧的索引才能创建新的。数据集处于编辑状态时, 系统自动维护当前的索引。特别地,当数据被多次编辑后,索引的效率将会受到不同程度的影响,通过系统的判断得知是否要求重新建立空间索引:
- 当前版本 UDB 和 PostgreSQL 数据源只支持 R 树索引(RTree),DB2 数据源只支持多级网格索引(Multi_Level_Grid);
- 数据库中的点数据集均不支持四叉树(QTree)索引和 R 树索引(RTree);
- 网络数据集不支持任何类型的空间索引;
- 复合数据集不支持多级网格索引;
- 路由数据集不支持图幅索引(TILE);
- 属性数据集不支持任何类型的空间索引;
- 对于数据库类型的数据源,数据库记录要大于1000条时才可以创建索引。
变量: - SpatialIndexType.NONE -- 无空间索引就是没有空间索引,适用于数据量非常小的情况
- SpatialIndexType.RTREE --
R 树索引是基于磁盘的索引结构,是 B 树(一维)在高维空间的自然扩展,易于与现有数据库系统集成,能够支持各种类型 的空间查询处理操作,在实践中得到了广泛的应用,是目前最流行的空间索引方法之一。R 树空间索引方法是设计一些包含 空间对象的矩形,将一些空间位置相近的目标对象,包含在这个矩形内,把这些矩形作为空间索引,它含有所包含的空间对 象的指针。 注意:
- 此索引适合于静态数据(对数据进行浏览、查询操作时)。
- 此索引支持数据的并发操作。
- SpatialIndexType.QTREE -- 四叉树是一种重要的层次化数据集结构,主要用来表达二维坐标下空间层次关系,实际上它是一维二叉树在二维空间的扩展。 那么,四叉树索引就是将一张地图四等分,然后再每一个格子中再四等分,逐层细分,直至不能再分。现在在 SuperMap 中四叉树最多允许分成13层。基于希尔伯特(Hilbert)编码的排序规则,从四叉树中可确定索引类中每个对象实例的被索 引属性值是属于哪个最小范围。从而提高了检索效率
- SpatialIndexType.TILE -- 图幅索引。在 SuperMap 中根据数据集的某一属性字段或根据给定的一个范围,将空间对象进行分类,通过索引进行管理已 分类的空间对象,以此提高查询检索速度
- SpatialIndexType.MULTI_LEVEL_GRID --
多级网格索引,又叫动态索引。多级网格索引结合了 R 树索引与四叉树索引的优点,提供非常好的并发编辑 支持,具有很好的普适性。若不能确定数据适用于哪种空间索引,可为其建立多级网格索引。采用划分多层网 格的方式来组织管理数据。网格索引的基本方法是将数据集按照一定的规则划分成相等或不相等的网格,记录 每一个地理对象所占的网格位置。在 GIS 中常用的是规则网格。当用户进行空间查询时,首先计算出用户查 询对象所在的网格,通过该网格快速查询所选地理对象,可以优化查询操作。
当前版本中,定义网格的索引为一级,二级和三级,每一级都有各自的划分规则,第一级的网格最小,第二级 和第三级的网格要相应得比前面的大。在建立多级网格索引时,根据具体数据及其分布的情况,网格的大小和 网格索引的级数由系统自动给出,不需要用户进行设置。
- SpatialIndexType.PRIMARY --
原生索引,创建的是空间索引。在PostgreSQL空间数据扩展PostGIS中是GIST索引,意思是通用的搜索树。在SQLServer空间数据扩展SQLSpatial中是多级格网索引:
- PostGIS的GIST索引是一种平衡的,树状结构的访问方法,主要使用了B-tree、R-tree、RD-tree索引算法。优点:适用于多维数据类型和集合数据类型,同样适用于其他的数据类型,GIST多字段索引在查询条件中包含索引字段的任何子集都会使用索引扫描。缺点:GIST索引创建耗时较长,占用空间也比较大。
- SQLSpatial的多级格网索引最多可以设置四级,每一级按照等分格网的方式依次进行。在创建索引时,可以选择高、中、低三种格网密度,分别对应(4*4)、(8*8)和(16*16),目前默认中格网密度。
-
MULTI_LEVEL_GRID= 5¶
-
NONE= 1¶
-
PRIMARY= 7¶
-
QTREE= 3¶
-
RTREE= 2¶
-
TILE= 4¶
-
class
iobjectspy.enums.DissolveType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum融合类型常量
变量: - DissolveType.ONLYMULTIPART -- 组合。将融合字段值相同的对象合并成一个复杂对象。
- DissolveType.SINGLE -- 融合。将融合字段值相同且拓扑邻近的对象合并成一个简单对象。
- DissolveType.MULTIPART -- 融合后组合。将融合字段值相同且拓扑邻近的对象合并成一个简单对象,然后将融合字段值相同的非邻近对象组合成一个复杂对象。
-
MULTIPART= 3¶
-
ONLYMULTIPART= 1¶
-
SINGLE= 2¶
-
class
iobjectspy.enums.TextAlignment¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了文本对齐类型常量。
指定文本中的各子对象的对齐方式。文本对象的每个子对象的位置是由文本的锚点和文本的对齐方式共同确定的。当文本子对象的锚点固定,对齐方式确定文本子对象与锚点的相对位置,从而确定文本子对象的位置。
变量: - TextAlignment.TOPLEFT -- 左上角对齐。当文本的对齐方式为左上角对齐时,文本子对象的最小外接矩形的左上角点在该文本子对象的锚点位置
- TextAlignment.TOPCENTER -- 顶部居中对齐。当文本的对齐方式为上面居中对齐时,文本子对象的最小外接矩形的上边线的中点在该文本子对象的锚点位置
- TextAlignment.TOPRIGHT -- 右上角对齐。当文本的对齐方式为右上角对齐时,文本子对象的最小外接矩形的右上角点在该文本子对象的锚点位置
- TextAlignment.BASELINELEFT -- 基准线左对齐。当文本的对齐方式为基准线左对齐时,文本子对象的基线的左端点在该文本子对象的锚点位置
- TextAlignment.BASELINECENTER -- 基准线居中对齐。当文本的对齐方式为基准线居中对齐时,文本子对象的基线的中点在该文本子对象的锚点位置
- TextAlignment.BASELINERIGHT -- 基准线右对齐。当文本的对齐方式为基准线右对齐时,文本子对象的基线的右端点在该文本子对象的锚点位置
- TextAlignment.BOTTOMLEFT -- 左下角对齐。当文本的对齐方式为左下角对齐时,文本子对象的最小外接矩形的左下角点在该文本子对象的锚点位置
- TextAlignment.BOTTOMCENTER -- 底部居中对齐。当文本的对齐方式为底线居中对齐时,文本子对象的最小外接矩形的底线的中点在该文本子对象的锚点位置
- TextAlignment.BOTTOMRIGHT -- 右下角对齐。当文本的对齐方式为右下角对齐时,文本子对象的最小外接矩形的右下角点在该文本子对象的锚点位置
- TextAlignment.MIDDLELEFT -- 左中对齐。当文本的对齐方式为左中对齐时,文本子对象的最小外接矩形的左边线的中点在该文本子对象的锚点位置
- TextAlignment.MIDDLECENTER -- 中心对齐。当文本的对齐方式为中心对齐时,文本子对象的最小外接矩形的中心点在该文本子对象的锚点位置
- TextAlignment.MIDDLERIGHT -- 右中对齐。当文本的对齐方式为右中对齐时,文本子对象的最小外接矩形的右边线的中点在该文本子对象的锚点位置
-
BASELINECENTER= 4¶
-
BASELINELEFT= 3¶
-
BASELINERIGHT= 5¶
-
BOTTOMCENTER= 7¶
-
BOTTOMLEFT= 6¶
-
BOTTOMRIGHT= 8¶
-
MIDDLECENTER= 10¶
-
MIDDLELEFT= 9¶
-
MIDDLERIGHT= 11¶
-
TOPCENTER= 1¶
-
TOPLEFT= 0¶
-
TOPRIGHT= 2¶
-
class
iobjectspy.enums.StringAlignment¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了多行文本排版方式类型常量
变量: - StringAlignment.LEFT -- 左对齐
- StringAlignment.CENTER -- 居中对齐
- StringAlignment.RIGHT -- 右对齐
- StringAlignment.DISTRIBUTED -- 分散对齐(两端对齐)
-
CENTER= 16¶
-
DISTRIBUTED= 144¶
-
LEFT= 0¶
-
RIGHT= 32¶
-
class
iobjectspy.enums.ColorGradientType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了颜色渐变类型常量。
颜色渐变是多种颜色间的逐渐混合,可以是从起始色到终止色两种颜色的渐变,或者在起始色到终止色之间具有多种中间颜色进行渐变。该颜色渐变类型可应用于专题图对象的颜色方案设置中如:单值专题图、 分段专题图、 统计专题图、标签专题图、栅格分段专题图和栅格单值专题图。
-
BLACKWHITE= 0¶
-
BLUEBLACK= 9¶
-
BLUERED= 18¶
-
BLUEWHITE= 3¶
-
CYANBLACK= 12¶
-
CYANBLUE= 21¶
-
CYANGREEN= 22¶
-
CYANWHITE= 6¶
-
GREENBLACK= 8¶
-
GREENBLUE= 16¶
-
GREENORANGEVIOLET= 24¶
-
GREENRED= 17¶
-
GREENWHITE= 2¶
-
PINKBLACK= 11¶
-
PINKBLUE= 20¶
-
PINKRED= 19¶
-
PINKWHITE= 5¶
-
RAINBOW= 23¶
-
REDBLACK= 7¶
-
REDWHITE= 1¶
-
SPECTRUM= 26¶
-
TERRAIN= 25¶
-
YELLOWBLACK= 10¶
-
YELLOWBLUE= 15¶
-
YELLOWGREEN= 14¶
-
YELLOWRED= 13¶
-
YELLOWWHITE= 4¶
-
-
class
iobjectspy.enums.Buffer3DJoinType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum放样的倒角样式类型常量 :var Buffer3DJoinType.SQUARE:尖角衔接样式 :var Buffer3DJoinType.ROUND:圆角衔接样式 :var Buffer3DJoinType.MITER:斜角衔接样式
-
MITER= 2¶
-
ROUND= 1¶
-
SQUARE= 0¶
-
-
class
iobjectspy.enums.SpatialQueryMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了空间查询操作模式类型常量。 空间查询是通过几何对象之间的空间位置关系来构建过滤条件的一种查询方式。例如:通过空间查询可以找到被包含在面中的空间对象,相离或者相邻的空间对象等。
变量: - SpatialQueryMode.NONE -- 无空间查询
- SpatialQueryMode.IDENTITY --
重合空间查询模式。返回被搜索图层中与搜索对象完全重合的对象。注意:搜索对象与被搜索对象的类型必须相同;且两个对象的交集不为空,搜索对象的边界及内部分别和被搜索对象的外部交集为空。 该关系适合的对象类型:
- 搜索对象:点、线、面;
- 被搜索对象:点、线、面。
如图:
- SpatialQueryMode.DISJOINT --
分离空间查询模式。返回被搜索图层中与搜索对象相离的对象。注意:搜索对象和被搜索对象相离,即无任何交集。 该关系适合的对象类型:
- 搜索对象:点、线、面;
- 被搜索对象:点、线、面。
如图:
- SpatialQueryMode.INTERSECT --
相交空间查询模式。返回与搜索对象相交的所有对象。注意:如果搜索对象是面,返回全部或部分被搜索对象包含的对象以及全部或部分包含搜索对象的对象;如果搜索对象不是面,返回全部或部分包含搜索对象的对象。 该关系适合的对象类型:
- 搜索对象:点、线、面;
- 被搜索对象:点、线、面。
如图:
- SpatialQueryMode.TOUCH --
邻接空间查询模式。返回被搜索图层中其边界与搜索对象边界相触的对象。注意:搜索对象和被搜索对象的内部交集为空。 该关系不适合的对象类型为:
- 点查询点的空间关系。
如图:
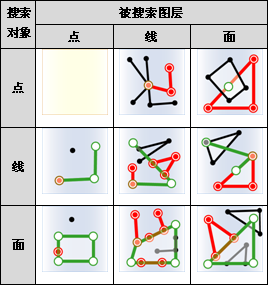
- SpatialQueryMode.OVERLAP --
叠加空间查询模式。返回被搜索图层中与搜索对象部分重叠的对象。 该关系适合的对象类型为:
- 线/线,面/面。其中,两个几何对象的维数必须一致,而且他们交集的维数也应该和几何对象的维数一样
注意:点与任何一种几何对象都不存在部分重叠的情况
如图:
- SpatialQueryMode.CROSS --
交叉空间查询模式。返回被搜索图层中与搜索对象(线)相交的所有对象(线或面)。注意:搜索对象和被搜索对象内部的交集不能为空;参与交叉(Cross)关系运算的两个对象必须有一个是线对象。 该关系适合的对象类型:
- 搜索对象:线;
- 被搜索对象:线、面。
如图:
- SpatialQueryMode.WITHIN --
被包含空间查询模式。返回被搜索图层中完全包含搜索对象的对象。如果返回的对象是面,其必须全部包含(包括边接触)搜索对象;如果返回的对象是线,其必须完全包含搜索对象;如果返回的对象是点,其必须与搜索对象重合。该类型与包含(Contain)的查询模式正好相反。 该关系适合的对象类型:
- 搜索对象: 点、线、面;
- 被搜索对象: 点、线、面。
如图:
- SpatialQueryMode.CONTAIN --
包含空间查询模式。返回被搜索图层中完全被搜索对象包含的对象。注:搜索对象和被搜索对象的边界交集可以不为空;点查线/点查面/线查面,不存在包含情况。 该关系适合的对象类型:
- 搜索对象:点、线、面;
- 被搜索对象:点、线、面。
如图:
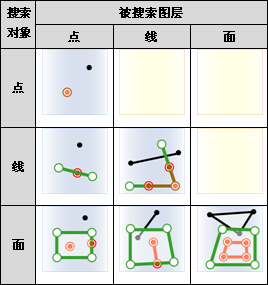
- SpatialQueryMode.INNERINTERSECT -- 内部相交查询模式,返回与搜索对象相交但不是仅接触的所有对象。也就是在相交算子的结果之上排除所有接触算子的结果。
-
CONTAIN= 7¶
-
CROSS= 5¶
-
DISJOINT= 1¶
-
IDENTITY= 0¶
-
INNERINTERSECT= 13¶
-
INTERSECT= 2¶
-
NONE= -1¶
-
OVERLAP= 4¶
-
TOUCH= 3¶
-
WITHIN= 6¶
-
class
iobjectspy.enums.StatisticsType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum字段统计类型常量
变量: - StatisticsType.MAX -- 统计字段的最大值
- StatisticsType.MIN -- 统计字段的最小值
- StatisticsType.SUM -- 统计字段的和
- StatisticsType.MEAN -- 统计字段的平均值
- StatisticsType.FIRST -- 保留第一个对象的字段值
- StatisticsType.LAST -- 保留最后一个对象的字段值。
-
FIRST= 5¶
-
LAST= 6¶
-
MAX= 1¶
-
MEAN= 4¶
-
MIN= 2¶
-
SUM= 3¶
-
class
iobjectspy.enums.JoinType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了定义两个表之间连接类型常量。
该类用于对相连接的两个表之间进行查询时,决定了查询结果中得到的记录的情况
变量: - JoinType.INNERJOIN -- 完全内连接,只有两个表中都有相关的记录才加入查询结果集。
- JoinType.LEFTJOIN -- 左连接,左边表中所有相关记录进入查询结果集,右边表中无相关的记录则其对应的字段值显示为空。
-
INNERJOIN= 0¶
-
LEFTJOIN= 1¶
-
class
iobjectspy.enums.BufferEndType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了缓冲区端点类型常量。
用以区分线对象缓冲区分析时的端点是圆头缓冲还是平头缓冲。
变量: - BufferEndType.ROUND -- 圆头缓冲。圆头缓冲区是在生成缓冲区时,在线段的端点处做半圆弧处理
- BufferEndType.FLAT -- 平头缓冲。平头缓冲区是在生成缓冲区时,在线段的端点处做圆弧的垂线。
-
FLAT= 2¶
-
ROUND= 1¶
-
class
iobjectspy.enums.BufferRadiusUnit¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该枚举定义了缓冲区分析半径单位类型常量
变量: - BufferRadiusUnit.MILIMETER -- 毫米
- BufferRadiusUnit.CENTIMETER -- 厘米
- BufferRadiusUnit.DECIMETER -- 分米
- BufferRadiusUnit.METER -- 米
- BufferRadiusUnit.KILOMETER -- 千米
- BufferRadiusUnit.INCH -- 英寸
- BufferRadiusUnit.FOOT -- 英尺
- BufferRadiusUnit.YARD -- 码
- BufferRadiusUnit.MILE -- 英里
-
CENTIMETER= 100¶
-
DECIMETER= 1000¶
-
FOOT= 3048¶
-
INCH= 254¶
-
KILOMETER= 10000000¶
-
METER= 10000¶
-
MILE= 16090000¶
-
MILIMETER= 10¶
-
YARD= 9144¶
-
class
iobjectspy.enums.StatisticMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了字段统计方法类型常量。对单一字段提供常用统计功能。SuperMap 提供的统计功能有6种,统计字段的最大值,最小值,平均值,总和,标准差以及方差。
变量: - StatisticMode.MAX -- 统计所选字段的最大值。
- StatisticMode.MIN -- 统计所选字段的最小值。
- StatisticMode.AVERAGE -- 统计所选字段的平均值。
- StatisticMode.SUM -- 统计所选字段的总和。
- StatisticMode.STDDEVIATION -- 统计所选字段的标准差。
- StatisticMode.VARIANCE -- 统计所选字段的方差。
-
AVERAGE= 3¶
-
MAX= 1¶
-
MIN= 2¶
-
STDDEVIATION= 5¶
-
SUM= 4¶
-
VARIANCE= 6¶
-
class
iobjectspy.enums.PrjCoordSysType¶ 基类:
iobjectspy._jsuperpy.enums.JEnumAn enumeration.
-
PCS_ADINDAN_UTM_37N= 20137¶
-
PCS_ADINDAN_UTM_38N= 20138¶
-
PCS_AFGOOYE_UTM_38N= 20538¶
-
PCS_AFGOOYE_UTM_39N= 20539¶
-
PCS_AGD_1966_AMG_48= 20248¶
-
PCS_AGD_1966_AMG_49= 20249¶
-
PCS_AGD_1966_AMG_50= 20250¶
-
PCS_AGD_1966_AMG_51= 20251¶
-
PCS_AGD_1966_AMG_52= 20252¶
-
PCS_AGD_1966_AMG_53= 20253¶
-
PCS_AGD_1966_AMG_54= 20254¶
-
PCS_AGD_1966_AMG_55= 20255¶
-
PCS_AGD_1966_AMG_56= 20256¶
-
PCS_AGD_1966_AMG_57= 20257¶
-
PCS_AGD_1966_AMG_58= 20258¶
-
PCS_AGD_1984_AMG_48= 20348¶
-
PCS_AGD_1984_AMG_49= 20349¶
-
PCS_AGD_1984_AMG_50= 20350¶
-
PCS_AGD_1984_AMG_51= 20351¶
-
PCS_AGD_1984_AMG_52= 20352¶
-
PCS_AGD_1984_AMG_53= 20353¶
-
PCS_AGD_1984_AMG_54= 20354¶
-
PCS_AGD_1984_AMG_55= 20355¶
-
PCS_AGD_1984_AMG_56= 20356¶
-
PCS_AGD_1984_AMG_57= 20357¶
-
PCS_AGD_1984_AMG_58= 20358¶
-
PCS_AIN_EL_ABD_BAHRAIN_GRID= 20499¶
-
PCS_AIN_EL_ABD_UTM_37N= 20437¶
-
PCS_AIN_EL_ABD_UTM_38N= 20438¶
-
PCS_AIN_EL_ABD_UTM_39N= 20439¶
-
PCS_AMERSFOORT_RD_NEW= 28992¶
-
PCS_ARATU_UTM_22S= 20822¶
-
PCS_ARATU_UTM_23S= 20823¶
-
PCS_ARATU_UTM_24S= 20824¶
-
PCS_ATF_NORD_DE_GUERRE= 27500¶
-
PCS_ATS_1977_UTM_19N= 2219¶
-
PCS_ATS_1977_UTM_20N= 2220¶
-
PCS_AZORES_CENTRAL_1948_UTM_ZONE_26N= 2189¶
-
PCS_AZORES_OCCIDENTAL_1939_UTM_ZONE_25N= 2188¶
-
PCS_AZORES_ORIENTAL_1940_UTM_ZONE_26N= 2190¶
-
PCS_BATAVIA_UTM_48S= 21148¶
-
PCS_BATAVIA_UTM_49S= 21149¶
-
PCS_BATAVIA_UTM_50S= 21150¶
-
PCS_BEIJING_1954_3_DEGREE_GK_25= 2401¶
-
PCS_BEIJING_1954_3_DEGREE_GK_25N= 2422¶
-
PCS_BEIJING_1954_3_DEGREE_GK_26= 2402¶
-
PCS_BEIJING_1954_3_DEGREE_GK_26N= 2423¶
-
PCS_BEIJING_1954_3_DEGREE_GK_27= 2403¶
-
PCS_BEIJING_1954_3_DEGREE_GK_27N= 2424¶
-
PCS_BEIJING_1954_3_DEGREE_GK_28= 2404¶
-
PCS_BEIJING_1954_3_DEGREE_GK_28N= 2425¶
-
PCS_BEIJING_1954_3_DEGREE_GK_29= 2405¶
-
PCS_BEIJING_1954_3_DEGREE_GK_29N= 2426¶
-
PCS_BEIJING_1954_3_DEGREE_GK_30= 2406¶
-
PCS_BEIJING_1954_3_DEGREE_GK_30N= 2427¶
-
PCS_BEIJING_1954_3_DEGREE_GK_31= 2407¶
-
PCS_BEIJING_1954_3_DEGREE_GK_31N= 2428¶
-
PCS_BEIJING_1954_3_DEGREE_GK_32= 2408¶
-
PCS_BEIJING_1954_3_DEGREE_GK_32N= 2429¶
-
PCS_BEIJING_1954_3_DEGREE_GK_33= 2409¶
-
PCS_BEIJING_1954_3_DEGREE_GK_33N= 2430¶
-
PCS_BEIJING_1954_3_DEGREE_GK_34= 2410¶
-
PCS_BEIJING_1954_3_DEGREE_GK_34N= 2431¶
-
PCS_BEIJING_1954_3_DEGREE_GK_35= 2411¶
-
PCS_BEIJING_1954_3_DEGREE_GK_35N= 2432¶
-
PCS_BEIJING_1954_3_DEGREE_GK_36= 2412¶
-
PCS_BEIJING_1954_3_DEGREE_GK_36N= 2433¶
-
PCS_BEIJING_1954_3_DEGREE_GK_37= 2413¶
-
PCS_BEIJING_1954_3_DEGREE_GK_37N= 2434¶
-
PCS_BEIJING_1954_3_DEGREE_GK_38= 2414¶
-
PCS_BEIJING_1954_3_DEGREE_GK_38N= 2435¶
-
PCS_BEIJING_1954_3_DEGREE_GK_39= 2415¶
-
PCS_BEIJING_1954_3_DEGREE_GK_39N= 2436¶
-
PCS_BEIJING_1954_3_DEGREE_GK_40= 2416¶
-
PCS_BEIJING_1954_3_DEGREE_GK_40N= 2437¶
-
PCS_BEIJING_1954_3_DEGREE_GK_41= 2417¶
-
PCS_BEIJING_1954_3_DEGREE_GK_41N= 2438¶
-
PCS_BEIJING_1954_3_DEGREE_GK_42= 2418¶
-
PCS_BEIJING_1954_3_DEGREE_GK_42N= 2439¶
-
PCS_BEIJING_1954_3_DEGREE_GK_43= 2419¶
-
PCS_BEIJING_1954_3_DEGREE_GK_43N= 2440¶
-
PCS_BEIJING_1954_3_DEGREE_GK_44= 2420¶
-
PCS_BEIJING_1954_3_DEGREE_GK_44N= 2441¶
-
PCS_BEIJING_1954_3_DEGREE_GK_45= 2421¶
-
PCS_BEIJING_1954_3_DEGREE_GK_45N= 2442¶
-
PCS_BEIJING_1954_GK_13= 21413¶
-
PCS_BEIJING_1954_GK_13N= 21473¶
-
PCS_BEIJING_1954_GK_14= 21414¶
-
PCS_BEIJING_1954_GK_14N= 21474¶
-
PCS_BEIJING_1954_GK_15= 21415¶
-
PCS_BEIJING_1954_GK_15N= 21475¶
-
PCS_BEIJING_1954_GK_16= 21416¶
-
PCS_BEIJING_1954_GK_16N= 21476¶
-
PCS_BEIJING_1954_GK_17= 21417¶
-
PCS_BEIJING_1954_GK_17N= 21477¶
-
PCS_BEIJING_1954_GK_18= 21418¶
-
PCS_BEIJING_1954_GK_18N= 21478¶
-
PCS_BEIJING_1954_GK_19= 21419¶
-
PCS_BEIJING_1954_GK_19N= 21479¶
-
PCS_BEIJING_1954_GK_20= 21420¶
-
PCS_BEIJING_1954_GK_20N= 21480¶
-
PCS_BEIJING_1954_GK_21= 21421¶
-
PCS_BEIJING_1954_GK_21N= 21481¶
-
PCS_BEIJING_1954_GK_22= 21422¶
-
PCS_BEIJING_1954_GK_22N= 21482¶
-
PCS_BEIJING_1954_GK_23= 21423¶
-
PCS_BEIJING_1954_GK_23N= 21483¶
-
PCS_BELGE_LAMBERT_1950= 21500¶
-
PCS_BOGOTA_COLOMBIA_BOGOTA= 21892¶
-
PCS_BOGOTA_COLOMBIA_EAST= 21894¶
-
PCS_BOGOTA_COLOMBIA_E_CENTRAL= 21893¶
-
PCS_BOGOTA_COLOMBIA_WEST= 21891¶
-
PCS_BOGOTA_UTM_17N= 21817¶
-
PCS_BOGOTA_UTM_18N= 21818¶
-
PCS_CAMACUPA_UTM_32S= 22032¶
-
PCS_CAMACUPA_UTM_33S= 22033¶
-
PCS_CARTHAGE_NORD_TUNISIE= 22391¶
-
PCS_CARTHAGE_SUD_TUNISIE= 22392¶
-
PCS_CARTHAGE_UTM_32N= 22332¶
-
PCS_CHINA_2000_3_DEGREE_GK_25= 21625¶
-
PCS_CHINA_2000_3_DEGREE_GK_25N= 21675¶
-
PCS_CHINA_2000_3_DEGREE_GK_26= 21626¶
-
PCS_CHINA_2000_3_DEGREE_GK_26N= 21676¶
-
PCS_CHINA_2000_3_DEGREE_GK_27= 21627¶
-
PCS_CHINA_2000_3_DEGREE_GK_27N= 21677¶
-
PCS_CHINA_2000_3_DEGREE_GK_28= 21628¶
-
PCS_CHINA_2000_3_DEGREE_GK_28N= 21678¶
-
PCS_CHINA_2000_3_DEGREE_GK_29= 21629¶
-
PCS_CHINA_2000_3_DEGREE_GK_29N= 21679¶
-
PCS_CHINA_2000_3_DEGREE_GK_30= 21630¶
-
PCS_CHINA_2000_3_DEGREE_GK_30N= 21680¶
-
PCS_CHINA_2000_3_DEGREE_GK_31= 21631¶
-
PCS_CHINA_2000_3_DEGREE_GK_31N= 21681¶
-
PCS_CHINA_2000_3_DEGREE_GK_32= 21632¶
-
PCS_CHINA_2000_3_DEGREE_GK_32N= 21682¶
-
PCS_CHINA_2000_3_DEGREE_GK_33= 21633¶
-
PCS_CHINA_2000_3_DEGREE_GK_33N= 21683¶
-
PCS_CHINA_2000_3_DEGREE_GK_34= 21634¶
-
PCS_CHINA_2000_3_DEGREE_GK_34N= 21684¶
-
PCS_CHINA_2000_3_DEGREE_GK_35= 21635¶
-
PCS_CHINA_2000_3_DEGREE_GK_35N= 21685¶
-
PCS_CHINA_2000_3_DEGREE_GK_36= 21636¶
-
PCS_CHINA_2000_3_DEGREE_GK_36N= 21686¶
-
PCS_CHINA_2000_3_DEGREE_GK_37= 21637¶
-
PCS_CHINA_2000_3_DEGREE_GK_37N= 21687¶
-
PCS_CHINA_2000_3_DEGREE_GK_38= 21638¶
-
PCS_CHINA_2000_3_DEGREE_GK_38N= 21688¶
-
PCS_CHINA_2000_3_DEGREE_GK_39= 21639¶
-
PCS_CHINA_2000_3_DEGREE_GK_39N= 21689¶
-
PCS_CHINA_2000_3_DEGREE_GK_40= 21640¶
-
PCS_CHINA_2000_3_DEGREE_GK_40N= 21690¶
-
PCS_CHINA_2000_3_DEGREE_GK_41= 21641¶
-
PCS_CHINA_2000_3_DEGREE_GK_41N= 21691¶
-
PCS_CHINA_2000_3_DEGREE_GK_42= 21642¶
-
PCS_CHINA_2000_3_DEGREE_GK_42N= 21692¶
-
PCS_CHINA_2000_3_DEGREE_GK_43= 21643¶
-
PCS_CHINA_2000_3_DEGREE_GK_43N= 21693¶
-
PCS_CHINA_2000_3_DEGREE_GK_44= 21644¶
-
PCS_CHINA_2000_3_DEGREE_GK_44N= 21694¶
-
PCS_CHINA_2000_3_DEGREE_GK_45= 21645¶
-
PCS_CHINA_2000_3_DEGREE_GK_45N= 21695¶
-
PCS_CHINA_2000_GK_13= 21513¶
-
PCS_CHINA_2000_GK_13N= 21573¶
-
PCS_CHINA_2000_GK_14= 21514¶
-
PCS_CHINA_2000_GK_14N= 21574¶
-
PCS_CHINA_2000_GK_15= 21515¶
-
PCS_CHINA_2000_GK_15N= 21575¶
-
PCS_CHINA_2000_GK_16= 21516¶
-
PCS_CHINA_2000_GK_16N= 21576¶
-
PCS_CHINA_2000_GK_17= 21517¶
-
PCS_CHINA_2000_GK_17N= 21577¶
-
PCS_CHINA_2000_GK_18= 21518¶
-
PCS_CHINA_2000_GK_18N= 21578¶
-
PCS_CHINA_2000_GK_19= 21519¶
-
PCS_CHINA_2000_GK_19N= 21579¶
-
PCS_CHINA_2000_GK_20= 21520¶
-
PCS_CHINA_2000_GK_20N= 21580¶
-
PCS_CHINA_2000_GK_21= 21521¶
-
PCS_CHINA_2000_GK_21N= 21581¶
-
PCS_CHINA_2000_GK_22= 21522¶
-
PCS_CHINA_2000_GK_22N= 21582¶
-
PCS_CHINA_2000_GK_23= 21523¶
-
PCS_CHINA_2000_GK_23N= 21583¶
-
PCS_CORREGO_ALEGRE_UTM_23S= 22523¶
-
PCS_CORREGO_ALEGRE_UTM_24S= 22524¶
-
PCS_C_INCHAUSARGENTINA_1= 22191¶
-
PCS_C_INCHAUSARGENTINA_2= 22192¶
-
PCS_C_INCHAUSARGENTINA_3= 22193¶
-
PCS_C_INCHAUSARGENTINA_4= 22194¶
-
PCS_C_INCHAUSARGENTINA_5= 22195¶
-
PCS_C_INCHAUSARGENTINA_6= 22196¶
-
PCS_C_INCHAUSARGENTINA_7= 22197¶
-
PCS_DATUM73_MODIFIED_PORTUGUESE_GRID= 27493¶
-
PCS_DATUM73_MODIFIED_PORTUGUESE_NATIONAL_GRID= 27492¶
-
PCS_DATUM_73_UTM_ZONE_29N= 27429¶
-
PCS_DEALUL_PISCULUI_1933_STEREO_33= 31600¶
-
PCS_DEALUL_PISCULUI_1970_STEREO_EALUL_PISCULUI_1970_STEREO_70= 31700¶
-
PCS_DHDN_GERMANY_1= 31491¶
-
PCS_DHDN_GERMANY_2= 31492¶
-
PCS_DHDN_GERMANY_3= 31493¶
-
PCS_DHDN_GERMANY_4= 31494¶
-
PCS_DHDN_GERMANY_5= 31495¶
-
PCS_DOUALA_UTM_32N= 22832¶
-
PCS_EARTH_LONGITUDE_LATITUDE= 1¶
-
PCS_ED50_CENTRAL_GROUP= 61002¶
-
PCS_ED50_OCCIDENTAL_GROUP= 61003¶
-
PCS_ED50_ORIENTAL_GROUP= 61001¶
-
PCS_ED_1950_UTM_28N= 23028¶
-
PCS_ED_1950_UTM_29N= 23029¶
-
PCS_ED_1950_UTM_30N= 23030¶
-
PCS_ED_1950_UTM_31N= 23031¶
-
PCS_ED_1950_UTM_32N= 23032¶
-
PCS_ED_1950_UTM_33N= 23033¶
-
PCS_ED_1950_UTM_34N= 23034¶
-
PCS_ED_1950_UTM_35N= 23035¶
-
PCS_ED_1950_UTM_36N= 23036¶
-
PCS_ED_1950_UTM_37N= 23037¶
-
PCS_ED_1950_UTM_38N= 23038¶
-
PCS_EGYPT_EXT_PURPLE_BELT= 22994¶
-
PCS_EGYPT_PURPLE_BELT= 22993¶
-
PCS_EGYPT_RED_BELT= 22992¶
-
PCS_ETRS89_PORTUGAL_TM06= 3763¶
-
PCS_ETRS_1989_UTM_28N= 25828¶
-
PCS_ETRS_1989_UTM_29N= 25829¶
-
PCS_ETRS_1989_UTM_30N= 25830¶
-
PCS_ETRS_1989_UTM_31N= 25831¶
-
PCS_ETRS_1989_UTM_32N= 25832¶
-
PCS_ETRS_1989_UTM_33N= 25833¶
-
PCS_ETRS_1989_UTM_34N= 25834¶
-
PCS_ETRS_1989_UTM_35N= 25835¶
-
PCS_ETRS_1989_UTM_36N= 25836¶
-
PCS_ETRS_1989_UTM_37N= 25837¶
-
PCS_ETRS_1989_UTM_38N= 25838¶
-
PCS_FAHUD_UTM_39N= 23239¶
-
PCS_FAHUD_UTM_40N= 23240¶
-
PCS_GAROUA_UTM_33N= 23433¶
-
PCS_GDA_1994_MGA_48= 28348¶
-
PCS_GDA_1994_MGA_49= 28349¶
-
PCS_GDA_1994_MGA_50= 28350¶
-
PCS_GDA_1994_MGA_51= 28351¶
-
PCS_GDA_1994_MGA_52= 28352¶
-
PCS_GDA_1994_MGA_53= 28353¶
-
PCS_GDA_1994_MGA_54= 28354¶
-
PCS_GDA_1994_MGA_55= 28355¶
-
PCS_GDA_1994_MGA_56= 28356¶
-
PCS_GDA_1994_MGA_57= 28357¶
-
PCS_GDA_1994_MGA_58= 28358¶
-
PCS_GGRS_1987_GREEK_GRID= 2100¶
-
PCS_ID_1974_UTM_46N= 23846¶
-
PCS_ID_1974_UTM_46S= 23886¶
-
PCS_ID_1974_UTM_47N= 23847¶
-
PCS_ID_1974_UTM_47S= 23887¶
-
PCS_ID_1974_UTM_48N= 23848¶
-
PCS_ID_1974_UTM_48S= 23888¶
-
PCS_ID_1974_UTM_49N= 23849¶
-
PCS_ID_1974_UTM_49S= 23889¶
-
PCS_ID_1974_UTM_50N= 23850¶
-
PCS_ID_1974_UTM_50S= 23890¶
-
PCS_ID_1974_UTM_51N= 23851¶
-
PCS_ID_1974_UTM_51S= 23891¶
-
PCS_ID_1974_UTM_52N= 23852¶
-
PCS_ID_1974_UTM_52S= 23892¶
-
PCS_ID_1974_UTM_53N= 23853¶
-
PCS_ID_1974_UTM_53S= 23893¶
-
PCS_ID_1974_UTM_54S= 23894¶
-
PCS_INDIAN_1954_UTM_47N= 23947¶
-
PCS_INDIAN_1954_UTM_48N= 23948¶
-
PCS_INDIAN_1975_UTM_47N= 24047¶
-
PCS_INDIAN_1975_UTM_48N= 24048¶
-
PCS_JAD_1969_JAMAICA_GRID= 24200¶
-
PCS_JAMAICA_1875_OLD_GRID= 24100¶
-
PCS_JAPAN_PLATE_ZONE_I= 32786¶
-
PCS_JAPAN_PLATE_ZONE_II= 32787¶
-
PCS_JAPAN_PLATE_ZONE_III= 32788¶
-
PCS_JAPAN_PLATE_ZONE_IV= 32789¶
-
PCS_JAPAN_PLATE_ZONE_IX= 32794¶
-
PCS_JAPAN_PLATE_ZONE_V= 32790¶
-
PCS_JAPAN_PLATE_ZONE_VI= 32791¶
-
PCS_JAPAN_PLATE_ZONE_VII= 32792¶
-
PCS_JAPAN_PLATE_ZONE_VIII= 32793¶
-
PCS_JAPAN_PLATE_ZONE_X= 32795¶
-
PCS_JAPAN_PLATE_ZONE_XI= 32796¶
-
PCS_JAPAN_PLATE_ZONE_XII= 32797¶
-
PCS_JAPAN_PLATE_ZONE_XIII= 32798¶
-
PCS_JAPAN_PLATE_ZONE_XIV= 32800¶
-
PCS_JAPAN_PLATE_ZONE_XIX= 32805¶
-
PCS_JAPAN_PLATE_ZONE_XV= 32801¶
-
PCS_JAPAN_PLATE_ZONE_XVI= 32802¶
-
PCS_JAPAN_PLATE_ZONE_XVII= 32803¶
-
PCS_JAPAN_PLATE_ZONE_XVIII= 32804¶
-
PCS_JAPAN_UTM_51= 32806¶
-
PCS_JAPAN_UTM_52= 32807¶
-
PCS_JAPAN_UTM_53= 32808¶
-
PCS_JAPAN_UTM_54= 32809¶
-
PCS_JAPAN_UTM_55= 32810¶
-
PCS_JAPAN_UTM_56= 32811¶
-
PCS_KALIANPUR_INDIA_0= 24370¶
-
PCS_KALIANPUR_INDIA_I= 24371¶
-
PCS_KALIANPUR_INDIA_IIA= 24372¶
-
PCS_KALIANPUR_INDIA_IIB= 24382¶
-
PCS_KALIANPUR_INDIA_IIIA= 24373¶
-
PCS_KALIANPUR_INDIA_IIIB= 24383¶
-
PCS_KALIANPUR_INDIA_IVA= 24374¶
-
PCS_KALIANPUR_INDIA_IVB= 24384¶
-
PCS_KERTAU_MALAYA_METERS= 23110¶
-
PCS_KERTAU_UTM_47N= 24547¶
-
PCS_KERTAU_UTM_48N= 24548¶
-
PCS_KKJ_FINLAND_1= 2391¶
-
PCS_KKJ_FINLAND_2= 2392¶
-
PCS_KKJ_FINLAND_3= 2393¶
-
PCS_KKJ_FINLAND_4= 2394¶
-
PCS_KOC_LAMBERT= 24600¶
-
PCS_KUDAMS_KTM= 31900¶
-
PCS_LA_CANOA_UTM_20N= 24720¶
-
PCS_LA_CANOA_UTM_21N= 24721¶
-
PCS_LEIGON_GHANA_GRID= 25000¶
-
PCS_LISBON_1890_PORTUGAL_BONNE= 61008¶
-
PCS_LISBON_PORTUGUESE_GRID= 20700¶
-
PCS_LISBON_PORTUGUESE_OFFICIAL_GRID= 20791¶
-
PCS_LOME_UTM_31N= 25231¶
-
PCS_LUZON_PHILIPPINES_I= 25391¶
-
PCS_LUZON_PHILIPPINES_II= 25392¶
-
PCS_LUZON_PHILIPPINES_III= 25393¶
-
PCS_LUZON_PHILIPPINES_IV= 25394¶
-
PCS_LUZON_PHILIPPINES_V= 25395¶
-
PCS_Lisboa_Hayford_Gauss_IGeoE= 53700¶
-
PCS_Lisboa_Hayford_Gauss_IPCC= 53791¶
-
PCS_MADEIRA_1936_UTM_ZONE_28N= 2191¶
-
PCS_MALONGO_1987_UTM_32S= 25932¶
-
PCS_MASSAWA_UTM_37N= 26237¶
-
PCS_MERCHICH_NORD_MAROC= 26191¶
-
PCS_MERCHICH_SAHARA= 26193¶
-
PCS_MERCHICH_SUD_MAROC= 26192¶
-
PCS_MGI_FERRO_AUSTRIA_CENTRAL= 31292¶
-
PCS_MGI_FERRO_AUSTRIA_EAST= 31293¶
-
PCS_MGI_FERRO_AUSTRIA_WEST= 31291¶
-
PCS_MHAST_UTM_32S= 26432¶
-
PCS_MINNA_NIGERIA_EAST_BELT= 26393¶
-
PCS_MINNA_NIGERIA_MID_BELT= 26392¶
-
PCS_MINNA_NIGERIA_WEST_BELT= 26391¶
-
PCS_MINNA_UTM_31N= 26331¶
-
PCS_MINNA_UTM_32N= 26332¶
-
PCS_MONTE_MARIO_ROME_ITALY_1= 26591¶
-
PCS_MONTE_MARIO_ROME_ITALY_2= 26592¶
-
PCS_MPORALOKO_UTM_32N= 26632¶
-
PCS_MPORALOKO_UTM_32S= 26692¶
-
PCS_NAD_1927_AK_1= 26731¶
-
PCS_NAD_1927_AK_10= 26740¶
-
PCS_NAD_1927_AK_2= 26732¶
-
PCS_NAD_1927_AK_3= 26733¶
-
PCS_NAD_1927_AK_4= 26734¶
-
PCS_NAD_1927_AK_5= 26735¶
-
PCS_NAD_1927_AK_6= 26736¶
-
PCS_NAD_1927_AK_7= 26737¶
-
PCS_NAD_1927_AK_8= 26738¶
-
PCS_NAD_1927_AK_9= 26739¶
-
PCS_NAD_1927_AL_E= 26729¶
-
PCS_NAD_1927_AL_W= 26730¶
-
PCS_NAD_1927_AR_N= 26751¶
-
PCS_NAD_1927_AR_S= 26752¶
-
PCS_NAD_1927_AZ_C= 26749¶
-
PCS_NAD_1927_AZ_E= 26748¶
-
PCS_NAD_1927_AZ_W= 26750¶
-
PCS_NAD_1927_BLM_14N= 32074¶
-
PCS_NAD_1927_BLM_15N= 32075¶
-
PCS_NAD_1927_BLM_16N= 32076¶
-
PCS_NAD_1927_BLM_17N= 32077¶
-
PCS_NAD_1927_CA_I= 26741¶
-
PCS_NAD_1927_CA_II= 26742¶
-
PCS_NAD_1927_CA_III= 26743¶
-
PCS_NAD_1927_CA_IV= 26744¶
-
PCS_NAD_1927_CA_V= 26745¶
-
PCS_NAD_1927_CA_VI= 26746¶
-
PCS_NAD_1927_CA_VII= 26747¶
-
PCS_NAD_1927_CO_C= 26754¶
-
PCS_NAD_1927_CO_N= 26753¶
-
PCS_NAD_1927_CO_S= 26755¶
-
PCS_NAD_1927_CT= 26756¶
-
PCS_NAD_1927_DE= 26757¶
-
PCS_NAD_1927_FL_E= 26758¶
-
PCS_NAD_1927_FL_N= 26760¶
-
PCS_NAD_1927_FL_W= 26759¶
-
PCS_NAD_1927_GA_E= 26766¶
-
PCS_NAD_1927_GA_W= 26767¶
-
PCS_NAD_1927_GU= 65061¶
-
PCS_NAD_1927_HI_1= 26761¶
-
PCS_NAD_1927_HI_2= 26762¶
-
PCS_NAD_1927_HI_3= 26763¶
-
PCS_NAD_1927_HI_4= 26764¶
-
PCS_NAD_1927_HI_5= 26765¶
-
PCS_NAD_1927_IA_N= 26775¶
-
PCS_NAD_1927_IA_S= 26776¶
-
PCS_NAD_1927_ID_C= 26769¶
-
PCS_NAD_1927_ID_E= 26768¶
-
PCS_NAD_1927_ID_W= 26770¶
-
PCS_NAD_1927_IL_E= 26771¶
-
PCS_NAD_1927_IL_W= 26772¶
-
PCS_NAD_1927_IN_E= 26773¶
-
PCS_NAD_1927_IN_W= 26774¶
-
PCS_NAD_1927_KS_N= 26777¶
-
PCS_NAD_1927_KS_S= 26778¶
-
PCS_NAD_1927_KY_N= 26779¶
-
PCS_NAD_1927_KY_S= 26780¶
-
PCS_NAD_1927_LA_N= 26781¶
-
PCS_NAD_1927_LA_S= 26782¶
-
PCS_NAD_1927_MA_I= 26787¶
-
PCS_NAD_1927_MA_M= 26786¶
-
PCS_NAD_1927_MD= 26785¶
-
PCS_NAD_1927_ME_E= 26783¶
-
PCS_NAD_1927_ME_W= 26784¶
-
PCS_NAD_1927_MI_C= 26789¶
-
PCS_NAD_1927_MI_N= 26788¶
-
PCS_NAD_1927_MI_S= 26790¶
-
PCS_NAD_1927_MN_C= 26792¶
-
PCS_NAD_1927_MN_N= 26791¶
-
PCS_NAD_1927_MN_S= 26793¶
-
PCS_NAD_1927_MO_C= 26797¶
-
PCS_NAD_1927_MO_E= 26796¶
-
PCS_NAD_1927_MO_W= 26798¶
-
PCS_NAD_1927_MS_E= 26794¶
-
PCS_NAD_1927_MS_W= 26795¶
-
PCS_NAD_1927_MT_C= 32002¶
-
PCS_NAD_1927_MT_N= 32001¶
-
PCS_NAD_1927_MT_S= 32003¶
-
PCS_NAD_1927_NC= 32019¶
-
PCS_NAD_1927_ND_N= 32020¶
-
PCS_NAD_1927_ND_S= 32021¶
-
PCS_NAD_1927_NE_N= 32005¶
-
PCS_NAD_1927_NE_S= 32006¶
-
PCS_NAD_1927_NH= 32010¶
-
PCS_NAD_1927_NJ= 32011¶
-
PCS_NAD_1927_NM_C= 32013¶
-
PCS_NAD_1927_NM_E= 32012¶
-
PCS_NAD_1927_NM_W= 32014¶
-
PCS_NAD_1927_NV_C= 32008¶
-
PCS_NAD_1927_NV_E= 32007¶
-
PCS_NAD_1927_NV_W= 32009¶
-
PCS_NAD_1927_NY_C= 32016¶
-
PCS_NAD_1927_NY_E= 32015¶
-
PCS_NAD_1927_NY_LI= 32018¶
-
PCS_NAD_1927_NY_W= 32017¶
-
PCS_NAD_1927_OH_N= 32022¶
-
PCS_NAD_1927_OH_S= 32023¶
-
PCS_NAD_1927_OK_N= 32024¶
-
PCS_NAD_1927_OK_S= 32025¶
-
PCS_NAD_1927_OR_N= 32026¶
-
PCS_NAD_1927_OR_S= 32027¶
-
PCS_NAD_1927_PA_N= 32028¶
-
PCS_NAD_1927_PA_S= 32029¶
-
PCS_NAD_1927_PR= 32059¶
-
PCS_NAD_1927_RI= 32030¶
-
PCS_NAD_1927_SC_N= 32031¶
-
PCS_NAD_1927_SC_S= 32033¶
-
PCS_NAD_1927_SD_N= 32034¶
-
PCS_NAD_1927_SD_S= 32035¶
-
PCS_NAD_1927_TN= 32036¶
-
PCS_NAD_1927_TX_C= 32039¶
-
PCS_NAD_1927_TX_N= 32037¶
-
PCS_NAD_1927_TX_NC= 32038¶
-
PCS_NAD_1927_TX_S= 32041¶
-
PCS_NAD_1927_TX_SC= 32040¶
-
PCS_NAD_1927_UTM_10N= 26710¶
-
PCS_NAD_1927_UTM_11N= 26711¶
-
PCS_NAD_1927_UTM_12N= 26712¶
-
PCS_NAD_1927_UTM_13N= 26713¶
-
PCS_NAD_1927_UTM_14N= 26714¶
-
PCS_NAD_1927_UTM_15N= 26715¶
-
PCS_NAD_1927_UTM_16N= 26716¶
-
PCS_NAD_1927_UTM_17N= 26717¶
-
PCS_NAD_1927_UTM_18N= 26718¶
-
PCS_NAD_1927_UTM_19N= 26719¶
-
PCS_NAD_1927_UTM_20N= 26720¶
-
PCS_NAD_1927_UTM_21N= 26721¶
-
PCS_NAD_1927_UTM_22N= 26722¶
-
PCS_NAD_1927_UTM_3N= 26703¶
-
PCS_NAD_1927_UTM_4N= 26704¶
-
PCS_NAD_1927_UTM_5N= 26705¶
-
PCS_NAD_1927_UTM_6N= 26706¶
-
PCS_NAD_1927_UTM_7N= 26707¶
-
PCS_NAD_1927_UTM_8N= 26708¶
-
PCS_NAD_1927_UTM_9N= 26709¶
-
PCS_NAD_1927_UT_C= 32043¶
-
PCS_NAD_1927_UT_N= 32042¶
-
PCS_NAD_1927_UT_S= 32044¶
-
PCS_NAD_1927_VA_N= 32046¶
-
PCS_NAD_1927_VA_S= 32047¶
-
PCS_NAD_1927_VI= 32060¶
-
PCS_NAD_1927_VT= 32045¶
-
PCS_NAD_1927_WA_N= 32048¶
-
PCS_NAD_1927_WA_S= 32049¶
-
PCS_NAD_1927_WI_C= 32053¶
-
PCS_NAD_1927_WI_N= 32052¶
-
PCS_NAD_1927_WI_S= 32054¶
-
PCS_NAD_1927_WV_N= 32050¶
-
PCS_NAD_1927_WV_S= 32051¶
-
PCS_NAD_1927_WY_E= 32055¶
-
PCS_NAD_1927_WY_EC= 32056¶
-
PCS_NAD_1927_WY_W= 32058¶
-
PCS_NAD_1927_WY_WC= 32057¶
-
PCS_NAD_1983_AK_1= 26931¶
-
PCS_NAD_1983_AK_10= 26940¶
-
PCS_NAD_1983_AK_2= 26932¶
-
PCS_NAD_1983_AK_3= 26933¶
-
PCS_NAD_1983_AK_4= 26934¶
-
PCS_NAD_1983_AK_5= 26935¶
-
PCS_NAD_1983_AK_6= 26936¶
-
PCS_NAD_1983_AK_7= 26937¶
-
PCS_NAD_1983_AK_8= 26938¶
-
PCS_NAD_1983_AK_9= 26939¶
-
PCS_NAD_1983_AL_E= 26929¶
-
PCS_NAD_1983_AL_W= 26930¶
-
PCS_NAD_1983_AR_N= 26951¶
-
PCS_NAD_1983_AR_S= 26952¶
-
PCS_NAD_1983_AZ_C= 26949¶
-
PCS_NAD_1983_AZ_E= 26948¶
-
PCS_NAD_1983_AZ_W= 26950¶
-
PCS_NAD_1983_CA_I= 26941¶
-
PCS_NAD_1983_CA_II= 26942¶
-
PCS_NAD_1983_CA_III= 26943¶
-
PCS_NAD_1983_CA_IV= 26944¶
-
PCS_NAD_1983_CA_V= 26945¶
-
PCS_NAD_1983_CA_VI= 26946¶
-
PCS_NAD_1983_CO_C= 26954¶
-
PCS_NAD_1983_CO_N= 26953¶
-
PCS_NAD_1983_CO_S= 26955¶
-
PCS_NAD_1983_CT= 26956¶
-
PCS_NAD_1983_DE= 26957¶
-
PCS_NAD_1983_FL_E= 26958¶
-
PCS_NAD_1983_FL_N= 26960¶
-
PCS_NAD_1983_FL_W= 26959¶
-
PCS_NAD_1983_GA_E= 26966¶
-
PCS_NAD_1983_GA_W= 26967¶
-
PCS_NAD_1983_GU= 65161¶
-
PCS_NAD_1983_HI_1= 26961¶
-
PCS_NAD_1983_HI_2= 26962¶
-
PCS_NAD_1983_HI_3= 26963¶
-
PCS_NAD_1983_HI_4= 26964¶
-
PCS_NAD_1983_HI_5= 26965¶
-
PCS_NAD_1983_IA_N= 26975¶
-
PCS_NAD_1983_IA_S= 26976¶
-
PCS_NAD_1983_ID_C= 26969¶
-
PCS_NAD_1983_ID_E= 26968¶
-
PCS_NAD_1983_ID_W= 26970¶
-
PCS_NAD_1983_IL_E= 26971¶
-
PCS_NAD_1983_IL_W= 26972¶
-
PCS_NAD_1983_IN_E= 26973¶
-
PCS_NAD_1983_IN_W= 26974¶
-
PCS_NAD_1983_KS_N= 26977¶
-
PCS_NAD_1983_KS_S= 26978¶
-
PCS_NAD_1983_KY_N= 26979¶
-
PCS_NAD_1983_KY_S= 26980¶
-
PCS_NAD_1983_LA_N= 26981¶
-
PCS_NAD_1983_LA_S= 26982¶
-
PCS_NAD_1983_MA_I= 26987¶
-
PCS_NAD_1983_MA_M= 26986¶
-
PCS_NAD_1983_MD= 26985¶
-
PCS_NAD_1983_ME_E= 26983¶
-
PCS_NAD_1983_ME_W= 26984¶
-
PCS_NAD_1983_MI_C= 26989¶
-
PCS_NAD_1983_MI_N= 26988¶
-
PCS_NAD_1983_MI_S= 26990¶
-
PCS_NAD_1983_MN_C= 26992¶
-
PCS_NAD_1983_MN_N= 26991¶
-
PCS_NAD_1983_MN_S= 26993¶
-
PCS_NAD_1983_MO_C= 26997¶
-
PCS_NAD_1983_MO_E= 26996¶
-
PCS_NAD_1983_MO_W= 26998¶
-
PCS_NAD_1983_MS_E= 26994¶
-
PCS_NAD_1983_MS_W= 26995¶
-
PCS_NAD_1983_MT= 32100¶
-
PCS_NAD_1983_NC= 32119¶
-
PCS_NAD_1983_ND_N= 32120¶
-
PCS_NAD_1983_ND_S= 32121¶
-
PCS_NAD_1983_NE= 32104¶
-
PCS_NAD_1983_NH= 32110¶
-
PCS_NAD_1983_NJ= 32111¶
-
PCS_NAD_1983_NM_C= 32113¶
-
PCS_NAD_1983_NM_E= 32112¶
-
PCS_NAD_1983_NM_W= 32114¶
-
PCS_NAD_1983_NV_C= 32108¶
-
PCS_NAD_1983_NV_E= 32107¶
-
PCS_NAD_1983_NV_W= 32109¶
-
PCS_NAD_1983_NY_C= 32116¶
-
PCS_NAD_1983_NY_E= 32115¶
-
PCS_NAD_1983_NY_LI= 32118¶
-
PCS_NAD_1983_NY_W= 32117¶
-
PCS_NAD_1983_OH_N= 32122¶
-
PCS_NAD_1983_OH_S= 32123¶
-
PCS_NAD_1983_OK_N= 32124¶
-
PCS_NAD_1983_OK_S= 32125¶
-
PCS_NAD_1983_OR_N= 32126¶
-
PCS_NAD_1983_OR_S= 32127¶
-
PCS_NAD_1983_PA_N= 32128¶
-
PCS_NAD_1983_PA_S= 32129¶
-
PCS_NAD_1983_PR_VI= 32161¶
-
PCS_NAD_1983_RI= 32130¶
-
PCS_NAD_1983_SC= 32133¶
-
PCS_NAD_1983_SD_N= 32134¶
-
PCS_NAD_1983_SD_S= 32135¶
-
PCS_NAD_1983_TN= 32136¶
-
PCS_NAD_1983_TX_C= 32139¶
-
PCS_NAD_1983_TX_N= 32137¶
-
PCS_NAD_1983_TX_NC= 32138¶
-
PCS_NAD_1983_TX_S= 32141¶
-
PCS_NAD_1983_TX_SC= 32140¶
-
PCS_NAD_1983_UTM_10N= 26910¶
-
PCS_NAD_1983_UTM_11N= 26911¶
-
PCS_NAD_1983_UTM_12N= 26912¶
-
PCS_NAD_1983_UTM_13N= 26913¶
-
PCS_NAD_1983_UTM_14N= 26914¶
-
PCS_NAD_1983_UTM_15N= 26915¶
-
PCS_NAD_1983_UTM_16N= 26916¶
-
PCS_NAD_1983_UTM_17N= 26917¶
-
PCS_NAD_1983_UTM_18N= 26918¶
-
PCS_NAD_1983_UTM_19N= 26919¶
-
PCS_NAD_1983_UTM_20N= 26920¶
-
PCS_NAD_1983_UTM_21N= 26921¶
-
PCS_NAD_1983_UTM_22N= 26922¶
-
PCS_NAD_1983_UTM_23N= 26923¶
-
PCS_NAD_1983_UTM_3N= 26903¶
-
PCS_NAD_1983_UTM_4N= 26904¶
-
PCS_NAD_1983_UTM_5N= 26905¶
-
PCS_NAD_1983_UTM_6N= 26906¶
-
PCS_NAD_1983_UTM_7N= 26907¶
-
PCS_NAD_1983_UTM_8N= 26908¶
-
PCS_NAD_1983_UTM_9N= 26909¶
-
PCS_NAD_1983_UT_C= 32143¶
-
PCS_NAD_1983_UT_N= 32142¶
-
PCS_NAD_1983_UT_S= 32144¶
-
PCS_NAD_1983_VA_N= 32146¶
-
PCS_NAD_1983_VA_S= 32147¶
-
PCS_NAD_1983_VT= 32145¶
-
PCS_NAD_1983_WA_N= 32148¶
-
PCS_NAD_1983_WA_S= 32149¶
-
PCS_NAD_1983_WI_C= 32153¶
-
PCS_NAD_1983_WI_N= 32152¶
-
PCS_NAD_1983_WI_S= 32154¶
-
PCS_NAD_1983_WV_N= 32150¶
-
PCS_NAD_1983_WV_S= 32151¶
-
PCS_NAD_1983_WY_E= 32155¶
-
PCS_NAD_1983_WY_EC= 32156¶
-
PCS_NAD_1983_WY_W= 32158¶
-
PCS_NAD_1983_WY_WC= 32157¶
-
PCS_NAHRWAN_1967_UTM_38N= 27038¶
-
PCS_NAHRWAN_1967_UTM_39N= 27039¶
-
PCS_NAHRWAN_1967_UTM_40N= 27040¶
-
PCS_NAPARIMA_1972_UTM_20N= 27120¶
-
PCS_NGN_UTM_38N= 31838¶
-
PCS_NGN_UTM_39N= 31839¶
-
PCS_NON_EARTH= 0¶
-
PCS_NORD_SAHARA_UTM_29N= 30729¶
-
PCS_NORD_SAHARA_UTM_30N= 30730¶
-
PCS_NORD_SAHARA_UTM_31N= 30731¶
-
PCS_NORD_SAHARA_UTM_32N= 30732¶
-
PCS_NTF_CENTRE_FRANCE= 27592¶
-
PCS_NTF_CORSE= 27594¶
-
PCS_NTF_FRANCE_I= 27581¶
-
PCS_NTF_FRANCE_II= 27582¶
-
PCS_NTF_FRANCE_III= 27583¶
-
PCS_NTF_FRANCE_IV= 27584¶
-
PCS_NTF_NORD_FRANCE= 27591¶
-
PCS_NTF_SUD_FRANCE= 27593¶
-
PCS_NZGD_1949_NORTH_ISLAND= 27291¶
-
PCS_NZGD_1949_SOUTH_ISLAND= 27292¶
-
PCS_OSGB_1936_BRITISH_GRID= 27700¶
-
PCS_POINTE_NOIRE_UTM_32S= 28232¶
-
PCS_PSAD_1956_PERU_CENTRAL= 24892¶
-
PCS_PSAD_1956_PERU_EAST= 24893¶
-
PCS_PSAD_1956_PERU_WEST= 24891¶
-
PCS_PSAD_1956_UTM_17S= 24877¶
-
PCS_PSAD_1956_UTM_18N= 24818¶
-
PCS_PSAD_1956_UTM_18S= 24878¶
-
PCS_PSAD_1956_UTM_19N= 24819¶
-
PCS_PSAD_1956_UTM_19S= 24879¶
-
PCS_PSAD_1956_UTM_20N= 24820¶
-
PCS_PSAD_1956_UTM_20S= 24880¶
-
PCS_PSAD_1956_UTM_21N= 24821¶
-
PCS_PTRA08_UTM25_ITRF93= 61007¶
-
PCS_PTRA08_UTM26_ITRF93= 61006¶
-
PCS_PTRA08_UTM28_ITRF93= 61004¶
-
PCS_PULKOVO_1942_GK_10= 28410¶
-
PCS_PULKOVO_1942_GK_10N= 28470¶
-
PCS_PULKOVO_1942_GK_11= 28411¶
-
PCS_PULKOVO_1942_GK_11N= 28471¶
-
PCS_PULKOVO_1942_GK_12= 28412¶
-
PCS_PULKOVO_1942_GK_12N= 28472¶
-
PCS_PULKOVO_1942_GK_13= 28413¶
-
PCS_PULKOVO_1942_GK_13N= 28473¶
-
PCS_PULKOVO_1942_GK_14= 28414¶
-
PCS_PULKOVO_1942_GK_14N= 28474¶
-
PCS_PULKOVO_1942_GK_15= 28415¶
-
PCS_PULKOVO_1942_GK_15N= 28475¶
-
PCS_PULKOVO_1942_GK_16= 28416¶
-
PCS_PULKOVO_1942_GK_16N= 28476¶
-
PCS_PULKOVO_1942_GK_17= 28417¶
-
PCS_PULKOVO_1942_GK_17N= 28477¶
-
PCS_PULKOVO_1942_GK_18= 28418¶
-
PCS_PULKOVO_1942_GK_18N= 28478¶
-
PCS_PULKOVO_1942_GK_19= 28419¶
-
PCS_PULKOVO_1942_GK_19N= 28479¶
-
PCS_PULKOVO_1942_GK_20= 28420¶
-
PCS_PULKOVO_1942_GK_20N= 28480¶
-
PCS_PULKOVO_1942_GK_21= 28421¶
-
PCS_PULKOVO_1942_GK_21N= 28481¶
-
PCS_PULKOVO_1942_GK_22= 28422¶
-
PCS_PULKOVO_1942_GK_22N= 28482¶
-
PCS_PULKOVO_1942_GK_23= 28423¶
-
PCS_PULKOVO_1942_GK_23N= 28483¶
-
PCS_PULKOVO_1942_GK_24= 28424¶
-
PCS_PULKOVO_1942_GK_24N= 28484¶
-
PCS_PULKOVO_1942_GK_25= 28425¶
-
PCS_PULKOVO_1942_GK_25N= 28485¶
-
PCS_PULKOVO_1942_GK_26= 28426¶
-
PCS_PULKOVO_1942_GK_26N= 28486¶
-
PCS_PULKOVO_1942_GK_27= 28427¶
-
PCS_PULKOVO_1942_GK_27N= 28487¶
-
PCS_PULKOVO_1942_GK_28= 28428¶
-
PCS_PULKOVO_1942_GK_28N= 28488¶
-
PCS_PULKOVO_1942_GK_29= 28429¶
-
PCS_PULKOVO_1942_GK_29N= 28489¶
-
PCS_PULKOVO_1942_GK_30= 28430¶
-
PCS_PULKOVO_1942_GK_30N= 28490¶
-
PCS_PULKOVO_1942_GK_31= 28431¶
-
PCS_PULKOVO_1942_GK_31N= 28491¶
-
PCS_PULKOVO_1942_GK_32= 28432¶
-
PCS_PULKOVO_1942_GK_32N= 28492¶
-
PCS_PULKOVO_1942_GK_4= 28404¶
-
PCS_PULKOVO_1942_GK_4N= 28464¶
-
PCS_PULKOVO_1942_GK_5= 28405¶
-
PCS_PULKOVO_1942_GK_5N= 28465¶
-
PCS_PULKOVO_1942_GK_6= 28406¶
-
PCS_PULKOVO_1942_GK_6N= 28466¶
-
PCS_PULKOVO_1942_GK_7= 28407¶
-
PCS_PULKOVO_1942_GK_7N= 28467¶
-
PCS_PULKOVO_1942_GK_8= 28408¶
-
PCS_PULKOVO_1942_GK_8N= 28468¶
-
PCS_PULKOVO_1942_GK_9= 28409¶
-
PCS_PULKOVO_1942_GK_9N= 28469¶
-
PCS_PULKOVO_1995_GK_10= 20010¶
-
PCS_PULKOVO_1995_GK_10N= 20070¶
-
PCS_PULKOVO_1995_GK_11= 20011¶
-
PCS_PULKOVO_1995_GK_11N= 20071¶
-
PCS_PULKOVO_1995_GK_12= 20012¶
-
PCS_PULKOVO_1995_GK_12N= 20072¶
-
PCS_PULKOVO_1995_GK_13= 20013¶
-
PCS_PULKOVO_1995_GK_13N= 20073¶
-
PCS_PULKOVO_1995_GK_14= 20014¶
-
PCS_PULKOVO_1995_GK_14N= 20074¶
-
PCS_PULKOVO_1995_GK_15= 20015¶
-
PCS_PULKOVO_1995_GK_15N= 20075¶
-
PCS_PULKOVO_1995_GK_16= 20016¶
-
PCS_PULKOVO_1995_GK_16N= 20076¶
-
PCS_PULKOVO_1995_GK_17= 20017¶
-
PCS_PULKOVO_1995_GK_17N= 20077¶
-
PCS_PULKOVO_1995_GK_18= 20018¶
-
PCS_PULKOVO_1995_GK_18N= 20078¶
-
PCS_PULKOVO_1995_GK_19= 20019¶
-
PCS_PULKOVO_1995_GK_19N= 20079¶
-
PCS_PULKOVO_1995_GK_20= 20020¶
-
PCS_PULKOVO_1995_GK_20N= 20080¶
-
PCS_PULKOVO_1995_GK_21= 20021¶
-
PCS_PULKOVO_1995_GK_21N= 20081¶
-
PCS_PULKOVO_1995_GK_22= 20022¶
-
PCS_PULKOVO_1995_GK_22N= 20082¶
-
PCS_PULKOVO_1995_GK_23= 20023¶
-
PCS_PULKOVO_1995_GK_23N= 20083¶
-
PCS_PULKOVO_1995_GK_24= 20024¶
-
PCS_PULKOVO_1995_GK_24N= 20084¶
-
PCS_PULKOVO_1995_GK_25= 20025¶
-
PCS_PULKOVO_1995_GK_25N= 20085¶
-
PCS_PULKOVO_1995_GK_26= 20026¶
-
PCS_PULKOVO_1995_GK_26N= 20086¶
-
PCS_PULKOVO_1995_GK_27= 20027¶
-
PCS_PULKOVO_1995_GK_27N= 20087¶
-
PCS_PULKOVO_1995_GK_28= 20028¶
-
PCS_PULKOVO_1995_GK_28N= 20088¶
-
PCS_PULKOVO_1995_GK_29= 20029¶
-
PCS_PULKOVO_1995_GK_29N= 20089¶
-
PCS_PULKOVO_1995_GK_30= 20030¶
-
PCS_PULKOVO_1995_GK_30N= 20090¶
-
PCS_PULKOVO_1995_GK_31= 20031¶
-
PCS_PULKOVO_1995_GK_31N= 20091¶
-
PCS_PULKOVO_1995_GK_32= 20032¶
-
PCS_PULKOVO_1995_GK_32N= 20092¶
-
PCS_PULKOVO_1995_GK_4= 20004¶
-
PCS_PULKOVO_1995_GK_4N= 20064¶
-
PCS_PULKOVO_1995_GK_5= 20005¶
-
PCS_PULKOVO_1995_GK_5N= 20065¶
-
PCS_PULKOVO_1995_GK_6= 20006¶
-
PCS_PULKOVO_1995_GK_6N= 20066¶
-
PCS_PULKOVO_1995_GK_7= 20007¶
-
PCS_PULKOVO_1995_GK_7N= 20067¶
-
PCS_PULKOVO_1995_GK_8= 20008¶
-
PCS_PULKOVO_1995_GK_8N= 20068¶
-
PCS_PULKOVO_1995_GK_9= 20009¶
-
PCS_PULKOVO_1995_GK_9N= 20069¶
-
PCS_QATAR_GRID= 28600¶
-
PCS_RT38_STOCKHOLM_SWEDISH_GRID= 30800¶
-
PCS_SAD_1969_UTM_17S= 29177¶
-
PCS_SAD_1969_UTM_18N= 29118¶
-
PCS_SAD_1969_UTM_18S= 29178¶
-
PCS_SAD_1969_UTM_19N= 29119¶
-
PCS_SAD_1969_UTM_19S= 29179¶
-
PCS_SAD_1969_UTM_20N= 29120¶
-
PCS_SAD_1969_UTM_20S= 29180¶
-
PCS_SAD_1969_UTM_21N= 29121¶
-
PCS_SAD_1969_UTM_21S= 29181¶
-
PCS_SAD_1969_UTM_22N= 29122¶
-
PCS_SAD_1969_UTM_22S= 29182¶
-
PCS_SAD_1969_UTM_23S= 29183¶
-
PCS_SAD_1969_UTM_24S= 29184¶
-
PCS_SAD_1969_UTM_25S= 29185¶
-
PCS_SAPPER_HILL_UTM_20S= 29220¶
-
PCS_SAPPER_HILL_UTM_21S= 29221¶
-
PCS_SCHWARZECK_UTM_33S= 29333¶
-
PCS_SPHERE_BEHRMANN= 53017¶
-
PCS_SPHERE_BONNE= 53024¶
-
PCS_SPHERE_CASSINI= 53028¶
-
PCS_SPHERE_ECKERT_I= 53015¶
-
PCS_SPHERE_ECKERT_II= 53014¶
-
PCS_SPHERE_ECKERT_III= 53013¶
-
PCS_SPHERE_ECKERT_IV= 53012¶
-
PCS_SPHERE_ECKERT_V= 53011¶
-
PCS_SPHERE_ECKERT_VI= 53010¶
-
PCS_SPHERE_EQUIDISTANT_CONIC= 53027¶
-
PCS_SPHERE_EQUIDISTANT_CYLINDRICAL= 53002¶
-
PCS_SPHERE_GALL_STEREOGRAPHIC= 53016¶
-
PCS_SPHERE_LOXIMUTHAL= 53023¶
-
PCS_SPHERE_MERCATOR= 53004¶
-
PCS_SPHERE_MILLER_CYLINDRICAL= 53003¶
-
PCS_SPHERE_MOLLWEIDE= 53009¶
-
PCS_SPHERE_PLATE_CARREE= 53001¶
-
PCS_SPHERE_POLYCONIC= 53021¶
-
PCS_SPHERE_QUARTIC_AUTHALIC= 53022¶
-
PCS_SPHERE_ROBINSON= 53030¶
-
PCS_SPHERE_SINUSOIDAL= 53008¶
-
PCS_SPHERE_STEREOGRAPHIC= 53026¶
-
PCS_SPHERE_TWO_POINT_EQUIDISTANT= 53031¶
-
PCS_SPHERE_VAN_DER_GRINTEN_I= 53029¶
-
PCS_SPHERE_WINKEL_I= 53018¶
-
PCS_SPHERE_WINKEL_II= 53019¶
-
PCS_SUDAN_UTM_35N= 29635¶
-
PCS_SUDAN_UTM_36N= 29636¶
-
PCS_TANANARIVE_UTM_38S= 29738¶
-
PCS_TANANARIVE_UTM_39S= 29739¶
-
PCS_TC_1948_UTM_39N= 30339¶
-
PCS_TC_1948_UTM_40N= 30340¶
-
PCS_TIMBALAI_1948_RSO_BORNEO= 23130¶
-
PCS_TIMBALAI_1948_UTM_49N= 29849¶
-
PCS_TIMBALAI_1948_UTM_50N= 29850¶
-
PCS_TM65_IRISH_GRID= 29900¶
-
PCS_TOKYO_PLATE_ZONE_I= 32761¶
-
PCS_TOKYO_PLATE_ZONE_II= 32762¶
-
PCS_TOKYO_PLATE_ZONE_III= 32763¶
-
PCS_TOKYO_PLATE_ZONE_IV= 32764¶
-
PCS_TOKYO_PLATE_ZONE_IX= 32769¶
-
PCS_TOKYO_PLATE_ZONE_V= 32765¶
-
PCS_TOKYO_PLATE_ZONE_VI= 32766¶
-
PCS_TOKYO_PLATE_ZONE_VII= 32767¶
-
PCS_TOKYO_PLATE_ZONE_VIII= 32768¶
-
PCS_TOKYO_PLATE_ZONE_X= 32770¶
-
PCS_TOKYO_PLATE_ZONE_XI= 32771¶
-
PCS_TOKYO_PLATE_ZONE_XII= 32772¶
-
PCS_TOKYO_PLATE_ZONE_XIII= 32773¶
-
PCS_TOKYO_PLATE_ZONE_XIV= 32774¶
-
PCS_TOKYO_PLATE_ZONE_XIX= 32779¶
-
PCS_TOKYO_PLATE_ZONE_XV= 32775¶
-
PCS_TOKYO_PLATE_ZONE_XVI= 32776¶
-
PCS_TOKYO_PLATE_ZONE_XVII= 32777¶
-
PCS_TOKYO_PLATE_ZONE_XVIII= 32778¶
-
PCS_TOKYO_UTM_51= 32780¶
-
PCS_TOKYO_UTM_52= 32781¶
-
PCS_TOKYO_UTM_53= 32782¶
-
PCS_TOKYO_UTM_54= 32783¶
-
PCS_TOKYO_UTM_55= 32784¶
-
PCS_TOKYO_UTM_56= 32785¶
-
PCS_USER_DEFINED= -1¶
-
PCS_VOIROL_N_ALGERIE_ANCIENNE= 30491¶
-
PCS_VOIROL_S_ALGERIE_ANCIENNE= 30492¶
-
PCS_VOIROL_UNIFIE_N_ALGERIE= 30591¶
-
PCS_VOIROL_UNIFIE_S_ALGERIE= 30592¶
-
PCS_WGS_1972_UTM_10N= 32210¶
-
PCS_WGS_1972_UTM_10S= 32310¶
-
PCS_WGS_1972_UTM_11N= 32211¶
-
PCS_WGS_1972_UTM_11S= 32311¶
-
PCS_WGS_1972_UTM_12N= 32212¶
-
PCS_WGS_1972_UTM_12S= 32312¶
-
PCS_WGS_1972_UTM_13N= 32213¶
-
PCS_WGS_1972_UTM_13S= 32313¶
-
PCS_WGS_1972_UTM_14N= 32214¶
-
PCS_WGS_1972_UTM_14S= 32314¶
-
PCS_WGS_1972_UTM_15N= 32215¶
-
PCS_WGS_1972_UTM_15S= 32315¶
-
PCS_WGS_1972_UTM_16N= 32216¶
-
PCS_WGS_1972_UTM_16S= 32316¶
-
PCS_WGS_1972_UTM_17N= 32217¶
-
PCS_WGS_1972_UTM_17S= 32317¶
-
PCS_WGS_1972_UTM_18N= 32218¶
-
PCS_WGS_1972_UTM_18S= 32318¶
-
PCS_WGS_1972_UTM_19N= 32219¶
-
PCS_WGS_1972_UTM_19S= 32319¶
-
PCS_WGS_1972_UTM_1N= 32201¶
-
PCS_WGS_1972_UTM_1S= 32301¶
-
PCS_WGS_1972_UTM_20N= 32220¶
-
PCS_WGS_1972_UTM_20S= 32320¶
-
PCS_WGS_1972_UTM_21N= 32221¶
-
PCS_WGS_1972_UTM_21S= 32321¶
-
PCS_WGS_1972_UTM_22N= 32222¶
-
PCS_WGS_1972_UTM_22S= 32322¶
-
PCS_WGS_1972_UTM_23N= 32223¶
-
PCS_WGS_1972_UTM_23S= 32323¶
-
PCS_WGS_1972_UTM_24N= 32224¶
-
PCS_WGS_1972_UTM_24S= 32324¶
-
PCS_WGS_1972_UTM_25N= 32225¶
-
PCS_WGS_1972_UTM_25S= 32325¶
-
PCS_WGS_1972_UTM_26N= 32226¶
-
PCS_WGS_1972_UTM_26S= 32326¶
-
PCS_WGS_1972_UTM_27N= 32227¶
-
PCS_WGS_1972_UTM_27S= 32327¶
-
PCS_WGS_1972_UTM_28N= 32228¶
-
PCS_WGS_1972_UTM_28S= 32328¶
-
PCS_WGS_1972_UTM_29N= 32229¶
-
PCS_WGS_1972_UTM_29S= 32329¶
-
PCS_WGS_1972_UTM_2N= 32202¶
-
PCS_WGS_1972_UTM_2S= 32302¶
-
PCS_WGS_1972_UTM_30N= 32230¶
-
PCS_WGS_1972_UTM_30S= 32330¶
-
PCS_WGS_1972_UTM_31N= 32231¶
-
PCS_WGS_1972_UTM_31S= 32331¶
-
PCS_WGS_1972_UTM_32N= 32232¶
-
PCS_WGS_1972_UTM_32S= 32332¶
-
PCS_WGS_1972_UTM_33N= 32233¶
-
PCS_WGS_1972_UTM_33S= 32333¶
-
PCS_WGS_1972_UTM_34N= 32234¶
-
PCS_WGS_1972_UTM_34S= 32334¶
-
PCS_WGS_1972_UTM_35N= 32235¶
-
PCS_WGS_1972_UTM_35S= 32335¶
-
PCS_WGS_1972_UTM_36N= 32236¶
-
PCS_WGS_1972_UTM_36S= 32336¶
-
PCS_WGS_1972_UTM_37N= 32237¶
-
PCS_WGS_1972_UTM_37S= 32337¶
-
PCS_WGS_1972_UTM_38N= 32238¶
-
PCS_WGS_1972_UTM_38S= 32338¶
-
PCS_WGS_1972_UTM_39N= 32239¶
-
PCS_WGS_1972_UTM_39S= 32339¶
-
PCS_WGS_1972_UTM_3N= 32203¶
-
PCS_WGS_1972_UTM_3S= 32303¶
-
PCS_WGS_1972_UTM_40N= 32240¶
-
PCS_WGS_1972_UTM_40S= 32340¶
-
PCS_WGS_1972_UTM_41N= 32241¶
-
PCS_WGS_1972_UTM_41S= 32341¶
-
PCS_WGS_1972_UTM_42N= 32242¶
-
PCS_WGS_1972_UTM_42S= 32342¶
-
PCS_WGS_1972_UTM_43N= 32243¶
-
PCS_WGS_1972_UTM_43S= 32343¶
-
PCS_WGS_1972_UTM_44N= 32244¶
-
PCS_WGS_1972_UTM_44S= 32344¶
-
PCS_WGS_1972_UTM_45N= 32245¶
-
PCS_WGS_1972_UTM_45S= 32345¶
-
PCS_WGS_1972_UTM_46N= 32246¶
-
PCS_WGS_1972_UTM_46S= 32346¶
-
PCS_WGS_1972_UTM_47N= 32247¶
-
PCS_WGS_1972_UTM_47S= 32347¶
-
PCS_WGS_1972_UTM_48N= 32248¶
-
PCS_WGS_1972_UTM_48S= 32348¶
-
PCS_WGS_1972_UTM_49N= 32249¶
-
PCS_WGS_1972_UTM_49S= 32349¶
-
PCS_WGS_1972_UTM_4N= 32204¶
-
PCS_WGS_1972_UTM_4S= 32304¶
-
PCS_WGS_1972_UTM_50N= 32250¶
-
PCS_WGS_1972_UTM_50S= 32350¶
-
PCS_WGS_1972_UTM_51N= 32251¶
-
PCS_WGS_1972_UTM_51S= 32351¶
-
PCS_WGS_1972_UTM_52N= 32252¶
-
PCS_WGS_1972_UTM_52S= 32352¶
-
PCS_WGS_1972_UTM_53N= 32253¶
-
PCS_WGS_1972_UTM_53S= 32353¶
-
PCS_WGS_1972_UTM_54N= 32254¶
-
PCS_WGS_1972_UTM_54S= 32354¶
-
PCS_WGS_1972_UTM_55N= 32255¶
-
PCS_WGS_1972_UTM_55S= 32355¶
-
PCS_WGS_1972_UTM_56N= 32256¶
-
PCS_WGS_1972_UTM_56S= 32356¶
-
PCS_WGS_1972_UTM_57N= 32257¶
-
PCS_WGS_1972_UTM_57S= 32357¶
-
PCS_WGS_1972_UTM_58N= 32258¶
-
PCS_WGS_1972_UTM_58S= 32358¶
-
PCS_WGS_1972_UTM_59N= 32259¶
-
PCS_WGS_1972_UTM_59S= 32359¶
-
PCS_WGS_1972_UTM_5N= 32205¶
-
PCS_WGS_1972_UTM_5S= 32305¶
-
PCS_WGS_1972_UTM_60N= 32260¶
-
PCS_WGS_1972_UTM_60S= 32360¶
-
PCS_WGS_1972_UTM_6N= 32206¶
-
PCS_WGS_1972_UTM_6S= 32306¶
-
PCS_WGS_1972_UTM_7N= 32207¶
-
PCS_WGS_1972_UTM_7S= 32307¶
-
PCS_WGS_1972_UTM_8N= 32208¶
-
PCS_WGS_1972_UTM_8S= 32308¶
-
PCS_WGS_1972_UTM_9N= 32209¶
-
PCS_WGS_1972_UTM_9S= 32309¶
-
PCS_WGS_1984_UTM_10N= 32610¶
-
PCS_WGS_1984_UTM_10S= 32710¶
-
PCS_WGS_1984_UTM_11N= 32611¶
-
PCS_WGS_1984_UTM_11S= 32711¶
-
PCS_WGS_1984_UTM_12N= 32612¶
-
PCS_WGS_1984_UTM_12S= 32712¶
-
PCS_WGS_1984_UTM_13N= 32613¶
-
PCS_WGS_1984_UTM_13S= 32713¶
-
PCS_WGS_1984_UTM_14N= 32614¶
-
PCS_WGS_1984_UTM_14S= 32714¶
-
PCS_WGS_1984_UTM_15N= 32615¶
-
PCS_WGS_1984_UTM_15S= 32715¶
-
PCS_WGS_1984_UTM_16N= 32616¶
-
PCS_WGS_1984_UTM_16S= 32716¶
-
PCS_WGS_1984_UTM_17N= 32617¶
-
PCS_WGS_1984_UTM_17S= 32717¶
-
PCS_WGS_1984_UTM_18N= 32618¶
-
PCS_WGS_1984_UTM_18S= 32718¶
-
PCS_WGS_1984_UTM_19N= 32619¶
-
PCS_WGS_1984_UTM_19S= 32719¶
-
PCS_WGS_1984_UTM_1N= 32601¶
-
PCS_WGS_1984_UTM_1S= 32701¶
-
PCS_WGS_1984_UTM_20N= 32620¶
-
PCS_WGS_1984_UTM_20S= 32720¶
-
PCS_WGS_1984_UTM_21N= 32621¶
-
PCS_WGS_1984_UTM_21S= 32721¶
-
PCS_WGS_1984_UTM_22N= 32622¶
-
PCS_WGS_1984_UTM_22S= 32722¶
-
PCS_WGS_1984_UTM_23N= 32623¶
-
PCS_WGS_1984_UTM_23S= 32723¶
-
PCS_WGS_1984_UTM_24N= 32624¶
-
PCS_WGS_1984_UTM_24S= 32724¶
-
PCS_WGS_1984_UTM_25N= 32625¶
-
PCS_WGS_1984_UTM_25S= 32725¶
-
PCS_WGS_1984_UTM_26N= 32626¶
-
PCS_WGS_1984_UTM_26S= 32726¶
-
PCS_WGS_1984_UTM_27N= 32627¶
-
PCS_WGS_1984_UTM_27S= 32727¶
-
PCS_WGS_1984_UTM_28N= 32628¶
-
PCS_WGS_1984_UTM_28S= 32728¶
-
PCS_WGS_1984_UTM_29N= 32629¶
-
PCS_WGS_1984_UTM_29S= 32729¶
-
PCS_WGS_1984_UTM_2N= 32602¶
-
PCS_WGS_1984_UTM_2S= 32702¶
-
PCS_WGS_1984_UTM_30N= 32630¶
-
PCS_WGS_1984_UTM_30S= 32730¶
-
PCS_WGS_1984_UTM_31N= 32631¶
-
PCS_WGS_1984_UTM_31S= 32731¶
-
PCS_WGS_1984_UTM_32N= 32632¶
-
PCS_WGS_1984_UTM_32S= 32732¶
-
PCS_WGS_1984_UTM_33N= 32633¶
-
PCS_WGS_1984_UTM_33S= 32733¶
-
PCS_WGS_1984_UTM_34N= 32634¶
-
PCS_WGS_1984_UTM_34S= 32734¶
-
PCS_WGS_1984_UTM_35N= 32635¶
-
PCS_WGS_1984_UTM_35S= 32735¶
-
PCS_WGS_1984_UTM_36N= 32636¶
-
PCS_WGS_1984_UTM_36S= 32736¶
-
PCS_WGS_1984_UTM_37N= 32637¶
-
PCS_WGS_1984_UTM_37S= 32737¶
-
PCS_WGS_1984_UTM_38N= 32638¶
-
PCS_WGS_1984_UTM_38S= 32738¶
-
PCS_WGS_1984_UTM_39N= 32639¶
-
PCS_WGS_1984_UTM_39S= 32739¶
-
PCS_WGS_1984_UTM_3N= 32603¶
-
PCS_WGS_1984_UTM_3S= 32703¶
-
PCS_WGS_1984_UTM_40N= 32640¶
-
PCS_WGS_1984_UTM_40S= 32740¶
-
PCS_WGS_1984_UTM_41N= 32641¶
-
PCS_WGS_1984_UTM_41S= 32741¶
-
PCS_WGS_1984_UTM_42N= 32642¶
-
PCS_WGS_1984_UTM_42S= 32742¶
-
PCS_WGS_1984_UTM_43N= 32643¶
-
PCS_WGS_1984_UTM_43S= 32743¶
-
PCS_WGS_1984_UTM_44N= 32644¶
-
PCS_WGS_1984_UTM_44S= 32744¶
-
PCS_WGS_1984_UTM_45N= 32645¶
-
PCS_WGS_1984_UTM_45S= 32745¶
-
PCS_WGS_1984_UTM_46N= 32646¶
-
PCS_WGS_1984_UTM_46S= 32746¶
-
PCS_WGS_1984_UTM_47N= 32647¶
-
PCS_WGS_1984_UTM_47S= 32747¶
-
PCS_WGS_1984_UTM_48N= 32648¶
-
PCS_WGS_1984_UTM_48S= 32748¶
-
PCS_WGS_1984_UTM_49N= 32649¶
-
PCS_WGS_1984_UTM_49S= 32749¶
-
PCS_WGS_1984_UTM_4N= 32604¶
-
PCS_WGS_1984_UTM_4S= 32704¶
-
PCS_WGS_1984_UTM_50N= 32650¶
-
PCS_WGS_1984_UTM_50S= 32750¶
-
PCS_WGS_1984_UTM_51N= 32651¶
-
PCS_WGS_1984_UTM_51S= 32751¶
-
PCS_WGS_1984_UTM_52N= 32652¶
-
PCS_WGS_1984_UTM_52S= 32752¶
-
PCS_WGS_1984_UTM_53N= 32653¶
-
PCS_WGS_1984_UTM_53S= 32753¶
-
PCS_WGS_1984_UTM_54N= 32654¶
-
PCS_WGS_1984_UTM_54S= 32754¶
-
PCS_WGS_1984_UTM_55N= 32655¶
-
PCS_WGS_1984_UTM_55S= 32755¶
-
PCS_WGS_1984_UTM_56N= 32656¶
-
PCS_WGS_1984_UTM_56S= 32756¶
-
PCS_WGS_1984_UTM_57N= 32657¶
-
PCS_WGS_1984_UTM_57S= 32757¶
-
PCS_WGS_1984_UTM_58N= 32658¶
-
PCS_WGS_1984_UTM_58S= 32758¶
-
PCS_WGS_1984_UTM_59N= 32659¶
-
PCS_WGS_1984_UTM_59S= 32759¶
-
PCS_WGS_1984_UTM_5N= 32605¶
-
PCS_WGS_1984_UTM_5S= 32705¶
-
PCS_WGS_1984_UTM_60N= 32660¶
-
PCS_WGS_1984_UTM_60S= 32760¶
-
PCS_WGS_1984_UTM_6N= 32606¶
-
PCS_WGS_1984_UTM_6S= 32706¶
-
PCS_WGS_1984_UTM_7N= 32607¶
-
PCS_WGS_1984_UTM_7S= 32707¶
-
PCS_WGS_1984_UTM_8N= 32608¶
-
PCS_WGS_1984_UTM_8S= 32708¶
-
PCS_WGS_1984_UTM_9N= 32609¶
-
PCS_WGS_1984_UTM_9S= 32709¶
-
PCS_WGS_1984_WORLD_MERCATOR= 3395¶
-
PCS_WORLD_BEHRMANN= 54017¶
-
PCS_WORLD_BONNE= 54024¶
-
PCS_WORLD_CASSINI= 54028¶
-
PCS_WORLD_ECKERT_I= 54015¶
-
PCS_WORLD_ECKERT_II= 54014¶
-
PCS_WORLD_ECKERT_III= 54013¶
-
PCS_WORLD_ECKERT_IV= 54012¶
-
PCS_WORLD_ECKERT_V= 54011¶
-
PCS_WORLD_ECKERT_VI= 54010¶
-
PCS_WORLD_EQUIDISTANT_CONIC= 54027¶
-
PCS_WORLD_EQUIDISTANT_CYLINDRICAL= 54002¶
-
PCS_WORLD_GALL_STEREOGRAPHIC= 54016¶
-
PCS_WORLD_HOTINE= 54025¶
-
PCS_WORLD_LOXIMUTHAL= 54023¶
-
PCS_WORLD_MERCATOR= 54004¶
-
PCS_WORLD_MILLER_CYLINDRICAL= 54003¶
-
PCS_WORLD_MOLLWEIDE= 54009¶
-
PCS_WORLD_PLATE_CARREE= 54001¶
-
PCS_WORLD_POLYCONIC= 54021¶
-
PCS_WORLD_QUARTIC_AUTHALIC= 54022¶
-
PCS_WORLD_ROBINSON= 54030¶
-
PCS_WORLD_SINUSOIDAL= 54008¶
-
PCS_WORLD_STEREOGRAPHIC= 54026¶
-
PCS_WORLD_TWO_POINT_EQUIDISTANT= 54031¶
-
PCS_WORLD_VAN_DER_GRINTEN_I= 54029¶
-
PCS_WORLD_WINKEL_I= 54018¶
-
PCS_WORLD_WINKEL_II= 54019¶
-
PCS_XIAN_1980_3_DEGREE_GK_25= 2349¶
-
PCS_XIAN_1980_3_DEGREE_GK_25N= 2370¶
-
PCS_XIAN_1980_3_DEGREE_GK_26= 2350¶
-
PCS_XIAN_1980_3_DEGREE_GK_26N= 2371¶
-
PCS_XIAN_1980_3_DEGREE_GK_27= 2351¶
-
PCS_XIAN_1980_3_DEGREE_GK_27N= 2372¶
-
PCS_XIAN_1980_3_DEGREE_GK_28= 2352¶
-
PCS_XIAN_1980_3_DEGREE_GK_28N= 2373¶
-
PCS_XIAN_1980_3_DEGREE_GK_29= 2353¶
-
PCS_XIAN_1980_3_DEGREE_GK_29N= 2374¶
-
PCS_XIAN_1980_3_DEGREE_GK_30= 2354¶
-
PCS_XIAN_1980_3_DEGREE_GK_30N= 2375¶
-
PCS_XIAN_1980_3_DEGREE_GK_31= 2355¶
-
PCS_XIAN_1980_3_DEGREE_GK_31N= 2376¶
-
PCS_XIAN_1980_3_DEGREE_GK_32= 2356¶
-
PCS_XIAN_1980_3_DEGREE_GK_32N= 2377¶
-
PCS_XIAN_1980_3_DEGREE_GK_33= 2357¶
-
PCS_XIAN_1980_3_DEGREE_GK_33N= 2378¶
-
PCS_XIAN_1980_3_DEGREE_GK_34= 2358¶
-
PCS_XIAN_1980_3_DEGREE_GK_34N= 2379¶
-
PCS_XIAN_1980_3_DEGREE_GK_35= 2359¶
-
PCS_XIAN_1980_3_DEGREE_GK_35N= 2380¶
-
PCS_XIAN_1980_3_DEGREE_GK_36= 2360¶
-
PCS_XIAN_1980_3_DEGREE_GK_36N= 2381¶
-
PCS_XIAN_1980_3_DEGREE_GK_37= 2361¶
-
PCS_XIAN_1980_3_DEGREE_GK_37N= 2382¶
-
PCS_XIAN_1980_3_DEGREE_GK_38= 2362¶
-
PCS_XIAN_1980_3_DEGREE_GK_38N= 2383¶
-
PCS_XIAN_1980_3_DEGREE_GK_39= 2363¶
-
PCS_XIAN_1980_3_DEGREE_GK_39N= 2384¶
-
PCS_XIAN_1980_3_DEGREE_GK_40= 2364¶
-
PCS_XIAN_1980_3_DEGREE_GK_40N= 2385¶
-
PCS_XIAN_1980_3_DEGREE_GK_41= 2365¶
-
PCS_XIAN_1980_3_DEGREE_GK_41N= 2386¶
-
PCS_XIAN_1980_3_DEGREE_GK_42= 2366¶
-
PCS_XIAN_1980_3_DEGREE_GK_42N= 2387¶
-
PCS_XIAN_1980_3_DEGREE_GK_43= 2367¶
-
PCS_XIAN_1980_3_DEGREE_GK_43N= 2388¶
-
PCS_XIAN_1980_3_DEGREE_GK_44= 2368¶
-
PCS_XIAN_1980_3_DEGREE_GK_44N= 2389¶
-
PCS_XIAN_1980_3_DEGREE_GK_45= 2369¶
-
PCS_XIAN_1980_3_DEGREE_GK_45N= 2390¶
-
PCS_XIAN_1980_GK_13= 2327¶
-
PCS_XIAN_1980_GK_13N= 2338¶
-
PCS_XIAN_1980_GK_14= 2328¶
-
PCS_XIAN_1980_GK_14N= 2339¶
-
PCS_XIAN_1980_GK_15= 2329¶
-
PCS_XIAN_1980_GK_15N= 2340¶
-
PCS_XIAN_1980_GK_16= 2330¶
-
PCS_XIAN_1980_GK_16N= 2341¶
-
PCS_XIAN_1980_GK_17= 2331¶
-
PCS_XIAN_1980_GK_17N= 2342¶
-
PCS_XIAN_1980_GK_18= 2332¶
-
PCS_XIAN_1980_GK_18N= 2343¶
-
PCS_XIAN_1980_GK_19= 2333¶
-
PCS_XIAN_1980_GK_19N= 2344¶
-
PCS_XIAN_1980_GK_20= 2334¶
-
PCS_XIAN_1980_GK_20N= 2345¶
-
PCS_XIAN_1980_GK_21= 2335¶
-
PCS_XIAN_1980_GK_21N= 2346¶
-
PCS_XIAN_1980_GK_22= 2336¶
-
PCS_XIAN_1980_GK_22N= 2347¶
-
PCS_XIAN_1980_GK_23= 2337¶
-
PCS_XIAN_1980_GK_23N= 2348¶
-
PCS_YOFF_1972_UTM_28N= 31028¶
-
PCS_ZANDERIJ_1972_UTM_21N= 31121¶
-
-
class
iobjectspy.enums.ImportMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了导入模式类型常量。用于控制在数据导入时出现的设置的目标对象(数据集等)名称已存在情况下,即设置的名称已有名称冲突时的操作模式。
变量: - ImportMode.NONE -- 如存在名称冲突,则自动修改目标对象的名称后进行导入。
- ImportMode.OVERWRITE -- 如存在名称冲突,则进行强制覆盖。
- ImportMode.APPEND -- 如存在名称冲突,则进行数据集的追加。
-
APPEND= 2¶
-
NONE= 0¶
-
OVERWRITE= 1¶
-
class
iobjectspy.enums.IgnoreMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了忽略颜色值模式的类型常量。
变量: - IgnoreMode.IGNORENONE -- 不忽略颜色值。
- IgnoreMode.IGNORESIGNAL -- 按值忽略,忽略某个或某几个颜色值。
- IgnoreMode.IGNOREBORDER -- 按照扫描线的方式忽略颜色值。
-
IGNOREBORDER= 2¶
-
IGNORENONE= 0¶
-
IGNORESIGNAL= 1¶
-
class
iobjectspy.enums.MultiBandImportMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了多波段导入模式类型常量,提供了导入多波段数据所采用的模式。
变量: - MultiBandImportMode.SINGLEBAND -- 将多波段数据导入为多个单波段数据集
- MultiBandImportMode.MULTIBAND -- 将多波段数据导入为一个多波段数据集
- MultiBandImportMode.COMPOSITE --
将多波段数据导入为一个单波段数据集,目前此模式适用于以下两种情况:
- 三波段 8 位的数据导入为一个 RGB 单波段 24 位的数据集;
- 四波段 8 位的数据导入为一个 RGBA 单波段 32 位的数据集。
-
COMPOSITE= 2¶
-
MULTIBAND= 1¶
-
SINGLEBAND= 0¶
-
class
iobjectspy.enums.CADVersion¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了 AutoCAD 版本类型常量。提供了 AutoCAD 的不同版本类型及说明。
变量: - CADVersion.CAD12 -- OdDb::vAC12 R11-12
- CADVersion.CAD13 -- OdDb::vAC13 R13
- CADVersion.CAD14 -- OdDb::vAC14 R14
- CADVersion.CAD2000 -- OdDb::vAC15 2000-2002
- CADVersion.CAD2004 -- OdDb::vAC18 2004-2006
- CADVersion.CAD2007 -- OdDb::vAC21 2007
-
CAD12= 12¶
-
CAD13= 13¶
-
CAD14= 14¶
-
CAD2000= 2000¶
-
CAD2004= 2004¶
-
CAD2007= 2007¶
-
class
iobjectspy.enums.TopologyRule¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了拓扑规则类型常量。
该类主要用于对点、线和面数据进行拓扑检查,是拓扑检查的一个参数。根据相应的拓扑规则,返回不符合规则的对象。
变量: - TopologyRule.REGION_NO_OVERLAP -- 面内无重叠,用于对面数据进行拓扑检查。检查一个面数据集(或者面记录集)中相互有重叠的面对象。此规则 多用于一个区域不能同时属于两个对象的情况。如行政区划面,相邻的区划之间要求不能有任何重叠,行政区划 数据上必须是每个区域都有明确的地域定义。此类数据还包括:土地利用图斑、邮政编码覆盖区划、公民投票选 区区划等。重叠部分作为错误生成到结果数据集中,错误数据集类型:面。注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.REGION_NO_GAPS --
面内无缝隙,用于对面数据进行拓扑检查。返回一个面数据集(或者面记录集)中相邻面之间有空隙的面对象。此规 则多用于检查一个面数据中,单个区域或相邻区域之间有空隙的情况。一般对于如土地利用图斑这样的数据,要求不 能有未定义土地利用类型的斑块,可使用此规则进行检查。
注意:
- 只对一个数据集或记录集本身进行检查。
- 若被检查的面数据集(或记录集)中存在自相交面对象,则检查可能失败或结果错误。建议检查时,先进行 “面内无自相交”(REGION_NO_SELF_INTERSECTION)规则检查,或自行对自相交面进行修改,确认无自相交 对象后再进行“面内无缝隙”规则检查。
- TopologyRule.REGION_NO_OVERLAP_WITH -- 面与面无重叠,用于对面数据进行拓扑检查。检查两个面数据集中重叠的所有对象。此规则检查第一个面数 据中,与第二个面数据有重叠的所有对象。如将水域数据与旱地数据叠加,可用此规则检查。重叠部分作为 错误生成到结果数据集中,错误数据集类型:面
- TopologyRule.REGION_COVERED_BY_REGION_CLASS -- 面被多个面覆盖,用于对面数据进行拓扑检查。检查第一个面数据集(或者面记录集)中没有 被第二个面数据集(或者面记录集)覆盖的对象。如:省界 Area1 中每一个省域都必须完全 被县界 Area2 中属于该省的面域所覆盖。未覆盖的部分将作为错误生成到结果数据集中,错误数据集类型:面
- TopologyRule.REGION_COVERED_BY_REGION -- 面被面包含,用于对面数据进行拓扑检查。 检查第一个面数据集(或者面记录集)中没有被第二个面数据集(或者面记录集)中任何对象包含的对象。即面数据 1 的区域都必须被面数据 2 的某一个区域完全包含。 未被包含的面对象整个将作为错误生成到结果数据集中,错误数据集类型:面。
- TopologyRule.REGION_BOUNDARY_COVERED_BY_LINE -- 面边界被多条线覆盖,用于对面数据进行拓扑检查。 检查面数据集(或者面记录集)中对象的边界没有被线数据集(或者线记录集)中的线覆盖的对象。 通常用于行政区界或地块和存储有边界线属性的线数据进行检查。面数据中不能存储一些边界线的属性, 此时需要专门的边界线数据,存储区域边界的不同属性,要求边界线与区域边界线完全重合。 未被覆盖的边界将作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.REGION_BOUNDARY_COVERED_BY_REGION_BOUNDARY -- 面边界被边界覆盖,用于对面数据进行拓扑检查。 检查面数据集(或者面记录集)中边界没有被另一面数据集(或者面记录集)中对象(可以为多个)的边界覆盖的对象。 未被覆盖的边界将作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.REGION_CONTAIN_POINT -- 面包含点,用于对面数据进行拓扑检查。 检查面数据集(或者面记录集)中没有包含任何点数据集(或者点记录集)中点的对象。例如省域数据与省会数据进行检查,每个省内都必须有一个省会城市,不包含任何点数据的面对象,都将被检查出来。 未包含点的面对象将作为错误生成到结果数据集中,错误数据集类型:面。
- TopologyRule.LINE_NO_INTERSECTION -- 线内无相交,用于对线数据进行拓扑检查。 检查一个线数据集(或者线记录集)中相互有相交(不包括端点和内部接触及端点和端点接触)的线对象。交点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_NO_OVERLAP -- 线内无重叠,用于对线数据进行拓扑检查。检查一个线数据集(或者线记录集)中相互有重叠的线对象。对象之间重叠的部分将作为错误生成到结果数据集中,错误数据集类型:线。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_NO_DANGLES -- 线内无悬线,用于对线数据进行拓扑检查。检查一个线数据集(或者线记录集)中被定义为悬线的对象,包括过头线和长悬线。悬点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_NO_PSEUDO_NODES -- 线内无假结点,用于对线数据进行拓扑检查。返回一个线数据集(或者线记录集)中包含假结点的线对象。假结点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_NO_OVERLAP_WITH -- 线与线无重叠,用于对线数据进行拓扑检查。检查第一个线数据集(或者线记录集)中和第二个线数据集(或者线记录集)中的对象有重叠的所有对象。如交通路线中的公路和铁路不能出现重叠。 重叠部分作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.LINE_NO_INTERSECT_OR_INTERIOR_TOUCH -- 线内无相交或无内部接触,用于对线数据进行拓扑检查。返回一个线数据集(或者线记录集)中和其它线对象相交的线对象,即除端点之间接触外其它所有的相交或内部接触的线对象。 交点作为错误生成到结果数据集中,错误数据集类型:点。 注意:线数据集(或者线记录集)中所有交点必须是线的端点,即相交的弧段必须被打断,否则就违反此规则(自交不检查)。
- TopologyRule.LINE_NO_SELF_OVERLAP -- 线内无自交叠,用于对线数据进行拓扑检查。检查一个线数据集(或者线记录集)内相互有交叠(交集是线)的线对象。自交叠部分(线)将作为错误生成到结果数据集中,错误数据集类型:线。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_NO_SELF_INTERSECT -- 线内无自相交,用于对线数据进行拓扑检查。检查一个线数据集(或者线记录集)内自相交的线对象(包括自交叠的情况)。 交点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.LINE_BE_COVERED_BY_LINE_CLASS -- 线被多条线完全覆盖,用于对线数据进行拓扑检查。 检查第一个线数据集(或者线记录集)中没有与第二个线数据集(或者线记录集)中的对象有重合的对象。 未被覆盖的部分将作为错误生成到结果数据集中,错误数据集类型:线。 注意:线数据集(或线记录集)中每一个对象,都必须被另一个线数据集(或者线记录集)中的一个或多个线对象覆盖。如Line1中的某条公交路线必须被Line2中的一系列相连的街道覆盖。
- TopologyRule.LINE_COVERED_BY_REGION_BOUNDARY -- 线被面边界覆盖,用于对线数据进行拓扑检查。检查线数据集(或者线记录集)中没有与面数据集(或者面记录集)中某个对象的边界重合的对象。(可被多个面的边界覆盖)。 未被边界覆盖的部分将作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.LINE_END_POINT_COVERED_BY_POINT -- 线端点必须被点覆盖,用于对线数据进行拓扑检查。 检查线数据集(或者线记录集)中的端点没有与点数据集(或者点记录集)中任何一个点重合的对象。 未被覆盖的端点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.POINT_COVERED_BY_LINE -- 点必须在线上,用于对点数据进行拓扑检查。 返回点数据集(或者点记录集)中没有被线数据集(或者线记录集)中的某个对象覆盖的对象。如高速公路上的收费站。 未被覆盖的点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.POINT_COVERED_BY_REGION_BOUNDARY -- 点必须在面的边界上,用于对点数据进行拓扑检查。 检查点数据集(或者点记录集)中没有在面数据集(或者面记录集)中某个对象的边界上的对象。 不在面边界上的点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.POINT_CONTAINED_BY_REGION -- 点被面完全包含,用于对点数据进行拓扑检查。 检查点数据集(或者点记录集)中没有被面数据集(或者面记录集)中任何一个对象内部包含的点对象。 不在面内的点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.POINT_BECOVERED_BY_LINE_END_POINT -- 点必须被线端点覆盖,用于对点数据进行拓扑检查。 返回点数据集(或者点记录集)中没有被线数据集(或者线记录集)中任意对象的端点覆盖的对象。
- TopologyRule.NO_MULTIPART -- 无复杂对象。检查一个数据集或记录集内包含子对象的复杂对象,适用于面和线。 复杂对象将作为错误生成到结果数据集中,错误数据集类型:线或面。
- TopologyRule.POINT_NO_IDENTICAL -- 无重复点,用于对点数据进行拓扑检查。检查点数据集中的重复点对象。点数据集内发生重叠的对象都将作为拓扑错误生成。 所有重复的点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:只对一个数据集或记录集本身进行检查。
- TopologyRule.POINT_NO_CONTAINED_BY_REGION -- 点不被面包含。检查点数据集(或者点记录集)中被面数据集(或者面记录集)中某一个对象内部包含的点对象。 被面包含的点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:点若位于面边界上,则不违背此规则。
- TopologyRule.LINE_NO_INTERSECTION_WITH_REGION -- 线不能和面相交或被包含。检查线数据集(或者线记录集)中和面数据集(或者面记录集)中的面对象相交或者被面对象包含的线对象。 线面交集部分将作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.REGION_NO_OVERLAP_ON_BOUNDARY -- 面边界无交叠,用于对面数据进行拓扑检查。 检查面数据集或记录集中的面对象的边界与另一面数据集或记录集中的对象边界有交叠的部分。 边界重叠的部分将作为错误生成到结果数据集中,错误数据集类型:线。
- TopologyRule.REGION_NO_SELF_INTERSECTION -- 面内无自相交,用于对面数据进行拓扑检查。 检查面数据中是否存在自相交的对象。 面对象自相交的交点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.LINE_NO_INTERSECTION_WITH -- 线与线无相交,即线对象和线对象不能相交。 检查第一个线数据集(或者线记录集)中没有与第二个线数据集(或者线记录集)中的对象有相交的对象。 交点将作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.VERTEX_DISTANCE_GREATER_THAN_TOLERANCE -- 节点距离必须大于容限。检查点、线、面类型的两个数据集内部或者两个数据集之间对象的节点距离是否小于容限。 不大于容限的节点将作为错误生成到结果数据集中,错误数据集类型:点。 注意:如果两节点重合,即距离为0,则不视为拓扑错误。
- TopologyRule.LINE_EXIST_INTERSECT_VERTEX -- 线段相交处必须存在交点。线、面类型的数据集内部或两个数据集之间,线段与线段十字相交处必须存在节点,且此节点至少存在于两个相交线段中的一个。 如不满足则将此交点计算出来作为错误生成到结果数据集中,错误数据集类型:点。 注意:两条线段端点相接的情况不违反规则。
- TopologyRule.VERTEX_MATCH_WITH_EACH_OTHER -- 节点之间必须互相匹配,即容限范围内线段上存在垂足点。 检查线、面类型数据集内部或两个数据集之间,点数据集和线数据集、点数据集和面数据之间,在当前节点 P 的容限范围内,线段 L 上应存在一个节点 Q 在与之匹配,即 Q 在 P 的容限范围内。如不满足,则计算 P 到 L 的“垂足” A 点(即 A 与 P 匹配)作为错误生成到结果数据集中,错误数据集类型:点。
- TopologyRule.NO_REDUNDANT_VERTEX -- 线或面边界无冗余节点。检查线数据集或面数据集中是否存在有冗余节点的对象。线对象或面对象边界上的两节点之间如果存在其他共线节点,则这些共线节点为冗余节点。 冗余节点将作为错误生成到结果数据集中,错误数据类型:点
- TopologyRule.LINE_NO_SHARP_ANGLE -- 线内无打折。检查线数据集(或记录集)中线对象是否存在打折。若一条线上连续四个节点形成的两个夹角均小于所给的尖角角度容限,则认为线段在此处打折。
产生尖角的第一个折点作为错误生成到结果数据集中,错误数据类型:点。
注意:在使用
topology_validate()方法对该规则检查时,通过该方法的 tolerance 参数设置尖角容 - TopologyRule.LINE_NO_SMALL_DANGLES -- 线内无短悬线,用于对线数据进行拓扑检查。检查线数据集(或记录集)中线对象是否是短悬线。一条悬线的长度小于悬线容限的线对象即为短悬线
短悬线的端点作为错误生成到结果数据集中,错误数据类型:点。
注意:在使用
topology_validate()方法对该规则检查时,通过该方法的 tolerance 参数设置短悬线容限。 - TopologyRule.LINE_NO_EXTENDED_DANGLES -- 线内无长悬线,用于对线数据进行拓扑检查。检查线数据集(或记录集)中线对象是否是长悬线。一条悬线按其行进方向延伸了指定的长度(悬线容限)之后与某弧段有交点,则该线对象为长悬线。
长悬线需要延长一端的端点作为错误生成到结果数据集中,错误数据类型:点。
注意:在使用
topology_validate()方法对该规则检查时,通过该方法的 tolerance 参数设置长悬线容限。 - TopologyRule.REGION_NO_ACUTE_ANGLE -- 面内无锐角,用于对面数据进行拓扑检查。检查面数据集(或记录集)中面对象是否存在锐角。若面边界线上连续三个节点形成的夹角小于所给的锐角角度容限,则认为此夹角为锐角。
产生锐角的第二个节点作为错误生成到结果数据集中,错误数据类型:点。
注意:在使用
topology_validate()方法对该规则检查时,通过该方法的 tolerance 参数设置锐角容限。
-
LINE_BE_COVERED_BY_LINE_CLASS= 16¶
-
LINE_COVERED_BY_REGION_BOUNDARY= 17¶
-
LINE_END_POINT_COVERED_BY_POINT= 18¶
-
LINE_EXIST_INTERSECT_VERTEX= 31¶
-
LINE_NO_DANGLES= 10¶
-
LINE_NO_EXTENDED_DANGLES= 36¶
-
LINE_NO_INTERSECTION= 8¶
-
LINE_NO_INTERSECTION_WITH= 29¶
-
LINE_NO_INTERSECTION_WITH_REGION= 26¶
-
LINE_NO_INTERSECT_OR_INTERIOR_TOUCH= 13¶
-
LINE_NO_OVERLAP= 9¶
-
LINE_NO_OVERLAP_WITH= 12¶
-
LINE_NO_PSEUDO_NODES= 11¶
-
LINE_NO_SELF_INTERSECT= 15¶
-
LINE_NO_SELF_OVERLAP= 14¶
-
LINE_NO_SHARP_ANGLE= 34¶
-
LINE_NO_SMALL_DANGLES= 35¶
-
NO_MULTIPART= 23¶
-
NO_REDUNDANT_VERTEX= 33¶
-
POINT_BECOVERED_BY_LINE_END_POINT= 22¶
-
POINT_CONTAINED_BY_REGION= 21¶
-
POINT_COVERED_BY_LINE= 19¶
-
POINT_COVERED_BY_REGION_BOUNDARY= 20¶
-
POINT_NO_CONTAINED_BY_REGION= 25¶
-
POINT_NO_IDENTICAL= 24¶
-
REGION_BOUNDARY_COVERED_BY_LINE= 5¶
-
REGION_BOUNDARY_COVERED_BY_REGION_BOUNDARY= 6¶
-
REGION_CONTAIN_POINT= 7¶
-
REGION_COVERED_BY_REGION= 4¶
-
REGION_COVERED_BY_REGION_CLASS= 3¶
-
REGION_NO_ACUTE_ANGLE= 37¶
-
REGION_NO_GAPS= 1¶
-
REGION_NO_OVERLAP= 0¶
-
REGION_NO_OVERLAP_ON_BOUNDARY= 27¶
-
REGION_NO_OVERLAP_WITH= 2¶
-
REGION_NO_SELF_INTERSECTION= 28¶
-
VERTEX_DISTANCE_GREATER_THAN_TOLERANCE= 30¶
-
VERTEX_MATCH_WITH_EACH_OTHER= 32¶
-
class
iobjectspy.enums.GeoSpatialRefType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了空间坐标系类型常量。
空间坐标系类型,用以区分平面坐标系、地理坐标系、投影坐标系,其中地理坐标系又称为经纬度坐标系。
变量: - GeoSpatialRefType.SPATIALREF_NONEARTH -- 平面坐标系。当坐标系为平面坐标系时,不能进行投影转换。
- GeoSpatialRefType.SPATIALREF_EARTH_LONGITUDE_LATITUDE -- 地理坐标系。地理坐标系由大地参照系、中央经线、坐标单位组成。在地理坐标系中,单位可以是度,分,秒。东西向(水平方向)的范围为-180度至180度。南北向(垂直方向)的范围为-90度至90度。
- GeoSpatialRefType.SPATIALREF_EARTH_PROJECTION -- 投影坐标系。投影坐标系统由地图投影方式、投影参数、坐标单位和地理坐标系组成。SuperMap Objects Java 中提供了很多预定义的投影系统,用户可以直接使用,此外,用户还可以定制自己的投影系统。
-
SPATIALREF_EARTH_LONGITUDE_LATITUDE= 1¶
-
SPATIALREF_EARTH_PROJECTION= 2¶
-
SPATIALREF_NONEARTH= 0¶
-
class
iobjectspy.enums.GeoCoordSysType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum-
GCS_ADINDAN= 4201¶
-
GCS_AFGOOYE= 4205¶
-
GCS_AGADEZ= 4206¶
-
GCS_AGD_1966= 4202¶
-
GCS_AGD_1984= 4203¶
-
GCS_AIN_EL_ABD_1970= 4204¶
-
GCS_AIRY_1830= 4001¶
-
GCS_AIRY_MOD= 4002¶
-
GCS_ALASKAN_ISLANDS= 37260¶
-
GCS_AMERSFOORT= 4289¶
-
GCS_ANNA_1_1965= 37231¶
-
GCS_ANTIGUA_ISLAND_1943= 37236¶
-
GCS_ARATU= 4208¶
-
GCS_ARC_1950= 4209¶
-
GCS_ARC_1960= 4210¶
-
GCS_ASCENSION_ISLAND_1958= 37237¶
-
GCS_ASTRO_1952= 37214¶
-
GCS_ATF_PARIS= 4901¶
-
GCS_ATS_1977= 4122¶
-
GCS_AUSTRALIAN= 4003¶
-
GCS_AYABELLE= 37208¶
-
GCS_AZORES_CENTRAL_1948= 4183¶
-
GCS_AZORES_OCCIDENTAL_1939= 4182¶
-
GCS_AZORES_ORIENTAL_1940= 4184¶
-
GCS_BARBADOS= 4212¶
-
GCS_BATAVIA= 4211¶
-
GCS_BATAVIA_JAKARTA= 4813¶
-
GCS_BEACON_E_1945= 37212¶
-
GCS_BEDUARAM= 4213¶
-
GCS_BEIJING_1954= 4214¶
-
GCS_BELGE_1950= 4215¶
-
GCS_BELGE_1950_BRUSSELS= 4809¶
-
GCS_BELGE_1972= 4313¶
-
GCS_BELLEVUE= 37215¶
-
GCS_BERMUDA_1957= 4216¶
-
GCS_BERN_1898= 4217¶
-
GCS_BERN_1898_BERN= 4801¶
-
GCS_BERN_1938= 4306¶
-
GCS_BESSEL_1841= 4004¶
-
GCS_BESSEL_MOD= 4005¶
-
GCS_BESSEL_NAMIBIA= 4006¶
-
GCS_BISSAU= 37209¶
-
GCS_BOGOTA= 4218¶
-
GCS_BOGOTA_BOGOTA= 4802¶
-
GCS_BUKIT_RIMPAH= 4219¶
-
GCS_CACANAVERAL= 37239¶
-
GCS_CAMACUPA= 4220¶
-
GCS_CAMPO_INCHAUSPE= 4221¶
-
GCS_CAMP_AREA= 37253¶
-
GCS_CANTON_1966= 37216¶
-
GCS_CAPE= 4222¶
-
GCS_CARTHAGE= 4223¶
-
GCS_CARTHAGE_DEGREE= 37223¶
-
GCS_CHATHAM_ISLAND_1971= 37217¶
-
GCS_CHINA_2000= 37313¶
-
GCS_CHUA= 4224¶
-
GCS_CLARKE_1858= 4007¶
-
GCS_CLARKE_1866= 4008¶
-
GCS_CLARKE_1866_MICH= 4009¶
-
GCS_CLARKE_1880= 4034¶
-
GCS_CLARKE_1880_ARC= 4013¶
-
GCS_CLARKE_1880_BENOIT= 4010¶
-
GCS_CLARKE_1880_IGN= 4011¶
-
GCS_CLARKE_1880_RGS= 4012¶
-
GCS_CLARKE_1880_SGA= 4014¶
-
GCS_CONAKRY_1905= 4315¶
-
GCS_CORREGO_ALEGRE= 4225¶
-
GCS_COTE_D_IVOIRE= 4226¶
-
GCS_DABOLA= 37210¶
-
GCS_DATUM_73= 4274¶
-
GCS_DEALUL_PISCULUI_1933= 4316¶
-
GCS_DEALUL_PISCULUI_1970= 4317¶
-
GCS_DECEPTION_ISLAND= 37254¶
-
GCS_DEIR_EZ_ZOR= 4227¶
-
GCS_DHDNB= 4314¶
-
GCS_DOS_1968= 37218¶
-
GCS_DOS_71_4= 37238¶
-
GCS_DOUALA= 4228¶
-
GCS_EASTER_ISLAND_1967= 37219¶
-
GCS_ED_1950= 4230¶
-
GCS_ED_1987= 4231¶
-
GCS_EGYPT_1907= 4229¶
-
GCS_ETRS_1989= 4258¶
-
GCS_EUROPEAN_1979= 37201¶
-
GCS_EVEREST_1830= 4015¶
-
GCS_EVEREST_BANGLADESH= 37202¶
-
GCS_EVEREST_DEF_1967= 4016¶
-
GCS_EVEREST_DEF_1975= 4017¶
-
GCS_EVEREST_INDIA_NEPAL= 37203¶
-
GCS_EVEREST_MOD= 4018¶
-
GCS_EVEREST_MOD_1969= 37006¶
-
GCS_FAHUD= 4232¶
-
GCS_FISCHER_1960= 37002¶
-
GCS_FISCHER_1968= 37003¶
-
GCS_FISCHER_MOD= 37004¶
-
GCS_FORT_THOMAS_1955= 37240¶
-
GCS_GANDAJIKA_1970= 4233¶
-
GCS_GAN_1970= 37232¶
-
GCS_GAROUA= 4234¶
-
GCS_GDA_1994= 4283¶
-
GCS_GEM_10C= 4031¶
-
GCS_GGRS_1987= 4121¶
-
GCS_GRACIOSA_1948= 37241¶
-
GCS_GREEK= 4120¶
-
GCS_GREEK_ATHENS= 4815¶
-
GCS_GRS_1967= 4036¶
-
GCS_GRS_1980= 4019¶
-
GCS_GUAM_1963= 37220¶
-
GCS_GUNUNG_SEGARA= 37255¶
-
GCS_GUX_1= 37221¶
-
GCS_GUYANE_FRANCAISE= 4235¶
-
GCS_HELMERT_1906= 4020¶
-
GCS_HERAT_NORTH= 4255¶
-
GCS_HITO_XVIII_1963= 4254¶
-
GCS_HJORSEY_1955= 37204¶
-
GCS_HONG_KONG_1963= 37205¶
-
GCS_HOUGH_1960= 37005¶
-
GCS_HUNGARIAN_1972= 4237¶
-
GCS_HU_TZU_SHAN= 4236¶
-
GCS_INDIAN_1954= 4239¶
-
GCS_INDIAN_1960= 37256¶
-
GCS_INDIAN_1975= 4240¶
-
GCS_INDONESIAN= 4021¶
-
GCS_INDONESIAN_1974= 4238¶
-
GCS_INTERNATIONAL_1924= 4022¶
-
GCS_INTERNATIONAL_1967= 4023¶
-
GCS_ISTS_061_1968= 37242¶
-
GCS_ISTS_073_1969= 37233¶
-
GCS_ITRF_1993= 4915¶
-
GCS_JAMAICA_1875= 4241¶
-
GCS_JAMAICA_1969= 4242¶
-
GCS_JAPAN_2000= 37301¶
-
GCS_JOHNSTON_ISLAND_1961= 37222¶
-
GCS_KALIANPUR= 4243¶
-
GCS_KANDAWALA= 4244¶
-
GCS_KERGUELEN_ISLAND_1949= 37234¶
-
GCS_KERTAU= 4245¶
-
GCS_KKJ= 4123¶
-
GCS_KOC_= 4246¶
-
GCS_KRASOVSKY_1940= 4024¶
-
GCS_KUDAMS= 4319¶
-
GCS_KUSAIE_1951= 37259¶
-
GCS_LAKE= 4249¶
-
GCS_LA_CANOA= 4247¶
-
GCS_LC5_1961= 37243¶
-
GCS_LEIGON= 4250¶
-
GCS_LIBERIA_1964= 4251¶
-
GCS_LISBON= 4207¶
-
GCS_LISBON_1890= 4904¶
-
GCS_LISBON_LISBON= 4803¶
-
GCS_LOMA_QUINTANA= 4288¶
-
GCS_LOME= 4252¶
-
GCS_LUZON_1911= 4253¶
-
GCS_MADEIRA_1936= 4185¶
-
GCS_MAHE_1971= 4256¶
-
GCS_MAKASSAR= 4257¶
-
GCS_MAKASSAR_JAKARTA= 4804¶
-
GCS_MALONGO_1987= 4259¶
-
GCS_MANOCA= 4260¶
-
GCS_MASSAWA= 4262¶
-
GCS_MERCHICH= 4261¶
-
GCS_MGI_= 4312¶
-
GCS_MGI_FERRO= 4805¶
-
GCS_MHAST= 4264¶
-
GCS_MIDWAY_1961= 37224¶
-
GCS_MINNA= 4263¶
-
GCS_MONTE_MARIO= 4265¶
-
GCS_MONTE_MARIO_ROME= 4806¶
-
GCS_MONTSERRAT_ISLAND_1958= 37244¶
-
GCS_MPORALOKO= 4266¶
-
GCS_NAD_1927= 4267¶
-
GCS_NAD_1983= 4269¶
-
GCS_NAD_MICH= 4268¶
-
GCS_NAHRWAN_1967= 4270¶
-
GCS_NAPARIMA_1972= 4271¶
-
GCS_NDG_PARIS= 4902¶
-
GCS_NGN= 4318¶
-
GCS_NGO_1948_= 4273¶
-
GCS_NORD_SAHARA_1959= 4307¶
-
GCS_NSWC_9Z_2_= 4276¶
-
GCS_NTF_= 4275¶
-
GCS_NTF_PARIS= 4807¶
-
GCS_NWL_9D= 4025¶
-
GCS_NZGD_1949= 4272¶
-
GCS_OBSERV_METEOR_1939= 37245¶
-
GCS_OLD_HAWAIIAN= 37225¶
-
GCS_OMAN= 37206¶
-
GCS_OSGB_1936= 4277¶
-
GCS_OSGB_1970_SN= 4278¶
-
GCS_OSU_86F= 4032¶
-
GCS_OSU_91A= 4033¶
-
GCS_OS_SN_1980= 4279¶
-
GCS_PADANG_1884= 4280¶
-
GCS_PADANG_1884_JAKARTA= 4808¶
-
GCS_PALESTINE_1923= 4281¶
-
GCS_PICO_DE_LAS_NIEVES= 37246¶
-
GCS_PITCAIRN_1967= 37226¶
-
GCS_PLESSIS_1817= 4027¶
-
GCS_POINT58= 37211¶
-
GCS_POINTE_NOIRE= 4282¶
-
GCS_PORTO_SANTO_1936= 37247¶
-
GCS_PSAD_1956= 4248¶
-
GCS_PUERTO_RICO= 37248¶
-
GCS_PULKOVO_1942= 4284¶
-
GCS_PULKOVO_1995= 4200¶
-
GCS_QATAR= 4285¶
-
GCS_QATAR_1948= 4286¶
-
GCS_QORNOQ= 4287¶
-
GCS_REUNION= 37235¶
-
GCS_RT38_= 4308¶
-
GCS_RT38_STOCKHOLM= 4814¶
-
GCS_S42_HUNGARY= 37257¶
-
GCS_SAD_1969= 4291¶
-
GCS_SAMOA_1962= 37252¶
-
GCS_SANTO_DOS_1965= 37227¶
-
GCS_SAO_BRAZ= 37249¶
-
GCS_SAPPER_HILL_1943= 4292¶
-
GCS_SCHWARZECK= 4293¶
-
GCS_SEGORA= 4294¶
-
GCS_SELVAGEM_GRANDE_1938= 37250¶
-
GCS_SERINDUNG= 4295¶
-
GCS_SPHERE= 4035¶
-
GCS_SPHERE_AI= 37008¶
-
GCS_STRUVE_1860= 4028¶
-
GCS_SUDAN= 4296¶
-
GCS_S_ASIA_SINGAPORE= 37207¶
-
GCS_S_JTSK= 37258¶
-
GCS_TANANARIVE_1925= 4297¶
-
GCS_TANANARIVE_1925_PARIS= 4810¶
-
GCS_TERN_ISLAND_1961= 37213¶
-
GCS_TIMBALAI_1948= 4298¶
-
GCS_TM65= 4299¶
-
GCS_TM75= 4300¶
-
GCS_TOKYO= 4301¶
-
GCS_TRINIDAD_1903= 4302¶
-
GCS_TRISTAN_1968= 37251¶
-
GCS_TRUCIAL_COAST_1948= 4303¶
-
GCS_USER_DEFINE= -1¶
-
GCS_VITI_LEVU_1916= 37228¶
-
GCS_VOIROL_1875= 4304¶
-
GCS_VOIROL_1875_PARIS= 4811¶
-
GCS_VOIROL_UNIFIE_1960= 4305¶
-
GCS_VOIROL_UNIFIE_1960_PARIS= 4812¶
-
GCS_WAKE_ENIWETOK_1960= 37229¶
-
GCS_WAKE_ISLAND_1952= 37230¶
-
GCS_WALBECK= 37007¶
-
GCS_WAR_OFFICE= 4029¶
-
GCS_WGS_1966= 37001¶
-
GCS_WGS_1972= 4322¶
-
GCS_WGS_1972_BE= 4324¶
-
GCS_WGS_1984= 4326¶
-
GCS_XIAN_1980= 37312¶
-
GCS_YACARE= 4309¶
-
GCS_YOFF= 4310¶
-
GCS_ZANDERIJ= 4311¶
-
-
class
iobjectspy.enums.ProjectionType¶ 基类:
iobjectspy._jsuperpy.enums.JEnumAn enumeration.
-
PRJ_ALBERS= 43007¶
-
PRJ_BAIDU_MERCATOR= 43048¶
-
PRJ_BEHRMANN= 43017¶
-
PRJ_BONNE= 43024¶
-
PRJ_BONNE_SOUTH_ORIENTATED= 43046¶
-
PRJ_CASSINI= 43028¶
-
PRJ_CHINA_AZIMUTHAL= 43037¶
-
PRJ_CONFORMAL_AZIMUTHAL= 43034¶
-
PRJ_ECKERT_I= 43015¶
-
PRJ_ECKERT_II= 43014¶
-
PRJ_ECKERT_III= 43013¶
-
PRJ_ECKERT_IV= 43012¶
-
PRJ_ECKERT_V= 43011¶
-
PRJ_ECKERT_VI= 43010¶
-
PRJ_EQUALAREA_CYLINDRICAL= 43041¶
-
PRJ_EQUIDISTANT_AZIMUTHAL= 43032¶
-
PRJ_EQUIDISTANT_CONIC= 43027¶
-
PRJ_EQUIDISTANT_CYLINDRICAL= 43002¶
-
PRJ_GALL_STEREOGRAPHIC= 43016¶
-
PRJ_GAUSS_KRUGER= 43005¶
-
PRJ_GNOMONIC= 43036¶
-
PRJ_HOTINE= 43025¶
-
PRJ_HOTINE_AZIMUTH_NATORIGIN= 43042¶
-
PRJ_HOTINE_OBLIQUE_MERCATOR= 43044¶
-
PRJ_LAMBERT_AZIMUTHAL_EQUAL_AREA= 43033¶
-
PRJ_LAMBERT_CONFORMAL_CONIC= 43020¶
-
PRJ_LOXIMUTHAL= 43023¶
-
PRJ_MERCATOR= 43004¶
-
PRJ_MILLER_CYLINDRICAL= 43003¶
-
PRJ_MOLLWEIDE= 43009¶
-
PRJ_NONPROJECTION= 43000¶
-
PRJ_OBLIQUE_MERCATOR= 43043¶
-
PRJ_OBLIQUE_STEREOGRAPHIC= 43047¶
-
PRJ_ORTHO_GRAPHIC= 43035¶
-
PRJ_PLATE_CARREE= 43001¶
-
PRJ_POLYCONIC= 43021¶
-
PRJ_QUARTIC_AUTHALIC= 43022¶
-
PRJ_RECTIFIED_SKEWED_ORTHOMORPHIC= 43049¶
-
PRJ_ROBINSON= 43030¶
-
PRJ_SANSON= 43040¶
-
PRJ_SINUSOIDAL= 43008¶
-
PRJ_SPHERE_MERCATOR= 43045¶
-
PRJ_STEREOGRAPHIC= 43026¶
-
PRJ_TRANSVERSE_MERCATOR= 43006¶
-
PRJ_TWO_POINT_EQUIDISTANT= 43031¶
-
PRJ_VAN_DER_GRINTEN_I= 43029¶
-
PRJ_WINKEL_I= 43018¶
-
PRJ_WINKEL_II= 43019¶
-
-
class
iobjectspy.enums.GeoPrimeMeridianType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了中央经线类型常量。
变量: - GeoPrimeMeridianType.PRIMEMERIDIAN_USER_DEFINED -- 用户自定义
- GeoPrimeMeridianType.PRIMEMERIDIAN_GREENWICH -- 格林威治本初子午线,即0°经线
- GeoPrimeMeridianType.PRIMEMERIDIAN_LISBON -- 9°07'54".862 W
- GeoPrimeMeridianType.PRIMEMERIDIAN_PARIS -- 2°20'14".025 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_BOGOTA -- 74°04'51".3 W
- GeoPrimeMeridianType.PRIMEMERIDIAN_MADRID -- 3°41'16".58 W
- GeoPrimeMeridianType.PRIMEMERIDIAN_ROME -- 12°27'08".4 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_BERN -- 7°26'22".5 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_JAKARTA -- 106°48'27".79 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_FERRO -- 17°40'00" W
- GeoPrimeMeridianType.PRIMEMERIDIAN_BRUSSELS -- 4°22'04".71 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_STOCKHOLM -- 18°03'29".8 E
- GeoPrimeMeridianType.PRIMEMERIDIAN_ATHENS -- 23°42'58".815 E
-
PRIMEMERIDIAN_ATHENS= 8912¶
-
PRIMEMERIDIAN_BERN= 8907¶
-
PRIMEMERIDIAN_BOGOTA= 8904¶
-
PRIMEMERIDIAN_BRUSSELS= 8910¶
-
PRIMEMERIDIAN_FERRO= 8909¶
-
PRIMEMERIDIAN_GREENWICH= 8901¶
-
PRIMEMERIDIAN_JAKARTA= 8908¶
-
PRIMEMERIDIAN_LISBON= 8902¶
-
PRIMEMERIDIAN_MADRID= 8905¶
-
PRIMEMERIDIAN_PARIS= 8903¶
-
PRIMEMERIDIAN_ROME= 8906¶
-
PRIMEMERIDIAN_STOCKHOLM= 8911¶
-
PRIMEMERIDIAN_USER_DEFINED= -1¶
-
class
iobjectspy.enums.GeoSpheroidType¶ 基类:
iobjectspy._jsuperpy.enums.JEnumAn enumeration.
-
SPHEROID_AIRY_1830= 7001¶
-
SPHEROID_AIRY_MOD= 7002¶
-
SPHEROID_ATS_1977= 7041¶
-
SPHEROID_AUSTRALIAN= 7003¶
-
SPHEROID_BESSEL_1841= 7004¶
-
SPHEROID_BESSEL_MOD= 7005¶
-
SPHEROID_BESSEL_NAMIBIA= 7006¶
-
SPHEROID_CHINA_2000= 7044¶
-
SPHEROID_CLARKE_1858= 7007¶
-
SPHEROID_CLARKE_1866= 7008¶
-
SPHEROID_CLARKE_1866_MICH= 7009¶
-
SPHEROID_CLARKE_1880= 7034¶
-
SPHEROID_CLARKE_1880_ARC= 7013¶
-
SPHEROID_CLARKE_1880_BENOIT= 7010¶
-
SPHEROID_CLARKE_1880_IGN= 7011¶
-
SPHEROID_CLARKE_1880_RGS= 7012¶
-
SPHEROID_CLARKE_1880_SGA= 7014¶
-
SPHEROID_EVEREST_1830= 7015¶
-
SPHEROID_EVEREST_DEF_1967= 7016¶
-
SPHEROID_EVEREST_DEF_1975= 7017¶
-
SPHEROID_EVEREST_MOD= 7018¶
-
SPHEROID_EVEREST_MOD_1969= 40006¶
-
SPHEROID_FISCHER_1960= 40002¶
-
SPHEROID_FISCHER_1968= 40003¶
-
SPHEROID_FISCHER_MOD= 40004¶
-
SPHEROID_GEM_10C= 7031¶
-
SPHEROID_GRS_1967= 7036¶
-
SPHEROID_GRS_1980= 7019¶
-
SPHEROID_HELMERT_1906= 7020¶
-
SPHEROID_HOUGH_1960= 40005¶
-
SPHEROID_INDONESIAN= 7021¶
-
SPHEROID_INTERNATIONAL_1924= 7022¶
-
SPHEROID_INTERNATIONAL_1967= 7023¶
-
SPHEROID_INTERNATIONAL_1975= 40023¶
-
SPHEROID_KRASOVSKY_1940= 7024¶
-
SPHEROID_NWL_10D= 7026¶
-
SPHEROID_NWL_9D= 7025¶
-
SPHEROID_OSU_86F= 7032¶
-
SPHEROID_OSU_91A= 7033¶
-
SPHEROID_PLESSIS_1817= 7027¶
-
SPHEROID_POPULAR_VISUALISATON= 7059¶
-
SPHEROID_SPHERE= 7035¶
-
SPHEROID_SPHERE_AI= 40008¶
-
SPHEROID_STRUVE_1860= 7028¶
-
SPHEROID_USER_DEFINED= -1¶
-
SPHEROID_WALBECK= 40007¶
-
SPHEROID_WAR_OFFICE= 7029¶
-
SPHEROID_WGS_1966= 40001¶
-
SPHEROID_WGS_1972= 7043¶
-
SPHEROID_WGS_1984= 7030¶
-
-
class
iobjectspy.enums.GeoDatumType¶ 基类:
iobjectspy._jsuperpy.enums.JEnumAn enumeration.
-
DATUM_ADINDAN= 6201¶
-
DATUM_AFGOOYE= 6205¶
-
DATUM_AGADEZ= 6206¶
-
DATUM_AGD_1966= 6202¶
-
DATUM_AGD_1984= 6203¶
-
DATUM_AIN_EL_ABD_1970= 6204¶
-
DATUM_AIRY_1830= 6001¶
-
DATUM_AIRY_MOD= 6002¶
-
DATUM_ALASKAN_ISLANDS= 39260¶
-
DATUM_AMERSFOORT= 6289¶
-
DATUM_ANNA_1_1965= 39231¶
-
DATUM_ANTIGUA_ISLAND_1943= 39236¶
-
DATUM_ARATU= 6208¶
-
DATUM_ARC_1950= 6209¶
-
DATUM_ARC_1960= 6210¶
-
DATUM_ASCENSION_ISLAND_1958= 39237¶
-
DATUM_ASTRO_1952= 39214¶
-
DATUM_ATF= 6901¶
-
DATUM_ATS_1977= 6122¶
-
DATUM_AUSTRALIAN= 6003¶
-
DATUM_AYABELLE= 39208¶
-
DATUM_BARBADOS= 6212¶
-
DATUM_BATAVIA= 6211¶
-
DATUM_BEACON_E_1945= 39212¶
-
DATUM_BEDUARAM= 6213¶
-
DATUM_BEIJING_1954= 6214¶
-
DATUM_BELGE_1950= 6215¶
-
DATUM_BELGE_1972= 6313¶
-
DATUM_BELLEVUE= 39215¶
-
DATUM_BERMUDA_1957= 6216¶
-
DATUM_BERN_1898= 6217¶
-
DATUM_BERN_1938= 6306¶
-
DATUM_BESSEL_1841= 6004¶
-
DATUM_BESSEL_MOD= 6005¶
-
DATUM_BESSEL_NAMIBIA= 6006¶
-
DATUM_BISSAU= 39209¶
-
DATUM_BOGOTA= 6218¶
-
DATUM_BUKIT_RIMPAH= 6219¶
-
DATUM_CACANAVERAL= 39239¶
-
DATUM_CAMACUPA= 6220¶
-
DATUM_CAMPO_INCHAUSPE= 6221¶
-
DATUM_CAMP_AREA= 39253¶
-
DATUM_CANTON_1966= 39216¶
-
DATUM_CAPE= 6222¶
-
DATUM_CARTHAGE= 6223¶
-
DATUM_CHATHAM_ISLAND_1971= 39217¶
-
DATUM_CHINA_2000= 39313¶
-
DATUM_CHUA= 6224¶
-
DATUM_CLARKE_1858= 6007¶
-
DATUM_CLARKE_1866= 6008¶
-
DATUM_CLARKE_1866_MICH= 6009¶
-
DATUM_CLARKE_1880= 6034¶
-
DATUM_CLARKE_1880_ARC= 6013¶
-
DATUM_CLARKE_1880_BENOIT= 6010¶
-
DATUM_CLARKE_1880_IGN= 6011¶
-
DATUM_CLARKE_1880_RGS= 6012¶
-
DATUM_CLARKE_1880_SGA= 6014¶
-
DATUM_CONAKRY_1905= 6315¶
-
DATUM_CORREGO_ALEGRE= 6225¶
-
DATUM_COTE_D_IVOIRE= 6226¶
-
DATUM_DABOLA= 39210¶
-
DATUM_DATUM_73= 6274¶
-
DATUM_DEALUL_PISCULUI_1933= 6316¶
-
DATUM_DEALUL_PISCULUI_1970= 6317¶
-
DATUM_DECEPTION_ISLAND= 39254¶
-
DATUM_DEIR_EZ_ZOR= 6227¶
-
DATUM_DHDN= 6314¶
-
DATUM_DOS_1968= 39218¶
-
DATUM_DOS_71_4= 39238¶
-
DATUM_DOUALA= 6228¶
-
DATUM_EASTER_ISLAND_1967= 39219¶
-
DATUM_ED_1950= 6230¶
-
DATUM_ED_1987= 6231¶
-
DATUM_EGYPT_1907= 6229¶
-
DATUM_ETRS_1989= 6258¶
-
DATUM_EUROPEAN_1979= 39201¶
-
DATUM_EVEREST_1830= 6015¶
-
DATUM_EVEREST_BANGLADESH= 39202¶
-
DATUM_EVEREST_DEF_1967= 6016¶
-
DATUM_EVEREST_DEF_1975= 6017¶
-
DATUM_EVEREST_INDIA_NEPAL= 39203¶
-
DATUM_EVEREST_MOD= 6018¶
-
DATUM_EVEREST_MOD_1969= 39006¶
-
DATUM_FAHUD= 6232¶
-
DATUM_FISCHER_1960= 39002¶
-
DATUM_FISCHER_1968= 39003¶
-
DATUM_FISCHER_MOD= 39004¶
-
DATUM_FORT_THOMAS_1955= 39240¶
-
DATUM_GANDAJIKA_1970= 6233¶
-
DATUM_GAN_1970= 39232¶
-
DATUM_GAROUA= 6234¶
-
DATUM_GDA_1994= 6283¶
-
DATUM_GEM_10C= 6031¶
-
DATUM_GGRS_1987= 6121¶
-
DATUM_GRACIOSA_1948= 39241¶
-
DATUM_GREEK= 6120¶
-
DATUM_GRS_1967= 6036¶
-
DATUM_GRS_1980= 6019¶
-
DATUM_GUAM_1963= 39220¶
-
DATUM_GUNUNG_SEGARA= 39255¶
-
DATUM_GUX_1= 39221¶
-
DATUM_GUYANE_FRANCAISE= 6235¶
-
DATUM_HELMERT_1906= 6020¶
-
DATUM_HERAT_NORTH= 6255¶
-
DATUM_HITO_XVIII_1963= 6254¶
-
DATUM_HJORSEY_1955= 39204¶
-
DATUM_HONG_KONG_1963= 39205¶
-
DATUM_HOUGH_1960= 39005¶
-
DATUM_HUNGARIAN_1972= 6237¶
-
DATUM_HU_TZU_SHAN= 6236¶
-
DATUM_INDIAN_1954= 6239¶
-
DATUM_INDIAN_1960= 39256¶
-
DATUM_INDIAN_1975= 6240¶
-
DATUM_INDONESIAN= 6021¶
-
DATUM_INDONESIAN_1974= 6238¶
-
DATUM_INTERNATIONAL_1924= 6022¶
-
DATUM_INTERNATIONAL_1967= 6023¶
-
DATUM_ISTS_061_1968= 39242¶
-
DATUM_ISTS_073_1969= 39233¶
-
DATUM_JAMAICA_1875= 6241¶
-
DATUM_JAMAICA_1969= 6242¶
-
DATUM_JAPAN_2000= 39301¶
-
DATUM_JOHNSTON_ISLAND_1961= 39222¶
-
DATUM_KALIANPUR= 6243¶
-
DATUM_KANDAWALA= 6244¶
-
DATUM_KERGUELEN_ISLAND_1949= 39234¶
-
DATUM_KERTAU= 6245¶
-
DATUM_KKJ= 6123¶
-
DATUM_KOC= 6246¶
-
DATUM_KRASOVSKY_1940= 6024¶
-
DATUM_KUDAMS= 6319¶
-
DATUM_KUSAIE_1951= 39259¶
-
DATUM_LAKE= 6249¶
-
DATUM_LA_CANOA= 6247¶
-
DATUM_LC5_1961= 39243¶
-
DATUM_LEIGON= 6250¶
-
DATUM_LIBERIA_1964= 6251¶
-
DATUM_LISBON= 6207¶
-
DATUM_LOMA_QUINTANA= 6288¶
-
DATUM_LOME= 6252¶
-
DATUM_LUZON_1911= 6253¶
-
DATUM_MAHE_1971= 6256¶
-
DATUM_MAKASSAR= 6257¶
-
DATUM_MALONGO_1987= 6259¶
-
DATUM_MANOCA= 6260¶
-
DATUM_MASSAWA= 6262¶
-
DATUM_MERCHICH= 6261¶
-
DATUM_MGI= 6312¶
-
DATUM_MHAST= 6264¶
-
DATUM_MIDWAY_1961= 39224¶
-
DATUM_MINNA= 6263¶
-
DATUM_MONTE_MARIO= 6265¶
-
DATUM_MONTSERRAT_ISLAND_1958= 39244¶
-
DATUM_MPORALOKO= 6266¶
-
DATUM_NAD_1927= 6267¶
-
DATUM_NAD_1983= 6269¶
-
DATUM_NAD_MICH= 6268¶
-
DATUM_NAHRWAN_1967= 6270¶
-
DATUM_NAPARIMA_1972= 6271¶
-
DATUM_NDG= 6902¶
-
DATUM_NGN= 6318¶
-
DATUM_NGO_1948= 6273¶
-
DATUM_NORD_SAHARA_1959= 6307¶
-
DATUM_NSWC_9Z_2= 6276¶
-
DATUM_NTF= 6275¶
-
DATUM_NWL_9D= 6025¶
-
DATUM_NZGD_1949= 6272¶
-
DATUM_OBSERV_METEOR_1939= 39245¶
-
DATUM_OLD_HAWAIIAN= 39225¶
-
DATUM_OMAN= 39206¶
-
DATUM_OSGB_1936= 6277¶
-
DATUM_OSGB_1970_SN= 6278¶
-
DATUM_OSU_86F= 6032¶
-
DATUM_OSU_91A= 6033¶
-
DATUM_OS_SN_1980= 6279¶
-
DATUM_PADANG_1884= 6280¶
-
DATUM_PALESTINE_1923= 6281¶
-
DATUM_PICO_DE_LAS_NIEVES= 39246¶
-
DATUM_PITCAIRN_1967= 39226¶
-
DATUM_PLESSIS_1817= 6027¶
-
DATUM_POINT58= 39211¶
-
DATUM_POINTE_NOIRE= 6282¶
-
DATUM_POPULAR_VISUALISATION= 6055¶
-
DATUM_PORTO_SANTO_1936= 39247¶
-
DATUM_PSAD_1956= 6248¶
-
DATUM_PUERTO_RICO= 39248¶
-
DATUM_PULKOVO_1942= 6284¶
-
DATUM_PULKOVO_1995= 6200¶
-
DATUM_QATAR= 6285¶
-
DATUM_QATAR_1948= 6286¶
-
DATUM_QORNOQ= 6287¶
-
DATUM_REUNION= 39235¶
-
DATUM_S42_HUNGARY= 39257¶
-
DATUM_SAD_1969= 6291¶
-
DATUM_SAMOA_1962= 39252¶
-
DATUM_SANTO_DOS_1965= 39227¶
-
DATUM_SAO_BRAZ= 39249¶
-
DATUM_SAPPER_HILL_1943= 6292¶
-
DATUM_SCHWARZECK= 6293¶
-
DATUM_SEGORA= 6294¶
-
DATUM_SELVAGEM_GRANDE_1938= 39250¶
-
DATUM_SERINDUNG= 6295¶
-
DATUM_SPHERE= 6035¶
-
DATUM_SPHERE_AI= 39008¶
-
DATUM_STOCKHOLM_1938= 6308¶
-
DATUM_STRUVE_1860= 6028¶
-
DATUM_SUDAN= 6296¶
-
DATUM_S_ASIA_SINGAPORE= 39207¶
-
DATUM_S_JTSK= 39258¶
-
DATUM_TANANARIVE_1925= 6297¶
-
DATUM_TERN_ISLAND_1961= 39213¶
-
DATUM_TIMBALAI_1948= 6298¶
-
DATUM_TM65= 6299¶
-
DATUM_TM75= 6300¶
-
DATUM_TOKYO= 6301¶
-
DATUM_TRINIDAD_1903= 6302¶
-
DATUM_TRISTAN_1968= 39251¶
-
DATUM_TRUCIAL_COAST_1948= 6303¶
-
DATUM_USER_DEFINED= -1¶
-
DATUM_VITI_LEVU_1916= 39228¶
-
DATUM_VOIROL_1875= 6304¶
-
DATUM_VOIROL_UNIFIE_1960= 6305¶
-
DATUM_WAKE_ENIWETOK_1960= 39229¶
-
DATUM_WAKE_ISLAND_1952= 39230¶
-
DATUM_WALBECK= 39007¶
-
DATUM_WAR_OFFICE= 6029¶
-
DATUM_WGS_1966= 39001¶
-
DATUM_WGS_1972= 6322¶
-
DATUM_WGS_1972_BE= 6324¶
-
DATUM_WGS_1984= 6326¶
-
DATUM_XIAN_1980= 39312¶
-
DATUM_YACARE= 6309¶
-
DATUM_YOFF= 6310¶
-
DATUM_ZANDERIJ= 6311¶
-
-
class
iobjectspy.enums.CoordSysTransMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了投影转换方法类型常量。
在投影转换中,如果源投影和目标投影的地理坐标系不同,则需要进行参照系的转换。
参照系的转换有两种,基于网格的转换和基于公式的转换。本类所提供的转换方法均为基于公式的转换。依据转换参数的不同可以分为三参数法和七参数法。目前使 用最广泛的是七参数法。参数信息参见
CoordSysTransParameter;如果源投影和目标投影的地理坐标系相同,用户无需进行参照系的转换,即可以不进行CoordSysTransParameter参数信息的设置。本版本中的 GeocentricTranslation、Molodensky、MolodenskyAbridged 是基于地心的三参数转换 法;PositionVector、CoordinateFrame、BursaWolf都是七参数法。变量: - CoordSysTransMethod.MTH_GEOCENTRIC_TRANSLATION -- 基于地心的三参数转换法
- CoordSysTransMethod.MTH_MOLODENSKY -- 莫洛金斯基(Molodensky)转换法
- CoordSysTransMethod.MTH_MOLODENSKY_ABRIDGED -- 简化的莫洛金斯基转换法
- CoordSysTransMethod.MTH_POSITION_VECTOR -- 位置矢量法
- CoordSysTransMethod.MTH_COORDINATE_FRAME -- 基于地心的七参数转换法
- CoordSysTransMethod.MTH_BURSA_WOLF -- Bursa-Wolf 方法
- CoordSysTransMethod.MolodenskyBadekas -- 莫洛金斯基—巴待卡斯投影转换方法,一种十参数的空间坐标转换模型。
-
MTH_BURSA_WOLF= 42607¶
-
MTH_COORDINATE_FRAME= 9607¶
-
MTH_GEOCENTRIC_TRANSLATION= 9603¶
-
MTH_MOLODENSKY= 9604¶
-
MTH_MOLODENSKY_ABRIDGED= 9605¶
-
MTH_POSITION_VECTOR= 9606¶
-
MolodenskyBadekas= 49607¶
-
class
iobjectspy.enums.StatisticsFieldType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum点抽稀的统计类型,统计的是抽稀点原始点集的值
变量: - StatisticsFieldType.AVERAGE -- 统计平均值
- StatisticsFieldType.SUM -- 统计和
- StatisticsFieldType.MAXVALUE -- 最大值
- StatisticsFieldType.MINVALUE -- 最小值
- StatisticsFieldType.VARIANCE -- 方差
- StatisticsFieldType.SAMPLEVARIANCE -- 样本方差
- StatisticsFieldType.STDDEVIATION -- 标准差
- StatisticsFieldType.SAMPLESTDDEV -- 样本标准差
-
AVERAGE= 1¶
-
MAXVALUE= 3¶
-
MINVALUE= 4¶
-
SAMPLESTDDEV= 8¶
-
SAMPLEVARIANCE= 6¶
-
STDDEVIATION= 7¶
-
SUM= 2¶
-
VARIANCE= 5¶
-
class
iobjectspy.enums.VectorResampleType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum矢量数据集重采样方法类型常量
变量: - VectorResampleType.RTBEND -- 使用光栏采样算法进行重采样
- VectorResampleType.RTGENERAL -- 使用道格拉斯算法进行重采样
-
RTBEND= 1¶
-
RTGENERAL= 2¶
-
class
iobjectspy.enums.ArcAndVertexFilterMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了弧段求交过滤模式常量。
弧段求交用于将线对象在相交处打断,通常是对线数据建立拓扑关系时的首要步骤。
变量: - ArcAndVertexFilterMode.NONE --
不过滤,即在所有交点处打断线对象。该模式下设置过滤线表达式或过滤点数据集均无效。 如下图所示,线对象 A、B、C、D 在它们的相交处分别打断,即 A、B 在它们相交处分别被打断,C 在与 A、D 的相交处被打断。
- ArcAndVertexFilterMode.ARC --
仅由过滤线表达式过滤,即过滤线表达式查询出的线对象不打断。该模式下设置过滤点记录集无效。 如下图所示,线对象 C 是满足过滤线表达式的对象,则线对象 C 整条线不会在任何位置被打断。
- ArcAndVertexFilterMode.VERTEX --
仅由过滤点记录集过滤,即线对象在过滤点所在位置(或与过滤点的距离在容限范围内)处不打断。该模式下设置过滤线表达式无效。 如下图所示,某个过滤点位于线对象 A 和 C 在相交处,则在该处 C 不会被打断,其他相交位置仍会打断。
- ArcAndVertexFilterMode.ARC_AND_VERTEX --
由过滤线表达式和过滤点记录集共同决定哪些位置不打断,二者为且的关系,即只有过滤线表达式查询出的线对象在过滤点位置处(或二者在容限范围内)不打断。 如下图所示,线对象 C 是满足过滤线表达式的对象,A、B 相交处,C、D 相交处分别有一个过滤点,根据该模式规则,过滤线上过滤点所在的位置不会被打断,即 C 在与 D 的相交处不打断。
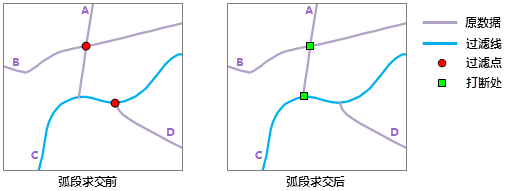
- ArcAndVertexFilterMode.ARC_OR_VERTEX --
过滤线表达式查询出的线对象以及过滤点位置处(或与过滤点距离在容限范围内)的线对象不打断,二者为并的关系。 如下图所示,线对象 C 是满足过滤线表达式的对象,A、B 相交处,C、D 相交处分别有一个过滤点,根据该模式规则,结果如右图所示,C 整体不被打断,A、B 相交处也不打断。
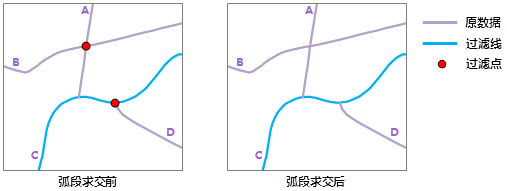
-
ARC= 2¶
-
ARC_AND_VERTEX= 4¶
-
ARC_OR_VERTEX= 5¶
-
NONE= 1¶
-
VERTEX= 3¶
- ArcAndVertexFilterMode.NONE --
-
class
iobjectspy.enums.RasterResampleMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum栅格重采样计算方式的类型常量
变量: - RasterResampleMode.NEAREST -- 最邻近法。最邻近法是将最邻近的栅格值赋予新栅格。该方法的优点是不会改变原始栅格值,简单且处理速度快,但该种方法最大会有半个格子大小的位移。适用于表示分类或某种专题的离散数据,如土地利用,植被类型等。
- RasterResampleMode.BILINEAR -- 双线性内插法。双线性内插使用内插点在输入栅格中的 4 邻域进行加权平均来计算新栅格值,权值根据 4 邻域中每个格子中心距内插点的距离来决定。该种方法的重采样结果会比最邻近法的结果更光滑,但会改变原来的栅格值。适用于表示某种现象分布、地形表面的连续数据,如 DEM、气温、降雨量分布、坡度等,这些数据本来就是通过采样点内插得到的连续表面。
- RasterResampleMode.CUBIC -- 三次卷积内插法。三次卷积内插法较为复杂,与双线性内插相似,同样会改变栅格值,不同之处在于它使用 16 邻域来加权计算,会使计算结果得到一些锐化的效果。该种方法同样会改变原来的栅格值,且有可能会超出输入栅格的值域范围,且计算量大。适用于航片和遥感影像的重采样。
-
BILINEAR= 1¶
-
CUBIC= 2¶
-
NEAREST= 0¶
-
class
iobjectspy.enums.ResamplingMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了创建金字塔类型常量。
变量: - ResamplingMethod.AVERAGE -- 平均值
- ResamplingMethod.NEAR -- 邻近值
-
AVERAGE= 1¶
-
NEAR= 2¶
-
class
iobjectspy.enums.AggregationType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum定义了聚合操作时结果栅格的计算方式类型常量
变量: - AggregationType.SUM -- 一个聚合栅格内包含的所有栅格值之和
- AggregationType.MIN -- 一个聚合栅格内包含的所有栅格值中的最小值
- AggregationType.MAX -- 一个聚合栅格内包含的所有栅格值中的最大值
- AggregationType.AVERRAGE -- 一个聚合栅格内包含的所有栅格值中的平均值
- AggregationType.MEDIAN -- 一个聚合栅格内包含的所有栅格值中的中值
-
AVERRAGE= 3¶
-
MAX= 2¶
-
MEDIAN= 4¶
-
MIN= 1¶
-
SUM= 0¶
-
class
iobjectspy.enums.ReclassPixelFormat¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了栅格数据集的像元值的存储类型常量
变量: - ReclassPixelFormat.BIT32 -- 整型
- ReclassPixelFormat.BIT64 -- 长整型
- ReclassPixelFormat.SINGLE -- 单精度
- ReclassPixelFormat.DOUBLE -- 双精度
-
BIT32= 320¶
-
BIT64= 64¶
-
DOUBLE= 6400¶
-
SINGLE= 3200¶
-
class
iobjectspy.enums.ReclassSegmentType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了重分级区间类型常量。
变量: - ReclassSegmentType.OPENCLOSE -- 左开右闭,如 (number1, number2]。
- ReclassSegmentType.CLOSEOPEN -- 左闭右开,如 [number1, number2)。
-
CLOSEOPEN= 1¶
-
OPENCLOSE= 0¶
-
class
iobjectspy.enums.ReclassType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了栅格重分级类型常量
变量: - ReclassType.UNIQUE -- 单值重分级,即对指定的某些单值进行重新赋值。
- ReclassType.RANGE -- 范围重分级,即将一个区间内的值重新赋值为一个值。
-
RANGE= 2¶
-
UNIQUE= 1¶
-
class
iobjectspy.enums.NeighbourShapeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - NeighbourShapeType.RECTANGLE --
矩形邻域,矩形的大小由指定的宽和高来确定,矩形范围内的单元格参与邻域统计的计算。矩形邻域的默认宽和高均 为 0(单位为地理单位或栅格单位)。
- NeighbourShapeType.CIRCLE --
圆形邻域,圆形邻域的大小根据指定的半径来确定,圆形范围内的所有单元格都参与邻域处理,只要单元格有部分包含在 圆形范围内都将参与邻域统计。圆形邻域的默认半径为 0(单位为地理单位或栅格单位)。
- NeighbourShapeType.ANNULUS --
圆环邻域。环形邻域的大小根据指定的外圆半径和内圆半径来确定,环形区域内的单元格都参与邻域处理。环行邻域的 默认外圆半径和内圆半径均为 0(单位为地理单位或栅格单位)。
- NeighbourShapeType.WEDGE --
扇形邻域。扇形邻域的大小根据指定的圆半径、起始角度和终止角度来确定。在扇形区内的所有单元格都参与邻域处理。 扇形邻域的默认半径为 0(单位为地理单位或栅格单位),起始角度和终止角度的默认值均为 0 度。
-
ANNULUS= 3¶
-
CIRCLE= 2¶
-
RECTANGLE= 1¶
-
WEDGE= 4¶
- NeighbourShapeType.RECTANGLE --
-
class
iobjectspy.enums.SearchMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了内插时使用的样本点的查找方式类型常量。
对于同一种插值方法,样本点的选择方法不同,得到的插值结果也会不同。SuperMap 提供四种插值查找方式,分别为不进行查找,块(QUADTREE) 查找,定长查找(KDTREE_FIXED_RADIUS)和 变长查找(KDTREE_FIXED_COUNT)。
变量: - SearchMode.NONE -- 不进行查找,使用所有的输入点进行内插分析。
- SearchMode.QUADTREE -- 块查找方式,即根据设置的每个块内的点的最多数量对数据集进行分块,使用块内的点进行插值运算。 注意: 目前只对 Kriging、RBF 插值方法起作用,而对 IDW 插值方法不起作用。
- SearchMode.KDTREE_FIXED_RADIUS -- 定长查找方式,即指定半径范围内所有的采样点都参与栅格单元的插值运算。该方式由查找半径(search_radius)和 期望参与运算的最少样点数(expected_count)两个参数来最终确定参与运算的采样点。 当计算某个位置的未知数值时,会以该位置为圆心,以设定的定长值(即查找半径)为半径,落在这个范围内的 采样点都将参与运算;但如果设置了期望参与运算的最少点数,若查找半径范围内的点数达不到该数值,将自动 扩展查找半径直到找到指定的数目的采样点。
- SearchMode.KDTREE_FIXED_COUNT -- 变长查找方式,即距离栅格单元最近的指定数目的采样点参与插值运算。该方式由期望参与运算的最多样 点数(expected_count)和查找半径(search_radius)两个参数来最终确定参与运算的采样点。当计算某 个位置的未知数值时,会查找该位置附近的 N 个采样点,N 值即为设定的固定点数(即期望参与运算的最多样点 数),那么这 N 个采样点都将参与运算;但如果设置了查找半径,若半径范围内的点数少于设置的固定点数,则 范围之外的采样点被舍弃,不参与运算。
-
KDTREE_FIXED_COUNT= 3¶
-
KDTREE_FIXED_RADIUS= 2¶
-
NONE= 0¶
-
QUADTREE= 1¶
-
class
iobjectspy.enums.Exponent¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了泛克吕金(UniversalKriging)插值时样点数据中趋势面方程的阶数的类型常量。样点数据集中样点之间固有的某种趋势,可以通过函数或者多项式的拟合呈现。
变量: - SearchMode.EXP1 -- 阶数为1,表示样点数据集中趋势面呈一阶趋势。
- SearchMode.EXP2 -- 阶数为2,表示样点数据集中趋势面呈二阶趋势。
-
EXP1= 1¶
-
EXP2= 2¶
-
class
iobjectspy.enums.VariogramMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了克吕金(Kriging)插值时的半变函数类型常量。 定义克吕金(Kriging)插值时的半变函数类型。包括指数型、球型和高斯型。用户所选择的半变函 数类型会影响未知点的预测,特别是曲线在原点处的不同形状有重要意义。曲线在原点处越陡,则较近领域对该预测值的影响就越大。因此输出表面就会越不光滑。 每种类型都有各自适用的情况。
变量: - VariogramMode.EXPONENTIAL --
指数函数(Exponential Variogram Mode)。这种类型适用于在空间自相关关系随距离增加成指数递减的情况。 下图所示为空间自相关关系在无穷处完全消失。指数函数较为常用。
- VariogramMode.GAUSSIAN --
高斯函数(Gaussian Variogram Mode)。
- VariogramMode.SPHERICAL --
球型函数(Spherical Variogram Mode)。这种类型显示了空间自相关关系逐渐减少的情况下(即半变函数值逐渐 增加),直到超出一定的距离,空间自相关关系为0。球型函数较为常用。
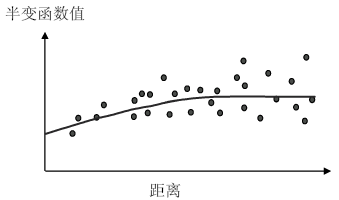
-
EXPONENTIAL= 0¶
-
GAUSSIAN= 1¶
-
SPHERICAL= 9¶
- VariogramMode.EXPONENTIAL --
-
class
iobjectspy.enums.ComputeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了距离栅格最短路径分析的计算方式类型常量
变量: - ComputeType.CELL --
像元路径,目标对象对应的每一个栅格单元都生成一条最短路径。如下图所示,红色点作为源,黑线框多边形作为目标,采用该方式 进行栅格最短路径分析,得到蓝色单元格表示的最短路径。
- ComputeType.ZONE --
区域路径,每个目标对象对应的栅格区域都只生成一条最短路径。如下图所示,红色点作为源,黑线框多边形作为目标,采用该方 式进行栅格最短路径分析,得到蓝色单元格表示的最短路径。
- ComputeType.ALL --
单一路径,所有目标对象对应的单元格只生成一条最短路径,即对于整个目标区域数据集来说所有路径中最短的那一条。如下图所示, 红色点作为源,黑线框多边形作为目标,采用该方式进行栅格最短路径分析,得到蓝色单元格表示的最短路径。
-
ALL= 2¶
-
CELL= 0¶
-
ZONE= 1¶
- ComputeType.CELL --
-
class
iobjectspy.enums.SmoothMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了光滑方法类型常量。用于从 Grid 或 DEM 数据生成等值线或等值面时对等值线或者等值面的边界线进行平滑。
等值线的生成是通过对原栅格数据进行插值,然后连接等值点得到,所以得到的结果是棱角分明的折线,等值面的生成是通过对原栅格数据进行插值,然后连接等值 点得到等值线,再由相邻等值线封闭组成的,所以得到的结果是棱角分明的多边形面,这两者均需要进行一定的光滑处理,SuperMap 提供两种光滑处理的方法, B 样条法和磨角法。
变量: - SmoothMethod.NONE -- 不进行光滑。
- SmoothMethod.BSPLINE --
B 样条法。B 样条法是以一条通过折线中一些节点的 B 样条曲线代替原始折线来达到光滑的目的。B 样条曲线是贝塞尔曲线 的一种扩展。如下图所示,B 样条曲线不必通过原线对象的所有节点。除经过的原折线上的一些点外,曲线上的其他点通过 B 样条函数拟合得出。
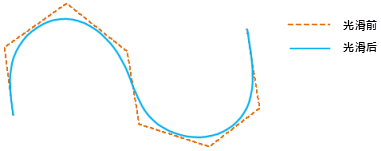
对非闭合的线对象使用 B 样条法后,其两端点的相对位置保持不变。
- SmoothMethod.POLISH --
磨角法。磨角法是一种运算相对简单,处理速度比较快的光滑方法,但是效果比较局限。它的主要过程是将折线上的两条相邻的 线段,分别在距离夹角顶点三分之一线段长度处添加节点,将夹角两侧新添加的两节点相连,从而将原线段的节点磨平,故称 磨角法。下图为进行一次磨角法的过程示意图。
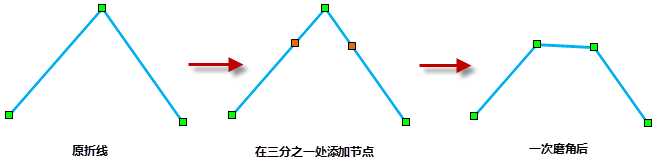
可以多次磨角以得到接近光滑的线。对非闭合的线对象使用磨角法后,其两端点的相对位置保持不变。
-
BSPLINE= 0¶
-
NONE= -1¶
-
POLISH= 1¶
-
class
iobjectspy.enums.ShadowMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了晕渲图渲染方式类型常量。
变量: - ShadowMode.IllUMINATION_AND_SHADOW -- 渲染和阴影。同时考虑当地的光照角以及阴影的作用。
- ShadowMode.SHADOW -- 阴影。只考虑区域是否位于阴影中。
- ShadowMode.IllUMINATION -- 渲染。只考虑当地的光照角。
-
IllUMINATION= 3¶
-
IllUMINATION_AND_SHADOW= 1¶
-
SHADOW= 2¶
-
class
iobjectspy.enums.SlopeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了坡度的单位类型常量。
变量: - SlopeType.DEGREE -- 以角度为单位来表示坡度。
- SlopeType.RADIAN -- 以弧度为单位来表示坡度。
- SlopeType.PERCENT -- 以百分数来表示坡度。 该百分数为垂直高度和水平距离的比值乘以100,即单位水平距离上的高度值乘以100, 或者说是坡度的正切值乘以100。
-
DEGREE= 1¶
-
PERCENT= 3¶
-
RADIAN= 2¶
-
class
iobjectspy.enums.NeighbourUnitType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了邻域分析的单位类型常量。
变量: - NeighbourUnitType.CELL -- 栅格坐标,即使用栅格数作为邻域单位。
- NeighbourUnitType.MAP -- 地理坐标,即使用地图的长度单位作为邻域单位。
-
CELL= 1¶
-
MAP= 2¶
-
class
iobjectspy.enums.InterpolationAlgorithmType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了插值分析所支持的算法的类型常量。
对于一个区域,如果只有部分离散点数据已知,要想创建或者模拟一个表面或者场,需要对未知点的值进行估计,通常采用的是内插表面的方法。SuperMap 中提供 三种内插方法,用于模拟或者创建一个表面,分别是:距离反比权重法(IDW)、克吕金插值方法(Kriging)、径向基函数插值法(RBF)。选用何种方法进行内 插,通常取决于样点数据的分布和要创建表面的类型。
变量: - InterpolationAlgorithmType.IDW -- 距离反比权值(Inverse Distance Weighted)插值法。该方法通过计算附近区域离散点群的平均值来估算 单元格的值,生成栅格数据集。这是一种简单有效的数据内插方法,运算速度相对较快。距离离散中心越近的点,其估算值越受影响。
- InterpolationAlgorithmType.SIMPLEKRIGING -- 简单克吕金(Simple Kriging)插值法。简单克吕金是常用的克吕金插值方法之一,该方法假 定用于插值的字段值的期望(平均值)已知的某一常数。
- InterpolationAlgorithmType.KRIGING -- 普通克吕金(Kriging)插值法。最常用的克吕金插值方法之一。该方法假定用于插值的字段值的期望(平 均值)未知且恒定。它利用一定的数学函数,通过对给定的空间点进行拟合来估算单元格的值,生 成格网数据集。它不仅可以生成一个表面,还可以给出预测结果的精度或者确定性的度量。因此,此方法计 算精度较高,常用于社会科学及地质学。
- InterpolationAlgorithmType.UNIVERSALKRIGING -- 泛克吕金(Universal Kriging)插值法。泛克吕金也是常用的克吕金插值方法之一,该 方法假定用于插值的字段值的期望(平均值)未知的变量。在样点数据中存在某种主导趋势,并且该趋势可以通过某一个确定 的函数或者多项式进行拟合的情况下适用泛克吕金插值法。
- InterpolationAlgorithmType.RBF --
径向基函数(Radial Basis Function)插值法。该方法假设变化是平滑的,它有两个特点:
- 表面必须精确通过数据点;
- 表面必须有最小曲率。
该插值在创建有视觉要求的曲线和等高线方面有优势。
- InterpolationAlgorithmType.DENSITY -- 点密度(Density)插值法
-
DENSITY= 9¶
-
IDW= 0¶
-
KRIGING= 2¶
-
RBF= 6¶
-
SIMPLEKRIGING= 1¶
-
UNIVERSALKRIGING= 3¶
-
class
iobjectspy.enums.GriddingLevel¶ 基类:
iobjectspy._jsuperpy.enums.JEnum对于几何面对象的查询(GeometriesRelation),通过设置面对象的格网化,可以加快判断速度,比如面包含点判断。 单个面对象的格网化 等级越高,所需的内存也越多,一般适用于面对象少但单个面对象比较大的情形。
变量: - GriddingLevel.NONE -- 无格网化
- GriddingLevel.LOWER -- 低等级格网化,对每个面使用 32*32 个方格进行格网化
- GriddingLevel.MIDDLE -- 中等级格网化,对每个面使用 64*64 个方格进行格网化
- GriddingLevel.NORMAL -- 一般等级格网化,对每个面使用 128*128 个方格进行格网化
- GriddingLevel.HIGHER -- 高等级格网化,对每个面使用 256*256 个方格进行格网化
-
HIGHER= 4¶
-
LOWER= 1¶
-
MIDDLE= 2¶
-
NONE= 0¶
-
NORMAL= 3¶
-
class
iobjectspy.enums.RegionToPointMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum面转点的方式
变量: - RegionToPointMode.VERTEX -- 节点模式,将面对象的每个节点都转换为一个点对象
- RegionToPointMode.INNER_POINT -- 内点模式,将面对象的内点转换为一个点对象
- RegionToPointMode.SUB_INNER_POINT -- 子对象内点模式,将面对象的每个子对象的内点分别转换为一个点对象
- RegionToPointMode.TOPO_INNER_POINT -- 拓扑内点模式,对复杂面对象进行保护性分解后得到的多个面对象的内点,分别转换为一个子对象。
-
INNER_POINT= 2¶
-
SUB_INNER_POINT= 3¶
-
TOPO_INNER_POINT= 4¶
-
VERTEX= 1¶
-
class
iobjectspy.enums.LineToPointMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum线转点的方式
变量: - LineToPointMode.VERTEX -- 节点模式,将线对象的每个节点都转换为一个点对象
- LineToPointMode.INNER_POINT -- 内点模式,将线对象的内点转换为一个点对象
- LineToPointMode.SUB_INNER_POINT -- 子对象内点模式,将线对象的每个子对象的内点分别转换为一个点对象,如果线的子对象数目为1,将与 INNER_POINT 的结果相同。
- LineToPointMode.START_NODE -- 起始点模式,将线对象的第一个节点,即起点,转换为一个点对象
- LineToPointMode.END_NODE -- 终止点模式,将线对象的最后一个节点,即终点,转换为一个点对象
- LineToPointMode.START_END_NODE -- 起始终止点模式,将线对象的起点和终点分别转换为一个点对象
- LineToPointMode.SEGMENT_INNER_POINT -- 线段内点模式,将线对象的每个线段的内点,分别转换为一个点对象,线段指的是相邻两个节点构成的线。
- LineToPointMode.SUB_START_NODE -- 子对象起始点模式,将线对象的每个子对象的第一个点,分别转换为一个点对象
- LineToPointMode.SUB_END_NODE -- 子对象终止点模式,将线对象的每个子对象的对后一个点,分别转换为一个点对象
- LineToPointMode.SUB_START_END_NODE -- 子对象起始终止点模式,将线对象的每个子对象的第一个点和最后一个点,分别转换为一个点对象。
-
END_NODE= 5¶
-
INNER_POINT= 2¶
-
SEGMENT_INNER_POINT= 7¶
-
START_END_NODE= 6¶
-
START_NODE= 4¶
-
SUB_END_NODE= 9¶
-
SUB_INNER_POINT= 3¶
-
SUB_START_END_NODE= 10¶
-
SUB_START_NODE= 8¶
-
VERTEX= 1¶
-
class
iobjectspy.enums.EllipseSize¶ 基类:
iobjectspy._jsuperpy.enums.JEnum输出椭圆的大小常量
变量: - EllipseSize.SINGLE --
一个标准差。输出椭圆的长半轴和短半轴是对应的标准差的一倍。当几何对象具有空间正态分布时,即这些几 何对象在中心处集中而朝向外围时较少,则生成的椭圆将会包含约占总数68%的几何对象在内。

- EllipseSize.TWICE --
二个标准差。输出椭圆的长半轴和短半轴是对应的标准差的二倍。当几何对象具有空间正态分布时,即这些几 何对象在中心处集中而朝向外围时较少,则生成的椭圆将会包含约占总数95%的几何对象在内。
- EllipseSize.TRIPLE --
三个标准差。输出椭圆的长半轴和短半轴是对应的标准差的三倍。当几何对象具有空间正态分布时,即这些几 何对象在中心处集中而朝向外围时较少,则生成的椭圆将会包含约占总数99%的几何对象在内。
-
SINGLE= 1¶
-
TRIPLE= 3¶
-
TWICE= 2¶
- EllipseSize.SINGLE --
-
class
iobjectspy.enums.SpatialStatisticsType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum数据集进行空间度量后的字段统计类型常量
变量: - SpatialStatisticsType.MAX -- 统计字段的最大值。只对数值型字段有效。
- SpatialStatisticsType.MIN -- 统计字段的最小值。只对数值型字段有效。
- SpatialStatisticsType.SUM -- 统计字段的和。只对数值型字段有效。
- SpatialStatisticsType.MEAN -- 统计字段的平均值。只对数值型字段有效。
- SpatialStatisticsType.FIRST -- 保留第一个对象的字段值。对数值、布尔、时间和文本型字段都有效。
- SpatialStatisticsType.LAST -- 保留最后一个对象的字段值。对数值、布尔、时间和文本型字段都有效。
- SpatialStatisticsType.MEDIAN -- 统计字段的中位数。只对数值型字段有效。
-
FIRST= 5¶
-
LAST= 6¶
-
MAX= 1¶
-
MEAN= 4¶
-
MEDIAN= 7¶
-
MIN= 2¶
-
SUM= 3¶
-
class
iobjectspy.enums.DistanceMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum距离计算方法常量
变量: - DistanceMethod.EUCLIDEAN --
欧式距离。计算两点间的直线距离。
DistanceMethod_EUCLIDEAN.png
- DistanceMethod.MANHATTAN --
曼哈顿距离。计算两点的x和y坐标的差值绝对值求和。该类型暂时不可用,仅作为测试,使用结果未知。
DistanceMethod_MANHATTAN.png
-
EUCLIDEAN= 1¶
-
MANHATTAN= 2¶
- DistanceMethod.EUCLIDEAN --
-
class
iobjectspy.enums.KernelFunction¶ 基类:
iobjectspy._jsuperpy.enums.JEnum地理加权回归分析核函数类型常量。
变量: - KernelFunction.GAUSSIAN --
高斯核函数。
高斯核函数计算公式:
W_ij=e^(-((d_ij/b)^2)/2)。
其中W_ij为点i和点j之间的权重,d_ij为点i和点j之间的距离,b为带宽范围。
- KernelFunction.BISQUARE --
二次核函数。 二次核函数计算公式:
如果d_ij≤b, W_ij=(1-(d_ij/b)^2))^2;否则,W_ij=0。
其中W_ij为点i和点j之间的权重,d_ij为点i和点j之间的距离,b为带宽范围。
- KernelFunction.BOXCAR --
盒状核函数。
盒状核函数计算公式:
如果d_ij≤b, W_ij=1;否则,W_ij=0。
其中W_ij为点i和点j之间的权重,d_ij为点i和点j之间的距离,b为带宽范围。
- KernelFunction.TRICUBE --
立方体核函数。
立方体核函数计算公式:
如果d_ij≤b, W_ij=(1-(d_ij/b)^3))^3;否则,W_ij=0。
其中W_ij为点i和点j之间的权重,d_ij为点i和点j之间的距离,b为带宽范围。
-
BISQUARE= 2¶
-
BOXCAR= 3¶
-
GAUSSIAN= 1¶
-
TRICUBE= 4¶
- KernelFunction.GAUSSIAN --
-
class
iobjectspy.enums.KernelType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum地理加权回归分析带宽类型常量
变量: - KernelType.FIXED -- 固定型带宽。针对每个回归分析点,使用一个固定的值作为带宽范围。
- KernelType.ADAPTIVE -- 可变型带宽。针对每个回归分析点,使用回归点与第K个最近相邻点之间的距离作为带宽范围。其中,K为相邻数目。
-
ADAPTIVE= 2¶
-
FIXED= 1¶
-
class
iobjectspy.enums.BandWidthType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum地理加权回归分析带宽确定方式常量。
变量: - BandWidthType.AICC -- 使用" Akaike 信息准则(AICc)"确定带宽范围。
- BandWidthType.CV -- 使用"交叉验证"确定带宽范围。
- BandWidthType.BANDWIDTH -- 根据给定的固定距离或固定相邻数确定带宽范围。
-
AICC= 1¶
-
BANDWIDTH= 3¶
-
CV= 2¶
-
class
iobjectspy.enums.AggregationMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum用于通过事件点创建数据集进行分析的聚合方法常量
变量: - AggregationMethod.NETWORKPOLYGONS -- 计算合适的网格大小,创建网格面数据集,生成的网格面数据集以面网格单元的点计数将作
为分析字段执行热点分析。网格会覆盖在输入事件点的上方,并将计算每个面网格单元内的
点数目。如果未提供事件点发生区域的边界面数据(参阅
optimized_hot_spot_analyst()的 bounding_polygons 参数), 则会利用输入事件点数据集范围划分网格,并且会删除不含点的面网格单元,仅会分析剩下的 面网格单元;如果提供了边界面数据,则只会保留并分析在边界面数据集范围内的面网格单元。 - AggregationMethod.AGGREGATIONPOLYGONS -- 需要提供聚合事件点以获得事件计数的面数据集(参阅 参阅
optimized_hot_spot_analyst()的 aggregating_polygons 参数), 将计算每个面对象内的点事件数目,然后对面数据集以点事件数目作为分析字段执行热点分析。 - AggregationMethod.SNAPNEARBYPOINTS -- 为输入事件点数据集计算捕捉距离并使用该距离聚合附近的事件点,为每个聚合点提供一个 点计数,代表聚合到一起的事件点数目,然后对生成聚合点数据集以聚合在一起的点事件数 目作为分析字段执行热点分析
-
AGGREGATIONPOLYGONS= 2¶
-
NETWORKPOLYGONS= 1¶
-
SNAPNEARBYPOINTS= 3¶
- AggregationMethod.NETWORKPOLYGONS -- 计算合适的网格大小,创建网格面数据集,生成的网格面数据集以面网格单元的点计数将作
为分析字段执行热点分析。网格会覆盖在输入事件点的上方,并将计算每个面网格单元内的
点数目。如果未提供事件点发生区域的边界面数据(参阅
-
class
iobjectspy.enums.StreamOrderType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum流域水系编号(即河流分级)方法类型常量
变量: - StreamOrderType.STRAHLER --
Strahler 河流分级法。Strahler 河流分级法由 Strahler 于 1957 年提出。其规则定义为:直接发 源于河源的河流为 1 级河流;同级的两条河流交汇形成的河流的等级比原来增加 1 级;不同等级的两 条河流交汇形成的河流的级等于原来河流中级等较高者。
- StreamOrderType.SHREVE --
Shreve 河流分级法。Shreve 河流分级法由 Shreve 于 1966 年提出。其规则定义为:直接发源于河源 的河流等级为 1 级,两条河流交汇形成的河流的等级为两条河流等级的和。例如,两条 1 级河流交汇形 成 2 级河流,一条 2 级河流和一条 3 级河流交汇形成一条 5 级河流。
-
SHREVE= 2¶
-
STRAHLER= 1¶
- StreamOrderType.STRAHLER --
-
class
iobjectspy.enums.TerrainInterpolateType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum地形插值类型常量
变量: - TerrainInterpolateType.IDW -- 距离反比权值插值法。参考
InterpolationAlgorithmType.IDW - TerrainInterpolateType.KRIGING -- 克吕金内插法。参考
InterpolationAlgorithmType.KRIGING - TerrainInterpolateType.TIN -- 不规则三角网。先将给定的线数据集生成一个TIN模型,然后根据给定的极值点信息以及湖信息生成DEM模型。
-
IDW= 1¶
-
KRIGING= 2¶
-
TIN= 3¶
- TerrainInterpolateType.IDW -- 距离反比权值插值法。参考
-
class
iobjectspy.enums.TerrainStatisticType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum地形统计类型常量
变量: - TerrainStatisticType.UNIQUE -- 去重复点统计。
- TerrainStatisticType.MEAN -- 平均数统计。
- TerrainStatisticType.MIN -- 最小值统计。
- TerrainStatisticType.MAX -- 最大值统计。
- TerrainStatisticType.MAJORITY -- 众数指的是出现频率最高的栅格值。目前只用于栅格分带统计。
- TerrainStatisticType.MEDIAN -- 中位数指的是按栅格值从小到大排列,位于中间位置的栅格值。目前只用于栅格分带统计。
-
MAJORITY= 5¶
-
MAX= 4¶
-
MEAN= 2¶
-
MEDIAN= 6¶
-
MIN= 3¶
-
UNIQUE= 1¶
-
class
iobjectspy.enums.EdgeMatchMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该枚举定义了图幅接边的方式常量。
变量: - EdgeMatchMode.THEOTHEREDGE -- 向一边接边。接边连接点为接边目标数据集中发生接边关联的记录的端点,源数据集中接边关联到的记录的端点将移动到该连接点。
- EdgeMatchMode.THEMIDPOINT -- 在中点位置接边。 接边连接点为接边目标数据集和源数据集中发生接边关联记录端点的中点,源和目标数据集中发生接边关联的记录的端点将移动到该连接点。
- EdgeMatchMode.THEINTERSECTION -- 在交点位置接边。接边连接点为接边目标数据集和源数据集中发生接边关联记录端点的连线和接边线的交点,源和目标数据集中发生接边关联的记录的端点将移动到该连接点。
-
THEINTERSECTION= 3¶
-
THEMIDPOINT= 2¶
-
THEOTHEREDGE= 1¶
-
class
iobjectspy.enums.FunctionType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变换函数类型常量
变量: - FunctionType.NONE -- 不使用变换函数。
- FunctionType.LOG -- 变换函数为log,要求原值大于0。
- FunctionType.ARCSIN -- 变换函数为 arcsin,要求原值在范围[-1,1]内。
-
ARCSIN= 3¶
-
LOG= 2¶
-
NONE= 1¶
-
class
iobjectspy.enums.StatisticsCompareType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum比较类型常量
变量: - StatisticsCompareType.LESS -- 小于。
- StatisticsCompareType.LESS_OR_EQUAL -- 小于或等于。
- StatisticsCompareType.EQUAL -- 等于。
- StatisticsCompareType.GREATER -- 大于。
- StatisticsCompareType.GREATER_OR_EQUAL -- 大于或等于。
-
EQUAL= 3¶
-
GREATER= 4¶
-
GREATER_OR_EQUAL= 5¶
-
LESS= 1¶
-
LESS_OR_EQUAL= 2¶
-
class
iobjectspy.enums.GridStatisticsMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum栅格统计类型常量
变量: - GridStatisticsMode.MIN -- 最小值
- GridStatisticsMode.MAX -- 最大值
- GridStatisticsMode.MEAN -- 平均值
- GridStatisticsMode.STDEV -- 标准差
- GridStatisticsMode.SUM -- 总和
- GridStatisticsMode.VARIETY -- 种类
- GridStatisticsMode.RANGE -- 值域,即最大值与最小值的差
- GridStatisticsMode.MAJORITY -- 众数(出现频率最高的栅格值)
- GridStatisticsMode.MINORITY -- 最少数(出现频率最低的栅格值)
- GridStatisticsMode.MEDIAN -- 中位数(将所有栅格的值从小到大排列,取位于中间位置的栅格值)
-
MAJORITY= 8¶
-
MAX= 2¶
-
MEAN= 3¶
-
MEDIAN= 10¶
-
MIN= 1¶
-
MINORITY= 9¶
-
RANGE= 7¶
-
STDEV= 4¶
-
SUM= 5¶
-
VARIETY= 6¶
-
class
iobjectspy.enums.ConceptualizationModel¶ 基类:
iobjectspy._jsuperpy.enums.JEnum空间关系概念化模型常量
变量: - ConceptualizationModel.INVERSEDISTANCE -- 反距离模型。任何要素都会影响目标要素,但是随着距离的增加,影响会越小。要素之间的权重为距离分之一。
- ConceptualizationModel.INVERSEDISTANCESQUARED -- 反距离平方模型。与"反距离模型"相似,随着距离的增加,影响下降的更快。要素之间的权重为距离的平方分之一。
- ConceptualizationModel.FIXEDDISTANCEBAND -- 固定距离模型。在指定的固定距离范围内的要素具有相等的权重(权重为1),在指定的固定距离范围之外的要素不会影响计算(权重为0)。
- ConceptualizationModel.ZONEOFINDIFFERENCE -- 无差别区域模型。 该模型是"反距离模型"和"固定距离模型"的结合。在指定的固定距离范围内的要素具有相等的权重(权重为1);在指定的固定距离范围之外的要素,随着距离的增加,影响会越小。
- ConceptualizationModel.CONTIGUITYEDGESONLY -- 面邻接模型。只有面面在有共享边界、重叠、包含、被包含的情况才会影响目标要素(权重为1),否则,将会排除在目标要素计算之外(权重为0)。
- ConceptualizationModel.CONTIGUITYEDGESNODE -- 面邻接模型。只有面面在有接触的情况才会影响目标要素(权重为1),否则,将会排除在目标要素计算之外(权重为0)。
- ConceptualizationModel.KNEARESTNEIGHBORS -- K最邻近模型。 距目标要素最近的K个要素包含在目标要素的计算中(权重为1),其余的要素将会排除在目标要素计算之外(权重为0)。
- ConceptualizationModel.SPATIALWEIGHTMATRIXFILE -- 提供空间权重矩阵文件。
-
CONTIGUITYEDGESNODE= 6¶
-
CONTIGUITYEDGESONLY= 5¶
-
FIXEDDISTANCEBAND= 3¶
-
INVERSEDISTANCE= 1¶
-
INVERSEDISTANCESQUARED= 2¶
-
KNEARESTNEIGHBORS= 7¶
-
SPATIALWEIGHTMATRIXFILE= 8¶
-
ZONEOFINDIFFERENCE= 4¶
-
class
iobjectspy.enums.AttributeStatisticsMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum在进行点连接成线时和矢量数据集属性更新时,进行属性统计的模式。
变量: - AttributeStatisticsMode.MAX -- 统计最大值,可以对数值型、文本型和时间类型的字段进行统计。
- AttributeStatisticsMode.MIN -- 统计最小值,可以对数值型、文本型和时间类型的字段进行统计。
- AttributeStatisticsMode.SUM -- 统计一组数的和,只对数值型字段有效
- AttributeStatisticsMode.MEAN -- 统计一组数的平均值,只对数值型字段有效
- AttributeStatisticsMode.STDEV -- 统计一组数的标准差,只对数值型字段有效
- AttributeStatisticsMode.VAR -- 统计一组数的方差,只对数值型字段有效
- AttributeStatisticsMode.MODALVALUE -- 取众数,众数是出现频率最高的的值,可以是任何类型字段
- AttributeStatisticsMode.RECORDCOUNT -- 统计一组数的记录数。统计记录数不针对特定的字段,只针对一个分组。
- AttributeStatisticsMode.MAXINTERSECTAREA -- 取相交面积最大。如果面对象与提供属性的多个面对象相交,则取与原面对象相交面积最大的对象属性值用于更新。对任意类型的字段有效。
只对矢量数据集属性更新(
update_attributes())有效
-
COUNT= 8¶
-
MAX= 1¶
-
MAXINTERSECTAREA= 9¶
-
MEAN= 4¶
-
MIN= 2¶
-
MODALVALUE= 7¶
-
STDEV= 5¶
-
SUM= 3¶
-
VAR= 6¶
-
class
iobjectspy.enums.VCTVersion¶ 基类:
iobjectspy._jsuperpy.enums.JEnumVCT 版本
变量: - VCTVersion.CNSDTF_VCT -- 国家自然标准 1.0
- VCTVersion.LANDUSE_VCT -- 国家土地利用 2.0
- VCTVersion.LANDUSE_VCT30 -- 国家土地利用 3.0
-
CNSDTF_VCT= 1¶
-
LANDUSE_VCT= 3¶
-
LANDUSE_VCT30= 6¶
-
class
iobjectspy.enums.RasterJoinType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum定义了镶嵌结果栅格值的统计类型常量。
变量: - RasterJoinType.RJMFIRST -- 栅格重叠区域镶嵌后取第一个栅格数据集中的值。
- RasterJoinType.RJMLAST -- 栅格重叠区域镶嵌后取最后一个栅格数据集中的值。
- RasterJoinType.RJMMAX -- 栅格重叠区域镶嵌后取所有栅格数据集中相应位置的最大值。
- RasterJoinType.RJMMIN -- 栅格重叠区域镶嵌后取所有栅格数据集中相应位置的最小值。
- RasterJoinType.RJMMean -- 栅格重叠区域镶嵌后取所有栅格数据集中相应位置的平均值。
-
RJMFIRST= 0¶
-
RJMLAST= 1¶
-
RJMMAX= 2¶
-
RJMMIN= 3¶
-
RJMMean= 4¶
-
class
iobjectspy.enums.RasterJoinPixelFormat¶ 基类:
iobjectspy._jsuperpy.enums.JEnum定义了镶嵌结果像素格式类型常量。
变量: - RasterJoinPixelFormat.RJPMONO -- 即 PixelFormat.UBIT1。
- RasterJoinPixelFormat.RJPFBIT -- 即 PixelFormat.UBIT4
- RasterJoinPixelFormat.RJPBYTE -- 即 PixelFormat.UBIT8
- RasterJoinPixelFormat.RJPTBYTE -- 即 PixelFormat.BIT16
- RasterJoinPixelFormat.RJPRGB -- 即 PixelFormat.RGB
- RasterJoinPixelFormat.RJPRGBAFBIT -- 即 PixelFormat.RGBA
- RasterJoinPixelFormat.RJPLONGLONG -- 即 PixelFormat.BIT64
- RasterJoinPixelFormat.RJPLONG -- 即 PixelFormat.BIT32
- RasterJoinPixelFormat.RJPFLOAT -- 即 PixelFormat.SINGLE
- RasterJoinPixelFormat.RJPDOUBLE -- 即 PixelFormat.DOUBLE
- RasterJoinPixelFormat.RJPFIRST -- 参与镶嵌的第一个栅格数据集的像素格式。
- RasterJoinPixelFormat.RJPLAST -- 参与镶嵌的最后一个栅格数据集的像素格式。
- RasterJoinPixelFormat.RJPMAX -- 参与镶嵌的栅格数据集中最大的像素格式。
- RasterJoinPixelFormat.RJPMIN -- 参与镶嵌的栅格数据集中最小的像素格式。
- RasterJoinPixelFormat.RJPMAJORITY -- 参与镶嵌的栅格数据集中出现频率最高的像素格式,如果像素格式出现的频率相同,取索引值最小的。
-
RJPBYTE= 8¶
-
RJPDOUBLE= 6400¶
-
RJPFBIT= 4¶
-
RJPFIRST= 10000¶
-
RJPFLOAT= 3200¶
-
RJPLAST= 20000¶
-
RJPLONG= 320¶
-
RJPLONGLONG= 64¶
-
RJPMAJORITY= 50000¶
-
RJPMAX= 30000¶
-
RJPMIN= 40000¶
-
RJPMONO= 1¶
-
RJPRGB= 24¶
-
RJPRGBAFBIT= 32¶
-
RJPTBYTE= 16¶
-
class
iobjectspy.enums.PlaneType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum平面类型常量 :var PlaneType.PLANEXY:由X、Y坐标方向构成的平面,即XY平面 :var PlaneType.PLANEYZ:由X、Z坐标方向构成的平面,即YZ平面 :var PlaneType.PLANEXZ:由Y、Z坐标方向构成的平面,即XZ平面
-
PLANEXY= 0¶
-
PLANEXZ= 2¶
-
PLANEYZ= 1¶
-
-
class
iobjectspy.enums.ChamferStyle¶ 基类:
iobjectspy._jsuperpy.enums.JEnum放样的倒角样式类型常量 :var ChamferStyle.SOBC_CIRCLE_ARC:二阶贝塞尔曲线(the second order bezier curve)圆弧 :var ChamferStyle.SOBC_ELLIPSE_ARC:二阶贝塞尔曲线(the second order bezier curve)椭圆弧
-
SOBC_CIRCLE_ARC= 0¶
-
SOBC_ELLIPSE_ARC= 1¶
-
-
class
iobjectspy.enums.ViewShedType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了对多个观察点(被观察点)进行可视域分析时,可视域的类型常量。 :var ViewShedType.VIEWSHEDINTERSECT: 共同可视域,取多个观察点可视域范围的交集。 :var ViewShedType.VIEWSHEDUNION: 非共同可视域,取多个观察点可视域范围的并集。
-
VIEWSHEDINTERSECT= 0¶
-
VIEWSHEDUNION= 1¶
-
-
class
iobjectspy.enums.ImageType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了地图出图的图片类型常量
变量: - ImageType.BMP -- BMP 是 Windows 使用的一种标准格式,用于存储设备无关和应用程序无关的图像。一个给定 BMP 文件的每像素位数值(1、4、8、15、24、32 或 64)在文件头中指定。每像素 24 位的 BMP 文件是通用的。BMP 文件通常是不压缩的,因此,不太适合通过 Internet 传输。
- ImageType.GIF -- GIF 是一种用于在网页中显示图像的通用格式。GIF 文件适用于画线、有纯色块的图片和在颜色之间有清晰边界的图片。GIF 文件是压缩的,但是在压缩过程中没有信息丢失;解压缩的图像与原始图像完全一样。GIF 文件中的一种颜色可以被指定为透明,这样,图像将具有显示它的任何网页的背景色。在单个文件中存储一系列 GIF 图像可以形成一个动画 GIF。GIF 文件每像素最多能存储 8 位,所以它们只限于使用 256 种颜色。
- ImageType.JPG -- JPEG 是一种适应于自然景观(如扫描的照片)的压缩方案。一些信息会在压缩过程中丢失,但是这些丢失人眼是察觉不到的。JPEG 文件每像素存储 24 位,因此它们能够显示超过 16,000,000 种颜色。JPEG 文件不支持透明或动画。JPEG 不是一种文件格式。“JPEG 文件交换格式 (JFIF)”是一种文件格式,常用于存储和传输已根据 JPEG 方案压缩的图像。Web 浏览器显示的 JFIF 文件使用 .jpg 扩展名。
- ImageType.PDF -- PDF(Portable Document Format) 文件格式是 Adobe 公司开发的电子文件格式。这种文件格式与操作系统平台无关,也就是说,PDF 文件不管是在 Windows,Unix 还是在苹果公司的 Macos 操作系统中都是通用的
- ImageType.PNG -- PNG 类型。PNG 格式不但保留了许多 GIF 格式的优点,还提供了超出 GIF 的功能。像 GIF 文件一样,PNG 文件在压缩时也不损失信息。PNG 文件能以每像素 8、24 或 48 位来存储颜色,并以每像素 1、2、4、8 或 16 位来存储灰度。相比之下,GIF 文件只能使用每像素 1、2、4 或 8 位。PNG 文件还可为每个像素存储一个 alpha 值,该值指定了该像素颜色与背景颜色混合的程度。PNG 优于 GIF 之处在于,它能渐进地显示一幅图像(也就是说,在图像通过网络连接传递的过程中,显示的图像将越来越完整)。PNG 文件可包含灰度校正和颜色校正信息,以便图像可在各种各样的显示设备上精确地呈现。
- ImageType.TIFF -- TIFF 是一种灵活的和可扩展的格式,各种各样的平台和图像处理应用程序都支持这种格式。TIFF 文件能以每像素任意位来存储图像,并可以使用各种各样的压缩算法。单个的多页 TIFF 文件可以存储数幅图像。可以把与图像相关的信息(扫描仪制造商、主机、压缩类型、打印方向和每像素采样,等等)存储在文件中并使用标签来排列这些信息。可以根据需要通过批准和添加新标签来扩展 TIFF 格式。
-
BMP= 121¶
-
GIF= 124¶
-
JPG= 122¶
-
PDF= 33¶
-
PNG= 123¶
-
TIFF= 103¶
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
class
iobjectspy.enums.FillGradientMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum定义渐变填充模式的渐变模式。所有渐变模式都是两种颜色之间的渐变,即从渐变起始色到渐变终止色之间的渐变。
对于不同的渐变模式风格,可以在
GeoStyle中对其旋转角度,渐变的起始色(前景色)和终止色(背景色),渐变填充中心点的位置(对线性渐变无效)等进行设置。默认情况下,渐变旋转角度为0,渐变填充中心点为填充区域范围的中心点。以下对各种渐变模式的说明都采用默认的渐变旋转角度和中心点。 关于渐变填充旋转的详细信息,请参见GeoStyle类中的set_fill_gradient_angle()方法; 关于渐变填充中心点的设置,请参见GeoStyle类中的set_fill_gradient_offset_ratio_x()和set_fill_gradient_offset_ratio_y()方法。 渐变风格的计算都是以填充区域的边界矩形,即最小外接矩形作为基础的,因而以下提到的填充区域范围即为填充区域的最小外接矩形。变量: - FillGradientMode.NONE -- 无渐变。当使用普通填充模式时,设置渐变模式为无渐变
- FillGradientMode.LINEAR --
线性渐变。从水平线段的起始点到终止点的渐变。如图所示,从水平线段的起始点到终止点,其颜色从起始色均匀渐变到终止色,垂直于该线段的直线上颜色相同,不发生渐变
- FillGradientMode.RADIAL --
辐射渐变。 以填充区域范围的中心点作为渐变填充的起始点,距离中心点最远的边界点作为终止点的圆形渐变。注意在同一个圆周上颜色不发生变化,不同的圆之间颜色发生渐变。 如图所示,从渐变填充的起始点到终止点,其以起始点为圆心的各个圆的颜色随着圆的半径的增大从起始色均匀渐变到终止色
- FillGradientMode.CONICAL --
- 圆锥渐变。从起始母线到终止母线,渐变在逆时针和顺时针两个方向发生渐变,都是从起始色渐变到终止色。注意填充区域范围中心点为圆锥的顶点,在圆锥的母线上颜色不发生变化。
- 如图所示,渐变的起始母线在填充区域范围中心点右侧的并经过该中心点的水平线上,上半圆锥颜色按逆时针发生渐变,下半圆锥按顺时针发生渐变,两个方向渐变的起始母线和终止母线分别相同,在逆时针方向和顺时针方向两个方向从起始母线转到终止母线的过程中,渐变都是从起始色均匀渐变到终止色
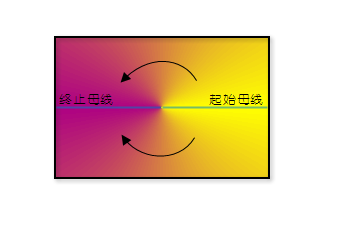
- FillGradientMode.SQUARE --
四角渐变。以填充区域范围的中心点作为渐变填充的起始点,以填充区域范围的最小外接矩形的较短边的中点为终止点的正方形渐变。注意在每个正方形上的颜色不发生变化, 不同的正方形之间颜色发生变化。 如图所示,从渐变填充的起始点到终止点,其以起始点为中心的正方形的颜色随着边长的增大从起始色均匀渐变到终止色
-
CONICAL= 3¶
-
LINEAR= 1¶
-
NONE= 0¶
-
RADIAL= 2¶
-
SQUARE= 4¶
-
class
iobjectspy.enums.ColorSpaceType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了色彩空间类型常量。
由于成色原理的不同,决定了显示器、投影仪这类靠色光直接合成颜色的颜色设备和打印机、印刷机这类靠使用颜料的印刷设备在生成颜色方式上的区别。针对上述不同成色方式,针对上述不同成色方式,SuperMap提供 7 种色彩空间,分别为 RGB、CMYK、RGBA、CMY、YIQ、YUV 和 YCC,可以适用于不同的系统之中。
变量: - ColorSpaceType.RGB -- 该类型主要在显示系统中使用。RGB 是红色,绿色,蓝色的缩写。RGB 色彩模式使用 RGB 模型为图像中每一个像素的 RGB 分量分配一个0~255范围内的强度值
- ColorSpaceType.CMYK -- 该类型主要在印刷系统使用。CMYK 分别为青色,洋红,黄,黑。它通过调整青色、品红、黄色三种基本色的浓度混合出各种颜色的颜料,利用黑色调节明度和纯度。
- ColorSpaceType.RGBA -- 该类型主要在显示系统中使用。RGB 是红色,绿色,蓝色的缩写,A则用来控制透明度。
- ColorSpaceType.CMY -- 该类型主要在印刷系统使用。CMY(Cyan,Magenta,Yellow)分别为青色,品红,黄。该类型通过调整青色、品红、黄色三种基本色的浓度混合出各种颜色的颜料。
- ColorSpaceType.YIQ -- 该类型主要用于北美电视系统(NTSC).
- ColorSpaceType.YUV -- 该类型主要用于欧洲电视系统(PAL).
- ColorSpaceType.YCC -- 该类型主要用于 JPEG 图像格式。
- ColorSpaceType.UNKNOW -- 未知
-
CMY= 3¶
-
CMYK= 4¶
-
RGB= 1¶
-
RGBA= 2¶
-
UNKNOW= 0¶
-
YCC= 7¶
-
YIQ= 5¶
-
YUV= 6¶
-
class
iobjectspy.enums.ImageInterpolationMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了影像插值模式常量。
变量: - ImageInterpolationMode.NEARESTNEIGHBOR -- 最临近插值模式。
- ImageInterpolationMode.LOW -- 低质量插值模式。
- ImageInterpolationMode.HIGH -- 高质量插值模式。
- ImageInterpolationMode.DEFAULT -- 默认插值模式。
- ImageInterpolationMode.HIGHQUALITYBICUBIC -- 高质量的双线性插值模式。
- ImageInterpolationMode.HIGHQUALITYBILINEAR -- 最高质量的双三次插值法模式。
-
DEFAULT= 3¶
-
HIGH= 2¶
-
HIGHQUALITYBICUBIC= 5¶
-
HIGHQUALITYBILINEAR= 4¶
-
LOW= 1¶
-
NEARESTNEIGHBOR= 0¶
-
class
iobjectspy.enums.ImageDisplayMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum影像显示模式,目前支持组合模式和拉伸模式两种。
变量: - ImageDisplayMode.COMPOSITE -- 组合模式。 组合模式针对多波段影像,影像按照设置的波段索引顺序组合为RGB显示,目前只支持RGB和RGBA色彩空间的显示。
- ImageDisplayMode.STRETCHED -- 拉伸模式。拉伸模式支持所有影像(包括单波段和多波段),针对多波段影像,当设置了该显示模式后,将显示设置的波段索引的第一个波段去显示。
-
COMPOSITE= 0¶
-
STRETCHED= 1¶
-
class
iobjectspy.enums.MapColorMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了地图颜色模式类型常量。
该颜色模式只是针对地图显示而言,而且只对矢量要素起作用。 各颜色模式在转换时,地图的专题风格不会改变,而且各种颜色模式的转换是根据 地图的专题风格颜色来的。 SuperMap 组件产品在设置地图风格时,提供了5种颜色模式。
变量: - MapColorMode.DEFAULT -- 默认彩色模式,对应 32 位增强真彩色模式。用 32 个比特来存储颜色,其中红,绿,蓝和 alpha 各用 8 比特来表示。
- MapColorMode.BLACK_WHITE -- 黑白模式。根据地图的专题风格(默认彩色模式),将地图要素用两种颜色显示:黑色和白色。 专题风格颜色为白色的要素仍显示成白色,其余颜色都以黑色显示。
- MapColorMode.GRAY -- 灰度模式。根据地图的专题风格(默认彩色模式),对红,绿,蓝分量设置不同的权重,以灰度显示出来。
- MapColorMode.BLACK_WHITE_REVERSE -- 黑白反色模式。根据地图的专题风格(默认彩色模式),专题风格颜色为黑色的要素转换成白色,其余颜色都以黑色显示
- MapColorMode.ONLY_BLACK_WHITE_REVERSE -- 黑白反色,其它颜色不变。根据地图的专题风格(默认彩色模式),把专题风格颜色为黑色的要素 转换成白色,专题风格颜色为白色的要素转换成黑色,其它颜色不变。
-
BLACK_WHITE= 1¶
-
BLACK_WHITE_REVERSE= 3¶
-
DEFAULT= 0¶
-
GRAY= 2¶
-
ONLY_BLACK_WHITE_REVERSE= 4¶
-
class
iobjectspy.enums.LayerGridAggregationType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum网格聚合图的格网类型。
变量: - LayerGridAggregationType.QUADRANGLE -- 矩形格网
- LayerGridAggregationType.HEXAGON -- 六边形格网
-
HEXAGON= 2¶
-
QUADRANGLE= 1¶
-
class
iobjectspy.enums.NeighbourNumber¶ 基类:
iobjectspy._jsuperpy.enums.JEnum空间连通性的邻域像元个数
变量: - NeighbourNumber.FOUR --
上下左右4个像元作为邻近像元。仅当具有相同值的像元与上下左右四个最邻近像元中的每个像元直接连接时,才 会定义这些像元之间的连通性。正交像元会保留矩形区域的拐角。

- NeighbourNumber.EIGHT --
相邻8个像元作为邻近像元。仅当具有相同值的像元位于彼此最近的8个最邻近像元时,才会定义这些像元间的连 通性。八个相邻像元使矩形变得光滑。

-
EIGHT= 2¶
-
FOUR= 1¶
- NeighbourNumber.FOUR --
-
class
iobjectspy.enums.MajorityDefinition¶ 基类:
iobjectspy._jsuperpy.enums.JEnum在进行替换之前指定必须具有相同值的相邻(空间连接)像元数,即相邻像元的相同值在连续为多少时,才进行替换。
变量: - MajorityDefinition.HALF -- 表示半数像元必须具有相同值并且相邻,即大于等于四分之二或八分之四的已连接像元必须具有相同值,此时 可获得更平滑的效果。
- MajorityDefinition.MAJORITY -- 表示多数像元必须具有相同值并且相邻,即大于等于四分之三或八分之五的已连接像元必须具有相同值。
-
HALF= 1¶
-
MAJORITY= 2¶
-
class
iobjectspy.enums.BoundaryCleanSortType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum边界清理的排序方法。即指定要在平滑处理中使用的排序类型。这将确定像元可扩展到相邻像元的优先级
变量: - BoundaryCleanSortType.NOSORT -- 不按大小排序。值较大的区域具有较高的优先级,可以扩展到值较小的若干区域。
- BoundaryCleanSortType.DESCEND -- 以大小的降序顺序对区域进行排序。总面积较大的区域具有较高的优先级,可以扩展到总面积较小的 若干区域。
- BoundaryCleanSortType.ASCEND -- 以大小的升序顺序对区域进行排序。总面积较小的区域具有较高的优先级,可以扩展到总面积较大的 若干区域。
-
ASCEND= 3¶
-
DESCEND= 2¶
-
NOSORT= 1¶
-
class
iobjectspy.enums.OverlayAnalystOutputType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum叠加分析返回结果几何对象类型。只对面面相交算子有效。
变量: - OverlayAnalystOutputType.INPUT -- 结果对象类型与输入的源数据类型保持一致
- OverlayAnalystOutputType.POINT -- 结果对象类型为点对象
-
INPUT= 0¶
-
POINT= 1¶
-
class
iobjectspy.enums.FieldSign¶ 基类:
iobjectspy._jsuperpy.enums.JEnum字段标识常量
变量: - FieldSign.ID -- ID 字段
- FieldSign.GEOMETRY -- Geometry 字段
- FieldSign.NODEID -- NodeID 字段
- FieldSign.FNODE -- FNode 字段
- FieldSign.TNODE -- TNode 字段
- FieldSign.EDGEID -- EdgeID 字段
-
EDGEID= 4¶
-
FNODE= 2¶
-
GEOMETRY= 12¶
-
ID= 11¶
-
NODEID= 1¶
-
TNODE= 3¶
-
class
iobjectspy.enums.PyramidResampleType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum建立影像金字塔时所采用的重采样方式。
变量: - PyramidResampleType.NONE -- 不进行重采样
- PyramidResampleType.NEAREST -- 最临近法,一种简单的采样方式
- PyramidResampleType.AVERAGE -- 平均值法,计算所有有效值的均值进行重采样计算。
- PyramidResampleType.GAUSS -- 使用高斯内核计算的方式进行重采样,这种对于高对比度和图案边界比较明显的图像效果比较好。
- PyramidResampleType.AVERAGE_MAGPHASE -- 平均联合数据法,在一个 magphase 空间中平均联合数据,用于复数数据空间的图像的重采样方式。
-
AVERAGE= 2¶
-
AVERAGE_MAGPHASE= 4¶
-
GAUSS= 3¶
-
NEAREST= 1¶
-
NONE= 0¶
-
class
iobjectspy.enums.DividePolygonType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum切割面对象的类型。具体参考 :py:fun:`.divide_polygon`
变量: - DividePolygonType.AREA -- 按面积大小切割多边形
- DividePolygonType.PART -- 等比切割多边形
-
AREA= 1¶
-
PART= 2¶
-
class
iobjectspy.enums.DividePolygonOrientation¶ 基类:
iobjectspy._jsuperpy.enums.JEnum切割面多边形时,起始切割方位,即切割后结果面对象中一个切割面的位置。具体参考 :py:fun:`.divide_polygon`
变量: - DividePolygonOrientation.WEST -- 切割面位置为西
- DividePolygonOrientation.NORTH -- 切割面位置为北
- DividePolygonOrientation.EAST -- 切割面位置为东
- DividePolygonOrientation.SOUTH -- 切割面位置为南
-
EAST= 3¶
-
NORTH= 2¶
-
SOUTH= 4¶
-
WEST= 1¶
-
class
iobjectspy.enums.RegularizeMethod¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - RegularizeMethod.RIGHTANGLES -- 直角
- RegularizeMethod.RIGHTANGLESANDDIAGONALS -- 直角和对角
- RegularizeMethod.ANYANGLE -- 任意角
- RegularizeMethod.CIRCLE -- 圆
-
ANYANGLE= 3¶
-
CIRCLE= 4¶
-
RIGHTANGLES= 1¶
-
RIGHTANGLESANDDIAGONALS= 2¶
-
class
iobjectspy.enums.OverlayOutputAttributeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum多图层叠加分析字段属性返回类型
变量: - OverlayOutputAttributeType.ALL -- 返回所有的非系统字段和对象的ID,SmUserID 也不返回。
- OverlayOutputAttributeType.ONLYID -- 仅返回对象的 ID
- OverlayOutputAttributeType.ONLYATTRIBUTES -- 仅返回对象的非系统字段,且 SmUserID 字段不返回
-
ALL= 0¶
-
ONLYATTRIBUTES= 2¶
-
ONLYID= 1¶
-
class
iobjectspy.enums.TimeDistanceUnit¶ 基类:
iobjectspy._jsuperpy.enums.JEnum时间距离单位
变量: - TimeDistanceUnit.SECONDS -- 秒
- TimeDistanceUnit.MINUTES -- 分
- TimeDistanceUnit.HOURS -- 小时
- TimeDistanceUnit.DAYS -- 天
- TimeDistanceUnit.WEEKS -- 周
- TimeDistanceUnit.MONTHS -- 月
- TimeDistanceUnit.YEARS -- 年
-
DAYS= 5¶
-
HOURS= 4¶
-
MINUTES= 3¶
-
MONTHS= 7¶
-
SECONDS= 2¶
-
WEEKS= 6¶
-
YEARS= 8¶
-
class
iobjectspy.enums.GJBLayerType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum变量: - GJBLayerType.GJB_A -- 测量控制点
- GJBLayerType.GJB_B -- 工农业社会文化设施
- GJBLayerType.GJB_C -- 居民地及附属设置
- GJBLayerType.GJB_D -- 陆地交通
- GJBLayerType.GJB_E -- 管线
- GJBLayerType.GJB_F -- 水域、陆地
- GJBLayerType.GJB_G -- 海底地貌及底质
- GJBLayerType.GJB_H -- 礁石、沉船、障碍物
- GJBLayerType.GJB_I -- 水文
- GJBLayerType.GJB_J -- 陆地地貌及土质
- GJBLayerType.GJB_K -- 境界与政区
- GJBLayerType.GJB_L -- 植被
- GJBLayerType.GJB_M -- 地磁要素
- GJBLayerType.GJB_N -- 助航设备及航道
- GJBLayerType.GJB_O -- 海上区域界线
- GJBLayerType.GJB_P -- 航空要素
- GJBLayerType.GJB_Q -- 军事区域
- GJBLayerType.GJB_R -- 注记
- GJBLayerType.GJB_S -- 元数据
-
GJB_A= 1¶
-
GJB_B= 2¶
-
GJB_C= 3¶
-
GJB_D= 4¶
-
GJB_E= 5¶
-
GJB_F= 6¶
-
GJB_G= 7¶
-
GJB_H= 8¶
-
GJB_I= 9¶
-
GJB_J= 10¶
-
GJB_K= 11¶
-
GJB_L= 12¶
-
GJB_M= 13¶
-
GJB_N= 14¶
-
GJB_O= 15¶
-
GJB_P= 16¶
-
GJB_Q= 17¶
-
GJB_R= 18¶
-
GJB_S= 19¶
iobjectspy.env module¶
-
iobjectspy.env.is_auto_close_output_datasource()¶ 是否自动关闭结果数据源对象。在处理数据或分析时,设置的结果数据源信息如果是程序自动打开的(即当前工作空间下不存在此数据源),默认情形下程序在 完成单个功能后会自动关闭。用户可以通过设置
set_auto_close_output_datasource()使结果数据源不被自动关闭,这样,结果数据源将存在于当前的工作空间中。返回类型: bool
-
iobjectspy.env.set_auto_close_output_datasource(auto_close)¶ 设置是否关闭结果数据源对象。在处理数据或分析时,设置的结果数据源信息如果是程序自动打开的(不是用户调用打开数据源接口打开,即当前工作空间下不存在此数据源),默认情形下程序在 完成单个功能后会自动关闭。用户可以通过此接口设置 auto_close 为 False 使结果数据源不被自动关闭,这样,结果数据源将存在于当前的工作空间中。
参数: auto_close (bool) -- 是否自动关闭程序内部打开的数据源对象。
-
iobjectspy.env.is_use_analyst_memory_mode()¶ 空间分析是否使用内存模式
返回类型: bool
-
iobjectspy.env.set_analyst_memory_mode(is_use_memory)¶ 设置空间分析是否启用内存模式。
参数: is_use_memory (bool) -- 启用内存模式设置 True , 否则设置为 False
-
iobjectspy.env.get_omp_num_threads()¶ 获取并行计算所使用的线程数
返回类型: int
-
iobjectspy.env.set_omp_num_threads(num_threads)¶ 设置并行计算所使用的线程数
参数: num_threads (int) -- 并行计算所使用的线程数
-
iobjectspy.env.set_iobjects_java_path(bin_path, is_copy_jars=True)¶ 设置 iObjects Java 组件 Bin 目录地址。设置的 Bin 目录地址会保存到 env.json 文件中。
参数: - bin_path (str) -- iObjects Java 组件 Bin 目录地址
- is_copy_jars (bool) -- 是否同时拷贝 iObjects Java 组件的 jars 到 iObjectsPy 目录。
-
iobjectspy.env.get_iobjects_java_path()¶ 获取设置的 iObjects Java 组件 Bin 目录地址。只能获取到主动设置或保存到 env.json 文件中的目录地址。默认值为 None。
返回类型: str
-
iobjectspy.env.get_show_features_count()¶ 获取打印矢量数据集时显示的记录数目。
返回类型: int
-
iobjectspy.env.set_show_features_count(features_count)¶ 设置打印矢量数据集时显示的记录数目
>>> set_show_features_count(100) >>> dt = open_datasource('/iobjectspy/example_data.udbx')['zone'] >>> print(dt)
参数: features_count (int) -- 打印矢量数据集时显示的记录数目
iobjectspy.mapping module¶
-
class
iobjectspy.mapping.Map¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase地图类,负责地图显示环境的管理。
地图是对地理数据的可视化,通常由一个或多个图层组成。地图必须与一个工作空间相关联,以便来显示该工作空间中的数据。另外,对地图的显 示方式的设置将对其中的所有图层起作用。该类提供了对地图的各种显示方式的返回和设置,如地图的显示范围,比例尺,坐标系统以及文本、点 等图层的默认显示方式等,并提供了对地图进行的相关操作的方法,如地图的打开与关闭,缩放、全幅显示,以及地图的输出等。
-
add_aggregation(dataset, min_color=None, max_color=None)¶ 根据给定的点数据集制作一幅默认风格的网格聚合图。
参数: - dataset (DatasetVector) -- 参与制作网格聚合图的数据,该数据必须为点矢量数据集。
- min_color (Color or tuple[int,int,int]) -- 网格单元统计值最小值对应的颜色,网格聚合图将通过maxColor和minColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
- max_color (Color or tuple[int,int,int]) -- 网格单元统计值最大值对应的颜色,网格聚合图将通过maxColor和minColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
返回: 网格聚合图图层对象。
返回类型:
-
add_dataset(dataset, is_add_to_head=True, layer_setting=None)¶ 添加数据集到地图中
参数: - dataset (Dataset or DatasetVector or DatasetImage or DatasetGrid) -- 被添加的数据集对象
- is_add_to_head (bool) -- 是否添加到地图的最上层
- layer_setting (LayerSetting or Theme) -- 地图图层设置对象或专题图图层对象
返回: 添加成功返回图层对象,否则返回 None
返回类型:
-
add_heatmap(dataset, kernel_radius, max_color=None, min_color=None)¶ 根据给定的点数据集和参数设置制作一幅热力图,也就是将给定的点数据以热力图的渲染方式进行显示。 热力图是通过颜色分布,描述诸如人群分布、密度和变化趋势等的一种地图表现手法,因此,能够非常直观地呈现一些原本不易理解或表达的数据,比如密度、频度、温度等。 热力图图层除了可以反映点要素的相对密度,还可以表示根据属性进行加权的点密度,以此考虑点本身的权重对于密度的贡献。
参数: - dataset (DatasetVector) -- 参与制作热力图的数据,该数据必须为点矢量数据集。
- kernel_radius (int) -- 用于计算密度的查找半径。
- max_color (Color or tuple[int,int,int]) -- 低点密度的颜色。热力图图层将通过高点密度颜色(maxColor)和低点密度颜色(minColor)确定渐变的颜色方案。
- min_color (Color or tuple[int,int,int]) -- 高点密度的颜色。热力图图层将通过高点密度颜色(maxColor)和低点密度颜色(minColor)确定渐变的颜色方案。
返回: 热力图图层对象
返回类型:
-
add_to_tracking_layer(geos, style=None, is_antialias=False, is_symbol_scalable=False, symbol_scale=None)¶ 添加几何对象到跟踪图层
参数: 返回: 当前地图对象的跟踪图层对象
返回类型:
-
close()¶ 关闭当前地图。
-
find_layer(layer_name)¶ 返回指定的图层名称的图层对象。
参数: layer_name (str) -- 指定的图层名称。 返回: 返回指定的图层名称的图层对象。 返回类型: Layer
-
from_xml(xml, workspace_version=None)¶ 根据指定的 XML 字符串创建地图对象。 任何地图都可以导出成 xml 字符串,而地图的 xml 字符串也可以导入成为一个地图来显示。地图的 xml 字符串中存储了关于地图及其图 层的显示设置以及关联的数据信息等。
参数: - xml (str) -- 用来创建地图的 xml 字符串。
- workspace_version (WorkspaceVersion or str) -- xml 内容所对应的工作空间的版本。使用该参数时,请确保指定的版本与 xml 内容相符。若不相符,可能会导致部分图层的风格丢失。
返回: 若地图对象创建成功,返回 true,否则返回 false。
返回类型: bool
-
get_angle()¶ 返回当前地图的旋转角度。单位为度,精度到 0.1 度。逆时针方向为正方向,如果用户输入负值,地图则以顺时针方向旋转。
返回: 当前地图的旋转角度。 返回类型: float
-
get_bounds()¶ 返回当前地图的空间范围。地图的空间范围是其所显示的各数据集的范围的最小外接矩形,即包含各数据集范围的最小的矩形。当地图显示的数据集增加或删除时,其空间范围也会相应发生变化。
返回: 当前地图的空间范围。 返回类型: Rectangle
-
get_color_mode()¶ 返回当前地图的颜色模式。地图的颜色模式包括彩色模式,黑白模式,灰度模式以及黑白反色模式等,具体请参见
MapColorMode类。返回: 地图的颜色模式 返回类型: MapColorMode
-
get_description()¶ 返回当前地图的描述信息。
返回: 当前地图的描述信息。 返回类型: str
-
get_dpi()¶ 返回地图的DPI,代表每英寸有多少个像素
返回: 地图的DPI 返回类型: float
-
get_dynamic_prj_trans_method()¶ 返回地图动态投影时所使用的地理坐标系转换算法。默认值为
CoordSysTransMethod.MTH_GEOCENTRIC_TRANSLATION返回: 地图动态投影时所使用的投影算法 返回类型: CoordSysTransMethod
-
get_dynamic_prj_trans_parameter()¶ 设置地图动态投影时,当源投影与目标目标投影所基于的地理坐标系不同时,可以通过该方法设置转换参数。
返回: 动态投影坐标系的转换参数。 返回类型: CoordSysTransParameter
-
get_image_size()¶ 返回出图时图片的大小,以像素为单位
返回: 返回出图时图片的宽度和高度 返回类型: tuple[int,int]
-
get_layer(index_or_name)¶ 返回此图层集合中指定名称的图层对象。
参数: index_or_name (str or int) -- 图层的名称或索引 返回: 此图层集合中指定名称的图层对象。 返回类型: Layer
-
get_layers_count()¶ 返回此图层集合中图层对象的总数。
返回: 此图层集合中图层对象的总数 返回类型: int
-
get_max_scale()¶ 返回地图的最大比例尺。
返回: 地图的最大比例尺。 返回类型: float
-
get_min_scale()¶ 返回地图的最小比例尺
返回: 地图的最小比例尺。 返回类型: float
-
get_name()¶ 返回当前地图的名称。
返回: 当前地图的名称。 返回类型: str
-
get_prj()¶ 返回地图的投影坐标系统
返回: 地图的投影坐标系统。 返回类型: PrjCoordSys
-
get_scale()¶ 返回当前地图的显示比例尺。
返回: 当前地图的显示比例尺。 返回类型: float
-
get_view_bounds()¶ 返回当前地图的可见范围,也称显示范围。当前地图的可见范围除了可以通过
set_view_bounds()方法来进行设置,还可以通过设置显示范 围的中心点(set_center())和显示比例尺(set_scale())的方式来进行设置。返回: 当前地图的可见范围。 返回类型: Rectangle
-
index_of_layer(layer_name)¶ 返回此图层集合中指定名称的图层的索引。
参数: layer_name (str) -- 要查找的图层的名称。 返回: 找到指定图层则返回图层索引,否则返回-1。 返回类型: int
-
is_clip_region_enabled()¶ 返回地图显示裁剪区域是否有效,true 表示有效。
返回: 地图显示裁剪区域是否有效 返回类型: bool
-
is_contain_layer(layer_name)¶ 判定此图层集合对象是否包含指定名称的图层。
参数: layer_name (str) -- 可能包含在此图层集合中的图层对象的名称。 返回: 若此图层中包含指定名称的图层则返回 true,否则返回 false。 返回类型: bool
-
is_dynamic_projection()¶ 返回是否允许地图动态投影显示。地图动态投影显示是指如果当前地图窗口中地图的投影信息与数据源的投影信息不同,利用地图动态投影显 示可以将当前地图的投影信息转换为数据源的投影信息。
返回: 是否允许地图动态投影显示。 返回类型: bool
-
is_fill_marker_angle_fixed()¶ 返回是否固定填充符号的填充角度。
返回: 是否固定填充符号的填充角度。 返回类型: bool
-
is_line_antialias()¶ 返回是否地图线型反走样显示。
返回: 是否地图线型反走样显示。 返回类型: bool
-
is_map_thread_drawing_enabled()¶ 返回是否另启线程绘制地图元素,true表示另启线程绘制地图元素,可以提升大数据量地图的绘制性能。
返回: 指示是否另启线程绘制地图元素,true表示另启线程绘制地图元素,可以提升大数据量地图的绘制性能。 返回类型: bool
-
is_marker_angle_fixed()¶ 返回一个布尔值指定点状符号的角度是否固定。针对地图中的所有点图层。
返回: 用于指定点状符号的角度是否固定。 返回类型: bool
-
is_overlap_displayed()¶ 返回重叠时是否显示对象。
返回: 重叠时是否显示对象。 返回类型: bool
-
is_use_system_dpi()¶ 是否使用系统的 DPI
返回: 是否使用系统 DPI 返回类型: bool
-
move_layer_to(src_index, tag_index)¶ 将此图层集合中的指定索引的图层移动到指定的目标索引。
参数: - src_index (int) -- 要移动图层的原索引
- tag_index (int) -- 图层要移动到的目标索引。
返回: 移动成功返回 true,否则返回 false。
返回类型: bool
-
open(name)¶ 打开指定名称的地图。该指定名称为地图所关联的工作空间中的地图集合对象中的一个地图的名称,注意与地图的显示名称相区别。
参数: name (str) -- 地图名称。 返回: 返回类型: bool
-
output_to_file(file_name, output_bounds=None, dpi=0, image_size=None, is_back_transparent=False, is_show_to_ipython=False)¶ 将当前地图输出的文件中,支持 BMP, PNG, JPG, GIF, PDF, TIFF 文件。不保存跟踪图层。
参数: - file_name (str) -- 结果文件路径,必须带文件后缀名。
- image_size (tuple[int,int]) -- 设置出图时图片的大小,以像素为单位。如果不设置,使用当前地图的 image_size,具体参考
get_image_size() - output_bounds (Rectangle) -- 地图输出范围。如果不设置,默认使用当前地图的视图范围,具体参考
get_view_bounds() - dpi (int) -- 地图的DPI,代表每英寸有多少个像素。如果不设置,默认使用当前地图的 DPI,具体参考
get_dpi() - is_back_transparent (bool) -- 是否背景透明。该参数仅在 type 参数设置为 GIF 和 PNG 类型时有效。
- is_show_to_ipython (bool) -- 是否在 ipython 中显示。注意,只能在 jupyter python 环境中显示,所以需要 ipython 和 jupyter 环境。只支持 PNG、JPG 和 GIF 在 jupyter 中显示。
返回: 输出成功返回 True, 否则返回 False
返回类型: bool
-
output_tracking_layer_to_png(file_name, output_bounds=None, dpi=0, is_back_transparent=False, is_show_to_ipython=False)¶ 将当前地图的跟踪图层输出为png 文件,在调用此接口前,用户可以通过 set_image_size 设置图片大小。
参数: - file_name (str) -- 结果文件路径,必须带文件后缀名。
- output_bounds (Rectangle) -- 地图输出范围。如果不设置,默认使用当前地图的视图范围,具体参考
get_view_bounds() - dpi (int) -- 地图的DPI,代表每英寸有多少个像素。如果不设置,默认使用当前地图的 DPI,具体参考
get_dpi() - is_back_transparent (bool) -- 是否背景透明。
- is_show_to_ipython (bool) -- 是否在 ipython 中显示。注意,只能在 jupyter python 环境中显示,所以需要 ipython 和 jupyter 环境。
返回: 输出成功返回 True, 否则返回 False
返回类型: bool
-
refresh(refresh_all=False)¶ 重新绘制当前地图。
参数: refresh_all (bool) -- 当 refresh_all 为 TRUE 时,在刷新地图时,同时刷新其中的快照图层。 快照图层,一种特殊的图层组, 该图层组包含的图层作为地图的一个快照图层,采用特殊的绘制方式,快照图层只在第一次显示时进行绘制, 此后,如果地图显示范围未发生变化,快照图层都将使用该显示,也就是快照图层不随地图刷新而重新绘制; 如果地图显示范围发生变化,将自动触发快照图层的刷新绘制。快照图层是提高地图显示性能的手段之一。 如果地图的显示范围不发生变化,刷新地图时,快照图层是不刷新的;如果需要强制刷新可以通过 refresh_all 刷新地图便可以同时刷新快照图层。 返回: self 返回类型: Map
-
remove_layer(index_or_name)¶ 从此图层集合中删除一个指定名称的图层。删除成功则返回 true。
参数: index_or_name (str or int) -- 要删除图层的名称或索引 返回: 删除成功则返回 true,否则返回 false。 返回类型: bool
-
set_angle(value)¶ 设置当前地图的旋转角度。单位为度,精度到 0.1 度。逆时针方向为正方向,如果用户输入负值,地图则以顺时针方向旋转
参数: value (float) -- 指定当前地图的旋转角度。 返回: self 返回类型: Map
-
set_clip_region(region)¶ 设置地图显示裁剪的区域。 用户可以任意设定一个地图显示的区域,该区域外的地图内容,将不会显示。
参数: region (GeoRegion or Rectangle) -- 地图显示裁剪的区域。 返回: self 返回类型: Map
-
set_clip_region_enabled(value)¶ 设置地图显示裁剪区域是否有效,true 表示有效。
参数: value (bool) -- 显示裁剪区域是否有效。 返回: self 返回类型: Map
-
set_color_mode(value)¶ 设置当前地图的颜色模式
参数: value (str or MapColorMode) -- 指定当前地图的颜色模式。 返回: self 返回类型: Map
-
set_dynamic_prj_trans_method(value)¶ 设置地图动态投影时,当源投影与目标目标投影所基于的地理坐标系不同时,需要设置该转换算法。
参数: value (CoordSysTransMethod or str) -- 地理坐标系转换算法 返回: self 返回类型: Map
-
set_dynamic_prj_trans_parameter(parameter)¶ 设置动态投影坐标系的转换参数。
参数: parameter (CoordSysTransParameter) -- 动态投影坐标系的转换参数。 返回: self 返回类型: Map
-
set_dynamic_projection(value)¶ 设置是否允许地图动态投影显示。地图动态投影显示是指如果当前地图窗口中地图的投影信息与数据源的投影信息不同,利用地图动态投影显 示可以将当前地图的投影信息转换为数据源的投影信息。
参数: value (bool) -- 是否允许地图动态投影显示。 返回: self 返回类型: Map
-
set_fill_marker_angle_fixed(value)¶ 设置是否固定填充符号的填充角度。
参数: value (bool) -- 是否固定填充符号的填充角度。 返回: self 返回类型: Map
-
set_image_size(width, height)¶ 设置出图时图片的大小,以像素为单位。
参数: - width (int) -- 出图时图片的宽度
- height (int) -- 出图时图片的高度
返回: self
返回类型:
-
set_map_thread_drawing_enabled(value)¶ 设置是否另启线程绘制地图元素,true表示另启线程绘制地图元素,可以提升大数据量地图的绘制性能。
参数: value (bool) -- 一个布尔值,指示是否另启线程绘制地图元素,true表示另启线程绘制地图元素,可以提升大数据量地图的绘制性能。 返回: self 返回类型: Map
-
set_mark_angle_fixed(value)¶ 设置一个布尔值指定点状符号的角度是否固定。针对地图中的所有点图层。
参数: value (bool) -- 指定点状符号的角度是否固定 返回: self 返回类型: Map
-
set_prj(prj)¶ 设置地图的投影坐标系统
参数: prj (PrjCoordSys) -- 地图的投影坐标系统。 返回: self 返回类型: Map
-
set_use_system_dpi(value)¶ 设置是否使用系统 DPI
参数: value (bool) -- 是否使用系统 DPI。True,表示使用系统的DPI,False,表示使用地图的设置。 返回: self 返回类型: Map
-
set_view_bounds(bounds)¶ 设置当前地图的可见范围,也称显示范围。当前地图的可见范围除了可以通过
set_view_bounds()方法来进行设置,还可以通过设置显示范 围的中心点(set_center())和显示比例尺(set_scale())的方式来进行设置。参数: bounds (Rectangle) -- 指定当前地图的可见范围。 返回: self 返回类型: Map
-
show_to_ipython()¶ 将当前地图在 ipython 中显示,注意,只能在 jupyter python 环境中显示,所以需要 ipython 和 jupyter 环境
返回: 显示成功返回 True,否则返回 False 返回类型: bool
-
to_xml()¶ 返回此地图对象的 XML 字符串形式的描述。 任何地图都可以导出成 xml 字符串,而地图的 xml 字符串也可以导入成为一个地图来显示。地图的 xml 字符串中存储了关于地图及其图 层的显示设置以及关联的数据信息等。此外,可以将地图的 xml 字符串保存成一个 xml 文件。
返回: 地图的 XML 形式的描述 返回类型: str
-
tracking_layer¶ TrackingLayer -- 返回当前地图的跟踪图层对象
-
-
class
iobjectspy.mapping.LayerSetting¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase图层设置基类。该类是对图层的显示风格的设置的基类。 对矢量数据集,栅格数据集以及影像数据集的图层风格分别使用 LayerSettingVector, LayerSettingGrid 和 LayerSettingImage 类中提供的方法进行设置。 矢量图层中所有要素采用相同的渲染风格,栅格图层采用颜色表来显示其像元,影像的图层的风格设置是对影像的亮度,对比度以及透明度等的设置。
-
class
iobjectspy.mapping.LayerSettingImage¶ 基类:
iobjectspy._jsuperpy.mapping.LayerSetting影像图层设置类。
-
get_background_value()¶ 获取影像中被视为背景的值
返回: 影像中被视为背景的值 返回类型: float
-
get_brightness()¶ 返回影像图层的亮度。值域范围为 -100 到 100,增加亮度为正,降低亮度为负。亮度值可以保存到工作空间。
返回: 影像图层的亮度值。 返回类型: int
-
get_contrast()¶ 返回影像图层的对比度。值域范围为 -100 到 100,增加对比度为正,降低对比度为负。
返回: 影像图层的对比度。 返回类型: int
-
get_display_band_indexes()¶ 返回当前影像图层显示的波段索引。假设当前影像图层有若干波段,当需要按照设置的色彩模式(如 RGB)设置显示波段时,指定色彩(如 RGB 中的红色、绿色、蓝色)对应的波段索引(如0,2,1)即可。
返回: 当前影像图层显示的波段索引。 返回类型: list[int]
-
get_display_color_space()¶ 返回影像图层的色彩显示模式。它会根据影像图层当前的色彩格式和显示的波段将该影像图层以该色彩模式进行显示。
返回: 影像图层的色彩显示模式。 返回类型: ColorSpaceType
-
get_display_mode()¶ 返回影像显示模式。
返回: 影像显示模式。 返回类型: ImageDisplayMode
-
get_image_interpolation_mode()¶ 设置显示图像时使用的插值算法。
返回: 显示图像时使用的插值算法 返回类型: ImageInterpolationMode
-
get_opaque_rate()¶ 返回影像图层显示的不透明度。不透明度为一个 0-100 之间的数。0为不显示;100为完全不透明。只对影像图层有效,在地图旋转的情况下也有效。
返回: 影像图层显示的不透明度。 返回类型: int
-
get_special_value()¶ 获取影像中的特殊值。该特殊值可以通过
set_special_value_color()指定显示颜色。返回: 影像中的特殊值 返回类型: float
-
get_transparent_color_tolerance()¶ 返回背景透明色容限,容限值范围为[0,255]。
返回: 背景透明色容限 返回类型: int
-
is_transparent()¶ 设置是否使影像图层背景透明
返回: 一个布尔值指定是否使影像图层背景透明。 返回类型: bool
-
set_background_color(value)¶ 设置指定的背景值的显示颜色。
参数: value (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 定的背景值的显示颜色 返回: self 返回类型: LayerSettingImage
-
set_background_value(value)¶ 设置影像中被视为背景的值
参数: value (float) -- 影像中被视为背景的值 返回: self 返回类型: LayerSettingImage
-
set_brightness(value)¶ 设置影像图层的亮度。值域范围为 -100 到 100,增加亮度为正,降低亮度为负。
参数: value (int) -- 影像图层的亮度值。 返回: self 返回类型: LayerSettingImage
-
set_contrast(value)¶ 设置影像图层的对比度。值域范围为 -100 到 100,增加对比度为正,降低对比度为负。
参数: value (int) -- 影像图层的对比度。 返回: self 返回类型: LayerSettingImage
-
set_display_band_indexes(indexes)¶ 设置当前影像图层显示的波段索引。假设当前影像图层有若干波段,当需要按照设置的色彩模式(如 RGB)设置显示波段时,指定色彩(如 RGB 中的红色、绿色、蓝色)对应的波段索引(如0,2,1)即可。
参数: indexes (list[int] or tuple[int]) -- 当前影像图层显示的波段索引。 返回: self 返回类型: LayerSettingImage
-
set_display_color_space(value)¶ 设置影像图层的色彩显示模式。它会根据影像图层当前的色彩格式和显示的波段将该影像图层以该色彩模式进行显示。
参数: value (ColorSpaceType) -- 影像图层的色彩显示模式。 返回: self 返回类型: LayerSettingImage
-
set_display_mode(value)¶ 设置影像显示模式。
参数: value (ImageDisplayMode) -- 影像显示模式,多波段支持两种显示模式,单波段只支持拉伸显示模式。 返回: self 返回类型: LayerSettingImage
-
set_image_interpolation_mode(value)¶ 设置显示图像时使用的插值算法
参数: value (ImageInterpolationMode or str) -- 指定的插值算法 返回: self 返回类型: LayerSettingImage
-
set_opaque_rate(value)¶ 设置影像图层显示的不透明度。不透明度为一个 0-100 之间的数。0为不显示;100为完全不透明。只对影像图层有效,在地图旋转的情况下也有效
参数: value (int) -- 影像图层显示的不透明度 返回: self 返回类型: LayerSettingImage
-
set_special_value(value)¶ 设置影像中的特殊值,该特殊值可以通过
set_special_value_color()指定显示颜色。参数: value (float) -- 影像中的特殊值 返回: self 返回类型: LayerSettingImage
-
set_special_value_color(color)¶ 设置
set_special_value()所设定的特殊值的显示颜色参数: color (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 特殊值的显示颜色 返回: self 返回类型: LayerSettingImage
-
set_transparent(value)¶ 设置是否使影像图层背景透明
参数: value (bool) -- 一个布尔值指定是否使影像图层背景透明 返回: self 返回类型: LayerSettingImage
-
set_transparent_color(color)¶ 设置背景透明色。
参数: color (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 背景透明色 返回: self 返回类型: LayerSettingImage
-
set_transparent_color_tolerance(value)¶ 设置背景透明色容限,容限值范围为[0,255]。
参数: value (int) -- 背景透明色容限 返回: self 返回类型: LayerSettingImage
-
-
class
iobjectspy.mapping.LayerSettingVector(style=None)¶ 基类:
iobjectspy._jsuperpy.mapping.LayerSetting矢量图层设置类。
该类主要用来设置矢量图层的显示风格。矢量图层用单一的符号或风格绘制所有的要素。当你只想可视化地显示你的空间数据,只关心空间数据中 各要素在什么位置,而不关心各要素在数量或性质上的不同时,可以用普通图层来显示要素数据。
-
set_style(style)¶ 设置矢量图层的风格。
参数: style (GeoStyle) -- 矢量图层的风格。 返回: self 返回类型: LayerSettingVector
-
-
class
iobjectspy.mapping.LayerSettingGrid¶ 基类:
iobjectspy._jsuperpy.mapping.LayerSetting栅格图层设置类。
栅格图层设置是针对普通图层而言的。栅格图层采用颜色表来显示其像元。SuperMap 的颜色表是按照 8 比特的 RGB 彩色坐标系来显示像元的, 您可以根据像元的属性值来设置其显示颜色值,从而形象直观地表示栅格数据反映的现象。
-
get_brightness()¶ 返回 Grid 图层的亮度,值域范围为 -100 到 100,增加亮度为正,降低亮度为负。
返回: Grid 图层的亮度。 返回类型: int
-
get_contrast()¶ 返回 Grid 图层的对比度,值域范围为 -100 到 100,增加对比度为正,降低对比度为负。
返回: Grid 图层的对比度。 返回类型: int
-
get_image_interpolation_mode()¶ 返回显示图像时使用的插值算法。
返回: 显示图像时使用的插值算法 返回类型: ImageInterpolationMode
-
get_opaque_rate()¶ 返回 Grid 图层显示不透明度。不透明度为一个 0-100 之间的数。0 为不显示;100 为完全不透明。只对栅格图层有效,在地图旋转的情况下也有效。
返回: Grid 图层显示不透明度。 返回类型: int
-
get_special_value()¶ 返回图层的特殊值。 在新增一个 Grid 图层时,该方法的返回值与数据集的 NoValue 属性值相等。
返回: 返回类型: float
-
is_special_value_transparent()¶ 返回图层的特殊值(SpecialValue)所处区域是否透明。
返回: 一个布尔值,图层的特殊值(SpecialValue)所处区域透明返回 true,否则返回 false。 返回类型: bool
-
set_brightness(value)¶ 设置 Grid 图层的亮度,值域范围为 -100 到 100,增加亮度为正,降低亮度为负。
参数: value (int) -- 返回: self 返回类型: LayerSettingGrid
-
set_color_dictionary(colors)¶ 设置图层的颜色对照表
参数: colors (dict[float, Color]) -- 指定图层的颜色对照表。 返回: self 返回类型: LayerSettingGrid
-
set_color_table(value)¶ 设置颜色表。
参数: value (Colors) -- 颜色表 返回: self 返回类型: LayerSettingGrid
-
set_contrast(value)¶ 设置 Grid 图层的对比度,值域范围为 -100 到 100,增加对比度为正,降低对比度为负。
参数: value (int) -- Grid 图层的对比度。 返回: self 返回类型: LayerSettingGrid
-
set_image_interpolation_mode(value)¶ 设置显示图像时使用的插值算法。
参数: value (ImageInterpolationMode or str) -- 指定的插值算法。 返回: self 返回类型: LayerSettingGrid
-
set_opaque_rate(value)¶ 设置 Grid 图层显示的不透明度。不透明度为一个 0-100 之间的数。0 为不显示;100 为完全不透明。只对栅格图层有效,在地图旋转的情况下也有效。
参数: value (int) -- Grid 图层显示不透明度。 返回: self 返回类型: LayerSettingGrid
-
set_special_value(value)¶ 设置图层的特殊值。
参数: value (float) -- 图层的特殊值 返回: self 返回类型: LayerSettingGrid
-
set_special_value_color(value)¶ 设置栅格数据集特殊值数据的颜色。
参数: value (Color or tuple[int,int,int] or tuple[int,int,int,int]) -- 栅格数据集特殊值数据的颜色。 返回: self 返回类型: LayerSettingGrid
-
set_special_value_transparent(value)¶ 设置图层的特殊值(SpecialValue)所处区域是否透明。
参数: value (bool) -- 图层的特殊值(SpecialValue)所处区域是否透明。 返回: self 返回类型: LayerSettingGrid
-
-
class
iobjectspy.mapping.TrackingLayer(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase跟踪图层类。
在 SuperMap 中,每个地图窗口都有一个跟踪图层,确切地说,每个地图显示时都有一个跟踪图层。 跟踪图层是一个空白的透明图层,总是在地 图各图层的最上层,主要用于在一个处理或分析过程中,临时存放一些图形对象,以及一些文本等。 只要地图显示,跟踪图层就会存在,你不可 以删除跟踪图层,也不可以改变其位置。
在 SuperMap 中跟踪图层的作用主要有以下方面:
- 当不想往记录集中添加几何对象,而又需要这个几何对象的时候,就可以把这个几何对象临时添加到跟踪图层上,用完该几何对象之后清除跟踪 图层即可。例如,当需要测量距离时,需要在地图上拉一条线,但是这一条线在地图上并不存在,此时就可以使用跟踪图层来实现。
- 当需要对目标进行动态跟踪的时候,如果把目标放到记录集中,要实现动态跟踪就得不断地刷新整个图层,这样会大大影响效率,如果将这个需 要进行跟踪地目标放到跟踪层上,这样就只需要刷新跟踪图层即可实现动态跟踪。
- 当需要进行批量地往记录集中添加几何对象的时候,可以先将这些对象临时放在跟踪图层上,确定需要添加之后再把跟踪图层上的几何对象批量 地添加到记录集中。
请注意避免把跟踪图层作为存储大量临时几何对象的容器,如果有大量的临时数据,建议在本地计算机临时目录下(如:c: emp)创建临时数据 源,并在临时数据源中创建相应的临时数据集来保存临时数据。
你可以对跟踪图层进行控制,包括控制跟踪图层是否可显示以及符号是否随图缩放。跟普通图层不同的是,跟踪图层中的对象是不保存的,只是在 地图显示时,临时存在内存中。当地图关闭后,跟踪图层中的对象依然存在,相应内存释放掉才会消失,当地图再次被打开后,跟踪图层又显示为 一个空白而且透明的图层。
该类提供了对跟踪图层上的几何对象进行添加,删除等管理的方法。并且可以通过设置标签的方式对跟踪图层上的几何对象进行分类,你可以将标 签理解为对几何对象的描述,相同用途的几何对象可以具有相同的标签。
-
add(geo, tag)¶ 向当前跟踪图层中添加一个几何对象,并给出其标签信息。
参数: 返回: 添加到跟踪图层的几何对象的索引。
返回类型: int
-
clear()¶ 清空此跟踪图层中的所有几何对象。
返回: self 返回类型: TrackingLayer
-
finish_edit_bulk()¶ 完成批量更新
返回: self 返回类型: TrackingLayer
-
flush_bulk_edit()¶ 批量更新时强制刷新并保存本次批量编辑的数据。
返回: 强制刷新返回 true,否则返回 false。 返回类型: bool
-
get_symbol_scale()¶ 返回此跟踪图层的符号缩放基准比例尺。
返回: 跟踪图层的符号缩放基准比例尺。 返回类型: float
-
get_tag(index)¶ 返回此跟踪图层中指定索引的几何对象的标签。
参数: index (int) -- 要返回标签的几何对象的索引。 返回: 此跟踪图层中指定索引的几何对象的标签。 返回类型: str
-
index_of(tag)¶ 返回第一个与指定标签相同的几何对象所处的索引值。
参数: tag (str) -- 需要进行索引检查的标签。 返回: 返回第一个与指定标签相同的几何对象所处的索引值。 返回类型: int
-
is_antialias()¶ 返回一个布尔值指定是否反走样跟踪图层。文本、线型被设置为反走样后,可以去除一些显示锯齿,使显示更加美观。如图分别为线型和文本 反走样前和反走样后的效果对比
返回: 反走样跟踪图层返回 true;否则返回 false。 返回类型: bool
-
is_symbol_scalable()¶ 返回跟踪图层的符号大小是否随图缩放。true 表示当随着地图的缩放而缩放,在地图放大的同时,符号同时也放大。
返回: 一个布尔值指示跟踪图层的符号大小是否随图缩放。 返回类型: bool
-
is_visible()¶ 返回此跟踪图层是否可见。true 表示此跟踪图层可见,false 表示此跟踪图层不可见。当此跟踪图层不可见时,其他的设置都将无效。
返回: 指示此图层是否可见。 返回类型: bool
-
remove(index)¶ 在当前跟踪图层中删除指定索引的几何对象。
参数: index (int) -- 要删除的几何对象的索引。 返回: 删除成功返回 true;否则返回 false。 返回类型: bool
-
set(index, geo)¶ 将跟踪图层中的指定的索引处的几何对象替换为指定的几何对象,若此索引处原先有其他几何对象,则会被删除。
参数: 返回: 替换成功返回 true;否则返回 false。
返回类型: bool
-
set_antialias(value)¶ 设置一个布尔值指定是否反走样跟踪图层。
参数: value (bool) -- 指定是否反走样跟踪图层。 返回: self 返回类型: TrackingLayer
-
set_symbol_scalable(value)¶ 设置跟踪图层的符号大小是否随图缩放。true 表示当随着地图的缩放而缩放,在地图放大的同时,符号同时也放大。
参数: value (bool) -- 一个布尔值指示跟踪图层的符号大小是否随图缩放。 返回: self 返回类型: TrackingLayer
-
set_symbol_scale(value)¶ 设置此跟踪图层的符号缩放基准比例尺。
参数: value (float) -- 此跟踪图层的符号缩放基准比例尺。 返回: self 返回类型: TrackingLayer
-
set_tag(index, tag)¶ 设置此跟踪图层中指定索引的几何对象的标签
参数: - index (int) -- 要设置标签的几何对象的索引。
- tag (str) -- 几何对象的新标签。
返回: 设置成功返回 true;否则返回 false。
返回类型: bool
-
set_visible(value)¶ 设置此跟踪图层是否可见。true 表示此跟踪图层可见,false 表示此跟踪图层不可见。当此跟踪图层不可见时,其他的设置都将无效。
参数: value (bool) -- 指示此图层是否可见。 返回: self 返回类型: TrackingLayer
-
start_edit_bulk()¶ 开始批量更新
返回: self 返回类型: TrackingLayer
-
class
iobjectspy.mapping.Layer(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase图层类。
该类提供了图层显示和控制等的便于地图管理的一系列方法。当数据集被加载到地图窗口中显示时,就形成了一个图层,因此图层是数据集的可视 化显示。一个图层是对一个数据集的引用或参考。 图层分为普通图层和专题图层,矢量的普通图层中所有要素采用相同的渲染风格,栅格图层采用颜色表来显示其像元;而专题图层的则采用指定类 型的专题图风格来渲染其中的要素或像元。影像数据只对应普通图层。普通图层的风格通过
get_layer_setting()和set_layer_setting()方法来返回或设置。该类的实例不可被创建。只可以通过在
Map类Map.add_dataset()方法来创建-
bounds¶ Rectangle -- 图层的范围
-
caption¶ str -- 返回图层的标题。图层的标题为图层的显示名称,例如在图例或排版制图时显示的图层的名称即为图层的标题。注意与图层的名称相区别。
-
dataset¶ Dataset -- 返回此图层对应的数据集对象。图层是对数据集的引用,因而,一个图层与一个数据集相对应。
-
from_xml(xml)¶ 根据指定的XML字符串创建图层对象。 任何图层都可以导出成xml字符串,而图层的xml字符串也可以导入成为一个图层来进行显示。图层的 xml字符串中存储了关于图层的显示的设置以及关联的数据信息等对图层的所有的设置。可以将图层的xml字符串保存成一个xml文件。
参数: xml (str) -- 用来创建图层的XML字符串 返回: 创建成功则返回true,否则返回false。 返回类型: bool
-
get_display_filter()¶ 返回图层显示过滤条件。通过设置显示过滤条件,可以使图层中的一些要素显示,而另一些要素不显示,以便重点分析感兴趣的要素,而过滤掉其他要素。
注意:该方法仅支持属性查询,不支持空间查询
返回: 图层显示过滤条件。 返回类型: QueryParameter
-
get_layer_setting()¶ 返回普通图层的风格设置。普通图层风格的设置对矢量数据图层,栅格数据图层以及影像数据图层是不相同的。
LayerSettingVector,LayerSettingGrid,LayerSettingImage类分别用来对矢量数 据图层,栅格数据图层和影像数据图层的风格进行设置和修改。返回: 普通图层的风格设置 返回类型: LayerSetting
-
get_max_visible_scale()¶ 返回此图层的最大可见比例尺。最大可见比例尺不可为负,当地图的当前显示比例尺大于或等于图层最大可见比例尺时,此图层将不显示。
返回: 图层的最大可见比例尺。 返回类型: float
-
get_min_visible_scale()¶ 返回: 返回类型: float
-
get_opaque_rate()¶ 返回图层的不透明度。
返回: 图层的不透明度。 返回类型: int
-
is_antialias()¶ 返回图层是否开启反走样。
返回: 指示图层是否开启反走样。true 为开启反走样,false 为不开启。 返回类型: bool
-
is_clip_region_enabled()¶ 返回裁剪区域是否有效。
返回: 指定裁剪区域是否有效。true 表示有效,false 表示无效。 返回类型: bool
-
is_symbol_scalable()¶ 返回图层的符号大小是否随图缩放。默认为 false。true 表示当图层被放大或缩小时,符号也随之放大或缩小。
返回: 图层的符号大小是否随图缩放。 返回类型: bool
-
is_visible()¶ 返回此图层是否可见。true 表示此图层可见,false 表示图层不可见。当图层不可见时,其他所有的属性的设置将无效
返回: 图层是否可见。 返回类型: bool
-
is_visible_scale(scale)¶ 返回指定的比例尺是否为可视比例尺,即在设定的最小显示比例尺和最大显示比例尺之间
参数: scale (float) -- 指定的显示比例尺。 返回: 返回 true,表示指定的比例尺为可视比例尺;否则为 false。 返回类型: bool
-
set_antialias(value)¶ 设置图层是否开启反走样。
参数: value (bool) -- 指示图层是否开启反走样。true 为开启反走样,false 为不开启。 返回: self 返回类型: Layer
-
set_caption(value)¶ 设置图层的标题。图层的标题为图层的显示名称,例如在图例或排版制图时显示的图层的名称即为图层的标题。注意与图层的名称相区别。
参数: value (str) -- 指定图层的标题。 返回: self 返回类型: Layer
-
set_clip_region(region)¶ 设置图层的裁剪区域。
参数: region (GeoRegion or Rectangle) -- 图层的裁剪区域。 返回: self 返回类型: Layer
-
set_clip_region_enabled(value)¶ 设置裁剪区域是否有效。
参数: value (bool) -- 指定裁剪区域是否有效,true 表示有效,false 表示无效。 返回: self 返回类型: Layer
-
set_dataset(dt)¶ 设置此图层对应的数据集对象。图层是对数据集的引用,因而,一个图层与一个数据集相对应
参数: dt (Dataset) -- 此图层对应的数据集对象 返回: self 返回类型: Layer
-
set_display_filter(parameter)¶ 设置图层显示过滤条件。通过设置显示过滤条件,可以使图层中的一些要素显示,而另一些要素不显示,以便重点分析感兴趣的要素,而过滤掉其他要素。比如说通过连接(JoinItem)的方式将一个外部表的字段作为专题图的表达字段,在生成专题图后进行显示时,需要调用此方法,否则专题图将创建失败。
注意:该方法仅支持属性查询,不支持空间查询
参数: parameter (QueryParameter) -- 指定图层显示过滤条件。 返回: self 返回类型: Layer
-
set_layer_setting(setting)¶ 设置普通图层的风格
参数: setting (LayerSetting) -- 普通图层的风格设置。 返回: self 返回类型: Layer
-
set_max_visible_scale(value)¶ 设置此图层的最大可见比例尺。最大可见比例尺不可为负,当地图的当前显示比例尺大于或等于图层最大可见比例尺时,此图层将不显示。
参数: value (float) -- 指定图层的最大可见比例尺。 返回: self 返回类型: Layer
-
set_min_visible_scale(value)¶ 返回此图层的最小可见比例尺。最小可见比例尺不可为负。当地图的当前显示比例尺小于图层最小可见比例尺时,此图层将不显示。
参数: value (float) -- 图层的最小可见比例尺。 返回: self 返回类型: Layer
-
set_symbol_scalable(value)¶ 设置图层的符号大小是否随图缩放。默认为 false。true 表示当图层被放大或缩小时,符号也随之放大或缩小。
参数: value (bool) -- 指定图层的符号大小是否随图缩放。 返回: self 返回类型: Layer
-
set_visible(value)¶ 设置此图层是否可见。true 表示此图层可见,false 表示图层不可见。当图层不可见时,其他所有的属性的设置将无效。
参数: value (bool) -- 指定图层是否可见。 返回: self 返回类型: Layer
-
to_xml()¶ 返回此图层对象的 XML字符串形式的描述。 任何图层都可以导出成xml字符串,而图层的xml字符串也可以导入成为一个图层来进行显示。图 层的xml字符串中存储了关于图层的显示的设置以及关联的数据信息等对图层的所有的设置。可以将图层的xml字符串保存成一个xml文件。
返回: 返回此图层对象的 XML字符串形式的描述。 返回类型: str
-
-
class
iobjectspy.mapping.LayerHeatmap(java_object)¶ 基类:
iobjectspy._jsuperpy.mapping.Layer热力图图层类,该类继承自Layer类。
热力图是通过颜色分布,描述诸如人群分布、密度和变化趋势等的一种地图表现手法,因此,能够非常直观地呈现一些原本不易理解或表达的数据,比如密度、频度、温度等。 热力图图层除了可以反映点要素的相对密度,还可以表示根据属性进行加权的点密度,以此考虑点本身的权重对于密度的贡献。 热力图图层将随地图放大或缩小而发生更改,是一种动态栅格表面,例如,绘制全国旅游景点的访问客流量的热力图,当放大地图后,该热力图就可以反映某省内或者局部地区的旅游景点访问客流量分布情况。
-
get_fuzzy_degree()¶ 返回热力图中颜色渐变的模糊程度。
返回: 热力图中颜色渐变的模糊程度 返回类型: float
-
get_intensity()¶ 返回热力图中高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变色带中高点密度颜色(MaxColor)所占的比重,该值越 大,表示在色带中高点密度颜色所占比重越大。
返回: 热力图中高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变色带中高点密度颜色(MaxColor)所占的比重 返回类型: float
-
get_kernel_radius()¶ 返回用于计算密度的核半径。单位为:屏幕坐标。
返回: 用于计算密度的核半径 返回类型: int
-
get_max_color()¶ 返回高点密度的颜色,热力图图层将通过高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变的颜色方案。
返回: 高点密度的颜色 返回类型: Color
-
get_max_value()¶ 返回一个最大值。当前热力图图层中最大值(MaxValue)与最小值(MinValue)之间栅格将使用MaxColor和MinColor所确定的色带进行渲 染,其他大于MaxValue的栅格将以MaxColor渲染;而者小于MinValue的栅格将以MinColor渲染。
返回: 最大值 返回类型: float
-
get_min_color()¶ 返回低点密度的颜色,热力图图层将通过高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变的颜色方案。
返回: 低点密度的颜色 返回类型: Color
-
get_min_value()¶ 返回一个最小值。当前热力图图层中最大值(MaxValue)与最小值(MinValue)之间栅格将使用MaxColor和MinColor所确定的色带进行渲 染,其他大于MaxValue的栅格将以MaxColor渲染;而者小于MinValue的栅格将以MinColor渲染。
返回: 最小值 返回类型: float
-
get_weight_field()¶ 返回权重字段。热力图图层除了可以反映点要素的相对密度,还可以表示根据权重字段进行加权的点密度,以此考虑点本身的权重对于密度的贡献。
返回: 权重字段 返回类型: str
-
set_colorset(colors)¶ 设置用于显示当前热力图的颜色集合。
参数: colors (Colors) -- 用于显示当前热力图的颜色集合 返回: self 返回类型: LayerHeatmap
-
set_fuzzy_degree(value)¶ 设置热力图中颜色渐变的模糊程度。
参数: value (float) -- 热力图中颜色渐变的模糊程度。 返回: self 返回类型: LayerHeatmap
-
set_intensity(value)¶ 设置热力图中高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变色带中高点密度颜色(MaxColor)所占的比重,该值越大,表示在色带中高点密度颜色所占比重越大。
参数: value (float) -- 热力图中高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变色带中高点密度颜色(MaxColor)所占的比重 返回: self 返回类型: LayerHeatmap
-
set_kernel_radius(value)¶ 设置用于计算密度的核半径。单位为:屏幕坐标。 核半径在热力图中所起的作用如下所述:
- 热力图将根据设置的核半径值对每个离散点建立一个缓冲区。核半径数值的单位为:屏幕坐标;
- 对每个离散点建立缓冲区后,对每个离散点的缓冲区,使用渐进的灰度带(完整的灰度带是0~255)从内而外,由浅至深地填充;
- 由于灰度值可以叠加(值越大颜色越亮,在灰度带中则显得越白。在实际中,可以选择ARGB模型中任一通道作为叠加灰度值),从而对于有缓冲区交叉的区域,可以叠加灰度值,因而缓冲区交叉的越多,灰度值越大,这块区域也就越“热”;
- 以叠加后的灰度值为索引,从一条有256种颜色的色带中(例如彩虹色)映射颜色,并对图像重新着色,从而实现热力图。
查找半径越大,生成的密度栅格越平滑且概化程度越高;值越小,生成的栅格所显示的信息越详细。
参数: value (int) -- 计算密度的核半径 返回: self 返回类型: LayerHeatmap
-
set_max_color(value)¶ 设置高点密度的颜色,热力图图层将通过高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变的颜色方案。
参数: value (Color or tuple[int,int,int]) -- 高点密度的颜色 返回: self 返回类型: LayerHeatmap
-
set_max_value(value)¶ 设置一个最大值。当前热力图图层中最大值(MaxValue)与最小值(MinValue)之间栅格将使用MaxColor和MinColor所确定的色带进行渲 染,其他大于MaxValue的栅格将以MaxColor渲染;而者小于MinValue的栅格将以MinColor渲染。 如果没有指定最大最小值,系统将自动 计算获得当前热力图图层中的最大和最小值。
参数: value (float) -- 最大值 返回: self 返回类型: LayerHeatmap
-
set_min_color(value)¶ 设置低点密度的颜色,热力图图层将通过高点密度颜色(MaxColor)和低点密度颜色(MinColor)确定渐变的颜色方案。
参数: value (Color or tuple[int,int,int]) -- 低点密度的颜色 返回: self 返回类型: LayerHeatmap
-
set_min_value(value)¶ 设置一个最小值。当前热力图图层中最大值(MaxValue)与最小值(MinValue)之间栅格将使用MaxColor和MinColor所确定的色带进行渲 染,其他大于MaxValue的栅格将以MaxColor渲染;而者小于MinValue的栅格将以MinColor渲染。
参数: value (float) -- 最小值 返回: self 返回类型: LayerHeatmap
-
set_weight_field(value)¶ 设置权重字段。热力图图层除了可以反映点要素的相对密度,还可以表示根据权重字段进行加权的点密度,以此考虑点本身的权重对于密度的贡献。 根据核半径(KernelRadius)确定的离散点缓冲区,其叠加确定了热度分布密度,而权重则是确定了点对于密度的影响力,点的权重值确定了 该点缓冲区的对于密度的影响力,即如果点缓冲区原来的影响系数为1,点的权重值为10,则引入权重后,该点缓冲区的影响系数为1*10=10,以此类推其他离散点缓冲区的密度影响系数。
那么,引入权重后,将获得一个新的叠加后的灰度值为索引,在利用指定的色带为其着色,从而实现引入权重的热力图。
参数: value (str) -- 权重字段。热力图图层除了可以反映点要素的相对密度,还可以表示根据权重字段进行加权的点密度,以此考虑点本身的权重对于密度的贡献。 返回: self 返回类型: LayerHeatmap
-
-
class
iobjectspy.mapping.LayerGridAggregation(java_object)¶ 基类:
iobjectspy._jsuperpy.mapping.Layer网格聚合图
-
get_colorset()¶ 返回网格单元统计值最大值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
返回: 网格单元统计值最大值对应的颜色 返回类型: Colors
-
get_grid_height()¶ 返回设置矩形格网的高度。单位为:屏幕坐标。
返回: 矩形格网的高度 返回类型: int
-
get_grid_type()¶ 返回网格聚合图的格网类型
返回: 网格聚合图的格网类型 返回类型: LayerGridAggregationType
-
get_grid_width()¶ 返回六边形格网的边长,或者矩形格网的宽度。单位为:屏幕坐标。
返回: 六边形格网的边长,或者矩形格网的宽度 返回类型: int
-
get_max_color()¶ 返回网格单元统计值最大值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
返回: 网格单元统计值最大值对应的颜色 返回类型: Color
-
get_min_color()¶ 返回网格单元统计值最小值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
返回: 网格单元统计值最小值对应的颜色 返回类型: Color
-
get_original_point_style()¶ 返回点数据显示的风格。对网格聚合图进行放大浏览,当比例尺较大时,将不显示聚合的网格效果,而显示原始点数据内容。
返回: 点数据显示的风格。 返回类型: GeoStyle
-
get_weight_field()¶ 返回权重字段。网格聚合图每个网格单元的统计值默认为落在该单元格内的点对象数目,此外,还可以引入点的权重信息,考虑网格单元内点的加权值作为网格的统计值。
返回: 权重字段 返回类型: str
-
is_show_label()¶ 是否显示网格单元标签
返回: 是否显示网格单元标签,true表示显示;false表示不显示。 返回类型: bool
-
set_colorset(colors)¶ 设置网格单元统计值最大值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
参数: colors (Colors) -- 网格单元统计值最大值对应的颜色 返回: self 返回类型: LayerGridAggregation
-
set_grid_height(value)¶ 设置矩形格网的高度。单位为:屏幕坐标。
参数: value (int) -- 矩形格网的高度 返回: self 返回类型: LayerGridAggregation
-
set_grid_type(value)¶ 设置网格聚合图的格网类型,可以为矩形网格或者六边形网格。
参数: value (LayerGridAggregationType or str) -- 网格聚合图的格网类型 返回: self 返回类型: LayerGridAggregation
-
set_grid_width(value)¶ 设置六边形格网的边长,或者矩形格网的宽度。单位为:屏幕坐标。
参数: value (int) -- 六边形格网的边长,或者矩形格网的宽度 返回: self 返回类型: LayerGridAggregation
-
set_label_style(value)¶ 设置网格单元内统计值标签的风格。
参数: value (TextStyle) -- 网格单元内统计值标签的风格。 返回: self 返回类型: LayerGridAggregation
-
set_line_style(value)¶ 设置网格单元矩形边框线的风格。
参数: value (GeoStyle) -- 网格单元矩形边框线的风格 返回: self 返回类型: LayerGridAggregation
-
set_max_color(value)¶ 设置网格单元统计值最大值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
参数: value (Color or tuple[int,int,int]) -- 网格单元统计值最大值对应的颜色 返回: self 返回类型: LayerGridAggregation
-
set_min_color(value)¶ 设置网格单元统计值最小值对应的颜色,网格聚合图将通过MaxColor和MinColor确定渐变的颜色方案,然后基于网格单元统计值大小排序,对网格单元进行颜色渲染。
参数: value (Color or tuple[int,int,int]) -- 网格单元统计值最小值对应的颜色 返回: self 返回类型: LayerGridAggregation
-
set_original_point_style(value)¶ 设置点数据显示的风格。 对网格聚合图进行放大浏览,当比例尺较大时,将不显示聚合的网格效果,而显示原始点数据内容。
参数: value (GeoStyle) -- 点数据显示的风格 返回: self 返回类型: LayerGridAggregation
-
set_show_label(value)¶ 设置是否显示网格单元标签。
参数: value (bool) -- 指示是否显示网格单元标签,true表示显示;false表示不显示。 返回: self 返回类型: LayerGridAggregation
-
set_weight_field(value)¶ 设置权重字段。网格聚合图每个网格单元的统计值默认为落在该单元格内的点对象数目,此外,还可以引入点的权重信息,考虑网格单元内点的加权值作为网格的统计值。
参数: value (str) -- 权重字段。网格聚合图每个网格单元的统计值默认为落在该单元格内的点对象数目,此外,还可以引入点的权重信息,考虑网格单元内点的加权值作为网格的统计值。 返回: self 返回类型: LayerGridAggregation
-
update_data()¶ 根据数据变化自动更新当前网格聚合图
返回: self 返回类型: LayerGridAggregation
-
-
class
iobjectspy.mapping.ThemeType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum专题图类型常量。
矢量数据和光栅数据都可以用来制作专题图,所不同的是矢量数据的专题图是基于其属性表中的属性信息,而光栅数据则是基于像元值。SuperMap 提供用于矢量 数据(点,线,面以及复合数据集)的专题图,包括单值专题图,范围分段专题图,点密度专题图,统计专题图,等级符号专题图,标签专题图和自定义专题图,也 提供了适合于光栅数据(栅格数据集)的专题图功能,包括栅格分段专题图和栅格单值专题图。
变量: - ThemeType.UNIQUE -- 单值专题图。单值专题图中,专题变量的值相同的要素归为一类,为每一类设定一种渲染风格,如颜色或符号等,作为专题变量的字 段或表达式的值相同的要素采用相同的渲染风格,从而用来区分不同的类别。
- ThemeType.RANGE -- 分段专题图。在分段专题图中,专题变量的值被分成多个范围段,在同一个范围段中要素或记录使用相同的颜色或符号风格进行显示。 可使用的分段的方法有等距离分段法,平方根分段法,标准差分段法,对数分段法,等计数分段法。分段专题图所基于的专题变量必须 为数值型。
- ThemeType.GRAPH --
统计专题图。统计专题图为每个要素或记录绘制统计图来反映其对应的专题变量的值的大小。统计专题图可以基于多个变量,反映多种 属性,即可以将多个变量的值绘制在一个统计图上。目前提供的统计图类型有:面积图,阶梯图,折线图,点状图,柱状图,三维柱状 图,饼图,三维饼图,玫瑰图,三维玫瑰图,堆叠柱状图以及三维堆叠柱状图。
- ThemeType.GRADUATEDSYMBOL --
等级符号专题图。等级符号专题图用符号的大小来表现要素或记录的所对应的字段或表达式(专题变量)的值的大小。 使用渐变的符号来绘制要素时,专题变量的值也被分成很多范围段,在一个范围段中的要素或记录用同样大小的符号来 绘制。等级符号专题图所基于的专题变量必须为数值型。
- ThemeType.DOTDENSITY --
点密度专题图。点密度专题图使用点的个数的多少或密集程度来反映一个区域或范围所对应的专题数据的值,其中一个点代表 了一定数量,则一个区域内的点的个数乘以点所表示的数量就是此区域对应的专题变量的值。点的个数越多越密集,则数据反 的事物或现象在该区域的密度或浓度越大。点密度专题图所基于的专题变量必须为数值型。
- ThemeType.LABEL --
标签专题图。标签专题图是用文本形式在图层上直接显示属性表中的数据,实质上是对图层的标注
- ThemeType.CUSTOM -- 自定义专题图。通过自定义专题图,用户可以对每个要素或记录设置特定的风格,并把这些设置存储到一个或多个字段中,然后基于 这个或这些字段来绘制专题图。在 SuperMap 中各种符号,线型或填充等风格都有对应的 ID 值,而颜色值,符号大小,线宽等 都可以用数值型的数据来设置。使用自定义专题图,用户非常自由地来表达各要素和数据。
- ThemeType.GRIDRANGE --
栅格分段专题图。在栅格分段专题图中,栅格的所有像元值被分成多个范围段,像元值在同一个范围段中的像元使用相同的颜色 进行显示。可使用的分段的方法有等距离分段法,平方根分段法,对数分段法。
- ThemeType.GRIDUNIQUE --
栅格单值专题图。栅格单值专题图中,栅格中像元值相同的像元归为一类,为每一类设定一种颜色,从而用来区分不同的类别。 如土地利用分类图中,土地利用类型相同的像元的值相同,将使用相同的颜色来渲染,从而区分不同的土地利用类型。

-
CUSTOM= 8¶
-
DOTDENSITY= 5¶
-
GRADUATEDSYMBOL= 4¶
-
GRAPH= 3¶
-
GRIDRANGE= 12¶
-
GRIDUNIQUE= 11¶
-
LABEL= 7¶
-
RANGE= 2¶
-
UNIQUE= 1¶
-
class
iobjectspy.mapping.Theme¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase专题图类,该类是所有专题图的基类。所有专题图类,如单值专题图,标签专题图,分段专题图等都继承自该类。
-
from_xml(xml)¶ 从 XML 字符串中导入专题图信息。 在 SuperMap 中,各种专题图的风格的设置都可以导出成 XML 格式的字符串,此 XML 格式的字符串中记录了关于这种专题图的所有设置,如对于标签专 题图的 XML 格式字符串会记录专题图类型,可见比例尺,标签风格的设置,是否流动显示,是否自动避让等等对该标签专题图的所有风格的设置以及用来制作 标签专题图的字段或表达式。这种 XML 格式字符串可以用来导入,对专题图进行设置
该接口需要注意的是,xml 记录的信息必须与当前对象的类型对应。例如,如果 xml 中记录的标签专题图信息,则当前对象必须为 ThemeLabel 对象。 如果不清楚 xml 中记录的专题图类型,可以使用
Theme.make_from_xml()从 xml 中构建一个新的专题图对象。参数: xml (str) -- 包含专题图信息的 XML 字符串或文件路径 返回: 导入成功返回 True, 否则返回 False。 返回类型: bool
-
static
make_from_xml(xml)¶ 导入专题图信息,并构建一个新的专题图对象。
参数: xml (str) -- 包含专题图信息的 XML 字符串或文件路径 返回: 专题图对象 返回类型: Theme
-
to_xml()¶ 导出专题图信息为 XML 字符串。
返回: 专题图信息的 XML 字符串 返回类型: str
-
type¶ ThemeType -- 专题图的类型
-
-
class
iobjectspy.mapping.ThemeUniqueItem(value, style, caption, visible=True)¶ 基类:
object单值专题图子项类。
单值专题图是将专题值相同的要素归为一类,为每一类设定一种渲染风格,其中每一类就是一个专题图子项。 比如,利用单值专题图制作行政区划图,Name 字 段代表省/直辖市名,该字段用来做专题变量,如果该字段的字段值总共有5种不同值,则该行政区划图有5个专题图子项,其中每一个子项内的要素 Name 字段值 都相同。
参数: - value (str) -- 单值专题图子项的单值
- style (GeoStyle) -- 每个单值专题图子项的显示风格
- caption (str) -- 单值专题图子项的名称
- visible (bool) -- 单值专题图子项是否可见
-
caption¶ str -- 每个单值专题图子项的名称
-
set_caption(value)¶ 设置每个单值专题图子项的名称
参数: value (str) -- 每个单值专题图子项的名称 返回: self 返回类型: ThemeUniqueItem
-
set_style(value)¶ 设置每个单值专题图子项的显示风格
参数: value (GeoStyle) -- 每个单值专题图子项的显示风格 返回: self 返回类型: ThemeUniqueItem
-
set_value(value)¶ 设置单值专题图子项的单值
参数: value (str) -- 单值专题图子项的单值 返回: self 返回类型: ThemeUniqueItem
-
set_visible(value)¶ 设置单值专题图子项是否可见
参数: value (bool) -- 单值专题图子项是否可见 返回: self 返回类型: ThemeUniqueItem
-
style¶ GeoStyle -- 每个单值专题图子项的显示风格
-
value¶ str -- 单值专题图子项的单值
-
visible¶ bool -- 单值专题图子项是否可见
-
class
iobjectspy.mapping.ThemeUnique(expression=None, default_style=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme单值专题图类。
将字段或表达式的值相同的要素采用相同的风格来显示,从而用来区分不同的类别。例如,在表示土地的面数据中表示土地利用类型的字段中有草地,林地,居民地, 耕地等值,使用单值专题图进行渲染时,每种类型的土地利用类型被赋予一种颜色或填充风格,从而可以看出每种类型的土地利用的分布区域和范围。可用于地质图、 地貌图、植被图、土地利用图、政治行政区划图、自然区划图、经济区划图等。单值专题图着重表示现象质的差别,一般不表示数量的特征。尤其是有交叉或重叠现 象时,此类不推荐使用,例如:民族分布区等。
注意:如果通过连接(Join)或关联(Link)的方式与一个外部表建立了联系,当专题图的专题变量用到外部表的字段时,在显示专题图时,需要调 用
Layer.set_display_filter()方法,否则专题图将出图失败。以下代码演示通过数据集创建默认单值专题图:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['zones'] >>> mmap = Map() >>> theme = ThemeUnique.make_default(dt, 'zone', ColorGradientType.CYANGREEN) >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/unique_theme.png')
也可以通过以下方式创建单值专题图:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['zones'] >>> mmap = Map() >>> default_style = GeoStyle().set_fill_fore_color('yellow').set_fill_back_color('green').set_fill_gradient_mode('RADIAL') >>> theme = ThemeUnique('zone', default_style) >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/unique_theme.png')
或者指定自定义项:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['zones'] >>> >>> theme = ThemeUnique() >>> theme.set_expression('zone') >>> color = [Color.gold(), Color.blueviolet(), Color.rosybrown(), Color.coral()] >>> zone_values = dt.get_field_values(['zone'])['zone'] >>> for index, value in enumerate(zone_values): >>> theme.add(ThemeUniqueItem(value, GeoStyle().set_fill_fore_color(colors[index % 4]), str(index))) >>> >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/unique_theme.png')
参数: - expression (str) -- 单值专题图字段表达式。用于制作单值专题图的字段或字段表达式。该字段可以为要素的某一属性(如地质图中的年代或成份), 其值的数据类型可以为数值型或字符型。
- default_style (GeoStyle) -- 单值专题图的默认风格。对于那些未在单值专题图子项之列的对象使用该风格显示。如未设置,则使用图层默认风格显示。
-
add(item)¶ 添加单值专题图子项。
参数: item (ThemeUniqueItem) -- 单值专题图子项 返回: self 返回类型: ThemeUnique
-
clear()¶ 删除所有单值专题图子项。执行该方法后,所有的单值专题图子项都被释放,不再可用。
返回: self 返回类型: ThemeUnique
-
expression¶ str -- 单值专题图字段表达式。用于制作单值专题图的字段或字段表达式。该字段可以为要素的某一属性(如地质图中的年代或成份),其值的数据类型可 以为数值型或字符型。
-
extend(items)¶ 批量添加单值专题图子项。
参数: items (list[ThemeUniqueItem] or tuple[ThemeUniqueItem]) -- 单值专题图子项列表 返回: self 返回类型: ThemeUnique
-
get_count()¶ 返回: 返回类型: int
-
get_custom_marker_angle_expression()¶ 返回一个字段表达式,该字段表达式用于控制对象对应的点单值题图中点符号的旋转角度,字段表达式中的字段必须为数值型字段。 通过该接口可以指定一个 字段也可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以数值指定的角度统一进行旋转。
返回: 字段表达式 返回类型: str
-
get_custom_marker_size_expression()¶ 返回一个字段表达式,该字段表达式用于控制对象对应的点单值题图中点符号的大小,字段表达式中的字段必须为数值型字段。 通过该接口可以指定一个字段 也可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以数值指定的大小统一显示。
该项设置仅对点单值专题图有效。
返回: 字段表达式 返回类型: str
-
get_item(index)¶ 返回指定序号的单值专题图子项。
参数: index (int) -- 指定的单值专题图子项的序号。 返回: 单值专题图子项 返回类型: ThemeUniqueItem
-
get_offset_x()¶ 返回点、线、面图层制作的单值专题图中的对象相对于原来位置的水平偏移量。
返回: 点、线、面图层制作的单值专题图中的对象相对于原来位置的水平偏移量。 返回类型: str
-
get_offset_y()¶ 返回点、线、面图层制作的单值专题图中的对象相对于原来位置的垂直偏移量。
返回: 点、线、面图层制作的单值专题图中的对象相对于原来位置的垂直偏移量。 返回类型: str
-
index_of(value)¶ 返回单值专题图中指定子项单值在当前序列中的序号。
参数: value (str) -- 给定的单值专题图子项单值。 返回: 返回类型: int
-
insert(index, item)¶ 将给定的单值专题图子项插入到指定序号的位置。
参数: - index (int) -- 指定的单值专题图子项序列的序号。
- item (ThemeUniqueItem) -- 将被插入的单值专题图子项。
返回: 插入成功返回 True,否则返回 False
返回类型: bool
-
is_default_style_visible()¶ 单值专题图默认风格是否可见
返回: 单值专题图默认风格是否可见。 返回类型: bool
-
is_offset_prj_coordinate_unit()¶ 获取水平或垂直偏移量的单位是否是地理坐标系单位
返回: 水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。 返回类型: bool
-
static
make_default(dataset, expression, color_gradient_type=None, join_items=None)¶ 根据给定的矢量数据集和单值专题图字段表达式生成默认的单值专题图。
参数: - dataset (DatasetVector or str) -- 矢量数据集
- expression (str) -- 单值专题图字段表达式。
- color_gradient_type (str or ColorGradientType) -- 颜色渐变模式
- join_items (list[JoinItem] or tuple[JoinItem]) -- 外部表连接项。如果要将制作的专题图添加到地图中,作为地图中的图层,需要对该专题图图层进行以下设置,通过该专题图图层对
应的 Layer 对象的
Layer.set_display_filter()方法,该方法中的 parameter 参数为QueryParameter对象,这里需要通过 QueryParameter 对象的QueryParameter.set_join_items()方法,将专题的外部表 连接项(即当前方法的 join_items 参数)指定给该专题图图层对应的 Layer 对象,这样所做的专题图在地图中显示才正确。
返回: 新的单值专题图
返回类型:
-
static
make_default_four_colors(dataset, color_field, colors=None)¶ 根据指定的面数据集、颜色字段名称、颜色生成默认的四色单值专题图。 四色单值专题图是指在一幅地图上,只用四种颜色就能使具有公共边的面对象着上不 同的颜色。
注意:对于面数据集复杂度低的情形下,采用四种颜色即可生成四色单值专题图;若面数据集复杂度高,则着色结果可能为五色。
参数: - dataset (DatasetVector or str) -- 指定的面数据集。由于该构造函数将修改面数据集的属性信息,因此,需保证 dataset 为非只读。
- color_field (str) -- 着色字段的名称。着色字段必须为整型字段。它可以为面数据集中已有属性字段,也可以是自定义的其它字段。若为已存在属 性字段,需保证该字段类型为整型,系统将修改该字段的属性值,并分别赋值为1、2、3、4;若为自定义的其它字段,需保证 字段名合法,则系统首先在面数据集中创建该字段,并分别赋值为1、2、3、4。由此,着色字段已分别赋值为1、2、3、4, 代表着四种不同的颜色,根据该字段的值即可生成四色专题图。
- colors (Colors) -- 用户传入的用来制作专题图的颜色。系统对传入颜色的数目不做规定,比如,用户只传入了一种颜色,则在生成专题图时,系统 会自动补齐出图所需的颜色。
返回: 四色单值专题图
返回类型:
-
remove(index)¶ 删除一个指定序号的单值专题图子项。
参数: index (int) -- 指定的将被删除的单值专题图子项序列的序号。 返回: 返回类型: bool
-
reverse_style()¶ 对单值专题图中子项的风格进行反序显示。
返回: self 返回类型: ThemeUnique
-
set_custom_marker_angle_expression(value)¶ 设置一个字段表达式,该字段表达式用于控制对象对应的点单值题图中点符号的旋转角度,字段表达式中的字段必须为数值型字段。通过该接口可以指定一个字 段也可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以数值指定的角度统一进行旋转。
该项设置仅对点单值专题图有效。
参数: value (str) -- 字段表达式 返回: self 返回类型: ThemeUnique
-
set_custom_marker_size_expression(value)¶ 设置一个字段表达式,该字段表达式用于控制对象对应的点单值题图中点符号的大小,字段表达式中的字段必须为数值型字段。 通过该接口可以指定一个字段 也可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以数值指定的大小统一显示。
该项设置仅对点单值专题图有效。
参数: value (str) -- 字段表达式 返回: self 返回类型: ThemeUnique
-
set_default_style(style)¶ 设置单值专题图的默认风格。对于那些未在单值专题图子项之列的对象使用该风格显示。如未设置,则使用图层默认风格显示。
参数: style (GeoStyle) -- 返回: self 返回类型: ThemeUnique
-
set_default_style_visible(value)¶ 设置单值专题图默认风格是否可见。
参数: value (bool) -- 单值专题图默认风格是否可见 返回: self 返回类型: ThemeUnique
-
set_expression(value)¶ 设置单值专题图字段表达式。用于制作单值专题图的字段或字段表达式。该字段可以为要素的某一属性(如地质图中的年代或成份),其值的数据类型可以为数值型或字符型。
参数: value (str) -- 指定单值专题图字段表达式 返回: self 返回类型: ThemeUnique
-
set_offset_prj_coordinate_unit(value)¶ 设置水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。具体查看
set_offset_x()和set_offset_y()接口。参数: value (bool) -- 水平或垂直偏移量的单位是否是地理坐标系单位 返回: self 返回类型: ThemeUnique
-
set_offset_x(value)¶ 设置点、线、面图层制作的单值专题图中的对象相对于原来位置的水平偏移量。
偏移量的单位由
set_offset_prj_coordinate_unit()决定, 为True表示采用采用地理坐标单位,否则采用设备单位参数: value (str) -- 点、线、面图层制作的单值专题图中的对象相对于原来位置的水平偏移量。 返回: self 返回类型: ThemeUnique
-
set_offset_y(value)¶ 设置点、线、面图层制作的单值专题图中的对象相对于原来位置的垂直偏移量。
偏移量的单位由
set_offset_prj_coordinate_unit()决定, 为True表示采用采用地理坐标单位,否则采用设备单位参数: value (str) -- 点、线、面图层制作的单值专题图中的对象相对于原来位置的垂直偏移量。 返回: self 返回类型: ThemeUnique
-
class
iobjectspy.mapping.ThemeRangeItem(start, end, caption, style=None, visible=True)¶ 基类:
object分段专题图子项类。 在分段专题图中,将分段字段的表达式的值按照某种分段模式被分成多个范围段。每个分段都有其分段起始值、终止值、名称和风格等。每个分段所表示的范围为 [Start, End)。
参数: - start (float) -- 分段专题图子项的起始值。
- end (float) -- 分段专题图子项的终止值。
- caption (str) -- 分段专题图子项的名称。
- style (GeoStyle) -- 分段专题图子项的显示风格。
- visible (bool) -- 分段专题图中的子项是否可见。
-
caption¶ str -- 分段专题图中子项的名称。
-
end¶ float -- 分段专题图子项的终止值
-
set_caption(value)¶ 设置分段专题图中子项的名称。
参数: value (str) -- 分段专题图中子项的名称。 返回: self 返回类型: ThemeRangeItem
-
set_end(value)¶ 设置分段专题图子项的终止值。
参数: value (float) -- 分段专题图子项的终止值 返回: self 返回类型: ThemeRangeItem
-
set_start(value)¶ 设置分段专题图子项的起始值。
如果该子项是分段中第一个子项,那么该起始值就是分段的最小值;如果子项的序号大于等于 1 的时候,该起始值必须与前一子项的终止值相同,否则系统会抛出异常。
参数: value (float) -- 分段专题图子项的起始值 返回: self 返回类型: ThemeRangeItem
-
set_style(value)¶ 设置分段专题图中每一个分段专题图子项的对应的风格。
参数: value (GeoStyle) -- 分段专题图中每一个分段专题图子项的对应的风格。 返回: self 返回类型: ThemeRangeItem
-
set_visible(value)¶ 设置分段专题图中的子项是否可见。
参数: value (bool) -- 指定分段专题图中的子项是否可见。 返回: self 返回类型: ThemeRangeItem
-
start¶ float -- 分段专题图子项的起始值
-
style¶ GeoStyle -- 返回分段专题图中每一个分段专题图子项的对应的风格。
-
visible¶ bool -- 返回分段专题图中的子项是否可见。
-
class
iobjectspy.mapping.RangeMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了分段专题图的分段方式类型常量。
在分段专题图中,作为专题变量的字段或表达式的值按照某种分段方式被分成多个范围段,要素或记录根据其所对应的字段值或表达式值被分配到其中一个分段中, 在同一个范围段中要素或记录使用相同的风格进行显示。分段专题图一般用来表现连续分布现象的数量或程度特征,如降水量的分布,土壤侵蚀强度的分布等, 从而反映现象在各区域的集中程度或发展水平的分布差异。
SuperMap 组件产品提供多种分类的方法,包括等距离分段法,平方根分段法,标准差分段法,对数分段法,等计数分段法,以及自定义距离法,显然这些分段方法 根据一定的距离进行分段,因而分段专题图所基于的专题变量必须为数值型。
变量: - RangeMode.EUQALINTERVAL --
等距离分段。等距离分段是根据作为专题变量的字段或表达式的最大值和最小值,按照用户设定的分段数进行相等间距的分 段。在等距离分段中,每一段具有相等的长度。求算等距分段的距离间隔公式为:
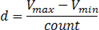
其中,d 为分段的距离间隔,Vmax 为专题变量的最大值,Vmin 为专题变量的最小值,count 为用户指定的分段数。则每一分段的分段点的求算公式为:
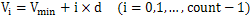
其中,Vi 为分段点的值,i 为从0到 count-1 的正整数,表示各分段,当 i 等于0时,Vi 为 Vmin;当 i 等于 count-1 时,Vi 为 Vmax。
例如你选择一个字段作为专题变量,其值是从1到10,你需要用等距离分段法将其分为4段,则分别为1-2.5,2.5-5,5-7.5和7.5-10。注意, 分段中使用 “” 和 “”,所以分段点的值划归到下一段。
注意:按照这种分段方式,很有可能某个分段中没有数值,即落到该段中的记录或要素为0个。
- RangeMode.SQUAREROOT --
平方根分段。平方根分段方法实质上是对原数据的平方根的等距离分段,其首先取所有数据的平方根进行等距离分段,得到处理 后数据的分段点,然后将这些分段点的值进行平方作为原数据的分段点,从而得到原数据的分段方案。所以,按照这种分段方式, 也很有可能某个分段中没有数值,即落到该段中的记录或要素为0个。该方法适用于一些特定数据,如最小值与最大值之间相差 比较大时,用等距离分段法可能需要分成很多的段才能区分,用平方根分段方法可以压缩数据间的差异,用较少的分段数却比较 准确地进行分段。专题变量的平方根的分段间隔距离计算公式为:
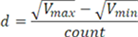
其中,d 为分段的距离间隔,Vmax 为专题变量的最大值,Vmin 为专题变量的最小值,count 为用户指定的分段数。则专题变量的分段的段点的求算公式为:

其中,Vi 为分段点的值,i 为从0到 count-1 的正整数,表示各分段,当 i 等于0时,Vi 为 Vmin。 注意:数据中有负数则不适合这种方法。
- RangeMode.STDDEVIATION --
标准差分段。标准差分段方法反映了各要素的某属性值对其平均值的偏离。该方法首先计算出专题变量的平均值和标准偏差, 在此基础上进行分段。标准差分段的每个分段长度都是一个标准差,最中间的那一段以平均值为中心,左边分段点和右边分段 点分别与平均值相差0.5个标准差。设专题变量值的平均值为 mean,标准偏差为 std,则分段效果如图所示:

例如对专题变量为1-100之间的值,且专题变量的平均值为50,标准偏差为20,则分段为40-60,20-40,60-80,0-20,80-100共5段。 落在不同分段范围内的要素分别被设置为不同的显示风格。
注意:标准差的段数由计算结果决定,用户不可控制。
- RangeMode.LOGARITHM --
对数分段。对数分段方法的实现的原理与平方根分段方法基本相同,所不同的是平方根方法是对原数据取平方根,而对数分段方 法是对原数据取对数,即对原数据的以10为底的对数值的等距离分段,其首先对原数据所有值的对数进行等距离分段,得到处 理后数据的分段点,然后以10为底,这些分段点的值作为指数的幂得到原数据的各分段点的值,从而得到分段方案。适用于最大 值与最小值相差很大,用等距离分段不是很理想的情况,对数分段法比平方根分段法具有更高的压缩率,使数据间的差异尺度更 小,优化分段结果。专题变量的对数的等距离分段的距离间隔的求算公式为:
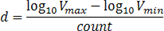
其中,d 为分段的距离间隔,Vmax 为专题变量的最大值,Vmin 为专题变量的最小值,count 为用户指定的分段数。从而专题变量的分段点的求算公式为:
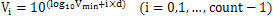
其中,Vi 为分段点的值,i 为从0到 count-1 的正整数,表示各分段,当 i 等于0时,Vi 为 Vmin;当 i 等于 count-1 时,Vi 为 Vmax。 注意:数据中有负数则不适合这种方法。
- RangeMode.QUANTILE --
等计数分段。在等计数分段中,尽量保证每一段内的对象个数尽可能的相等。这个相等的个数是多少是由用户指定的分段数以及实 际的要素个数来决定的,在可以均分的情况下,每段中对象数目应该是一样的,但是当每段对象数据均分时,分段结果的最后几段 会多一个对象。 比如,有9个对象,分9段的话,每段一个对象;分8段的话,前7段是1个对象,第8段是2个对象;分7段的话, 前5段是1个对象,第6段和第7段是2个对象。这种分段方法适合于线性分布的数据。等计数分段的每段中的要素个数的求算公式为:
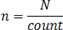
其中,n 为每段中的要素个数,N 为要进行分段的要素的总个数,count 为用户指定的分段数。当 n 的计算结果不是整数时,采用取整方式。
- RangeMode.CUSTOMINTERVAL --
自定义分段。在自定义分段中,由用户指定各段的长度,即间隔距离来进行分段,分段数由 SuperMap 根据指定的间隔 距离以及专题变量的最大和最小值来计算。各分段点的求算公式为:
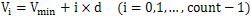
其中,Vi 为各分段点的值,Vmin 为专题变量的最小值,d 为用户指定的距离,count 为计算出来的分段数,i 为从0到 count-1 的正整数,表示各分段,当 i 等于0时,Vi 为 Vmin;当 i 等于 count-1 时,Vi 为 Vmax。
- RangeMode.NONE -- 空分段模式
-
CUSTOMINTERVAL= 5¶
-
EUQALINTERVAL= 0¶
-
LOGARITHM= 3¶
-
NONE= 6¶
-
QUANTILE= 4¶
-
SQUAREROOT= 1¶
-
STDDEVIATION= 2¶
- RangeMode.EUQALINTERVAL --
-
class
iobjectspy.mapping.ThemeRange(expression=None, items=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme分段专题图类。 按照提供的分段方法对字段的属性值进行分段,并根据每个属性值所在的分段范围赋予相应对象的显示风格。
注意: 制作分段专题图,如果首尾区间没有设置风格,且没有设置默认风格,那么无论是添加到首部还是尾部,首尾区间默认采用用户所添加的第一个分段的风格,比如: 总共分5段,
add()方法依次添加 [0,1)、[1,2)、[2,4)三段,那么首区间(负无穷,0),尾区间[4,正无穷),采用[0,1)的风格。以下代码演示通过数据集创建默认分段专题图:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['zones'] >>> mmap = Map() >>> theme = ThemeRange.make_default(dt, 'SmID', RangeMode.EUQALINTERVAL, 6, ColorGradientType.RAINBOW) >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/range_theme.png')
也可以通过以下方式创建单值专题图:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['zones'] >>> >>> theme = ThemeRange('SmID') >>> theme.add(ThemeRangeItem(1, 20, GeoStyle().set_fill_fore_color('gold'), '1'), is_add_to_head=True) >>> theme.add(ThemeRangeItem(20, 50, GeoStyle().set_fill_fore_color('rosybrown'), '2'), is_add_to_head=False) >>> theme.add(ThemeRangeItem(50, 90, GeoStyle().set_fill_fore_color('coral'), '3'), is_add_to_head=False) >>> theme.add(ThemeRangeItem(90, 160, GeoStyle().set_fill_fore_color('crimson'), '4'), is_add_to_head=False) >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/range_theme.png')
参数: - expression (str) -- 分段字段表达式。
- items (list[ThemeRangeItem] or tuple[ThemeRangeItem]) -- 分段专题图子项列表
-
add(item, is_normalize=True, is_add_to_head=False)¶ 添加分段专题图子项
参数: - item (ThemeRangeItem) -- 分段专题图子项
- is_normalize (bool) -- 表示是否规整化,is_normalize 为 True 时, item 值不合法,则进行规整,is_normalize 为 Fasle 时, item 值不合法则抛异常。
- is_add_to_head (bool) -- 是否添加到分段列表的开头。如果为 False,则添加到分段列表的尾部。
返回: self
返回类型:
-
clear()¶ 删除分段专题图的所有分段子项。执行该方法后,所有的分段专题图子项都被释放,不再可用。
返回: self 返回类型: ThemeRange
-
expression¶ str -- 分段字段表达式
-
extend(items)¶ 批量添加分段专题图子项
参数: items (list[ThemeRangeItem] or tuple[ThemeRangeItem]) -- 分段专题图子项列表 返回: self 返回类型: ThemeRange
-
get_count()¶ 返回分段专题图中分段的个数
返回: 分段专题图中分段的个数 返回类型: int
-
get_custom_interval()¶ 获取自定义段长
返回: 自定位段长 返回类型: float
-
get_item(index)¶ 返回指定序号的分段专题图中分段专题图子项
参数: index (int) -- 指定的分段专题图序号 返回: 分段专题图中分段专题图子项 返回类型: ThemeRangeItem
-
get_offset_x()¶ 获取水平方向偏移量
返回: 水平方向偏移量 返回类型: str
-
get_offset_y()¶ 获取垂直方向偏移量
返回: 垂直方向偏移量 返回类型: str
-
get_precision()¶ 获取范围分段专题图的舍入精度。
返回: 舍入精度 返回类型: float
-
index_of(value)¶ 返回分段专题图中指定分段字段值在当前分段序列中的序号。
参数: value (str) -- 给定的分段字段值。 返回: 分段字段值在分段序列中的序号。如果该值不存在,就返回 -1。 返回类型: int
-
is_offset_prj_coordinate_unit()¶ 获取水平或垂直偏移量的单位是否是地理坐标系单位
返回: 水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。 返回类型: bool
-
static
make_default(dataset, expression, range_mode, range_parameter, color_gradient_type=None, range_precision=0.1, join_items=None)¶ 根据给定的矢量数据集、分段字段表达式、分段模式、相应的分段参数、颜色渐变填充模式、外部连接表项和舍入精度,生成默认的分段专题图。
注意:通过连接外部表的方式制作专题图时,对于 UDB 数据源,连接类型不支持内连接,即不支持
JoinType.INNERJOIN连接类型。参数: - dataset (DatasetVector or str) -- 矢量数据集。
- expression (str) -- 分段字段表达式
- range_mode (str or RangeMode) -- 分段模式
- range_parameter (float) -- 分段参数。当分段模式为等距离分段法,平方根分段,对数分段法,等计数分段法其中一种时,该参数为分段个数; 当分段模式为标准差分段法的时候,该参数不起作用;当分段模式为自定义距离时,该参数表示自定义距离。
- color_gradient_type (ColorGradientType or str) -- 颜色渐变模式
- range_precision (float) -- 分段值的精度。如,计算得到的分段值为13.02145,而分段精度为0.001,则分段值取13.021
- join_items (list[JoinItem] or tuple[JoinItem]) -- 外部表连接项。如果要将制作的专题图添加到地图中,作为地图中的图层,需要对该专题图图层进行以下设置,通过该专题图图层对
应的 Layer 对象的
Layer.set_display_filter()方法,该方法中的 parameter 参数为QueryParameter对象,这里需要通过 QueryParameter 对象的QueryParameter.set_join_items()方法,将专题的外部表 连接项(即当前方法的 join_items 参数)指定给该专题图图层对应的 Layer 对象,这样所做的专题图在地图中显示才正确。
返回: 结果分段专题图对象
返回类型:
-
range_mode¶ RangeMode -- 分段模式
-
reverse_style()¶ 对分段专题图中分段的风格进行反序显示。比如,专题图有三个分段,分别为 item1,item2,item3,调用反序显示后,item3 的风格与 item1 会调换,item2 的显示风格不变。
返回: self 返回类型: ThemeRange
-
set_expression(value)¶ 设置分段字段表达式。 通过对比某要素分段字段表达式的值与(按照一定的分段模式确定的)各分段范围的分段值,来确定该要素所在的范围段,从而对落在不同分段内的要素设置为不同的风格。
参数: value (str) -- 指定分段字段表达式。 返回: self 返回类型: ThemeRange
-
set_offset_prj_coordinate_unit(value)¶ 设置水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。具体查看
set_offset_x()和set_offset_y()接口。参数: value (bool) -- 水平或垂直偏移量的单位是否是地理坐标系单位 返回: self 返回类型: ThemeRange
-
set_offset_x(value)¶ 设置水平方向偏移量。
偏移量的单位由
set_offset_prj_coordinate_unit()决定, 为True表示采用采用地理坐标单位,否则采用设备单位参数: value (str) -- 水平方向偏移量。 返回: self 返回类型: ThemeRange
-
set_offset_y(value)¶ 设置垂直方向偏移量。
偏移量的单位由
set_offset_prj_coordinate_unit()决定, 为True表示采用采用地理坐标单位,否则采用设备单位参数: value (str) -- 返回: self 返回类型: ThemeRange
-
set_precision(value)¶ 设置范围分段专题图的舍入精度。
如,计算得到的分段值为13.02145,而分段精度为0.001,则分段值取13.021。
参数: value (float) -- 舍入精度 返回: self 返回类型: ThemeRange
-
class
iobjectspy.mapping.MixedTextStyle(default_style=None, styles=None, separator=None, split_indexes=None)¶ 基类:
object文本复合风格类。
该类主要用于对标签专题图中标签的文本内容进行风格设置。通过该类用户可以使标签的文字显示不同的风格,比如文本 “喜马拉雅山”,通过本类可以将前三个字用红色显示,后两个字用蓝色显示。
对同一文本设置不同的风格实质上是对文本的字符进行分段,同一分段内的字符具有相同的显示风格。对字符分段有两种方式,一种是利用分隔符对文本进行分段;另一种是根据分段索引值进行分段。
- 利用分隔符对文本进行分段 比如用“&”作分隔符,它将文本“5&109”分为“5”和“109”两部分,在显示时,“5”和分隔符“&”使用同一个风格,字符串“109”使用相同的风格。
- 利用分段索引值进行分段 文本中字符的索引值是以0开始的整数,比如文本“珠穆朗玛峰”,第一个字符(“珠”)的索引值为0,第二个字符(“穆”)的索引值为1, 以此类推;当设置分段索引值为1,3,4,9时,字符分段范围相应的就是(-∞,1),[1,3),[3,4),[4,9),[9,+∞),可以看出索引号为0的字符(即“珠” ) 在第一个分段内,索引号为1,2的字符(即“穆”、“朗”)位于第二个分段内,索引号为3的字符(“玛”)在第三个分段内,索引号为4的字符(“峰”)在第四个分段内,其余分段中没有字符。
参数: -
default_style¶ TextStyle -- 缺省时的风格
-
get_separator()¶ 获取文本的分隔符
返回: 文本的分隔符。 返回类型: str
-
get_split_indexes()¶ 返回分段索引值,分段索引值用来对文本中的字符进行分段
返回: 返回分段索引值 返回类型: list[int]
-
is_separator_enabled¶ bool -- 文本的分隔符是否有效
-
set_default_style(value)¶ 设置缺省时的风格
参数: value (TextStyle) -- 缺省时的风格 返回: self 返回类型: MixedTextStyle
-
set_separator(value)¶ 设置文本的分隔符,分隔符的风格采用默认风格,并且分隔符只能设置一个字符。
文本的分隔符是一个将文本分割开的符号,比如用“_”作分隔符,它将文本“5_109”分为“5”和“109”两部分,假设有风格数组:style1、style2和默认文 本风格DefaultStyle。在显示时,“5”使用Style1风格显示,分隔符“_”使用默认风格(DefaultStyle),字符“1”,“0”,“9”使用Style2的风格。
参数: value (str) -- 指定文本的分隔符 返回: self 返回类型: MixedTextStyle
-
set_separator_enabled(value)¶ 设置文本的分隔符是否有效。 分隔符有效时利用分隔符对文本进行分段;无效时根据文本中字符的位置进行分段。分段后,同一分段内的字符具有相同的显示风格。
参数: value (bool) -- 文本的分隔符是否有效 返回: self 返回类型: MixedTextStyle
-
set_split_indexes(value)¶ 设置分段索引值,分段索引值用来对文本中的字符进行分段。
文本中字符的索引值是以 0 开始的整数,比如文本“珠穆朗玛峰”,第一个字符(“珠”)的索引值为0,第二个字符(“穆”)的索引值为1,以此类推;当设置 分段索引值为1,3,4,9时,字符分段范围相应的就是(-∞,1),[1,3),[3,4),[4,9),[9,+∞),可以看出索引号为0的字符(即“珠” )在第一个 分段内,索引号为1,2的字符(即“穆”、“朗”)位于第二个分段内,索引号为3的字符(“玛”)在第三个分段内,索引号为4的字符(“峰”)在第四个分段内, 其余分段中没有字符。
参数: value (list[int] or tuple[int]) -- 指定分段索引值 返回: self 返回类型: MixedTextStyle
-
set_styles(value)¶ 设置文本样式集合。文本样式集合中的样式用于不同分段内的字符。
参数: value (list[TextStyle] or tuple[TextStyle]) -- 文本样式集合 返回: self 返回类型: MixedTextStyle
-
styles¶ list[TextStyle] -- 文本样式集合
-
class
iobjectspy.mapping.LabelMatrix(cols, rows)¶ 基类:
object矩阵标签类。
通过该类可以制作出复杂的标签来标注对象。该类可以包含 n*n 个矩阵标签元素,矩阵标签元素的类型可以是图片,符号,标签专题图等。目前支持的矩阵标签元 素类型为
LabelMatrixImageCell,LabelMatrixSymbolCell,ThemeLabel,传入其他类型将 会抛出异常。 不支持矩阵标签元素中包含矩阵标签,矩阵标签元素不支持含有特殊符号的表达式,不支持沿线标注。以下代码示范了如何通过 LabelMatrix 类制作复杂的标签来标注对象:
>>> label_matrix = LabelMatrix(2,2) >>> label_matrix.set(0, 0, LabelMatrixImageCell('path', 5, 5, is_size_fixed=False)) >>> label_matrix.set(1, 0, ThemeLabel().set_label_expression('Country')) >>> label_matrix.set(0, 1, LabelMatrixSymbolCell('Symbol', GeoStyle.point_style(0, 0, (6,6), 'red'))) >>> label_matrix.set(1, 1, ThemeLabel().set_label_expression('Capital')) >>> theme_label = ThemeLabel() >>> theme_label.set_matrix_label(label_matrix)
参数: - cols (int) -- 列数
- rows (int) -- 行数
-
cols¶ int -- 列数
-
get(col, row)¶ 设置指定行列位置处所对应的对象。
参数: - col (int) -- 指定的列数
- row (int) -- 指定的行数
返回: 指定行列位置处所对应的对象
返回类型:
-
rows¶ int -- 行数
-
set(col, row, value)¶ 设置指定行列位置处所对应的对象。
参数: - col (int) -- 指定的列数。
- row (int) -- 指定的行数
- value (LabelMatrixImageCell or LabelMatrixSymbolCell or ThemeLabel) -- 指定行列位置处所对应的对象
返回: self
返回类型:
-
class
iobjectspy.mapping.LabelMatrixImageCell(path_field, width=1.0, height=1.0, rotation=0.0, is_size_fixed=False)¶ 基类:
object图片类型的矩阵标签元素类。
该类型的对象可作为矩阵标签对象中的一个矩阵标签元素
具体参考
LabelMatrix.参数: - path_field (str) -- 记录了图片类型的矩阵标签元素所使用图片的路径的字段名称。
- width (float) -- 图片的宽度,单位为毫米
- height (float) -- 图片的高度,单位为毫米。
- rotation (float) -- 图片的旋转角度。
- is_size_fixed (bool) -- 图片的大小是否固定
-
height¶ float -- 返回图片的高度,单位为毫米
-
is_size_fixed¶ bool -- 图片的大小是否固定
-
path_field¶ str
-
rotation¶ float -- 图片的旋转角度
-
set_height(value)¶ 设置图片的高度,单位为毫米
参数: value (float) -- 图片的高度 返回: self 返回类型: LabelMatrixImageCell
-
set_path_field(value)¶ 参数: value (str) -- 返回: self 返回类型: LabelMatrixImageCell
-
set_rotation(value)¶ 设置图片的旋转角度。
参数: value (float) -- 图片的旋转角度。 返回: self 返回类型: LabelMatrixImageCell
-
set_size_fixed(value)¶ 设置图片的大小是否固定
参数: value (bool) -- 图片的大小是否固定 返回: self 返回类型: LabelMatrixImageCell
-
set_width(value)¶ 设置图片的宽度,单位为毫米
参数: value (float) -- 图片的宽度,单位为毫米 返回: self 返回类型: LabelMatrixImageCell
-
width¶ float -- 返回图片的宽度,单位为毫米
-
class
iobjectspy.mapping.LabelMatrixSymbolCell(symbol_id_field, style=None)¶ 基类:
object符号类型的矩阵标签元素类。
该类型的对象可作为矩阵标签对象中的一个矩阵标签元素。
具体参考
LabelMatrix.参数: - symbol_id_field (str) -- 记录所使用符号 ID 的字段名称。
- style (GeoStyle) -- 所使用符号的样式
-
set_style(value)¶ 设置所使用符号的样式
参数: value (GeoStyle) -- 所使用符号的样式 返回: self 返回类型: LabelMatrixSymbolCell
-
set_symbol_id_field(value)¶ 设置记录所使用符号 ID 的字段名称。
参数: value (str) -- 记录所使用符号 ID 的字段名称。 返回: self 返回类型: LabelMatrixSymbolCell
-
style¶ GeoStyle -- 返回所使用符号的样式
-
symbol_id_field¶ str -- 返回记录所使用符号 ID 的字段名称。
-
class
iobjectspy.mapping.LabelBackShape¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了标签专题图中标签背景的形状类型常量。
标签背景是 SuperMap iObjects 支持的一种标签的显示风格,是使用一定颜色的各种形状作为各标签背景,从而可以突出显示标签或者使标签专题图更美观。
变量: - LabelBackShape.NONE -- 空背景, 不使用任何的形状作为标签的背景。
- LabelBackShape.RECT -- 矩形背景。标签背景的形状为矩形
- LabelBackShape.ROUNDRECT -- 圆角矩形背景。标签背景的形状为圆角矩形
- LabelBackShape.ELLIPSE -- 椭圆形背景。标签背景的形状为椭圆形
- LabelBackShape.DIAMOND -- 菱形背景。标签背景的形状为菱形
- LabelBackShape.TRIANGLE -- 三角形背景。标签背景的形状为三角形
- LabelBackShape.MARKER -- 符号背景。标签背景的形状为设定的符号,该符号可以分别通过
ThemeLabel.set_back_style()的方法来设置。
-
DIAMOND= 4¶
-
ELLIPSE= 3¶
-
MARKER= 6¶
-
NONE= 0¶
-
RECT= 1¶
-
ROUNDRECT= 2¶
-
TRIANGLE= 5¶
-
class
iobjectspy.mapping.AvoidMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该枚举定义了标签专题图中标签文本的避让方式类型常量。
变量: - AvoidMode.TWO -- 两方向文本避让。
- AvoidMode.FOUR -- 四方向文本避让
- AvoidMode.EIGHT -- 八方向文本避让。
- AvoidMode.FREE -- 环绕文本避让。
-
EIGHT= 3¶
-
FOUR= 2¶
-
FREE= 4¶
-
TWO= 1¶
-
class
iobjectspy.mapping.AlongLineCulture¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了沿线标注文字显示习惯的类型常量。
变量: - AlongLineCulture.ENGLISH -- 以英文习惯显示,文字的走向总是与线的方向垂直。
- AlongLineCulture.CHINESE -- 以中文习惯显示,在线与水平方向的角度属于[]时,文字方向与线的方向平行,否则垂直。
-
CHINESE= 1¶
-
ENGLISH= 0¶
-
class
iobjectspy.mapping.AlongLineDirection¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了标签沿线标注方向类型常量。 路线与水平方向的锐角夹角在 60 度以上表示上下方向,60 度以下表示左右方向
变量: - AlongLineDirection.ALONG_LINE_NORMAL -- 沿线的法线方向放置标签。
- AlongLineDirection.LEFT_TOP_TO_RIGHT_BOTTOM -- 从上到下,从左到右放置。
- AlongLineDirection.RIGHT_TOP_TO_LEFT_BOTTOM -- 从上到下,从右到左放置。
- AlongLineDirection.LEFT_BOTTOM_TO_RIGHT_TOP -- 从下到上,从左到右放置。
- AlongLineDirection.RIGHT_BOTTOM_TO_LEFT_TOP -- 从下到上,从右到左放置。
-
ALONG_LINE_NORMAL= 0¶
-
LEFT_BOTTOM_TO_RIGHT_TOP= 3¶
-
LEFT_TOP_TO_RIGHT_BOTTOM= 1¶
-
RIGHT_BOTTOM_TO_LEFT_TOP= 4¶
-
RIGHT_TOP_TO_LEFT_BOTTOM= 2¶
-
class
iobjectspy.mapping.AlongLineDrawingMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了标签沿线标注绘制策略类型常量。
SuperMap GIS 8C(2017)版本开始,调整了沿线标注的绘制策略,为了兼容以前版本,提供了一个“兼容绘制”选项。
在新的绘制策略中,用户可根据实际应用需求,选择标签绘制的方式是将标签作为一个整体绘制还是将标签中的文字和字母拆分开绘制。一般情况下沿线标注中,采用 拆分绘制,标签与被标注的线走势相吻合;如果为整行绘制,那么标签将作为一个整体,此设置一般用于带背景标签的沿线标注。
变量: - AlongLineDrawingMode.COMPATIBLE -- 兼容绘制
- AlongLineDrawingMode.WHOLEWORD -- 整行绘制
- AlongLineDrawingMode.EACHWORD -- 拆分绘制
-
COMPATIBLE= 0¶
-
EACHWORD= 2¶
-
WHOLEWORD= 1¶
-
class
iobjectspy.mapping.OverLengthLabelMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了标签专题图中超长标签的处理模式类型常量。
对于标签的长度超过设置的标签最大长度的标签称为超长标签, 标签的最大长度可以通过
ThemeLabel.set_overlength_label()方法来返回 和设置。 SuperMap 组件产品提供三种超长标签的处理方式来控制超长标签的显示行为。变量: - OverLengthLabelMode.NONE -- 对超长标签不进行处理。
- OverLengthLabelMode.OMIT -- 省略超出部分。此模式将超长标签中超出指定的标签最大长度(MaxLabelLength)的部分用省略号表示。
- OverLengthLabelMode.NEWLINE -- 换行显示。此模式将超长标签中超出指定的标签最大长度的部分换行显示,即用多行来显示超长标签。
-
NEWLINE= 2¶
-
NONE= 0¶
-
OMIT= 1¶
-
class
iobjectspy.mapping.ThemeLabelRangeItem(start, end, caption, style, visible=True, offset_x=0.0, offset_y=0.0)¶ 基类:
object分段标签专题图子项。
分段标签专题图是指对对象标签基于指定字段表达式的值进行分段,同一段内的对象标签相同的风格显示,不同段的标签使用不同风格显示。其中,一个分段对应一个 分段标签专题图子项。
参数: - start (float) -- 子项对应分段的起始值。
- end (float) -- 子项对应分段的终止值。
- caption (str) -- 子项的名称。
- style (TextStyle) -- 子项的文本风格。
- visible (bool) -- 分段标签专题图子项是否可见
- offset_x (float) -- 子项中的标签在 X 方向偏移量。
- offset_y (float) -- 子项中的标签在 Y 方向偏移量。
-
caption¶ str -- 子项的名称。
-
end¶ float -- 子项对应分段的终止值。
-
offset_x¶ float -- 子项中的标签在X方向偏移量。
-
offset_y¶ float -- 子项中的标签在Y方向偏移量。
-
set_caption(value)¶ 设置子项的名称。
参数: value (str) -- 子项的名称。 返回: self 返回类型: ThemeLabelRangeItem
-
set_end(value)¶ 设置子项对应分段的终止值。
参数: value (float) -- 返回: self 返回类型: ThemeLabelRangeItem
-
set_offset_x(value)¶ 设置子项中的标签在X方向偏移量
参数: value (float) -- 子项中的标签在X方向偏移量 返回: self 返回类型: ThemeLabelRangeItem
-
set_offset_y(value)¶ 设置子项中的标签在Y方向偏移量。
参数: value (float) -- 子项中的标签在Y方向偏移量。 返回: self 返回类型: ThemeLabelRangeItem
-
set_start(value)¶ 设置子项对应分段的起始值。
参数: value (float) -- 子项对应分段的起始值。 返回: self 返回类型: ThemeLabelRangeItem
-
set_style(value)¶ 设置子项的文本风格
参数: value (TextStyle) -- 子项的文本风格 返回: self 返回类型: ThemeLabelRangeItem
-
set_visible(value)¶ 设置分段标签专题图子项是否可见
参数: value (bool) -- 分段标签专题图子项是否可见 返回: self 返回类型: ThemeLabelRangeItem
-
start¶ float -- 子项对应分段的起始值。
-
style¶ TextStyle -- 子项的文本风格
-
visible¶ bool -- 分段标签专题图子项是否可见
-
class
iobjectspy.mapping.ThemeLabelRangeItems(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase分段标签专题图子项集合。
分段标签专题图是指对对象标签基于指定字段表达式的值进行分段,同一段内的对象标签相同的风格显示,不同段的标签使用不同风格显示。其中,一个分段对应 一个分段标签专题图子项。
-
add(item, is_normalize=True, is_add_to_head=False)¶ 添加分段标签专题图子项
参数: - item (ThemeLabelRangeItem) -- 分段标签专题图子项
- is_normalize (bool) -- 是否对不合法的子项进行修正,True进行修正,False 不进行修正并抛异常提示改子项为不合法值。
- is_add_to_head (bool) -- 是否添加到列表的头部,为 True 时添加到列表的头部,为 False 时添加到尾部。
返回: self
返回类型:
-
clear()¶ 删除分段标签专题图的子项。 执行该方法后,所有的标签专题图子项都被释放,不再可用。
返回: self 返回类型: ThemeLabelRangeItems
-
extend(items, is_normalize=True)¶ 批量添加分段标签专题图子项。默认按顺序添加到子项列表的末尾。
参数: - items (list[ThemeLabelRangeItem] or tuple[ThemeLabelRangeItem]) -- 分段标签专题图子项列表
- is_normalize (bool) -- 是否对不合法的子项进行修正,True进行修正,False 不进行修正并抛异常提示改子项为不合法值。
返回: self
返回类型:
-
get_count()¶ 返回分段标签专题图子项集合中的子项个数。
返回: 分段标签专题图子项集合中的子项个数 返回类型: int
-
get_item(index)¶ 返回指定序号的分段标签专题图子项集合中的子项。
参数: index (int) -- 指定的分段标签专题图子项的序号。 返回: 指定序号的分段标签专题图子项集合中的子项。 返回类型: ThemeLabelRangeItem
-
index_of(value)¶ 返回标签专题图中指定分段字段值在当前分段序列中的序号。
参数: value (str) -- 给定的分段字段值。 返回: 分段字段值在分段序列中的序号。如果该值不存在,就返回-1。 返回类型: int
-
reverse_style()¶ 对分段标签专题图中分段的风格进行反序显示。
返回: self 返回类型: ThemeLabelRangeItems
-
-
class
iobjectspy.mapping.ThemeLabelUniqueItem(unique_value, caption, style, visible=True, offset_x=0.0, offset_y=0.0)¶ 基类:
object单值标签专题图子项。
单值标签专题图是指对对象标签基于指定字段表达式的值进行分类,值相同的对象标签为一类使用相同的风格显示,不同类的标签使用不同风格显示;其中,一个单 值对应一个单值标签专题图子项。
参数: - unique_value (str) -- 单值。
- caption (str) -- 单值标签专题图子项的名称。
- style (TextStyle) -- 单值对应的文本风格
- visible (bool) -- 单值标签专题图子项是否可见
- offset_x (float) -- 子项中的标签在X方向偏移量
- offset_y (float) -- 子项中的标签在Y方向偏移量
-
caption¶ str -- 单值标签专题图子项的名称
-
offset_x¶ float -- 子项中的标签在X方向偏移量
-
offset_y¶ float -- 子项中的标签在Y方向偏移量
-
set_caption(value)¶ 设置单值标签专题图子项的名称
参数: value (str) -- 返回: self 返回类型: ThemeLabelUniqueItem
-
set_offset_x(value)¶ 设置子项中的标签在X方向偏移量。
参数: value (float) -- 子项中的标签在X方向偏移量 返回: self 返回类型: ThemeLabelUniqueItem
-
set_offset_y(value)¶ 设置子项中的标签在Y方向偏移量。
参数: value (float) -- 子项中的标签在Y方向偏移量 返回: self 返回类型: ThemeLabelUniqueItem
-
set_style(value)¶ 参数: value (TextStyle) -- 返回: self 返回类型: ThemeLabelUniqueItem
-
set_unique_value(value)¶ 设置单值标签专题图子项对应的单值。
参数: value (str) -- 单值标签专题图子项对应的单值。 返回: self 返回类型: ThemeLabelUniqueItem
-
set_visible(value)¶ 设置单值标签专题图子项是否可见。True 表示可见,False表示不可见。
参数: value (bool) -- 单值标签专题图子项是否可见 返回: self 返回类型: ThemeLabelUniqueItem
-
style¶ TextStyle
-
unique_value¶ str -- 返回单值标签专题图子项对应的单值。
-
visible¶ bool -- 返回单值标签专题图子项是否可见。
-
class
iobjectspy.mapping.ThemeLabelUniqueItems(java_object)¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase单值标签专题图子项集合。
单值标签专题图是指对对象标签基于指定字段表达式的值进行分类,值相同的对象标签为一类使用相同的风格显示,不同类的标签使用不同风格显示;其中,一个单 值对应一个单值标签专题图子项。
-
add(item)¶ 向单值标签专题图子项集合中添加一个子项。
参数: item (ThemeLabelUniqueItem) -- 要添加到集合中的单值标签专题图子项 返回: self 返回类型: ThemeLabelUniqueItems
-
clear()¶ 删除单值标签专题图子项集合中的子项。 执行该方法后,所有的单值标签专题图子项都被释放,不再可用。
返回: self 返回类型: ThemeLabelUniqueItems
-
extend(items)¶ 批量添加单值标签专题图子项
参数: items (list[ThemeLabelUniqueItem] or tuple[ThemeLabelUniqueItem]) -- 单值标签专题图子项集合 返回: self 返回类型: ThemeLabelUniqueItems
-
get_count()¶ 返回单值标签专题图子项集合中的子项个数。
返回: 单值标签专题图子项集合中的子项个数 返回类型: int
-
get_default_offset_x()¶ 返回单值标签专题图默认子项中标签在X方向上的偏移量
返回: 单值标签专题图默认子项中标签在X方向上的偏移量 返回类型: float
-
get_default_offset_y()¶ 返回单值标签专题图默认子项中标签在Y方向上的偏移量
返回: 单值标签专题图默认子项中标签在Y方向上的偏移量 返回类型: float
-
get_item(index)¶ 返回指定序号的单值标签专题图子项集合中的子项
参数: index (int) -- 指定序号 返回: 单值标签专题图子项 返回类型: ThemeLabelUniqueItem
-
insert(index, item)¶ 向单值标签专题图子项集合中插入一个子项。
参数: - index (int) -- 指定子项插入的序号位置。
- item (ThemeLabelUniqueItem) -- 指定的要添加到集合中的单值标签专题图子项。
返回: 插入成功返回 True,否则返回 False。
返回类型: bool
-
remove(index)¶ 移除集合中指定序号位置处的单值标签专题图子项。
参数: index (int) -- 要移除的单值标签专题图子项的序号 返回: 移除成功返回 True,否则返回 False 返回类型: bool
-
reverse_style()¶ 对单值标签专题图中单值风格进行反序显示。
返回: self 返回类型: ThemeLabelUniqueItems
-
set_default_offset_x(value)¶ 设置单值标签专题图默认子项中标签在X方向上的偏移量
参数: value (float) -- 单值标签专题图默认子项中标签在X方向上的偏移量 返回: self 返回类型: ThemeLabelUniqueItems
-
set_default_offset_y(value)¶ 设置单值标签专题图默认子项中标签在Y方向上的偏移量
参数: value (float) -- 单值标签专题图默认子项中标签在Y方向上的偏移量 返回: self 返回类型: ThemeLabelUniqueItems
-
set_default_style(style)¶ 设置单值标签专题图默认子项的文本风格,该默认风格用于未指定对应单值的子项。
参数: style (GeoStyle) -- 单值标签专题图默认子项的文本风格 返回: self 返回类型: ThemeLabelUniqueItems
-
-
class
iobjectspy.mapping.ThemeLabel¶ 基类:
iobjectspy._jsuperpy.mapping.Theme标签专题图类。
标签专题图的标注可以是数字、字母与文字,例如:河流、湖泊、海洋、山脉、城镇、村庄等地理名称,高程、等值线数值、河流流速、公路段里程、航海线里程等。
在标签专题图中,你可以对标签的显示风格和位置进行设置或控制,你可以为所有的标签都设置统一的显示风格和位置选项来显示;也可以通过单值标签专题图,基于 指定字段表达式的值进行分类,值相同的对象标签为一类使用相同的风格显示,不同类的标签使用不同风格显示;还可以通过分段标签专题图,基于指定字段表达式的 值进行分段,同一段内的对象标签相同的风格显示,不同段的标签使用不同风格显示。
标签专题图有多种类型:统一标签专题图、单值标签专题图、复合风格标签专题图、分段标签专题图以及自定义标签专题图,通过ThemeLabel类可以实现以上所有 风格标签专题图的设置,建议用户不要同时设置两种或两种以上的风格,如果同时设置了多种风格,标签专题图的显示将按照下表的优先级情况进行风格显示:
注意:地图上一般还会出现图例说明,图名,比例尺等等,那些都是制图元素,不属于标签专题图标注的范畴
注意:如果通过连接(Join)或关联(Link)的方式与一个外部表建立了联系,当专题图的专题变量用到外部表的字段时,在显示专题图时,需要调 用
Layer.set_display_filter()方法,否则专题图将出图失败。构建统一风格标签专题图:
>>> text_style = TextStyle().set_fore_color(Color.rosybrown()).set_font_name('微软雅黑') >>> theme = ThemeLabel().set_label_expression('zone').set_uniform_style(text_style)
构建默认单值标签专题图:
>>> theme = ThemeLabel.make_default_unique(dataset, 'zone', 'color_field', ColorGradientType.CYANGREEN)
构建默认分段标签专题图:
>>> theme = ThemeLabel.make_default_range(dataset, 'zone', 'color_field', RangeMode.EUQALINTERVAL, 6)
构建复合风格标签专题图:
>>> mixed_style = MixedTextStyle() >>> mixed_style.set_default_style(TextStyle().set_fore_color('rosybrown')) >>> mined_style.set_separator_enabled(True).set_separator("_") >>> theme = ThemeLabel().set_label_expression('zone').set_uniform_mixed_style(mixed_style)
-
get_along_line_culture()¶ 返回沿线标注使用的语言文化习惯。默认值与当前系统的非 Unicode 语言相关。如果是中文环境,为 CHINESE,否则为 ENGLISH。
返回: 沿线标注使用的语言文化习惯 返回类型: AlongLineCulture
-
get_along_line_direction()¶ 返回标签沿线标注方向。默认值
AlongLineDirection.ALONG_LINE_NORMAL.返回: 标签沿线标注方向。 返回类型: AlongLineDirection
-
get_along_line_drawing_mode()¶ 返回设置在沿线标注中,标签绘制所采用的策略。默认为
AlongLineDrawingMode.COMPATIBLE返回: 标签绘制所采用的策略 返回类型: AlongLineDrawingMode
-
get_along_line_space_ratio()¶ 返回沿线文本间隔比率。该值为字高的倍数。
- 注意:
- 该值大于1就以线中心为准,按指定间隔往两边标注;
- 该值在0到1之间(包含1)就在线中心按照沿线角度标注单个文本。
- 该值小于等于0采用默认的沿线标注模式。
返回: 沿线文本间隔比率 返回类型: float
-
get_along_line_word_angle_range()¶ 返回沿线标注中字与字或者字母与字母间相对角度的容限值,单位为:度。 沿线标注中,中文标签与英文标签为了适应弯曲线的走势,文字或者字母会发生旋转,但是单个字或者字母始终与其当前标注点位的切线方向垂直,因此,会出 现如下图所示的效果,相邻字或者字母形成一定的夹角,当线的弯曲度较大时,夹角也增大,会出现标签整体不美观的效果。因此,该接口通过一个给定的容限 值,限制相邻字或者字母夹角最大值,以保证沿线标注的美观性。
夹角容限值越小,标签越紧凑,但弯度大的地方可能就无法进行标注;夹角容限值越大,弯度大的地方也能显示标注,但是沿线标注的美观性降低了。
沿线标注中字与字或者字母与字母间相对角度指的是什么?如下图所示:
返回: 沿线标注中字与字或者字母与字母间相对角度的容限值,单位为:度 返回类型: int
-
get_back_shape()¶ 返回标签专题图中的标签背景的形状类型
返回: 标签专题图中的标签背景的形状类型 返回类型: LabelBackShape
-
get_label_angle_expression()¶ 返回一个字段,该字段为数值型字段,字段值控制文本的旋转角度
返回: 一个字段,该字段为数值型字段,字段值控制文本的旋转角度 返回类型: str
-
get_label_color_expression()¶ 返回一个字段,该字段为数值型字段,控制文字颜色
返回: 一个字段,该字段为数值型字段,控制文字颜色。 返回类型: str
-
get_label_font_type_expression()¶ 返回一个字段名称,字段值为字体名称,如:微软雅黑、宋体,控制标签专题图中标签文本的字体样式。
返回: 一个字段名称,该字段控制标签专题图中标签文本的字体样式。 返回类型: str
-
get_label_repeat_interval()¶ 返回在沿线标注时循环标注的间隔。所设置的间隔大小代表打印后相邻标注间隔的纸面距离,单位为0.1毫米。例如:循环标注间隔值设置为500,地图打印后, 在纸面上量算相邻标注间的距离就为5厘米。
返回: 沿线标注时循环标注的间隔 返回类型: float
-
get_label_size_expression()¶ 返回一个字段,该字段为数值型字段,字段值控制文字字高,数值单位为毫米。
返回: 一个字段,该字段控制文字字高。 返回类型: str
-
get_matrix_label()¶ 返回标签专题图中的矩阵标签。在矩阵标签中,标签以矩阵的形式排列在一起。
返回: 标签专题图中的矩阵标签 返回类型: LabelMatrix
-
get_max_label_length()¶ 返回标签在每一行显示的最大长度。默认值为256
如果输入的字符超过设置的最大长度,可以采用两种方式处理,一种是以换行的方式进行显示,这种方式自动调整字间距,尽量使每一行的字符个数相近,故 每一行显示的字符个数小于等于设置的最大长度; 另一种是以省略号方式进行显示,当输入的字符大于设置的最大长度时,多出的字符将以省略号的方式进行显示。
返回: 每一行显示的最大长度。 返回类型: int
-
get_max_text_height()¶ 返回标签中文本的最大高度。该方法在标签不固定大小时有效,当放大后的文本高度超过最大高度之后就不再放大。高度单位为 0.1 毫米。
返回: 标签中文本的最大高度。 返回类型: int
-
get_min_text_height()¶ 返回标签中文本的最小高度。
返回: 标签中文本的最小高度。 返回类型: int
-
get_numeric_precision()¶ 返回标签中数字的精度。例如标签对应的数字是 8071.64529347,返回值为0时,显示8071,为1时,显示8071.6;为3时,则是8071.645
返回: 标签中数字的精度。 返回类型: int
-
get_offset_x()¶ 返回标签专题图中标记文本相对于要素内点的水平偏移量
返回: 标签专题图中标记文本相对于要素内点的水平偏移量。 返回类型: str
-
get_offset_y()¶ 返回标签专题图中标记文本相对于要素内点的垂直偏移量
返回: 标签专题图中标记文本相对于要素内点的垂直偏移量 返回类型: str
-
get_overlength_mode()¶ 返回超长标签的处理方式。对超长标签可以不作任何处理,也可以省略超出的部分,或者以换行方式进行显示。
返回: 超长标签的处理方式 返回类型: OverLengthLabelMode
-
get_range_expression()¶ 返回分段字段表达式。其中分段表达式中的值必须为数值型的。 用户根据该方法的返回值来比较其从开始到结束的每一个分段值,以确定采用什么风格来显示给定标注字段表达式相应的标注文本。
返回: 分段字段表达式 返回类型: str
-
get_range_items()¶ 返回分段标签专题图子项集合。基于字段表达式值的分段结果,一个分段对应一个分段标签专题图子项。通过此对象添加分段标签专题图子项。
返回: 分段标签专题图子项集合 返回类型: ThemeLabelRangeItems
-
get_split_separator()¶ 获取用于标签文本换行的换行符,可以为:“/”、“;”、空格等
如果通过
set_overlength_label()接口设置 overlength_mode 为OverLengthLabelMode.NEWLINE,即换行 方式,同时通过 split_separator 设置了换行符,那么,标签文本将按照特殊字符指定的位置进行换行显示。当标签专题图使用换行的方式进行超长文本处理时,可以通过给定特殊字符的方式控制文本的换行位置,这就需要您提前做好数据准备,在用于标注的字段中, 在字段值需要换行的位置加入您设定的换行符,如“/”、“;”、空格,当使用特殊字符换行时,将在出现指定的特殊字符处进行换行,并且指定的特殊字符不显示。
返回: 用于标签文本换行的换行符 返回类型: str
-
get_text_extent_inflation()¶ 返回标签中文本在 X,Y 正方向上的缓冲范围。通过设置该值可以修改文本在地图中所占空间的大小,必须非负。
返回: 标签中文本在 X,Y 正方向上的缓冲范围。 返回类型: tuple[int,int]
-
get_uniform_mixed_style()¶ 返回标签专题图统一的文本复合风格
返回: 标签专题图统一的文本复合风格 返回类型: MixedTextStyle
-
get_unique_expression()¶ 返回单值字段表达式,表达式可以为一个字段,也可以为多个字段构成的表达式,通过该表达式的值控制对象标签的风格,表达式值相同的对象标签使用相同的风格进行显示。
返回: 单值字段表达式 返回类型: str
-
get_unique_items()¶ 返回单值标签专题图子项集合。基于单值字段表达式值相同的对象标签为一类,一个单值对应一个单值标签专题图子项。
返回: 单值标签专题图子项集合。 返回类型: ThemeLabelUniqueItems
-
is_along_line()¶ 返回是否沿线显示文本。True 表示沿线显示文本,False 表示正常显示文本。沿线标注属性只适用于线数据集专题图。默认值为 True
返回: 是否沿线显示文本。 返回类型: bool
-
is_angle_fixed()¶ 当沿线显示文本时,是否将文本角度固定。True 表示按固定文本角度显示文本,False 表示按照沿线角度显示文本。默认值为 False。
返回: 当沿线显示文本时,是否将文本角度固定。 返回类型: bool
-
is_flow_enabled()¶ 返回是否流动显示标签。默认为 True。
返回: 是否流动显示标签 返回类型: bool
-
is_leader_line_displayed()¶ 返回是否显示标签和它标注的对象之间的牵引线。默认值为 False,即不显示。
返回: 是否显示标签和它标注的对象之间的牵引线。 返回类型: bool
-
is_offset_prj_coordinate_unit()¶ 获取水平或垂直偏移量的单位是否是地理坐标系单位
返回: 水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。
-
is_on_top()¶ 返回标签专题图图层是否显示在最上层。这里的最上层是指所有非标签专题图图层的上层。
返回: 标签专题图图层是否显示在最上层 返回类型: bool
-
is_overlap_avoided()¶ 返回是否允许以文本避让方式显示文本。只针对该标签专题图层中的文本数据。
返回: 是否自动避免文本叠盖。 返回类型: bool
-
is_repeat_interval_fixed()¶ 返回循环标注间隔是否固定。True 表示固定循环标注间隔,循环标注间隔不随地图的缩放而变化;False 表示循环标注间隔随地图的缩放而变化。
返回: 循环标注间隔固定返回 True;否则返回 False 返回类型: bool
-
is_repeated_label_avoided()¶ 返回是否避免地图重复标注。
对于代表北京地铁四号线的线数据,假如由4条子线段组成,当以名称字段(字段值为:地铁四号线)做为专题变量制作标签专题图且设置沿线标注时,如果不 选择避免地图重复标注,则显示效果如左图,如果选择了避免地图重复标注,系统会将这条折线的四个子线部分看成一条线来进行标注,其显示效果如下图所示。
返回: 返回类型: bool
-
is_small_geometry_labeled()¶ 当标签的长度大于被标注对象本身的长度时,返回是否显示该标签。
在标签的长度大于线或者面对象本身的长度时,如果选择继续标注,则标签文字会叠加在一起显示,为了清楚完整的显示该标签,可以采用换行模式来显示标 签,但必须保证每行的长度小于对象本身的长度。
返回: 是否显示长度大于被标注对象本身长度的标签 返回类型: bool
-
is_support_text_expression()¶ 返回是否支持文本表达式,即上下标功能。默认值为 False,不支持文本表达式
返回: 是否支持文本表达式,即上下标功能 返回类型: bool
-
is_vertical()¶ 是否使用竖排标签
返回: 是否使用竖排标签 返回类型: bool
-
label_expression¶ str -- 标注字段表达式
-
static
make_default_range(dataset, label_expression, range_expression, range_mode, range_parameter, color_gradient_type=None, join_items=None)¶ 生成默认的分段标签专题图。
参数: - dataset (DataestVector or str) -- 用于制作分段标签专题图的矢量数据集。
- label_expression (str) -- 标注字段表达式
- range_expression (str) -- 分段字段表达式。
- range_mode (RangeMode or str) -- 分段模式
- range_parameter (float) -- 分段参数。当分段模式为等距离分段法,平方根分段法其中一种时,该参数为分段值;当分段模式为标准差分段法的时候,该参数不起作用;当分段模式为自定义距离时,该参数表示自定义距离。
- color_gradient_type (ColorGradientType or str) -- 颜色渐变模式。
- join_items (list[JoinItem] or tuple[JoinItem]) -- 外部表连接项
返回: 分段标签专题图对象
返回类型:
-
static
make_default_unique(dataset, label_expression, unique_expression, color_gradient_type=None, join_items=None)¶ 生成默认的单值标签专题图。
参数: - dataset (DatasetVector or str) -- 用于制作单值标签专题图的矢量数据集。
- label_expression (str) -- 标注字段表达式
- unique_expression (str) -- 指定一个字段或者多个字段组成的表达式。该表达式的值用来对对象标签进行分类,值相同的对象标签为一类使用相同的风格显示,不同类的标签使用不同风格显示。
- color_gradient_type (ColorGradientType or str) -- 颜色渐变模式
- join_items (list[JoinItem] or tuple[JoinItem]) -- 外部表连接项
返回: 单值标签专题图对象
返回类型:
-
set_along_line(is_along_line=True, is_angle_fixed=False, culture=None, direction='ALONG_LINE_NORMAL', drawing_mode='COMPATIBLE', space_ratio=None, word_angle_range=None, repeat_interval=0, is_repeat_interval_fixed=False, is_repeated_label_avoided=False)¶ 设置沿线显示文本,只适用于线数据及标签专题图。
参数: - is_along_line (bool) -- 是否沿线显示文本
- is_angle_fixed (bool) -- 是否将文本角度固定
- culture (AlongLineCulture or str) -- 沿线标注使用的语言文化习惯。默认与当前系统的非 Unicode 语言相关。如果是中文环境,为 CHINESE,否则为 ENGLISH。
- direction (AlongLineDirection or str) -- 标签沿线标注方向
- drawing_mode (AlongLineDrawingMode or str) -- 标签绘制所采用的策略
- space_ratio (float) --
沿线文本间隔比率,为字高的倍数。 注意:
- 该值大于 1 就以线中心为准,按指定间隔往两边标注
- 该值在 0 到 1 之间(包含1)就在线中心按照沿线角度标注单个文本
- 该值小于等于 0 采用默认的沿线标注模式
- word_angle_range (int) -- 字与字或者字母与字母间相对角度的容限值,单位为:度
- repeat_interval (float) -- 沿线标注时循环标注的间隔。所设置的间隔大小代表打印后相邻标注间隔的纸面距离,单位为0.1毫米
- is_repeat_interval_fixed (bool) -- 循环标注间隔是否固定
- is_repeated_label_avoided (bool) -- 是否避免地图重复标注
返回: self
返回类型:
-
set_back_shape(value)¶ 设置标签专题图中的标签背景的形状类型,默认不显示任何背景
参数: value (LabelBackShape or str) -- 标签专题图中的标签背景的形状类型 返回: self 返回类型: ThemeLabel
-
set_back_style(value)¶ 返回标签专题图中的标签背景风格。
参数: value (GeoStyle) -- 标签专题图中的标签背景风格。 返回: self 返回类型: ThemeLabel
-
set_flow_enabled(value)¶ 设置是否流动显示标签。 流动显示只适合于线和面要素的标注
参数: value (bool) -- 是否流动显示标签。 返回: self 返回类型: ThemeLabel
-
set_label_angle_expression(value)¶ 设置一个字段,该字段为数值型字段,字段值控制文本的旋转角度。指定字段后,标签的文字旋转角度将从对应记录的该字段值中读取。
参数: value (str) -- 一个字段,该字段为数值型字段,字段值控制文本的旋转角度。 数值单位为度。角度旋转以逆时针方向为正方向,对应数值为正值;角度值支持负值,表示沿顺时针方向旋转。 关于标签旋转角度和偏移,如果两者同时设置后,先对标签进行角度旋转,再进行偏移。 返回: self 返回类型: ThemeLabel
-
set_label_color_expression(value)¶ 设置一个字段,该字段为数值型字段,控制文字颜色,指定字段后,标签的文字颜色将从对应记录的该字段值中读取。
参数: value (str) -- 一个字段,该字段为数值型字段,控制文字颜色。 颜色值支持十六进制表达下为0xRRGGBB,即按照RGB排列。 返回: self 返回类型: ThemeLabel
-
set_label_expression(value)¶ 设置标注字段表达式
参数: value (str) -- 标注字段表达式 返回: self 返回类型: ThemeLabel
-
set_label_font_type_expression(value)¶ 设置一个字段,该字段值为字体名称,如:微软雅黑、宋体,控制标签专题图中标签文本的字体样式。指定字段后,标签的字体样式将从对应记录的该字段值中读取。
参数: value (str) -- 一个字段,该字段控制标签专题图中标签文本的字体样式。 如果字段值指定的字体在当前系统中不存在,或者字段值为无值,将按照 当前标签专题图所设置的具体字体进行显示,如: set_uniform_style()方法所设置的文本风格中的字体。返回: self 返回类型: ThemeLabel
-
set_label_size_expression(value)¶ 设置一个字段,该字段为数值型字段,字段值控制文字字高,数值单位为毫米。指定字段后,标签的文字大小将从对应记录的该字段值中读取。
参数: value (str) -- 一个字段,该字段控制文字字高。 如果字段值为无值,将按照当前标签专题图所设置的字体大小的具体数值进行显示 返回: self 返回类型: ThemeLabel
-
set_leader_line(is_displayed=False, leader_line_style=None)¶ 设置标签与其标注对象之间牵引线是否显示,以及牵引线风格等。
参数: - is_displayed (bool) -- 是否显示标签和它标注的对象之间的牵引线。
- leader_line_style (GeoStyle) -- 标签与其标注对象之间牵引线的风格。
返回: self
返回类型:
-
set_matrix_label(value)¶ 设置标签专题图中的矩阵标签。在矩阵标签中,标签以矩阵的形式排列在一起。
参数: value (LabelMatrix) -- 标签专题图中的矩阵标签 返回: self 返回类型: ThemeLabel
-
set_max_text_height(value)¶ 设置标签中文本的最大高度。该方法在标签不固定大小时有效,当放大后的文本高度超过最大高度之后就不再放大。高度单位为 0.1 毫米。
参数: value (int) -- 标签中文本的最大高度。 返回: self 返回类型: ThemeLabel
-
set_min_text_height(value)¶ 设置标签中文本的最小高度。
参数: value (int) -- 标签中文本的最大宽度。 返回: self 返回类型: ThemeLabel
-
set_numeric_precision(value)¶ 设置标签中数字的精度。例如标签对应的数字是8071.64529347,返回值为0时,显示8071,为1时,显示8071.6;为3时,则是8071.645。
参数: value (int) -- 标签中数字的精度。 返回: self 返回类型: ThemeLabel
-
set_offset_prj_coordinate_unit(value)¶ 设置水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。具体查看
set_offset_x()和set_offset_y()接口。参数: value (bool) -- 水平或垂直偏移量的单位是否是地理坐标系单位 返回: self 返回类型: ThemeLabel
-
set_offset_x(value)¶ 设置标签专题图中标记文本相对于要素内点的水平偏移量。 该偏移量的值为一个常量值或者字段表达式所表示的值,即如果字段表达式为 SmID,其中 SmID=2,那么偏移量的值为 2。
偏移量的单位由
set_offset_prj_coordinate_unit()决定, 为True表示采用采用地理坐标单位,否则采用设备单位参数: value (str) -- 返回: self 返回类型: ThemeLabel
-
set_offset_y(value)¶ 设置标签专题图中标记文本相对于要素内点的垂直偏移量。
该偏移量的值为一个常量值或者字段表达式所表示的值,即如果字段表达式为 SmID,其中 SmID=2,那么偏移量的值为 2。
参数: value (str) -- 标签专题图中标记文本相对于要素内点的垂直偏移量。 返回: self 返回类型: ThemeLabel
-
set_on_top(value)¶ 设置标签专题图图层是否显示在最上层。这里的最上层是指所有非标签专题图图层的上层。
一般制图时,都会把地图中标签专题图图层放在所有非标签专题图图层的最前面,但当使用了图层分组时,分组内的标签专题图层有可能被位于上层图层分组中 的其他普通图层掩盖,为了即保持图层分组状态,又要使标签不被掩盖,可以使用 set_on_top 方法传入true值,标签专题图不论当前在地图中的位置,都将显 示在最前面;如果有多个标签专题图图层都通过 set_on_top 方法传入 true值,那么他们之间显示顺序,由他们所在地图的图层顺序决定。
参数: value (bool) -- 标签专题图图层是否显示在最上层 返回: self 返回类型: ThemeLabel
-
set_overlap_avoided(value)¶ 设置是否允许以文本避让方式显示文本。只针对该标签专题图层中的文本数据。
注:在标签重叠度很大的情况下,即使使用自动避让功能,可能也无法完全避免标签重叠现象。当两个相互重叠的标签同时设置了文本避让时,ID 靠前的标签 文本具有优先绘制权。
参数: value (bool) -- 是否自动避免文本叠盖 返回: self 返回类型: ThemeLabel
-
set_overlap_avoided_mode(value)¶ 设置文本自动避让方式
参数: value (AvoidMode or str) -- 文本自动避让方式 返回: self 返回类型: ThemeLabel
-
set_overlength_label(overlength_mode=None, max_label_length=256, split_separator=None)¶ 设置处理超长文本。
参数: - overlength_mode (OverLengthLabelMode or str) -- 超长标签的处理方式。对超长标签可以不作任何处理,也可以省略超出的部分,或者以换行方式进行显示。
- max_label_length (int) -- 标签在每一行显示的最大长度。如果超过这个长度,可以采用两种方式来处理,一种是换行的模式进行显示,另一种是以省略号方式显示。
- split_separator (str) -- 用于标签文本换行的换行符,可以为:“/”、“;”、空格等。当超长标签处理方式为 NEWLINE 时,将根据指定的字符进行换行。
返回: self
返回类型:
-
set_range_label(range_expression, range_mode)¶ 设置分段标签专题图。
参数: - range_expression (str) -- 分段字段表达式。其中分段表达式中的值必须为数值型的。
- range_mode (RangeMode or str) -- 分段模式
返回: self
返回类型:
-
set_small_geometry_labeled(value)¶ 当标签的长度大于被标注对象本身的长度时,设置是否显示该标签。
在标签的长度大于线或者面对象本身的长度时,如果选择继续标注,则标签文字会叠加在一起显示,为了清楚完整的显示该标签,可以采用换行模式来显示标签, 但必须保证每行的长度小于对象本身的长度。
参数: value (bool) -- 是否显示长度大于被标注对象本身长度的标签 返回: self 返回类型: ThemeLabel
-
set_support_text_expression(value)¶ 设置是否支持文本表达式,即上下标功能。 当选择字段为文本类型,文本中含有上下标,并且是根据特定的标准时(文本表达式请参考下面说明),需要设置此属性,以便正确显示文本(如下右图)。 下图为分别设置此属性值为 False 和 True 时的效果对比:

注意:
- 当设置该属性为true后,具有上下标的文本的标签的对齐方式只能显示为“左上角”效果,不具有上下标的文本的标签的对齐方式与文本风格中设置的对齐方式相同。
- 不支持有旋转角度的文本标签,即文本标签的旋转角度不为0时,该属性的设置无效。
- 不支持竖排、换行显示的文本标签。
- 不支持包含删除线、下划线、分隔符的文本标签。
- 不支持线数据集的标签专题图沿线标注的文本标签。
- 当地图有旋转角度时,设置了支持文本表达式的文本标签不随地图的旋转而旋转。
- 不支持特殊符号的标签专题图的文本标签。
- 含有上下标的文本表达式中,#+表示上标;#-表示下标,#=表示分割一个字符串为两个上下标部分。
- 设置了支持文本表达式的文本标签如果以"#+"、"#-"、"#="开始,整个字符串原样输出。
下图为分别设置此属性值为false和true时的效果对比:

遇到#+或者#-,后边紧挨着的字符串都当成上下标内容、当第三次遇到#+或#-时采用新串规则。下图为分别设置此属性值为flse和true时的效果对比。

含有上下标的文本表达式中,两个连续的"#+"的效果同一个"#-",两个连续的"#-"的效果同一个"#+"。 下图为分别设置此属性值为false和true时的效果对比:

目前支持该功能的标签专题图类型为统一风格标签专题图,分段风格标签专题图和标签矩阵专题图。
参数: value (bool) -- 否支持文本表达式 返回: self 返回类型: ThemeLabel
-
set_text_extent_inflation(width, height)¶ 设置标签中文本在 X,Y 正方向上的缓冲范围。通过设置该值可以修改文本在地图中所占空间的大小,必须非负。
参数: - width (int) -- X 方向的大小
- height (int) -- Y 方向的大小
返回: self
返回类型:
-
set_uniform_mixed_style(value)¶ 设置标签专题图统一的文本复合风格。 当同时设置了文本复合风格(
get_uniform_mixed_style())和文本风格 (get_uniform_style())时, 绘制风格优先级,文本复合风格大于文本风格。参数: value (MixedTextStyle) -- 标签专题图的文本复合风格 返回: self 返回类型: ThemeLabel
-
set_uniform_style(value)¶ 设置统一文本风格
参数: value (TextStyle) -- 统一文本风格 返回: self 返回类型: ThemeLabel
-
set_unique_label(unique_expression)¶ 设置单值标签标签专题图。
参数: unique_expression (str) -- 单值字段表达式 返回: self 返回类型: ThemeLabel
-
set_vertical(value)¶ 设置是否使用竖排标签。
- 不支持矩阵标签和沿线标注。
- 不支持有旋转角度的文本标签,即文本标签的旋转角度大于0时,该属性的设置无效。
参数: value (bool) -- 是否使用竖排标签 返回: self 返回类型: ThemeLabel
-
-
class
iobjectspy.mapping.ThemeGraphItem(expression, caption, style=None, range_setting=None)¶ 基类:
object统计专题图子项类。
统计专题图通过为每个要素或记录绘制统计图来反映其对应的专题值的大小。统计专题图可以基于多个变量,反映多种属性,即可以将多个专题变量的值绘制在一个 统计图上。每一个专题变量对应的统计图即为一个专题图子项。本类用来设置统计专题图子项的名称,专题变量,显示风格和分段风格。
参数: - expression (str) -- 统计专题图的专题变量。专题变量可以是一个字段或字段表达式
- caption (str) -- 专题图子项的名称
- style (GeoStyle) -- 统计专题图子项的显示风格
- range_setting (ThemeRange) -- 统计专题图子项的分段风格
-
caption¶ str -- 专题图子项的名称
-
expression¶ str -- 统计专题图的专题变量
-
range_setting¶ ThemeRange -- 返回统计专题图子项的分段风格
-
set_caption(value)¶ 设置专题图子项的名称。
参数: value (str) -- 专题图子项的名称 返回: self 返回类型: ThemeGraphItem
-
set_expression(value)¶ 设置统计专题图的专题变量。专题变量可以是一个字段或字段表达式。
参数: value (str) -- 统计专题图的专题变量 返回: self 返回类型: ThemeGraphItem
-
set_range_setting(value)¶ 设置统计专题图子项的分段风格
参数: value (ThemeRange) -- 统计专题图子项的分段风格 返回: self 返回类型: ThemeGraphItem
-
set_style(value)¶ 设置统计专题图子项的显示风格
参数: value (GeoStyle) -- 返回: self 返回类型: ThemeGraphItem
-
style¶ GeoStyle -- 返回统计专题图子项的分段风格。
-
class
iobjectspy.mapping.ThemeGraphType¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了统计专题图的统计图类型常量。
变量: - ThemeGraphType.AREA --
面积图。面积图显示的时候,多个 ThemeGraphItem 合成一个面,面的风格采用第一个 ThemeGraphItem 的风格渲染。
- ThemeGraphType.STEP --
阶梯图。
- ThemeGraphType.LINE --
折线图。
- ThemeGraphType.POINT --
点状图。
- ThemeGraphType.BAR --
柱状图
- ThemeGraphType.BAR3D --
三维柱状图
- ThemeGraphType.PIE --
饼图
- ThemeGraphType.PIE3D --
三维饼图。三维饼状图注记标签的大小会根据统计符号的大小进行调整,以避免统计符号很多时,出现统计符号很小,而注记很大,界面上满屏幕都是注记的问题。
- ThemeGraphType.ROSE --
玫瑰图
- ThemeGraphType.ROSE3D --
三维玫瑰图
- ThemeGraphType.STACK_BAR --
堆叠柱状图
- ThemeGraphType.STACK_BAR3D --
三维堆叠柱状图
- ThemeGraphType.RING --
环状图
-
AREA= 0¶
-
BAR= 4¶
-
BAR3D= 5¶
-
LINE= 2¶
-
PIE= 6¶
-
PIE3D= 7¶
-
POINT= 3¶
-
RING= 14¶
-
ROSE= 8¶
-
ROSE3D= 9¶
-
STACK_BAR= 12¶
-
STACK_BAR3D= 13¶
-
STEP= 1¶
- ThemeGraphType.AREA --
-
class
iobjectspy.mapping.ThemeGraphTextFormat¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了统计专题图文本显示格式类型常量。
变量: - ThemeGraphTextFormat.PERCENT --
百分数。以各子项所占的百分比来进行标注。
- ThemeGraphTextFormat.VALUE --
真实数值。以各子项的真实数值来进行标注。

- ThemeGraphTextFormat.CAPTION --
标题。以各子项的标题来进行标注。

- ThemeGraphTextFormat.CAPTION_PERCENT --
标题+百分数。以各子项的标题和百分比来进行标注。
- ThemeGraphTextFormat.CAPTION_VALUE --
标题+真实数值。以各子项的标题和真实数值来进行标注。
-
CAPTION= 3¶
-
CAPTION_PERCENT= 4¶
-
CAPTION_VALUE= 5¶
-
PERCENT= 1¶
-
VALUE= 2¶
- ThemeGraphTextFormat.PERCENT --
-
class
iobjectspy.mapping.GraphAxesTextDisplayMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum统计专题图坐标轴文本显示模式。
变量: - GraphAxesTextDisplayMode.NONE -- 没有显示
- GraphAxesTextDisplayMode.YAXES -- 显示 Y 轴的文本
- GraphAxesTextDisplayMode.ALL -- 显示全部文本
-
ALL= 3¶
-
NONE= 0¶
-
YAXES= 2¶
-
class
iobjectspy.mapping.ThemeGraph(graph_type='PIE3D', graduated_mode='CONSTANT', items=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme统计专题图类。 统计专题图通过为每个要素或记录绘制统计图来反映其对应的专题值的大小。统计专题图可以基于多个变量,反映多种属性,即可以将多个专题变量的值绘制在一个统计图上。
参数: - graph_type (ThemeGraphType or str) -- 统计专题图的统计图类型。根据实际的数据和用途的不同,可以选择不同类型的统计图。
- graduated_mode (GraduatedMode or str) -- 专题图分级模式
- items (list[ThemeGraphItem] or tuple[ThemeGraphItem]) -- 统计专题图子项列表
-
add(item)¶ 添加统计专题图子项
参数: item (ThemeGraphItem) -- 统计专题图子项 返回: self 返回类型: ThemeGraph
-
clear()¶ 删除统计专题图中的所有子项。
返回: self 返回类型: ThemeGraph
-
exchange_item(index1, index2)¶ 将指定序号的两个子项进行位置交换。
参数: - index1 (int) -- 指定的交换第一个子项的序号。
- index2 (int) -- 指定的交换第二个子项的序号。
返回: 交换成功,返回 True,否则为 False
返回类型: bool
-
extend(items)¶ 批量添加统计专题图子项
参数: items (list[ThemeGraphItem] or tuple[ThemeGraphItem]) -- 统计专题图子项列表 返回: self 返回类型: ThemeGraph
-
get_axes_text_display_mode()¶ 显示坐标轴文本时,显示的文本模式
返回: 显示坐标轴文本时,显示的文本模式 返回类型: GraphAxesTextDisplayMode
-
get_bar_space_ratio()¶ 返回柱状专题图中柱体的间隔,返回值为一个系数值,数值范围为0到10,默认值为1
返回: 柱状专题图中柱体的间隔 返回类型: float
-
get_bar_width_ratio()¶ 返回柱状专题图中每一个柱的宽度,返回值为一个系数值,数值范围为0到10,默认值为1。柱状统计图的柱宽等于原始柱宽乘以系数值。
返回: 柱状专题图中每一个柱的宽度。为一个系数值,数值范围为0到10 返回类型: float
-
get_count()¶ 返回统计专题图子项的个数
返回: 统计专题图子项的个数 返回类型: int
-
get_custom_graph_size_expression()¶ 返回一个字段表达式,该字段表达式用于控制对象对应的统计专题图元素的大小,字段表达式中的字段必须为数值型字段。 该字段表达式可以指定一个字段也 可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以该数值指定的大小统一显示。
返回: 用于控制对象对应的统计专题图元素的大小的字段表达式 返回类型: str
-
get_graph_text_format()¶ 返回统计专题图文本显示格式
返回: 统计专题图文本显示格式 返回类型: ThemeGraphTextFormat
-
get_graph_text_style()¶ 返回统计图上的文字标注风格。统计专题图上坐标轴的文本对齐方式均采用右下角的对齐方式,以防止坐标轴压盖文本
返回: 统计图上的文字标注风格。 返回类型: TextStyle
-
get_item(index)¶ 用指定的统计专题图子项替代指定序号上的专题图子项。
参数: index (int) -- 指定的序号。 返回: 统计专题图子项 返回类型: ThemeGraphItem
-
get_max_graph_size()¶ 返回统计专题图中统计符号显示的最大值。统计图中统计符号的显示大小均在最大、最小值之间逐渐变化。统计图的最大、最小值是与统计对象的多少和图层大小相关系的一个值。
返回: 统计专题图中统计符号显示的最大值 返回类型: float
-
get_min_graph_size()¶ 返回统计专题图中统计符号显示的最小值。
返回: 统计专题图中统计符号显示的最小值。 返回类型: float
-
get_offset_x()¶ 返回统计图的水平偏移量
返回: 水平偏移量 返回类型: str
-
get_offset_y()¶ 返回统计图的垂直偏移量
返回: 垂直偏移量 返回类型: str
-
get_rose_angle()¶ 返回统计图中玫瑰图或三维玫瑰图分片的角度。单位为度,精确到 0.1 度
返回: 统计图中玫瑰图或三维玫瑰图分片的角度 返回类型: float
-
get_start_angle()¶ 返回饼状统计图的起始角度,默认以水平方向为正向。单位为度,精确到 0.1 度。
返回: 饼状统计图的起始角度 :rtype: float
-
graduated_mode¶ GraduatedMode -- 专题图分级模式
-
graph_type¶ ThemeGraphType -- 统计专题图的统计图类型
-
index_of(expression)¶ 返回统计专题图中指定统计字段表达式的对象在当前统计图子项序列中的序号。
参数: expression (str) -- 指定的统计字段表达式。 返回: 统计专题图子项在序列中的序号。 返回类型: int
-
insert(index, item)¶ 将给定的统计专题图子项插入到指定序号的位置。
参数: - index (int) -- 指定的统计专题图子项序列的序号。
- item (ThemeGraphItem) -- 将被插入的统计专题图子项。
返回: 插入成功返回 True,否则为 False
返回类型: bool
-
is_all_directions_overlapped_avoided()¶ 返回是否允许以全方向统计专题图避让
返回: 是否允许以全方向统计专题图避让 返回类型: bool
-
is_axes_displayed()¶ 返回是否显示坐标轴
返回: 是否显示坐标轴 返回类型: bool
-
is_axes_grid_displayed()¶ 获取是否在统计图坐标轴上显示网格
返回: 是否在统计图坐标轴上显示网格 返回类型: bool
-
is_axes_text_displayed()¶ 返回是否显示坐标轴的文本标注。
返回: 是否显示坐标轴的文本标注 返回类型: bool
-
is_display_graph_text()¶ 返回是否显示统计图上的文本标注
返回: 是否显示统计图上的文本标注 返回类型: bool
-
is_flow_enabled()¶ 返回统计专题图是否流动显示。
返回: 统计专题图是否流动显示 返回类型: bool
-
is_global_max_value_enabled()¶ 返回是否使用全局最大值制作统计专题图。True,表示使用全局最大值作为统计图元素的最大值,保证同一专题图层中统计图元素具有一致的刻度。
返回: 是否使用全局最大值制作统计专题图 返回类型: bool
-
is_graph_size_fixed()¶ 返回在放大或者缩小地图时统计图是否固定大小。
返回: 在放大或者缩小地图时统计图是否固定大小。 返回类型: bool
-
is_leader_line_displayed()¶ 返回是否显示统计图和它所表示的对象之间的牵引线。如果渲染符号偏移该对象,图与对象之间可以采用牵引线进行连接。
返回: 是否显示统计图和它所表示的对象之间的牵引线 返回类型: bool
-
is_negative_displayed()¶ 返回专题图中是否显示属性为负值的数据。
返回: 专题图中是否显示属性为负值的数据 返回类型: bool
-
is_offset_prj_coordinate_unit()¶ 获取水平或垂直偏移量的单位是否是地理坐标系单位
返回: 水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。 返回类型: bool
-
is_overlap_avoided()¶ 返回统计图是否采用避让方式显示。采用避让方式显示返回 true,否则返回 false
返回: 是否采用避让方式显示 返回类型: bool
-
remove(index)¶ 在统计专题图子项序列中删除指定序号的统计专题图子项。
参数: index (int) -- 指定的将被删除子项的序号 返回: 删除成功,返回 True;否则返回 False。 返回类型: bool
-
set_all_directions_overlapped_avoided(value)¶ 设置是否允许以全方向统计专题图避让。全方向即指以统计专题图外边框和基准线而形成的 12 个方向。四方向是指以统计专题图外边矩形框的四个角点方向。
通常统计专题图避让是以全方向进行的,虽然避让比较合理,但会影响显示效率;如果提高显示效率,请设置为False。
参数: value (bool) -- 是否以全方向统计专题图避让 返回: self 返回类型: ThemeGraph
-
set_axes(is_displayed=True, color=(128, 128, 128), is_text_displayed=False, text_display_mode='', text_style=None, is_grid_displayed=False)¶ 设置是否坐标轴,以及坐标轴文本标注相关内容。
参数: - is_displayed (bool) -- 是否显示坐标轴。
- color (Color or str) -- 坐标轴颜色
- is_text_displayed (bool) -- 是否显示坐标轴的文本标注
- text_display_mode (GraphAxesTextDisplayMode or str) -- 显示坐标轴文本时,显示的文本模式
- text_style (TextStyle) -- 统计图坐标轴文本的风格
- is_grid_displayed (bool) -- 是否在统计图坐标轴上显示网格
返回: self
返回类型:
-
set_bar_space_ratio(value)¶ 设置柱状专题图中柱体的间隔,设置的值为一个系数值,数值范围为0到10,默认值为1。柱状统计图的柱体间隔等于原始间隔乘以系数值。
参数: value (float) -- 柱状专题图中柱体的间隔 返回: self 返回类型: ThemeGraph
-
set_bar_width_ratio(value)¶ 设置柱状专题图中每一个柱的宽度,设置的值为一个系数值,数值范围为0到10,默认值为1。柱状统计图的柱宽等于原始柱宽乘以系数值。
参数: value (float) -- 柱状专题图中每一个柱的宽度,该值为一个系数值,数值范围为0到10。 返回: self 返回类型: ThemeGraph
-
set_custom_graph_size_expression(value)¶ 设置一个字段表达式,该字段表达式用于控制对象对应的统计专题图元素的大小,字段表达式中的字段必须为数值型字段。 该字段表达式可以指定一个字段也 可以指定一个字段表达式;还可以指定一个数值,此时所有专题图子项将以该数值指定的大小统一显示。
参数: value (str) -- 用于控制对象对应的统计专题图元素的大小的字段表达式 返回: self 返回类型: ThemeGraph
-
set_display_graph_text(value)¶ 设置是否显示统计图上的文本标注
参数: value (bool) -- 指定是否显示统计图上的文本标注 返回: self 返回类型: ThemeGraph
-
set_flow_enabled(value)¶ 设置统计专题图是否流动显示。
参数: value (bool) -- 统计专题图是否流动显示。 返回: self 返回类型: ThemeGraph
-
set_global_max_value_enabled(value)¶ 设置是否使用全局最大值制作统计专题图。True,表示使用全局最大值作为统计图元素的最大值,保证同一专题图层中统计图元素具有一致的刻度。
参数: value (bool) -- 是否使用全局最大值制作统计专题图 返回: self 返回类型: ThemeGraph
-
set_graduated_mode(value)¶ 设置设置专题图分级模式
参数: value (GraduatedMode or str) -- 设置专题图分级模式 返回: self 返回类型: ThemeGraph
-
set_graph_size_fixed(value)¶ 设置在放大或者缩小地图时统计图是否固定大小。
参数: value (bool) -- 在放大或者缩小地图时统计图是否固定大小。 返回: self 返回类型: ThemeGraph
-
set_graph_text_format(value)¶ 设置统计专题图文本显示格式。
参数: value (ThemeGraphTextFormat or str) -- 统计专题图文本显示格式 返回: self 返回类型: ThemeGraph
-
set_graph_text_style(value)¶ 设置统计图上的文字标注风格。统计专题图上坐标轴的文本对齐方式均采用右下角的对齐方式,以防止坐标轴压盖文本
参数: value (TextStyle) -- 统计图上的文字标注风格 返回: self 返回类型: ThemeGraph
-
set_graph_type(value)¶ 设置统计专题图的统计图类型。根据实际的数据和用途的不同,可以选择不同类型的统计图。
参数: value (ThemeGraphType or str) -- 统计专题图的统计图类型 返回: self 返回类型: ThemeGraph
-
set_leader_line(is_displayed, style)¶ 设置显示统计图和它所表示的对象之间的牵引线
参数: - is_displayed (bool) -- 是否显示统计图和它所表示的对象之间的牵引线
- style (GeoStyle) -- 统计图与其表示对象之间牵引线的风格。
返回: self
返回类型:
-
set_max_graph_size(value)¶ 设置统计专题图中统计符号显示的最大值。统计图中统计符号的显示大小均在最大、最小值之间逐渐变化。统计图的最大、最小值是与统计对象的多少和图层大小相关系的一个值。
当
is_graph_size_fixed()为 True 时,单位为 0.01mm,is_graph_size_fixed()为 False 时,使用地图单位。参数: value (float) -- 统计专题图中统计符号显示的最大值 返回: self 返回类型: ThemeGraph
-
set_min_graph_size(value)¶ 设置统计专题图中统计符号显示的最小值。统计图中统计符号的显示大小均在最大、最小值之间逐渐变化。统计图的最大、最小值是与统计对象的多少和图层大小相关系的一个值。
当
is_graph_size_fixed()为 True 时,单位为 0.01mm,is_graph_size_fixed()为 False 时,使用地图单位。参数: value (float) -- 统计专题图中统计符号显示的最小值。 返回: self 返回类型: ThemeGraph
-
set_negative_displayed(value)¶ 设置专题图中是否显示属性为负值的数据。
该方法对面积图、阶梯图、折线图、点状图、柱状图、三维柱状图无效,因为在绘制时会始终显示负值数据;
对于饼图、三维饼图、玫瑰图、三维玫瑰图、金字塔专题图-条形、金字塔专题图-面形,如果用户将该方法参数设为 True,则将负值取绝对值后按照正值进 行处理,若设置为 False,则不对其进行绘制(正、负值数据均不绘制)
参数: value (bool) -- 专题图中是否显示属性为负值的数据 返回: self 返回类型: ThemeGraph
-
set_offset_prj_coordinate_unit(value)¶ 设置水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。具体查看
set_offset_x()和set_offset_y()接口。参数: value (bool) -- 水平或垂直偏移量的单位是否是地理坐标系单位 返回: self 返回类型: ThemeGraph
-
set_offset_x(value)¶ 设置统计图的水平偏移量
参数: value (str) -- 水平偏移量 返回: self 返回类型: ThemeGraph
-
set_offset_y(value)¶ 设置统计图的垂直偏移量
参数: value (str) -- 垂直偏移量 返回: self 返回类型: ThemeGraph
-
set_overlap_avoided(value)¶ 设置统计图是否采用避让方式显示。
- 对数据集制作统计专题图 当统计图采用避让方式显示时,如果
Map.is_overlap_displayed()方法设置为 True,则在统计图重叠度很大的情况下, 会出现无法完全避免统计图重叠的现象;当Map.is_overlap_displayed()方法设置为 False 时,会过滤掉一些统计图,从而保证所有的统计图均不重叠。 - 对数据集同时制作统计专题图和标签专题图 - 当统计图不显示子项文本时,标签专题图的标签即使和统计图重叠,两者也都可正常显示; - 当统计图显示子项文本时,如果统计图中的子项文本和标签专题图中的标签不重叠,则两者均正常显示;如果重叠,则会过滤掉统计图的子项文本,只显示标签。
参数: value (bool) -- 是否采用避让方式显示 返回: self 返回类型: ThemeGraph - 对数据集制作统计专题图 当统计图采用避让方式显示时,如果
-
set_rose_angle(value)¶ 设置统计图中玫瑰图或三维玫瑰图分片的角度。单位为度,精确到 0.1 度。
参数: value (float) -- 统计图中玫瑰图或三维玫瑰图分片的角度。 返回: self 返回类型: ThemeGraph
-
set_start_angle(value)¶ 设置饼状统计图的起始角度,默认以水平方向为正向。单位为度,精确到 0.1 度。 只有选择的统计图类型为饼状图(饼图、三维饼图、玫瑰图、三维玫瑰图)时才有效。
参数: value (float) -- 返回: self 返回类型: ThemeGraph
-
class
iobjectspy.mapping.GraduatedMode¶ 基类:
iobjectspy._jsuperpy.enums.JEnum该类定义了专题图分级模式类型常量。主要用在统计专题图和等级符号专题图中。
分级主要是为了减少制作专题图时数据大小之间的差异。如果数据之间差距较大,则可以采用对数或者平方根的分级方式来进行,这样就减少了数据之间的绝对大小 的差异,使得专题图的视觉效果比较好,同时不同类别之间的比较也还是有意义的。有三种分级模式:常数、对数和平方根,对于有值为负数的字段,在采用对数和 平方根的分级方式时,将取负值的绝对值作为参与计算的值。
变量: - GraduatedMode.CONSTANT -- 常量分级模式。按属性表中原始数值的线性比例进行分级运算。
- GraduatedMode.SQUAREROOT -- 平方根分级模式。按属性表中原始数值平方根的线性比例进行分级运算。
- GraduatedMode.LOGARITHM -- 对数分级模式。按属性表中原始数值自然对数的线性比例进行分级运算。
-
CONSTANT= 0¶
-
LOGARITHM= 2¶
-
SQUAREROOT= 1¶
-
class
iobjectspy.mapping.ThemeGraduatedSymbol(expression=None, base_value=0, positive_style=None, graduated_mode='CONSTANT')¶ 基类:
iobjectspy._jsuperpy.mapping.Theme等级符号专题图类。
SuperMap iObjects 的等级符号专题图是采用不同的形状、颜色和大小的符号, 表示各自独立的、以整体概念显示的各个物体的数量与质量特征。 通常以符号的形状、颜色和大小反映物体的特定属性; 符号的形状与颜色表示质量特征,符号的大小表示数量特征。
例如,可以通过以下方式创建等级符号专题图对象:
>>> theme = ThemeGraduatedSymbol.make_default(dataset, 'SmID')
或者:
>>> theme = ThemeGraduatedSymbol() >>> theme.set_expression('SmID').set_graduated_mode(GraduatedMode.CONSTANT).set_base_value(120).set_flow_enabled(True)
参数: - expression (str) -- 用于创建等级符号专题图的字段或字段表达式。用于制作等级符号专题图的字段或者字段表达式应为数值型字段
- base_value (float) -- 等级符号专题图的基准值,单位同专题变量的单位
- positive_style (GeoStyle) -- 正值的等级符号风格
- graduated_mode (GraduatedMode or str) -- 等级符号专题图分级模式
-
base_value¶ float -- 等级符号专题图的基准值,单位同专题变量的单位。
-
expression¶ str -- 用于创建等级符号专题图的字段或字段表达式。
-
get_offset_x()¶ 获取等级符号 X 坐标方向(横向)偏移量
返回: 等级符号 X 坐标方向(横向)偏移量 返回类型: str
-
get_offset_y()¶ 获取等级符号 Y 坐标方向(纵向)偏移量
返回: 等级符号 Y 坐标方向(纵向)偏移量 返回类型: str
-
get_positive_style()¶ 返回正值的等级符号风格。
返回: 正值的等级符号风格。 返回类型: bool
-
graduated_mode¶ GraduatedMode -- 返回等级符号专题图分级模式
-
is_flow_enabled()¶ 返回等级符号是否流动显示
返回: 等级符号是否流动显示 返回类型: bool
-
is_leader_line_displayed()¶ 返回是否显示等级符号及其相应对象之间的牵引线。
返回: 是否显示等级符号及其相应对象之间的牵引线 返回类型: bool
-
is_negative_displayed()¶ 返回是否显示负值的等级符号风格,true 表示显示
返回: 是否显示负值的等级符号风格 返回类型: bool
-
is_offset_prj_coordinate_unit()¶ 获取水平或垂直偏移量的单位是否是地理坐标系单位
返回: 水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。 返回类型: bool
-
is_zero_displayed()¶ 返回是否显示 0 值的等级符号风格,True 表示显示
返回: 是否显示 0 值的等级符号风格 返回类型: bool
-
static
make_default(dataset, expression, graduated_mode='CONSTANT')¶ 生成默认的等级符号专题图。
参数: - dataset (DataetVector or str) -- 矢量数据集。
- expression (str) -- 字段表达式
- graduated_mode (GraduatedMode or str) -- 专题图分级模式类型。
返回: 等级符号专题图
返回类型:
-
set_base_value(value)¶ 设置等级符号专题图的基准值,单位同专题变量的单位。
每个符号的显示大小等于
get_positive_style()(或get_zero_style()或get_negative_style())GeoStyle.marker_size()*value/base_value, 其中,value 指的是经过分级计算后的专题值, 即按照用户选择的分级模式(graduated_mode)对专题值进行计算后得到的值。参数: value (float) -- 等级符号专题图的基准值 返回: self 返回类型: ThemeGraduatedSymbol
-
set_expression(value)¶ 设置用于创建等级符号专题图的字段或字段表达式。 用于制作等级符号专题图的字段或者字段表达式应为数值型字段。
参数: value (str) -- 用于创建等级符号专题图的字段或字段表达式。 返回: self 返回类型: ThemeGraduatedSymbol
-
set_flow_enabled(value)¶ 设置等级符号是否流动显示。
参数: value (bool) -- 等级符号是否流动显示。 返回: self 返回类型: ThemeGraduatedSymbol
-
set_graduated_mode(value)¶ 设置等级符号专题图分级模式。
- 分级主要是为了减少制作等级符号专题图中数据大小之间的差异。如果数据之间差距较大,则可以采用对数或者平方根的分级方式来进行,这样就减少了数据 之间的绝对大小的差异,使得等级符号的视觉效果比较好,同时不同类别之间的比较也还是有意义的;
- 有三种分级模式:常数、对数和平方根,对于有值为负数的字段,不可以采用对数和平方根的分级方式;
- 不同的分级模式用于确定符号大小的数值是不相同的,常数按照字段的原始数据进行,对数则是对每条记录对应的专题值取自然对数、平方根则是对其取平方 根,用最终得到的结果来确定其等级符号的大小。
参数: value (GraduatedMode or str) -- 等级符号专题图分级模式 返回: self 返回类型: ThemeGraduatedSymbol
-
set_leader_line(is_displayed, style)¶ 设置显示等级符号及其相应对象之间的牵引线
参数: - is_displayed (bool) -- 是否显示 等级符号及其相应对象之间的牵引线的风格
- style (GeoStyle) --
返回: self
返回类型:
-
set_negative_displayed(is_displayed, style)¶ 设置是否显示负值的等级符号风格,true 表示显示。
参数: - is_displayed (bool) -- 是否显示负值的等级符号风格
- style (GeoStyle) -- 负值的等级符号风格
返回: self
返回类型:
-
set_offset_prj_coordinate_unit(value)¶ 设置水平或垂直偏移量的单位是否是地理坐标系单位。如果为 True 则是地理坐标单位,否则采用设备单位。具体查看
set_offset_x()和set_offset_y()接口。参数: value (bool) -- 水平或垂直偏移量的单位是否是地理坐标系单位 返回: self 返回类型: ThemeGraduatedSymbol
-
set_offset_x(value)¶ 设置等级符号 X 坐标方向(横向)偏移量
参数: value (str) -- 等级符号 X 坐标方向(横向)偏移量 返回: self 返回类型: ThemeGraduatedSymbol
-
set_offset_y(value)¶ 设置等级符号 Y 坐标方向(纵向)偏移量
参数: value (str) -- 等级符号 Y 坐标方向(纵向)偏移量 返回: self 返回类型: ThemeGraduatedSymbol
-
set_positive_style(value)¶ 设置正值的等级符号风格。
参数: value (GeoStyle) -- 正值的等级符号风格。 返回: self 返回类型: ThemeGraduatedSymbol
-
class
iobjectspy.mapping.ThemeDotDensity(expression=None, value=None, style=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme点密度专题图类。
SuperMap iObjects 的点密度专题图用一定大小、形状相同的点表示现象分布范围、数量特征和分布密度。 点的多少和所代表的意义由地图的内容确定。
以下代码示范了如何制作点密度专题图:
>>> ds = open_datasource('/home/data/data.udb') >>> dt = ds['world'] >>> mmap = Map() >>> theme = ThemeDotDensity('Pop_1994', 10000000.0) >>> mmap.add_dataset(dt, True, theme) >>> mmap.set_image_size(2000, 2000) >>> mmap.view_entire() >>> mmap.output_to_file('/home/data/mapping/dotdensity_theme.png')
参数: - expression (str) -- 用于创建点密度专题图的字段或字段表达式。
- value (float) -- 专题图中每一个点所代表的数值。点值的确定与地图比例尺以及点的大小有关。 地图比例尺越大,相应的图面范围也越大,点相应 就可以越多,此时点值就可以设置相对小一些。 点形状越大,点值相应就应该设置的小一些。点值过大或过小都是不合适的。
- style (GeoStyle) -- 点密度专题图中点的风格
-
expression¶ str -- 用于创建点密度专题图的字段或字段表达式。
-
set_expression(expression)¶ 设置用于创建点密度专题图的字段或字段表达式。
参数: expression (str) -- 用于创建点密度专题图的字段或字段表达式 返回: self 返回类型: ThemeDotDensity
-
set_style(style)¶ 设置点密度专题图中点的风格。
参数: style (GeoStyle) -- 点密度专题图中点的风格 返回: self 返回类型: ThemeDotDensity
-
set_value(value)¶ 设置专题图中每一个点所代表的数值。
点值的确定与地图比例尺以及点的大小有关。 地图比例尺越大,相应的图面范围也越大,点相应就可以越多,此时点值就可以设置相对小一些。 点形状越大, 点值相应就应该设置的小一些。点值过大或过小都是不合适的。
参数: value (float) -- 专题图中每一个点所代表的数值。 返回: self 返回类型: ThemeDotDensity
-
style¶ GeoStyle -- 点密度专题图中点的风格
-
value¶ float -- 专题图中每一个点所代表的数值
-
class
iobjectspy.mapping.ThemeGridUniqueItem(unique_value, color, caption, visible=True)¶ 基类:
object栅格单值专题图子项类。
参数: - unique_value (str) -- 栅格单值专题图子项的单值
- color (Color) -- 栅格单值专题图子项的显示颜色
- caption (str) -- 栅格单值专题图子项的名称
- visible (bool) -- 栅格单值专题图子项是否可见
-
caption¶ str -- 栅格单值专题图子项的名称
-
color¶ Color -- 栅格单值专题图子项的显示颜色
-
set_caption(value)¶ 设置每个栅格单值专题图子项的名称
参数: value (str) -- 每个栅格单值专题图子项的名称 返回: self 返回类型: ThemeGridUniqueItem
-
set_color(value)¶ 设置每个栅格单值专题图子项的显示颜色。
参数: value (Color or str) -- 栅格单值专题图子项的显示颜色。 返回: self 返回类型: ThemeGridUniqueItem
-
set_unique_value(value)¶ 设置栅格单值专题图子项的单值
参数: value (str) -- 栅格单值专题图子项的单值 返回: self 返回类型: ThemeGridUniqueItem
-
set_visible(value)¶ 设置栅格单值专题图子项是否可见
参数: value (bool) -- 栅格单值专题图子项是否可见 返回: self 返回类型: ThemeGridUniqueItem
-
unique_value¶ str -- 栅格单值专题图子项的单值
-
visible¶ bool -- 栅格单值专题图子项是否可见
-
class
iobjectspy.mapping.ThemeGridUnique(items=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme栅格单值专题图类。
栅格单值专题图,是将单元格值相同的归为一类,为每一类设定一种颜色,从而用来区分不同的类别。栅格单值专题图适用于离散栅格数据和部分连续栅格数据,对于 单元格值各不相同的那些连续栅格数据,使用栅格单值专题图不具有任何意义。
例如,可以通过以下方式创建栅格专题图对象:
>>> theme = ThemeGridUnique.make_default(dataset, 'RAINBOW')
或者:
>>> theme = ThemeGridUnique() >>> theme.add(ThemeGridUniqueItem(1, Color.rosybrown(), '1')) >>> theme.add(ThemeGridUniqueItem(2, Color.coral(), '2')) >>> theme.add(ThemeGridUniqueItem(3, Color.darkred(), '3')) >>> theme.add(ThemeGridUniqueItem(4, Color.blueviolet(), '4')) >>> theme.add(ThemeGridUniqueItem(5, Color.greenyellow(), '5')) >>> theme.set_default_color(Color.white())
参数: items (list[ThemeGridUniqueItem] or tuple[ThemeGridUniqueItem]) -- 栅格单值专题图子项列表 -
add(item)¶ 添加栅格单值专题图子项
参数: item (ThemeGridUniqueItem) -- 栅格单值专题图子项 返回: self 返回类型: ThemeGridUnique
-
clear()¶ 删除所有栅格单值专题图子项。
返回: self 返回类型: ThemeGridUnique
-
extend(items)¶ 批量添加栅格单值专题图子项
参数: items (list[ThemeGridUniqueItem] or tuple[ThemeGridUniqueItem]) -- 栅格单值专题图子项列表 返回: self 返回类型: ThemeGridUnique
-
get_count()¶ 返回栅格单值专题图子项个数
返回: 栅格单值专题图子项个数 返回类型: int
-
get_default_color()¶ 返回栅格单值专题图的默认颜色,对于那些未在栅格单值专题图子项之列的对象使用该颜色显示。如未设置,则使用图层默认的颜色显示。
返回: 栅格单值专题图的默认颜色。 返回类型: Color
-
get_item(index)¶ 返回指定序号的栅格单值专题图子项
参数: index (int) -- 指定的栅格单值专题图子项的序号 返回: 指定序号的栅格单值专题图子项 返回类型: ThemeGridUniqueItem
-
get_special_value()¶ 返回栅格单值专题图层的特殊值。 在新增一个栅格图层时,该方法的返回值与数据集的 NoValue 属性值相等。
返回: 栅格单值专题图层的特殊值。 返回类型: float
-
index_of(unique_value)¶ 返回栅格单值专题图中指定子项单值在当前序列中的序号。
参数: unique_value (int) -- 给定的栅格单值专题图子项的单值 返回: 栅格专题图子项在序列中的序号值。如果该值不存在,就返回 -1。 返回类型: int
-
insert(index, item)¶ 将给定的栅格单值专题图子项插入到指定序号的位置。
参数: - index (int) -- 指定的栅格单值专题图子项序列的序号。
- item (ThemeGridUniqueItem) -- 插入的栅格单值专题图子项。
返回: self
返回类型:
-
is_special_value_transparent()¶ 栅格单值专题图层的特殊值所处区域是否透明。
返回: 栅格单值专题图层的特殊值所处区域是否透明;True表示透明;False表示不透明。 返回类型: bool
-
static
make_default(dataset, color_gradient_type=None)¶ 根据给定的栅格数据集和颜色渐变模式生成默认的栅格单值专题图。 只支持对栅格值为整型的栅格数据集制作单值专题图,对于栅格值为浮点型的栅格数据集不能制作栅格单值专题图。
参数: - dataset (DatasetGrid or str) -- 栅格数据集
- color_gradient_type (ColorGradientType or str) -- 颜色渐变模式
返回: 新的栅格单值专题图类的对象实例
返回类型:
-
remove(index)¶ 删除一个指定序号的栅格单值专题图子项。
参数: index (int) -- 指定的将被删除的栅格单值专题图子项序列的序号。 返回: 删除成功,返回 True;否则返回 False。 返回类型: bool
-
reverse_color()¶ 对栅格单值专题图中子项的颜色进行反序显示。
返回: self 返回类型: ThemeGridUnique
-
set_default_color(color)¶ 设置栅格单值专题图的默认颜色,对于那些未在栅格单值专题图子项之列的对象使用该颜色显示。如未设置,则使用图层默认的颜色显示。
参数: color (Color or str) -- 栅格单值专题图的默认颜色 返回: self 返回类型: ThemeGridUnique
-
-
class
iobjectspy.mapping.ThemeGridRangeItem(start, end, color, caption, visible=True)¶ 基类:
object栅格分段专题图子项类。
在栅格分段专题图中,将分段字段的表达式的值按照某种分段模式被分成多个范围段。本类用来设置每个范围段的分段起始值、终止值、名称和颜色等。 每个分段所表示的范围为 [Start,End)。
参数: - start (float) -- 栅格分段专题图子项的起始值
- end (float) -- 栅格分段专题图子项的终止值
- color (Color) -- 栅格分段专题图中每一个分段专题图子项的对应的颜色。
- caption (str) -- 栅格分段专题图中子项的名称
- visible (bool) -- 栅格分段专题图中的子项是否可见
-
caption¶ str -- 栅格分段专题图中子项的名称
-
color¶ Color -- 栅格分段专题图中每一个分段专题图子项的对应的颜色。
-
end¶ float -- 栅格分段专题图子项的终止值
-
set_caption(value)¶ 设置栅格分段专题图中子项的名称。
参数: value (str) -- 栅格分段专题图中子项的名称。 返回: self 返回类型: ThemeGridRangeItem
-
set_color(value)¶ 设置栅格分段专题图中每一个分段专题图子项的对应的颜色。
参数: value (Color or str) -- 栅格分段专题图中每一个分段专题图子项的对应的颜色。 返回: self 返回类型: ThemeGridRangeItem
-
set_end(value)¶ 设置栅格分段专题图子项的终止值。 注意:如果该子项是分段中最后一个子项,那么该终止值就是分段的最大值;如果不是最后一项,该终止值必须与下一子项的起始值相同,否则系统抛出异常。
参数: value (float) -- 栅格分段专题图子项的终止值。 返回: self 返回类型: ThemeGridRangeItem
-
set_start(value)¶ 设置栅格分段专题图子项的起始值。 注意:如果该子项是分段中第一个子项,那么该起始值就是分段的最小值;如果子项的序号大于等于 1 的时候,该起始值必须与前一子项的终止值相同,否则 系统会抛出异常。
参数: value (float) -- 栅格分段专题图子项的起始值。 返回: self 返回类型: ThemeGridRangeItem
-
set_visible(value)¶ 设置栅格分段专题图中的子项是否可见
参数: value (bool) -- 栅格分段专题图中的子项是否可见 返回: self 返回类型: ThemeGridRangeItem
-
start¶ float -- 栅格分段专题图子项的起始值
-
visible¶ bool -- 栅格分段专题图中的子项是否可见
-
class
iobjectspy.mapping.ThemeGridRange(items=None)¶ 基类:
iobjectspy._jsuperpy.mapping.Theme栅格分段专题图类。
栅格分段专题图,是将所有单元格的值按照某种分段方式分成多个范围段,值在同一个范围段中的单元格使用相同的颜色进行显示。栅格分段专题图一般用来反映连 续分布现象的数量或程度特征。比如某年的全国降水量分布图,将各气象站点的观测值经过内插之后生成的栅格数据进行分段显示。该类类似于分段专题图类,不同 点在于分段专题图的操作对象是矢量数据,而栅格分段专题图的操作对象是栅格数据。
例如,可以通过以下方式创建栅格专题图对象:
>>>theme = ThemeGridRange.make_default(dataset, 'EUQALINTERVAL', 6, 'RAINBOW')或者:
>>> theme = ThemeGridRange() >>> theme.add(ThemeGridRangeItem(-999, 3, 'rosybrown', '1')) >>> theme.add(ThemeGridRangeItem(3, 6, 'darkred', '2')) >>> theme.add(ThemeGridRangeItem(6, 9, 'cyan', '3')) >>> theme.add(ThemeGridRangeItem(9, 20, 'blueviolet', '4')) >>> theme.add(ThemeGridRangeItem(20, 52, 'darkkhaki', '5'))
参数: items (list[ThemeGridRangeItem] or tuple[ThemeGridRangeItem]) -- 栅格分段专题图子项列表 -
add(item, is_normalize=True, is_add_to_head=False)¶ 添加栅格分段专题图子项列表
参数: - item (ThemeGridRangeItem) -- 栅格分段专题图子项列表
- is_normalize (bool) -- 表示是否规整化,normalize 为 true时, item 值不合法,则进行规整,normalize 为 fasle时, item 值不合法则抛异常
- is_add_to_head (bool) -- 是否添加到分段列表的头部,如果为True则添加到头部,否则添加到尾部。
返回: self
返回类型:
-
clear()¶ 删除栅格分段专题图的一个分段值。执行该方法后,所有的栅格分段专题图子项都被释放,不再可用。
返回: self 返回类型: ThemeGridRange
-
extend(items, is_normalize=True)¶ 批量添加栅格分段专题图子项列表。默认添加到末尾。
参数: - items (list[ThemeGridRangeItem] or tuple[ThemeGridRangeItem]) -- 栅格分段专题图子项列表
- is_normalize (bool) -- 表示是否规整化,normalize 为 true时, item 值不合法,则进行规整,normalize 为 fasle时, item 值不合法则抛异常
返回: self
返回类型:
-
get_count()¶ 返回栅格分段专题图中分段的个数
返回: 栅格分段专题图中分段的个数 返回类型: int
-
get_item(index)¶ 返回指定序号的栅格分段专题图中分段专题图子项
参数: index (int) -- 指定的栅格分段专题图子项序号。 返回: 指定序号的栅格分段专题图中分段专题图子项。 返回类型: ThemeGridRangeItem
-
get_special_value()¶ 返回栅格分段专题图层的特殊值。
返回: 栅格分段专题图层的特殊值。 返回类型: float
-
index_of(value)¶ 返回栅格分段专题图中指定分段字段值在当前分段序列中的序号。
参数: value (str) -- 返回: 分段字段值在分段序列中的序号。如果给定的分段字段的值不存在与其对应的序号,就返回-1。 返回类型: int
-
is_special_value_transparent()¶ 栅格分段专题图层的特殊值所处区域是否透明。
返回: 栅格分段专题图层的特殊值所处区域是否透明;True表示透明;False表示不透明。 返回类型: bool
-
static
make_default(dataset, range_mode, range_parameter, color_gradient_type=None)¶ 根据给定的栅格数据集、分段模式和相应的分段参数生成默认的栅格分段专题图。
参数: - dataset (DatasetGrid or str) -- 栅格数据集。
- range_mode (RangeMode or str) -- 分段模式。只支持等距离分段法,平方根分段法,对数分段法,以及自定义距离法。
- range_parameter (float) -- 分段参数。当分段模式为等距离分段法,平方根分段法,对数分段法其中一种时,该参数为分段个数;当分段模式为自定义距离时,该参数表示自定义距离。
- color_gradient_type (ColorGradientType or str) -- 颜色渐变模式。
返回: 新的栅格分段专题图对象。
返回类型:
-
range_mode¶ RangeMode -- 当前专题图的分段模式
-
reverse_color()¶ 对分段专题图中分段的风格进行反序显示。
返回: self 返回类型: ThemeGridRange
-
-
class
iobjectspy.mapping.ThemeCustom¶ 基类:
iobjectspy._jsuperpy.mapping.Theme自定义专题图类,该类可以通过字段表达式来动态设置显示的风格。
-
get_fill_back_color_expression()¶ 返回表示填充背景色的字段表达式。
返回: 表示填充背景色的字段表达式。 返回类型: str
-
get_fill_fore_color_expression()¶ 返回表示填充颜色的字段表达式。
返回: 表示填充颜色的字段表达式 返回类型: str
-
get_fill_gradient_angle_expression()¶ 返回表示填充角度的字段表达式
:return:表示填充角度的字段表达式 :rtype: str
-
get_fill_gradient_mode_expression()¶ 返回表示填充渐变类型的字段表达式。
返回: 表示填充渐变类型的字段表达式。 返回类型: str
-
get_fill_gradient_offset_ratio_x_expression()¶ 返回表示填充中心点 X 方向偏移量的字段表达式
返回: 表示填充中心点 X 方向偏移量的字段表达式 返回类型: str
-
get_fill_gradient_offset_ratio_y_expression()¶ 返回表示填充中心点 Y 方向偏移量的字段表达式
返回: 表示填充中心点 Y 方向偏移量的字段表达式 返回类型: str
-
get_fill_opaque_rate_expression()¶ 返回表示填充不透明度的字段表达式
返回: 表示填充不透明度的字段表达式 返回类型: str
-
get_fill_symbol_id_expression()¶ 返回表示填充符号风格的字段表达式。
返回: 表示填充符号风格的字段表达式。 返回类型: str
-
get_line_color_expression()¶ 返回: 返回类型: str
-
get_line_symbol_id_expression()¶ 获取表示线型符号或是点符号的颜色的字段表达式
返回: 表示线型符号或是点符号的颜色的字段表达式 返回类型: str
-
get_line_width_expression()¶ 获取表示线型符号线宽的字段表达式
返回: 表示线型符号线宽的字段表达式 返回类型: str
-
get_marker_angle_expression()¶ 返回表示点符号旋转角度的字段表达式。旋转的方向为逆时针方向,单位为度
返回: 表示点符号旋转角度的字段表达式 返回类型: str
-
get_marker_size_expression()¶ 返回表示点符号尺寸的字段表达式。单位为毫米
返回: 表示点符号尺寸的字段表达式。 返回类型: str
-
get_marker_symbol_id_expression()¶ 返回表示点符号风格的字段表达式。
返回: 表示点符号风格的字段表达式。 返回类型: str
-
is_argb_color_mode()¶ 返回颜色表达式中的颜色表示规则是否为RGB模式。默认值为 False。
当返回值为true时,表示颜色表达式的值采用RRGGBB的方式来表达颜色。(RRGGBB为16进制的颜色转换为十进制的数值,一般通过将桌面颜色面板下的16 进制值转为十进制数值获取。)
当属性值为false时,表示颜色表达式的值采用BBGGRR的方式来表达颜色。(BBGGRR为16进制的颜色转换为十进制的数值,一般通过将桌面颜色面板,首先 将目标颜色的R和B值互换,然后将获得的16进制值转为十进制数值即为目标颜色的BBGGRR十进制数值。)
返回: 颜色表达式中的颜色表示规则是否为RGB模式 返回类型: bool
-
set_argb_color_mode(value)¶ 设置颜色表达式中的颜色表示规则是否为RGB模式。默认值为 False。
当返回值为true时,表示颜色表达式的值采用RRGGBB的方式来表达颜色。(RRGGBB为16进制的颜色转换为十进制的数值,一般通过将桌面颜色面板下的16 进制值转为十进制数值获取。)
当属性值为false时,表示颜色表达式的值采用BBGGRR的方式来表达颜色。(BBGGRR为16进制的颜色转换为十进制的数值,一般通过将桌面颜色面板,首先 将目标颜色的R和B值互换,然后将获得的16进制值转为十进制数值即为目标颜色的BBGGRR十进制数值。)
参数: value (bool) -- 颜色表达式中的颜色表示规则是否为RGB模式 返回: self 返回类型: ThemeCustom
-
set_fill_back_color_expression(value)¶ 设置表示填充背景色的字段表达式
参数: value (str) -- 表示填充背景色的字段表达式。 返回: self 返回类型: ThemeCustom
-
set_fill_fore_color_expression(value)¶ 设置表示填充颜色的字段表达式
参数: value (str) -- 表示填充颜色的字段表达式 返回: self 返回类型: ThemeCustom
-
set_fill_gradient_angle_expression(value)¶ 设置表示填充角度的字段表达式
参数: value (str) -- 表示填充角度的字段表达式 返回: self 返回类型: ThemeCustom
-
set_fill_gradient_mode_expression(value)¶ 设置表示填充渐变类型的字段表达式。
参数: value (str) -- 表示填充渐变类型的字段表达式。 返回: self 返回类型: ThemeCustom
-
set_fill_gradient_offset_ratio_x_expression(value)¶ 设置表示填充中心点 X 方向偏移量的字段表达式
参数: value (str) -- 表示填充中心点 X 方向偏移量的字段表达式 返回: self 返回类型: ThemeCustom
-
set_fill_gradient_offset_ratio_y_expression(value)¶ 设置表示填充中心点 Y 方向偏移量的字段表达式
参数: value (str) -- 表示填充中心点 Y 方向偏移量的字段表达式 返回: self 返回类型: ThemeCustom
-
set_fill_opaque_rate_expression(value)¶ 设置表示填充不透明度的字段表达式
参数: value (str) -- 表示填充不透明度的字段表达式 返回: self 返回类型: ThemeCustom
-
set_fill_symbol_id_expression(value)¶ 设置表示填充符号风格的字段表达式。
参数: value (str) -- 表示填充符号风格的字段表达式。 返回: self 返回类型: ThemeCustom
-
set_line_color_expression(value)¶ 设置表示线型符号或是点符号的颜色的字段表达式
参数: value (str) -- 表示线型符号或是点符号的颜色的字段表达式 返回: self 返回类型: ThemeCustom
-
set_line_symbol_id_expression(value)¶ 设置表示线型符号风格的字段表达式
参数: value (str) -- 表示线型符号风格的字段表达式 返回: self 返回类型: ThemeCustom
-
set_line_width_expression(value)¶ 设置表示线型符号线宽的字段表达式。
参数: value (str) -- 表示线型符号线宽的字段表达式 返回: self 返回类型: ThemeCustom
-
set_marker_angle_expression(value)¶ 设置表示点符号旋转角度的字段表达式。旋转的方向为逆时针方向,单位为度
参数: value (str) -- 表示点符号旋转角度的字段表达式。 返回: self 返回类型: ThemeCustom
-
set_marker_size_expression(value)¶ 设置表示点符号尺寸的字段表达式。单位为毫米。
参数: value (str) -- 表示点符号尺寸的字段表达式。单位为毫米。 返回: self 返回类型: ThemeCustom
-
set_marker_symbol_id_expression(value)¶ 设置表示点符号风格的字段表达式。
参数: value (str) -- 表示点符号风格的字段表达式。 返回: self 返回类型: ThemeCustom
-
iobjectspy.threeddesigner module¶
-
iobjectspy.threeddesigner.linear_extrude(input_data, out_data=None, out_dataset_name='Extrude_Result', height=None, twist=0.0, scaleX=1.0, scaleY=1.0, progress=None)¶ 线性拉伸:将矢量面根据给定高度拉伸为白模模型 :param input_data: 给定的面数据集 :param out_data: 输出数据源 :param out_dataset_name: 输出数据集名字 :param bLonLat: :param height: :param twist: :param scaleX: :param scaleY: :return:
-
iobjectspy.threeddesigner.build_house(input_data, out_data=None, out_dataset_name='House', wallHeight=0.0, wallMaterial=None, eaveHeight=0.0, eaveWidth=0.0, eaveMaterial=None, roofWidth=0.0, roofSlope=0.0, roofMaterial=None, progress=None)¶ 构建房屋模型:由多边形构建房屋模型(可构建墙体、挑檐、屋顶) :param input_data:指定的源矢量数据集,支持二三维面数据集 :param out_data:输出数据源 :param out_dataset_name:输出数据集名称 :param wallHeight:房屋的墙体高度 :param wallMaterail:墙体材质参数 :param eaveHeight:屋檐高度 :param eaveWidth:屋檐宽度 :param eaveMaterial:屋檐材质参数 :param roofWidth:屋顶宽度 :param roofSlope:屋顶坡度,单位度 :param roofMaterail:屋顶材质参数 :param progress:进度事件 :return:返回模型数据集
-
iobjectspy.threeddesigner.compose_models(value)¶
-
class
iobjectspy.threeddesigner.Material3D¶ 基类:
object材质相关参数设置,主要是颜色,纹理图片和纹理重复模式和重复次数
-
color¶
-
is_texture_times_repeat¶
-
set_color(color)¶
-
set_is_texture_times_repeat(b)¶
-
set_texture_file(textureFile)¶
-
set_uTiling(uTiling)¶
-
set_vTiling(vTiling)¶
-
texture_file¶
-
uTiling¶
-
vTiling¶
-
-
iobjectspy.threeddesigner.building_height_check(input_data=None, height=0.0)¶ 规划控高检查 :param input_data:建筑模型记录集或者数据集 :param height:限制高度 :return:返回超高建筑ID
-
iobjectspy.threeddesigner.lonLatToENU(points, pntInsert)¶ : 将经纬度的点转成以经纬度作为插入点的笛卡尔坐标系的点 :param points:带转换的点(支持二三维点) :param pntInsert:pntInsert插入点 :return:以经纬度作为插入点的笛卡尔坐标系的点(三维点)
-
class
iobjectspy.threeddesigner.BoolOperation3D¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase-
check()¶ 对模型对象进行检查是否满足布尔运算条件 :param geometry3d: :return:
-
erase(erase_geomety3d)¶ 两个指定三维几何对象的差运算 :param geometry3d: :param erase_geomety3d: :return: 返回差集Geometry3D对象
-
intersect(intersect_geomety3d)¶ 两个指定三维几何对象的交集 :param geometry3d: :param geomety3d: :return: 返回交集Geometry3D对象
-
isClosed()¶ 检查Geometry3D对象是否闭合 :param geometry3d: :return: true表示闭合,false表示不闭合
-
union(union_geomety3d)¶ 两个指定三维几何对象的并集 :param geometry3d: :param union_geomety3d: :return: 返回并集Geometry3D对象
-
-
class
iobjectspy.threeddesigner.ModelBuilder3D¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase-
create_buffer(offset, bLonLat=False, joinType=Buffer3DJoinType.ROUND)¶ 三维缓冲,支持线、面缓冲(拓展)成面;模型缓冲(拓展)成三维实体模型 :param geometry:线、面及模型对象 :param offset:缓冲距离 :param bLonLat:是否是经纬度 :param joinType:衔接样式,包括尖角、圆角、斜角。
三维线缓冲成面支持尖角衔接样式,缓冲成体支持尖角和圆角衔接样式。 三维面仅支持缓冲成三维面,衔接样式包括尖角和圆角衔接样式。 实体模型仅支持缓存成体,无衔接样式返回:
-
linear_extrude(geometry, bLonLat, height)¶ 线性拉伸 该方法仅在 Windows 平台版本中支持,在 Linux版本中不提供 :param geometry:待进行线性拉伸的面 :param bLonLat:是否是经纬度 :param height:拉伸高度 :param twist:旋转角度 :param scaleX:绕X轴方向缩放 :param scaleY:绕Y轴方向缩放 :param material:贴图设置 :return:返回GeoModel3D对象
-
loft(line3D, bLonLat=False, nChamfer=50, chamferStyle=ChamferStyle.SOBC_CIRCLE_ARC)¶ 放样,该方法仅在 Windows 平台版本中支持,在 Linux版本中不提供 :param geometry:放样的横截面, 支持二维对象:GeoLine,GeoLineEPS,GeoCirCle,GeoRegion,GeoRegionEPS,GeoEllipse,GeoRect 支持三维对象:GeoLine3D,GeoCircle3D,GeoRegion3D :param line3D:待放样的线对象 :param bLonLat:是否是经纬度 :param nChamfer:平滑程度 :param chamferStyle: 倒角样式 :param material:贴图设置 :return:返回GeoModel3D对象
-
mirror(plane=None)¶ :获取geomodel3d关于plane镜像的模型对象 :param plane:镜像面 :return:返回geomodel3d关于plane镜像的模型对象
-
plane_projection(plane=None)¶ 平面投影,在 Linux版本中不提供 :param geomodel3d:待进行截面投影的三维几何模型对象 :param plane:投影平面 :return:返回投影面
-
rotate_extrude(angle, slices, isgroup=False, hasStartFace=True, hasRingFace=True, hasEndFace=True)¶ 旋转拉伸 该方法仅在 Windows 平台版本中支持,在 Linux版本中不提供 :param geometry: 面对象(必须在平面坐标系下构建) :param angle:旋转角度 :param slices:切分次数 :param isgroup:是否拆分成多个对象 :param hasStartFace:是否需要起始面 :param hasRingFace:是否需要环 :param hasEndFace:是否需要终止面 :return: 返回GeoModel3D对象
-
section_projection(plane=None)¶ 截面投影,在 Linux版本中不提供 :param geometry:待进行截面投影的三维几何模型对象 :param plane:投影平面 :return:返回投影面
-
straight_skeleton(dAngle, bLonLat=False)¶ 直骨架生成 :param geometry:待直骨架的面对象 :param bLonLat:是否是经纬度 :param dAngle:拆分的角度阈值 :return:成功返回三维模型
-
-
class
iobjectspy.threeddesigner.ClassificationOperator¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBase-
add_labels_to_S3M_file(outputFolder, labelsArray)¶ 导入OSGB倾斜摄影数据,利用标签数组生成S3M数据,并保存到outputFolder中 :param osgbFilePath:OSGB倾斜摄影数据 :param outputFolder:结果保存路径 :param labelsArray:标签数组
-
extract_infos()¶ 导入OSGB倾斜摄影数据,得到该数据的顶点、法线以及标签信息 :param osgbFilePath:原始倾斜摄影切片OSGB数据
-
generate_training_set()¶ 导入S3M单体化数据,得到该数据的顶点、法线以及标签信息 :param diecretFilePath:单体化S3M数据
-
-
class
iobjectspy.threeddesigner.ClassificationInfos¶ 基类:
iobjectspy._jsuperpy.data._jvm.JVMBasecom.supermap.data.processing.ClassificationInfos 的python对象映射 单体化倾斜摄影数据OSGB,S3M的导出对象
-
labels¶ 标签列表 :return: list标签列表
-
normals¶ 法线列表 :return: list 法线列表
-
vertices¶ 顶点列表 :return: list 顶点列表
-
-
iobjectspy.threeddesigner.CreateIFCFile(DatasourcePath, RegionDatasetName, ModelDatasetName, IFCFilePath, ExtrudeHeightField)¶ 从数据集创建IFC文件 :DatasourcePath:数据源 :RegionDatasetName:数据集 :IFCFilePath:IFC保存路径 :ExtrudeHeightField:拉伸字段